4.1. Data Preprocessing
In this paper, we used the EmoDB and RAVDESS datasets. For our experiments, nested emotions such as happiness, anger, sadness, fear, neutrality, and disgust were used from both the EmoDB and RAVDESS datasets. EmoDB has a sampling rate of 16 kHz and RAVDESS has a sampling rate of 48 kHz, so both datasets were resampled to 22,025 Hz.
To ensure consistent conditions across the datasets, we adjusted the length of the emotion speech samples by padding shorter samples to match the length of the longest sample, so that all data was 10 s long, and we grouped and reorganized the datasets according to each emotion.
Table 2 shows the emotion data information.
In this paper, we also considered the utilization of diffusion by treating speech like an image [
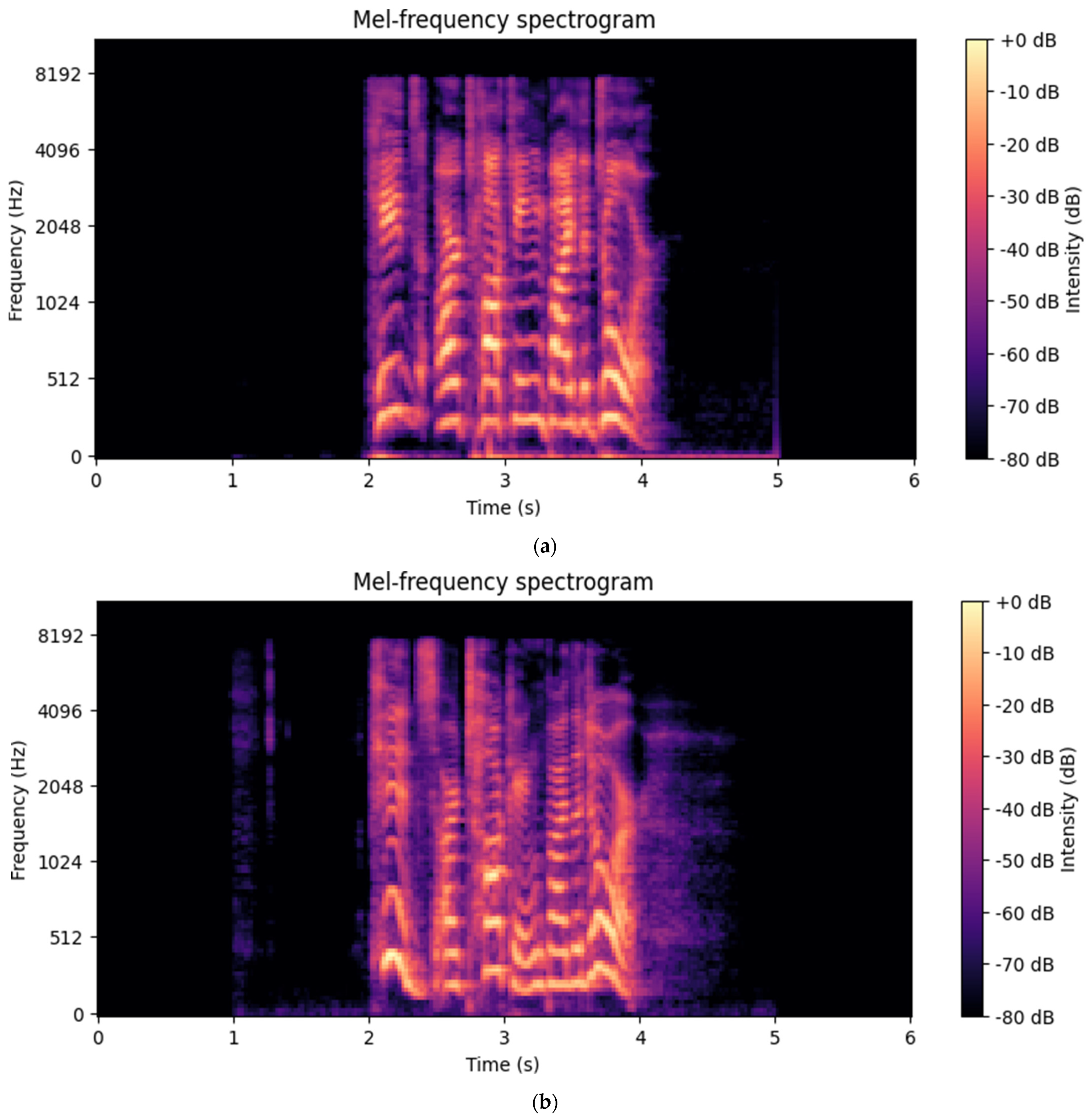
22]. Therefore, all the speech data were converted into mel-spectrograms using Python’s librosa library. The reason why we do not detect utterance segments in this process is that we use mel-spectrograms like images, where noise is injected during the diffusion and inversion process and subsequently removed. This way, the firing part of the image is reconstructed according to the features of the original data, while the padded part, which has no mel-spectrogram image, is not reconstructed. This approach justified bypassing the firing part. To avoid the loss of temporal information in the data, we did not use the Fast Fourier Transform (FFT), but rather the Short Time Fourier Transform (STFT) during the conversion. As a result, the emotional speech was converted into a mel-spectrogram using the STFT, and after several iterations of parameter tuning, considering the overall length and sampling rate of the WAV file, we chose a hop length of 256 and a window size of 1024 for the STFT [
23]. The converted mel-spectrograms were then subjected to Z-score normalization for standardization [
24].
