
An Image Retrieval Method for Lunar Complex Craters Integrating Visual and Depth Features


Abstract
:1. Introduction
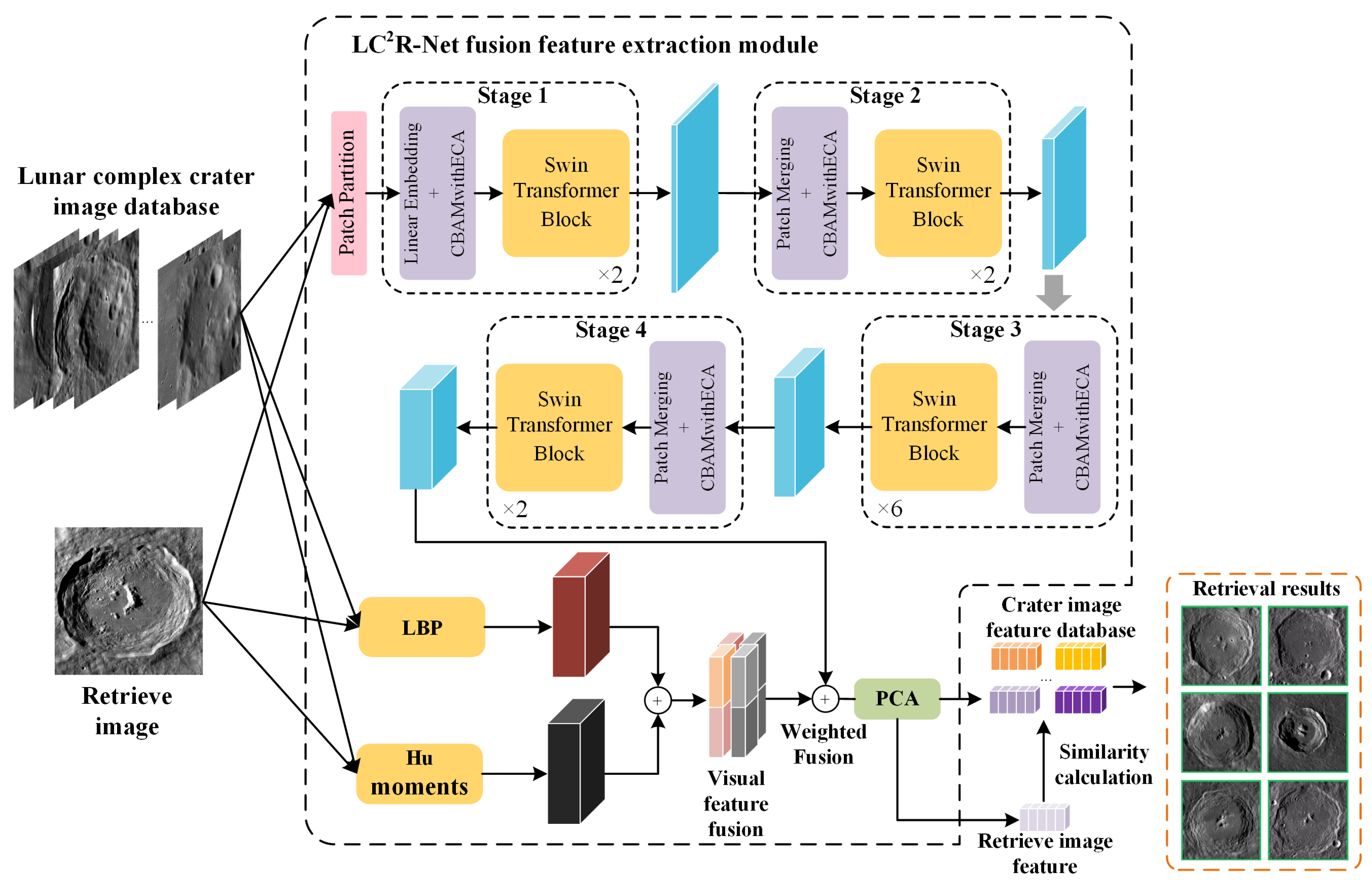
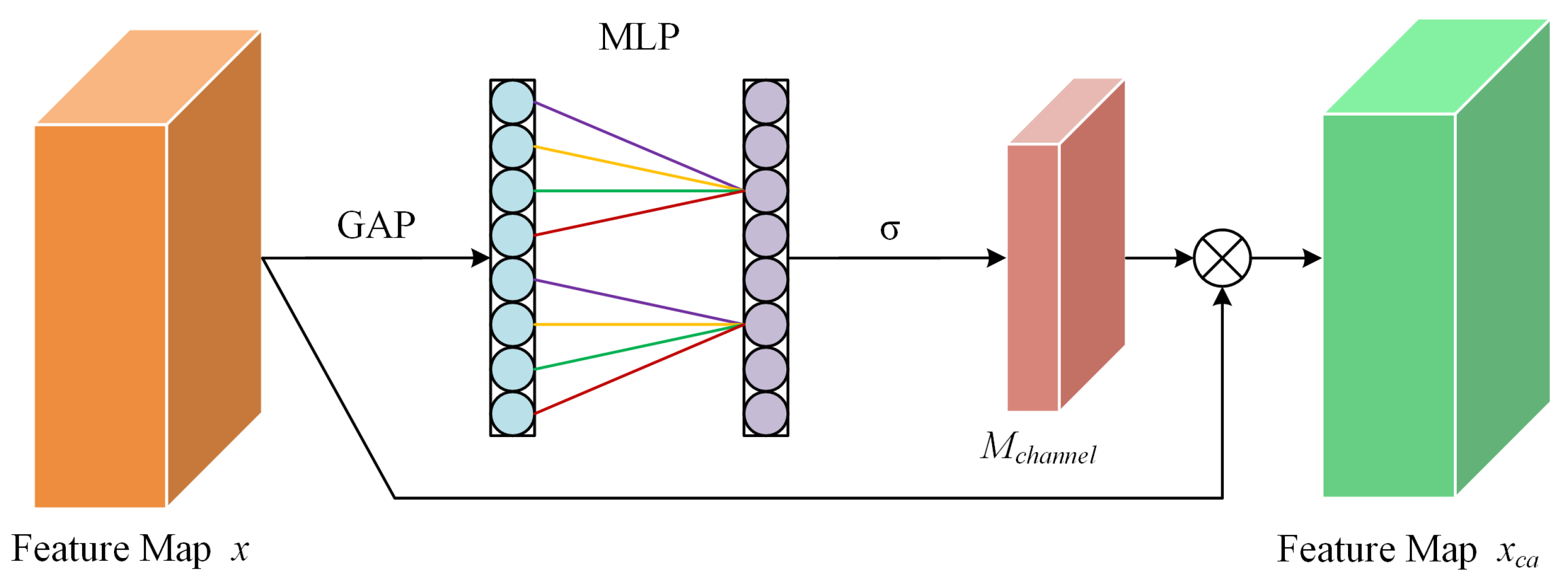
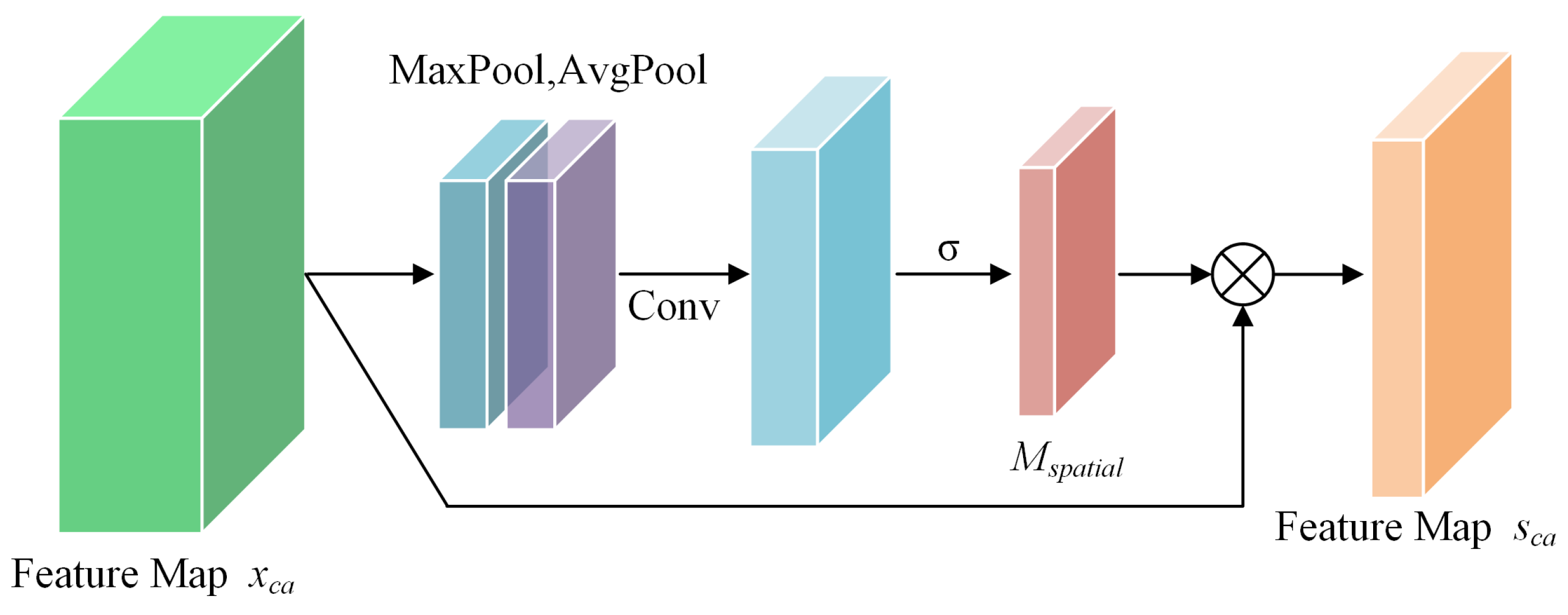
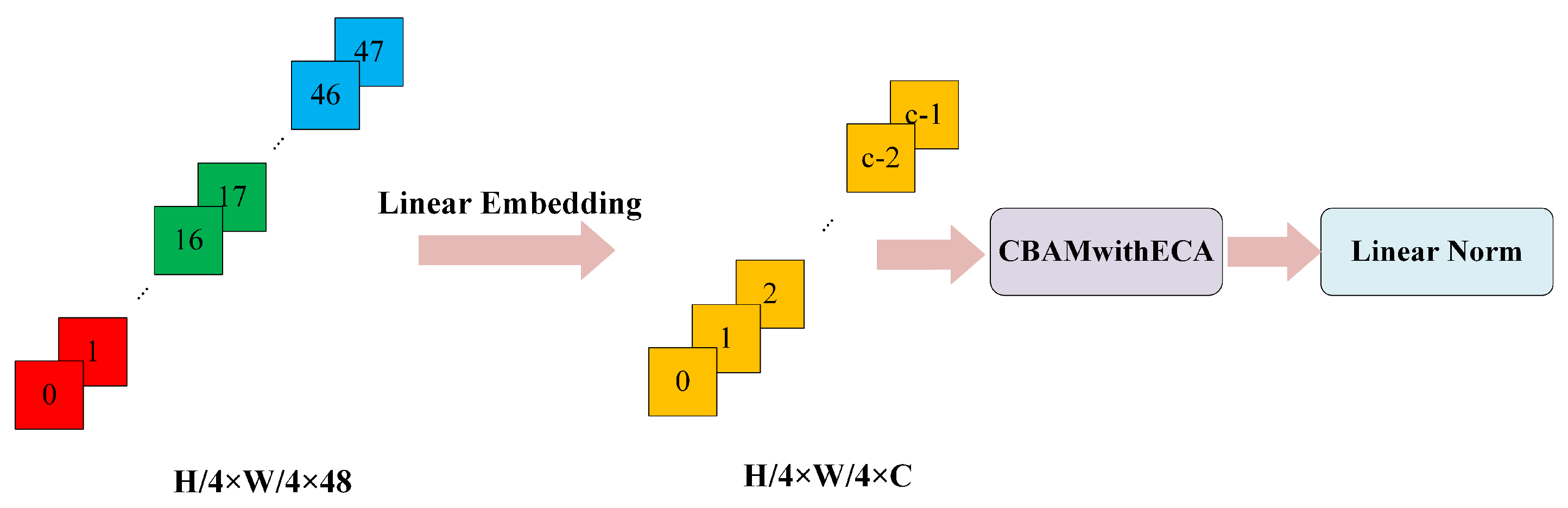
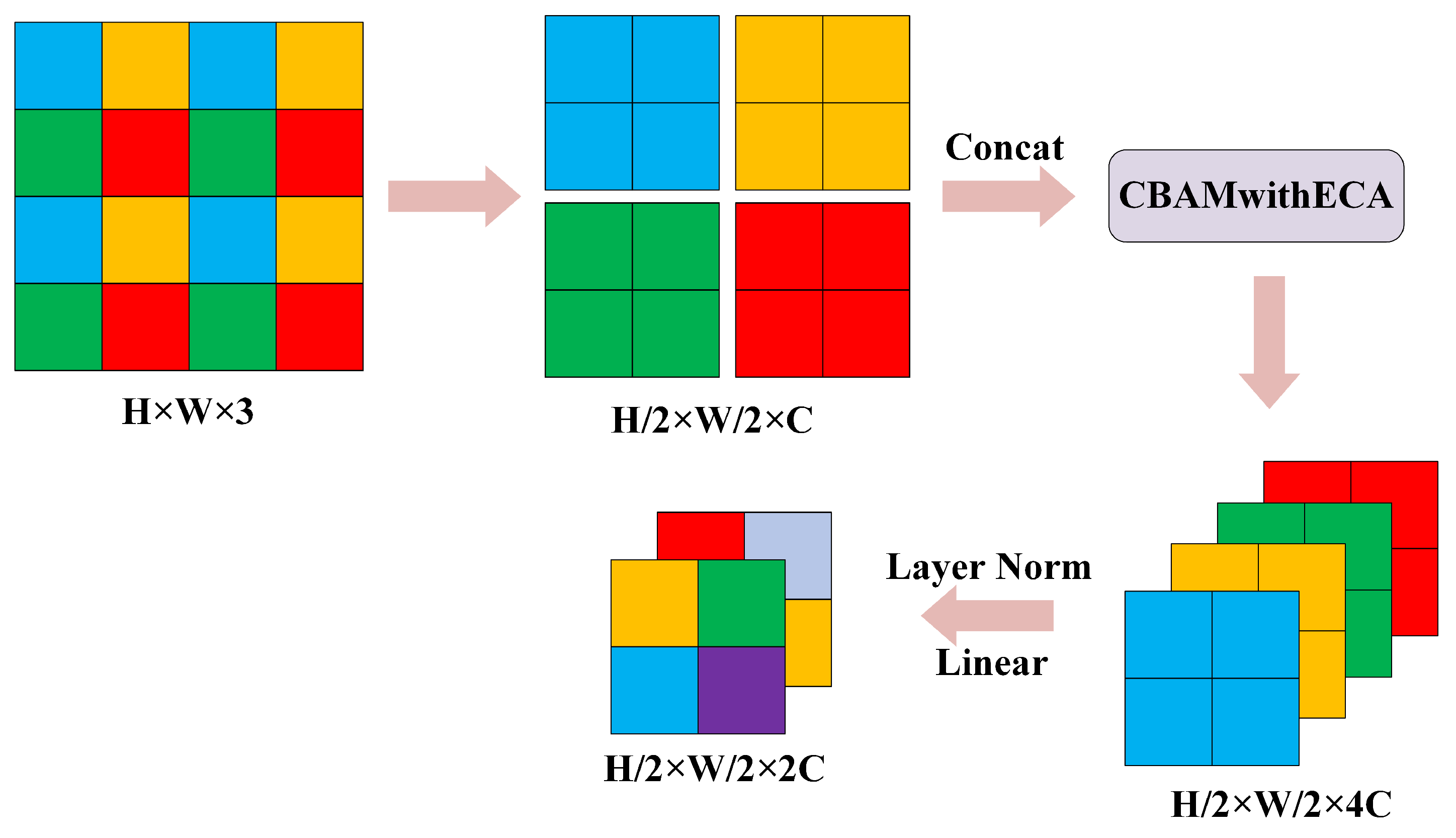
- The Swin Transformer is utilized as the feature extraction structure, and the CBAMwithECA module is integrated into the linear embedding and patch merging modules. Through the attention mechanism, the channel and spatial relevance of features are