Comparative Performance Evaluation of Modern Heterogeneous High-Performance Computing Systems CPUs

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. The Description of Computing Platforms and Utilized System Software
2.2. Benchmark Conditions and Means
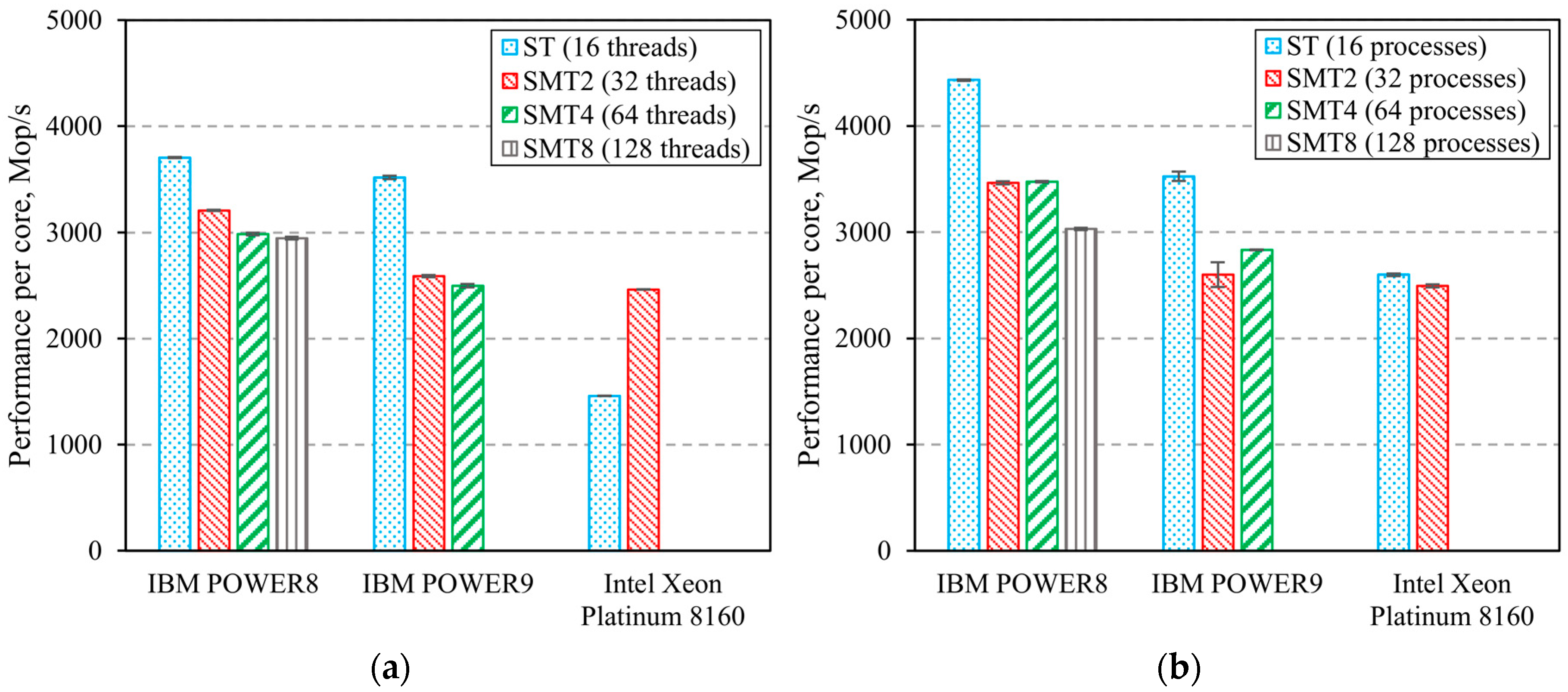
