2. Materials and Methods
2.1. Overall Design Approach and Method Selection
The proposed design approach commences with the predesign of an optimal base transformer architecture tailored to various FPGA types, followed by automatic adaptation and optimization according to the transformer variants provided by users.
The formulation of this design approach is governed by two primary reasons: First, there exist several limitations in directly employing RL or other deep-learning methods for optimizing the original code. These methods focus on optimizing local functions or loops within the constraints of the existing code structure. However, in substantial and complex projects such as transformers, implementing structural code modifications through these methods proves challenging, and these strategies often fail at fully leveraging the hardware capabilities. In contrast, by predesigning an optimal transformer, we can build upon existing research findings and practical experience, laying a solid foundation for subsequent automatic adaptation and optimization. Second, by understanding and adapting the transformer variants provided by users, the proposed framework can offer customized hardware designs to meet different design requirements and performance objectives.
2.2. Predesign of the Optimal Transformer
In the predesign phase, we employed a manual design methodology to construct a sophisticated transformer architecture tailored for FPGA devices. This methodology emphasizes hardware resource allocation, parallelism, and memory layout, ensuring optimal performance and efficiency. The hardware setup includes computation units for encode/decode processes and on-chip memory banks.
Our approach mirrors this by focusing on modular design, facilitating both shallow and deep network implementations. For instance, multihead attention and other modules are reconfigured based on control logic to form either encoder or decoder units. This modularity enables efficient resource usage. Moreover, we optimized the computation sequence within the attention layer for synchronous processing, significantly reducing latency. Our storage architecture mimics a quasi-distributed system, minimizing data transmission costs and power consumption associated with long-distance data movement. This comprehensive approach, combining modular design with optimized data flow and storage, forms the bedrock of our subsequent RL-driven optimization process.
As illustrated in
Figure 2, the hardware architecture encapsulates control modules, an on-chip cache, computation arrays, and nonlinear computation modules. The on-chip cache includes input, weight, and intermediate result/output caches, employing ping-pong operations to support continuous data processing. The overall data flow of the accelerator is illustrated in
Figure 3. The weight data of an attention sublayer or a feed-forward neural network layer are read in batches, and the next batch of weight data is synchronously loaded during computation. By sequentially loading weight data across network layers and storing interlayer computation results on-chip for the next sublayer computation, the interaction times with off-chip dynamic random-access memory (DRAM) are reduced.
Furthermore, the computation sequence within the attention layer is optimized, facilitating the synchronous computation of the Softmax function with matrix addition and multiplication, thereby mitigating computation latency. Through this task-level scheduling, the computation of all network layers in the transformer model is accelerated. To minimize the data transmission cost between computational and storage units, including the power consumption associated with long-distance transmission and complex address generation read–write cost, a quasi-distributed storage architecture is used, as shown in
Figure 4.
The storage and computation of each neuron are simulated using processing elements (PEs) and a register file (RF). In particular, the PEs are interlinked in a distributed fashion to emulate distributed connections amidst neurons, while multilevel storage entities such as first in, first out (FIFO), block random-access memory (BRAM), and DRAM are used outside the PE array to reduce data transmission overhead. Specifically, the storage architecture includes PE local registers, internal cache of the computation array (FIFO), on-chip global cache (BRAM), and off-chip DRAM, each having different access costs across multilevel storage hierarchies. The RF within PE, having the lowest access cost, serves as a basic unit point where data can be transferred laterally and longitudinally between each basic unit point. In this manner, the inherent data movement during computation maximally occurs at the RF storage level with the least access overhead, maximizing the consumption of data written by upper-level storage and reducing movement power consumption. When reading computational data from BRAM, the entire computation array is treated as a unit for data input, with basic unit points within the computation array interacting in a distributed manner, transferring input data between points to achieve data reuse across the input, weight, and output dimensions. Unlike the computation array, the local cache can store partial sums and results of matrix computation. Compared with storage in the global cache, adder units can access partial sums and results in a more rapid manner over shorter distances. Additionally, while computing nonlinear functions, this quasi-distributed storage architecture can avoid redundant reads of intermediate result data and reduce redundant computations, thereby accelerating inference.
