
An Aero-Engine Classification Method Based on Fourier Transform Infrared Spectrometer Spectral Feature Vectors

Abstract
:1. Introduction
- The infrared spectrum detection method for aero-engine hot jet is used as the basis and data source input of the identification of aero-engines. Aero-engine hot jet is an important infrared radiation characteristic of aero-engine, and the infrared spectrum provides the characteristic information of substances at the molecular level, so it is more scientific to utilize this method for classification.
- FT-IR is used to measure the infrared spectrum information of aero-engine hot jet. An FT-IR spectrometer has the advantages of fast scanning speed, excellent resolution, wide measurement spectral range, and high measurement accuracy. It can achieve exceptional spectral measurement, which is of great significance for the non-contact classification and recognition of aero-engines.
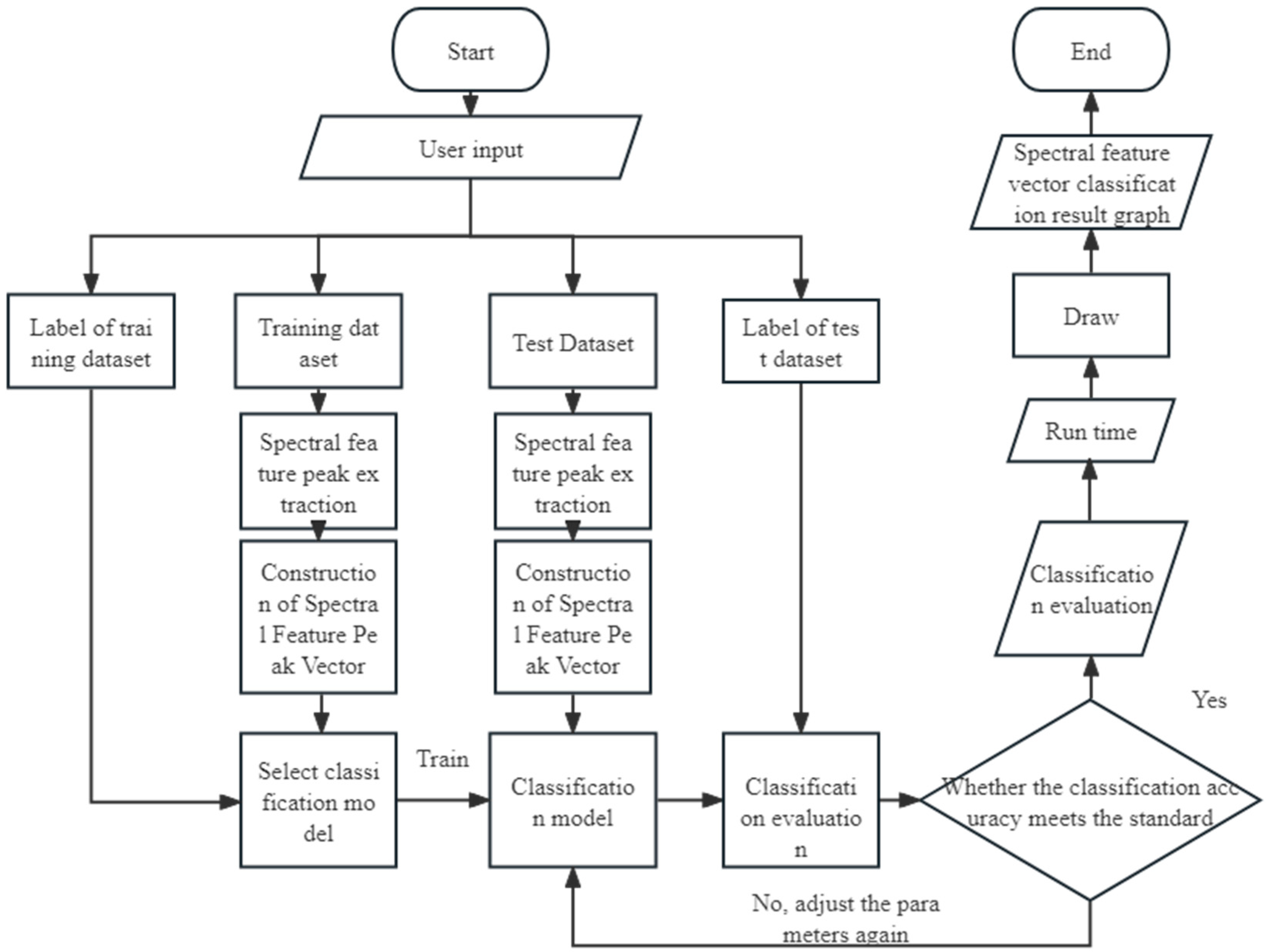
2. Spectral Feature Analysis and Spectral Feature Vector Construction
3. Spectral Eigenvector Classification Methods
- ①
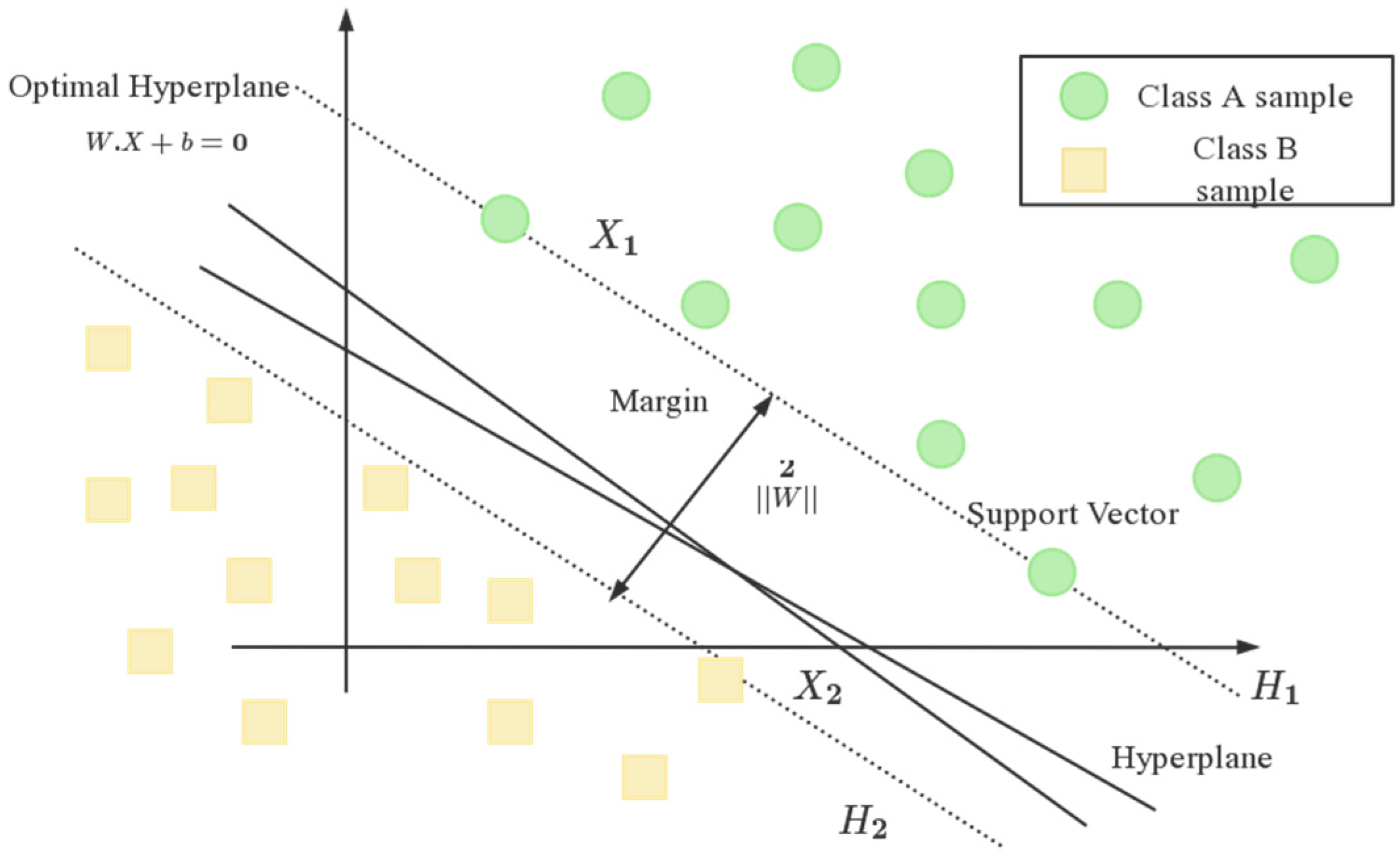
- Support vector machine (SVM) classification method
- ②
- XGBoost classification method
- ③
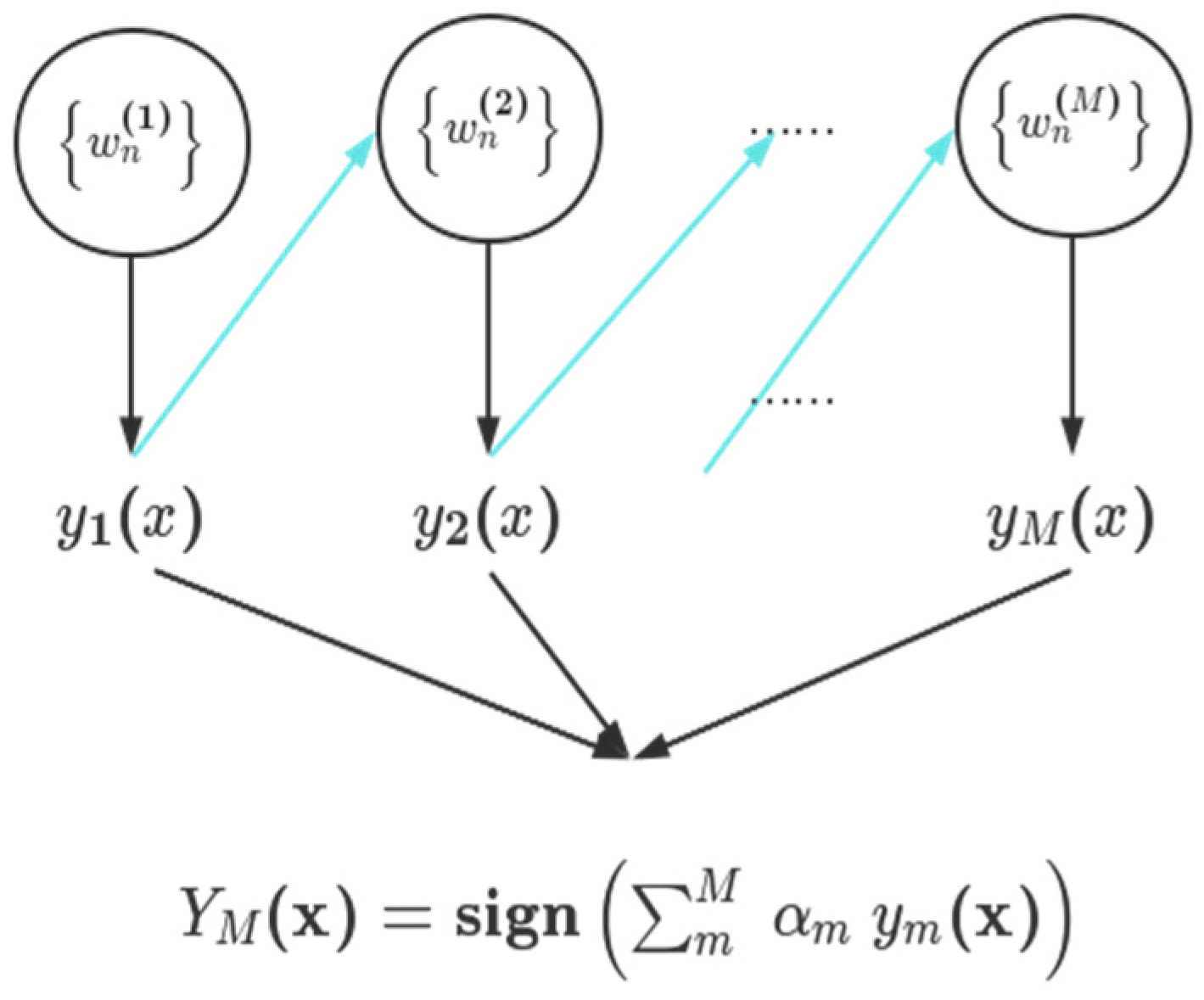
- AdaBoost classification method
- ④
- Light gradient boosting machine (LightGBM) classification method
- ⑤