enhanced, allowing for a comprehensive capture of the details and structural information within images. This enhancement improves the model’s capability to recognize and extract image features. It directs the model’s focus toward the global context, elevating the perceptibility of key features while concurrently suppressing less important features and noise information.
- By integrating visual features (texture features, shape features) with deep features, we balance the contribution of different features through a weighted approach, emphasizing important features during the fusion process. Furthermore, we apply PCA to condense the dimensionality of the integrated feature set. This process not only trims down the number of feature dimensions but also amplifies the retrieval process’s swiftness and effectiveness.
- Within the network’s training framework, we integrate a triplet loss function coupled with a strategy for mining difficult negative examples. This approach is designed to prompt the network to cultivate features with greater discrimination. By utilizing triplet loss, we optimize the embedded space, ensuring that vectors of akin images are positioned in closer proximity, whereas those of non-akin images are segregated, thereby markedly boosting the precision of our retrieval system.
2. Related Works
2.1. Methods Based on Traditional Features
2.2. Methods Based on Deep Features
2.3. Methods Based on Metric Learning
3. Proposed Method
3.1. Visual Feature Extraction
3.2. Deep Feature Extraction
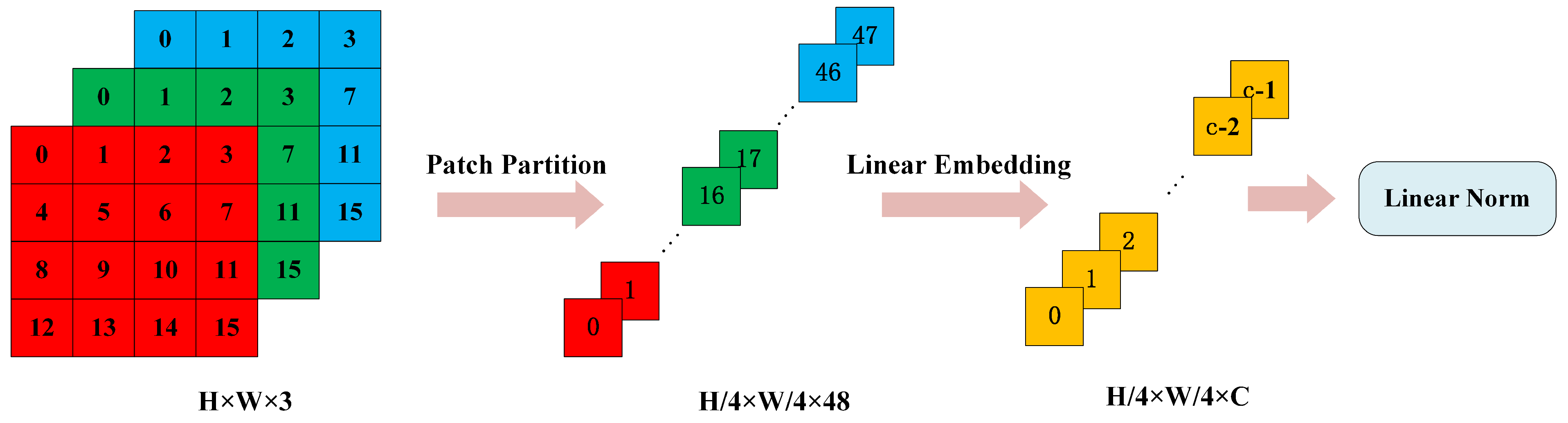
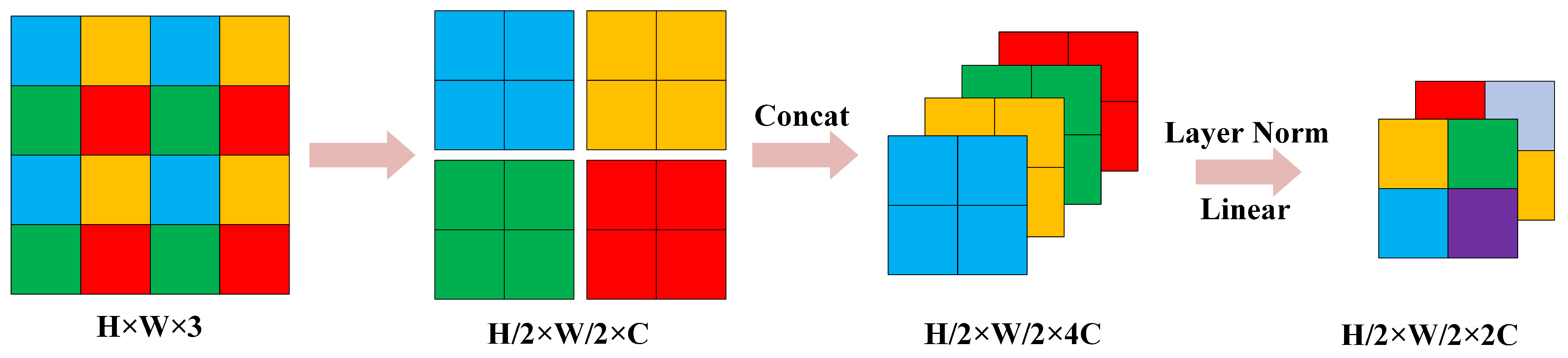
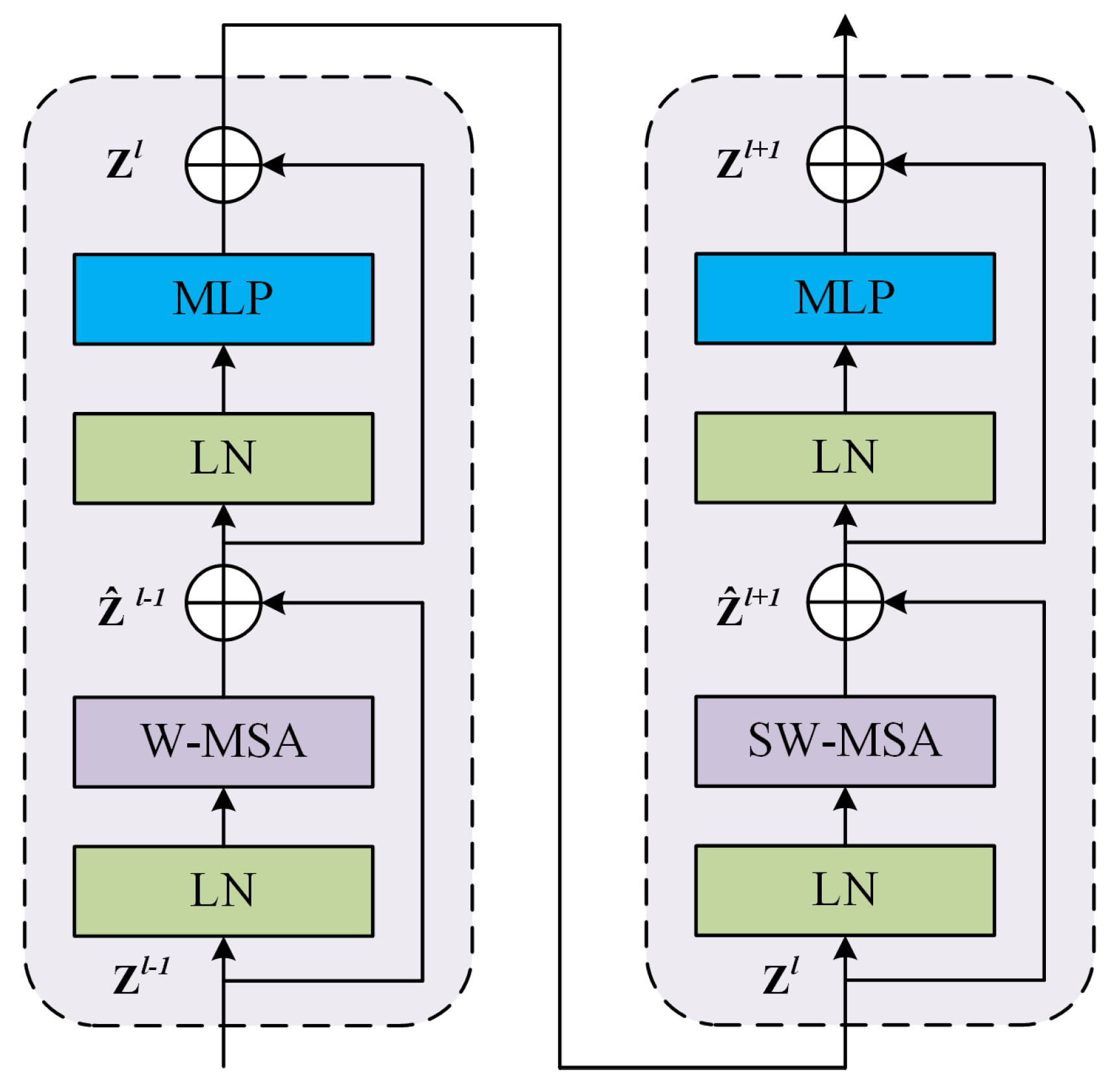
3.2.1. Backbone: Swin Transformer
- Patch Partition
- 2.
- Patch Merging
- 3.
