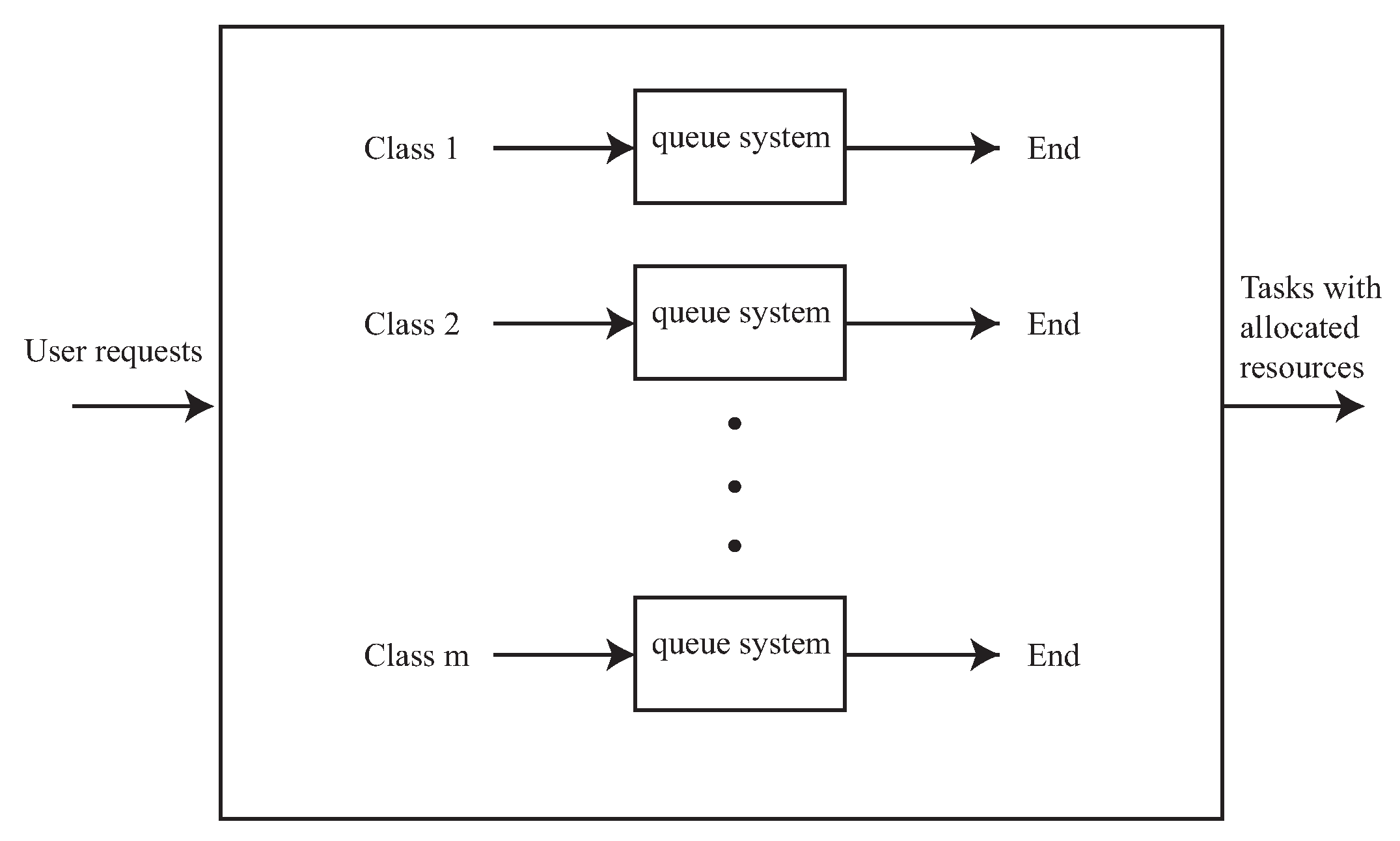
Our resource allocation scheme separates the user demands into classes, based on the dominant resource. Thus, there are
m classes. The resource allocator is a central system that handles a set of queue systems. Generally, the resource allocator has
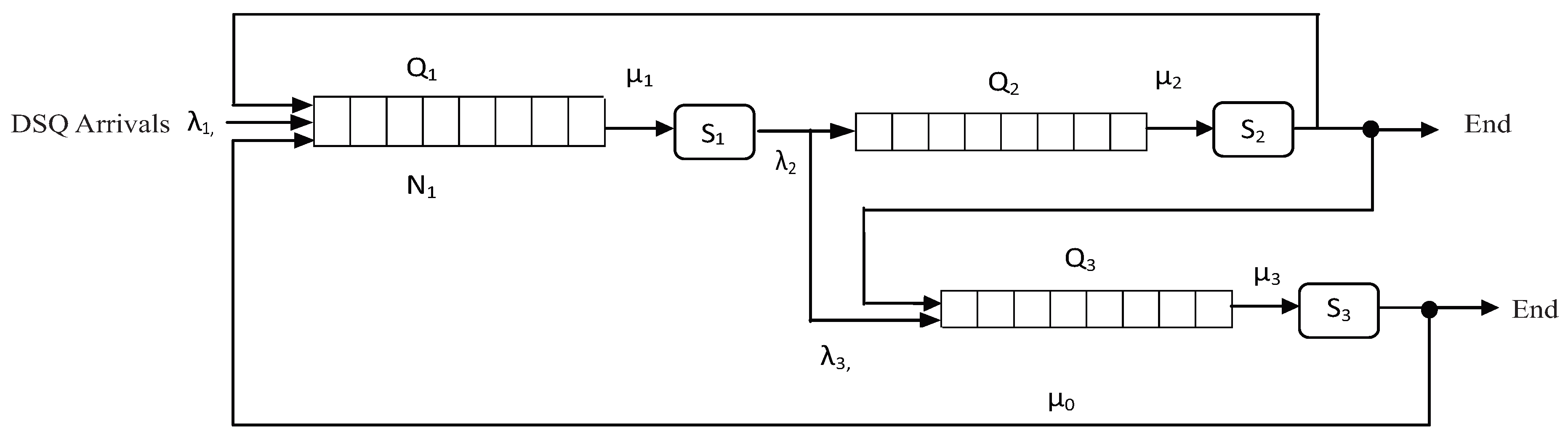