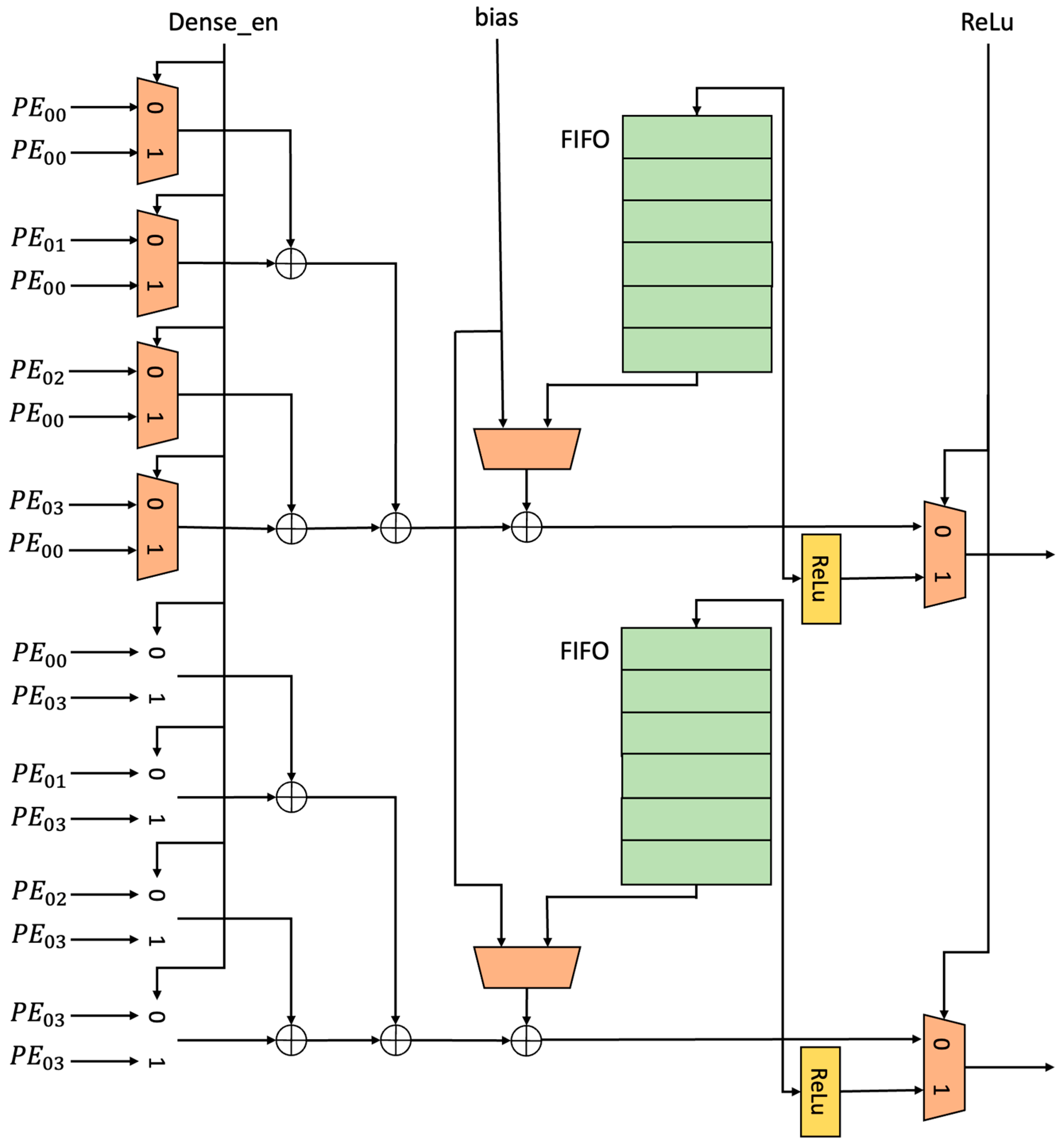
As shown in
Figure 2, the computation array consists of PEs and adder units, with each column of PEs sharing an adder unit. PEs handle matrix multiplication, while adder units manage the addition of PE results and accumulation of partial sums, which can be expanded based on actual inference demands. The regularity in the pruned offset diagonal matrix, referring to the consistent size and arrangement of submatrices, can be mapped efficiently to the regular computation array. The computation array internally adopts a fixed-weight data flow scheme, as shown in
Figure 5, with input and weights fed into computational units in row and sparse block forms, respectively, mitigating the efficiency drops caused by different input sentence lengths and computation modes of encoders and decoders. Input data are transmitted to the right in each cycle, enabling input re-use, while the weight data with the largest data scale only need to be read once from outside the array. The output is accumulated cycle by cycle within the adder unit, achieving output re-use. Each computational unit includes a PE and adder units, with each PE encompassing a multiplication unit and an RF storage unit, serving as regular distributed basic points that can efficiently map the locality of the offset diagonal matrix, i.e., the row and column dimensions of individual submatrices and regular distribution of nonzero values. Each PE contains 16 multipliers and one data distributor, as shown in
Figure 6, with the data distributor responsible for rearranging input data based on offset values to ensure the multiplication of input data and corresponding nonzero value weight data. Sparse decoding outside the PE is unnecessary, and the need to address indexing of partial sums and output or computation results is eliminated, as illustrated in
Figure 7. The adder unit is responsible for adding partial sum results or bias data generated by the column PE, as shown in
Figure 8, with each adder unit internally equipped with a local cache for caching partial sum results. This configuration helps reduce the data movement distance of partial sums. The dense_en signal controls the data source of the adder unit to switch between dense and sparse data paths, with the adder unit supporting the rectified linear unit activation function.
2.3. RL-Based Adaptive Bit-Width Optimization
The objective of this study is to better adapt to user-specific transformer variants while meeting specific performance and resource efficiency goals, such as reducing computation time and ensuring computational accuracy. This can be achieved by optimizing the bit-width of inputs/outputs and operations while maintaining the bit-width of weights. This assertion has been validated in a previous study [
26], which demonstrated that a certain bit-width for weights could ensure a balance between performance and accuracy.
The RL framework is chosen for its ability to dynamically adjust and learn optimal configurations through continuous interaction with the hardware design environment. Specifically, we design an RL framework that dynamically adjusts the bit-width of inputs/outputs and operations through continuous exploration and learning.
In our Q-learning implementation for adaptive bit-width optimization, the hyperparameters were carefully chosen to balance exploration, learning speed, and convergence. The selected hyperparameters are as follows:
Discount Factor (γ): Set between 0.8 and 0.9, this parameter determines the importance of future rewards. A higher discount factor encourages the algorithm to consider long-term rewards, facilitating a more strategic optimization over time.
Learning Rate: Chosen within the range of 0.1 to 0.3, the learning rate controls how much new information overrides old information. A moderate learning rate was selected to ensure that the algorithm steadily adapts to new findings without oscillating or diverging.
ε-Greedy Strategy: The ε value, set between 0.1 and 0.8, dictates the balance between exploration and exploitation. Initially set higher to encourage exploration, ε gradually decreases as the algorithm gains more knowledge about the environment, allowing more exploitation of known information.
The choice of these hyperparameters was based on the need to explore effectively the bit-width configuration space while ensuring stable and efficient learning. The discount factor was set closer to 1 to prioritize long-term effectiveness in bit-width optimization. The learning rate was calibrated to ensure that the algorithm could adapt to new insights at a reasonable pace. The ε-greedy strategy was used to balance exploring new configurations and exploiting known efficient configurations, which is crucial in the dynamically changing environment of FPGA-based transformer models.
Within this RL framework, our reward function is meticulously designed to prioritize computational accuracy, followed by computation time and then hardware resource utilization. This prioritization is reflective of our emphasis on ensuring the high precision of the transformer model, especially crucial in hardware implementations, while also maintaining efficient inference speeds. The specific formulation of the reward function is as follows:
Here, represents the reward at the state when action is taken. The weights correspond to the importance of computational accuracy, computation time, and hardware resource utilization, respectively, with signifying their relative importance in the optimization process. Its purpose is to optimize hardware resources and power consumption while ensuring computational accuracy.
The proposed reinforcement learning-based hardware design system includes the following modules:
Test Design Module: This module serves as the test object for the verification system.
Agent: This module, consisting of the action control module, transactions, and incentive sequences, is used to build a global action set and control the agent actions.
