
Efficient Vision Transformer YOLOv5 for Accurate and Fast Traffic Sign Detection

Abstract
:1. Introduction
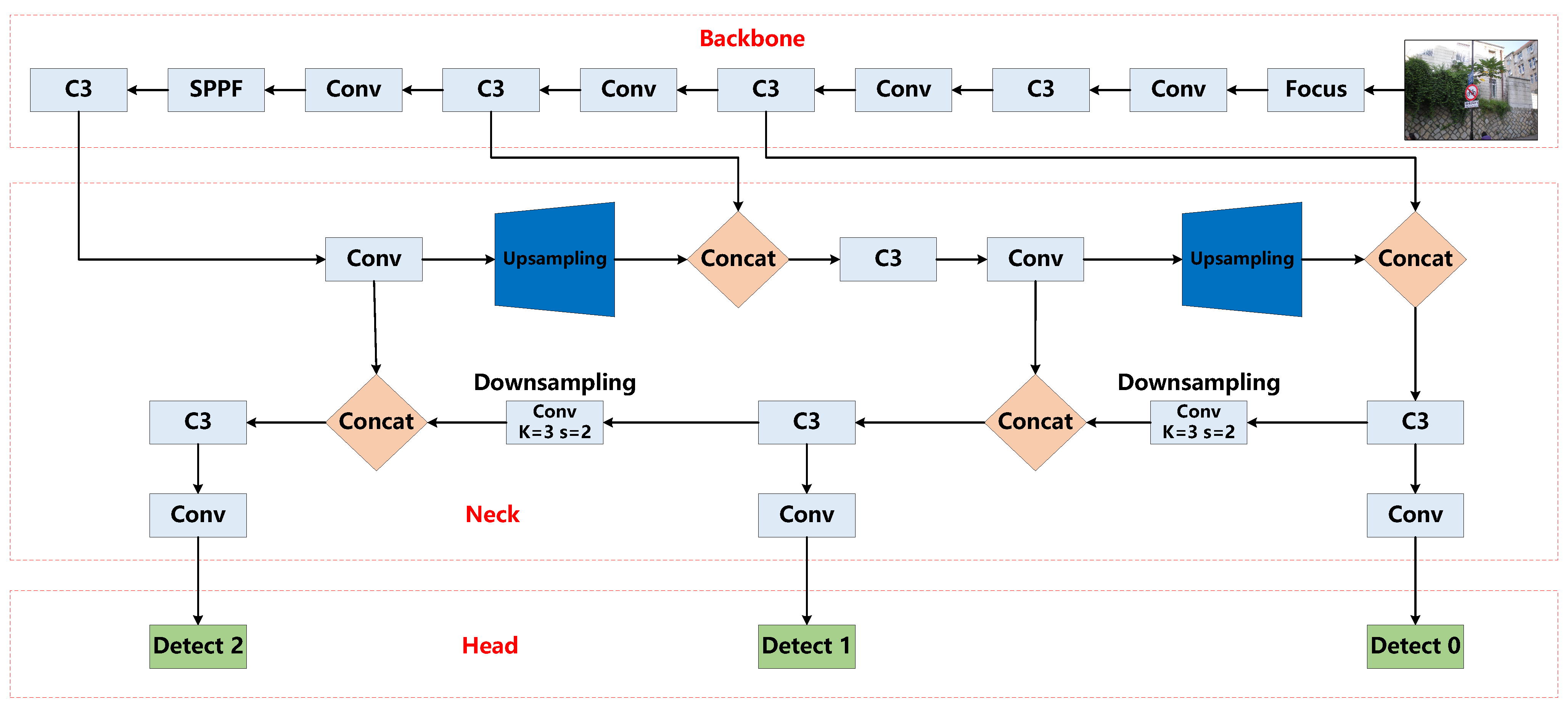
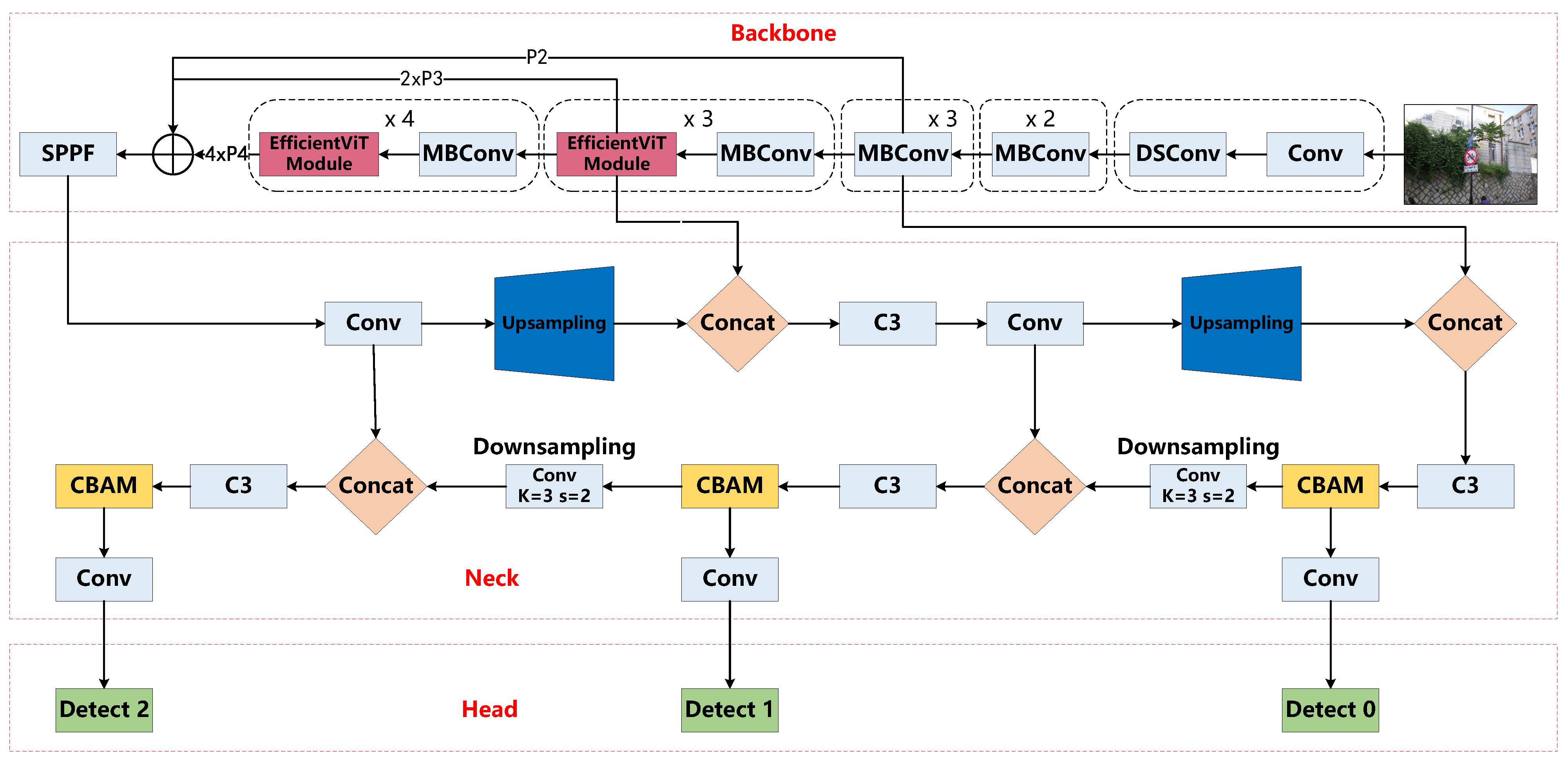
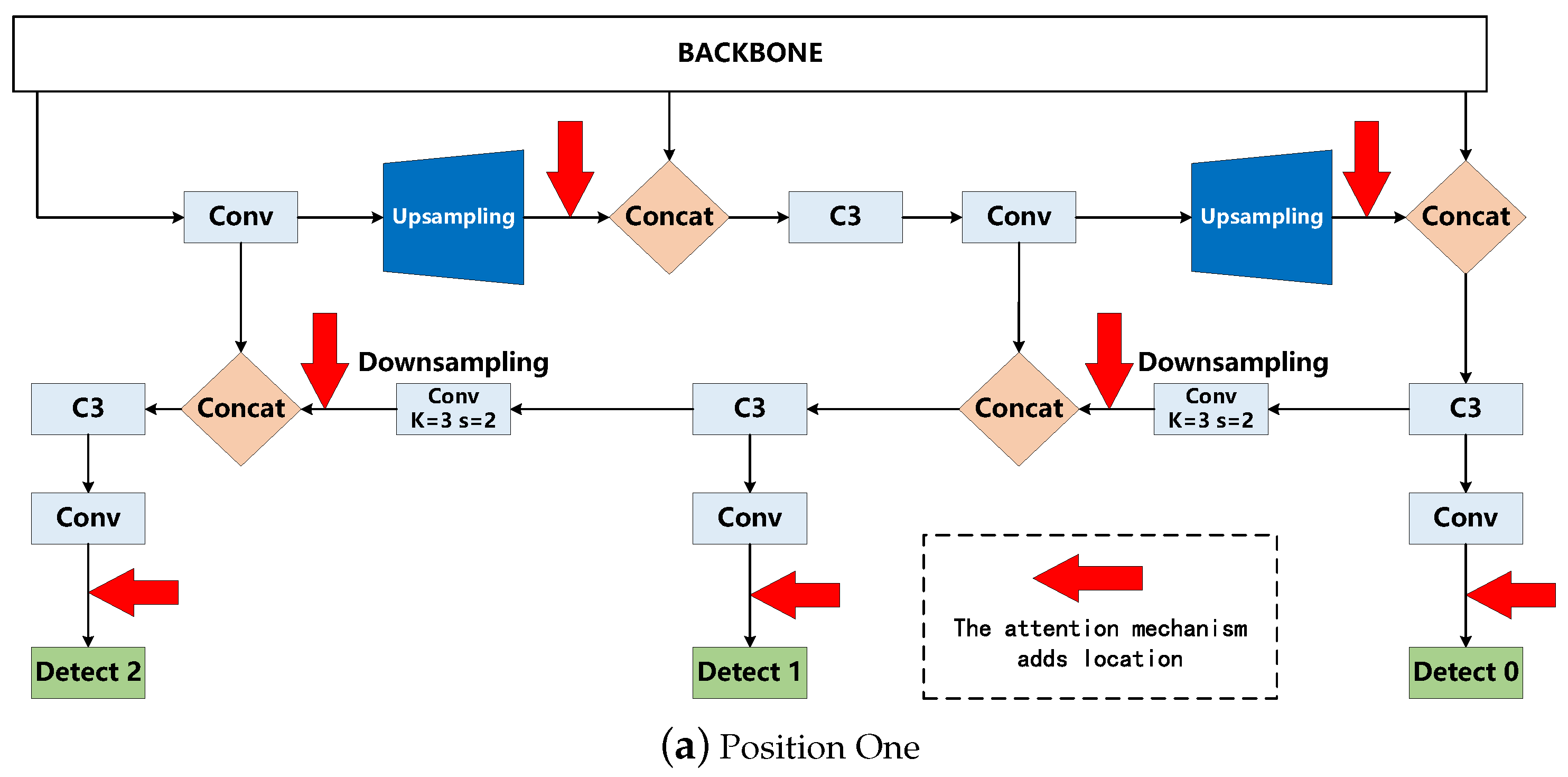
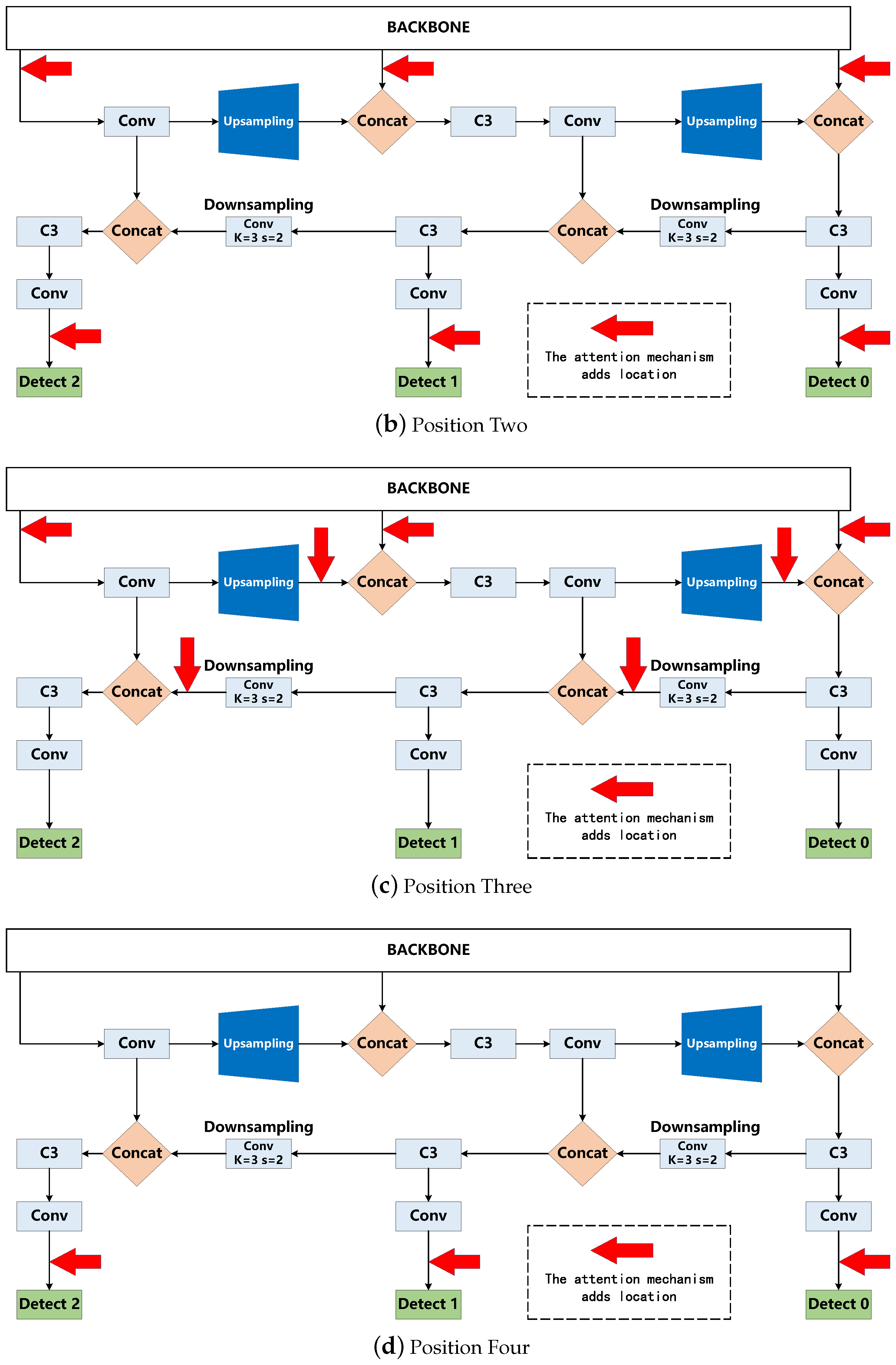
2. The YOLOv5-EfficinetViT Traffic Sign Detection Algorithm’s General Framework
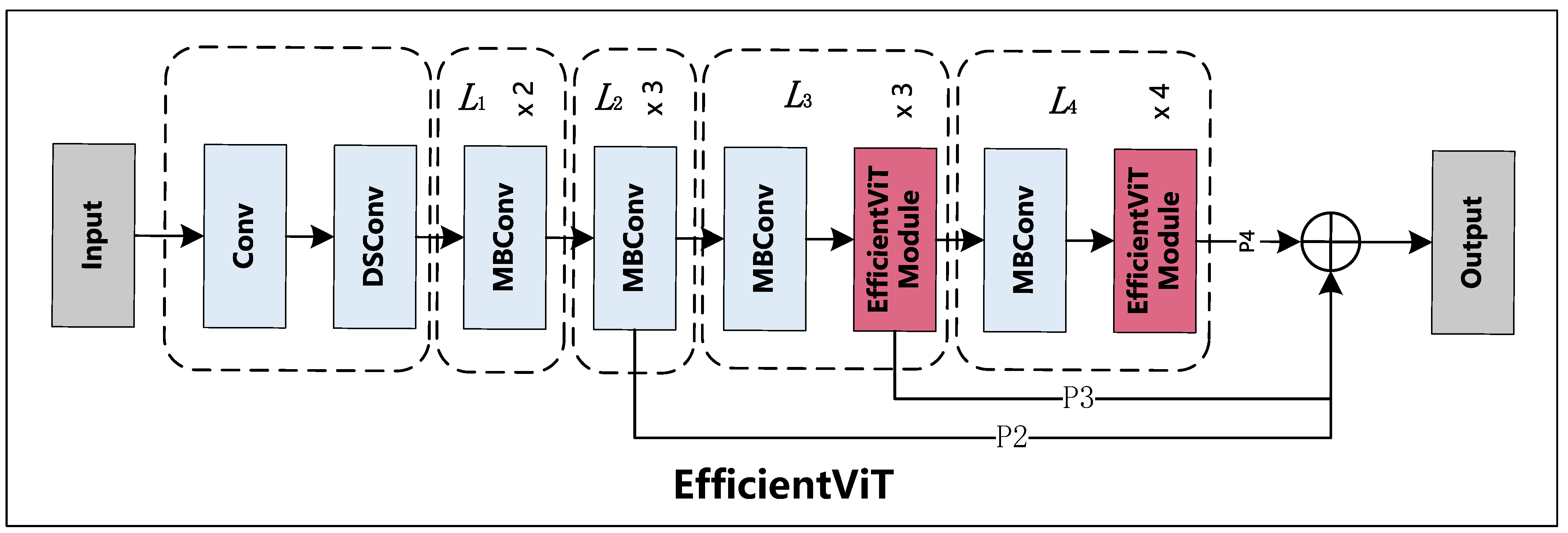
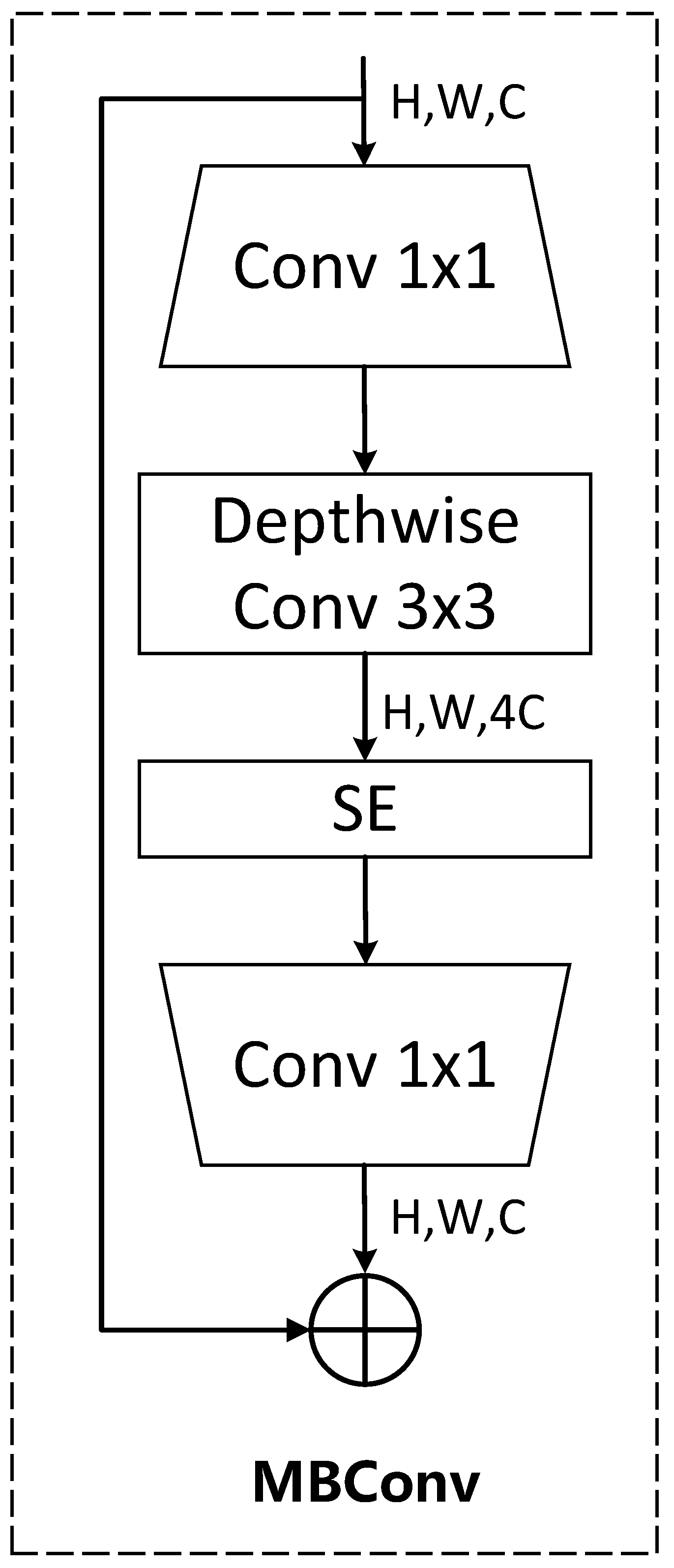
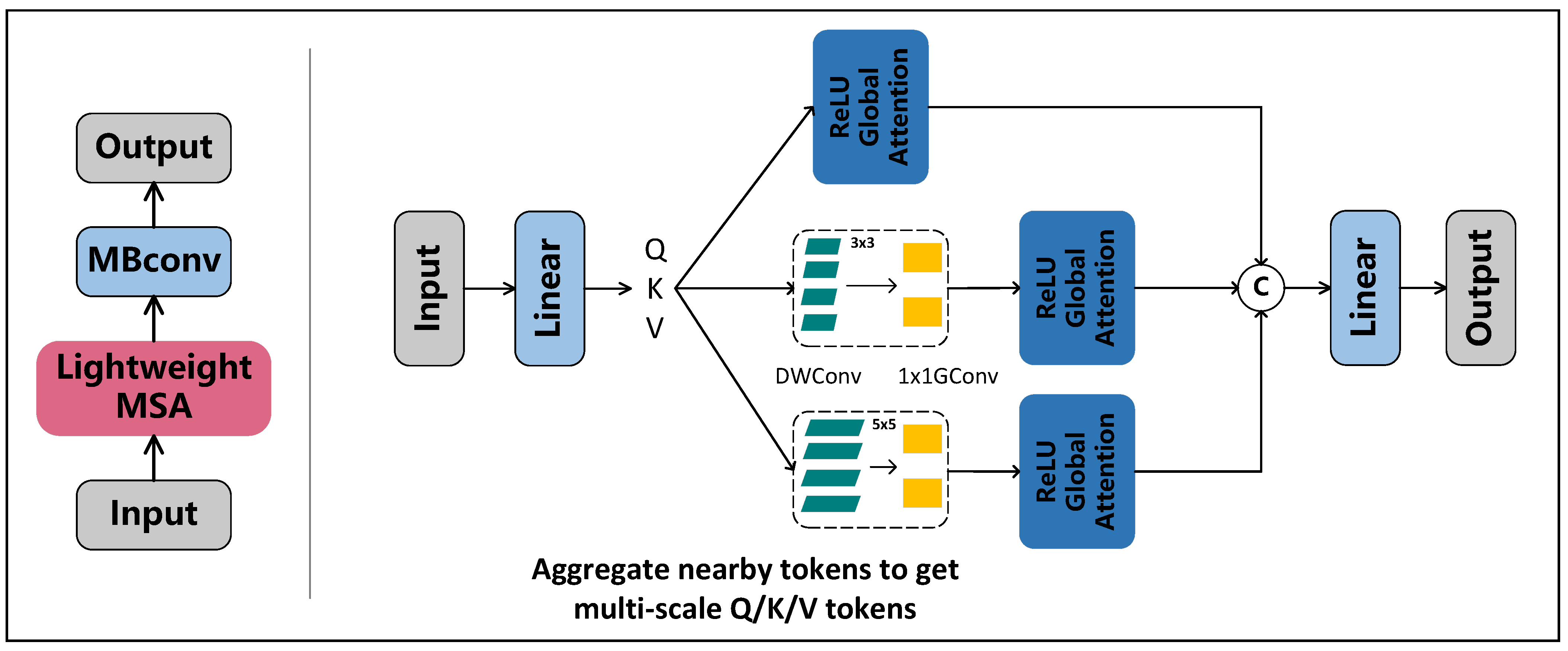
2.1. EfficientViT Backbone
2.2. Attention Mechanism
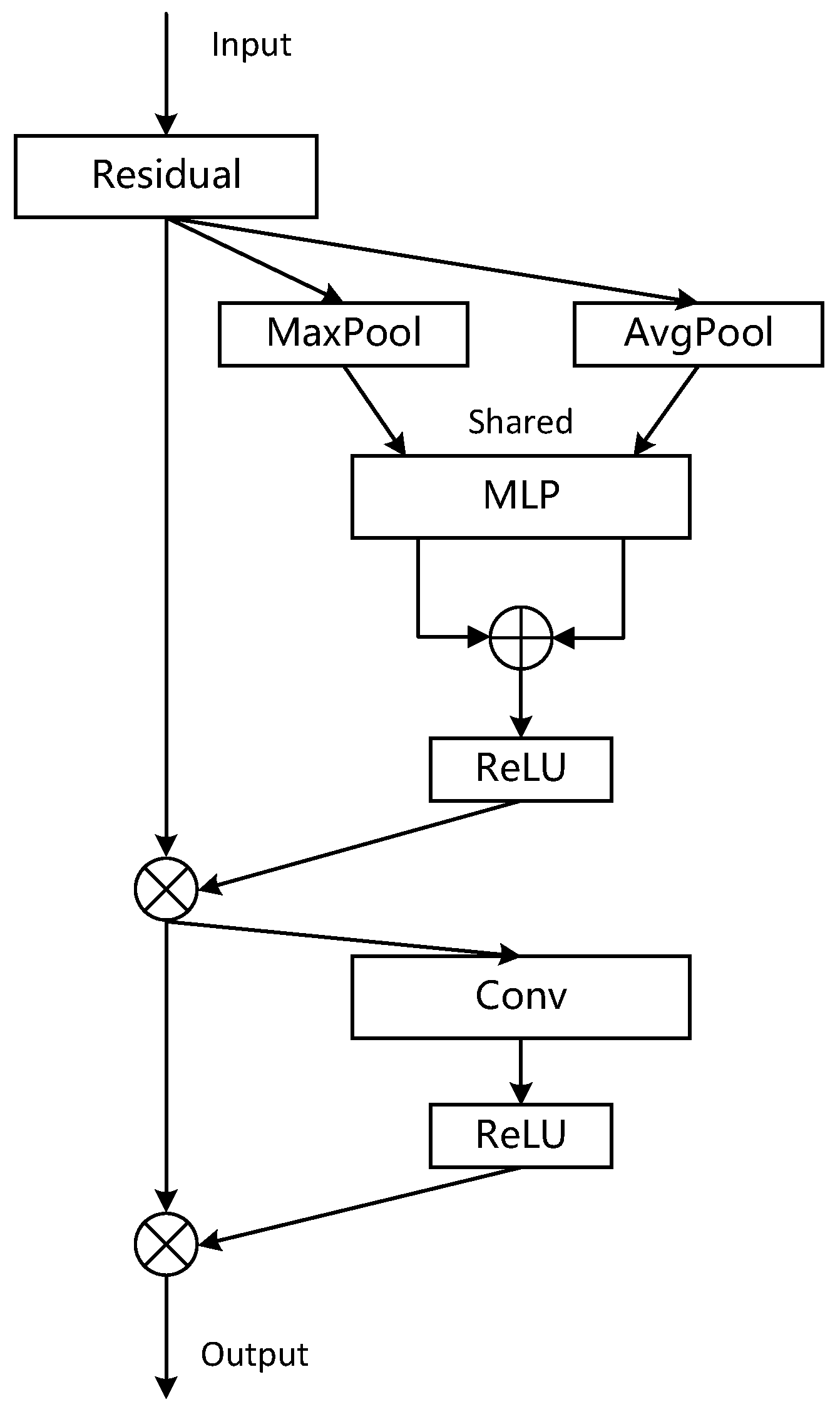
2.2.1. CBAM Attention Mechanism
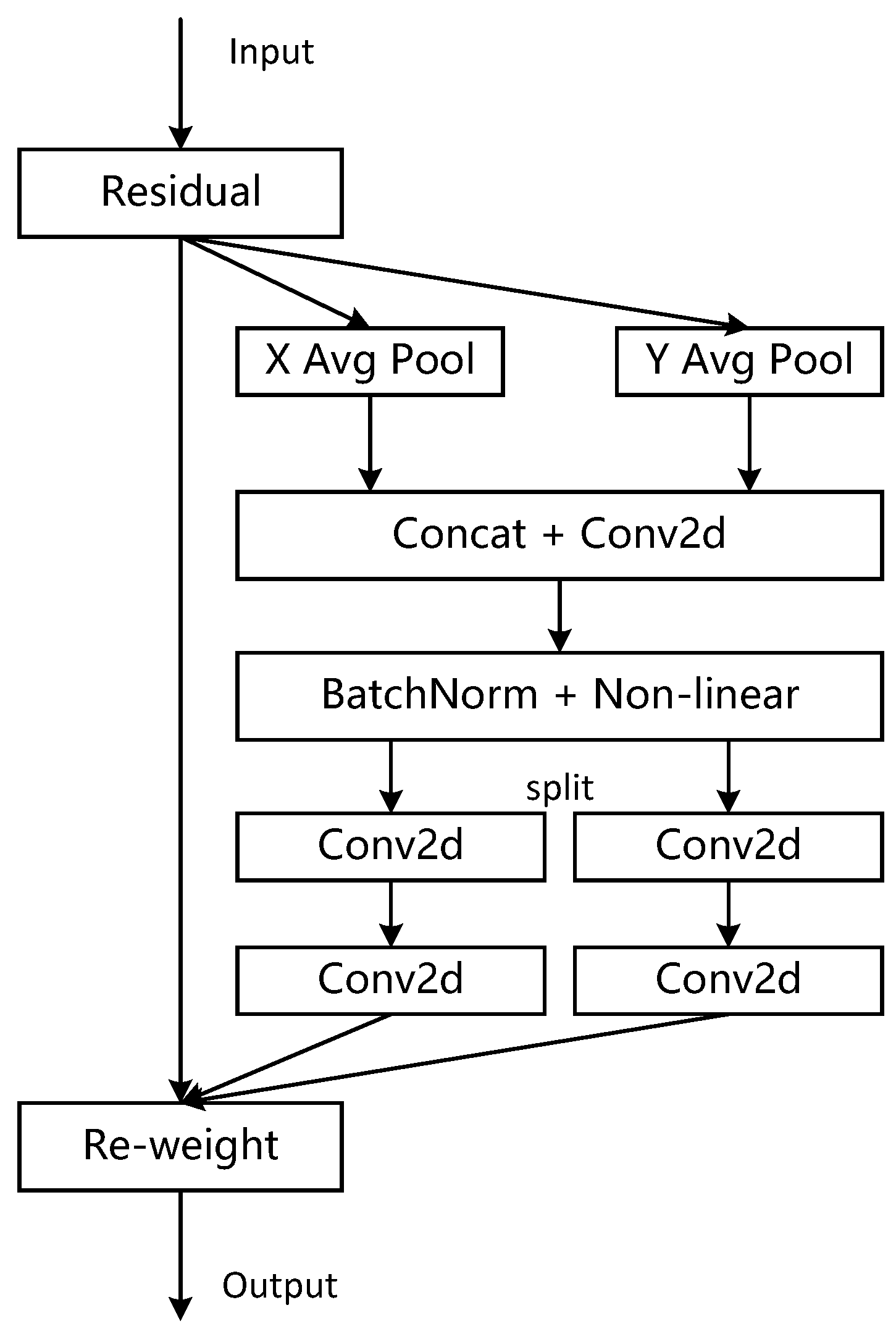
2.2.2. CA Attention Mechanisms
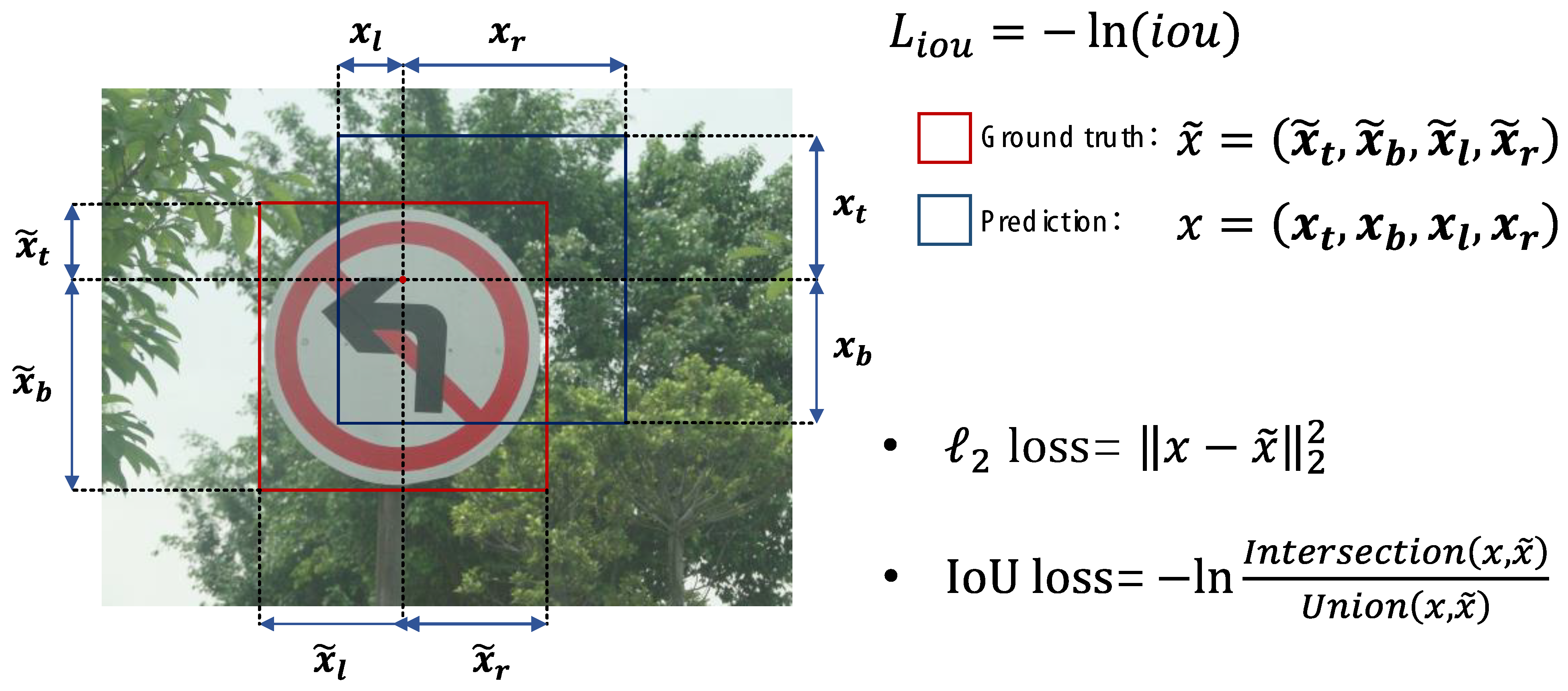
2.3. IoU Loss
2.3.1. EIoU Loss Function
2.3.2. SIoU Loss Function
2.3.3. Wise IoU Loss Function
- ; this will significantly amplify the of the common mass anchor frame.
- ; this will significantly reduce the of high quality anchor frames and significantly reduce their focus on the center distance when the anchor frame is well overlapped with the object frame.