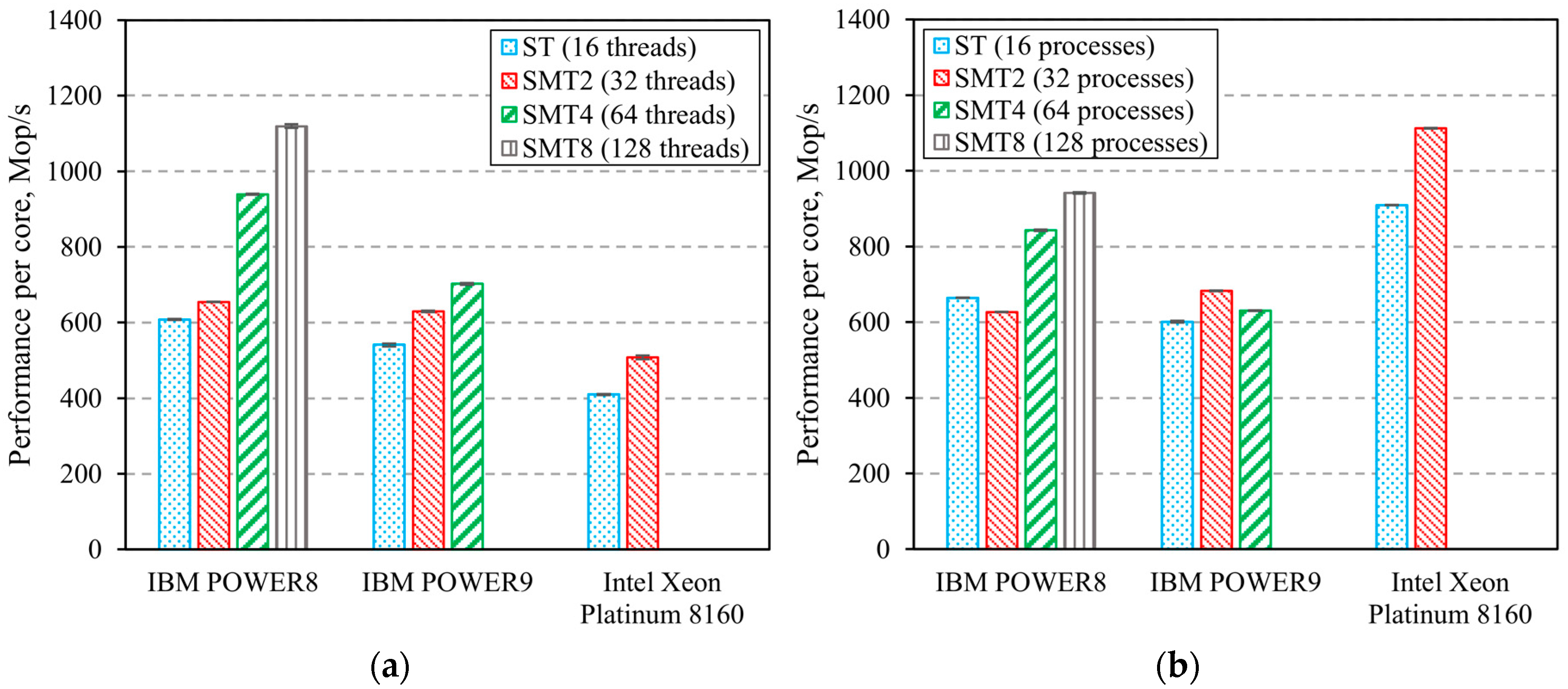
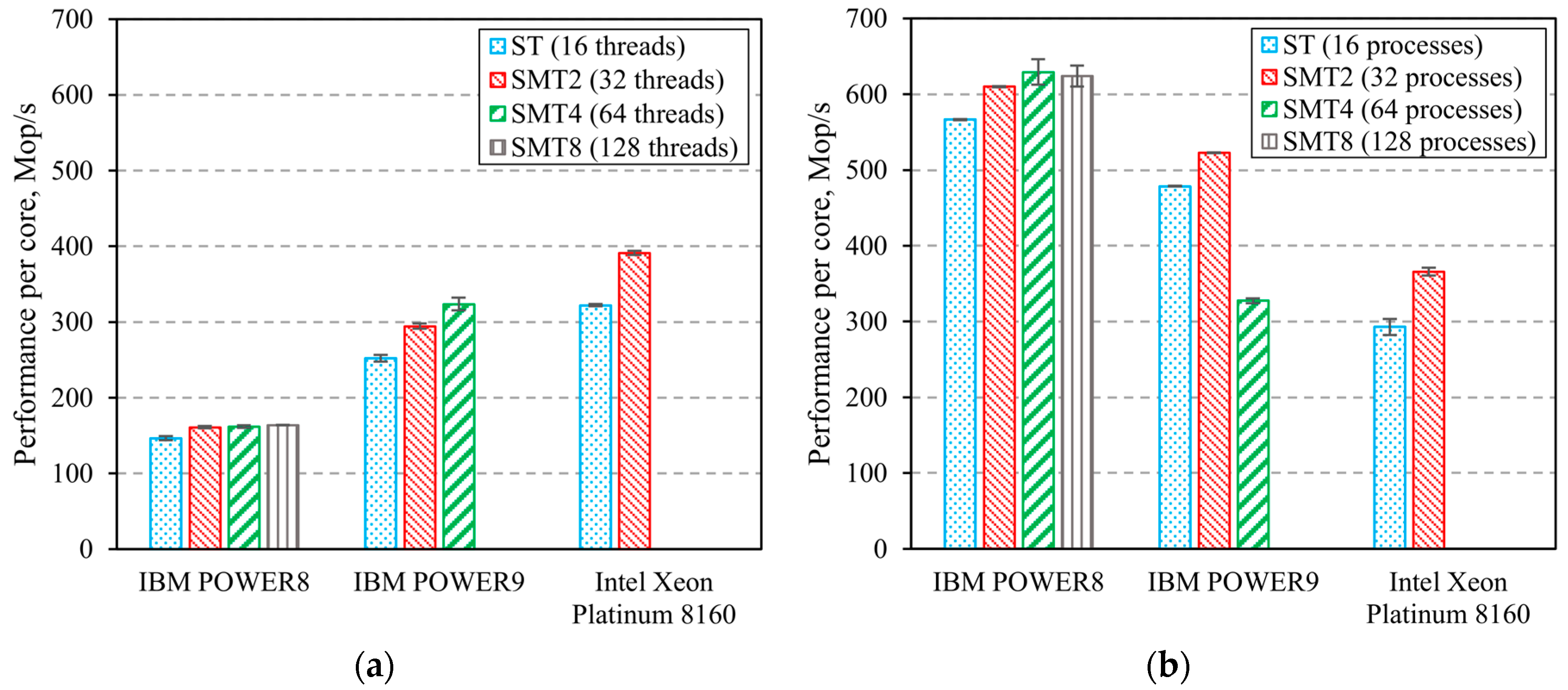
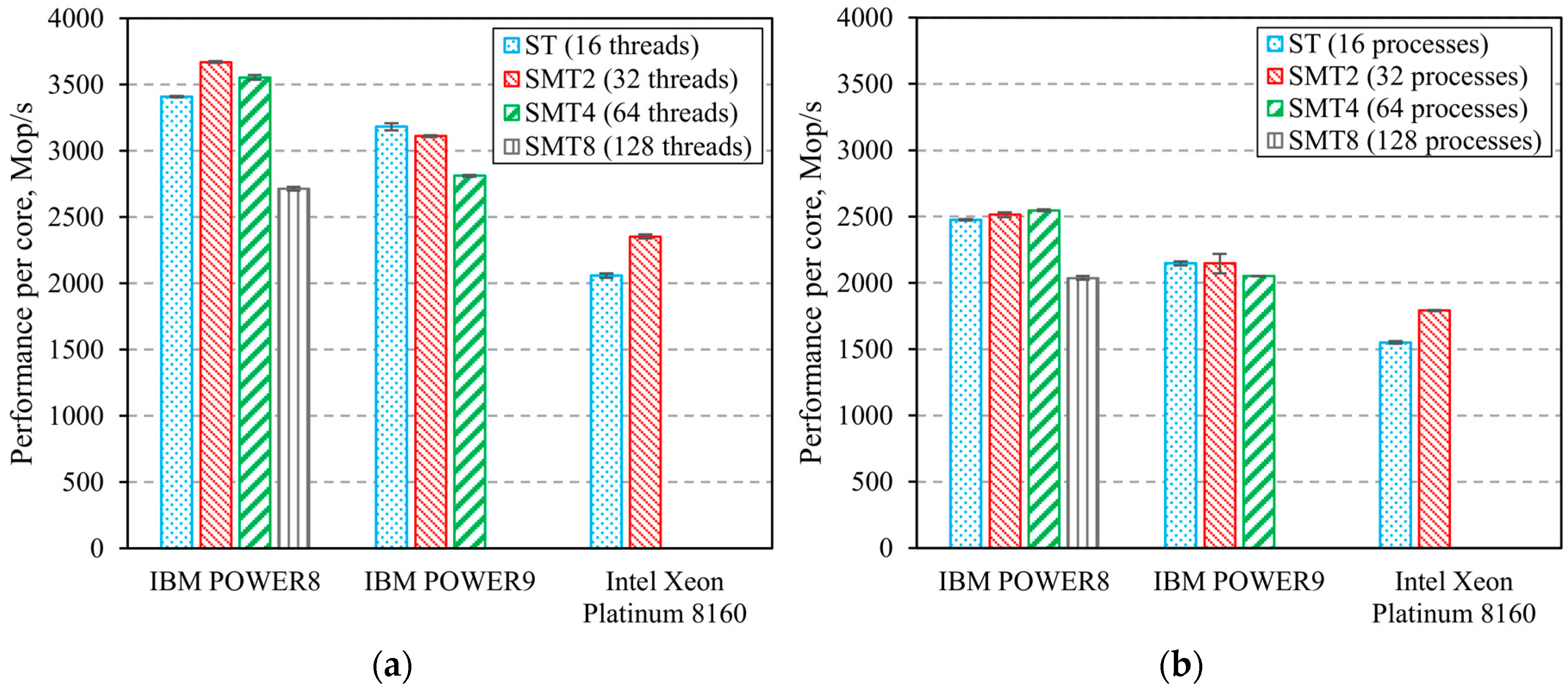
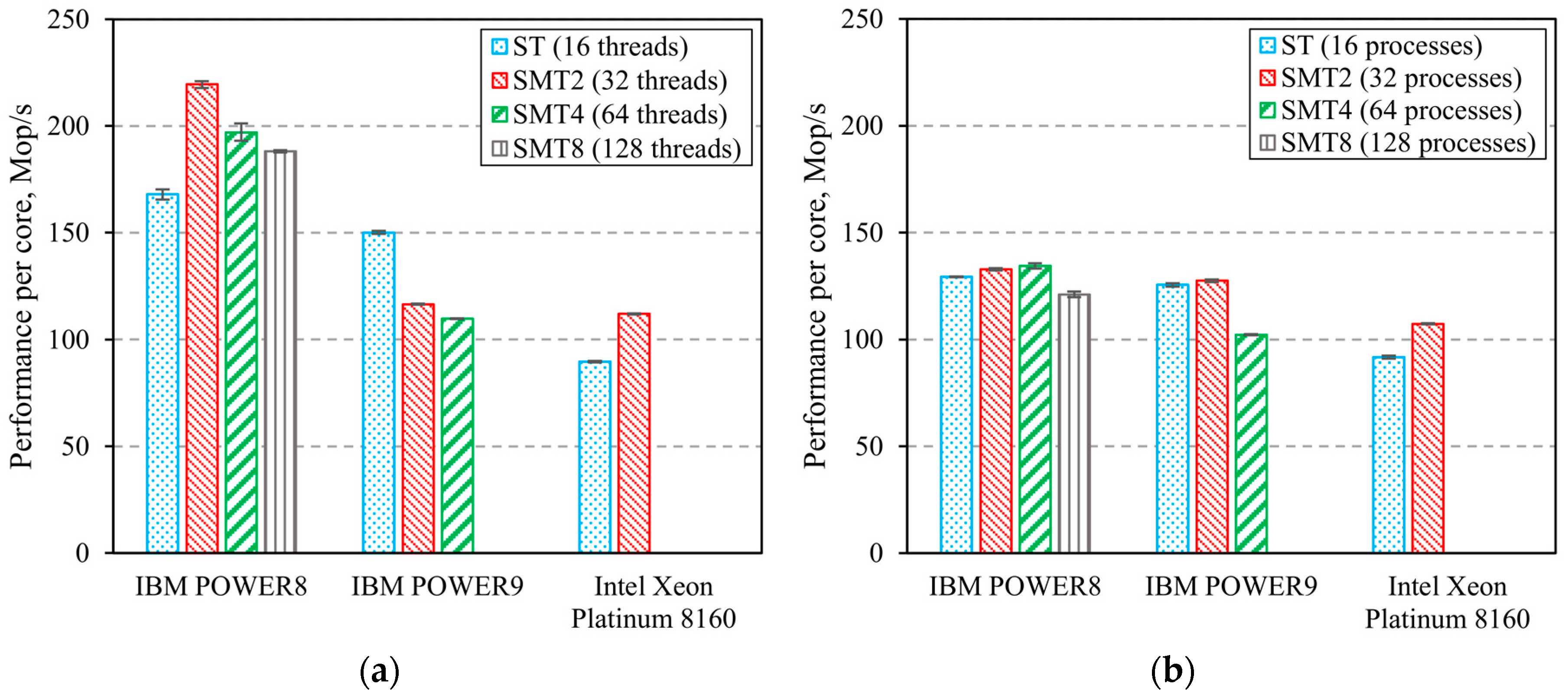
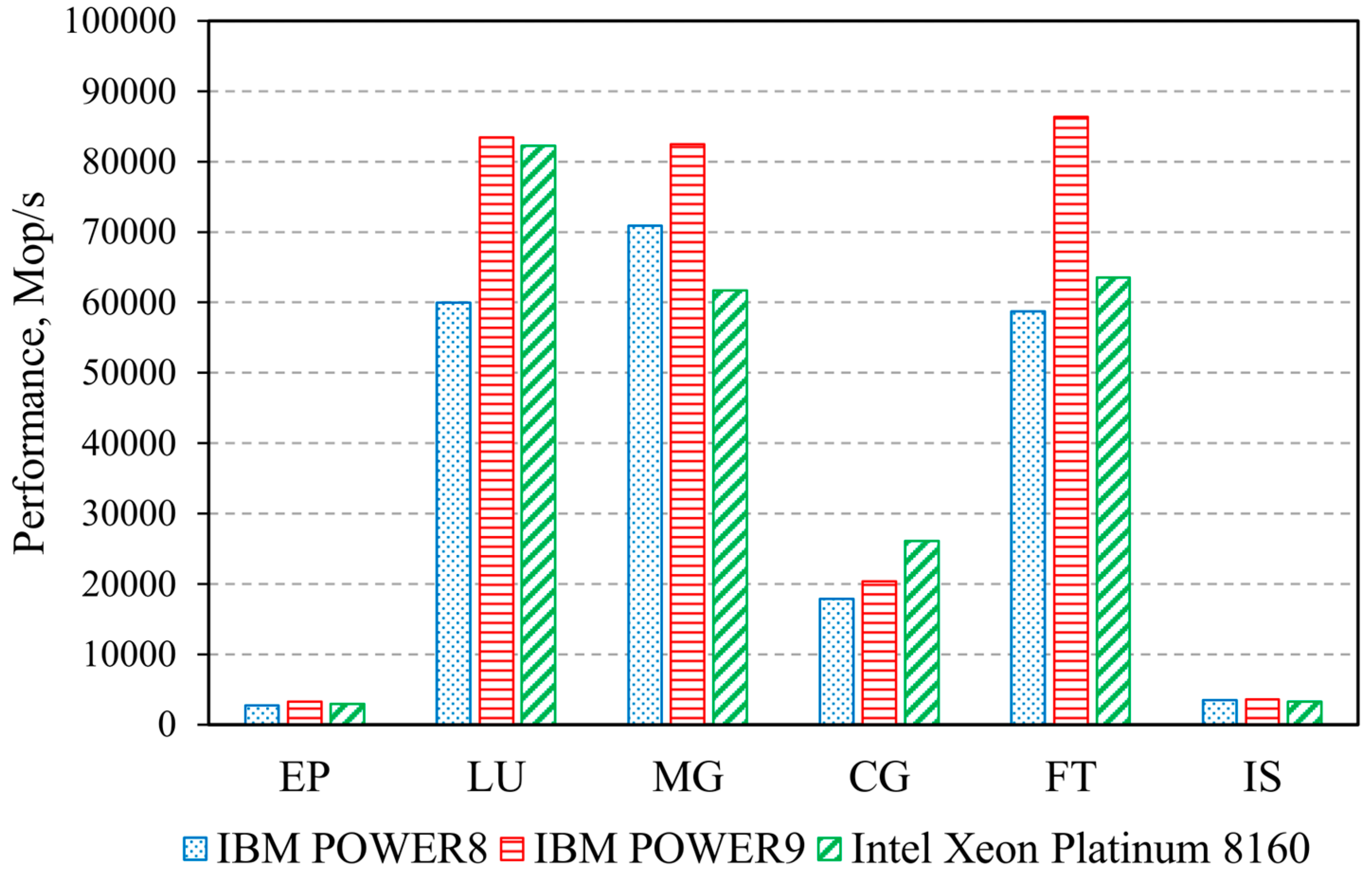
3. Computing Systems’ Benchmarks Results