- Swin Transformer Block
3.2.2. CBAMwithECA Attention Module
3.2.3. Loss Function
3.3. Feature Fusion and Retrieval
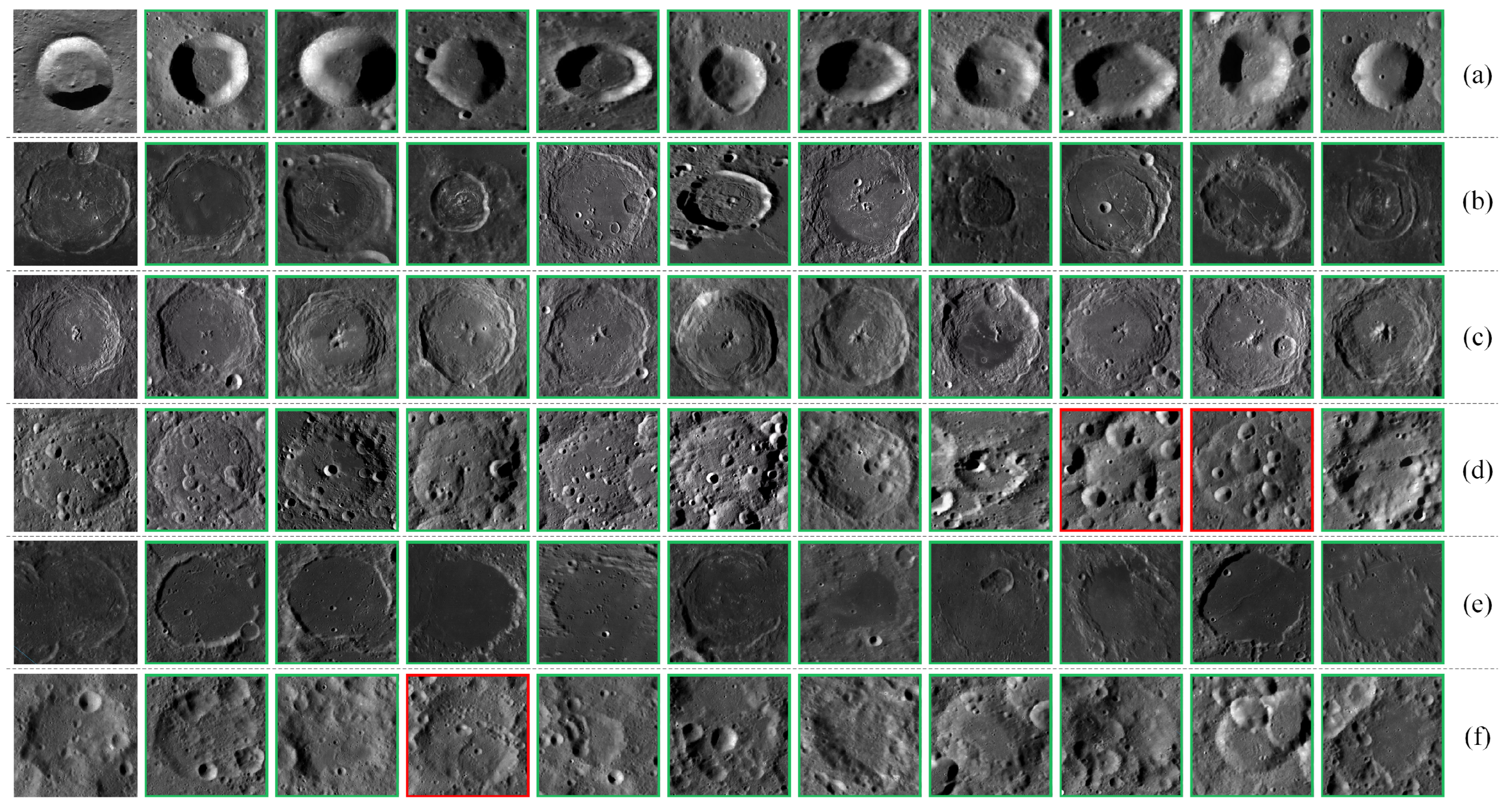
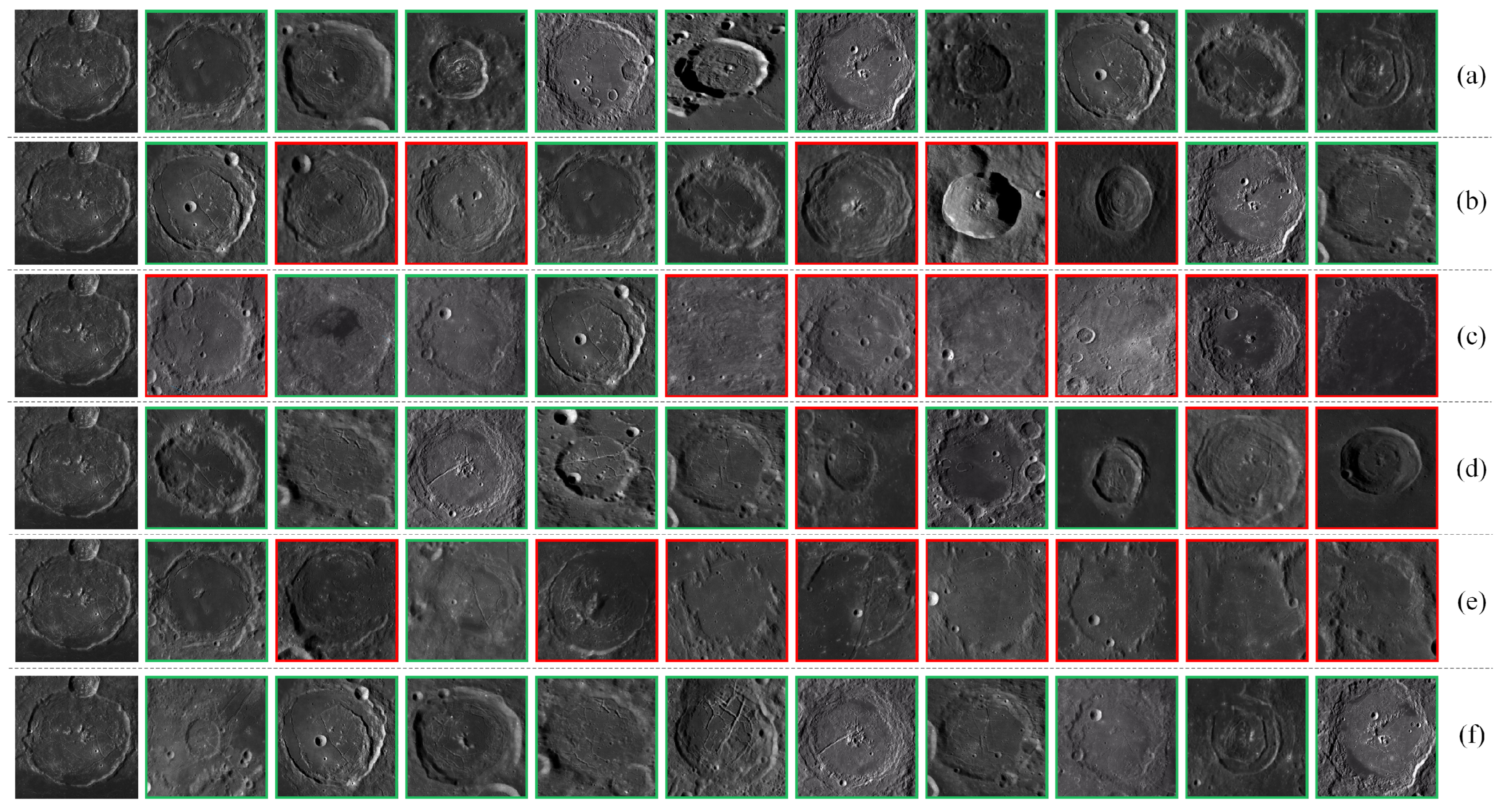
4. Lunar Complex Crater Dataset
5. Experiments and Analysis
5.1. Implementation Details
5.1.1. Experimental Setup
5.1.2. Evaluation Metrics
- Mean Average Precision ()
- 2.
- Average Normalized Modified Retrieval Rank ()
- 3.
