
Finger Vein Recognition Using DenseNet with a Channel Attention Mechanism and Hybrid Pooling

Abstract
:1. Introduction
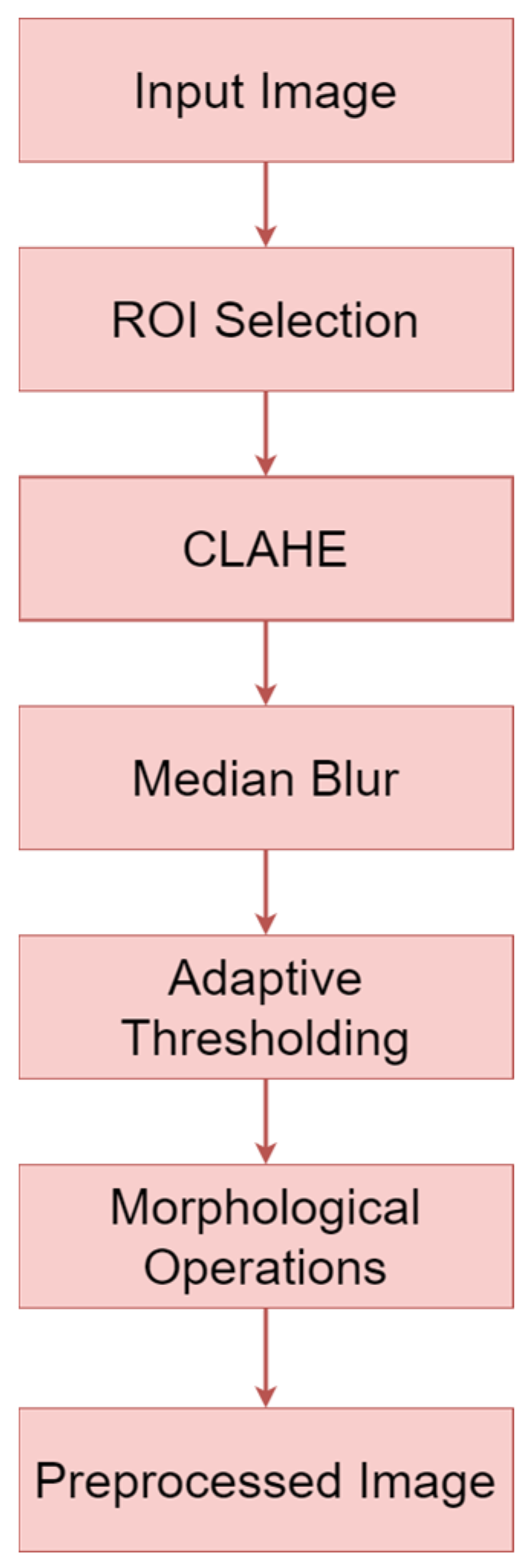
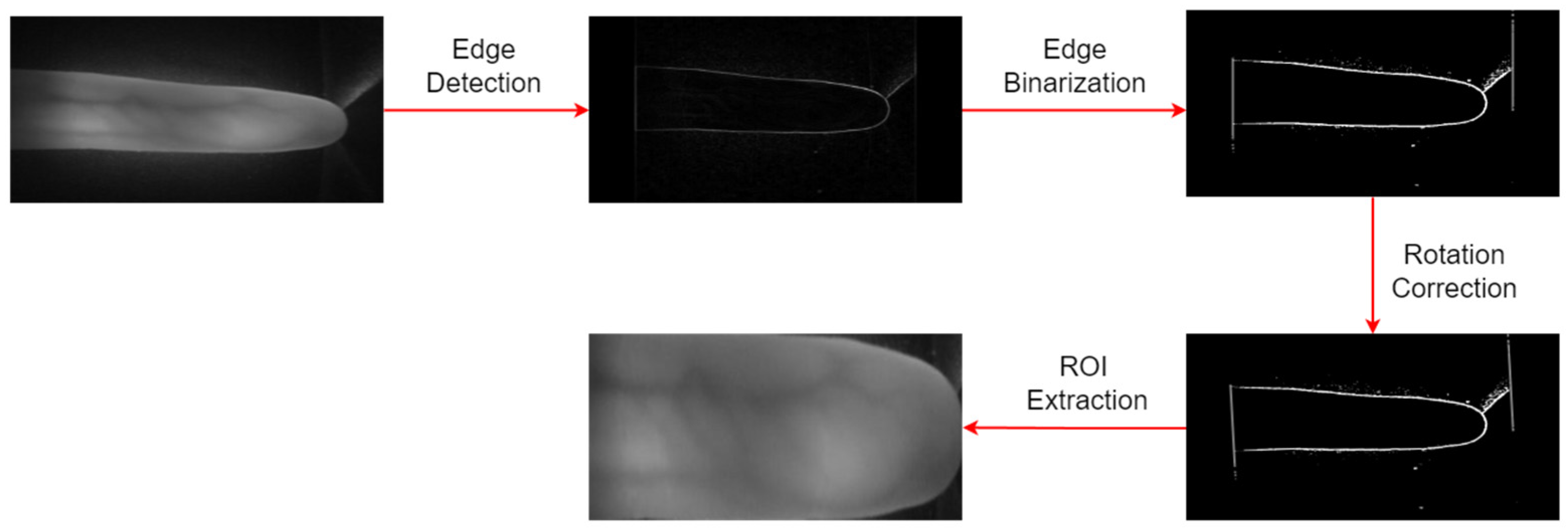
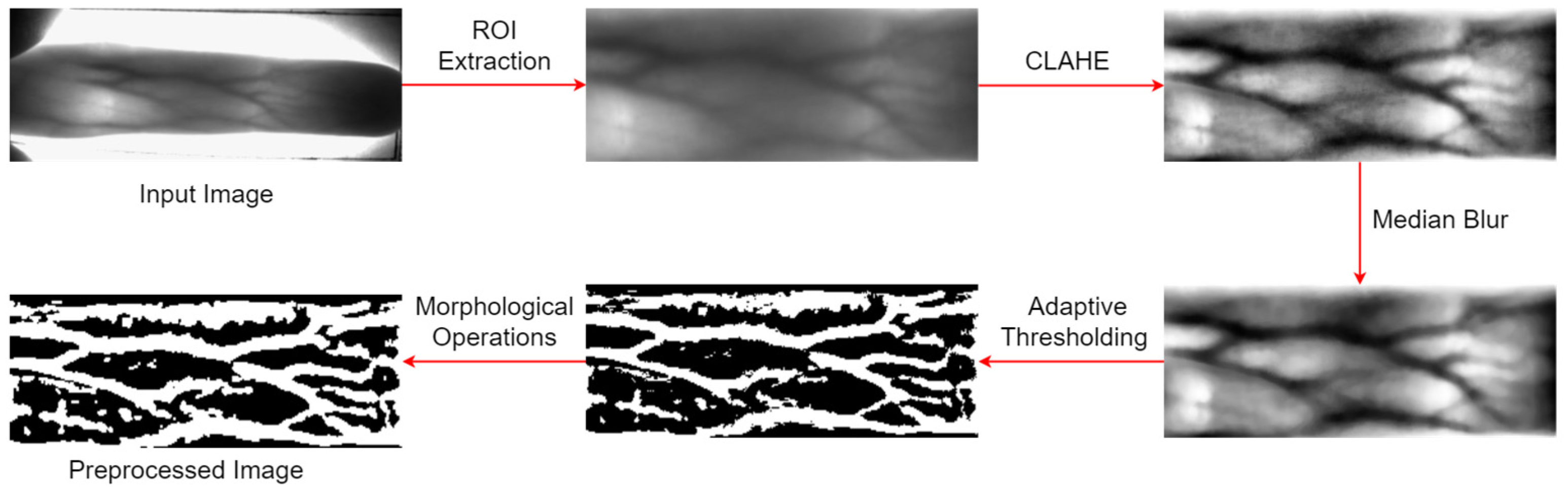
- To successfully separate vein patterns from the background in finger images, we develop an image preprocessing stage that consists of ROI extraction, contrast enhancement, median filtering, adaptive thresholding, and morphological