Urban Crowd Detection Using SOM, DBSCAN and LBSN Data Entropy: A Twitter Experiment in New York and Madrid


Abstract
:1. Introduction
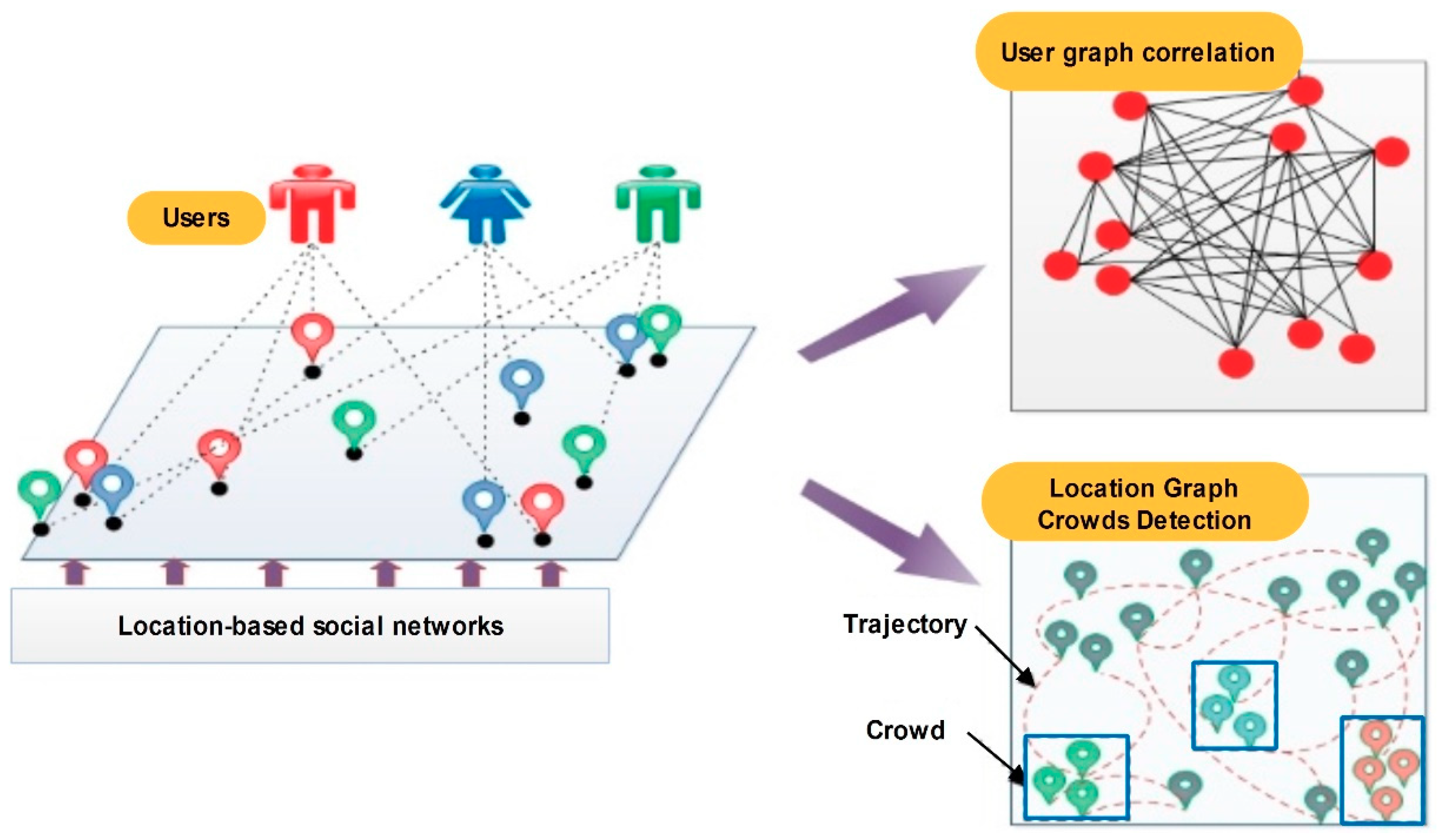
1.1. Concepts and Definitions of LBSNs
1.2. Background on Crowd Detection based LBSNs
2. Related Work
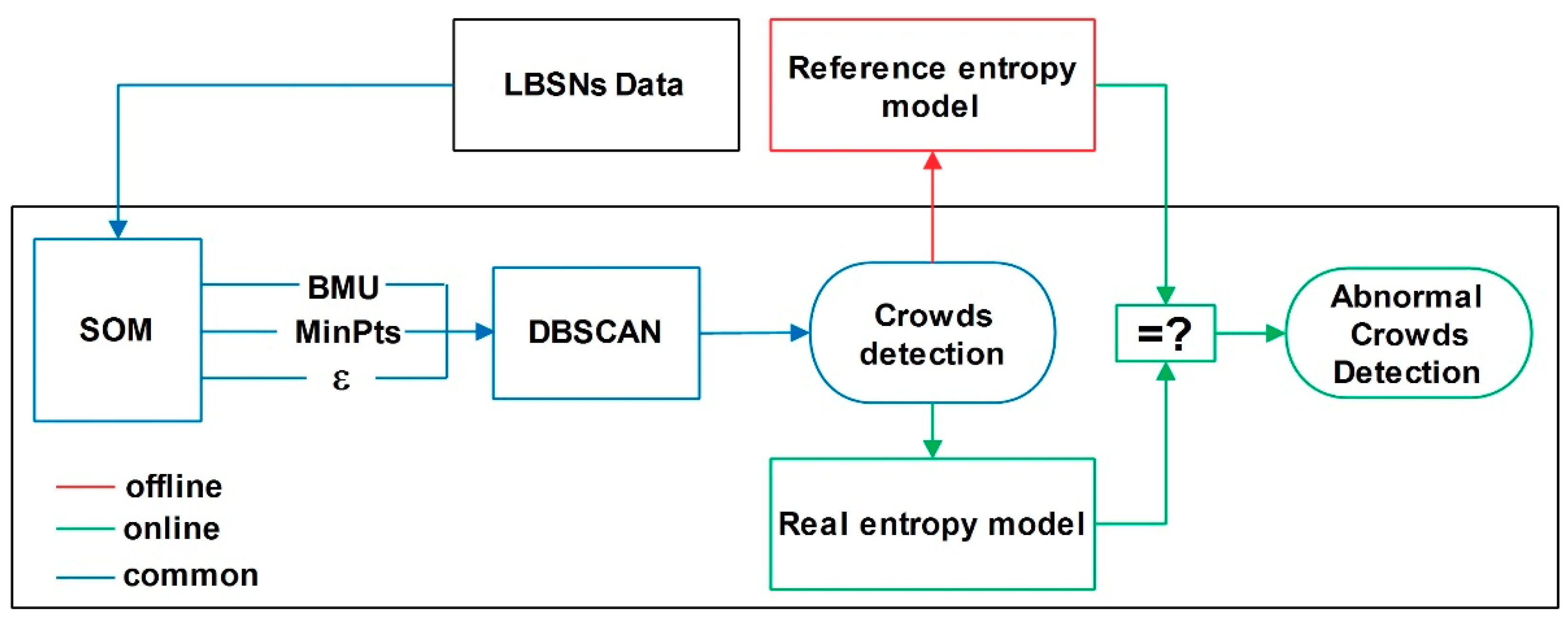
3. Methodology
3.1. SOM and DBSCAN
- Consider each BMU as a cluster centroid.
