

APIMiner: Identifying Web Application APIs Based on Web Page States Similarity Analysis
 , ,
, ,
Abstract
:1. Introduction
- We propose APIMiner, a framework for identifying APIs in web applications by dynamically traversing web pages based on web page state similarity analysis.
- We design a new state representation of the web page and page state similarity analysis method. The new state representation of the web page similarity analysis method can effectively improve the identification of APIs, accurately and effectively reducing the impact of similar pages during traversal.
- We conduct extensive experiments to verify the effectiveness of APIMiner. The experimental results show that APIMiner achieves good performance in terms of the number of identified APIs (average of 1136) and code coverage (average of 28,470).
2. Background
2.1. Web APIs
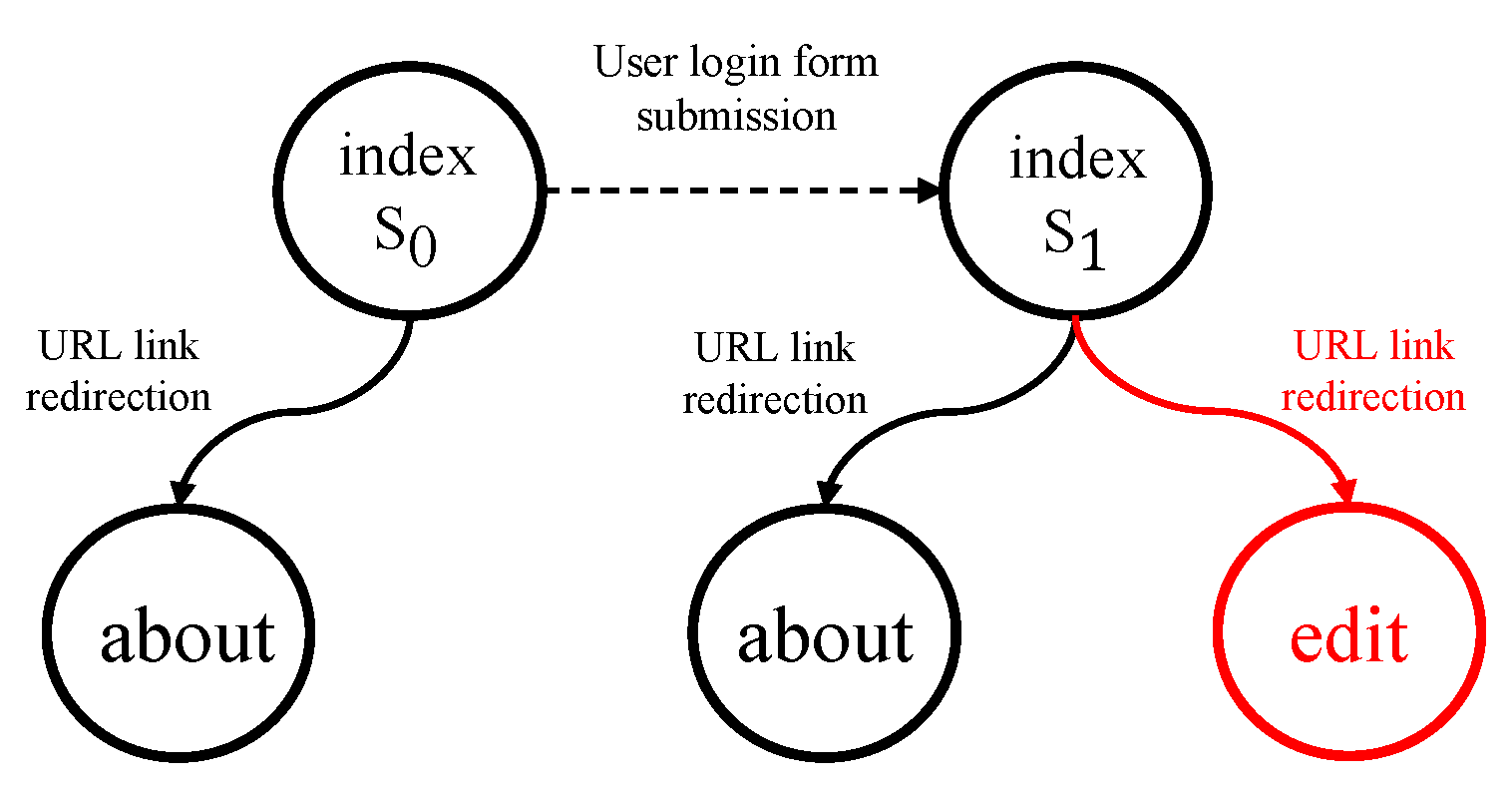
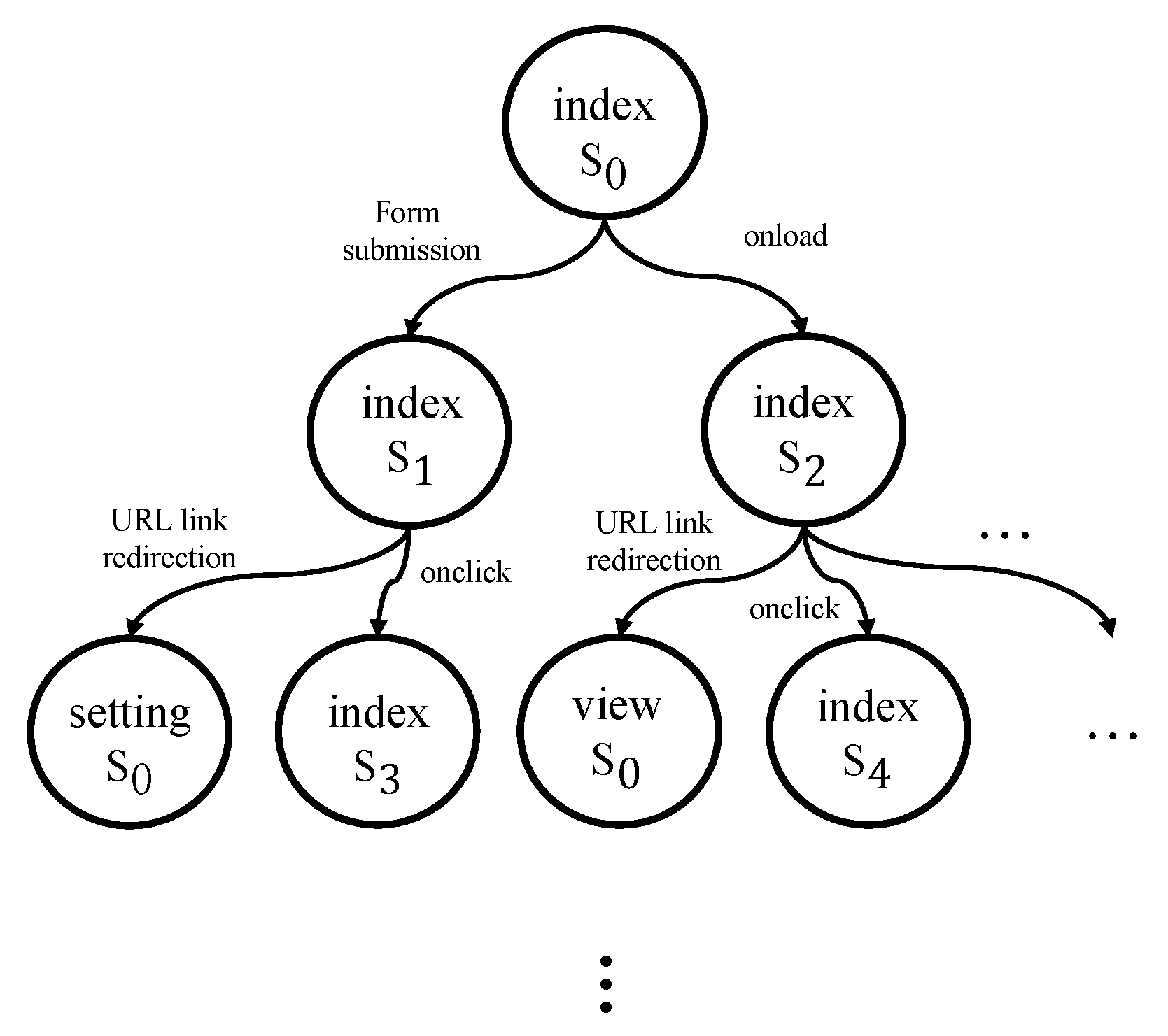
2.2. Web Page State
3. Overview
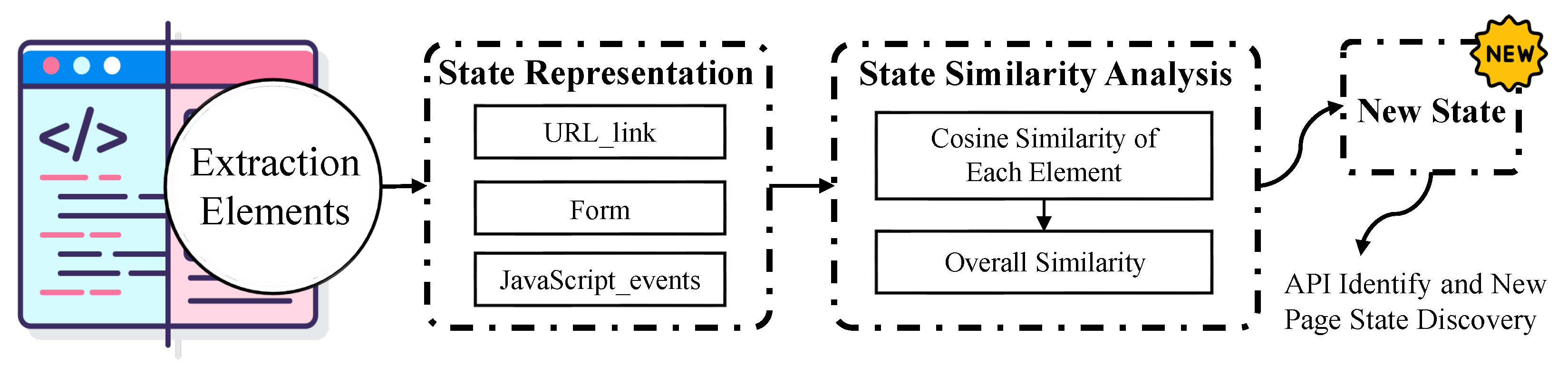
3.1. State Representation
3.2. State Similarity Analysis
| Algorithm 1 Traverse and similarity analysis method |
|
3.3. API Identification
4. Evaluation
- RQ1. How capable is APIMiner in page similarity analysis? How does it compare with existing similarity analysis methods?