- Retrieval Time
5.2. Comparison of LC2R-Net with Other Methods
5.3. Ablation Study




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP/% | ANMRR |
|---|---|---|
| Swin-T | 83.01 | 0.0755 |
| Swin-T + CBAMwithECA | 83.65 | 0.0725 |
| 83.75 | 0.0721 |
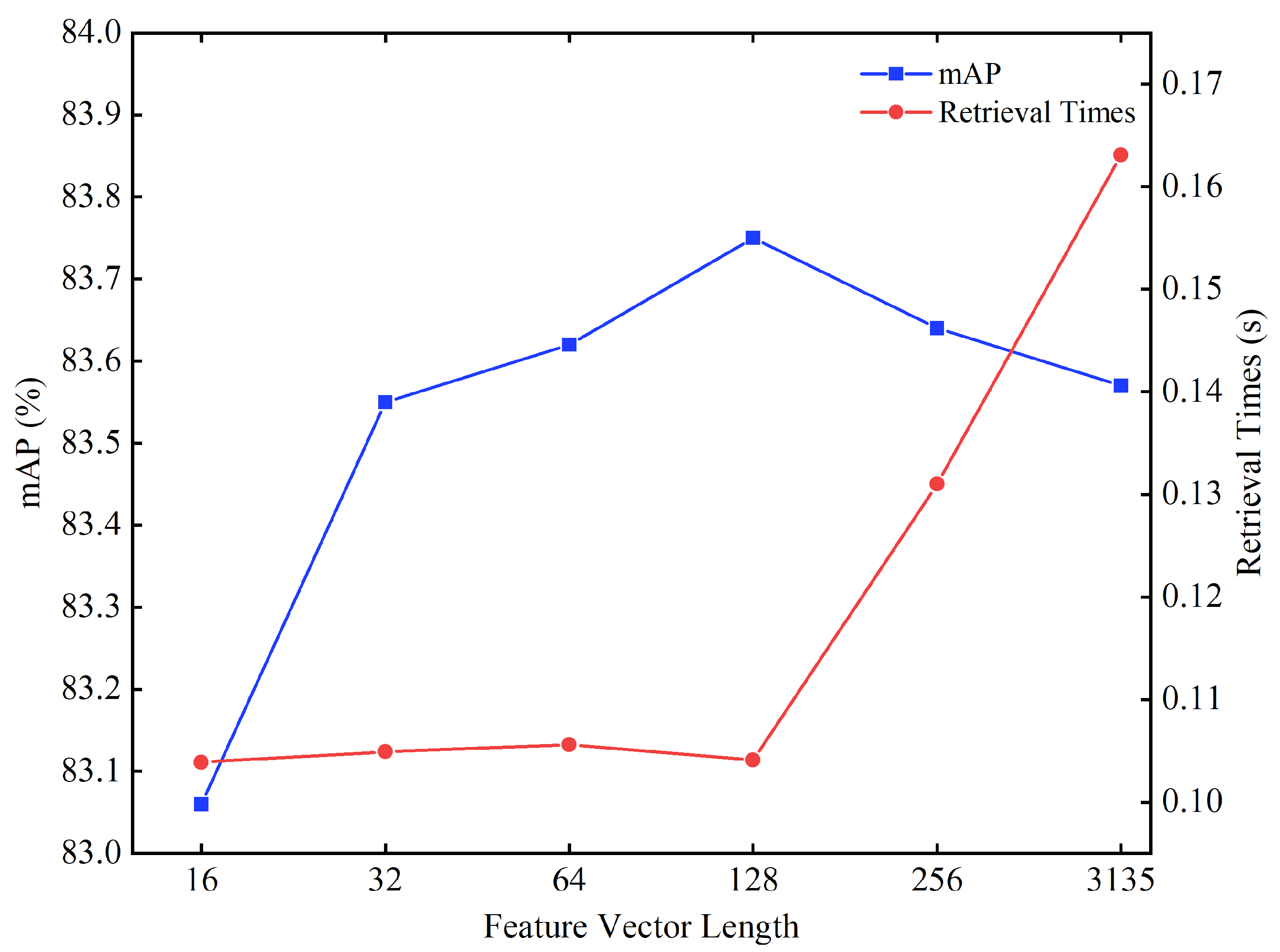
5.4. Parametric Analyses
5.5. Comparison of Retrieval Time
5.6. Impact of PCA Dimensionality Reduction on Retrieval Accuracy
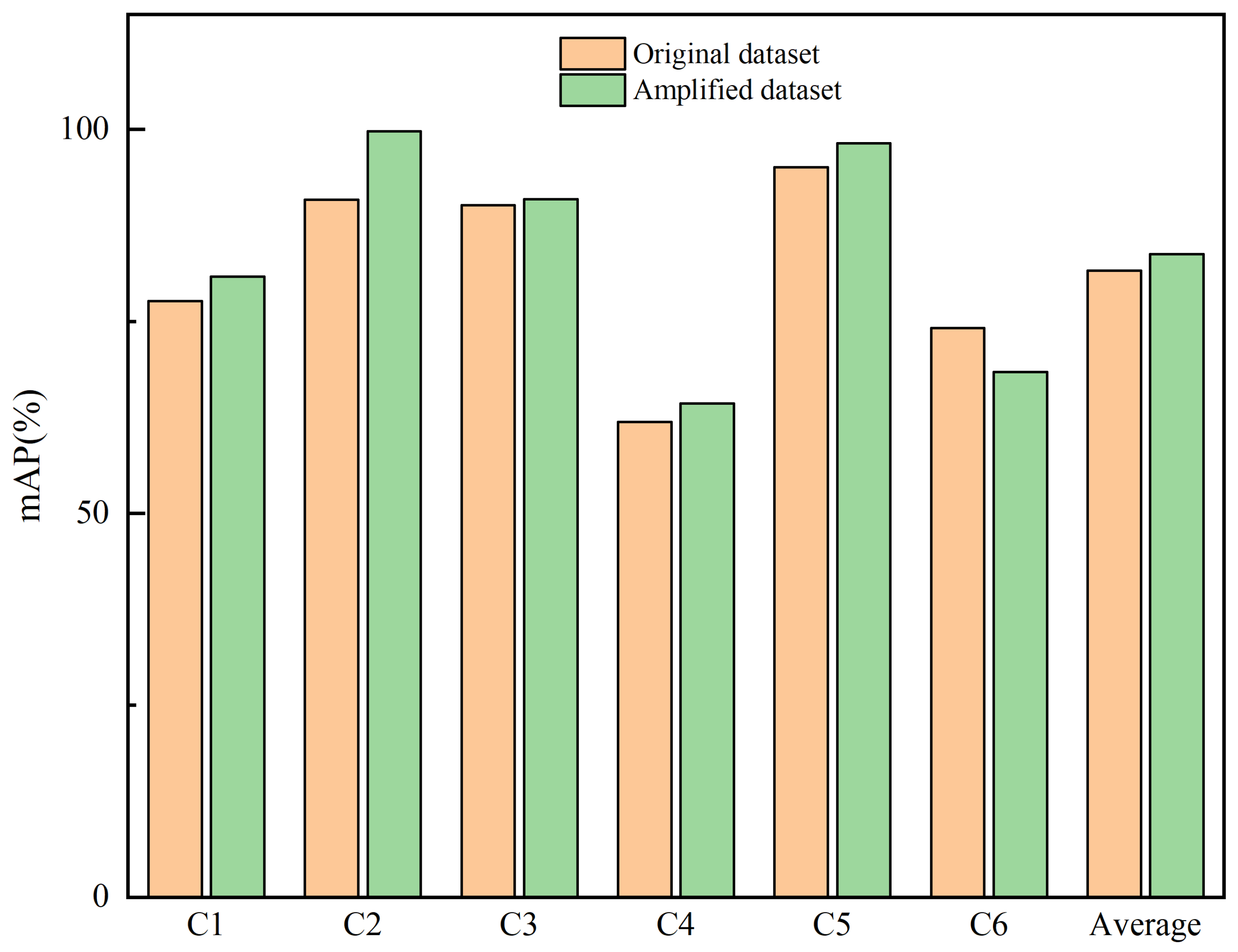
5.7. The Impact of Data Augmentation on Retrieval Accuracy
5.8. Further Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hartmann, W.K. Lunar cratering chronology. Icarus 1970, 13, 299–301. [Google Scholar] [CrossRef]
- Ryder, G. Mass flux in the ancient Earth-Moon system and benign implications for the origin of life on Earth. J. Geophys. Res. Planets 2002, 107, 6–11. [Google Scholar] [CrossRef]
- Chapman, C.R.; Cohen, B.A.; Grinspoon, D.H. What are the real constraints on the existence and magnitude of the late heavy bombardment? Icarus 2007, 189, 233–245. [Google Scholar] [CrossRef]
- Bottke, W.F.; Norman, M.D. The late heavy bombardment. Annu. Rev. Earth Planet. Sci. 2017, 45, 619–647. [Google Scholar] [CrossRef]
- Chen, M.; Lin, H.; Wen, Y.; He, L.; Hu, M. Sino-VirtualMoon: A 3D web platform using Chang’e-1 data for collaborative research. Planet. Space Sci. 2012, 65, 130–136. [Google Scholar] [CrossRef]
- Di, K.; Li, W.; Yue, Z.; Sun, Y.; Liu, Y. A machine learning approach to crater detection from topographic data. Adv. Space Res. 2014, 54, 2419–2429. [Google Scholar] [CrossRef]
- Sawabe, Y.; Matsunaga, T.; Rokugawa, S. Automated detection and classification of lunar craters using multiple approaches. Adv. Space Res. 2006, 37, 21–27. [Google Scholar] [CrossRef]
- Vijayan, S.; Vani, K.; Sanjeevi, S. Crater detection, classification and contextual information extraction in lunar images using a novel algorithm. Icarus 2013, 226, 798–815. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, H.; Bruzzone, L.; Benediktsson, J.A.; Liang, Y.; Liu, B.; Zeng, X.; Guan, R.; Li, C.; Ouyang, Z. Lunar impact crater identification and age estimation with Chang’E data by deep and transfer learning. Nat. Commun. 2020, 11, 6358. [Google Scholar] [CrossRef]
- Meyer, C.; Deans, M. Content based retrieval of images for planetary exploration. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 1377–1382. [Google Scholar]
- Chen, H.Z.; Jing, N.; Wang, J.; Chen, Y.G.; Chen, L. A novel saliency detection method for lunar remote sensing images. IEEE Geosci. Remote Sens. Lett. 2013, 11, 24–28. [Google Scholar] [CrossRef]
- Hua, K.A.; Shaykhian, G.A.; Beil, R.J.; Akpinar, K.; Martin, K.A. Saliency-based CBIR system for exploring lunar surface imagery. In Proceedings of the 2014 ASEE Annual Conference & Exposition, Indianapolis, Indiana, USA, 15–18 June 2014; pp. 24–1065. [Google Scholar]
- Tombe, R.; Viriri, S. Adaptive deep co-occurrence feature learning based on classifier-fusion for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 155–164. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, T.; Liu, C.; Zhang, L. An effective classification method for hyperspectral image with very high resolution based on encoder–decoder architecture. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1509–1519. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, X.; Yuan, Y.; Lu, X. Attribute-cooperated convolutional neural network for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8358–8371. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 56, 950–965. [Google Scholar] [CrossRef]
- Napoletano, P. Visual descriptors for content-based retrieval of remote-sensing images. Int. J. Remote Sens. 2018, 39, 1343–1376. [Google Scholar] [CrossRef]
- Ye, F.; Xiao, H.; Zhao, X.; Dong, M.; Luo, W.; Min, W. Remote sensing image retrieval using convolutional neural network features and weighted distance. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1535–1539. [Google Scholar] [CrossRef]
