One Shot Crowd Counting with Deep Scale Adaptive Neural Network

Abstract
:1. Introduction
2. Related Work
2.1. Related Algorithm for Crowd Density Estimation
2.2. The Open Dataset
3. The Proposed Method
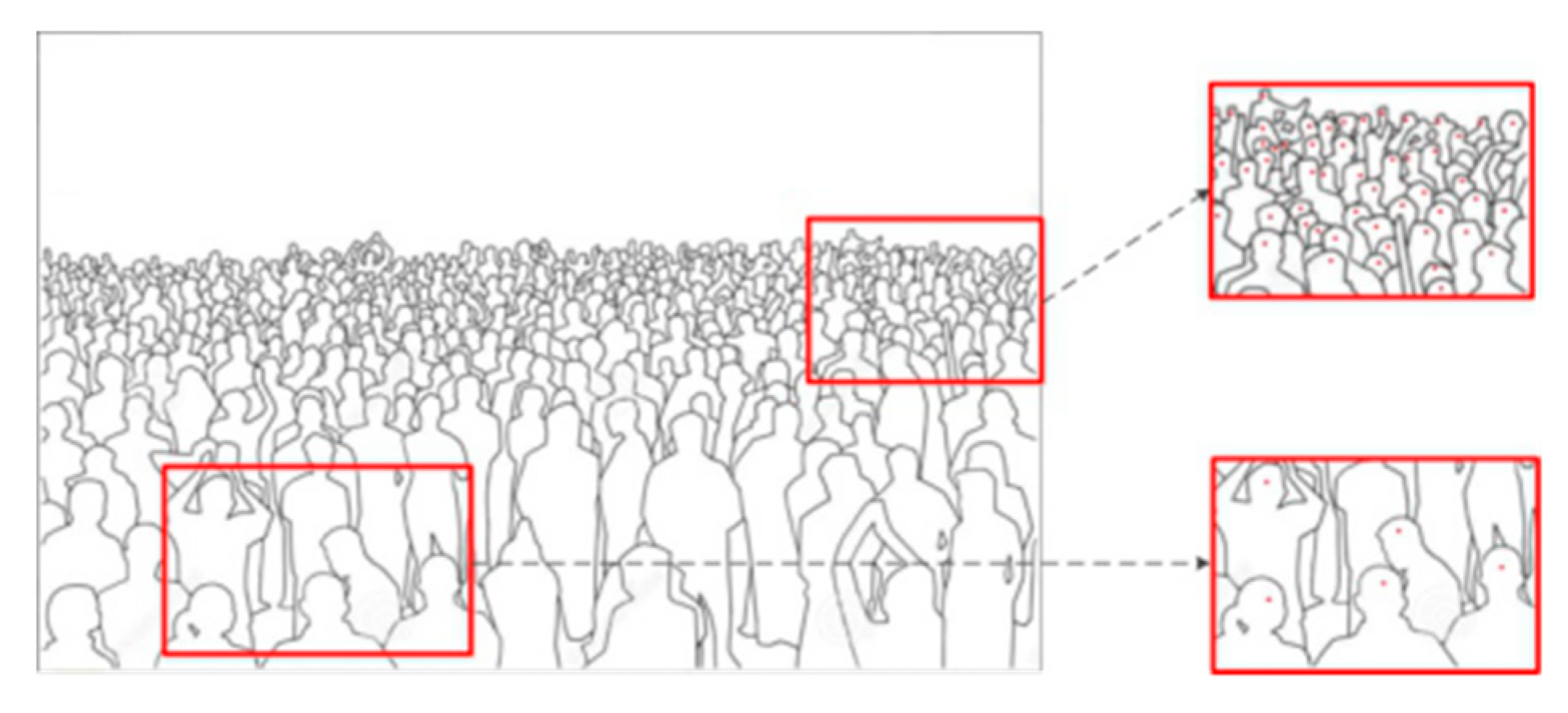
3.1. Converting to Maps of Crowd Density
3.2. The Processing of Camera Perspective
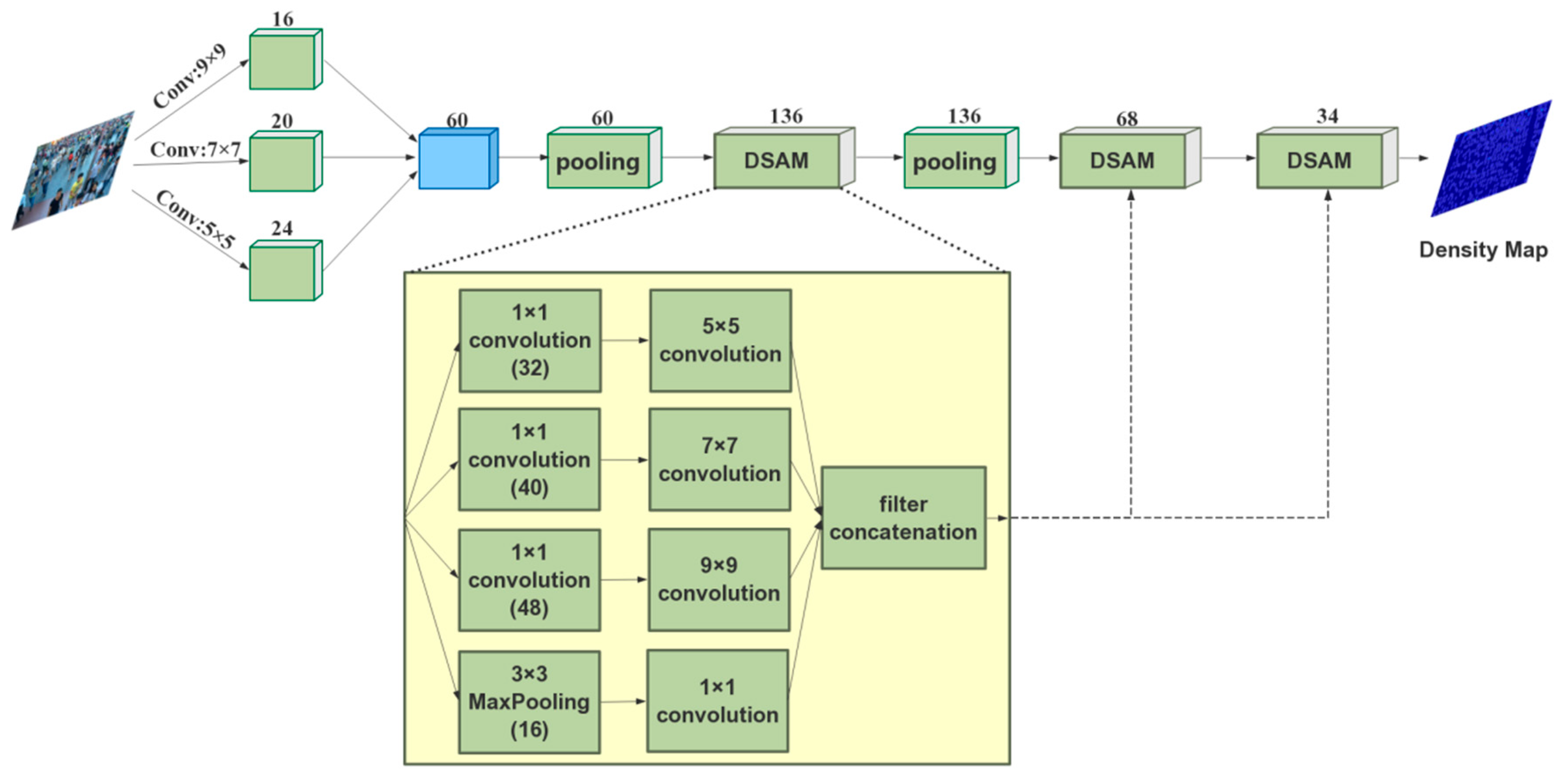
3.3. Deep Scale-Adaptive Module for Density Map
| Algorithm 1: The calculation of density map for crowd image |
| Input:I:test dataset |
| Output: density map |
| 1: function GenerateDensity(I) |
| 2: num←the number of image in I |
| 3: for i ∈ [0,num] do |
| 4: column1 = conv(image[i],5 × 5) |
| 5: column2 = conv(image[i],7 × 7) |
| 6: column3 = conv(image[i],9 × 9) |
| 7: merge1 = Merge(a,b,c) |
| 8: pooling1 = MaxPooling(merge1) |
| 9: merge2 = DSAM(pooling1) |
| 10: pooling2 = Merge(merge2) |
| 11: merge3 = DSAM(pooling2) |
| 12: merge4 = DSAM(merge3) |
| 13: return(Generate(merge4)) |
| 14: end for |
| 15: end function |
| 16: |
| 17: function DSAM(im) |
| 18: column_11 = conv(im,1 × 1) |
| 19: column_11 = conv(colmun_11,5 × 5) |
| 20: column_12 = conv(im,1 × 1) |
| 21: column_12 = conv(column_12,7 × 7) |
| 22: column_13 = conv(im,1 × 1) |
| 22: column_13 = conv(column_13,9 × 9) |
| 23: column_14 = MaxPooling(im) |
| 24: column_14 = conv(column_14,1 × 1) |
| 25: return Merge(column_11,column_12,column_13,column_14) |