- RQ2. How effective is APIMiner’s augmentation technology in identifying web application APIs? How does the number of web application APIs identified by APIMiner compare to state-of-the-art tools, such as Crawlergo and Wapiti3?
- RQ3. How does the coverage of APIMiner for web applications compare with existing methods?
4.1. Experimental Setup
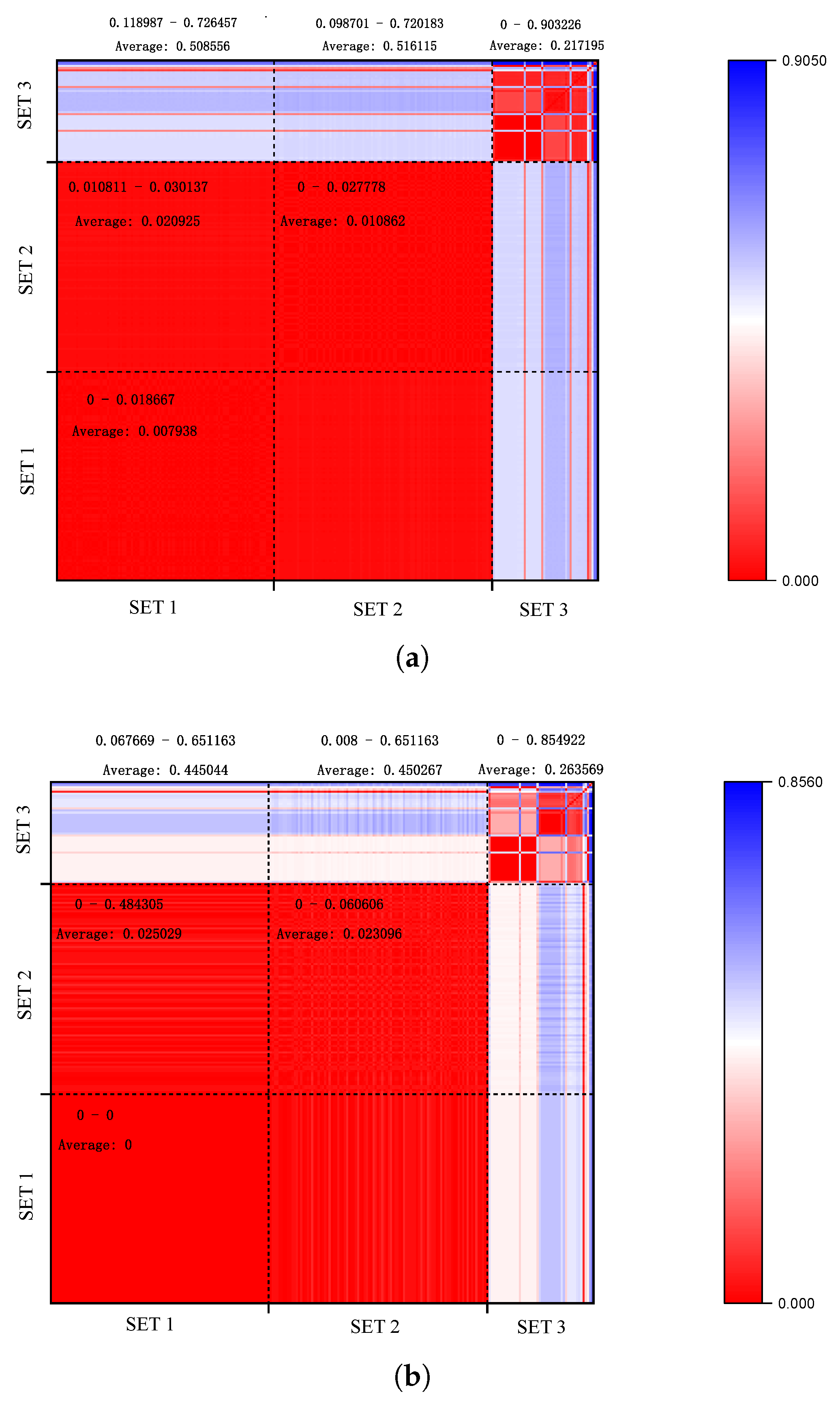
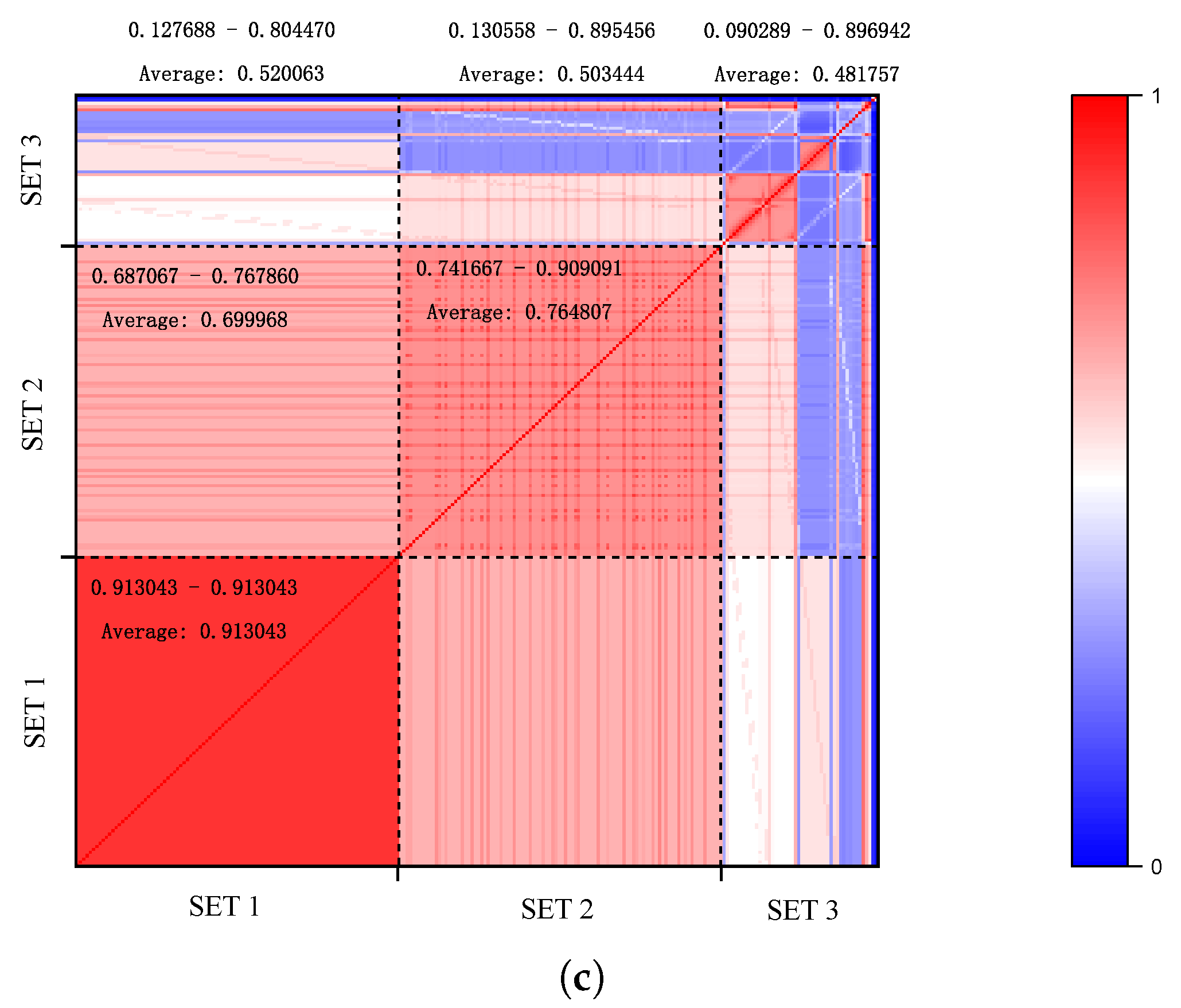
4.2. Similarity Analysis Capabilities
- (1)
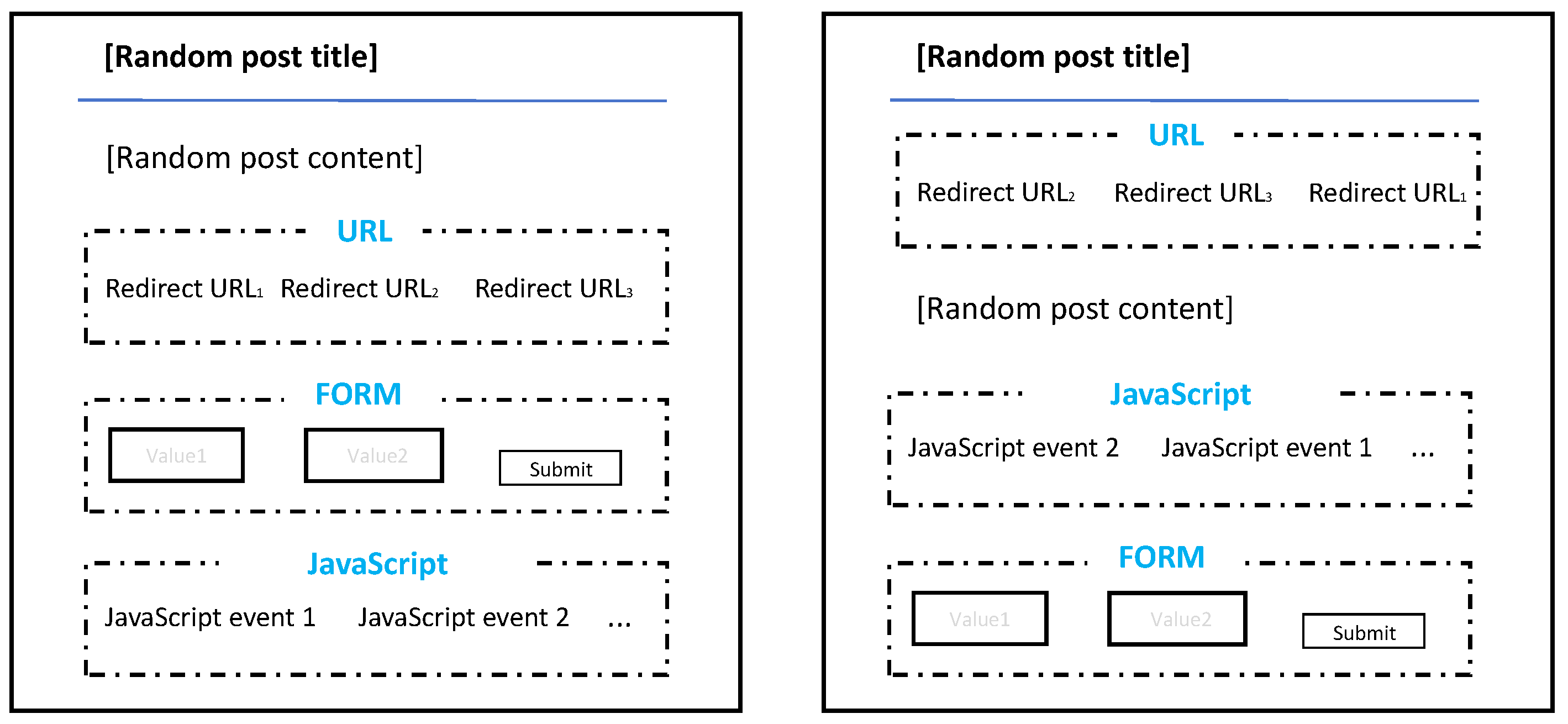
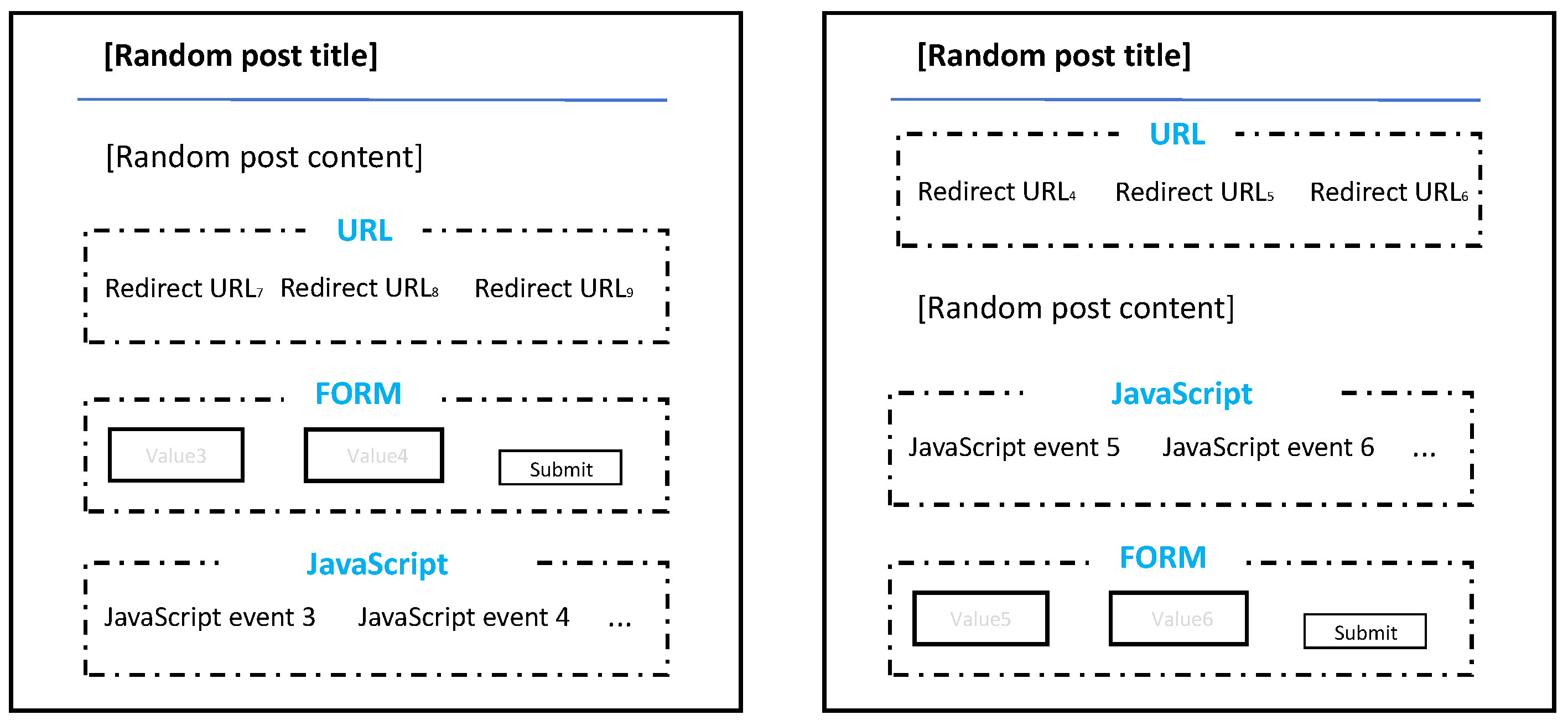
- The first set included pages with similar URLs, functionalities, and APIs intended to be clustered. The set consisted of post pages with highly similar URLs, forms, and JavaScript events but different article content in WordPress. It is worth mentioning that the order of the three types of elements may be different. An example of a post is shown in Figure 12.
- (2)
- The second set consisted of pages with similar access URLs but different APIs, which should not be clustered. These post pages contained completely different or partially similar URLs, forms, and JavaScript events. An example of a post is shown in Figure 13.