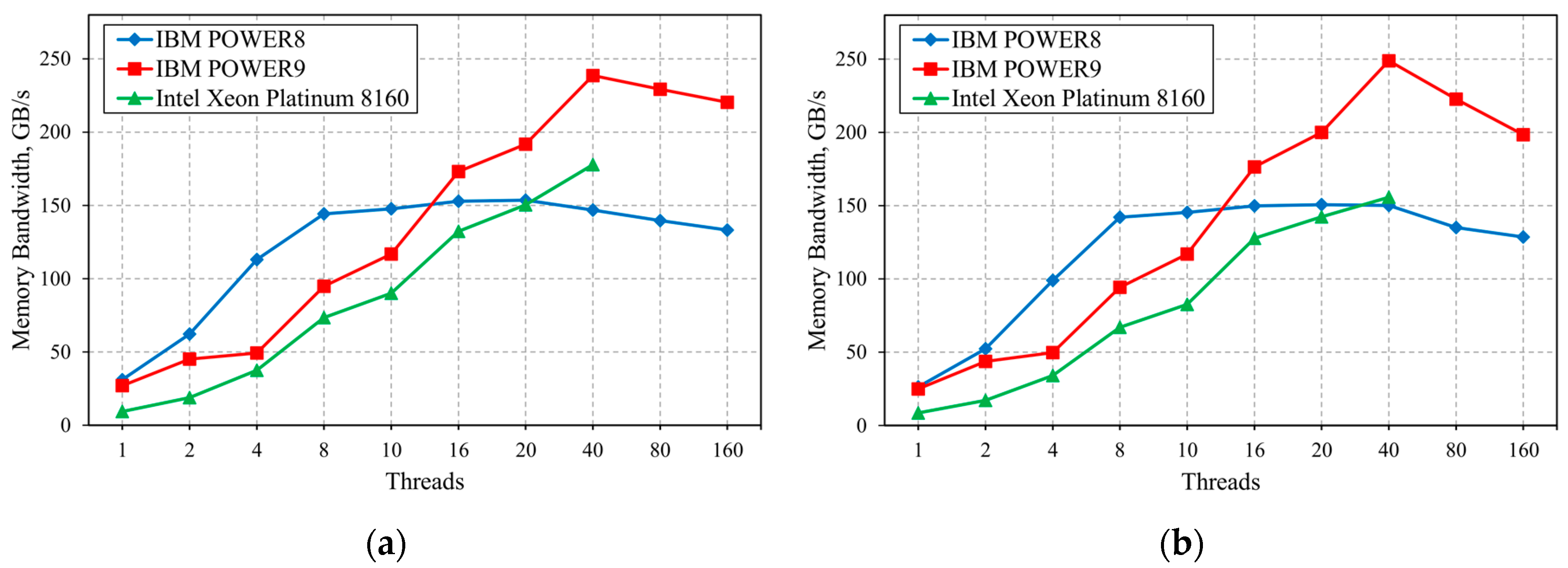
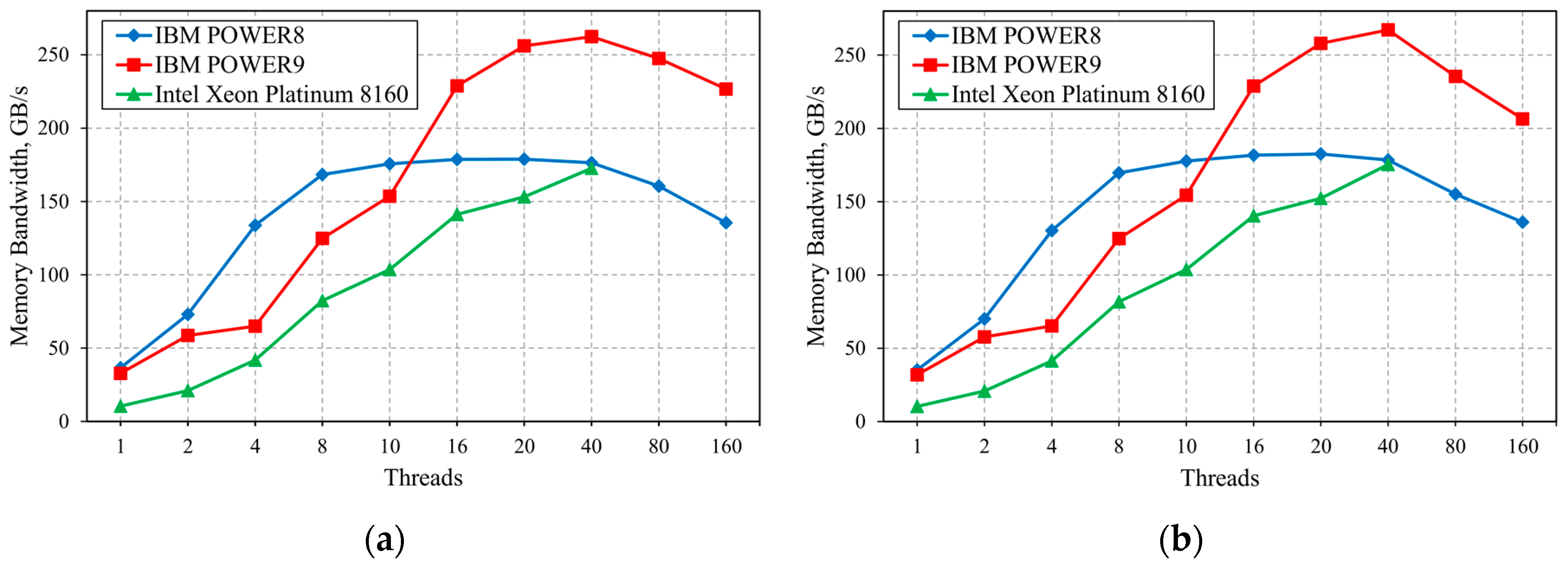
3.1. Memory Bandwidth Benchmark
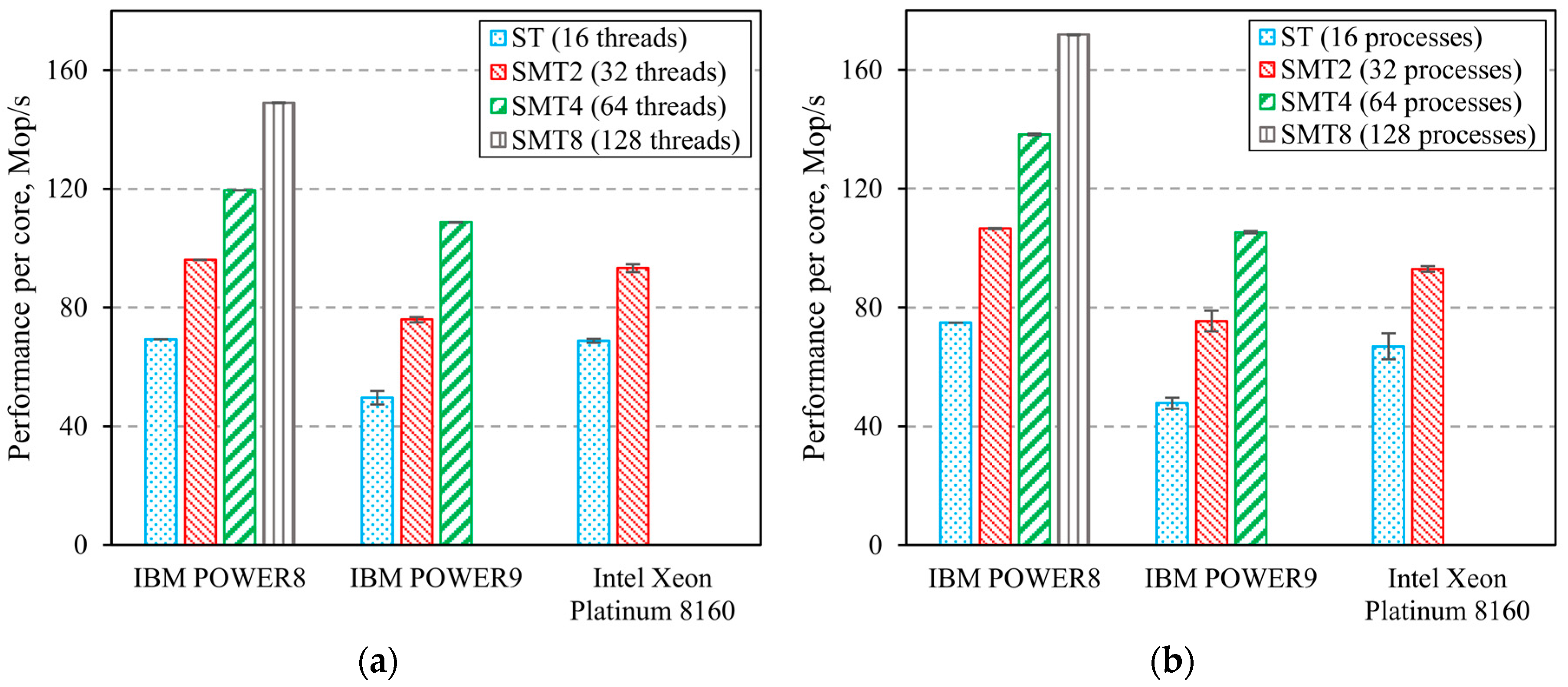
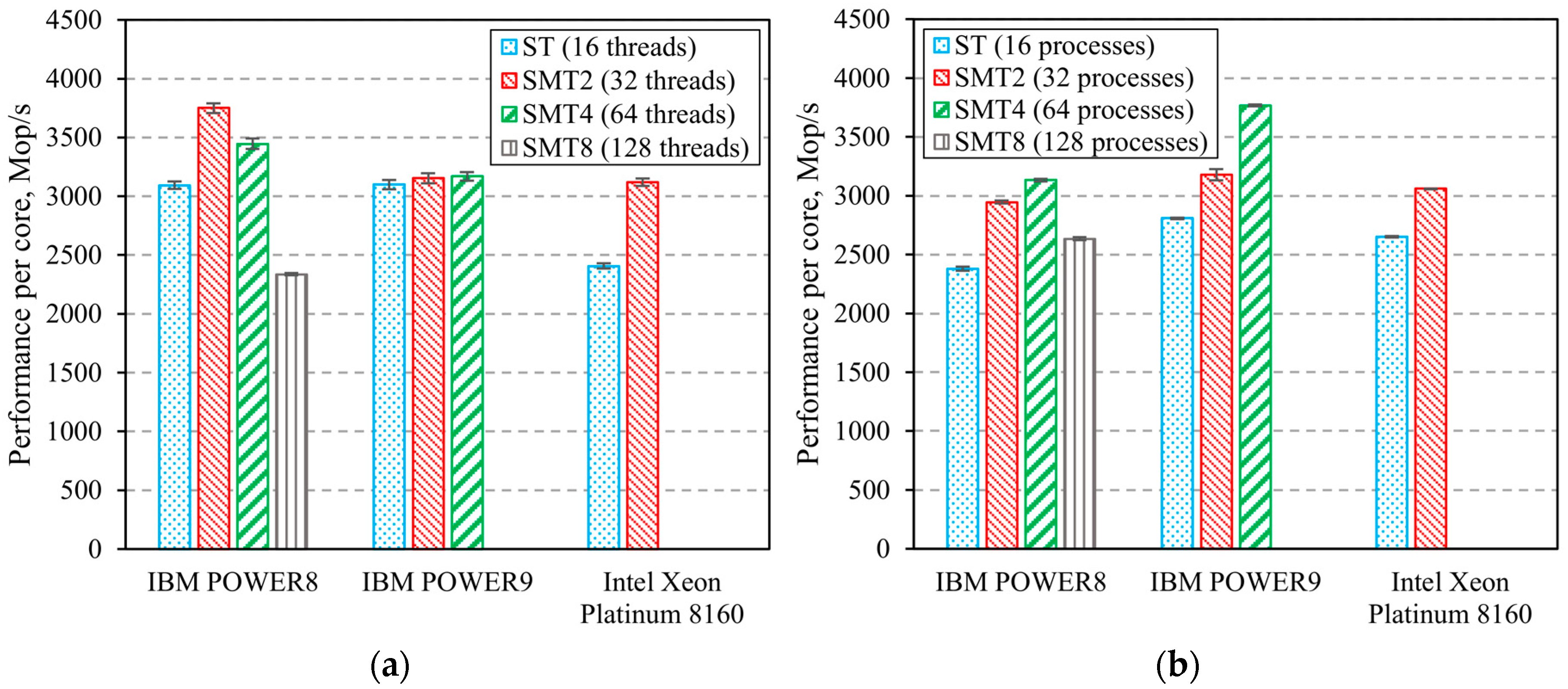
3.2. Computing Systems’ Parallel Benchmarks
4. Discussion
5. Conclusions
- Generally, all three of the considered CPUs and computer systems based on these CPUs can be deemed as balanced in terms of overall performance. However, CPU performance differences related to program code status should be noted, as well as differences related to utilization in multipurpose hybrid computing platforms.
- IBM processors are more efficient than Intel processors when executing a non-optimized code. This is due to their higher operating frequency, as well as the ability to start more threads per core, which improves the utilization of CPU execution units. On the other hand, systems based on Intel processors supporting vector instructions four times longer than IBM processors will have higher performance when executing similar operations in applications with optimized code (vectorized calculations; using optimized libraries, e.g., Intel MKL).