| 26: end function |
4. Some Configuration of Our Model
5. Experiments
5.1. Evaluation Metrics
5.2. A Brief Introduction to Comparison Algorithms
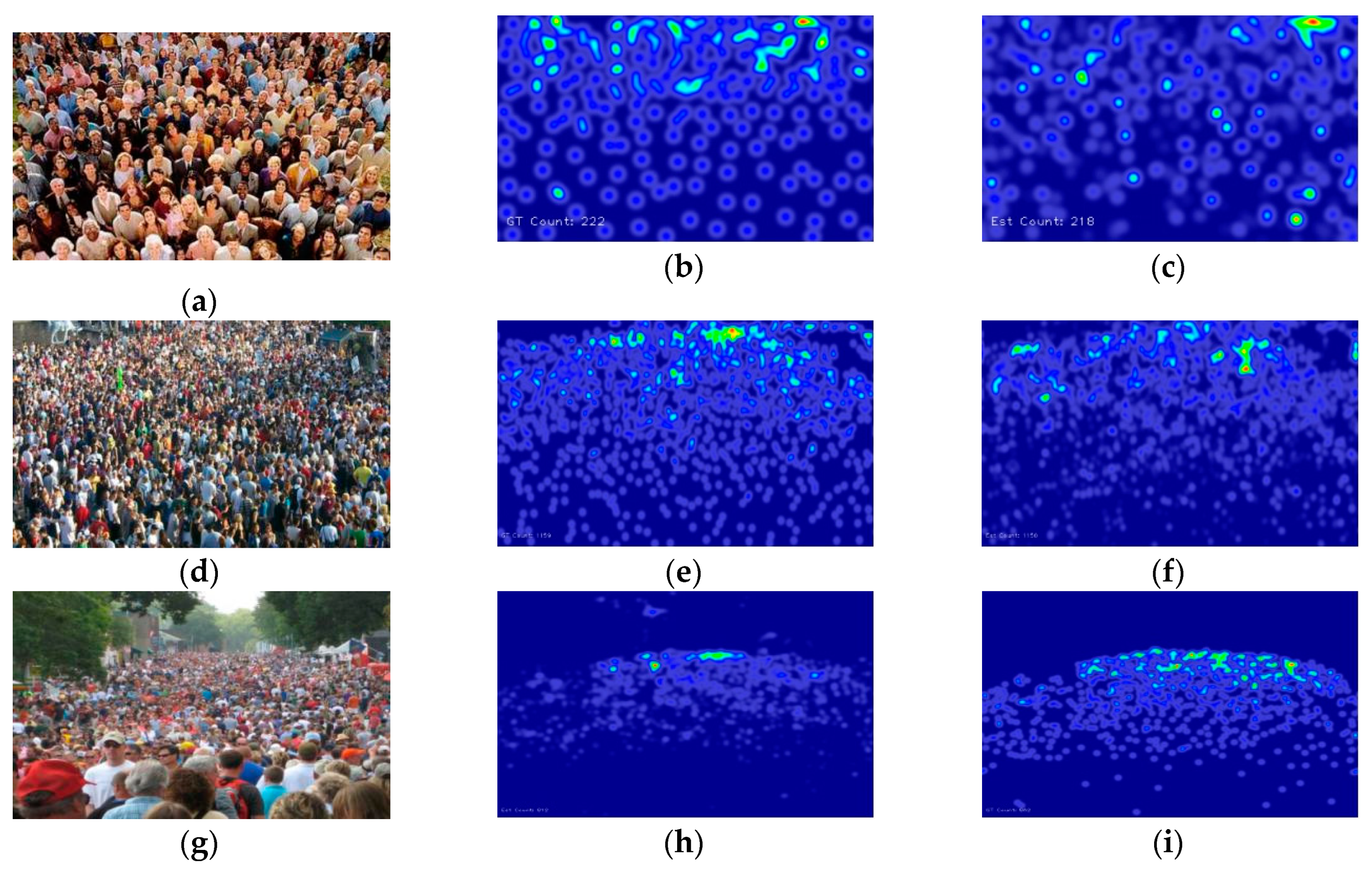
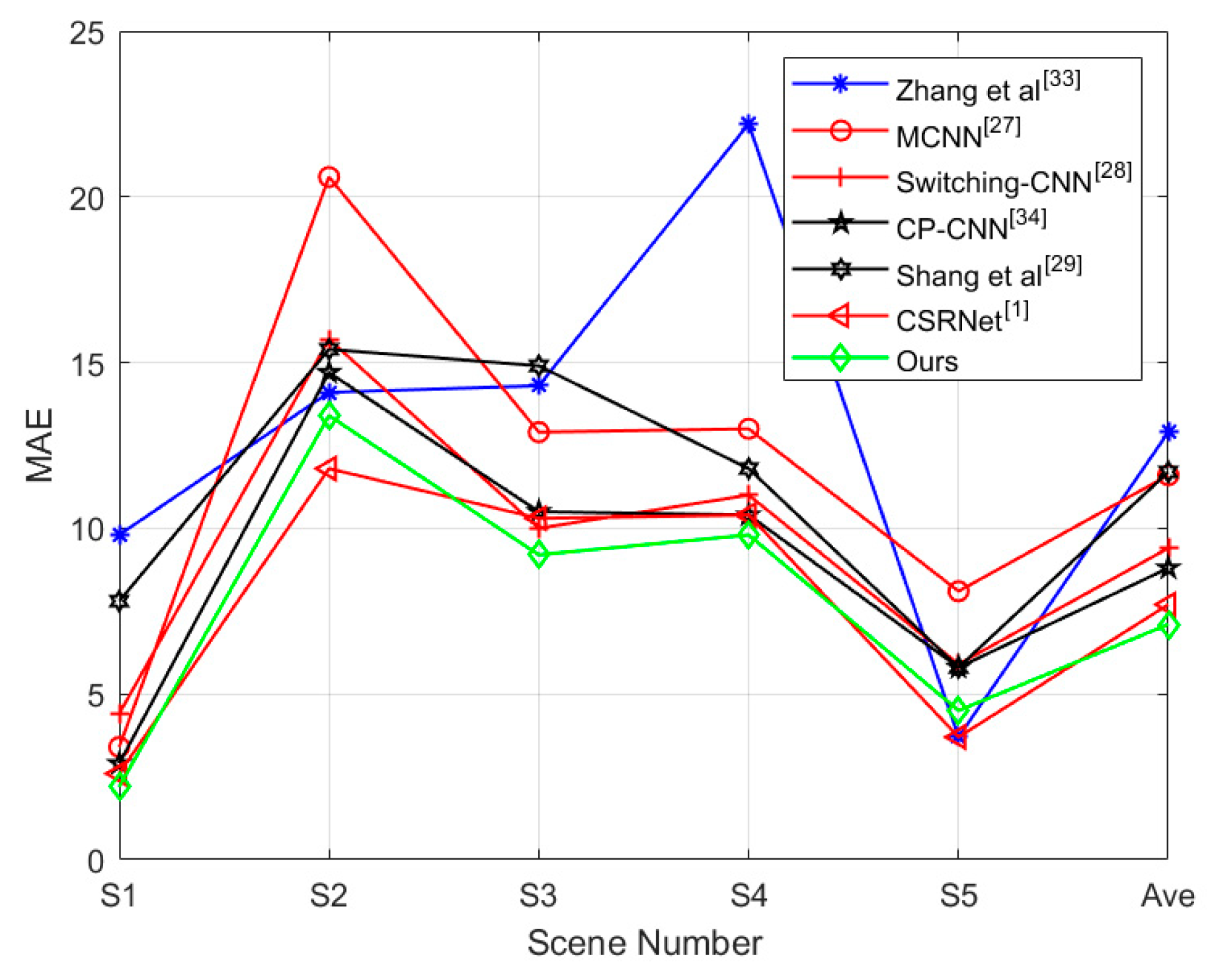
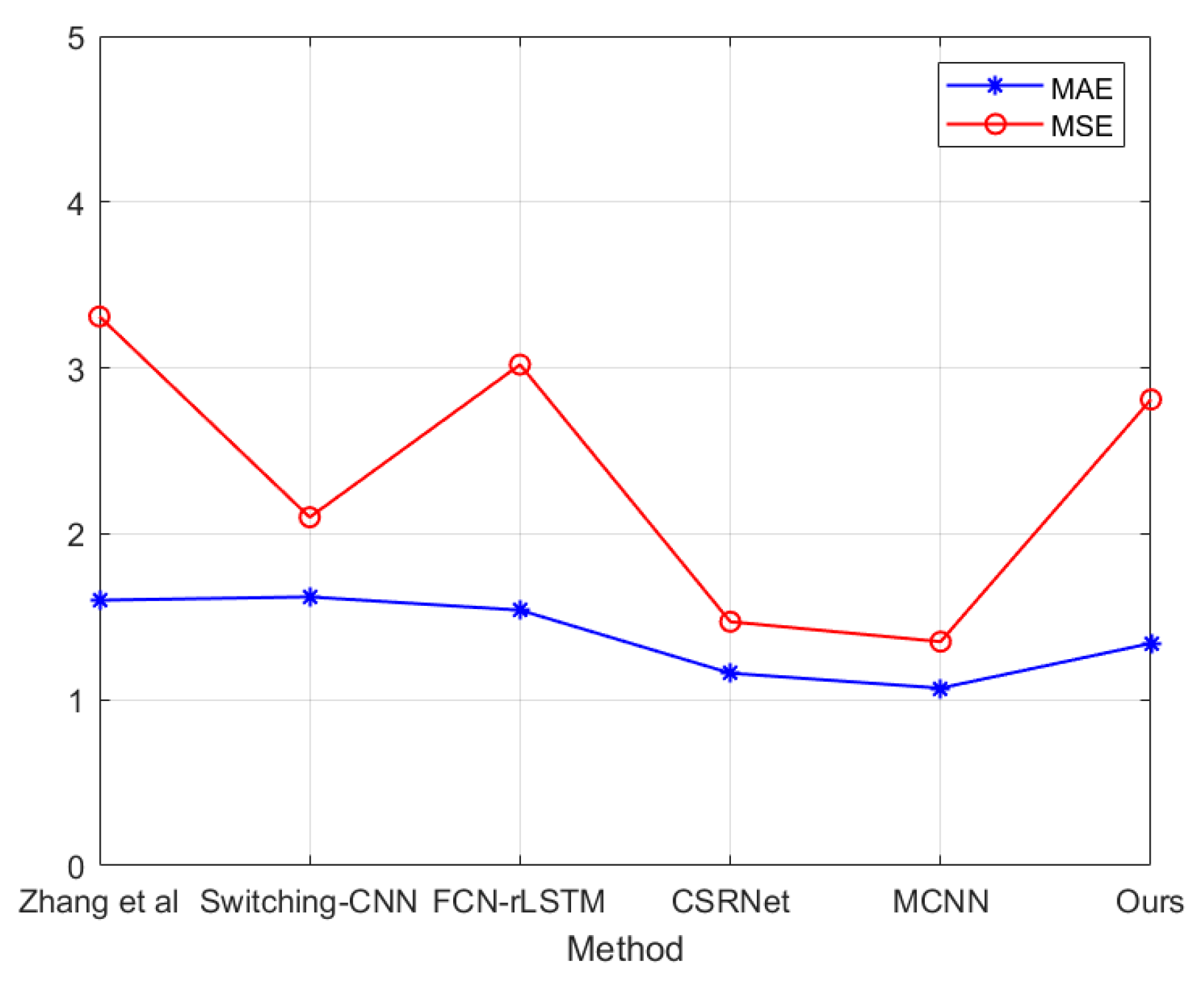
5.3. Evaluation and Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Revisiting Perspective Information for Efficient Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Sam, D.B.; Sajjan, N.N.; Maurya, H.; Babu, R.V. Almost Unsupervised Learning for Dense Crowd Counting. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Shang, C.; Haizhou, A.I.; Yang, Y. Crowd counting via learning perspective for multi-scale multi-view Web images. Front. Comput. Sci. 2019, 13, 579–587. [Google Scholar] [CrossRef]
- Shi, Z.; Le, Z.; Sun, Y.; Ye, Y. Multiscale Multitask Deep NetVLAD for Crowd Counting. IEEE Trans. Ind. Inform. 2018, 14, 4953–4962. [Google Scholar] [CrossRef]
- Maddah, H.; Ghazvini, M.; Ahmadi, M.H. Predicting the efficiency of CuO/water nanofluid in heat pipe heat exchanger using neural network. Int. Commun. Heat Mass Transf. 2019, 104, 33–40. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Leibe, B.; Seemann, E.; Schiele, B. Pedestrian detection in crowded scenes. IEEE Conf. Comput. Vision Pattern Recognit. 2005, 1, 878–885. [Google Scholar]