- (3)
- The third set comprised pages with completely distinct URLs and functionalities, which should not be clustered together. This set consisted of WordPress pages where users were not logged in.
4.3. Web Application API Identification
5. Discussion
6. Related Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Grent, H.; Akimov, A.; Aniche, M. Automatically identifying parameter constraints in complex Web APIs: A case study at Adyen. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Madrid, Spain, 25–28 May 2021; pp. 71–80. [Google Scholar]
- Atlidakis, V.; Godefroid, P.; Polishchuk, M. Restler: Stateful rest api fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 748–758. [Google Scholar]
- Hatfield-Dodds, Z.; Dygalo, D. Deriving semantics-aware fuzzers from web API schemas. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, Pittsburgh, PA, USA, 21–29 May 2022; pp. 345–346. [Google Scholar]
- Mesbah, A.; Bozdag, E.; Van Deursen, A. Crawling Ajax by inferring user interface state changes. In Proceedings of the 2008 eighth international conference on web engineering, Yorktown Heights, NJ, USA, 14–18 July 2008; pp. 122–134. [Google Scholar]
- Mesbah, A.; Van Deursen, A.; Lenselink, S. Crawling Ajax-based web applications through dynamic analysis of user interface state changes. ACM Trans. Web (TWEB) 2012, 6, 1–30. [Google Scholar] [CrossRef]
- Doupé, A.; Cavedon, L.; Kruegel, C.; Vigna, G. Enemy of the state: A state-aware black-box web vulnerability scanner. In Proceedings of the Presented as Part of the 21st {USENIX} Security Symposium ({USENIX} Security 12), Bellevue, WA, USA, 8–10 August 2012; pp. 523–538. [Google Scholar]
- Pellegrino, G.; Tschürtz, C.; Bodden, E.; Rossow, C. jäk: Using dynamic analysis to crawl and test modern web applications. In Proceedings of the Research in Attacks, Intrusions, and Defenses: 18th International Symposium, RAID 2015, Kyoto, Japan, 2–4 November 2015; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 295–316. [Google Scholar]
- Eriksson, B.; Pellegrino, G.; Sabelfeld, A. Black widow: Blackbox data-driven web scanning. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 1125–1142. [Google Scholar]
- Li, X.; Zhang, W.; Wang, D.; Zhang, B.; He, H. Algorithm of web page similarity comparison based on visual block. Comput. Sci. Inf. Syst. 2019, 16, 815–830. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, B.; Liu, Y.; Lv, F. Research on webpage similarity computing technology based on visual blocks. In Proceedings of the Social Media Processing: Third National Conference, SMP 2014, Beijing, China, 1–2 November 2014; Proceedings. Springer: Berlin/Heidelberg, Germany, 2014; pp. 187–197. [Google Scholar]
- Gowda, T.; Mattmann, C.A. Clustering web pages based on structure and style similarity (application paper). In Proceedings of the 2016 IEEE 17th International Conference on Information Reuse and Integration (IRI), Pittsburgh, PA, USA, 28–30 July 2016; pp. 175–180. [Google Scholar]
- Kang, C.Y. DOM-based web pages to determine the structure of the similarity algorithm. In Proceedings of the 2009 Third International Symposium on Intelligent Information Technology Application, Nanchang, China, 21–22 November 2009; Volume 2, pp. 245–248. [Google Scholar]
- What Is REST-REST API Tutorial. 2023. Available online: https://restfulapi.net/ (accessed on 10 November 2023).