- Yan, K.; Wang, Y.; Liang, D.; Huang, T.; Tian, Y. Cnn vs. sift for image retrieval: Alternative or complementary? In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 407–411. [Google Scholar]
- Cheng, Q.; Shao, K.; Li, C.; Li, S.; Li, J.; Shao, Z. A distributed system architecture for high-resolution remote sensing image retrieval by combining deep and traditional features. In Proceedings of the Image and Signal Processing for Remote Sensing XXIV, Berlin, Germany, 10–13 September 2018; Volume 10789, pp. 413–432. [Google Scholar]
- Zhang, M.; Cheng, Q.; Luo, F.; Ye, L. A triplet nonlocal neural network with dual-anchor triplet loss for high-resolution remote sensing image retrieval. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2711–2723. [Google Scholar] [CrossRef]
- Cao, R.; Zhang, Q.; Zhu, J.; Li, Q.; Li, Q.; Liu, B.; Qiu, G. Enhancing remote sensing image retrieval using a triplet deep metric learning network. Int. J. Remote Sens. 2020, 41, 740–751. [Google Scholar] [CrossRef]
- Liu, Y.; Ding, L.; Chen, C.; Liu, Y. Similarity-based unsupervised deep transfer learning for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7872–7889. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, X.; Lu, X. Remote Sensing Image Retrieval by Deep Attention Hashing With Distance-Adaptive Ranking. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4301–4311. [Google Scholar] [CrossRef]
- Ding, C.; Wang, M.; Zhou, Z.; Huang, T.; Wang, X.; Li, J. Siamese transformer network-based similarity metric learning for cross-source remote sensing image retrieval. Neural Comput. Appl. 2023, 35, 8125–8142. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring hierarchical convolutional features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Chaudhuri, U.; Dey, S.; Datcu, M.; Banerjee, B.; Bhattacharya, A. Interband retrieval and classification using the multilabeled sentinel-2 bigearthnet archive. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9884–9898. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Q.; Wang, G.; Xie, X.; Min, L.; Han, J. SFRNet: Fine-Grained Oriented Object Recognition via Separate Feature Refinement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610510. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 4005615. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Liu, Z.; Tan, Y.; He, Q.; Xiao, Y. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4486–4497. [Google Scholar] [CrossRef]
- Tekeste, I.; Demir, B. Advanced local binary patterns for remote sensing image retrieval. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6855–6858. [Google Scholar]
- Aptoula, E. Remote sensing image retrieval with global morphological texture descriptors. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3023–3034. [Google Scholar] [CrossRef]
- Xie, G.; Guo, B.; Huang, Z.; Zheng, Y.; Yan, Y. Combination of dominant color descriptor and Hu moments in consistent zone for content based image retrieval. IEEE Access 2020, 8, 146284–146299. [Google Scholar] [CrossRef]
- Chen, H.z.; Jing, N.; Wang, J.; Chen, Y.g.; Chen, L. Content Based Retrieval for Lunar Exploration Image Databases. In Proceedings of the Database Systems for Advanced Applications: 18th International Conference, DASFAA 2013, Wuhan, China, 22–25 April 2013; Proceedings, Part II 18. Springer: Berlin/Heidelberg, Germany, 2013; pp. 259–266. [Google Scholar]
- Wang, S.; Hou, D.; Xing, H. A novel multi-attention fusion network with dilated convolution and label smoothing for remote sensing image retrieval. Int. J. Remote Sens. 2022, 43, 1306–1322. [Google Scholar] [CrossRef]
- Ye, F.; Chen, S.; Meng, X.; Xin, J. Query-adaptive feature fusion base on convolutional neural networks for remote sensing image retrieval. In Proceedings of the 2021 International Conference on Digital Society and Intelligent Systems (DSInS), Chengdu, China, 3–4 December 2021; pp. 148–151. [Google Scholar]
