
Improving Real-Time Performance of Micro-ROS with Priority-Driven Chain-Aware Scheduling

Abstract
:1. Introduction
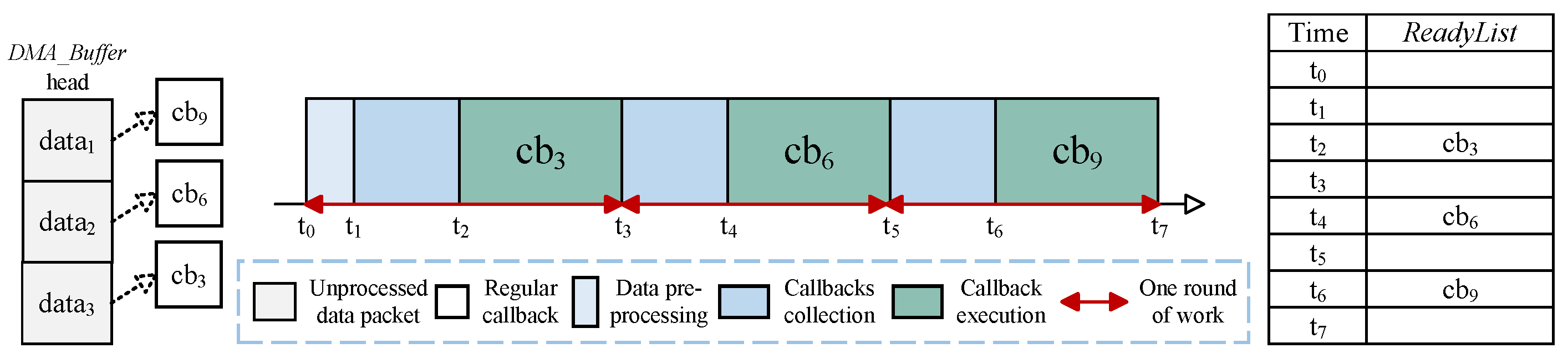
- Models of callback scheduling module and communication module in micro-ROS: Through detailed examination and analysis of the micro-ROS source code, we have discovered that the callback scheduling module implements a batch-based scheduling strategy. Moreover, data transmission within the communication module employs a sequential transmission strategy, and data reception adopts a FIFO-based data-processing strategy.
- Problems present in current micro-ROS designs: After thorough analysis and validation, we have identified three critical issues that severely impact the run-time predictability and efficiency of micro-ROS, stemming from unreasonable micro-ROS designs.
- Design principles of our proposed PoDS: Based on the micro-ROS architecture, we have designed and implemented a priority-driven chain-aware scheduling system named PoDS, which can effectively solve identified critical problems.
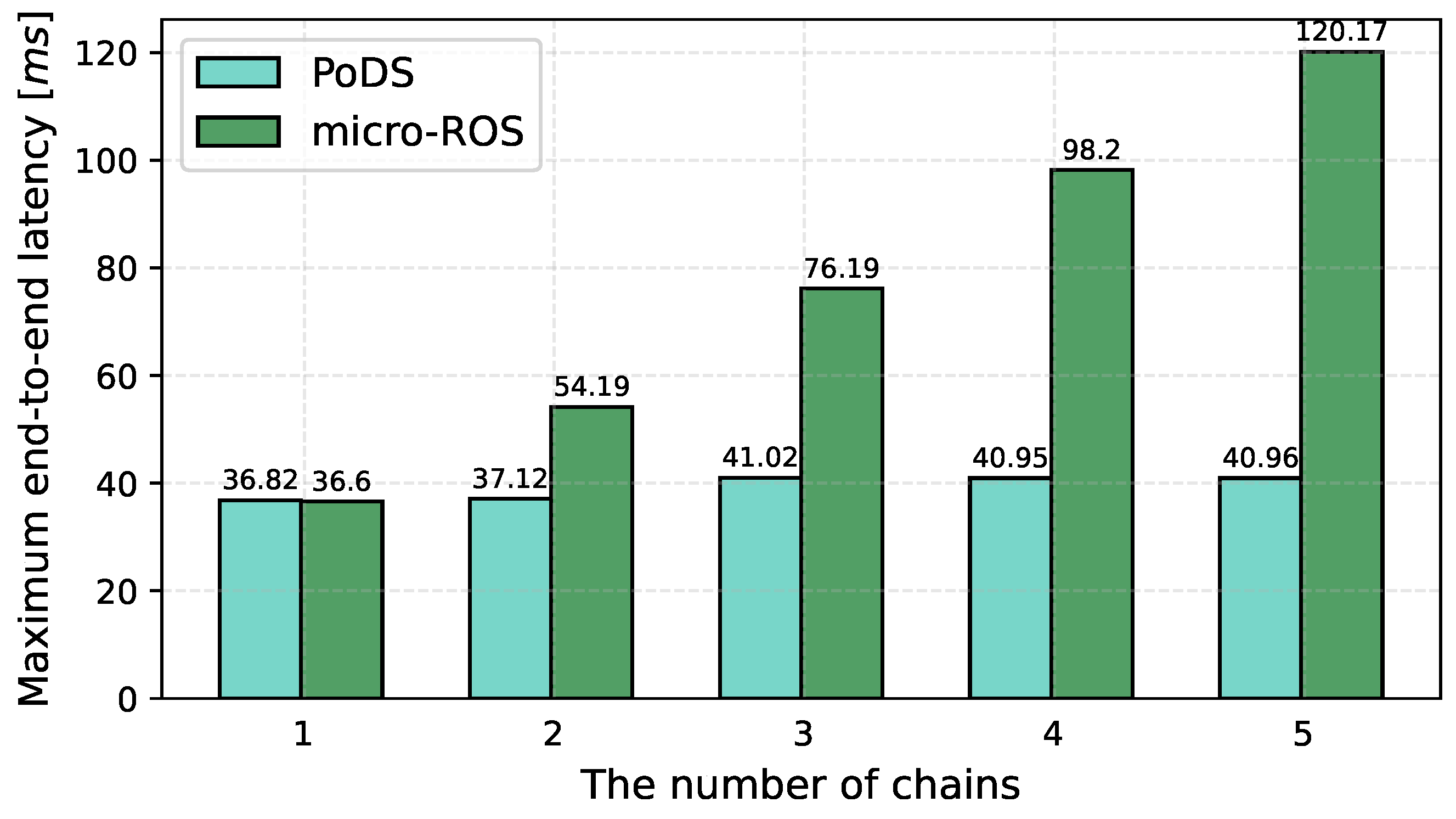
- Performance evaluation of PoDS and micro-ROS: We conducted a comprehensive series of experiments to evaluate and compare the real-time performance of our proposed PoDS with that of micro-ROS. The results demonstrate that our PoDS exhibits superior and more stable performance compared to micro-ROS.
2. Background
2.1. Micro-ROS Architecture
- Callback is the minimal schedulable execution entity in ROS 2 and micro-ROS. Micro-ROS provides four different types of callback, including timers, subscriptions, services, and clients. The timer callbacks are triggered periodically, while the regular callbacks are triggered by external events, such as receiving a related message.
- Chain essentially is a collection of callbacks implemented by application developers to meet specific requirements.