Hardware Design Verification Platform: Interaction with this platform is facilitated through a well-defined interface, ensuring seamless communication and data exchange and enabling accurate verification and feedback generation. This platform receives the incentive inputs from the agent, feeds them into the test design model and reference model according to the timing requirements; monitors the input/output of the test design module, compares simulation results, generates bit positions, and feeds this information back to the reward module.
Reward Module: The reward function is designed to reflect the achieved performance improvements and resource savings, which are crucial for meeting the specified objectives. This module establishes a return mechanism, with bit positions as the reward return for RL, and sends this information to the global state model.
Global State Model: The initial state is set based on the current bit-width configuration of the HLS design, providing a starting point for the exploration. The termination conditions are set to ensure a thorough exploration while avoiding excessive computations. The termination criterion may be based on the number of iterations, satisfactory performance/resource level, or no further improvement observed. This module builds a global state set based on the coverage of the test design module and sends the reward return to the state control module.
State Control Module: The states and actions are carefully defined to provide a manageable yet expressive representation of the bit-width configuration space, enabling efficient exploration and learning. This module builds a global state transition table, determines the current state of the system, and controls state transitions based on the received reward return.
To elucidate how this framework operates in practice, consider the following example of dynamic bit-width selection. In our RL method, the agent dynamically selects the optimal bit-width for various components of the Transformer model during the FPGA optimization process. The action space for the RL agent includes a range of bit-width options, such as 8-bit, 16-bit, and 32-bit configurations. The agent evaluates each configuration based on its impact on performance metrics like processing speed and computational accuracy. For example, in one scenario, the RL agent might choose a 16-bit configuration for certain operations where higher precision is required while selecting an 8-bit configuration for other operations where speed is more critical and high precision is less necessary. This decision-making is guided by the reward function, which balances the trade-off between accuracy, efficiency, and resource utilization. The agent iteratively tests and learns from these bit-width adjustments, converging towards an optimal configuration that meets the specific requirements of the FPGA-based transformer model.
The Q-learning algorithm is designed to ensure efficient learning and convergence to the optimal bit-width configuration, even in the presence of large state and action spaces. The construction of the global action set involves the following steps: According to the input quantity
m of the test design module, one input is randomized from
m inputs, while other inputs remain unchanged as one action, represented as,
,
, …,
. Thus, a total of
m actions constitute the global action set. The states are defined based on the bit-width: 1 bit corresponds to
; greater than 1 and less than 64 coverage states are evenly divided into
n−2 states, denoted as
,
, …,
; and 64 bits correspond to
. Thus, a total of
n states constitute the global state set. The global state transition table is constructed as follows: With
n states as the vertical coordinate and
n actions as the horizontal coordinate, the Q-table is constructed based on the maximum future reward expectation, considering the corresponding action under each state as the value, initialized as 0. This value is obtained according to the Q function:
where
represents the reward return obtained at the moment
in state
St by taking action
at;
is the discount factor, satisfying 0 ≤
≤ 1; and
} represents the maximum expected Q-value for the next state
. The action
, corresponding to the maximum expected Q-value, is the action taken at the moment
, pertaining to the state transition information. The Q-value of the corresponding state and action taken constitute the element of the matrix, and the Q-table is thus constructed, as indicated in
Table 1.
Table 1 has 11 global states as columns and
m actions as rows. Each cell in the table contains the expected reward Q-value calculated using the Q function. Notably, this value does not represent the maximum reward return obtained after taking a certain action; instead, it aims at maximizing the sum of the future discount rewards, i.e., obtaining the maximum discount reward expectation. All values are initialized to 0, thereby obtaining Q-table0. Based on Q-table0, the first row of global states is selected as the starting state
S0, that is, the state with a coverage of 0%. The maximum number of iterations
N is set to attain the target point
Sn−1. In the case of the Q-table, among all columns of the current state
St, we select the column with the maximum Q-value as action
at. If multiple columns house the same Q-value and the maximum value, one column is randomly selected from among these columns. After the agent takes action
at, the generated incentives are sent to the hardware design verification platform and test design module. The state control module determines whether the current state
St+1 is the target point in the global state. If so, the bit position of the designer is reached, the hardware design verification target is completed, and the training is terminated. If the target state is not reached in a given iteration, the following steps are implemented: The number of iterations is increased by 1, that is,
t =
t + 1. Next, we check whether the number of iterations has reached the maximum defined value,
N. If so, the algorithm proceeds to the final step, and the training is terminated. If not, the algorithm proceeds to the next step.