- Wang, H.; Zhou, Z.; Zong, H.; Miao, L. Wide-context attention network for remote sensing image retrieval. IEEE Geosci. Remote Sens. Lett. 2020, 18, 2082–2086. [Google Scholar] [CrossRef]
- Chaudhuri, U.; Banerjee, B.; Bhattacharya, A.; Datcu, M. Attention-driven graph convolution network for remote sensing image retrieval. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8019705. [Google Scholar] [CrossRef]
- Zhong, W.; Jiang, J.; Ma, Y. L2AMF-Net: An L2-Normed Attention and Multi-Scale Fusion Network for Lunar Image Patch Matching. Remote Sens. 2022, 14, 5156. [Google Scholar] [CrossRef]
- Fan, L.; Zhao, H.; Zhao, H. Global optimization: Combining local loss with result ranking loss in remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7011–7026. [Google Scholar] [CrossRef]
- Zhao, H.; Yuan, L.; Zhao, H. Similarity retention loss (SRL) based on deep metric learning for remote sensing image retrieval. ISPRS Int. J. Geo-Inf. 2020, 9, 61. [Google Scholar] [CrossRef]
- Fan, L.; Zhao, H.; Zhao, H. Distribution consistency loss for large-scale remote sensing image retrieval. Remote Sens. 2020, 12, 175. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Hu, M.K. Visual pattern recognition by moment invariants. IRE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving YOLOv5 with attention mechanism for detecting boulders from planetary images. Remote Sens. 2021, 13, 3776. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Balntas, V.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Learning local feature descriptors with triplets and shallow convolutional neural networks. Bmvc 2016, 1, 3. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]











| Parameter Name | Parameter Configuration |
|---|---|
| Initial learning rate | |
| Weight decay | |
| Margin | 2 |
| Training epochs | 25 |
| Category | Methods | |||||
|---|---|---|---|---|---|---|
| VGG16 | ResNet101 | DenseNet121 | EfficientnetV2-S | ViT | LC2R-Net | |
| Simple Crater | ||||||
| Floor-Fractured Crater | ||||||
| Central Peak Crater | ||||||
| Multi-Impacted Floor Crater | ||||||
| Lunar Oceanic Remnant Impact Crater | ||||||
| Impact Residual Crater | ||||||
| Average | ||||||
| Methods | mAP/% | ANMRR |
|---|---|---|
| LBP | 39.85 | 0.3717 |
| Hu | 29.81 | 0.4064 |
| LBP + Hu | 41.37 | 0.3616 |
| 83.75 | 0.0721 |
| Method | mAP/% | ANMRR | |
|---|---|---|---|
| 0 | 83.65 | 0.0725 | |
| 0.1 | 83.67 | 0.0716 | |
| 0.2 | 83.75 | 0.0721 | |
| 0.3 | 83.71 | 0.0728 | |
| 0.4 | 83.29 | 0.0756 | |
| 0.5 | 83.19 | 0.0769 | |
| 0.6 | 82.91 | 0.0752 | |
| 0.7 | 82.46 | 0.0798 | |
| 0.8 | 81.73 | 0.0811 | |
| 0.9 | 78.79 | 0.0934 | |
| 1.0 | 37.99 | 0.3943 |
| Methods | Feature Vector Length | Retrieval Times/s |
|---|---|---|
| VGG-16 | 4096 | 0.2134 |
| ResNet101 | 2048 | 0.2046 |
| DenseNet121 | 1024 | 0.1922 |
| EfficientNetV2-S | 1280 | 0.1942 |
| ViT | 768 | 0.1878 |
| Swin-T | 768 | 0.1884 |
| Swin-T + CBAMwithECA | 768 | 0.1907 |
| LBP + Hu | 2367 | 0.1630 |
| 128 | 0.1041 |
| Methods | mAP/% | ANMRR |
|---|---|---|
| Swin-T | 83.01 | 0.0755 |
| Swin-T + SE | 82.16 | 0.0795 |
| Swin-T + CBAM | 78.23 | 0.1038 |
| Swin-T + CBAMwithECA | 83.65 | 0.0725 |
| 83.75 | 0.0721 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Kang, Z.; Cao, Z. An Image Retrieval Method for Lunar Complex Craters Integrating Visual and Depth Features. Electronics 2024, 13, 1262. https://doi.org/10.3390/electronics13071262
Zhang Y, Kang Z, Cao Z. An Image Retrieval Method for Lunar Complex Craters Integrating Visual and Depth Features. Electronics. 2024; 13(7):1262. https://doi.org/10.3390/electronics13071262
Chicago/Turabian StyleZhang, Yingnan, Zhizhong Kang, and Zhen Cao. 2024. "An Image Retrieval Method for Lunar Complex Craters Integrating Visual and Depth Features" Electronics 13, no. 7: 1262. https://doi.org/10.3390/electronics13071262