- Pop, D.P.; Altar, A. Designing an MVC model for rapid web application development. Procedia Eng. 2014, 69, 1172–1179. [Google Scholar] [CrossRef]
- Popescu, D.A.; Nicolae, D. Determining the similarity of two web applications using the edit distance. In Proceedings of the Soft Computing Applications: Proceedings of the 6th International Workshop Soft Computing Applications (SOFA 2014), Timisoara, Romania, 24–26 July 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1, pp. 681–690. [Google Scholar]
- Vissers, T.; Van Goethem, T.; Joosen, W.; Nikiforakis, N. Maneuvering around clouds: Bypassing cloud-based security providers. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1530–1541. [Google Scholar]
- Drakonakis, K.; Ioannidis, S.; Polakis, J. ReScan: A Middleware Framework for Realistic and Robust Black-box Web Application Scanning. In Proceedings of the NDSS, San Diego, CA, USA, 27 February–3 March 2023. [Google Scholar]
- Crawlergo. 2022. Available online: https://github.com/Qianlitp/crawlergo (accessed on 25 January 2024).
- Wapiti. 2023. Available online: https://wapiti-scanner.github.io/ (accessed on 25 January 2024).
- Chen, Y.; Li, Y.; Pan, Z.; Lu, Y.; Chen, J.; Ji, S. URadar: Discovering Unrestricted File Upload Vulnerabilities via Adaptive Dynamic Testing. IEEE Trans. Inf. Forensics Secur. 2024, 19, 1251–1266. [Google Scholar] [CrossRef]
- Najork, M.; Wiener, J.L. Breadth-first crawling yields high-quality pages. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 114–118. [Google Scholar]
- HTTP Headers-HTTP|MDN. 2020. Available online: https://developer.mozilla.org/en-US/docs/web/http/headers (accessed on 25 January 2024).
- POST-HTTP|MDN. 2020. Available online: https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/POST (accessed on 25 January 2024).
- Alhuzali, A.; Gjomemo, R.; Eshete, B.; Venkatakrishnan, V. {NAVEX}: Precise and scalable exploit generation for dynamic web applications. In Proceedings of the USENIX Security Symposium, Baltimore, MD, USA, 15–17 August 2018; pp. 377–392. [Google Scholar]
- W3Techs. W3Techs.com-Usage Statistics and Market Share of Content Management Systems. 2021. Available online: https://w3techs.com/technologies/overview/content_management (accessed on 25 January 2024).
- Repository Search Results-GitHub. 2022. Available online: https://github.com/search?q=CMS+language%3APHP&type=repositories&s=stars&o=desc&l=PHP (accessed on 25 January 2024).
- Crawlergo Issues. 2022. Available online: https://github.com/Qianlitp/crawlergo/issues/82 (accessed on 25 January 2024).
- GitLab. Kostas Drakonakis/rescanApps·GitLab. 2023. Available online: https://gitlab.com/kostasdrk/rescanApps/-/tree/main (accessed on 25 January 2024).
- Maalej, W.; Robillard, M.P. Patterns of knowledge in API reference documentation. IEEE Trans. Softw. Eng. 2013, 39, 1264–1282. [Google Scholar] [CrossRef]
- Gao, C.; Wei, J.; Zhong, H.; Huang, T. Inferring data contract for web-based API. In Proceedings of the 2014 IEEE International Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 65–72. [Google Scholar]
- Atlidakis, V.; Godefroid, P.; Polishchuk, M. Rest-ler: Automatic intelligent rest api fuzzing. arXiv 2018, arXiv:1806.09739. [Google Scholar]
- Pandita, R.; Xiao, X.; Zhong, H.; Xie, T.; Oney, S.; Paradkar, A. Inferring method specifications from natural language API descriptions. In Proceedings of the 2012 34th international conference on software engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 815–825. [Google Scholar]
- Kals, S.; Kirda, E.; Kruegel, C.; Jovanovic, N. Secubat: A web vulnerability scanner. In Proceedings of the 15th International Conference on World Wide Web, Edinburgh, UK, 23–26 May 2006; pp. 247–256. [Google Scholar]
- Koppula, H.S.; Leela, K.P.; Agarwal, A.; Chitrapura, K.P.; Garg, S.; Sasturkar, A. Learning url patterns for webpage de-duplication. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, Edinburgh, UK, 23–26 May 2010; pp. 381–390. [Google Scholar]
- Nie, T.; Wang, Z.; Kou, Y.; Zhang, R. Crawling result pages for data extraction based on URL classification. In Proceedings of the 2010 Seventh Web Information Systems and Applications Conference, Huhehot, China, 20–22 August 2010; pp. 79–84. [Google Scholar]
- Wu, X.; Cao, C.; Wang, Y.; Fu, J.; Wang, S. Extracting knowledge from web tables based on DOM tree similarity. In Proceedings of the Knowledge Science, Engineering and Management: 9th International Conference, KSEM 2016, Passau, Germany, 5–7 October 2016; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2016; pp. 302–313. [Google Scholar]
- Kim, Y.; Park, J.; Kim, T.; Choi, J. Web information extraction by HTML tree edit distance matching. In Proceedings of the 2007 International Conference on Convergence Information Technology (ICCIT 2007), Gwangju, Republic of Korea, 21–23 November 2007; pp. 2455–2460. [Google Scholar]
- Abdelnabi, S.; Krombholz, K.; Fritz, M. Visualphishnet: Zero-day phishing website detection by visual similarity. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtually, 9–13 November 2020; pp. 1681–1698. [Google Scholar]
- Dalgic, F.C.; Bozkir, A.S.; Aydos, M. Phish-iris: A new approach for vision based brand prediction of phishing web pages via compact visual descriptors. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018; pp. 1–8. [Google Scholar]
- Lin, Y.; Liu, R.; Divakaran, D.M.; Ng, J.Y.; Chan, Q.Z.; Lu, Y.; Si, Y.; Zhang, F.; Dong, J.S. Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 11–13 August 2021; pp. 3793–3810. [Google Scholar]
- Liu, R.; Lin, Y.; Yang, X.; Ng, S.H.; Divakaran, D.M.; Dong, J.S. Inferring phishing intention via webpage appearance and dynamics: A deep vision based approach. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 1633–1650. [Google Scholar]
- Lin, X.; Ilia, P.; Polakis, J. Fill in the blanks: Empirical analysis of the privacy threats of browser form autofill. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 507–519. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Application | Version | LoC | # | Application | Version | LoC |
|---|---|---|---|---|---|---|---|
| 0 | Elgg | 2.3.10 | 96,582 | 5 | Joomla | 3.9.3 | 33,949 |
| 1 | Subrion | 4.2.1 | 319,112 | 6 | XE | 1.11.2 | 145,169 |
| 2 | CMSMadeSimple | 2.2.9.1 | 310,316 | 7 | WordPress | 5.0.3 | 1,249,842 |
| 3 | MyBB | 1.8.19 | 237,667 | 8 | phpBB | 3.2.5 | 193,720 |
| 4 | Backdrop | 1.12.1 | 73,739 | 9 | Drupal | 8.6.9 | 20,512 |
| # | Web Application | Enemy | Wapiti3 | Crawlergo | APIMiner | ||||
|---|---|---|---|---|---|---|---|---|---|
| No. | ELoC | No. | ELoC | No. | ELoC | No. | ELoC | ||
| 0 | Elgg | 3 | 7257 | 132 | 14,840 | 149 (3462) | 14,567 | 175 | 16,760 |
| 1 | Subrion | 0 | 1784 | 163 | 6000 | 269 (493) | 5368 | 511 | 12,515 |
| 2 | CMSMadeSimple | 7 | 1446 | 36 | 10,915 | 53 (57) | 15,732 | 138 | 20,724 |
| 3 | MyBB | 105 (1342) | 9237 | 162 (463) | 9983 | 147 (166) | 12,250 | 293 | 17,293 |
| 4 | Backdrop | 0 | 1054 | 109 | 14,733 | 500 (803) | 30,613 | 4222 | 42,526 |
| 5 | Joomla | 49 | 8702 | 200 | 17,199 | 68 (113) | 14,059 | 243 | 31,231 |
| 6 | XE | 0 | 5629 | 99 | 12,656 | 121 (355) | 16,052 | 286 | 23,380 |
| 7 | Wordpress | 140 | 17,203 | 184 | 31,401 | 79 (342) | 22,766 | 1304 | 41,322 |
| 8 | phpBB | 0 | 3888 | 59 | 5245 | 59 (344) | 11,342 | 77 | 12,200 |
| 9 | Drupal | 212 | 19,579 | 1824 | 29,953 | 274 (1380) | 37,941 | 4119 | 66,751 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Lu, Y.; Pan, Z.; Chen, J.; Shi, F.; Li, Y.; Jiang, Y. APIMiner: Identifying Web Application APIs Based on Web Page States Similarity Analysis. Electronics 2024, 13, 1112. https://doi.org/10.3390/electronics13061112
Chen Y, Lu Y, Pan Z, Chen J, Shi F, Li Y, Jiang Y. APIMiner: Identifying Web Application APIs Based on Web Page States Similarity Analysis. Electronics. 2024; 13(6):1112. https://doi.org/10.3390/electronics13061112
Chicago/Turabian StyleChen, Yuanchao, Yuliang Lu, Zulie Pan, Juxing Chen, Fan Shi, Yang Li, and Yonghui Jiang. 2024. "APIMiner: Identifying Web Application APIs Based on Web Page States Similarity Analysis" Electronics 13, no. 6: 1112. https://doi.org/10.3390/electronics13061112