- Enzweiler, M.; Gavrila, D.M. Monocular Pedestrian Detection: Survey and Experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179. [Google Scholar] [CrossRef] [PubMed]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian Detection via Classification on Riemannian Manifolds. IEEE Trans Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Zha, H. Riemannian Manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar]
- Viola, P.; Jones, M. Robust Real-time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Wu, B.; Nevatia, R. Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005. [Google Scholar]
- Wu, B.; Nevatia, R. Detection and Tracking of Multiple, Partially Occluded Humans by Bayesian Combination of Edgelet based Part Detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Lin, S.F.; Chen, J.Y.; Chao, H.X. Estimation of number of people in crowded scenes using perspective transformation. IEEE Trans. Syst. Man Cybern. 2001, 31, 645–654. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D. Cascade object detection with deformable part models. Commun. ACM 2010, 56, 2241–2248. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Ryan, D.; Denman, S.; Fookes, C.; Sridharan, S. Crowd Counting Using Multiple Local Features. In Proceedings of the IEEE Digital Image Computing: Techniques and Applications, Melbourne, Australia, 1–3 December 2009. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature Mining for Localised Crowd Counting. In Proceedings of the British Machine Vision Conference, Guildford, UK, 3–7 September 2012. [Google Scholar]
- Paragios, N.; Ramesh, V. A MRF-based Approach for Real-Time Subway Monitoring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Ma, Z.; Chan, A.B. Crossing the Line: Crowd Counting by Integer Programming with Local Features. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Ryan, D.; Denman, S.; Sridharan, S. An evaluation of crowd counting methods, features and regression models. Comput. Vis. Image Underst. 2014, 130, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Lempitsky, V.; Zisserman, A. Learning to Count Objects in Images. Adv. Neural Inf. Process. Syst. 2010, 1324–1332. [Google Scholar]
- Wang, C.; Zhang, H.; Yang, L. Deep People Counting in Extremely Dense Crowds. In Proceedings of the ACM International Conference on Multimedia, Shanghai, China, 23–26 June 2015; pp. 1299–1302. [Google Scholar]
- Fu, M.; Xu, P.; Li, X. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 81–88. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 June 2016; pp. 589–597. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar]
- Shang, C.; Ai, H.; Bai, B. End-to-end crowd counting via joint learning local and global count. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 1215–1219. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-Source Multi-Scale Counting in Extremely Dense Crowd Images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Loy, C.C.; Gong, S.; Xiang, T. From Semi-supervised to Transfer Counting of Crowds. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Chan, A.B.; Liang, Z.S.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high quality crowd density maps using contextual pyramid CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1861–1870. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian Detection with Unsupervised Multi-stage Feature Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhong, Z.; Yin, W.; Venetianer, P.L. Fast Crowd Density Estimation in Surveillance Videos without Training. In Proceedings of the IEEE Ninth International Conference on Advanced Video & Signal-based Surveillance, Beijing, China, 18–21 September 2012. [Google Scholar]
- Peng, S.; Fang, Z.; Gao, Y. Crowd Counting Based on Feature Fusion of Multi-Scale Fully Convolutional Networks. J. Wuhan Univ. (Sci. Ed.) 2018, 64, 249–254. [Google Scholar]
- Ahmadi, M.H.; Mohseni-Gharyehsafa, B.; Farzaneh-Gord, M.; Ravindra, D.; Jilte, R.K.; Chau, K.W. Applicability of connectionist methods to predict dynamic viscosity of silver/water nanofluid by using ANN-MLP, MARS and MPR algorithms. Eng. Appl. Comput. Fluid Mech. 2019, 13, 220–228. [Google Scholar] [CrossRef]