- Executor is a crucial factor influencing the real-time performance of micro-ROS, used to coordinate the execution order of callbacks with different priorities.
2.2. Callback Scheduling Model in Micro-ROS
2.3. Communication Model between Micro-ROS and ROS 2 Agent
2.3.1. Data Transmission
2.3.2. Data Reception
3. Motivation
3.1. Unpredictability in Callback Scheduling
3.2. Inefficiency and Unpredictability in Data Communication
3.2.1. Inefficiency in Data Transmission
3.2.2. Unpredictability in Data Reception
4. Overview
4.1. Design Goals and Challenges
4.2. PoDS Overview
5. Design
5.1. TIDE Executor
5.2. Priority-Based Data-Processing Mechanism
5.3. Communication Daemon
5.3.1. Parallel Transmission Handler
5.3.2. Interrupt-Based Data Reception Handler
6. Evaluation
6.1. Environment Setup
6.2. Experimental Results
6.2.1. Basic Characteristics
6.2.2. Performance under Reliable Communication
7. Related Work
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ROS Introduction. Available online: http://wiki.ros.org/ROS/Introduction/ (accessed on 24 March 2024).
- ROS Robots. Available online: https://robots.ros.org/ (accessed on 8 February 2024).
- Macenski, S.; Foote, T.; Gerkey, B.; Lalancette, C.; Woodall, W. Robot Operating System 2: Design, architecture, and uses in the wild. Sci. Robot. 2022, 7, eabm6074. [Google Scholar] [CrossRef] [PubMed]
- Belsare, K.; Rodriguez, A.C.; Sánchez, P.G.; Hierro, J.; Kołcon, T.; Lange, R.; Lütkebohle, I.; Malki, A.; Losa, J.M.; Melendez, F.; et al. Micro-ros. In Robot Operating System (ROS) The Complete Reference; Springer International Publishing: Cham, Switzerland, 2023; Volume 7, pp. 3–55. [Google Scholar]
- micro-ROS Puts ROS 2 on Microcontrollers. Available online: https://micro.ros.org/ (accessed on 13 February 2024).
