
Facial Beauty Prediction Combined with Multi-Task Learning of Adaptive Sharing Policy and Attentional Feature Fusion


Abstract
:1. Introduction
- We extend the AdaShare network, introduce DAB to solve the issue of distribution differences between different databases in multi-task learning on FBP and apply the network in various databases.
- We propose multi-task learning of an adaptive sharing policy combined with AFF to solve the issue of insufficient label information and overfitting for FBP, in which the receptive field is expanded, and more semantic information is obtained from the images.
- The experimental results show that multi-task learning of the adaptive sharing policy combined with AFF outperforms the baseline model and the other method on FBP.
2. Methods
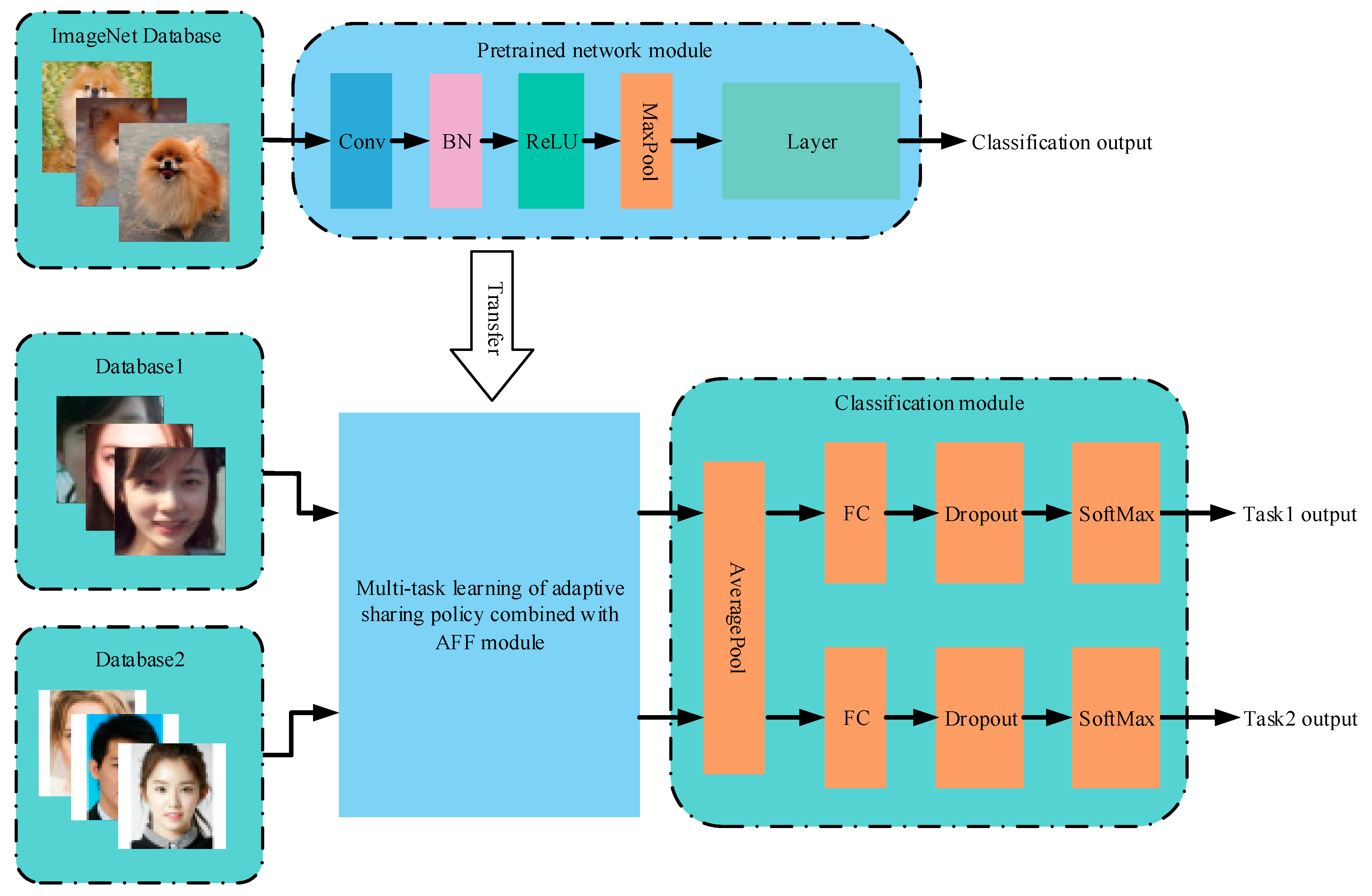
2.1. Network Model
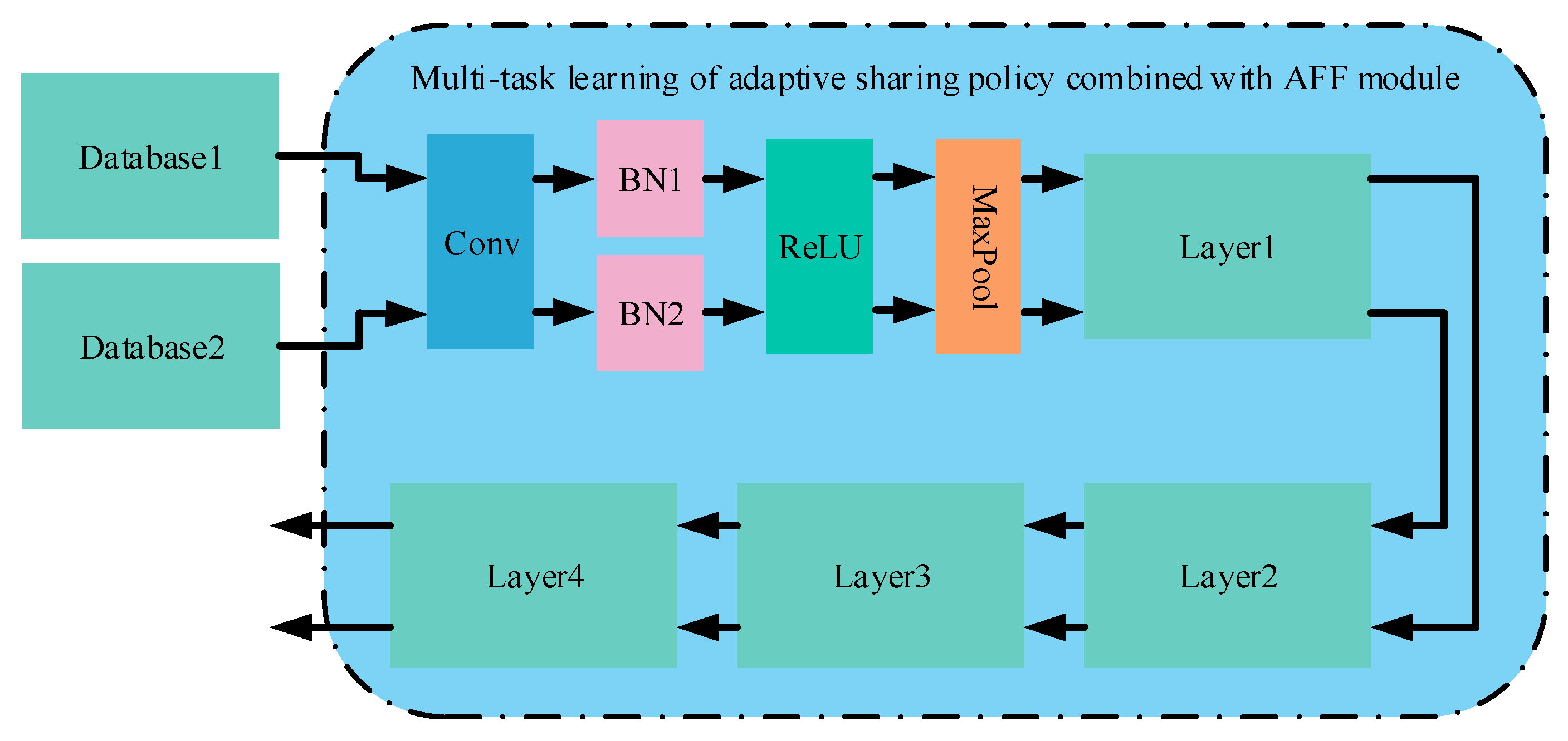
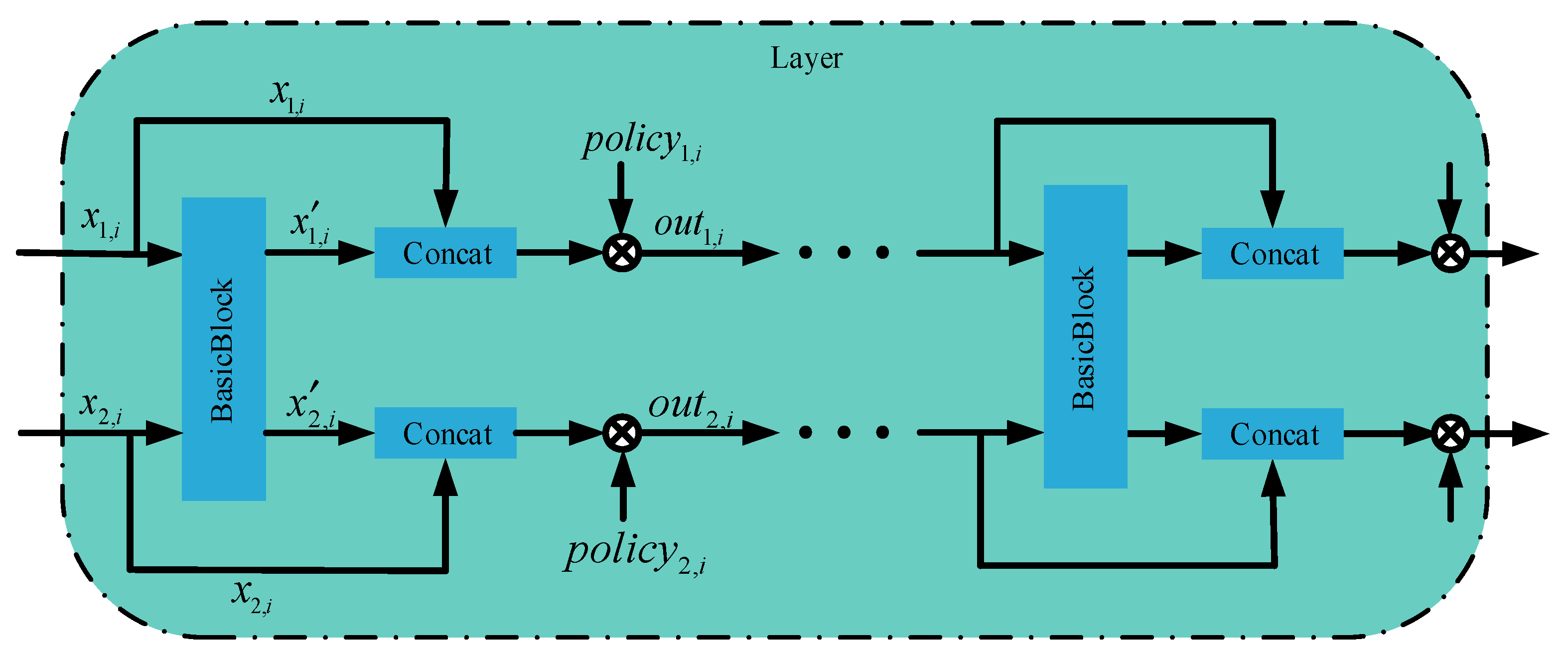
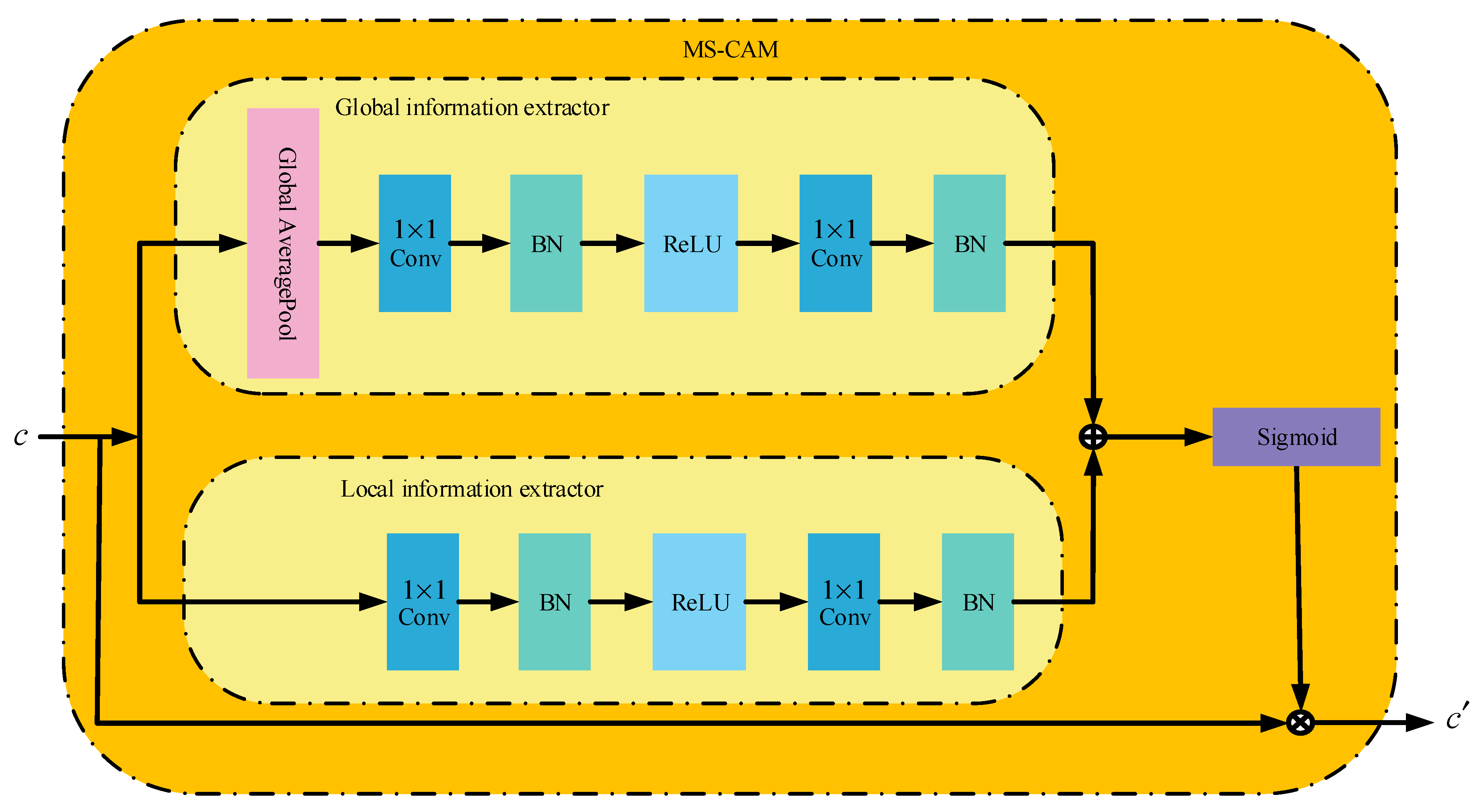
2.2. Multi-Task Learning of Adaptive Sharing Policy Combined with AFF Module
| Algorithm 1 Facial beauty prediction via adaptive sharing policy |
| Input: sample set Output: output set 1: is the number of layers in the backbone; 2: is the number of blocks in each layer; 3: is the adaptive policy of the current layer; 4: indicates the BasicBlock structure; 5: indicates the concatenation and multiplication; 6: for , do 7: for , do 8: 9: 10: end 11: end |