- Kopsiaftis, G.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Mantoglou, A. Gaussian Process Regression Tuned by Bayesian Optimization for Seawater Intrusion Prediction. Comput. Intell. Neurosci. 2019, 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. IEEE Adv. Video Signal Based Surveill. 2017, 1–6. [Google Scholar]
- Marsden, M.; McGuiness, K.; Little, S.; O’Connor, N.E. Fully convolutional crowd counting on highly congested scenes. In Proceedings of the International Conference on Computer Vision Theory and Applications, Berlin, Germany, 11–14 March 2016. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration of DSA-CNN | |||||
|---|---|---|---|---|---|
| Input (color image) | |||||
| Conv3-16 5 × 5 | Conv3-20 7 × 7 | Conv3-24 9 × 9 | |||
| Merged layer (60) | |||||
| MaxPooling (60) | |||||
| Conv3-32 | Conv3-40 | Conv3-48 | MaxPooling | ||
| 1 × 1 | 1 × 1 | 1 × 1 | 3 × 3 | ||
| Conv3-32 | Conv3-40 | Conv3-48 | Conv3-16 | ||
| 3 × 3 | 5 × 5 | 7 × 7 | 1 × 1 | ||
| Merged layer (136) | |||||
| MaxPooling (136) | |||||
| Conv3-16 | Conv3-20 | Conv3-24 | MaxPooling | ||
| 1 × 1 | 1 × 1 | 1 × 1 | 3 × 3 | ||
| Conv3-16 | Conv3-20 | Conv3-24 | Conv3-8 | ||
| 3 × 3 | 5 × 5 | 7 × 7 | 1 × 1 | ||
| Merged layer (68) | |||||
| Conv3-8 | Conv3-10 | Conv3-12 | MaxPooling | ||
| 1 × 1 | 1 × 1 | 1 × 1 | 3 × 3 | ||
| Conv3-8 | Conv3-10 | Conv3-12 | Conv3-4 | ||
| 3 × 3 | 5 × 5 | 7 × 7 | 1 × 1 | ||
| Merged layer (34) | |||||
| Conv3 1 × 1 | |||||