- Li, B.; Ma, Z.; Zhao, Y. 2D Mapping of Mobile Robot Based on micro-ROS. In Proceedings of the 2022 4th International Symposium on Robotics & Intelligent Manufacturing Technology (ISRIMT 2022), Online, 23–25 September 2022; IOP Publishing: Bristol, UK, 2022; Volume 2402, p. 012030. [Google Scholar]
- Features and Architecture. Available online: https://micro.ros.org/docs/overview/features/ (accessed on 13 February 2024).
- Barry, R. FreeRTOS. Internet, Oct. 2008. Available online: https://www.freertos.org/RTOS.html (accessed on 1 January 1980).
- The Zephyr Project. Available online: https://www.zephyrproject.org/ (accessed on 24 March 2024).
- Apache NuttX. Available online: https://nuttx.apache.org/ (accessed on 21 February 2024).
- eProsima Micro XRCE-DDS. Available online: https://micro-xrce-dds.docs.eprosima.com/en/latest/ (accessed on 30 March 2024).
- Micro XRCE-DDS. Available online: https://micro.ros.org/docs/concepts/middleware/Micro_XRCE-DDS/ (accessed on 13 February 2024).
- Micro XRCE-DDS Memory Profiling. Available online: https://micro.ros.org/docs/concepts/middleware/memo_prof/ (accessed on 13 February 2024).
- Staschulat, J.; Lütkebohle, I.; Lange, R. The rclc executor: Domain-specific deterministic scheduling mechanisms for ros applications on microcontrollers: Work-in-progress. In Proceedings of the 2020 International Conference on Embedded Software (EMSOFT), Shanghai, China, 20–25 September 2020; pp. 18–19. [Google Scholar]
- rclc Executor. Available online: https://micro.ros.org/docs/concepts/client_library/execution_management/#rclc-executor (accessed on 13 February 2024).
- NUCLEO-F767ZI. Available online: https://www.st.com/en/evaluation-tools/nucleo-f767zi.html (accessed on 5 April 2024).
- common_msgs—ROS Wiki. Available online: https://wiki.ros.org/common_msgs (accessed on 21 April 2024).
- Wei, H.; Shao, Z.; Huang, Z.; Chen, R.; Guan, Y.; Tan, J.; Shao, Z. RT-ROS: A real-time ROS architecture on multi-core processors. Future Gener. Comput. Syst. 2016, 56, 171–178. [Google Scholar] [CrossRef]
- Saito, Y.; Sato, F.; Azumi, T.; Kato, S.; Nishio, N. Rosch: Real-time scheduling framework for ros. In Proceedings of the 2018 IEEE 24th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hakodate, Japan, 28–31 August 2018; pp. 52–58. [Google Scholar]
- Suzuki, Y.; Azumi, T.; Kato, S.; Nishio, N. Real-time ros extension on transparent cpu/gpu coordination mechanism. In Proceedings of the 2018 IEEE 21st International Symposium on Real-Time Distributed Computing (ISORC), Singapore, 29–31 May 2018; pp. 184–192. [Google Scholar]
- Saito, Y.; Azumi, T.; Kato, S.; Nishio, N. Priority and synchronization support for ROS. In Proceedings of the 2016 IEEE 4th International Conference on Cyber-Physical Systems, Networks, and Applications (CPSNA), Nagoya, Japan, 6–7 October 2016; pp. 77–82. [Google Scholar]
- Casini, D.; Blaß, T.; Lütkebohle, I.; Brandenburg, B. Response-time analysis of ROS 2 processing chains under reservation-based scheduling. In Proceedings of the 31st Euromicro Conference on Real-Time Systems, Stuttgart, Germany, 9–12 July 2019; pp. 1–23. [Google Scholar]
- Blaß, T.; Casini, D.; Bozhko, S.; Brandenburg, B.B. A ROS 2 response-time analysis exploiting starvation freedom and execution-time variance. In Proceedings of the 2021 IEEE Real-Time Systems Symposium (RTSS), Dortmund, Germany, 7–10 December 2021; pp. 41–53. [Google Scholar]
- Tang, Y.; Feng, Z.; Guan, N.; Jiang, X.; Lv, M.; Deng, Q.; Yi, W. Response time analysis and priority assignment of processing chains on ros2 executors. In Proceedings of the 2020 IEEE Real-Time Systems Symposium (RTSS), Houston, TX, USA, 1–4 December 2020; pp. 231–243. [Google Scholar]
- Jiang, X.; Ji, D.; Guan, N.; Li, R.; Tang, Y.; Wang, Y. Real-time scheduling and analysis of processing chains on multi-threaded executor in ros 2. In Proceedings of the 2022 IEEE Real-Time Systems Symposium (RTSS), Houston, TX, USA, 5–8 December 2022; pp. 27–39. [Google Scholar]