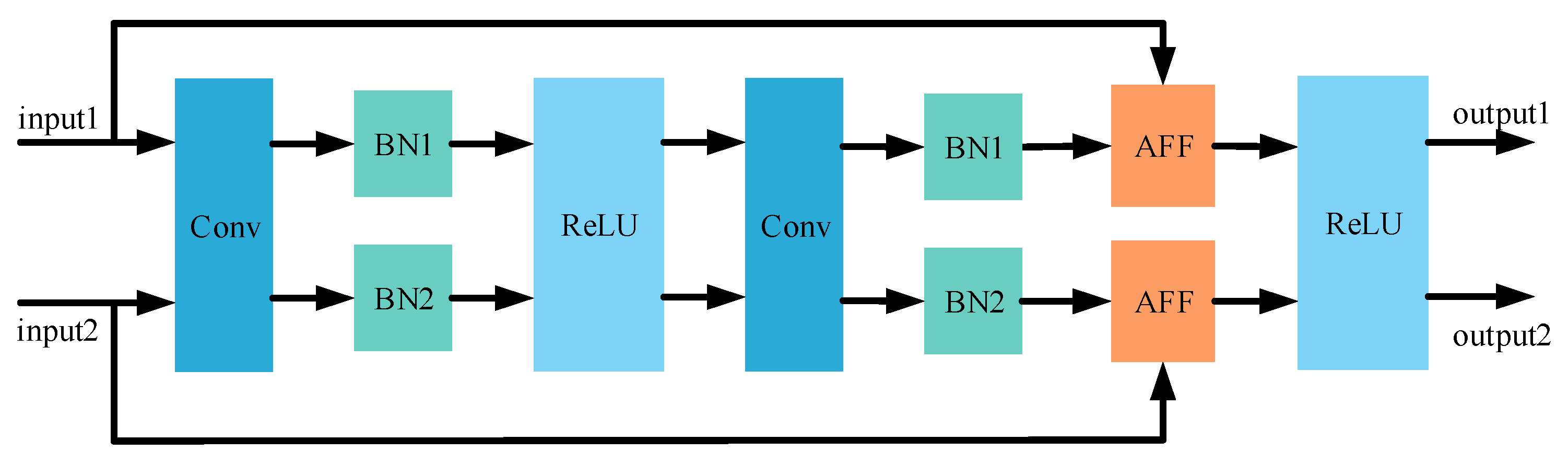
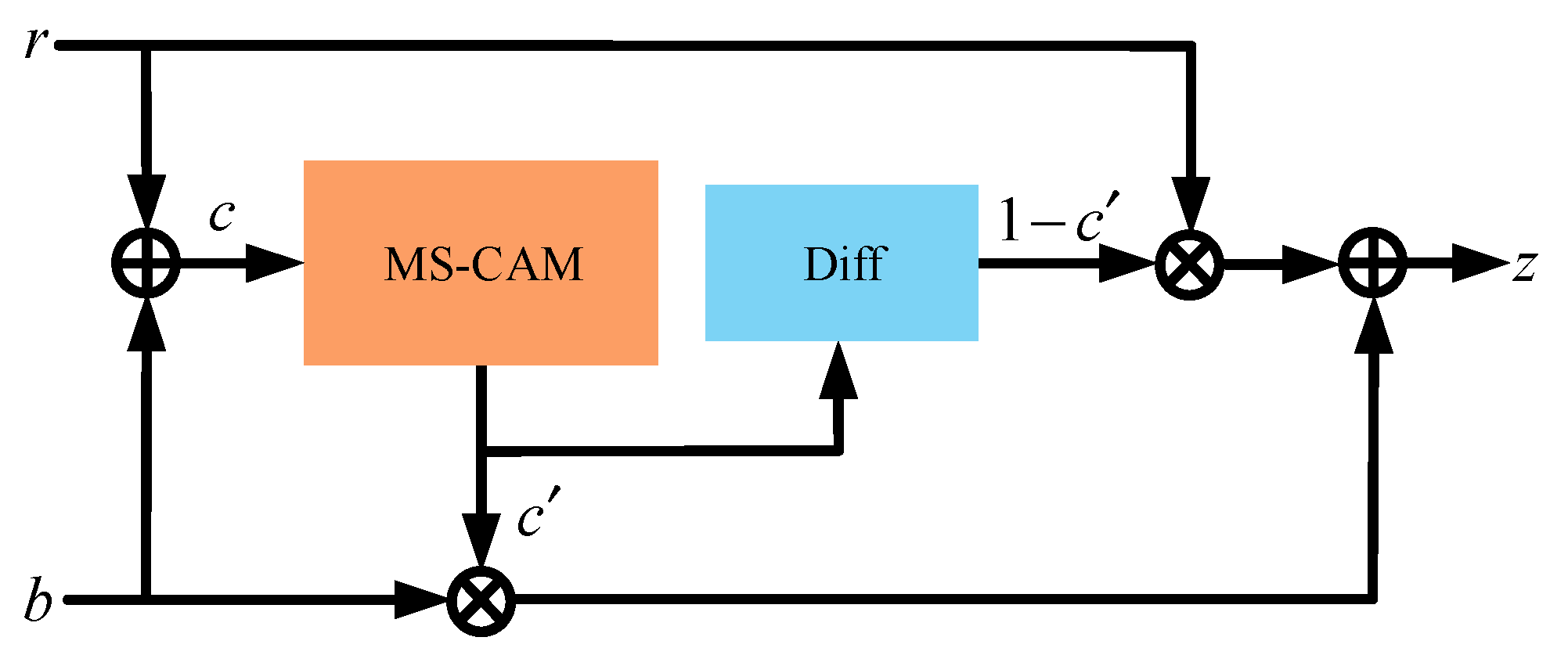
2.3. Attentional Feature Fusion
2.4. Loss Function
3. Experiments and Analysis
3.1. Experimental Databases
3.1.1. LSAFBD Database
3.1.2. SCUT-FBP5500 Database
3.2. Experimental Environment
3.3. Comparison Experiment between the Proposed Method and the Baseline
3.3.1. Experiments Based on Different Databases
3.3.2. Experiments with Different Weight Ratios Based on Different Databases
3.4. Comparison Experiments between the Proposed Method and Other Models
3.5. Comparison Experiments between the Proposed Method and Other Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lebedeva, I.; Ying, F.; Guo, Y. Personalized facial beauty assessment: A meta-learning approach. Vis. Comput. 2023, 39, 1095–1107. [Google Scholar] [CrossRef]
- Gan, J.; Wu, B.; Zhai, Y.; He, G.; Mai, C.; Bai, Z. Self-correcting noise labels for facial beauty prediction. Chin. J. Image Graph. 2022, 27, 2487–2495. [Google Scholar]
- Gan, J.; Wu, B.; Zou, Q.; Zheng, Z.; Mai, C.; Zhai, Y.; He, G.; Bai, Z. Application Research for Fusion Model of Pseudolabel and Cross Network. Comput. Intell. Neurosci. 2022, 2022, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Gan, J.; Xie, X.; Zhai, Y.; He, G.; Mai, C.; Luo, H. Facial beauty prediction fusing transfer learning and broad learning system. Soft Comput. 2023, 27, 13391–13404. [Google Scholar] [CrossRef]