- CatBoost classification method
- ⑥
- Random Forest (RF) classification method
- ⑦
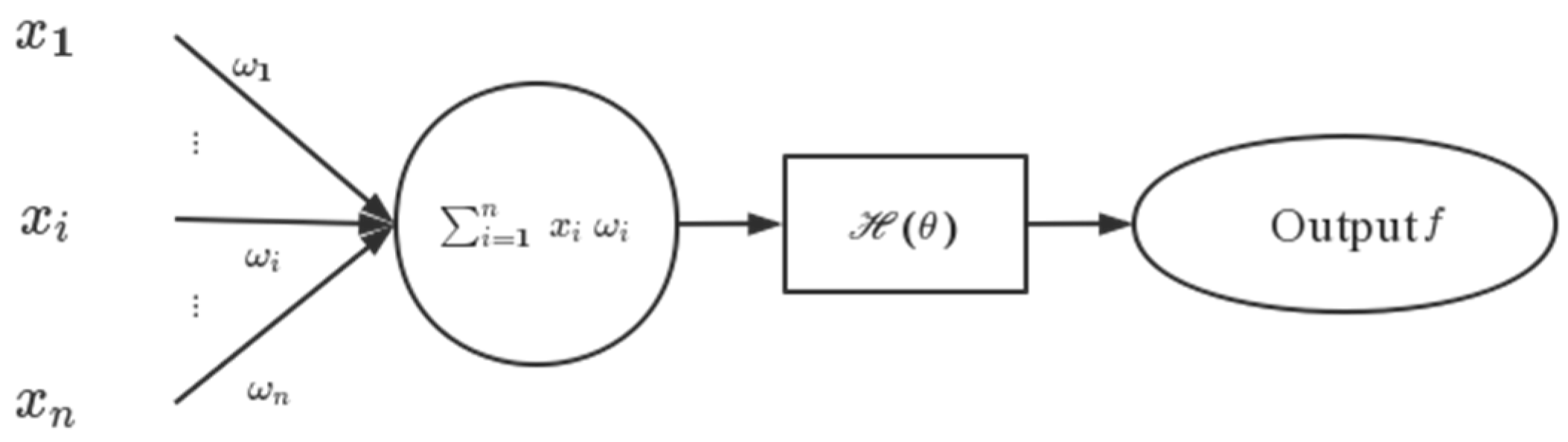
- Neural network (NN) classification method
4. Experiments and the Results
4.1. Experimental Design of Aero-Engine Spectral Measurement
4.2. Data Set Production and Spectral Feature Vectors Extraction
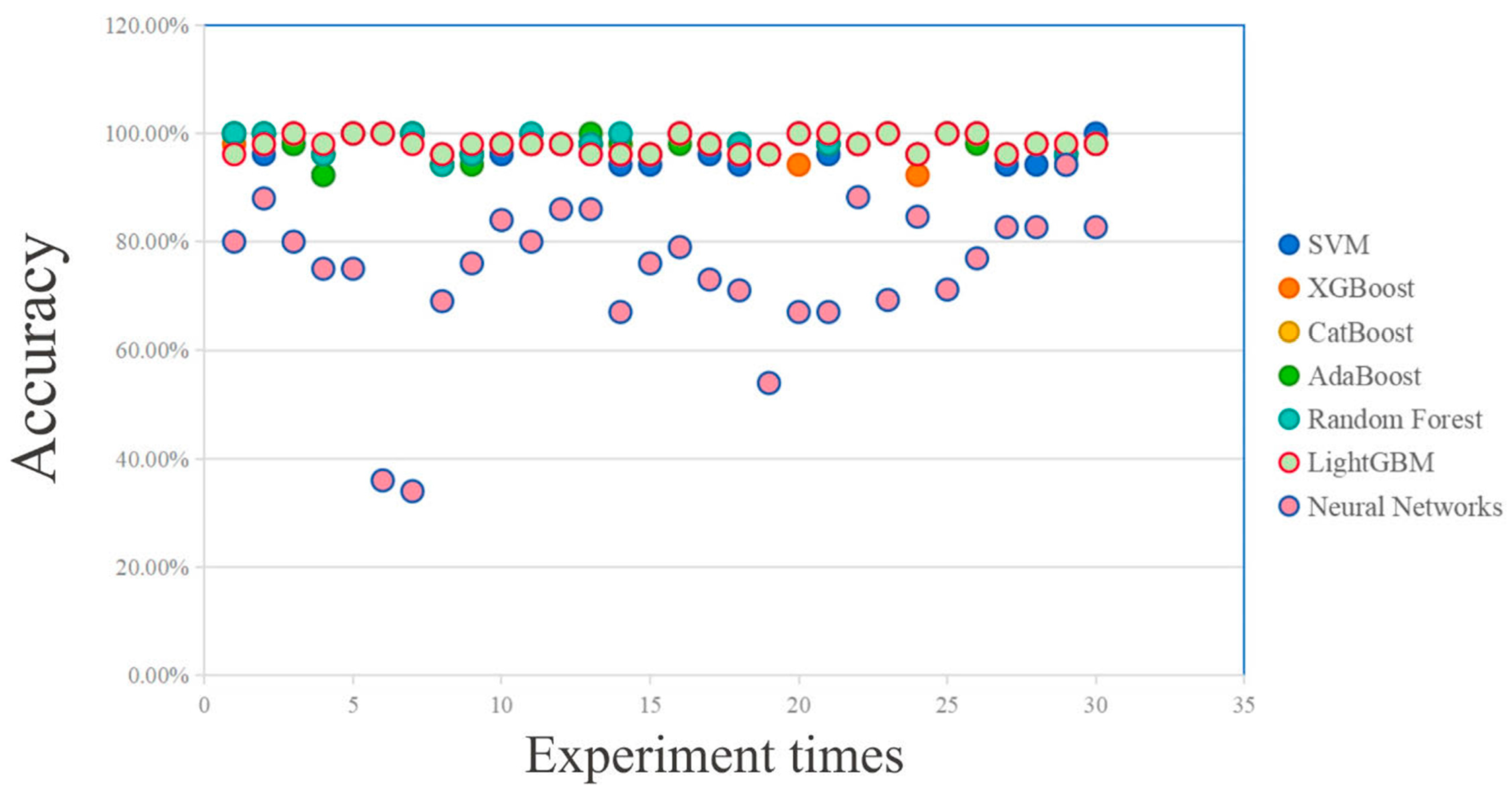
4.3. Assessment of the Accuracy of Classification Prediction Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Razeghi, M.; Nguyen, B.M. Advances in mid-infrared detection and imaging: A key issues review. Rep. Prog. Phys. 2014, 77, 082401. [Google Scholar] [CrossRef]
- Chikkaraddy, R.; Arul, R.; Jakob, L.A.; Baumberg, J.J. Single-molecule mid-IR detection through vibration ally-assisted luminescence. arXiv 2022, arXiv:2205.07792. [Google Scholar]
- Knez, D.; Toulson, B.W.; Chen, A.; Ettenberg, M.H.; Nguyen, H.; Potma, E.O.; Fishman, D.A. Spectral imaging at high definition and high speed in the mid-infrared. Sci. Adv. 2022, 8, eade4247. [Google Scholar] [CrossRef]
- Zhang, J.; Gong, Y. Automated identification of infrared spectra of hazardous clouds by passive FTIR remote sensing. In Multispectral and Hyperspectral Image Acquisition and Processing; SPIE: Bellingham, DC, USA, 2001; Volume 4548, pp. 356–362. [Google Scholar]