The complete process for bit adjustment involves the following steps:
Initialize the Q-table or neural network (if using deep RL) with arbitrary values.
Set the initial state, typically the current bit-width configuration of the HLS design.
Determine the termination conditions to ensure effective exploration and exploitation phases while preventing excessive iterations. Termination may be triggered by reaching a certain number of iterations, achieving a satisfactory performance/resource level, or observing no further improvement over a defined period.
Use an exploration strategy (e.g., ε-greedy) to decide whether to explore a new action or exploit the current knowledge.
Select an action, changing the bit-width of either the inputs/outputs or variables within operations.
Apply the selected action to the HLS design.
Obtain the new state and the reward from the environment (HLS design). The reward may be computed based on the achieved performance improvements or resource savings.
Update the Q-value of the state–action pair based on the obtained reward and the highest Q-value of the new state (according to the Q-learning update rule).
Repeat until a termination condition is met.
Extract the policy (optimal action in each state) from the Q-table or neural network.
Apply the policy to the HLS design to obtain the optimized bit-width configuration. The proposed method represents a practical and verifiable process for implementing RL in hardware design. The outcomes can be verified through the hardware design verification platform. The effectiveness of this method is evaluated through extensive experiments, as discussed in the following section.
3. Results and Comparisons
The previous sections described the proposed method, which is aimed at optimizing the bit-width of inputs/outputs and variables within operations for transformer-based designs based on FPGAs in the HLS environment. To demonstrate the effectiveness of the proposed approach, a well-optimized transformer design was developed for FPGAs, leveraging existing architectural principles and optimizing key aspects such as hardware resource allocation, parallelism, and memory layout. This predesigned optimal transformer served as a solid foundation for further adaptive optimization using RL.
We applied our methodologies to ZU7EV and ZU9EG FPGAs, assessing the performance and efficiency of our optimized designs. The implementation was executed using the Xilinx Vivado HLS 2020.1 tool. Our process involved first designing HLS code tailored for a transformer model, ensuring FPGA compatibility, especially in terms of key features like parallelism. Postdesign, the HLS code was compiled into a hardware description language.
The RL algorithm, developed using the PyTorch framework, then analyzed this compiled code to identify optimization opportunities. The focus was on bit-width adjustments, where specific values dictating the transformer model’s behavior were examined for potential parallel optimizations. The RL algorithm dynamically adjusted the bit-width in the HLS code, leading to the synthesis of various hardware designs. Each design variation offered different hardware sizes and latencies, presenting multiple avenues for optimization.
This detailed process illustrates the practical application of our RL-driven approach in optimizing FPGA-based transformer models, emphasizing its effectiveness and adaptability for real-world scenarios.
Table 2 presents the performance and resource utilization metrics of the predesigned transformer on the two FPGA platforms. Subsequently, the RL framework was introduced to dynamically adjust the bit-width based on the user-specified transformer variant, aiming to meet the desired performance and resource efficiency targets.
By introducing variants with floating point 16-bit (FP16) and integer 8-bit (INT8) precisions, the RL framework effectively fine-tuned the bit-width configurations, enhancing the performance and resource efficiency of the baseline transformer design. The comparison presented in
Table 3 demonstrates significant improvements in frame rate, throughput, and computation efficiency, emphasizing the efficacy of the proposed RL-based optimization approach.
The proposed RL framework displayed robustness and adaptability in optimizing various transformer variants, facilitating the realization of real-time inferences and diverse performance objectives. Furthermore, a comparison with other implementations demonstrated the superior performance and efficiency of the proposed design, thereby facilitating FPGA-based transformer acceleration. As depicted in
Table 2 and
Table 3, the application of the proposed RL framework resulted in a significant enhancement in both performance and resource efficiency when transitioning from FP32 to FP16 and INT8 precisions on both FPGA platforms. Specifically, on the ZU7EV, the frame rate (FPS) improved by 80% and 240% for FP16 and INT8 precisions, respectively. On the ZU9EG chip, these improvements were even more pronounced.