- Retrieve є-neighborhood for each BMU.
- Check that it contains MinPts points or more.
- Check if there is a , and , achievable by density from .
- Build and consider the central point between these two BMUs as the centroid of this new cluster.
- Initialization—Choose random values for the initial weight vectors (of the same type as the elements of the input space, a geographic coordinate (latitude and longitude)).
- Sampling—Draw a sample training input vector x(t) from the input space.
- Find the winning neuron c that has weight vector closest to the input vector, Equation (1).
- Apply the weight update equation, Equation (2).
- Keep returning to step 2 until the feature map stops changing.
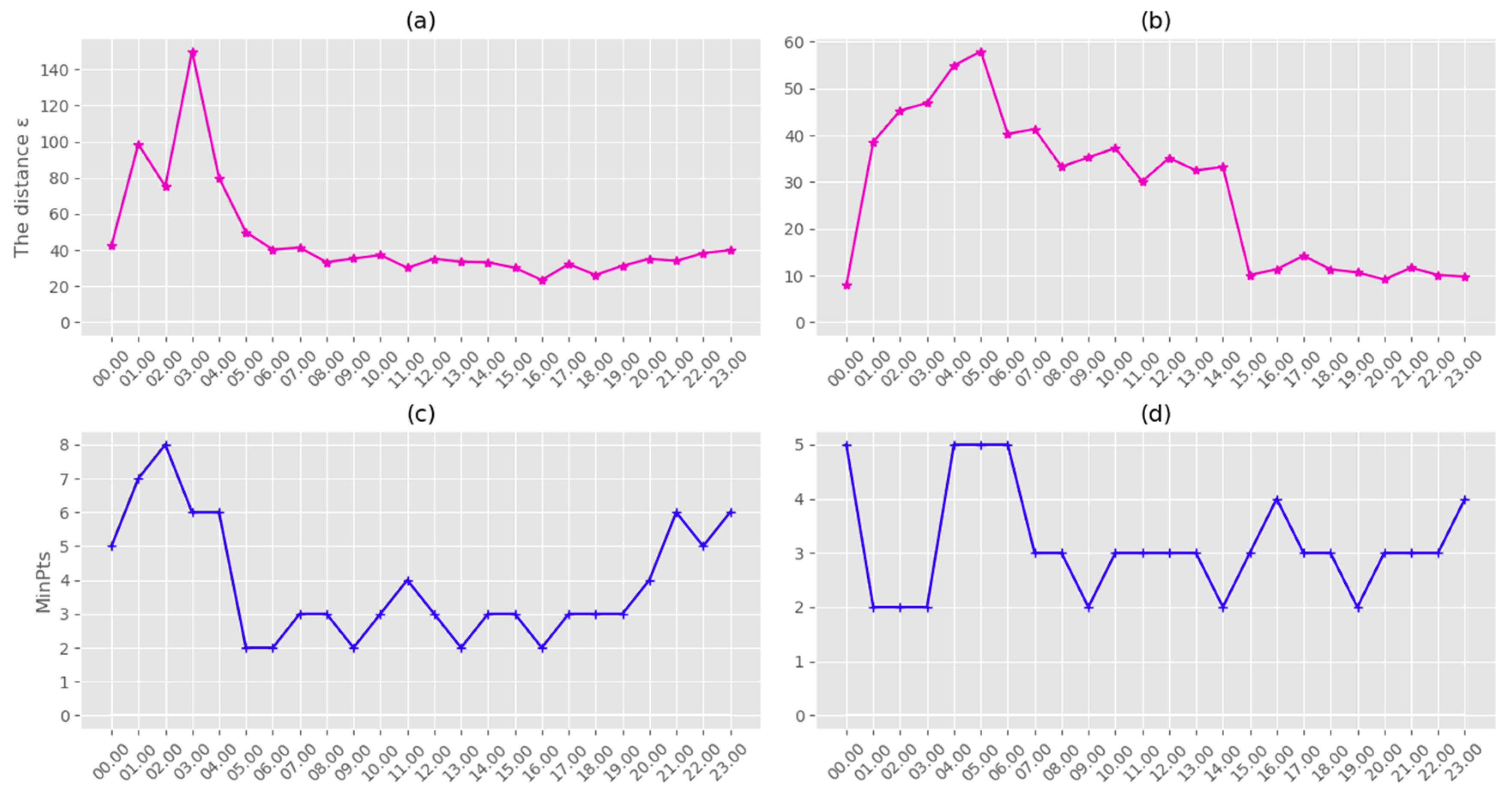
- Choose the parameters є and MinPts (Section 3.1).
- Establish DBSCAN (Section 3.1).
- Build the reference entropy model (Section 3.2).
- Build the real entropy model (Section 3.2).
- Compare the two models.
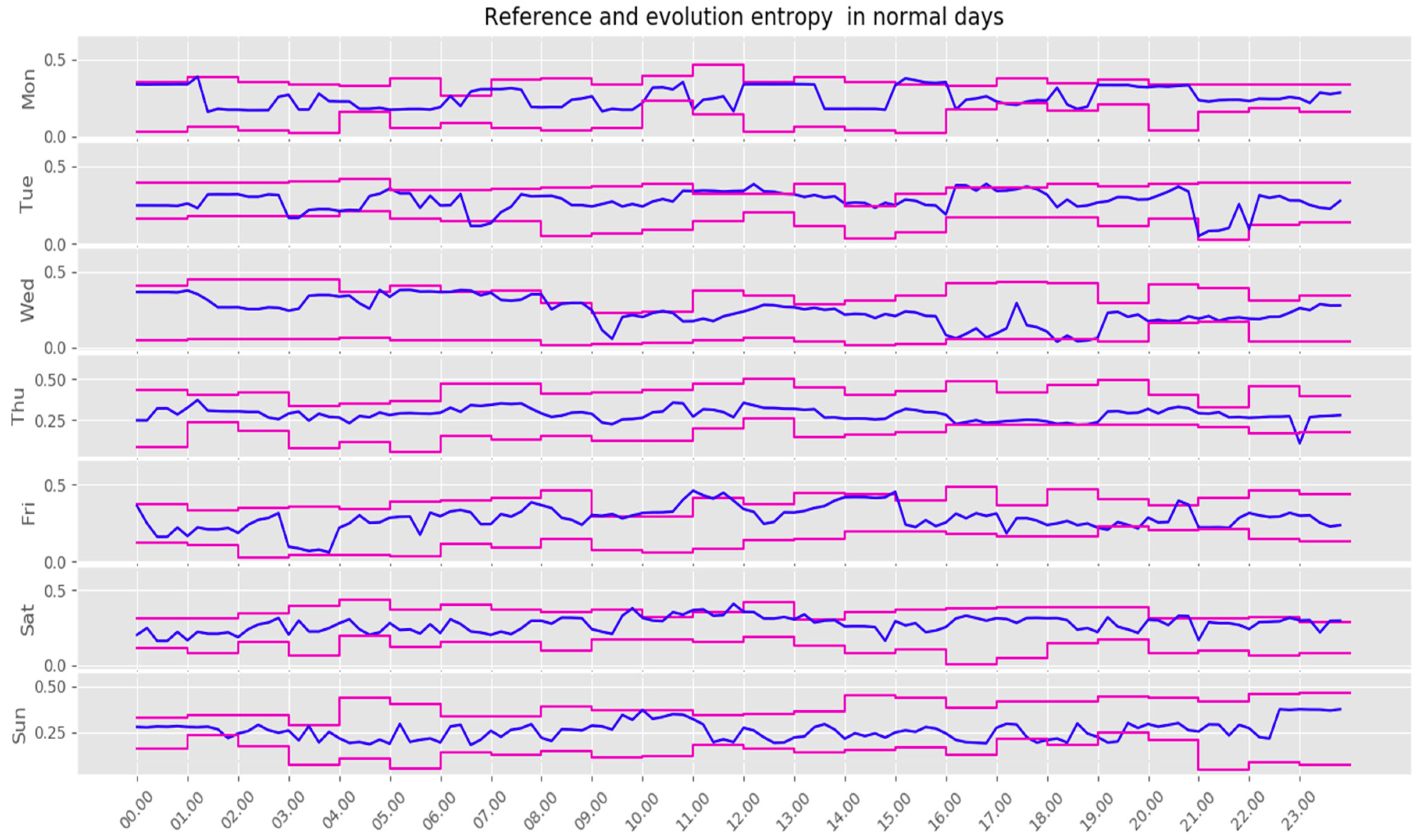
3.2. Real and Reference Entropy Models
3.3. Capturing Tweets
4. Experiments
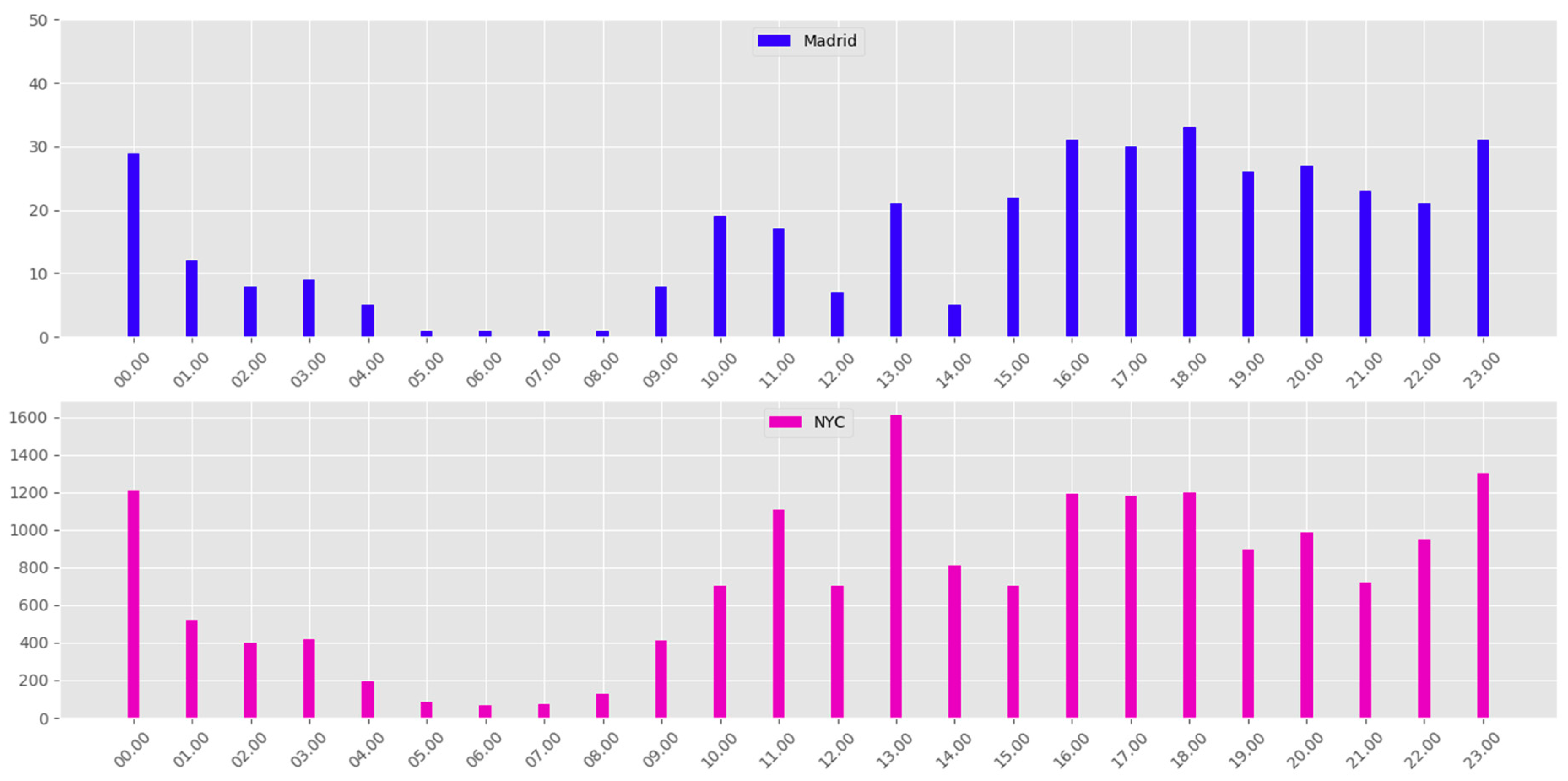
4.1. Data Sets
4.2. Reference Area
4.3. Results
5. Discussion
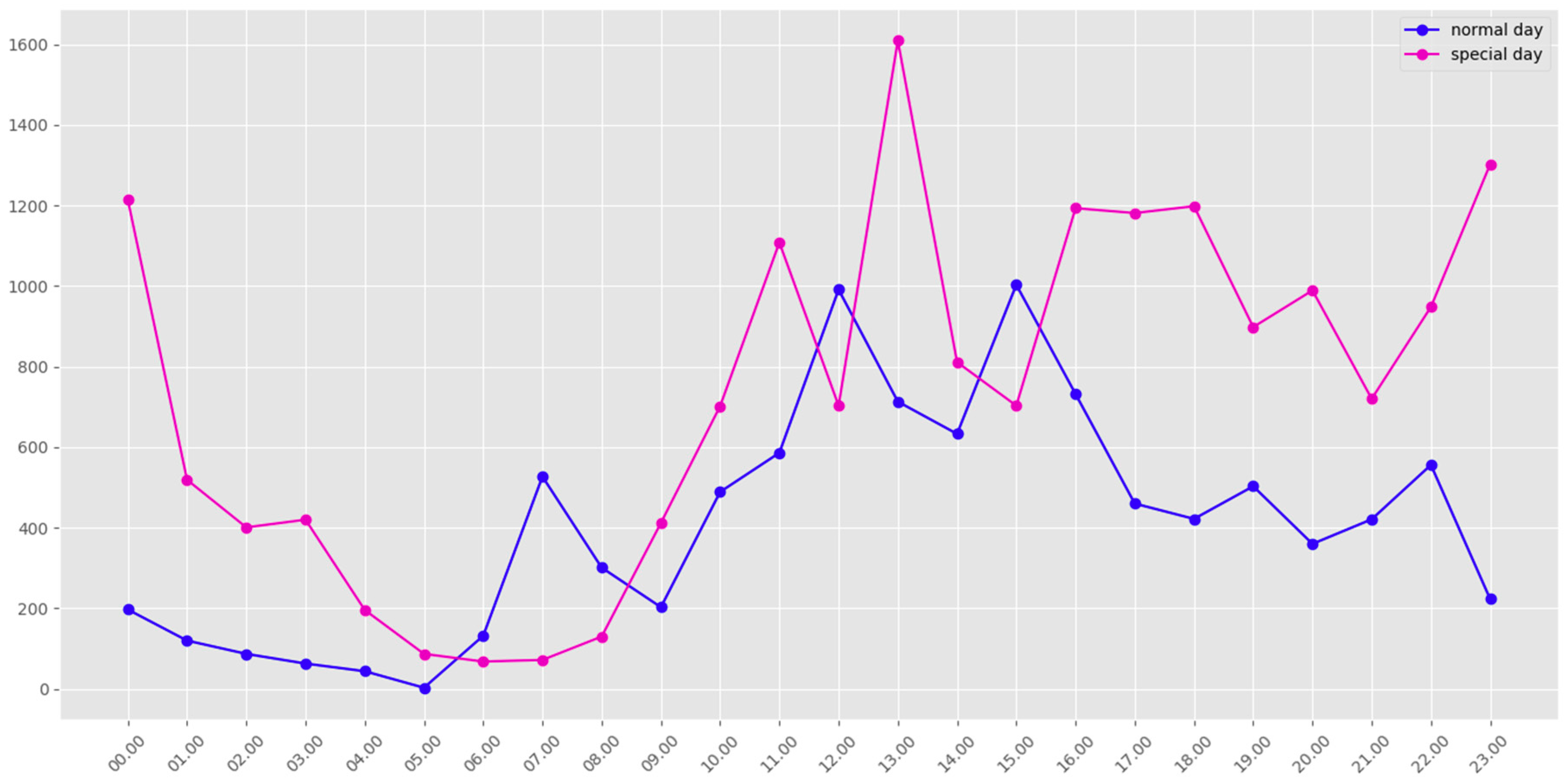
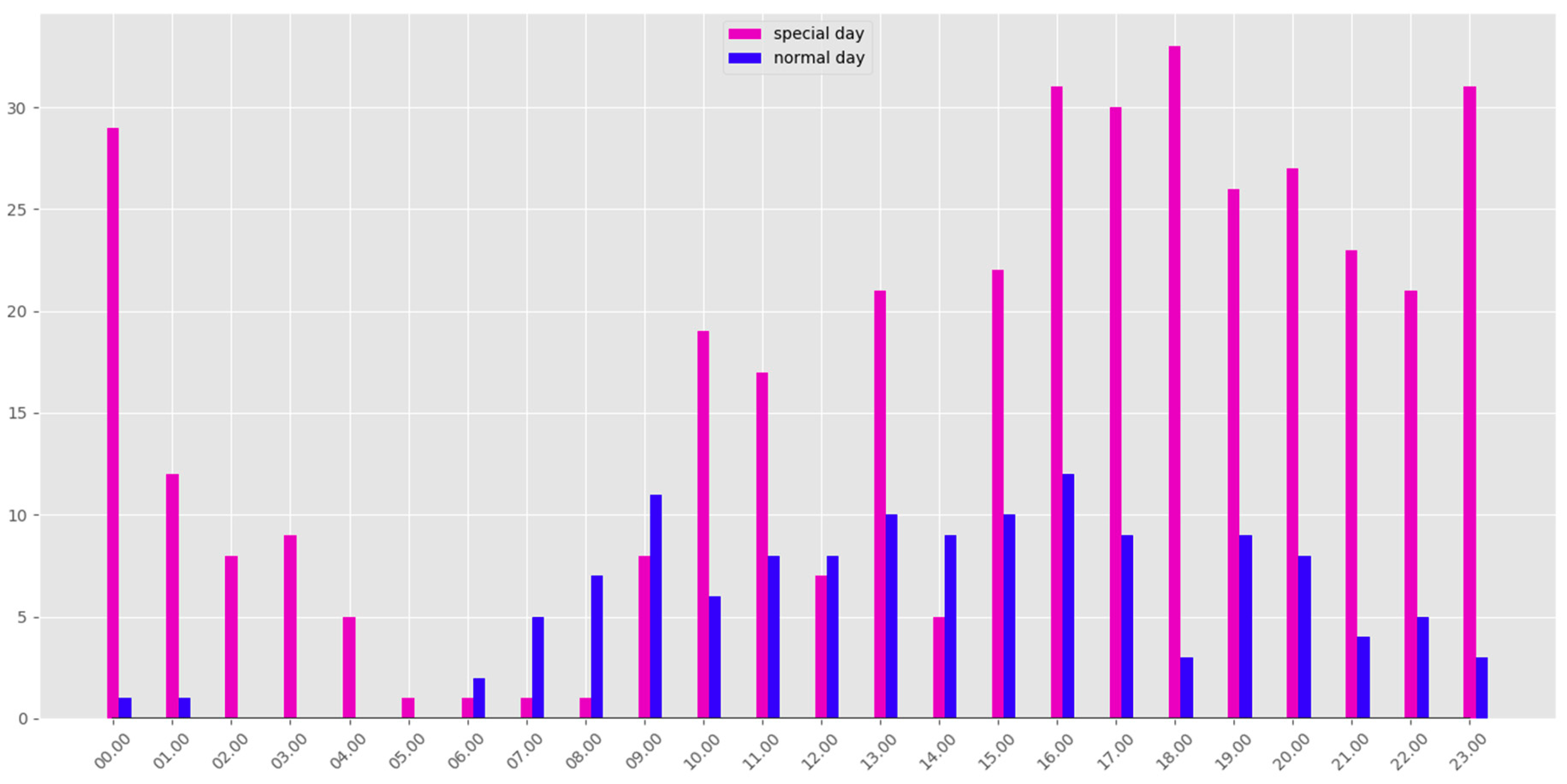
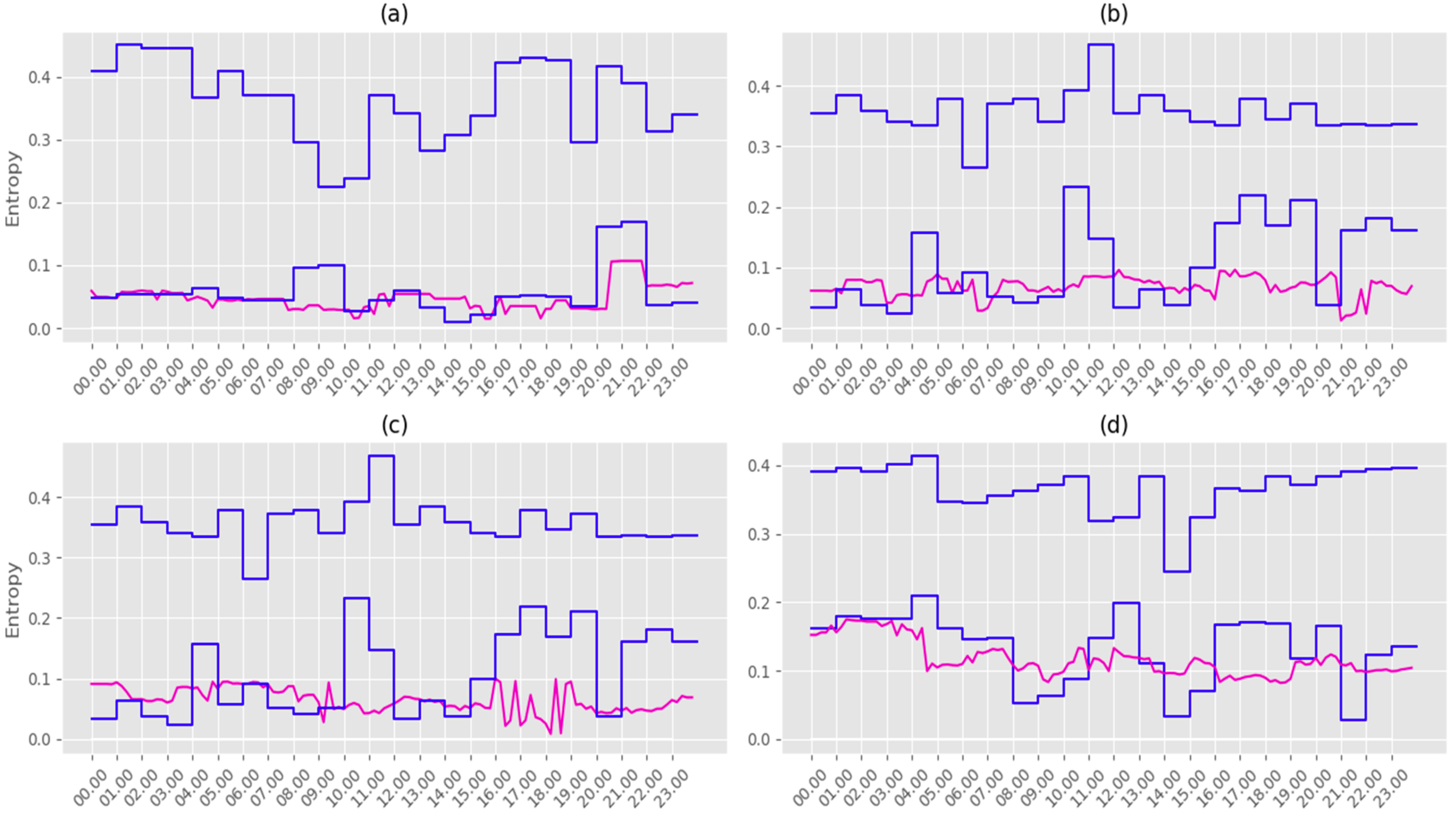
- The SOM (unsupervised clustering algorithm) and DBCSAN (density-based clustering algorithm) stage to identify and detect the crowds. This SOM and DBCSAN method for tweets clustering is well described in Section 3.1. Table 2, Table 3, Table 4 and Figure 4 summarize the obtained clustering results in NYC and Madrid city. The obtained results helped create a tool to support the abnormal events detection process, so this was a very important step. Figure 3, Figure 4 and Figure 5 show a detailed description of the state of the city on normal and special days in Madrid and NYC, illustrating the activity and the locations of the urban crowds. Figure 7 shows the dynamics of our system for estimating the parameters є and MinPts. All these results confirm the effectiveness of our method used in the first stage to detect and identify clusters dynamically, and imitating human nature movements. Therefore we have a robust methodology for identifying and detecting crowds that we can rely on.