- Gan, J.; Xie, X.; He, G.; Luo, H. TransBLS: Transformer combined with broad learning system for facial beauty prediction. Appl. Intell. 2023, 53, 26110–26125. [Google Scholar] [CrossRef]
- Liu, Q.; Lin, L.; Shen, Z.; Yu, Y. FBPFormer: Dynamic Convolutional Transformer for Global-Local-Contexual Facial Beauty Prediction. In Proceedings of the Artificial Neural Networks and Machine Learning (ICANN), Heraklion, Greece, 26–29 September 2023; pp. 223–235. [Google Scholar] [CrossRef]
- Laurinavičius, D.; Maskeliūnas, R.; Damaševičius, R. Improvement of Facial Beauty Prediction Using Artificial Human Faces Generated by Generative Adversarial Network. Cogn. Comput. 2023, 15, 998–1015. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, Y. NAS4FBP: Facial Beauty Prediction Based on Neural Architecture Search. In Proceedings of the Artificial Neural Networks and Machine Learning (ICANN), Bristol, UK, 6–9 September 2022; pp. 225–236. [Google Scholar]
- Bougourzi, F.; Dornaika, F.; Taleb-Ahmed, A. Deep learning based face beauty prediction via dynamic robust losses and ensemble regression. Knowl.-Based Syst. 2022, 242, 108246–108251. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, X.; Guan, H. AutoMTL: A Programming Framework for Automating Efficient Multi-task Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeuraIPS), New Orleans, LA, USA, 28 November–9 December 2022; pp. 34216–34228. [Google Scholar]
- Li, H.; Wang, Y.; Lyu, Z.; Shi, J. Multi-task learning for recommendation over heterogeneous information network. IEEE Trans. Knowl. Data Eng. 2020, 34, 789–802. [Google Scholar] [CrossRef]
- Fan, X.; Wang, H.; Zhao, Y.; Li, Y.; Tsui, K.L. An adaptive weight learning-based multi-task deep network for continuous blood pressure estimation using electrocardiogram signals. Sensors 2021, 21, 1595. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Shui, C.; Abbasi, M.; Robitaille, L.-E.; Wang, B.; Gagne, C. Task similarity estimation through adversarial multi-task neural network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 466–480. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Panda, R.; Feris, R.; Saenko, K. AdaShare: Learning What to Share for Efficient Deep Multi-task Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeuraIPS), Virtual, 6–12 December 2020; pp. 8728–8740. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 3559–3568. [Google Scholar]
- Wang, L.; Li, D.; Liu, H.; Peng, J.; Tian, L.; Shan, Y. Cross-dataset collaborative learning for semantic segmentation in autonomous driving. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 2487–2494. [Google Scholar]
- Kapidis, G.; Poppe, R.; Veltkamp, R.C. Multi-Dataset, Multi-task Learning of Egocentric Vision Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6618–6630. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-Softmax. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Parameters |
|---|---|
| Deep learning framework | Pytorch1.12.1 |
| Operating system | Ubuntu20.04 |
| Memory | 64 G |
| Channels | 64 |
| 1:0.6 | |
| Learning rate | 0.001 |
| Batch size | 32 |
| Optimizer | AdamW |
| Experiment Settings | Explanation |
|---|---|
| Database1 | LSAFBD |
| Database2 | SCUT-FBP5500 |
| Task1 | FBP |
| Task2 | GR |
| Batch Size | Method | Baseline without AFF | Baseline with AFF | Ours without AFF | Ours with AFF | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ||
| 32 | FBP | 58.01 | 56.51 | 59.52 | 57.70 | 59.12 | 57.72 | 61.37 | 59.72 | |
| 16 | FBP | 58.02 | 56.53 | 59.77 | 57.76 | 59.02 | 57.62 | 61.12 | 59.53 | |
| Batch Size | Method | Ours without AFF | Ours with AFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | Training Time | Training ACC | Testing ACC | Difference of ACC | Training Time | Training ACC | Testing ACC | Difference of ACC | ||