m queue systems, with a structure similar to the one shown in
Figure 1, one for each dominant resource. For
,
Figure 1 shows the structure of each queue system exactly.
Figure 2 shows the general structure of the resource allocator.
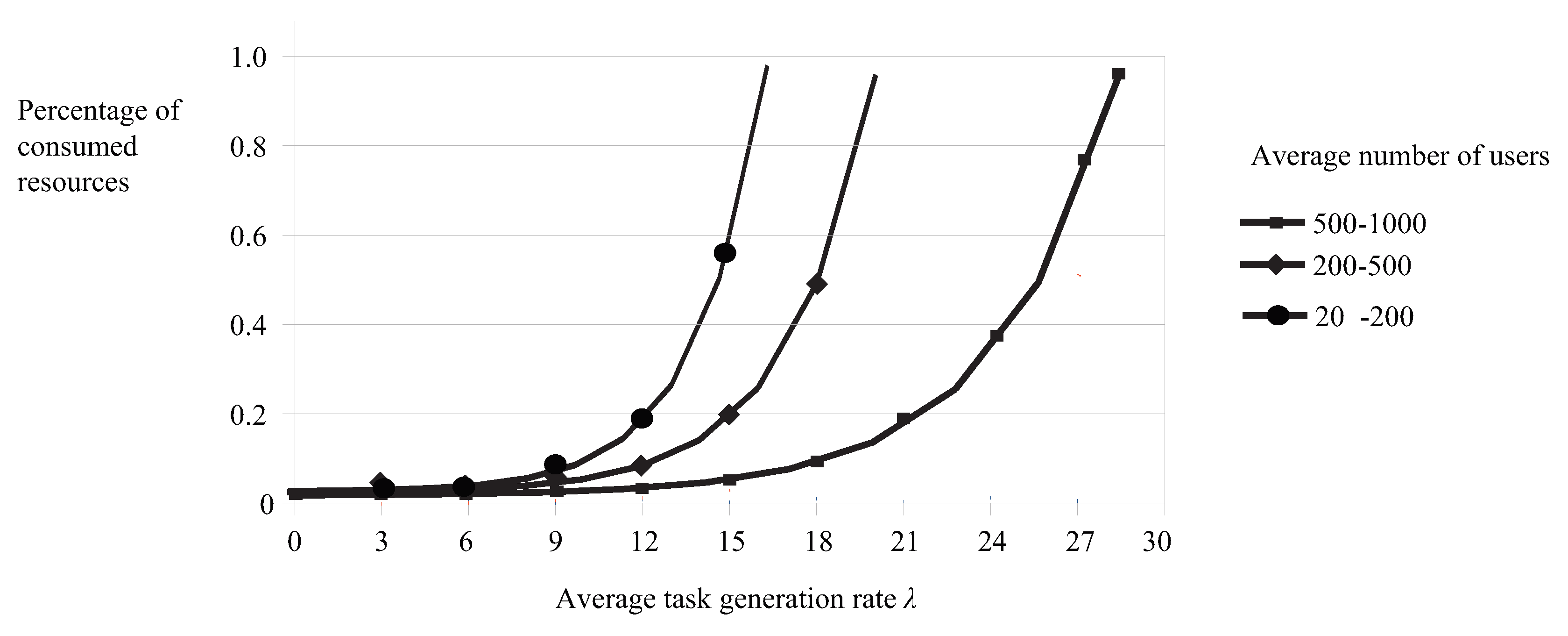
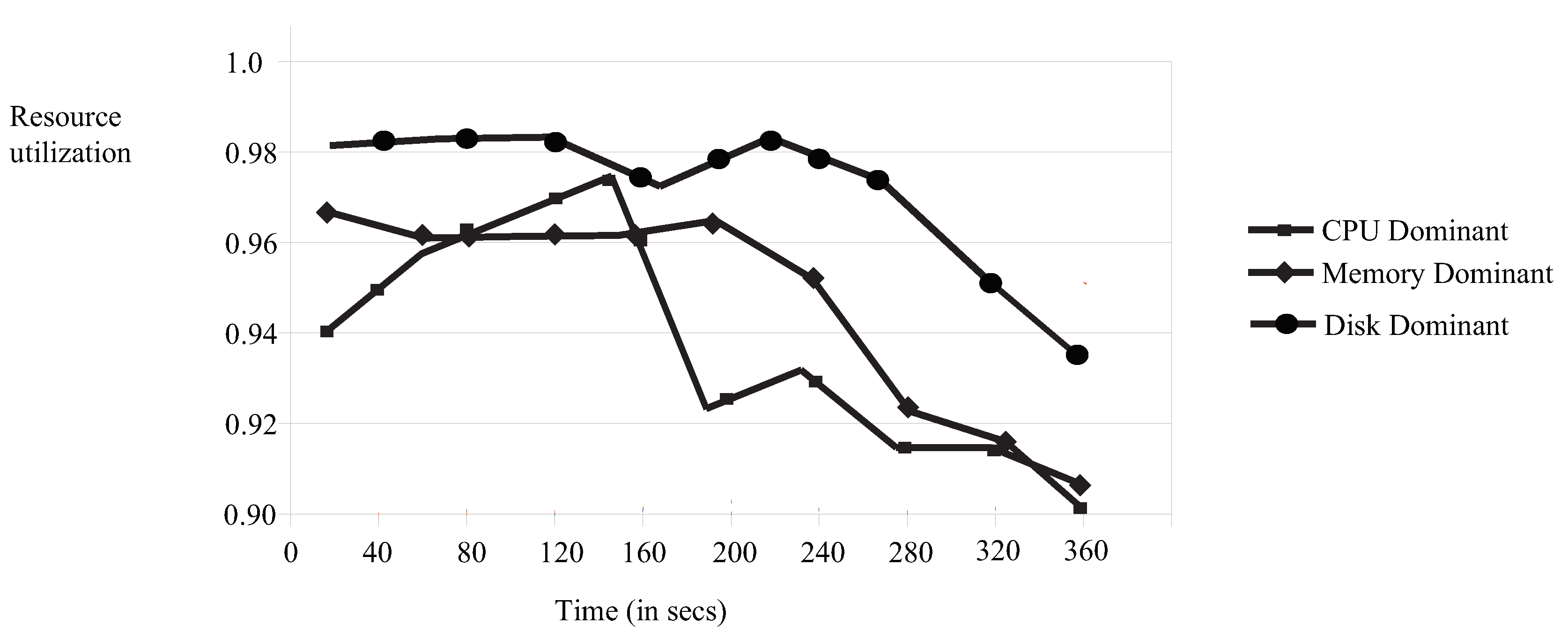
4.1. An Illustrative Example
To show how our policy can be applied, consider a cloud with three resources available, (CPU, Memory and Disk) = (40, 80 and 50). The mean service rate in all queues is
jobs per time unit. The amounts are given in units; a memory and disk unit can have a certain size. There are nine users that compete for these resources and their demands are given in
Table 2.