- The entropy model was applied to detect abnormal events in the crowds. The reference entropy model was then constructed offline. Figure 6 illustrates the evolution of the maximum and minimum reference value of the entropy for each day of the week. Figure 8 shows clearly the detection of special days in NYC, and proves the performances of our proposed model to determine whether the detected crowds fit into the daily pattern, or if they should be considered as evidence of something unusual happening in the city.
- The use of SOM in the first stage allows for:
- Reducing the input space, which then allows us to establish DBSCAN. The DBSCAN algorithm is difficult to use in very large dimensions.
- Using SOM to select є and MinPts parameters.
- Using SOM and DBSCAN to detect the clusters of varied density with different shapes and sizes from the large amount of data, which contains noise and outliers.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Flickr. Available online: http://www.flickr.com (accessed on 3 June 2018).
- Foursquare. Available online: https://fr.foursquare.com (accessed on 3 June 2018).
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the Geotag: Situating ‘Big Data’ and Leveraging the Potential of the Geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as Sensors: The World of Volunteered Geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Tang, K.P.; Lin, J.; Hong, J.I.; Siewiorek, D.P.; Sadeh, N. Rethinking Location Sharing: Exploring the Implications of Social-Driven vs. Purpose-Driven Location Sharing. In Proceedings of the 12th ACM International Conference on Ubiquitous Computing, UbiComp ’10, Copenhagen, Denmark, 26–29 September 2010; ACM: New York, NY, USA, 2010; pp. 85–94. [Google Scholar]
- Stefanidis, A.; Crooks, A.; Radzikowski, J. Harvesting Ambient Geospatial Information from Social Media Feeds. GeoJournal 2013, 78, 319–338. [Google Scholar] [CrossRef]
- Gordon, E.; e Silva, A.D.S. Urban Spaces. In Net Locality: Why location matters in a networked world; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; pp. 85–104. [Google Scholar]
- Couronné, T.; Raimond, A.-O.; Smoreda, Z. Looking at Spatiotemporal City Dynamics through Mobile Phone Lenses. In Proceedings of the 2011 International Conference on the Network of the Future, Paris, France, 28–30 November 2011; pp. 128–134. [Google Scholar]
- Reades, J.; Calabrese, F.; Ratti, C. Eigenplaces: Analysing Cities Using the Space–Time Structure of the Mobile Phone Network. Environ. Plan. B Plan. Des. 2009, 36, 824–836. [Google Scholar] [CrossRef]
- Ahas, R.; Aasa, A.; Yuan, Y.; Raubal, M.; Smoreda, Z.; Liu, Y.; Ziemlicki, C.; Tiru, M.; Zook, M. Everyday Space–Time Geographies: Using Mobile Phone-Based Sensor Data to Monitor Urban Activity in Harbin, Paris, and Tallinn. Int. J. Geogr. Inf. Sci. 2015, 29, 2017–2039. [Google Scholar] [CrossRef]
- González, M.C.; Hidalgo, C.A.; Barabási, A.-L. Understanding Individual Human Mobility Patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.-H.; Schrock, S.D.; Vander Broek, N.; Mulinazzi, T. Estimating Dynamic Origin-Destination Data and Travel Demand Using Cell Phone Network Data. Int. J. ITS Res. 2013, 11, 76–86. [Google Scholar] [CrossRef]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling daily human mobility motifs. J. R. Soc. Interface 2013, 10, 20130246. [Google Scholar] [CrossRef] [Green Version]
- Tatem, A.J.; Qiu, Y.; Smith, D.L.; Sabot, O.; Ali, A.S.; Moonen, B. The Use of Mobile Phone Data for the Estimation of the Travel Patterns and Imported Plasmodium Falciparum Rates among Zanzibar Residents. Malar J. 2009, 8, 287. [Google Scholar] [CrossRef]
- Lu, X.; Bengtsson, L.; Holme, P. Predictability of Population Displacement after the 2010 Haiti Earthquake. Proc. Natl. Acad. Sci. USA 2012, 109, 11576–11581. [Google Scholar] [CrossRef]
- Wesolowski, A.; Buckee, C.O.; Bengtsson, L.; Wetter, E.; Lu, X.; Tatem, A.J. Commentary: Containing the Ebola Outbreak—The Potential and Challenge of Mobile Network Data. PLoS Curr. 2014, 6. [Google Scholar] [CrossRef]
- Louail, T.; Lenormand, M.; Cantu Ros, O.G.; Picornell, M.; Herranz, R.; Frias-Martinez, E.; Ramasco, J.J.; Barthelemy, M. From Mobile Phone Data to the Spatial Structure of Cities. Sci. Rep. 2014, 4, 5276. [Google Scholar] [CrossRef] [PubMed]
- Williams, N.E.; Thomas, T.A.; Dunbar, M.; Eagle, N.; Dobra, A. Measures of Human Mobility Using Mobile Phone Records Enhanced with GIS Data. PLoS ONE 2015, 10, e0133630. [Google Scholar] [CrossRef] [PubMed]