| 32 | FBP | 2976.04 | 63.42 | 59.12 | 4.30% | 3867.85 | 63.49 | 61.37 | 2.12% | |
| 16 | FBP | 3555.86 | 63.12 | 59.02 | 4.10% | 4587.81 | 63.31 | 61.12 | 2.19% | |
| Batch Size | Method | Baseline without AFF | Baseline with AFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | Training Time | Training ACC | Testing ACC | Difference of ACC | Training Time | Training ACC | Testing ACC | Difference of ACC | ||
| 32 | FBP | 637.23 | 65.03 | 58.01 | 7.02% | 853.19 | 61.61 | 59.52 | 2.09% | |
| 16 | FBP | 800.91 | 65.28 | 58.02 | 7.26% | 1154.07 | 61.72 | 59.77 | 1.95% | |
| Batch Size | Method | Baseline without AFF | Baseline with AFF | Ours without AFF | Ours with AFF | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ||
| 32 | FBP | 73.41 | 70.64 | 74.50 | 71.72 | 74.23 | 72.02 | 75.41 | 73.82 | |
| GR | 98.27 | 98.26 | 98.55 | 98.55 | 96.52 | 96.52 | 97.09 | 97.09 | ||
| 16 | FBP | 73.67 | 70.13 | 74.61 | 71.91 | 73.95 | 71.91 | 75.13 | 73.27 | |
| GR | 98.45 | 98.45 | 98.73 | 98.73 | 96.43 | 96.40 | 96.89 | 96.88 | ||
| Batch Size | Method | Ours without AFF | Ours with AFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | Training Time | Training ACC | Testing ACC | Difference of ACC | Training Time | Training ACC | Testing ACC | Difference of ACC | ||
| 32 | FBP | 1587.81 | 77.68 | 74.23 | 3.45 | 2073.85 | 76.84 | 75.41 | 1.43 | |