3. Experimental Design
3.1. Experimental Dataset
3.2. Evaluation Metrics
4. Analysis of Experimental Results
4.1. Experimental Environment
4.2. Experimental Setup
4.3. Algorithm Detection Performance Comparison Analysis
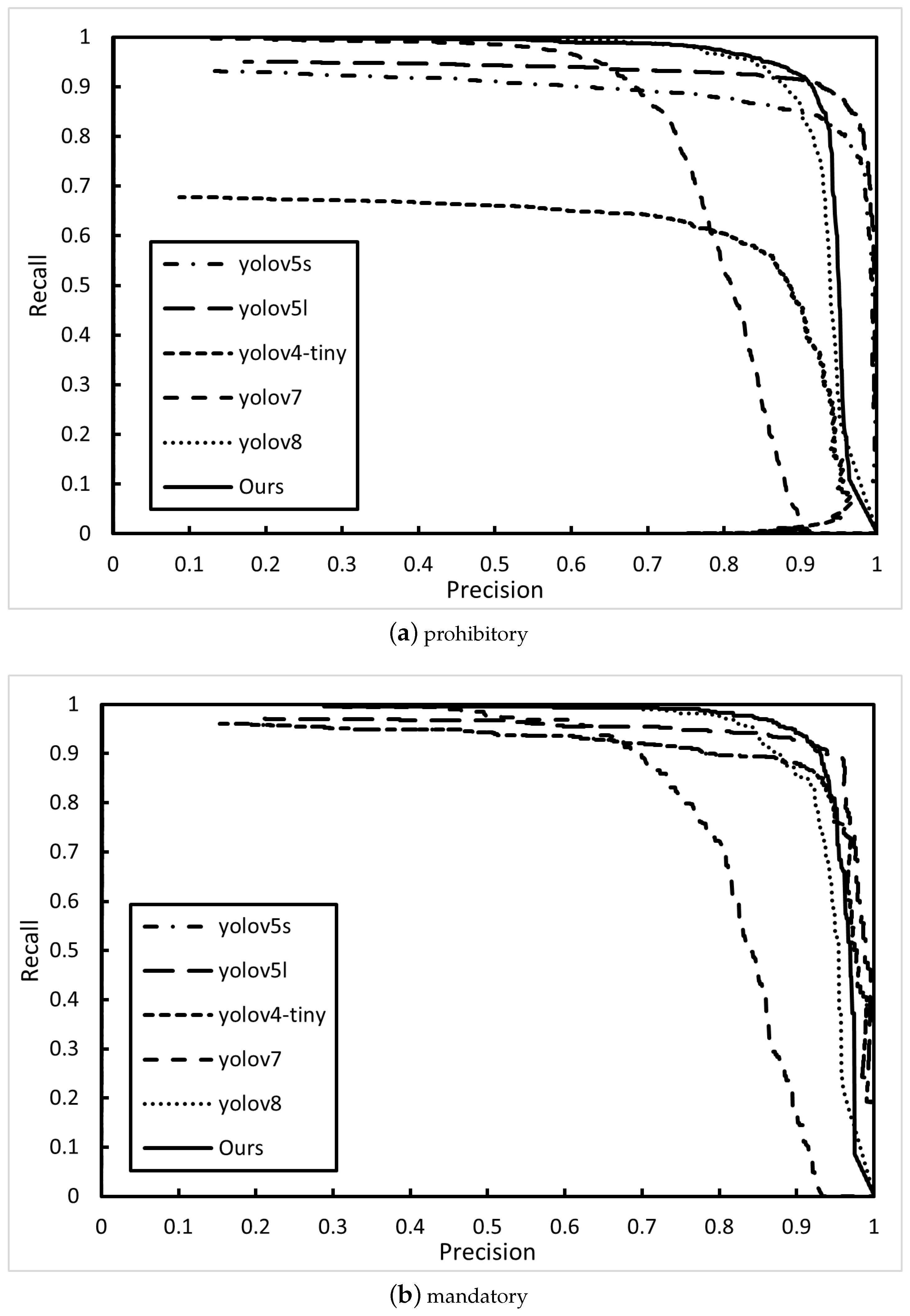
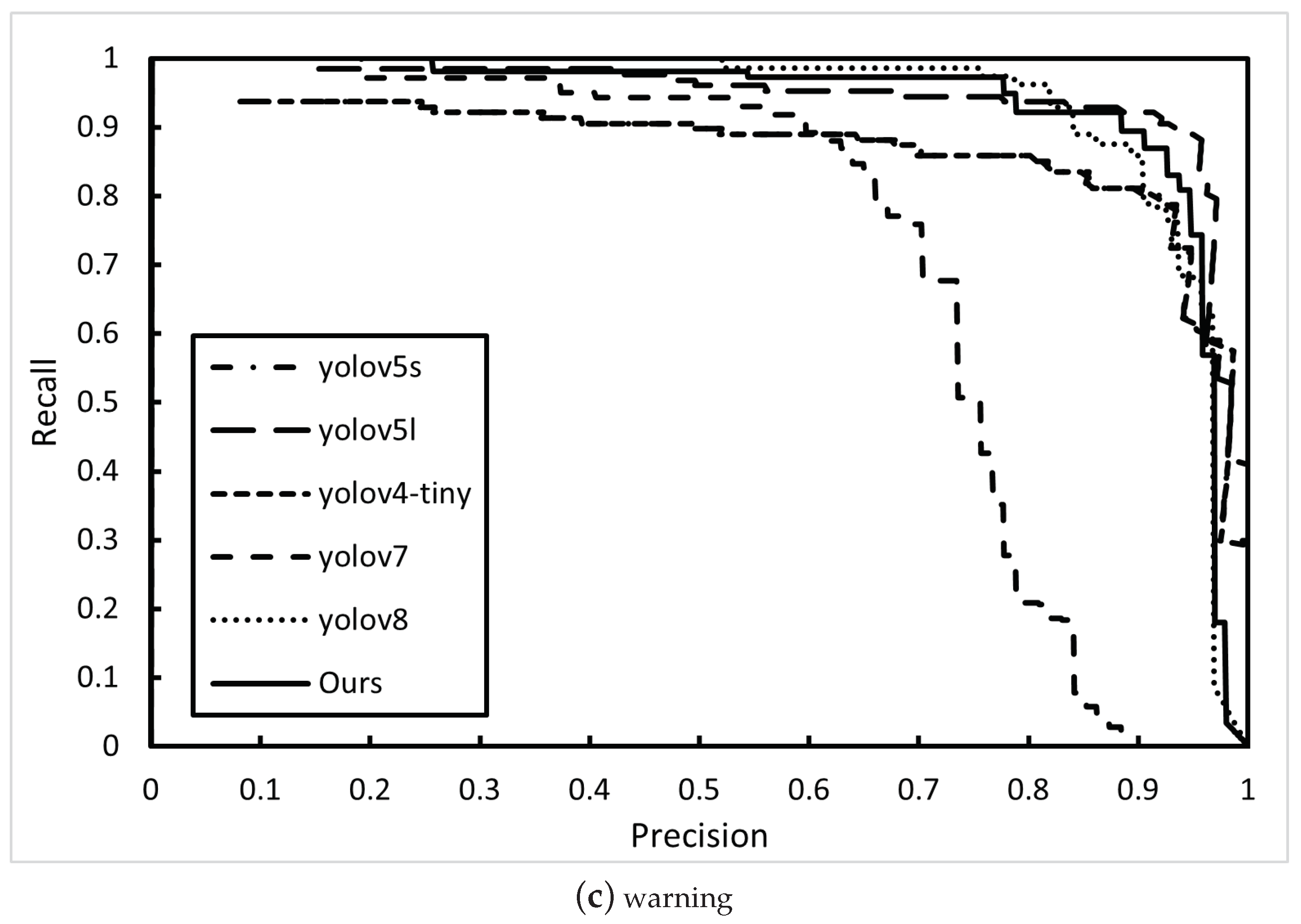
4.3.1. Algorithm P-R Curve Comparison
4.3.2. Comparative Analysis of Algorithm in Real-Time
4.3.3. Comparative Analysis of Algorithmic Ablation Experiments
4.3.4. Comparative Analysis of Experimental Results of Algorithm Detection Accuracy
4.4. Algorithm Detection Performance Comparison Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Wang, J.; Li, Y.; Wang, S. Traffic sign recognition with lightweight two-stage model in complex scenes. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1121–1131. [Google Scholar] [CrossRef]
- Kukkala, V.K.; Tunnell, J.; Pasricha, S.; Bradley, T. Advanced driver-assistance systems: A path toward autonomous vehicles. IEEE Consum. Electron. Mag. 2018, 7, 18–25. [Google Scholar] [CrossRef]