operations. The quality of the preprocessed image is compared with conventional preprocessing;
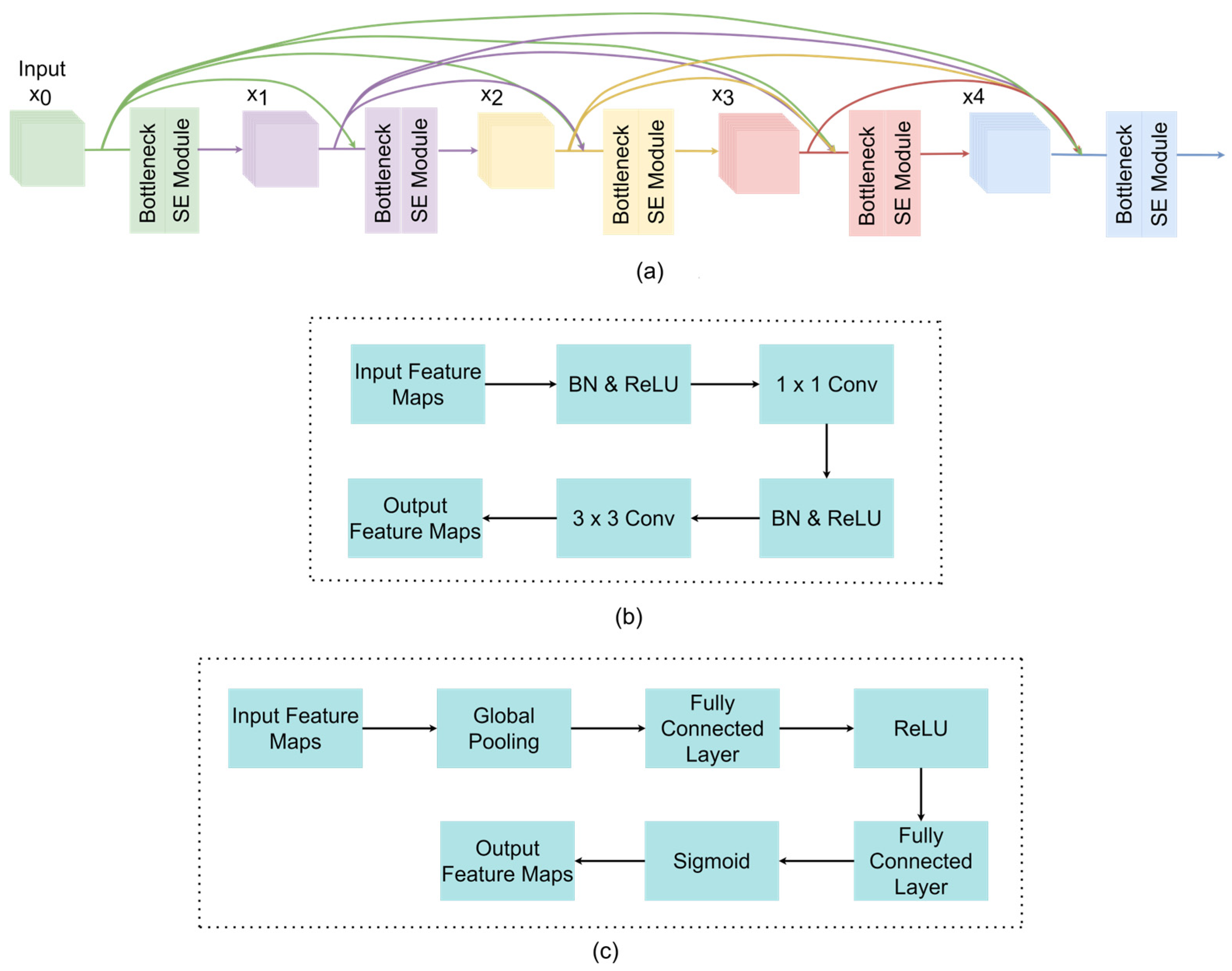
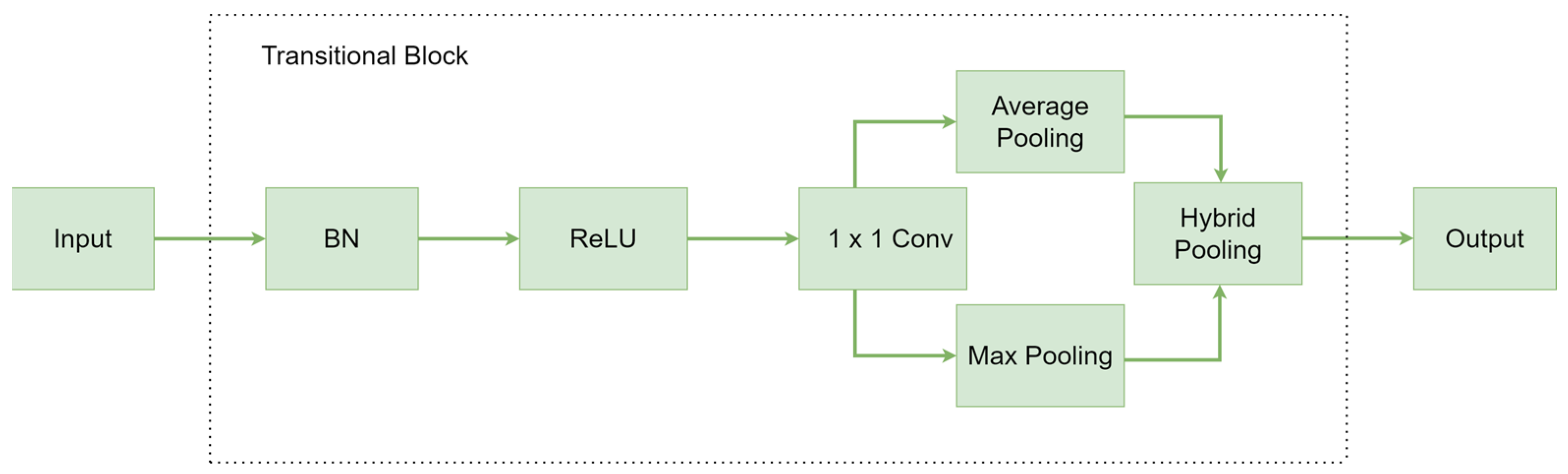
- To enhance the performance of the DenseNet backbone model, the SE-based channel attention mechanism and the HP strategy are integrated into the DenseNet network structure. The SE module emphasizes the important features related to finger vein patterns while suppressing less important