4.2. Speech Emotion Recognition (SER)
In this study, we used speech emotion recognition in two steps [
25]. First, emotion embeddings were utilized to generate emotion information for typical utterances. Mel-spectrograms containing emotion information were used as input data, and the minibatch technique was used to reduce the amount of computation during the training process. The model was constructed using Pytorch, based on Python, and the model was implemented using the ResNet-50 model, based on CNN specialized in feature extraction and classification. The labels mapped to the data were created by integer encoding of sentiment information followed by one-hot encoding. The training data and validation data were divided 8:2 for training, Adam was used as the optimization function, the learning rate was set to 1 × 10
−4, the CrossEntropyLoss function was used as the loss function, and the Epoch was set to 800 [
26,
27]. After training, we measured performance based on accuracy and F1 score for each label prediction and used an emotion classification model with a classification performance of 98.31% and an F1 score of 0.9831. We used the trained model in inference mode, where the output is an embedding vector containing emotion information rather than classification results, and then combined it with the utterance-style vector to perform emotion embedding.
Table 3 shows the parameters of the emotion recognition model for emotion embedding, and
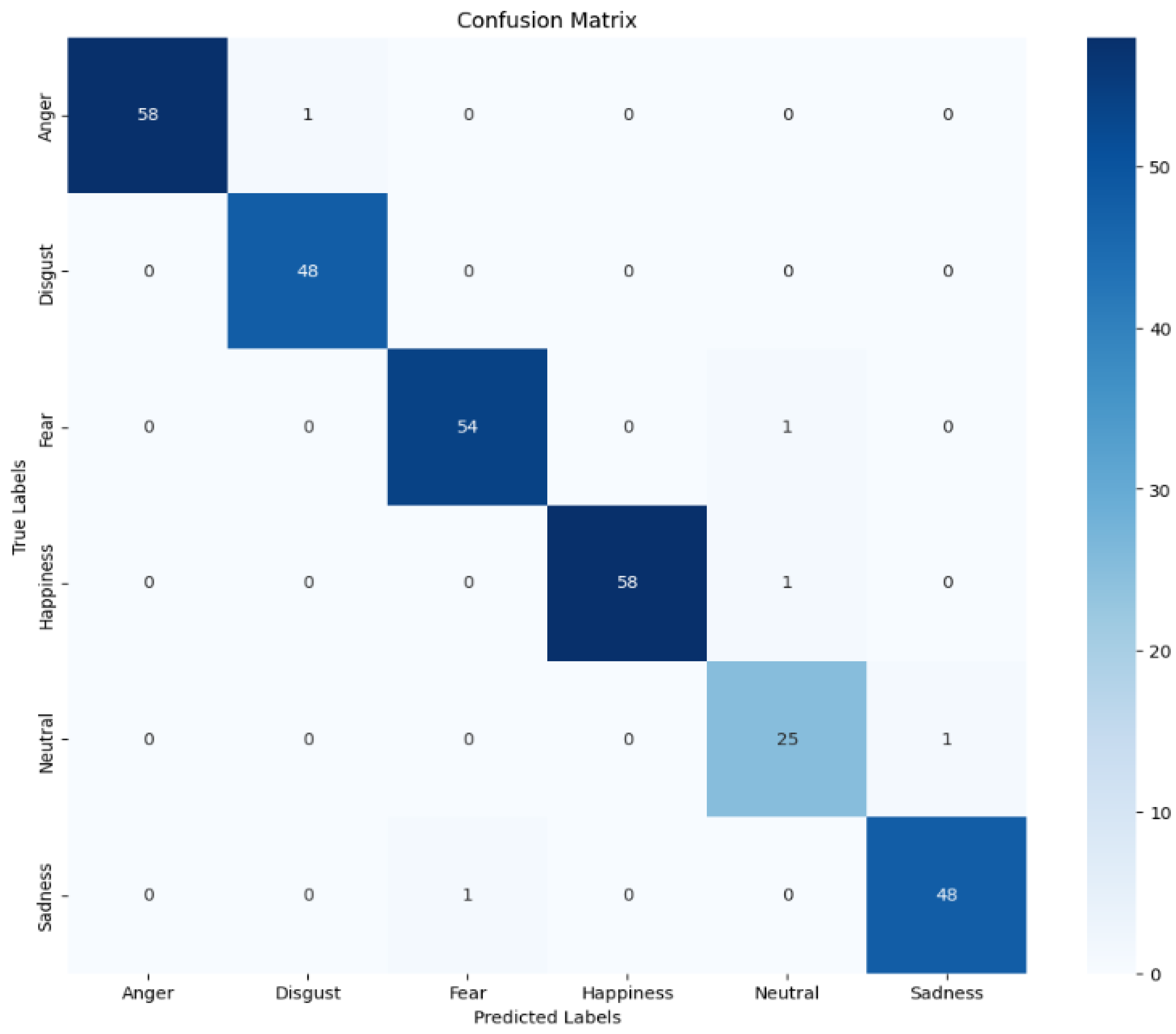
Figure 1 shows the confusion matrix of the spoken emotion recognition model.
We used the generated mel-spectrograms to validate the emotion feature enrichment. We compared the input EmoDB and RAVDESS data with the generated data based on the accuracy of the confusion matrix [
28].
4.3. Diffusion Models with Mel-Spectrograms
In this paper, we utilized a diffusion model to improve the quality of emotional speech data. The diffusion model is a generative AI model that generates data based on the user’s conditional input, input data, and trained data. The generation process is the process of injecting and extracting noise and producing the results requested by the user. It is mainly used in video, and we used mel-spectrograms to generate speech via a diffusion model in terms of signals like video [