| Method | Part_A | Part_B | ||
|---|---|---|---|---|
| MAE | MSE | MAE | MSE | |
| Zhang et al. [33] | 181.8 | 277.7 | 32.0 | 49.8 |
| MCNN [27] | 110.2 | 173.2 | 26.4 | 41.3 |
| Marsden et al. [41] | 126.5 | 173.5 | 23.8 | 33.1 |
| Cascaded-MTL [40] | 101.3 | 152.4 | 20.0 | 31.1 |
| Switching-CNN [28] | 90.4 | 135.0 | 21.6 | 33.4 |
| CP-CNN [34] | 73.6 | 106.4 | 20.1 | 30.1 |
| Ours | 68.4 | 103.5 | 22.3 | 27.4 |
| Method | Part_A | |
|---|---|---|
| PSNR | SSIM | |
| MCNN | 20.91 | 0.52 |
| CP-CNN | 21.72 | 0.72 |
| Ours | 21.95 | 0.83 |
| Method | UCF_CC_50 | |
|---|---|---|
| MAE | MSE | |
| Zhang et al. | 467.0 | 489.5 |
| MCNN | 377.6 | 509.1 |
| Marsden et al. | 338.6 | 424.5 |
| Cascaded-MTL | 322.8 | 397.9 |
| Switching-CNN | 318.1 | 439.2 |
| CP-CNN | 295.8 | 320.9 |
| Ours | 270.1 | 323.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Li, Z.; Qu, W.; Zhou, Y. One Shot Crowd Counting with Deep Scale Adaptive Neural Network. Electronics 2019, 8, 701. https://doi.org/10.3390/electronics8060701
Wu J, Li Z, Qu W, Zhou Y. One Shot Crowd Counting with Deep Scale Adaptive Neural Network. Electronics. 2019; 8(6):701. https://doi.org/10.3390/electronics8060701
Chicago/Turabian StyleWu, Junfeng, Zhiyang Li, Wenyu Qu, and Yizhi Zhou. 2019. "One Shot Crowd Counting with Deep Scale Adaptive Neural Network" Electronics 8, no. 6: 701. https://doi.org/10.3390/electronics8060701