- Noulas, A.; Scellato, S.; Mascolo, C.; Pontil, M. An Empirical Study of Geographic User Activity Patterns in Foursquare. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, San Francisco, CA, USA, 17–21 July 2011. [Google Scholar]
- Kelley, M.J. The Emergent Urban Imaginaries of Geosocial Media. GeoJournal 2013, 78, 181–203. [Google Scholar] [CrossRef]
- Ben Khalifa, M.; Díaz Redondo, R.P.; Vilas, A.F.; Rodríguez, S.S. Identifying Urban Crowds Using Geo-Located Social Media Data: A Twitter Experiment in New York City. J. Intell. Inf. Syst. 2017, 48, 287–308. [Google Scholar] [CrossRef]
- Gao, H.; Liu, H. Data Analysis on Location-Based Social Networks. In Mobile Social Networking: An Innovative Approach; Chin, A., Zhang, D., Eds.; Computational Social Sciences; Springer New York: New York, NY, USA, 2014; pp. 165–194. [Google Scholar]
- Domínguez, D.R.; Díaz Redondo, R.P.; Vilas, A.F.; Khalifa, M.B. Sensing the City with Instagram: Clustering Geolocated Data for Outlier Detection. Expert Syst. Appl. 2017, 78, 319–333. [Google Scholar] [CrossRef]
- Pelechrinis, K.; Quercia, D. Urban informatics and the web. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; p. 1547. [Google Scholar]
- Silva, T.H.; Melo, P.O.S.V.D.; Almeida, J.M.; Loureiro, A.A.F. Large-Scale Study of City Dynamics and Urban Social Behavior Using Participatory Sensing. IEEE Wirel. Commun. 2014, 21, 42–51. [Google Scholar] [CrossRef]
- De Nadai, M.; Staiano, J.; Larcher, R.; Sebe, N.; Quercia, D.; Lepri, B. The Death and Life of Great Italian Cities: A Mobile Phone Data Perspective. In Proceedings of the 25th International Conference on World Wide Web, WWW ’16, Montréal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland, 2016; pp. 413–423. [Google Scholar]
- Roberts, H.V. Using Twitter Data in Urban Green Space Research: A Case Study and Critical Evaluation. Appl. Geogr. 2017, 81, 13–20. [Google Scholar] [CrossRef]
- Comito, C.; Falcone, D.; Talia, D. Mining Human Mobility Patterns from Social Geo-Tagged Data. Pervasive Mobile Comput. 2016, 33, 91–107. [Google Scholar] [CrossRef]
- Kanno, M.; Ehara, Y.; Hirota, M.; Yokoyama, S.; Ishikawa, H. Visualizing High-Risk Paths Using Geo-Tagged Social Data for Disaster Mitigation. In Proceedings of the 9th ACM SIGSPATIAL Workshop on Location-based Social Networks, LBSN16, Burlingame, CA, USA, 31 October–3 November 2016; ACM: New York, NY, USA, 2016; pp. 4:1–4:8. [Google Scholar]
- Kim, K.-S.; Kojima, I.; Ogawa, H. Discovery of Local Topics by Using Latent Spatio-Temporal Relationships in Geo-Social Media. Int. J. Geogr. Inf. Sci. 2016, 30, 1899–1922. [Google Scholar] [CrossRef]
- Yang, J.; Hauff, C.; Houben, G.-J.; Bolivar, C.T. Diversity in Urban Social Media Analytics. In Web Engineering; Bozzon, A., Cudre-Maroux, P., Pautasso, C., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Lugano, Switzerland, 2016; pp. 335–353. [Google Scholar]
- Bordogna, G.; Frigerio, L.; Cuzzocrea, A.; Psaila, G. Clustering Geo-Tagged Tweets for Advanced Big Data Analytics. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 27 June–2 July 2016; pp. 42–51. [Google Scholar]
- Manca, M.; Boratto, L.; Morell Roman, V.; Martori i Gallissà, O.; Kaltenbrunner, A. Using Social Media to Characterize Urban Mobility Patterns: State-of-the-Art Survey and Case-Study. Online Soc. Netw. Media 2017, 1, 56–69. [Google Scholar] [CrossRef]
- Gao, S.; Liu, Y.; Wang, Y.; Ma, X. Discovering Spatial Interaction Communities from Mobile Phone Data. Trans. GIS 2013, 17, 463–481. [Google Scholar] [CrossRef] [Green Version]
- Ahas, R. Using Mobile Positioning Data for Mapping Space-Time Behavior and Developing LBS: Experiences from Estonia; Carto Talk: Tartu, Estonia, 2008. [Google Scholar]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A Review of Volunteered Geographic Information Quality Assessment Methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer Series in Information Sciences; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Sakkari, M.; Ejbali, R.; Zaied, M. Deep SOMs for Automated Feature Extraction and Classification from Big Data Streaming. In Proceedings of the Ninth International Conference on Machine Vision (ICMV 2016), Nice, France, 8–20 November 2016; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10341, p. 103412. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters a Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose. In Proceedings of the 7th International Conference on Weblogs and Social Media, ICWSM 2013, Cambridge, MA, USA, 8–11 July 2013; AAAI Press: Menlo Park, CA, USA, 2013; pp. 400–408. [Google Scholar]