- The POWER architecture seems to be the more preferable solution as an optimal choice for creating multipurpose hybrid computing platforms aimed at utilizing the resources of both CPUs and GPUs. IBM-based systems have a high-speed NVLink GPU interconnection bus. In particular, this solves the problem of a low GPU data transfer rate. At the same time, their high per-core performance allows for the efficient use of CPU resources to run hybrid applications, the majority of which require only one computational process per GPU. Nevertheless, the issue of overall performance evaluation of the considered hybrid computing systems requires additional research.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Martel, E.; Lazcano, R.; López, J.; Madroñal, D.; Salvador, R.; López, S.; Juarez, E.; Guerra, R.; Sanz, C.; Sarmiento, R. Implementation of the Principal Component Analysis onto High-Performance Computer Facilities for Hyperspectral Dimensionality Reduction: Results and Comparisons. Remote Sens. 2018, 10, 864. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Narayana, V.K.; El-Ghazawi, T. Exploring Graphics Processing Unit (GPU) Resource Sharing Efficiency for High Performance Computing. Computers 2013, 2, 176–214. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudi, S.A.; Belarbi, M.A.; Dadi, E.W.; Mahmoudi, S.; Benjelloun, M. Cloud-Based Image Retrieval Using GPU Platforms. Computers 2019, 8, 48. [Google Scholar] [CrossRef] [Green Version]
- Mal’kovskii, S.I.; Sorokin, A.A.; Korolev, S.P.; Zatsarinnyi, A.A.; Tsoi, G.I. Performance Evaluation of a Hybrid Computer Cluster Built on IBM POWER8 Microprocessors. Program. Comput. Softw. 2019, 45, 324–332. [Google Scholar] [CrossRef]
- Eggers, S.J.; Emer, J.S.; Levy, H.M.; Lo, J.L.; Stamm, R.L.; Tullsen, D.M. Simultaneous Multithreading: A Platform for Next-generation Processors. IEEE Micro 1997, 17, 12–19. [Google Scholar] [CrossRef] [Green Version]
- Sinharoy, B.; Van Norstrand, J.A.; Eickemeyer, R.J.; Le, H.Q.; Leenstra, J.; Nguyen, D.Q.; Konigsburg, B.; Ward, K.; Brown, M.D.; Moreira, J.E.; et al. IBM POWER8 Processor Core Microarchitecture. IBM J. Res. Dev. 2015, 59, 2:1–2:21. [Google Scholar] [CrossRef]
- Starke, W.J.; Stuecheli, J.; Daly, D.M.; Dodson, J.S.; Auernhammer, F.; Sagmeister, P.M.; Guthrie, G.L.; Marino, C.F.; Siegel, M.; Blaner, B. The Cache and Memory Subsystems of the IBM POWER8 Processor. IBM J. Res. Dev. 2015, 59, 1–13. [Google Scholar] [CrossRef]
- Sadasivam, S.K.; Thompto, B.W.; Kalla, R.; Starke, W.J. IBM Power9 Processor Architecture. IEEE Micro 2017, 37, 40–51. [Google Scholar] [CrossRef]
- Starke, W.J.; Dodson, J.S.; Stuecheli, J.; Retter, E.; Michael, B.W.; Powell, S.J.; Marcella, J.A. IBM POWER9 memory architectures for optimized systems. IBM J. Res. Dev. 2018, 62, 1–13. [Google Scholar] [CrossRef]
- Intel Xeon Processor Scalable Family Technical Overview. Available online: https://software.intel.com/content/www/us/en/develop/articles/intel-xeon-processor-scalable-family-technical-overview.html (accessed on 7 May 2020).
- Gorobets, A.V.; Neiman-Zade, M.I.; Okunev, S.K.; Kalyakin, A.A.; Soukov, S.A. Performance of Elbrus-8C Processor in Supercomputer CFD Simulations. Math. Models Comput. Simul. 2019, 11, 914–923. [Google Scholar] [CrossRef]
- Malkovsky, S.I.; Peresvetov, V.V. Performance Evaluation of the Computing Cluster on Quad-core Processors. In Proceedings of the Interregional Scientific-practical Conference Information and Communication Technologies in Education and Scientific Activity, Khabarovsk, Russia, 21–23 September 2009; pp. 261–268. [Google Scholar]
- McCalpin, J.D. Memory Bandwidth and Machine Balance in Current High Performance Computers. IEEE Comput. Soc. Tech. Committee Comput. Archit. (TCCA) Newsl. 1995, 59, 19–25. [Google Scholar]
- Bailey, D.; Barszcz, E.; Barton, J.; Browning, D.; Carter, R.; Dagum, L.; Fatoohi, R.; Fineberg, S.; Frederickson, P.; Lasinski, T.; et al. The NAS Parallel Benchmarks. RNR Technical Report RNR 94-007. March 1994. Available online: https://www.davidhbailey.com/dhbpapers/npb.pdf (accessed on 7 May 2020).
- Kumar, S.; Mamidala, A.R.; Faraj, D.A.; Smith, B.; Blocksome, M.; Cernohous, B.; Miller, D.; Parker, J.; Ratterman, J.; Heidelberger, P.; et al. PAMI: A Parallel Active Message Interface for the Blue Gene/Q Supercomputer. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium, Shanghai, China, 21–25 May 2012; pp. 763–773. [Google Scholar]
- Supalov, A.; Semin, A.; Dahnken, C.; Klemm, M. Optimizing HPC Applications with Intel Cluster Tools; Apress: New York City, NY, USA, 2014; p. 291. [Google Scholar]
- Takouna, I.; Dawoud, W.; Meinel, C. Analysis and Simulation of HPC Applications in Virtualized Data Centers. In Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besancon, France, 20–23 November 2012; pp. 498–507. [Google Scholar]
- Ibrahim, K.; Williams, S.; Oliker, L. Roofline Scaling Trajectories: A Method for Parallel Application and Architectural Performance Analysis. In Proceedings of the 2018 International Conference on High Performance Computing & Simulation, Orléans, France, 16–20 July 2018; pp. 350–358. [Google Scholar]
- Sorokin, A.A.; Makogonov, S.V.; Korolev, S.P. The Information Infrastructure for Collective Scientific Work in the Far East of Russia. Sci. Tech. Inf. Process. 2017, 4, 302–304. [Google Scholar] [CrossRef]
- Informatics Core Facility Statute. Available online: http://www.frccsc.ru/ckp (accessed on 22 January 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | IBM POWER8 | IBM POWER9 | Intel Xeon Platinum 8160 |
|---|---|---|---|
| Lithography | 22 nm | 14 nm | 14 nm |
| Operating frequency | 4.023 GHz | 3.5 GHz | 2.1 GHz |
| Cores | 10 | 20 | 24 |
| Command set extensions | VMX, VSX-2 | VMX, VSX-3 | SSE4.2, AVX, AVX2, AVX-512 |
| Hardware threads | 80 (SMT8) | 80 (SMT4) | 48 (SMT2) |
| Peak performance (double-precision) | 0.32 TFLOPS (0.032 TFLOPS per core) | 0.56 TFLOPS (0.028 TFLOPS per core) | 1.54 TFLOPS (0.064 TFLOPS per core) |
| L1I/L1D Cache (per core) capacity/associativity | 32/64 KB, 8-way | 32/32 KB, 8-way | 32/32 KB, 8-way |
| L2 cache (per core) capacity/associativity | 512 KB, 8-way | 256 KB, 8-way | 1024 KB, 16-way |
| L3 cache (per chip) capacity/associativity | 80 MB, 8-way | 100 MB, 20-way | 33 MB, 11-way |
| L4 Cache (per chip) capacity/associativity | 120 MB, 16-way (Centaur) | - | - |
| Memory channels | 4 | 8 | 6 |
| Memory type | DDR4-2400 | DDR4-2666 | DDR4-2666 |
| GPU bus | NVLink 1.0 | NVLink 2.0 | PCIe 3.0 |
| Software Type | IBM POWER8 System | IBM POWER9 System | Intel Xeon Platinum 8160 System |
|---|---|---|---|
| Operating System | CentOS 7.6 | RedHat 7.6 | CentOS 7.6 |
| Compiler | IBM XL C/C++, Fortran 16.1.1 | IBM XL C/C++, Fortran 16.1.1 | Intel C/C++, Fortran 19.0.5 |
| MPI Library | IBM Spectrum MPI 10.3 | IBM Spectrum MPI 10.3 | Intel MPI Library 2019 Update 5 |
| Tested Metrics | Benchmark Name | Software Version |
|---|---|---|
| Memory bandwidth benchmark | STREAM [13] | 5.10 |
| Benchmark for computing systems running parallel applications | NAS Parallel Benchmarks (NPB) [14] | 3.4 |
| Name | Operation | Byte per Iteration | FLOPS per Iteration |
|---|---|---|---|
| Copy | a(i) = b(i) | 16 | 0 |
| Scale | a(i) = q × b(i) | 16 | 1 |
| Add | a(i) = b(i) + c(i) | 24 | 1 |
| Triad | a(i) = b(i) + q × c(i) | 24 | 2 |
| Description/Processor | IBM POWER8 | IBM POWER9 | Intel Xeon Platinum 8160 |
|---|---|---|---|
| Memory channels | 4 | 8 | 6 |
| Bandwidth per channel (GB/s) | 28.8 | 21.25 | 21.33 |
| Total bandwidth (GB/s) | 115.2 | 170 | 128 |
| Benchmark | IBM POWER8 System | IBM POWER9 System | Intel Xeon Platinum 8160 System |
|---|---|---|---|
| STREAM (C) | -O0 -qsmp=omp -fno-builtin -qtune=pwr8 -mcpu=pwr8 -qarch=pwr8 | -O0 -qsmp=omp -fno-builtin -qtune=pwr9 -mcpu=pwr9 -qarch=pwr9 | -O3 -qopenmp -qopt-zmm-usage=high -mcmodel=medium |
| NPB (C) | -O3 -qsmp=omp -qarch=pwr8 -mcpu=pwr8 -qtune=pwr8 -qunroll=yes -qhot | -O3 -qsmp=omp -qarch=pwr9 -mcpu=pwr9 -qtune=pwr9 -qunroll=yes -qhot | -O3 -qopenmp -mcmodel=medium -shared-intel |
| NPB (FORTRAN) | -O3 -qsmp=omp -qarch=pwr8 -qtune=pwr8 -qunroll=yes -qhot -qnosave | -O3 -qsmp=omp -qarch=pwr9 -qtune=pwr9 -qunroll=yes -qhot -qnosave | -O3 -qopenmp |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sorokin, A.; Malkovsky, S.; Tsoy, G.; Zatsarinnyy, A.; Volovich, K. Comparative Performance Evaluation of Modern Heterogeneous High-Performance Computing Systems CPUs. Electronics 2020, 9, 1035. https://doi.org/10.3390/electronics9061035
Sorokin A, Malkovsky S, Tsoy G, Zatsarinnyy A, Volovich K. Comparative Performance Evaluation of Modern Heterogeneous High-Performance Computing Systems CPUs. Electronics. 2020; 9(6):1035. https://doi.org/10.3390/electronics9061035
Chicago/Turabian StyleSorokin, Aleksei, Sergey Malkovsky, Georgiy Tsoy, Alexander Zatsarinnyy, and Konstantin Volovich. 2020. "Comparative Performance Evaluation of Modern Heterogeneous High-Performance Computing Systems CPUs" Electronics 9, no. 6: 1035. https://doi.org/10.3390/electronics9061035