ones. The HP process used in the transitional blocks of SE-DenseNet-HP concatenates the average pooling method with a max pooling strategy to preserve the most discriminative and contextual information;
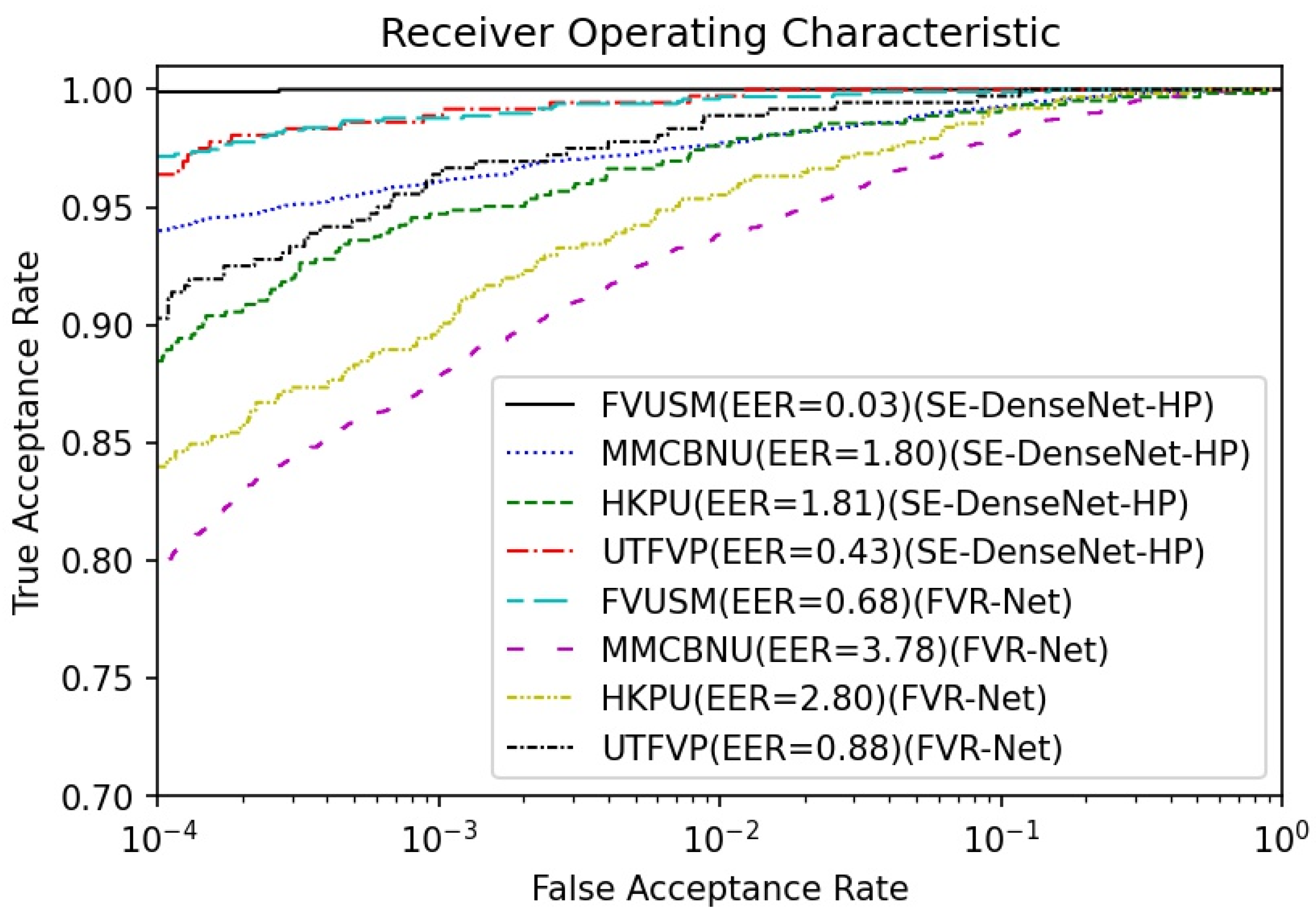
- To show the novelty of our proposed system, we compare the finger vein recognition performance of SE-DenseNet-HP with existing recognition approaches in terms of recognition accuracy, the receiver operating characteristic (ROC) curve, and the EER.
2. Related Works
3. Proposed Method
3.1. Data Preprocessing
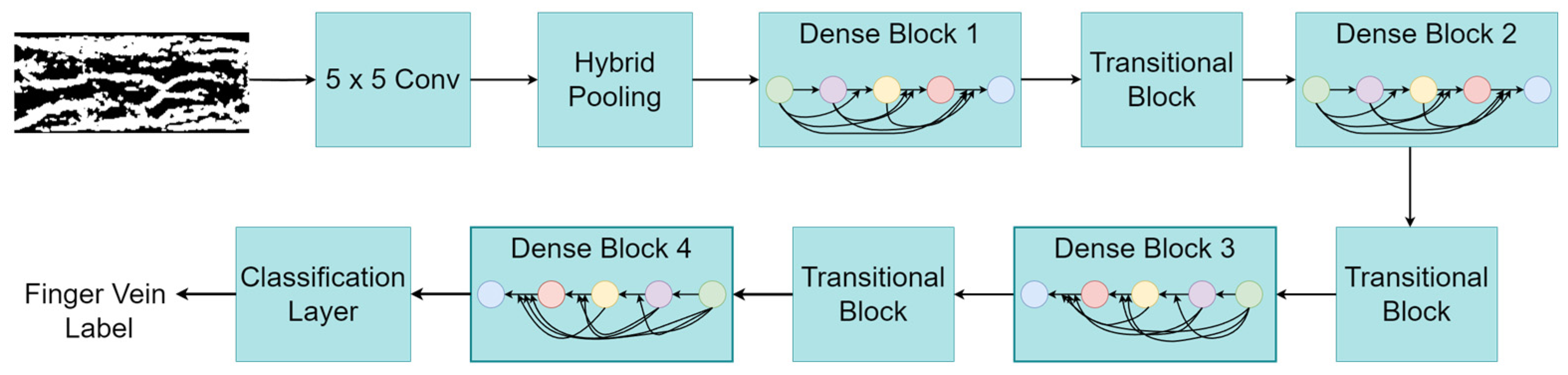
3.2. SE-DenseNet-HP Architecture
4. Experiments and Results
4.1. Experiment Datasets
4.2. Training, Validation, and Test Datasets
4.2.1. Training Stage
4.2.2. Testing Stage
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alay, N.; Al-Baity, H.H. Deep learning approach for multimodal biometric recognition system based on fusion of iris, face, and finger vein traits. Sensors 2020, 20, 5523. [Google Scholar] [CrossRef]
- Yang, W.; Luo, W.; Kang, W.; Huang, Z.; Wu, Q. FVRAS-Net: An Embedded Finger-Vein Recognition and AntiSpoofing System Using a Unified CNN. IEEE Trans. Instrum. Meas. 2020, 69, 8690–8701. [Google Scholar] [CrossRef]
- Hsia, C.-H.; Ke, L.-Y.; Chen, S.-T. Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System. Bioengineering 2023, 10, 919. [Google Scholar] [CrossRef]
- Qin, H.; El-Yacoubi, M.A. