Fake News Analysis Modeling Using Quote Retweet


Abstract
:
1. Introduction
- A novel fake news analysis modelling system was built by analysing Twitter’s Tweets and Quote RT together.
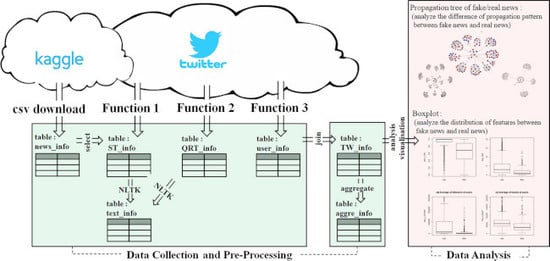
- A method was proposed to conveniently collect numerous Twitter data (tweets, Quote RT, user information) in stages for fake news analysis.
- Best features that could directly (effectively) affect fake news were identified through highly reliable statistical analysis and visualisation method.
- A novel visualisation method was applied for fake news phenomenon analysis and trend identification so that their characteristics could be easily investigated.
- For the evaluation of fake news classification function based on the method proposed in this study, comparative analysis was conducted using conventional studies by applying neural network, one of the artificial intelligence (AI) technologies, and its superiority was demonstrated.
2. Background
2.1. Twitter
2.2. Major Functions of Twitter
2.2.1. Follow
2.2.2. Tweeting
- Hashtag (#): it is usually used when mentioning keywords related with a Tweet. A link is added to the texts prefixed with a ‘#’ sign, and when it is clicked, search results for the pertinent keyword are shown.
- Mention (@): it is used for the purpose of mentioning a certain user by writing the user’s name after @. A Tweet notification is sent to the mentioned user. Mention is usually used for the purpose of conversation or question and answer (Q&A) between certain users, and the content of conversation may be disclosed to other users.
2.2.3. Retweet
2.2.4. Quote Retweet
2.3. Fake News
3. Related Work
4. Data Collection and Preprocessing
4.1. Data Collection
| Function 1: CollectSeedTweets | |
| input: startDate, endDate, news, isFake | |
| 1 | driver = createSeleniumDriver() |
| 2 | searchPage(driver, new, startDate, endDatae) |
| 3 | newBottom = 0 |
| 4 | lastBottom = scrollDown(driver) |
| 5 | while newBottom != lastBottom |
| 6 | preBottom = newBottom |
| 7 | newBottom = scrollDown(driver) |
| 8 | parser = createParser(driver.page_source) |
| 9 | userList = parser.find(“username”) |
| 10 | cnt = len(userList) |
| 11 | if(cnt == 0) return |
| 12 | id_time = parser.find(“tweet-timestamp”) |
| 13 | twidList, timeList = split(id_time) |
| 14 | txtList = parser.find(“tweettextsize”) |
| 15 | replycntList = parser.find(“action—reply”) |
| 16 | rtcntList = parser.find(“action—retweet”) |
| 17 | favocntList = parser.find(“action—favorite”) |
| 18 | imgList = parser.find(“adaptive-photo”) |
| 19 | videoList = parser.find(“playablemedia-player”) |
| 20 | newsList = createList(cnt, news) |
| 21 | parentList = createList(cnt, news) |
| 22 | isfakeList = createList(cnt, isFake) |
| 23 | depthList = createList(cnt, 0) |
| 24 | df = createDataframe( newsList, parentList, twidList, userList, timeList, txtList, replycntList, rtcntList, favocntList, imgList, videoList, isFake, depthList ) |
| 25 | InsertTable(df, “ST_info”) |
| Function 2: CollectQuoteRTs | |
| input: parentID, news, isFake | |
| 1 | global depth // initialize 0 |
| 2 | depth = depth + 1 |
| 3 | driver = createSeleniumDriver() |
| 4 | searchPage(driver, parentID) |
| 5 | newBottom = 0 |
| 6 | lastBottom = scrollDown(driver) |
| 7 | while newBottom != lastBottom |
| 8 | preBottom = newBottom |
| 9 | newBottom = scrollDown(driver) |
| 10 | parser = createParser(driver.page_source) |
| 11 | userList = parser.find(“username”) |
| 12 | cnt = len(userList) |
| 13 | if(cnt == 0) return |
| 14 | id_time = parser.find(“tweet-timestamp”) |
| 15 | twidList, timeList = split(id_time) |
| 16 | txtList = parser.find(“tweettextsize”) |
| 17 | replycntList = parser.find(“action—reply”) |
| 18 | rtcntList = parser.find(“action—retweet”) |
| 19 | favocntList = parser.find(“action—favorite”) |
| 20 | imgList = parser.find(“adaptive-photo”) |
| 21 | videoList = parser.find(“playablemedia-player”) |
| 22 | depthList = createList(cnt, depth) |
| 23 | newsList = createList(cnt, news) |
| 24 | parentList = createList(cnt, parentID) |
| 25 | isfakeList = createList(cnt, isFake) |
| 26 | df = createDataframe( newsList. parentList, twidList, userList, timeList, txtList, replycntList, rtcntList, favocntList, imgList, videoList, isFake, depthList ) |
| 27 | insertTable(df, “QRT_info”) |
| 28 | for id in idList: |
| CollectQuoteRTs(id, new, isFake) | |
| 29 | depth = depth − 1 |
| Function 3: CollectUserinfo | |
| input: userID, tweepyAPI | |
| 1 | info = tweepyAPI.get_user(userID) |
| 2 | df = createDataframe( userID, info.followers, info.followings, info.statuses, // tweet cnt info.created_at, // age info.description, // bio info.url ) |
| 3 | InsertTable(df, “user_info”) |
4.2. Preprocessing
5. Data Analysis
5.1. Statistics and Visualisation
5.2. Best Features
5.3. Neural Network-Based Fake News Classifier
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Hermida, A. Twittering the news: The emergence of ambient journalism. Journal. Pract. 2010, 4, 297–308. [Google Scholar] [CrossRef]
- Procter, R.; Crump, J.; Karstedt, S.; Voss, A.; Cantijoch, M. Reading the riots: What were the police doing on Twitter? Polic. Soc. 2013, 23, 413–436. [Google Scholar] [CrossRef]
- Van Dijck, J. The Culture of Connectivity: A Critical History of Social Media; Oxford University Press: New York, NY, USA, 2013; pp. 3–18. [Google Scholar]
- Fuchs, C. Social Media: A Critical Introduction, 2nd ed.; SAGE Publications Ltd.: London, UK, 2017; pp. 33–61. [Google Scholar]
- Jeong, S.S.; Seo, Y.S. Improving response capability of chatbot using twitter. J. Ambient Intell. Humaniz Comput. 2019, 1–14. [Google Scholar] [CrossRef]
- Phuvipadawat, S.; Murata, T. Breaking news detection and tracking in Twitter. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010; pp. 120–123. [Google Scholar]
- Kwak, H.; Lee, H.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 591–600. [Google Scholar]
- Yates, D.; Paquette, S. Emergency knowledge management and social media technologies: A case study of the 2010 Haitian earthquake. Int. J. Inf. 2011, 31, 6–13. [Google Scholar] [CrossRef]
- Yin, J.; Karimi, S.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using social media to enhance emergency situation awareness. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 4234–4238. [Google Scholar]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: A survey. ACM Comput. Surv. 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Huh, J.H. PLC-based design of monitoring system for ICT-integrated vertical fish farm. Hum. Centric Comput. Inf. Sci. 2017, 7, 1–19. [Google Scholar] [CrossRef]
- Sakaki, T.; Makoto, O.; Yutaka, M. Tweet analysis for real-time event detection and earthquake reporting system development. IEEE Trans. Knowl. Data Eng. 2012, 25, 919–931. [Google Scholar] [CrossRef]
- Internet Overtakes Newspapers As News Outlet. Available online: t.ly/2l7jR (accessed on 16 November 2019).
- Flanagin, A.J.; Miriam, M.J. Perceptions of Internet information credibility. Journal. Mass Commun. Q. 2000, 77, 515–540. [Google Scholar] [CrossRef]
- Johnson, T.J.; Kaye, B.K.; Bichard, S.L.; Wong, W.J. Every blog has its day: Politically-interested Internet users’ perceptions of blog credibility. J. Comput. Mediat. Commun. 2007, 13, 100–122. [Google Scholar] [CrossRef]
- Procter, R.; Vis, F.; Voss, A. Reading the riots on Twitter: Methodological innovation for the analysis of big data. Int. J. Soc. Res. Methodol. 2013, 16, 197–214. [Google Scholar] [CrossRef]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and Resolution of Rumours in Social Media: A Survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Starbird, K.; Maddock, J.; Orand, M.; Achterman, P.; Mason, R.M. Rumors, false flags, and digital vigilantes: Misinformation on twitter after the 2013 boston marathon bombing. In Proceedings of the iConference 2014, Berlin, Germany, 4–7 March 2014; pp. 654–662. [Google Scholar]
- DiFonzo, N.; Bordia, P. Rumor Psychology: Social and Organizational Approaches; American Psychological Association: Washington, DC, USA, 2007; pp. 5–15. [Google Scholar]
- DiFonzo, N.; Bordia, P.; Rosnow, R.L. Reining in rumors. Organ. Dyn. 1994, 23, 47–62. [Google Scholar] [CrossRef]
- Java, A.; Song, X.; Finin, T. Why we twitter: Understanding microblogging usage and communities. In Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis, San Jose, CA, USA, 12 August 2007; pp. 56–65. [Google Scholar]
- Robertson, S.P.; Vatrapu, R.K.; Medina, R. Off the wall political discourse: Facebook use in the 2008 US presidential election. Inf. Polity 2010, 15, 11–31. [Google Scholar] [CrossRef]
- Kushin, M.J.; Kitchener, K. Getting political on social network sites: Exploring online political discourse on Facebook. First Monday 2009, 14. [Google Scholar] [CrossRef]
- Halpern, D.; Gibbs, J. Social media as a catalyst for online deliberation? Exploring the affordances of Facebook and YouTube for political expression. Comput. Hum. Behav. 2013, 29, 1159–1168. [Google Scholar] [CrossRef]
- Pershad, Y.; Hangge, P.T.; Albadawi, H.; Oklu, R. Social medicine: Twitter in healthcare. J. Clin. Med. 2018, 7, 121. [Google Scholar] [CrossRef]
- Mustafaraj, E.; Metaxas, P.T. From obscurity to prominence in minutes: Political speech and real-time search. In Proceedings of the WebSci10: Extending the Frointer of Society On-Line, Raleigh, NC, USA, 26–27 April 2010; pp. 1–7. [Google Scholar]
- Tolmie, P.; Procter, R.; Rouncefield, M.; Liakata, M.; Zubiaga, A. Microblog Analysis as a Program of Work. ACM Trans. Soc. Comput. 2018, 1, 1–40. [Google Scholar] [CrossRef]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring minds: Early detection of rumors in social media from enquiry posts. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1359–1405. [Google Scholar]
- Lazer, D.M.J.; Baum, M.A.; Benkler, J.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, G.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Lukasik, M.; Srijith, P.K.; Vu, D.; Bontcheva, K.; Zubiaga, A.; Cohn, T. Hawkes processes for continuous time sequence classification: An application to rumour stance classification in twitter. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 393–398. [Google Scholar]
- Schwarz, J.; Morris, M. Augmenting web pages and search results to support credibility assessment. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 1245–1254. [Google Scholar]
- Haciyakupoglu, G.; Hui, J.Y.; Suguna, V.S.; Leong, D.; Rahman, M.F.B.A. Countering Fake News: A Survey of Recent Global Initiatives; RSIS: Singapore, 2018; pp. 1–22. [Google Scholar]
- Garimella, K.; Weber, I.; De Choudhury, M. Quote RTs on Twitter: Usage of the new feature for political discourse. In Proceedings of the 8th ACM Conference on Web Science, Hannover, Germany, 22–25 May 2016; pp. 200–204. [Google Scholar]
- Del Pilar Salas-Zárate, M.; Paredes-Valverde, M.A.; Rodriguez-García, M.Á.; Valencia-García, R.; Alor-Hernández, G. Automatic detection of satire in Twitter: A psycholinguistic-based approach. Knowl. Based Syst. 2017, 128, 20–33. [Google Scholar] [CrossRef]
- Berghel, H. Lies, damn lies, and fake news. Computer 2017, 50, 80–85. [Google Scholar] [CrossRef]
- Tan, E.E.G.; Ang, B. Clickbait: Fake News and Role of the State. RSIS Comment. 2017, 26, 1–4. [Google Scholar]
- Klünder, J.; Schmitt, A.; Hohl, P.; Schneider, K. Fake news: Simply agile. In Projektmanagement und Vorgehensmodelle 2017-Die Spannung Zwischen dem Prozess und den Mensch im Projekt; Gesellschaft für Informatik: Bonn, Germany, 2017; pp. 187–192. [Google Scholar]
- Bessi, A.; Ferrara, E. Social bots distort the 2016 US Presidential election online discussion. First Monday 2016, 21, 1–14. [Google Scholar] [CrossRef]
- Kraski, R. Combating Fake News in Social Media: US and German Legal Approaches. St. John’s Law Rev. 2018, 91, 923–955. [Google Scholar]
- Buhrmester, M.; Kwang, T.; Gosling, S.D. Amazon’s Mechanical Turk: A new source of inexpensive, yet high-quality, data? Perspect. Psychol. Sci. 2011, 6, 3–5. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K. Rumor detection over varying time windows. PLoS ONE 2017, 12, 1–19. [Google Scholar] [CrossRef]
- Foster, E.K.; Rosnow, R.L. Gossip and network relationships. Relating difficulty. Routledge 2013, 37, 177–196. [Google Scholar]
- Jin, Z.; Cao, J.; Zhang, Y.; Luo, J. News verification by exploiting conflicting social viewpoints in microblogs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2972–2978. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Yang, F.; Liu, Y.; Yu, X.; Yang, M. Automatic detection of rumor on sina weibo. In Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics, Beijing, China, 12–16 August 2012; pp. 1–7. [Google Scholar]
- Liu, X.; Nourbakhsh, A.; Li, Q.; Fang, R.; Shah, S. Real-time rumor debunking on twitter. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1867–1870. [Google Scholar]
- Maddock, J.; Starbird, K.; Al-Hassani, H.J.; Sandoval, D.E.; Orand, M.; Mason, R.M. Characterizing online rumoring behavior using multi-dimensional signatures. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 228–241. [Google Scholar]
- Zubiaga, A.; Liakata, M.; Procter, R.; Hoi, G.W.S.; Tolmie, P. Analysing how people orient to and spread rumours in social media by looking at conversational threads. PLoS ONE 2016, 11, 1–29. [Google Scholar] [CrossRef]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter under crisis: Can we trust what we RT. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; pp. 71–79. [Google Scholar]
- Cheng, J.J.; Liu, Y.; Shen, B.; Yuan, W.G. An epidemic model of rumor diffusion in online social networks. Eur. Phys. J. B 2013, 86, 1–7. [Google Scholar] [CrossRef]
- Chua, A.Y.; Tee, C.Y.; Pang, A.; Lim, E.P. The retransmission of rumor-related tweets: Characteristics of source and message. In Proceedings of the 7th 2016 International Conference on Social Media & Society, London, UK, 11–13 July 2016; pp. 1–10. [Google Scholar]
- Vosoughi, S. Automatic Detection and Verification of Rumors on Twitter. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 7 May 2015. [Google Scholar]
- Giasemidis, G.; Singleton, C.; Agrafiotis, I.; Nurse, J.R.; Pilgrim, A.; Willis, C.; Greetham, D.V. Determining the veracity of rumours on Twitter. In Proceedings of the International Conference on Social Informatics, Bellevue, WA, USA, 11–14 November 2016; pp. 185–205. [Google Scholar]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, Philadelphia, PA, USA, 7 July 2002; pp. 63–70. [Google Scholar]
- Getting Real about Fake News. Available online: https://www.kaggle.com/mrisdal/fake-news (accessed on 16 November 2019).
- News Category Dataset. Available online: https://www.kaggle.com/rmisra/news-category-dataset (accessed on 16 November 2019).
- Tweepy Documentation. Available online: https://buildmedia.readthedocs.org/media/pdf/tweepy/v3.6.0/tweepy.pdf (accessed on 16 November 2019).
- Avasarala, S. Selenium WebDriver Practical Guide; Packt Publishing Ltd.: Birmingham, UK, 2014; pp. 7–10. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance, Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Package ‘nnet’. Available online: http://brieger.esalq.usp.br/CRAN/web/packages/nnet/nnet.pdf (accessed on 16 November 2019).
- Huh, J.H. Big data analysis for personalized health activities: Machine learning processing for automatic keyword extraction approach. Symmetry 2018, 10, 93. [Google Scholar] [CrossRef]
- Seo, Y.S.; Bae, D.H. On the value of outlier elimination on software effort estimation research. Empir. Softw. Eng. 2013, 18, 659–698. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range | Fields | Description | Type |
|---|---|---|---|
| Prime information | news | Title of mentioned news by tweet | varchar |
| parent_id | Parent tweet id of tweet | varchar | |
| tweet_id | Tweet id | varchar | |
| user_id | Writer of tweet | varchar | |
| uptime | Upload date and time of tweet | datetime | |
| text | Text of tweet | varchar | |
| rt_cnt | Count of tweet | int | |
| rep_cnt | Count of reply | int | |
| fav_cnt | Count of favorite | int | |
| isQrt | Is quote retweet? or not (1 or 0) | int | |
| hasImg | Include image in tweet?(1 or 0) | int | |
| hasVideo | Include video in tweet? | int | |
| isFake | Is fake news? or not | int | |
| depth | Depth of tweet propagation tree | int | |
| Information of text in tweet | t_hasURL | Include URL in text of tweet?(1 or 0) | int |
| t_hasAt | Include ‘@’ in text of tweet? | int | |
| t_hasSharp | Include ‘#’ in text of tweet? | int | |
| t_hasExclam | Include ‘!’ in text of tweet? | int | |
| t_hasQuest | Include ‘?’ in text of tweet? | int | |
| t_pos_cnt | Count of positive words in text?(1 or 0) | int | |
| t_neg_cnt | Count of negative words in text? | int | |
| t_bigword_cnt | Count of uppercase words in text? | int | |
| t_senti_score | Score of sentiment of text | float | |
| User information of writer of tweet | u_follower_cnt | Count of followers of writer | int |
| u_following_cnt | Count of followings of writer | int | |
| u_tweet_cnt | Count of tweets(status) of writer | int | |
| u_createtime | Created time of account of writer | datetime | |
| u_hasBio | Include bio in profile of writer?(1 or 0) | int | |
| u_hasURL | Include URL in profile of writer? | int |
| Fields | Description | Type |
|---|---|---|
| news | News title | varchar |
| avg_rt_cnt | Average of count of retweets | float |
| avg_rep_cnt | Average of count of replies | float |
| avg_fav_cnt | Average of count of favorites | float |
| avg_depth | Average of depth of tweet propagation tree | float |
| rate_Qrt | Rate of included quote retweet | float |
| rate_img | Rate of included image | float |
| rate_multi | Rate of included multimedia | float |
| rate_t_at | Rate of included ‘@’ | float |
| rate_t_sharp | Rate of included ‘#’ | float |
| rate_t_url | Rate of included URL(in text of tweet) | float |
| rate_t_exclam | Rate of included ‘!’ | float |
| rate_t_quest | Rate of included ‘?’ | float |
| avg_t_pos_cnt | Average of count of positive words | float |
| avg_t_neg_cnt | Average of count of negative words | float |
| avg_t_bigword_cnt | Average of count of uppercase words | float |
| avg_t_senti_score | Average of score of sentiment | float |
| avg_u_followers | Average of followers(of writer) | float |
| avg_u_followings | Average of followings | float |
| avg_u_tweets | Average of tweets | float |
| avg_u_acc_age | Average of age(day) of account | float |
| rate_u_bio | Rate of included bio | float |
| rate_u_URL | Rate of included URL(in profile of writer) | float |
| isFake | Is fake? or not | int |
| URL | Reply | Depth | Followers | Tweets | Account | Qrt | Image | Multimedia | |
|---|---|---|---|---|---|---|---|---|---|
| Fake | 0.649 | 5.24 | 0.337 | 65,905.12 | 48,033.7 | 2203.1 | 0.315 | 0.194 | 0.297 |
| Real | 0.916 | 6.75 | 0.656 | 282,666.7 | 62,391.9 | 2450.7 | 0.620 | 0.148 | 0.253 |
| Variables | p-Value |
|---|---|
| rate _t_URL | 2.2 × 10−16 |
| avg_reply_cnt | 0.426 |
| avg_depth | 2.2 × 10−16 |
| avg_u_follower_cnt | 2.2 × 10−16 |
| avg_u_tweets_cnt | 1.841 × 10−9 |
| avg_u_acc_age | 2.2 × 10−16 |
| rate_Qrt | 2.2 × 10−16 |
| rate_img | 9.968 × 10−6 |
| rate_multi | 0.032 |
| Fake News | Real News | |
|---|---|---|
| average propagation period (days) | 706.61 | 107.72 |
| Classification Models | Tweet Range | Learning Features |
|---|---|---|
| Model 1 | only ST | Castillo’s best features. |
| Model 2 | ST + QRT | All features. (in Table 2) |
| Model 3 | ST + QRT | Best features. (in Table 3) |
| Target | Fake News | Real News | Total (Fake + Real) | |
|---|---|---|---|---|
| Models | ||||
| Model 1 | 70.09% | 71.36% | 70.93% | |
| Model 2 | 74.57% | 81.87.% | 80.72% | |
| Model 3 | 83.05% | 75.35 | 76.57% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, Y.; Park, C.-H.; Seo, Y.-S. Fake News Analysis Modeling Using Quote Retweet. Electronics 2019, 8, 1377. https://doi.org/10.3390/electronics8121377
Jang Y, Park C-H, Seo Y-S. Fake News Analysis Modeling Using Quote Retweet. Electronics. 2019; 8(12):1377. https://doi.org/10.3390/electronics8121377
Chicago/Turabian StyleJang, Yonghun, Chang-Hyeon Park, and Yeong-Seok Seo. 2019. "Fake News Analysis Modeling Using Quote Retweet" Electronics 8, no. 12: 1377. https://doi.org/10.3390/electronics8121377