| GR | 97.36 | 96.52 | 0.84 | 97.63 | 97.09 | 0.54 | ||||
| 16 | FBP | 1894.58 | 77.49 | 73.95 | 3.54 | 3076.09 | 76.44 | 75.13 | 1.31 | |
| GR | 97.13 | 96.43 | 0.70 | 97.50 | 96.89 | 0.61 | ||||
| Batch Size | Method | Baseline without AFF | Baseline with AFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task | Training Time | Training ACC | Testing ACC | Difference of ACC | Training Time | Training ACC | Testing ACC | Difference of ACC | ||
| 32 | FBP | 372.69 | 80.47 | 73.41 | 7.06 | 482.48 | 75.11 | 74.50 | 0.61 | |
| GR | 362.23 | 98.49 | 98.27 | 0.22 | 484.57 | 98.64 | 98.55 | 0.09 | ||
| 16 | FBP | 442.85 | 79.49 | 73.67 | 5.82 | 653.17 | 75.24 | 74.61 | 0.63 | |
| GR | 443.31 | 98.61 | 98.45 | 0.16 | 619.89 | 98.86 | 98.73 | 0.13 | ||
| Batch Size | 1:0.7 | 1:0.6 | 1:0.5 | |||||
|---|---|---|---|---|---|---|---|---|
| Task | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ||
| 32 | FBP | 58.91 | 56.94 | 61.37 | 59.72 | 58.62 | 56.70 | |
| 16 | FBP | 58.88 | 56.86 | 61.12 | 59.53 | 58.53 | 56.37 | |
| Batch Size | 1:0.7 | 1:0.6 | 1:0.5 | |||||
|---|---|---|---|---|---|---|---|---|
| Task | ACC | F1 Score | ACC | F1 Score | ACC | F1 Score | ||
| 32 | FBP | 73.65 | 71.42 | 75.41 | 73.82 | 73.58 | 71.40 | |
| GR | 97.18 | 97.18 | 97.09 | 97.09 | 96.45 | 96.44 | ||