Obviously, the jobs to be generated will either be CPU-intensive or memory-intensive. This means that our allocator will use two of the three available queue systems, 1 and 2. Each of the two systems will have three queues, and , where and are the DSQs of the two systems. In the first system, will accommodate the CPU-intensive jobs, while in the second system, will accommodate the memory-intensive jobs.
Algorithm 1 starts with the threshold values and . As discussed in the beginning of this section, an intuitive idea to define would be to find the percentage of CPUs requested as dominant from the total number of requested CPUs. In this example, 37 CPUs are requested as dominant resources (users 1–5) and another 16 as non-dominant resources. In total, 53 CPUs are required; thus, 37/53 = of the CPU requests are for dominant resources. Thus, and . Similarly, 93 out of the 115 in total memory requests are for dominant resources. This is , so , so .
| Algorithm 1: Describes the resource allocation policy. |
| 1. Find the threshold values ; |
| 2. Compute ; // Non-dominant resources. |
| 3. For all DSQ’s in parallel do |
| 4. Implement the fair policy; // (Steps 1–3; see Section 2.1). |
| 5. Compute ; // The total amount of dominant resources |
| // allocated. |
| 6. ; // Amounts of dominant resources |
| // left unallocated. |
| 7. End For; |
| 8. For all non-DSQ’s in parallel do |
| 9. Implement the fair policy using , the resources |
| not allocated as dominant; |
| 10. End For; |
The two queue systems execute in parallel, implementing the three steps of our fair policy described in Paragraph II.A. We get
. From Equation (
4), we get the maximum number of jobs for each user,
,
,
,
, and
and
jobs. From Equation (
5), the fair allocations for each job
(as the available resources for the dominant resource, CPU) are
= 28/21.08 = 1.33. Thus,
Thus,
will get four CPUs,
will get four CPUs,
will get five CPUs,
will get six CPUs and
will get nine CPUs. The total amount of resources allocated is 28 CPUs (step 5 of Algorithm 1); thus, no more resources are added to
(Step 6). The dominant server’s utilization
(queue system 1, queue 1) can be found from Equation (
7), and it is
. Thus the maximum rate at which the jobs are generated in
for CPU-intensive jobs is
19 jobs per time unit. Similarly, we repeat steps 3 to 6 of Algorithm 1, and find that the second queue system will allocate 12 memory units to
, 15 memory units to
, 17 memory units to
and 20 memory units to
. In total, 64 memory units will be allocated to user jobs having the memory as the dominant resource; thus, from step 6 of the algorithm, we add one more unit to
. That is, one more memory unit will be available for jobs whose dominant resource is not the memory. Thus,
. The parameters computed for the second queue system are shown in
Table 3. The dominant server’s utilization
(queue system 2, queue 1) can be found from Equation (
7), and it is
. Thus, the maximum rate at which the jobs are generated in
for memory-intensive jobs is
18.4 jobs per time unit.
Returning to the first queue system, it has to allocate memory and disk units to the users with CPUs as their dominant resource demanded. To allocate memory units, it needs to read the value of
(the number of memory units not allocated as dominant resources in the second queue system). These 16 units will be allocated using our fair allocation policy (lines 8 and 9 of Algorithm 1).
Table 4 shows the computed values. The jobs will be generated in
of the first queue system. The server’s utilization
(queue system 1, queue 2) can be found from Equation (
7), and it is
. Thus, the maximum rate at which the jobs are generated in
to allocate memory for CPU-intensive jobs is
19.7 jobs per time unit.
Returning to the second queue system, it has to allocate CPU and disk units to the users with memory as the dominant resource demanded. To allocate CPU units, the value of
needs to be read (the amount of CPU units not allocated as dominant resources in the first queue system). These 12 units will be allocated again using our fair allocation policy.
Table 5 shows the computed values. The jobs will be generated in
of the second queue system. The server’s utilization
(queue system 2, queue 2) can be found from Equation (
7), and it is
. Thus, the maximum rate at which the jobs are generated in
to allocate memory for CPU-intensive jobs is
19.7 jobs per time unit. Allocations in queues
and
are also performed in parallel.