The throughput, giga operations per second (GOPS), also increased substantially. For the ZU7EV platform, the throughput increased by 80% and 235% for FP16 and INT8 precisions, respectively, with even higher improvements noted for the ZU9EG chip. Enhancements in GOPS per digital signal processor (DSP) and GOPS per kilo lookup table (kLUT) demonstrated the enhanced resource efficiency achieved through the proposed RL framework. Overall, these improvements validated the effectiveness of the proposed RL framework in dynamically adjusting the bit-width of inputs/outputs and variables within operations while maintaining the bit-width of weights.
From the data presented in
Table 2 and
Table 3, it is evident that the introduction of RL optimization (for FP16 and INT8 precision) led to a significant improvement in frames per second (FPS) and giga operations per second (GOPS), compared to the original design (FP32 precision). The increase in FPS indicates a faster processing speed, which is crucial for applications requiring real-time feedback, such as video processing or live data analytics. This improvement underscores the advantages of dynamic bit-width optimization; by dynamically adjusting the bit-width of inputs/outputs and operations, our RL framework enables the hardware design to use resources more effectively without compromising computational accuracy. A lower bit-width reduces the computational burden of individual operations, thus enhancing overall processing speed. Moreover, the design of our reward function, prioritizing computational accuracy followed by computation time and hardware resource utilization, ensures that the optimization process maintains high accuracy while effectively reducing computation time. The choice of hyperparameters, including the adjustment of the learning rate and the application of the ε-greedy strategy, helps the algorithm strike a balance between exploring new configurations and exploiting known efficient configurations.
Our results demonstrate the advantages of RL, particularly Q-learning, in reducing latency and increasing throughput. The core strength of Q-learning in our design lies in its efficient traversal of the state−action space, swiftly identifying optimal bit-width configurations. Specifically, Q-learning in our proposed framework flexibly adjusts the workload of processing elements (PEs), reducing the time consumption per operation. Crucially, for FPGA-based systems, our approach enhances hardware resource utilization by adjusting bit-widths, thereby minimizing unnecessary data width and easing computational loads. This leads to an overall increase in processing speed. Moreover, our reward function design, focusing on computational accuracy, time efficiency, and resource utilization , ensures that the algorithm improves throughput without compromising model accuracy or system stability. In summary, our proposed method not only accelerates system response time but also optimizes resource allocation, presenting an effective pathway for optimizing transformer models on FPGA platforms.
Building upon this foundation, we further explored the application of our optimized transformer network in specific tasks like object detection and image segmentation. In the realm of object detection, our hardware design was augmented with a region proposal network (RPN) layer, which identifies and proposes candidate object-bound regions within an image. Additionally, a set of detection heads was integrated for the classification of these proposed regions and for bounding box regression, enabling the network to perform object localization in addition to classification. This demonstrates the practicality and effectiveness of our hardware-optimized approach in real-world scenarios. Similarly, for image segmentation, our approach entailed augmenting the simple transformer network with layers tailored for segmenting images. The hardware-specific adaptations included adding a U-Net-like architecture, incorporating convolutional layers for feature extraction and a series of up-sampling layers for pixel-level classification. This modification allows the network to generate segmentation maps, enabling it to distinguish between different objects and backgrounds at the pixel level. The incorporation of a skip-connection strategy ensures that fine-grained details are preserved in the segmented images. As seen in
Table 4, the performance of this detection and segmentation network was evaluated using the COCO dataset with fp16 precision in the ZU7EV platform, where it exhibited notably that the proposed method works well in both segmentation accuracy and processing speed.
Additionally, our optimized approach demonstrates commendable power efficiency, a crucial aspect for applications in embedded environments. In our evaluations, the optimized transformer network exhibited power consumption levels of 9.81 W for object detection and 11.1 W for image segmentation. These power levels are well within the acceptable range for most embedded applications, particularly in scenarios where energy efficiency is paramount. For instance, in remote monitoring or mobile devices, such reduced power consumption can significantly extend operational durations while maintaining necessary processing capabilities. This indicates that our approach not only excels in precision and processing speed but also offers notable advantages in energy efficiency, making it suitable for various power-sensitive application environments.