| 16 | FBP | 73.27 | 71.67 | 75.13 | 73.27 | 73.41 | 70.67 | |
| GR | 97.15 | 97.14 | 96.89 | 96.88 | 96.35 | 96.31 | ||
| Task | LSAFBD | SCUT-FBP5500 | |
|---|---|---|---|
| Methods | FBP | FBP | |
| GoogleNet [22] | 56.06 | 72.77 | |
| MobileNetV2 [23] | 50.70 | 72.13 | |
| MobileNetV3 [24] | 52.35 | 72.31 | |
| ShuffleNetV2 [25] | 59.97 | 75.14 | |
| DenseNet [26] | 59.32 | 73.95 | |
| EfficientNet [27] | 59.02 | 75.04 | |
| RegNet [28] | 59.02 | 74.68 | |
| ConvNeXt [29] | 60.67 | 75.32 | |
| Proposed method | 61.37 | 75.41 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, J.; Luo, H.; Xiong, J.; Xie, X.; Li, H.; Liu, J. Facial Beauty Prediction Combined with Multi-Task Learning of Adaptive Sharing Policy and Attentional Feature Fusion. Electronics 2024, 13, 179. https://doi.org/10.3390/electronics13010179
Gan J, Luo H, Xiong J, Xie X, Li H, Liu J. Facial Beauty Prediction Combined with Multi-Task Learning of Adaptive Sharing Policy and Attentional Feature Fusion. Electronics. 2024; 13(1):179. https://doi.org/10.3390/electronics13010179
Chicago/Turabian StyleGan, Junying, Heng Luo, Junling Xiong, Xiaoshan Xie, Huicong Li, and Jianqiang Liu. 2024. "Facial Beauty Prediction Combined with Multi-Task Learning of Adaptive Sharing Policy and Attentional Feature Fusion" Electronics 13, no. 1: 179. https://doi.org/10.3390/electronics13010179