14].
First, we embedded the utterance. Speech embedding refits data that are not sampled at 22,025 Hz, normalizes the wav, locates the start of the speech, and includes information about the start and end of the speech. It creates a mel-spectrogram for the input wav and normalizes it to prepare the mel-spectrogram for use as input data. The model also uses the mel-spectrogram obtained from the original emotional speech as one of the input data items, the emotion vector.
To solve the memory problem in training the model, we used mel-spectrogram resizing and a batch-based training process. The model is built on Python-based Pytorch and uses a CNN and attention-based encoder to extract features from the input mel-spectrograms. During this process, the utterance style of the mel-spectrogram was extracted, and the attention layer was used in each ResNet block to further focus on the noteworthy features. The second half of the diffusion model, the decoder, was then trained. The decoder used trigonometric and sequential functions to account for temporal information about the data, and the ResNet-based model structure was used to learn based on the features of the data. When using ResNet, we added temporal embeddings and emotion embeddings to focus on information about utterance and emotion and used a linear attention mechanism to focus more on information such as emotion, time, and intonation [
29].
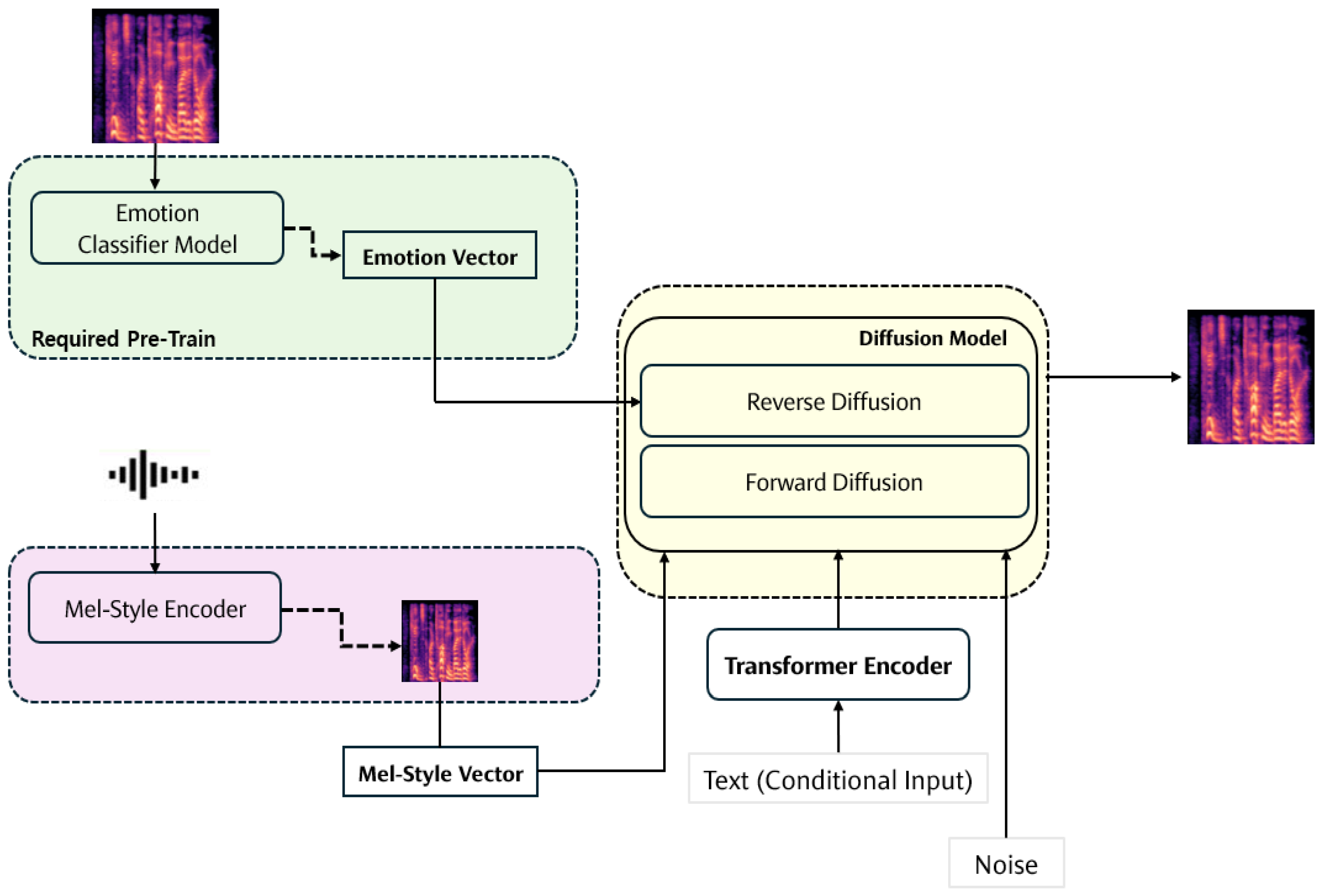
Table 4 shows the overall model design structure of the diffusion model for emotional speech generation.
The structure of the emotional speech generation model implemented in this paper is shown in
Figure 2 below.
The proposed method in this paper focuses on the augmented data containing more emotions, which is an important point in related works. It can be seen that the proposed method focuses more on the augmentation of the emotional utterance dataset than the emotional speech utterance, and we note that it is very difficult to obtain good quality data in this process, because of limitations in the emotional utterance dataset for emotion-related learning of artificial intelligence. From this perspective, the authors believe it will be helpful for future emotion-related research if the dataset is augmented with more emotions.