- Nandi, D.; Saif, A.S.; Prottoy, P.; Zubair, K.M.; Shubho, S.A. Traffic sign detection based on color segmentation of obscure image candidates: A comprehensive study. Int. J. Mod. Educ. Comput. Sci. 2018, 10, 35. [Google Scholar] [CrossRef]
- Zaklouta, F.; Stanciulescu, B. Real-time traffic sign recognition in three stages. Robot. Auton. Syst. 2014, 62, 16–24. [Google Scholar] [CrossRef]
- Vitabile, S.; Pollaccia, G.; Pilato, G.; Sorbello, F. Road signs recognition using a dynamic pixel aggregation technique in the HSV color space. In Proceedings of the Proceedings 11th International Conference on Image Analysis and Processing, Palermo, Italy, 26–28 September 2001; pp. 572–577. [Google Scholar]
- Yakimov, P.; Fursov, V. Traffic signs detection and tracking using modified hough transform. In Proceedings of the 2015 12th International Joint Conference on e-Business and Telecommunications (ICETE), Colmar, France, 20–22 July 2015; Volume 5, pp. 22–28. [Google Scholar]
- Balali, V.; Jahangiri, A.; Machiani, S.G. Multi-class US traffic signs 3D recognition and localization via image-based point cloud model using color candidate extraction and texture-based recognition. Adv. Eng. Inform. 2017, 32, 263–274. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Gao, B.; Jiang, Z.; Zhang, J. Traffic Sign Detection based on SSD. In Proceedings of the 2019 4th International Conference on Automation, Control and Robotics Engineering, Shenzhen, China, 19–21 July 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Qian, R.; Liu, Q.; Yue, Y.; Coenen, F.; Zhang, B. Road surface traffic sign detection with hybrid region proposal and fast R-CNN. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 555–559. [Google Scholar]
- Zuo, Z.; Yu, K.; Zhou, Q.; Wang, X.; Li, T. Traffic signs detection based on faster r-cnn. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), Atlanta, GA, USA, 5–8 June 2017; pp. 286–288. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cai, H.; Gan, C.; Han, S. EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation Visual Recognition. arXiv 2022, arXiv:2205.14756. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Liu, H.; Zhou, K.; Zhang, Y.; Zhang, Y. ETSR-YOLO: An improved multi-scale traffic sign detection algorithm based on YOLOv5. PLoS ONE 2023, 18, e0295807. [Google Scholar] [CrossRef] [PubMed]
- Chu, J.; Zhang, C.; Yan, M.; Zhang, H.; Ge, T. TRD-YOLO: A real-time, high-performance small traffic sign detection algorithm. Sensors 2023, 23, 3871. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.J.; Fang, J.J.; Liu, Y.X.; Feng Le, H.; Rao, Z.Q.; Zhao, J.X. CR-YOLOv8: Multiscale object detection in traffic sign images. IEEE Access 2023, 12, 219–228. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Quantity (pcs) |
|---|---|
| prohibitory | 16,745 |
| mandatory | 4539 |
| warning | 1241 |
| Optimizer | Batch-Size | Learning Rate | mAp@0.5% |
|---|---|---|---|
| SGD | 32 | 0.01 | 94.0% |
| SGD | 64 | 0.01 | 93.9% |
| SGD | 32 | 0.001 | 89.1% |
| Adam | 32 | 0.01 | 84.1% |
| Adam | 64 | 0.01 | 80.8% |
| Adam | 32 | 0.001 | 92.5% |
| AdamW | 32 | 0.01 | 93.2% |
| AdamW | 64 | 0.01 | 92.9% |
| AdamW | 32 | 0.001 | 92.0% |
| GA(SGD) | 32 | 0.0136 | 94.1% |
| Algorithm | Parameters | Prohibitory | Mandatory | Warning |
|---|---|---|---|---|
| YOLOv5(s) | P | 95.87% | 94.64% | 93.00% |
| R | 80.08% | 79.85% | 73.23% | |
| YOLOv5(l) | P | 96.05% | 96.25% | 95.54% |
| R | 86.43% | 87.01% | 84.25% | |
| YOLOv4-tiny | P | 76.72% | 75.27% | 81.73% |
| R | 61.52% | 65.35% | 66.93% | |
| YOLOv7 | P | 89.4% | 91.7% | 67.6% |
| R | 68.7% | 67.6% | 73.3% | |
| YOLOv8 | P | 92.8% | 92.9% | 87.4% |
| R | 84.9% | 84.9% | 89.4% | |
| YOLOv5-EfficientViT(Ours) | P | 93.50% | 93.70% | 88.10% |
| R | 88.3% | 90.6% | 90.4% |
| Algorithm | FPS (frame/s) |
|---|---|
| YOLOv5(s) | 44.47 |
| YOLOv5(l) | 39.30 |
| YOLOv4-tiny | 122.06 |
| YOLOv7 | 64.52 |
| YOLOv8 | 65.70 |
| YOLOv5-EfficientViT(Ours) | 62.50 |
| Number | Backbone | Attention Mechanisms | IoU Loss | mAP@0.5% | FPS (frame/s) |
|---|---|---|---|---|---|
| 1 | Mobilenetv3 | - | - | 83.2 % | 85.47 |
| 2 | EfficientFormerv2(s1) | - | - | 92.7 % | 32.26 |
| 3 | EfficientFormerv2(l) | - | - | 94.4% | 29.59 |
| 4 | EMO(1M) | - | - | 93.5 % | 60.61 |
| 5 | EMO(6M) | - | - | 93.7 % | 54.05 |
| 6 | EfficientViT(b1) | - | - | 93.7 % | 62.89 |
| 7 | EfficientViT(b2) | - | - | 93.8 % | 53.19 |
| 8 | EfficientViT(b1) | CA(a) | - | 92.5 % | 56.50 |
| 9 | EfficientViT(b1) | CA(b) | - | 93.4 % | 56.50 |
| 10 | EfficientViT(b1) | CA(c) | - | 92.5 % | 55.56 |
| 11 | EfficientViT(b1) | CA(d) | - | 92 % | 52.36 |
| 12 | EfficientViT(b1) | CBAM(a) | - | 93.7 % | 54.64 |
| 13 | EfficientViT(b1) | CBAM(b) | - | 93% | 57.14 |
| 14 | EfficientViT(b1) | CBAM(c) | - | 93.4 % | 53.48 |
| 15 | EfficientViT(b1) | CBAM(d) | - | 93.8% | 62.11 |
| 16 | EfficientViT(b1) | - | SIoU | 90.8 % | 71.94 |
| 17 | EfficientViT(b1) | - | EIOU | 91.2% | 67.57 |
| 18 | EfficientViT(b1) | - | Wise IoU | 93.9% | 63.29 |
| 19 | EfficientViT(Ours) | CBAM(d) | Wise IoU | 94.1% | 62.50 |
| Algorithm | Prohibitory AP | Mandatory AP | Warnin AP | mAP |
|---|---|---|---|---|