- Choi, H.; Xiang, Y.; Kim, H. PiCAS: New design of priority-driven chain-aware scheduling for ROS2. In Proceedings of the 2021 IEEE 27th Real-Time and Embedded Technology and Applications Symposium (RTAS), Nashville, TN, USA, 18–21 May 2021; pp. 251–263. [Google Scholar]
- Sobhani, H.; Choi, H.; Kim, H. Timing Analysis and Priority-driven Enhancements of ROS 2 Multi-threaded Executors. In Proceedings of the 2023 IEEE 29th Real-Time and Embedded Technology and Applications Symposium (RTAS), San Antonio, TX, USA, 9–12 May 2023; pp. 106–118. [Google Scholar]
- Liu, S.; Jiang, X.; Guan, N.; Wang, Z.; Yu, M.; Yi, W. RTeX: An Efficient and Timing-Predictable Multi-threaded Executor for ROS 2. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024; Early Access. [Google Scholar]
- Staschulat, J.; Lange, R.; Dasari, D.N. Budget-based real-time executor for micro-ROS. arXiv 2021, arXiv:2105.05590. [Google Scholar]
- Bappanadu, S.R. Modeling and Timing Analysis of Micro-ROS Application on an Off-Road Vehicle Control Unit. Master’s Thesis, University of Stuttgart, Stuttgart, Germany, 2022. [Google Scholar]
- Mudalige, N.D.; Zhura, I.; Babataev, I.; Nazarova, E.; Fedoseev, A.; Tsetserukou, D. Hyperdog: An open-source quadruped robot platform based on ros2 and micro-ros. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Prague, Czech Republic, 9–12 October 2022; pp. 436–441. [Google Scholar]
- Nguyen, P. Micro-Ros for Mobile Robotics Systems. 2022. Available online: https://mdh.diva-portal.org/smash/record.jsf?pid=diva2%3A1670378&dswid=7005 (accessed on 23 April 2024).
- Takase, H.; Mori, T.; Takagi, K.; Takagi, N. mROS: A lightweight runtime environment for robot software components onto embedded devices. In Proceedings of the 10th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, Nagasaki, Japan, 6–7 June 2019; pp. 1–6. [Google Scholar]
- lwIP—A Lightweight TCP/IP Stack—Summary. Available online: https://savannah.nongnu.org/projects/lwip/ (accessed on 19 April 2024).
- mROS 2. Available online: https://github.com/mROS-base/mros2 (accessed on 19 April 2024).
- Kampmann, A.; Wüstenberg, A.; Alrifaee, B.; Kowalewski, S. A portable implementation of the real-time publish-subscribe protocol for microcontrollers in distributed robotic applications. In Proceedings of the 2019 IEEE intelligent transportation systems conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 443–448. [Google Scholar]
- embeddedRTPS. Available online: https://github.com/embedded-software-laboratory/embeddedRTPS (accessed on 19 April 2024).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Successful Probability | 0 | 20% | 40% | 60% | 80% | 100% | |
|---|---|---|---|---|---|---|---|
| micro-ROS [ms] | MIN | 114.27 | 84.11 | 84.34 | 84.34 | 84.01 | 84.16 |
| AVE | 115.09 | 107.44 | 102.96 | 96.87 | 91.15 | 85.03 | |
| MAX | 115.96 | 115.81 | 116.19 | 116.54 | 115.78 | 85.80 | |
| STD | 0.34 | 10.79 | 10.73 | 14.70 | 12.03 | 0.33 | |
| PoDS [ms] | MIN | 48.31 | 40.94 | 40.94 | 40.94 | 40.94 | 41.06 |
| AVE | 48.97 | 47.04 | 45.59 | 43.97 | 42.48 | 41.07 | |
| MAX | 49.70 | 49.42 | 49.95 | 49.77 | 49.67 | 41.09 | |
| STD | 0.30 | 3.10 | 3.84 | 3.71 | 3.10 | 0.01 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Liu, S.; Ji, D.; Yi, W. Improving Real-Time Performance of Micro-ROS with Priority-Driven Chain-Aware Scheduling. Electronics 2024, 13, 1658. https://doi.org/10.3390/electronics13091658
Wang Z, Liu S, Ji D, Yi W. Improving Real-Time Performance of Micro-ROS with Priority-Driven Chain-Aware Scheduling. Electronics. 2024; 13(9):1658. https://doi.org/10.3390/electronics13091658
Chicago/Turabian StyleWang, Zilong, Songran Liu, Dong Ji, and Wang Yi. 2024. "Improving Real-Time Performance of Micro-ROS with Priority-Driven Chain-Aware Scheduling" Electronics 13, no. 9: 1658. https://doi.org/10.3390/electronics13091658