The diffusion model-based emotion synthesis model proposed in this paper is divided into two styles [
25].
The first is the emotion embedding module. The emotion embedding module requires a pre-trained emotion recognition model as mentioned above and extracts the emotion vector inferred from the emotion recognition model. It is confirmed that if the diffusion model is used without emotion embedding or in the learning process, as in [
10,
13], relatively little consideration is given to emotions when data augmentation is performed. Therefore, in [
11,
12], emotion embedding is used to extract emotion information from the emotion data to be used as training data, and then emotion embedding is performed in the learning process, such as emotion labels.
The second module is the mel-style embedding module, which focuses on utterance information. It utilizes the mel-spectrogram as training data to extract utterance information by emotion. In this paper, we consider using mel-spectrograms as images and use the mel-style embedding module to learn the progression structure, shape, and features of mel-spectrograms. In this way, emotion information can be embedded in the style of each emotion-specific mel-spectrogram to augment new emotional utterance data using a diffusion model, and it is expected that more emotion data will be augmented.
Since this paper focuses on augmenting emotional utterance data with more emotions, we evaluated the recognition rate of each emotion with an emotion recognition model, and since we use mel-spectrograms to do this, we stopped the augmentation step using the diffusion model at the mel-spectrogram.
The proposed method in this paper simplifies the emotion synthesis method into three steps: emotion, utterance information, and generation and purification, which enables the augmentation of emotional utterance data with a small amount of computing power and computation. In addition, it has the advantage of freely obtaining mel-spectrograms that can be utilized as speech features by adding conditional inputs from users to the trained model without having to spend a lot of time and money on data collection.






{kind=link}
{kind=link}
{kind=link}