- Roh, S.B.; Oh, S.K. Identification of Plastic Wastes by Using Fuzzy Radial Basis Function Neural Networks Classifier with Conditional Fuzzy C-Means Clustering. J. Electr. Eng. Technol. 2016, 11, 103–116. [Google Scholar] [CrossRef]
- Kumar, V.; Kashyap, M.; Gautam, S.; Shukla, P.; Joshi, K.B.; Vinayak, V. Fast Fourier infrared spectroscopy to characterize the biochemical composition in diatoms. J. Biosci. 2018, 43, 717–729. [Google Scholar] [CrossRef]
- Han, X.; Li, X.; Gao, M.; Tong, J.; Wei, X.; Li, S.; Ye, S.; Li, Y. Emissions of Airport Monitoring with Solar Occultation Flux-Fourier Transform Infrared Spectrometer. J. Spectrosc. 2018, 2018, 1069612. [Google Scholar] [CrossRef]
- Cięszczyk, S. Passive Open-Path FTIR Measurements and Spectral Interpretations for in situ Gas Monitoring and Process Diagnostics. Acta Phys. Pol. A 2014, 126, 673–678. [Google Scholar] [CrossRef]
- Schütze, C.; Lau, S.; Reiche, N.; Sauer, U.; Borsdorf, H.; Dietrich, P. Ground-based remote sensing with open-path Fourier-transform infrared (OP-FTIR) spec-troscopy for large-scale monitoring of greenhouse gases. Energy Procedia 2013, 37, 4276–4282. [Google Scholar] [CrossRef]
- Doubenskaia, M.; Pavlov, M.; Grigoriev, S.; Smurov, I. Definition of brightness temperature and restoration of true temperature in laser cladding using infrared camera. Surf. Coat. Technol. 2013, 220, 244–247. [Google Scholar] [CrossRef]
- Homan, D.C.; Cohen, M.H.; Hovatta, T.; Kellermann, K.I.; Kovalev, Y.Y.; Lister, M.L.; Popkov, A.V.; Pushkarev, A.B.; Ros, E.; Savolainen, T. MOJAVE. XIX. Brightness Temperatures and Intrinsic Properties of Blazar Jets. Astrophys. J. 2021, 923, 67. [Google Scholar] [CrossRef]
- Schumann, U. On the effect of emissions from aircraft engines on the state of the atmosphere. Ann. Geophys. 2005, 12, 365–384. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Zhang, Y.; Li, T. Three different SVM classification models in Tea Oil FTIR Application Research in Adulteration Detection. J. Phys. Conf. Ser. 2021, 1748, 022037. [Google Scholar] [CrossRef]
- Menezes, M.V.; Torres, L.C.; Braga, A.P. Width optimization of RBF kernels for binary classification of support vector machines: A density estimation-based approach. Pattern Recognit. Lett. 2019, 128, 1–7. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Nalluri, M.; Pentela, M.; Eluri, N.R. A Scalable Tree Boosting System: XGBoost. Int. J. Res. Stud. Sci. Eng. Technol. 2020, 7, 36–51. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2018, arXiv:1706.09516. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Dorogush, A.V.; Gulin, A.; Gusev, G.; Kazeev, N.; Prokhorenkova, L.O.; Vorobev, A. Fighting biases with dynamic boosting. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Proc. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Zeng, P. Artificial Neural Networks Principle for Finite Element Method. Z. Angew. Math. Mech. 1996, 76, 565–566. [Google Scholar]
- ArulRaj, K.; Karthikeyan, M.; Narmatha, D. A View of Artificial Neural Network Models in Different Application Areas. E3S Web Conf. 2021, 287, 03001. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Proc. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
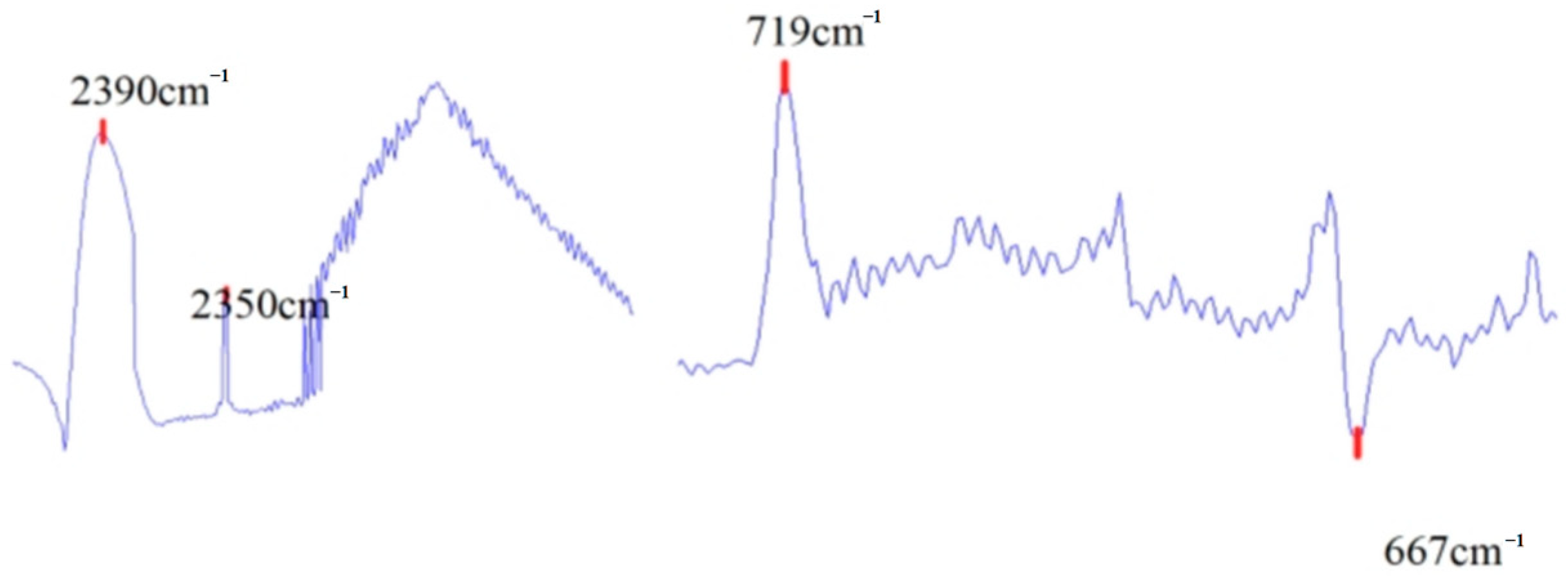
| Characteristic Peak Type | Emission Peak (cm−1) | Absorption Peak (cm−1) | ||
|---|---|---|---|---|
| Peak standard features | 2350 | 2390 | 719 | 667 |
| Characteristic peak range values | 2350.5–2348 | 2377–2392 | 722–718 | 666.7–670.5 |
| Methods | Categories | Application Scenarios | Advantages | Disadvantages |
|---|---|---|---|---|
| SVM | Supervised learning method | Classification and regression, text classification, image recognition | Adaptability of high-dimensional spatial data processing and small sample data processing | Less efficient processing of large data sets |
| XGBoost | Ensemble learning | Biclassification, multiclassification, and regression problems | High efficiency, flexibility, automatic selection of important features, prevention of overfitting, parallel computation | Less efficient processing of large data sets |
| Catboost | Ensemble learning | Biclassification, multiclassification, and regression problems | Strong ability of handling categorical features, robustness, high performance, GPU acceleration support, automatic feature selection, and friendly treatment of sparse data | Poor robustness of large-scale data and non-linear relationship processing |
| Adaboost | Ensemble learning | Biclassification, multiclassification, and regression problems | Easy to implement and adjust, not easy to overfit, combination with various basic classifiers | Noise sensitive |
| Random Forest | Ensemble learning | Image recognition, data prediction | Parallel processing, stable model, good generalization ability | Noise sensitive, long tree construction time, large memory consumption |
| LightGBM | Ensemble learning | Machine learning and data mining areas | Efficient, distributed structure, and high performance | Noise sensitive |
| Neural Network | Machine learning | Image classification, computer vision, natural language processing | High classification accuracy, strong parallel distributed processing, noise robustness | Extensive parameter adjustment, non-intuitive learning process, and long learning time |
| Name | Manufacturer | Measurement Pattern | Spectral Resolution (cm−1) | Spectral Measurement Range (μm) | Full Field of View Angle |
|---|---|---|---|---|---|
| EM27 | Bruker | Active/Passive | Active: 0.5/1 Passive: 0.5/1/4 | 2.5~12 | 30 mrad (no telescope) (1.7°) |
| Telemetry Fourier Transform Infrared Spectrometer | Aerospace Information Research Institute | Passive | 1 | 2.5~12 | 1.5° |
| Aero-Engine Serial Number | Environmental Temperature | Environmental Humidity | Detection Distance |
|---|---|---|---|
| 1 | 30 °C | 43.5% Rh | 11.8 m |
| 2 | 20 °C | 71.5% Rh | 5 m |
| 3 | 19 °C | 73.5% Rh | 10 m |
| Methods | Parameter Settings |
|---|---|
| SVM | decision_function_shape = ‘ovr’, kernel = ‘rbf’ |
| XGBoost | objective = ‘multi:softmax’, num_classes = num_classes |
| CatBoost | loss_function = ‘MultiClass’ |
| Adaboost | n_estimators = 200 |
| Random Forest | n_estimators = 300 |
| LightGBM | objective’: ‘multiclass’, ‘num_class’: num_classes |
| Neural Network | hidden_layer_sizes = (100), activation = ‘relu’, solver = ‘adam’, max_iter = 200 |
| Forecast Results | |||
|---|---|---|---|
| Positive samples | Negative samples | ||
| Real results | Positive samples | TP | TN |
| Negative samples | FP | FN | |
| Evaluation Criterion | Accuracy | Precision Score | Recall | F1 | Confusion Matrix | Running Time/s | |
|---|---|---|---|---|---|---|---|
| Classification Methods | |||||||
| feature vectors + SVM | 98.04% | 98.77% | 97.78% | 98.22% | 2.48 | ||
| Feature vectors + XGBoost | 98.04% | 98.77% | 97.78% | 98.22% | 2.62 | ||
| Feature vectors + CatBoost | 98.04% | 98.77% | 97.78% | 98.22% | 5.27 | ||
| Feature vectors + AdaBoost | 98.04% | 98.77% | 97.78% | 98.22% | 2.91 | ||