In our endeavor to achieve real-time inference and optimize transformer designs on FPGAs, we leveraged an innovative RL framework while exploring alternative software-based quantization techniques using PyTorch v2.1 with FP16 and INT8 precisions. Although software-based quantization increased the inference speed while maintaining a certain level of accuracy, the hardware optimization enabled by our RL framework significantly surpassed these improvements.
Theoretically, different software quantization schemes exhibit varying levels of accuracy and inference speed.
Table 5 presents the accuracy and speed metrics of three software quantization schemes.
In practice, the hardware-accelerated TensorRT 8.6 [
27] produces diverse levels of accuracy and inference speed, as indicated in
Table 6.
Upon comparing the hardware and software optimizations, we observed several key distinctions. Software quantization techniques, such as quantization aware training [
28], DoReFa-Net [
29], and parameterized clipping activation [
30], primarily aim to reduce computational and storage demands by quantizing network weights and activations, thereby enhancing inference speed without considerably sacrificing the accuracy. However, these software quantization schemes often require the original model to be modified, which can adversely affect the accuracy and generalizability of the model.
In contrast, the proposed RL framework adopts a hardware-level optimization approach. It optimizes the performance and resource efficiency of transformer designs on FPGAs by dynamically adjusting the bit-width of operations. The advantage of this method is that the original model does not need to be modified, and instead, performance improvements can be achieved by altering the underlying hardware implementation. Specifically, hardware optimization through the RL framework more effectively leverages the parallel processing capability and memory hierarchy of FPGAs, significantly improving inference speed while maintaining satisfactory accuracy.
We further conducted a comparative analysis between the Q-learning and Deep Q-Network (DQN) [
31] approaches on the ZU7EV and ZU9EG FPGA platforms as indicated in
Table 7. This comparison aimed to evaluate the efficacy of these methods in optimizing transformer models on FPGAs with respect to various performance metrics.
In our comparative analysis of Q-learning and DQN methods for optimizing bit-width in FPGA-based transformer models, we observed notable differences in performance. The Q-learning approach maintained a higher frames per second (FPS) rate and better throughput (GOPS), indicating its efficiency in real-time processing and overall throughput management. On the other hand, DQN exhibited superior performance in terms of GOPS per kLUT. This suggests that DQN might be more effective in scenarios where optimizing the use of lookup table (LUT) resources is crucial.
The distinct performance characteristics of these two methods can be attributed to their inherent algorithmic properties. Q-learning, with its direct approach to value estimation, likely navigated the state−action space more efficiently for the task of bit-width optimization. This method, due to its simplicity and tabular approach, might have been particularly effective in the constrained environment of FPGA bit-width configuration.
Conversely, DQN, which generally excels in larger state spaces, might have encountered challenges such as overfitting or less effective generalization in this specific context. This could result in less optimal bit-width adjustments. Additionally, the potential instability and unpredictable convergence behavior of DQN might have also played a role in its comparative underperformance.
Moreover, the exploration strategy employed by Q-learning might have been better aligned with the requirements of bit-width optimization, finding more efficient paths through the configuration space. These findings suggest that while DQN has its merits, especially in more complex or larger state spaces, Q-learning appears to be more suitable for tasks like bit-width optimization in FPGA-based transformer models. This is primarily due to its algorithmic efficiency, stability, and suitable exploration strategy in the context of hardware optimization.
Our research demonstrates significant advancements in FPGA-based transformer models using a Q-learning RL framework. However, it is important to acknowledge certain limitations. Firstly, our experiments are predicated on the use of high-level synthesis (HLS) for FPGA development, implying that our method’s applicability is tied to platforms conducive to HLS. This presents a boundary condition for the generalization of our findings across diverse FPGA environments. Secondly, while our approach shows promise in optimizing transformer models, its long-term stability and adaptability, particularly for more complex transformer-based architectures, warrant further investigation. The Q-learning algorithm, while efficient in navigating the state−action space for bit-width optimization, may not fully grasp or address the intricacies of complex, global scenarios inherent in advanced models. This limitation highlights a potential area for future research, where more sophisticated or nuanced RL strategies could be explored to enhance the global decision-making capabilities of the optimization process.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}