- Huang, Y.; Li, Y.; Shan, J. Spatial-Temporal Event Detection from Geo-Tagged Tweets. ISPRS Int. J. Geo-Inf. 2018, 7, 150. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst. 2017, 42, 19:1–19:21. [Google Scholar] [CrossRef]
- Garcia-Rubio, C.; Díaz Redondo, R.P.; Campo, C.; Fernández Vilas, A. Using Entropy of Social Media Location Data for the Detection of Crowd Dynamics Anomalies. Electronics 2018, 7, 380. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurements | 1 | 2 | 3 | 4 | 5 | 6 | H | |
|---|---|---|---|---|---|---|---|---|
| First Monday | ✓ | ✓ | ✓ | ✓ | ✕ | ✕ | 0.276 | |
| ✕ | ✕ | ✕ | ✕ | ✓ | ✓ | |||
| Second Monday | ✓ | ✓ | ✓ | ✓ | ✓ | ✕ | 0.499 | |
| ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | |||
| Third Monday | ✓ | ✓ | ✓ | ✓ | ✓ | ✕ | 0.499 | |
| ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | |||
| Forth Monday | ✓ | ✓ | ✓ | ✕ | ✕ | ✕ | 0.300 | |
| ✕ | ✕ | ✕ | ✓ | ✓ | ✓ | |||
| Time (h) | ε | MinPts | Number of Clusters | Noise Points |
|---|---|---|---|---|
| 15.00 | 30.12 | 3 | 1003 | 2654 |
| 16.00 | 23.41 | 2 | 732 | 2641 |
| 17.00 | 32.15 | 3 | 460 | 3546 |
| 18.00 | 26.21 | 3 | 422 | 4023 |
| 19.00 | 31.25 | 3 | 503 | 4895 |
| 20.00 | 35.10 | 4 | 360 | 5614 |
| 21.00 | 33.95 | 6 | 421 | 6210 |
| 22.00 | 38.25 | 5 | 556 | 5698 |
| 23.00 | 39.88 | 6 | 223 | 4512 |
| 00.00 | 42.50 | 5 | 197 | 4542 |
| 01.00 | 98.54 | 7 | 120 | 986 |
| 02.00 | 75.26 | 8 | 87 | 879 |
| 03.00 | 149.90 | 6 | 63 | 542 |
| 04.00 | 79.90 | 6 | 44 | 436 |
| 05.00 | 49.90 | 2 | 3 | 125 |
| 06.00 | 40.26 | 2 | 132 | 231 |
| 07.00 | 41.31 | 3 | 527 | 1895 |
| 08.00 | 33.25 | 3 | 301 | 1845 |
| 09.00 | 35.26 | 2 | 203 | 1954 |
| 10.00 | 37.21 | 3 | 489 | 2695 |
| 11.00 | 30.12 | 4 | 586 | 2828 |
| 12.00 | 35.11 | 3 | 991 | 3216 |
| 13.00 | 33.45 | 2 | 713 | 2963 |
| 14.00 | 33.21 | 3 | 633 | 3015 |
| Time (h) | ε | MinPts | Number of Clusters | Noise Points |
|---|---|---|---|---|
| 15.00 | 10.22 | 3 | 703 | 7641 |
| 16.00 | 11.32 | 2 | 1193 | 6631 |
| 17.00 | 14.12 | 3 | 1181 | 6521 |
| 18.00 | 11.32 | 3 | 1198 | 6579 |
| 19.00 | 10.65 | 2 | 898 | 6984 |
| 20.00 | 9.55 | 3 | 989 | 7285 |
| 21.00 | 11.65 | 3 | 720 | 9875 |
| 22.00 | 10.11 | 3 | 948 | 6578 |
| 23.00 | 9.75 | 4 | 1302 | 5487 |
| 00.00 | 7.91 | 5 | 1214 | 4987 |
| 01.00 | 38.54 | 2 | 519 | 1245 |
| 02.00 | 45.26 | 2 | 401 | 1574 |
| 03.00 | 46.90 | 2 | 420 | 1578 |
| 04.00 | 59.90 | 5 | 196 | 987 |
| 05.00 | 57.90 | 5 | 87 | 995 |
| 06.00 | 40.26 | 5 | 68 | 898 |
| 07.00 | 41.31 | 3 | 72 | 2458 |
| 08.00 | 33.25 | 3 | 130 | 2657 |
| 09.00 | 35.26 | 2 | 412 | 4578 |
| 10.00 | 37.21 | 3 | 702 | 4884 |
| 11.00 | 30.12 | 3 | 1108 | 4369 |
| 12.00 | 35.11 | 3 | 703 | 5698 |
| 13.00 | 33.45 | 3 | 1609 | 5321 |
| 14.00 | 33.21 | 2 | 811 | 4578 |
| Time (h) | ε | MinPts | Number of Clusters | Noise Points |
|---|---|---|---|---|
| 15.00 | 41.52 | 5 | 415 | 442 |
| 16.00 | 40.70 | 5 | 514 | 362 |
| 17.00 | 49.21 | 4 | 421 | 512 |
| 18.00 | 51.65 | 5 | 512 | 532 |
| 19.00 | 49.25 | 4 | 320 | 566 |
| 20.00 | 48.65 | 4 | 125 | 541 |
| 21.00 | 44.65 | 5 | 125 | 545 |
| 22.00 | 42.15 | 5 | 210 | 566 |
| 23.00 | 39.88 | 3 | 145 | 495 |
| 00.00 | 49.50 | 2 | 99 | 488 |
| 01.00 | 54.34 | 2 | 52 | 458 |
| 02.00 | 65.26 | 2 | 44 | 365 |
| 03.00 | 75.91 | 5 | 14 | 145 |
| 04.00 | 74.84 | 7 | 8 | 102 |
| 05.00 | 59.69 | 2 | 7 | 44 |
| 06.00 | 54.56 | 2 | 55 | 46 |
| 07.00 | 53.11 | 2 | 220 | 456 |
| 08.00 | 53.65 | 2 | 321 | 514 |
| 09.00 | 45.26 | 2 | 455 | 395 |
| 10.00 | 47.21 | 3 | 551 | 546 |
| 11.00 | 49.52 | 3 | 326 | 321 |
| 12.00 | 41.58 | 3 | 281 | 301 |
| 13.00 | 39.92 | 3 | 332 | 402 |
| 14.00 | 40.59 | 3 | 336 | 306 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sakkari, M.; D. Algarni, A.; Zaied, M. Urban Crowd Detection Using SOM, DBSCAN and LBSN Data Entropy: A Twitter Experiment in New York and Madrid. Electronics 2019, 8, 692. https://doi.org/10.3390/electronics8060692
Sakkari M, D. Algarni A, Zaied M. Urban Crowd Detection Using SOM, DBSCAN and LBSN Data Entropy: A Twitter Experiment in New York and Madrid. Electronics. 2019; 8(6):692. https://doi.org/10.3390/electronics8060692
Chicago/Turabian StyleSakkari, Mohamed, Abeer D. Algarni, and Mourad Zaied. 2019. "Urban Crowd Detection Using SOM, DBSCAN and LBSN Data Entropy: A Twitter Experiment in New York and Madrid" Electronics 8, no. 6: 692. https://doi.org/10.3390/electronics8060692