| Feature vectors + Random Forest | 98.04% | 98.77% | 97.78% | 98.22% | 3.09 | ||
| Feature vectors + LightGBM | 96.08% | 96.38% | 96.38% | 96.38% | 2.63 | ||
| Feature vectors + Neural Networks | 80.39% | 76.19% | 90.99% | 76.27% | 2.41 | ||
| Method Order | SVM | XGBoost | CatBoost | AdaBoost | Random Forest | LightGBM | Neural Networks |
|---|---|---|---|---|---|---|---|
| Average value | 97.17% | 97.74% | 98.13% | 98.00% | 98.32% | 98.07% | 74.52% |
| Variance | 0.06% | 0.04% | 0.03% | 0.04% | 0.03% | 0.02% | 1.84% |
| Standard deviation | 2.41% | 1.96% | 1.71% | 1.92% | 1.73% | 1.52% | 13.56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Han, W.; Shi, Z.; Liao, Y.; Li, Z. An Aero-Engine Classification Method Based on Fourier Transform Infrared Spectrometer Spectral Feature Vectors. Electronics 2024, 13, 915. https://doi.org/10.3390/electronics13050915
Du S, Han W, Shi Z, Liao Y, Li Z. An Aero-Engine Classification Method Based on Fourier Transform Infrared Spectrometer Spectral Feature Vectors. Electronics. 2024; 13(5):915. https://doi.org/10.3390/electronics13050915
Chicago/Turabian StyleDu, Shuhan, Wei Han, Zhengyang Shi, Yurong Liao, and Zhaoming Li. 2024. "An Aero-Engine Classification Method Based on Fourier Transform Infrared Spectrometer Spectral Feature Vectors" Electronics 13, no. 5: 915. https://doi.org/10.3390/electronics13050915