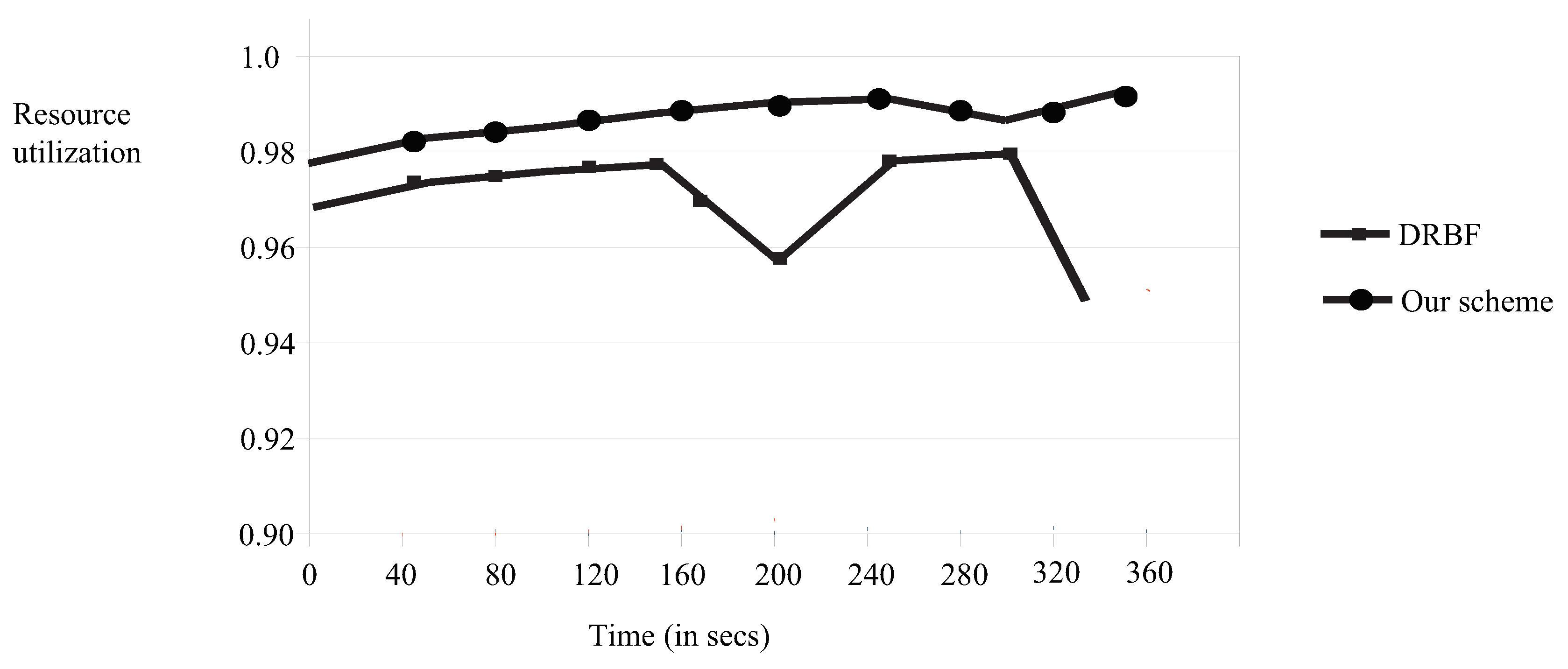
Finally, the two systems have to allocate disks to all users. The disk is not the dominant resource for any of the users. Disk allocation will be performed separately based on our fair policy. In total, 68 disk units have been requested by all users: 28 () from users whose dominant resource was the CPU and 40 () from users whose dominant resource was the memory. Intuitively, the values are 20 disk units for the first queue system and 30 for the second. As a result, users 1–5 get 1,4,4,5 and 6 disks respectively, from the first system and the system utilization is 0.957%. The maximum rate at which the jobs are generated in for the CPU-intensive jobs to which the disks are allocated is 19.15 jobs. Finally, users 6–9 get 6,7,7 and 9 disks respectively from the second system, and the system utilization is 0.925%. The maximum rate at which the jobs are generated in for the memory-intensive jobs to which the disks are allocated is 19.5 jobs.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}