| YOLOv5(s) | 89.37% | 91.33% | 87.32% | 89.34% |
| YOLOv5(l) | 93.11% | 94.51% | 94.69% | 94.1% |
| YOLOv4-tiny | 60.29% | 60.01% | 67.76% | 62.69% |
| YOLOv7 | 78.8% | 81.6% | 72.2% | 77.6% |
| YOLOv8 | 91.7% | 92.6% | 92.5% | 92.3% |
| ETSR-YOLO | - | - | - | 88.3% |
| TRD-YOLO | - | - | - | 86.3% |
| CR-YOLOv8 | - | - | - | 86.9% |
| YOLOv5-EfficientViT(Ours) | 93.7% | 95.4% | 93.2% | 94.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, G.; Wu, Z.; Xu, L.; Liang, Y. Efficient Vision Transformer YOLOv5 for Accurate and Fast Traffic Sign Detection. Electronics 2024, 13, 880. https://doi.org/10.3390/electronics13050880
Zeng G, Wu Z, Xu L, Liang Y. Efficient Vision Transformer YOLOv5 for Accurate and Fast Traffic Sign Detection. Electronics. 2024; 13(5):880. https://doi.org/10.3390/electronics13050880
Chicago/Turabian StyleZeng, Guang, Zhizhou Wu, Lipeng Xu, and Yunyi Liang. 2024. "Efficient Vision Transformer YOLOv5 for Accurate and Fast Traffic Sign Detection" Electronics 13, no. 5: 880. https://doi.org/10.3390/electronics13050880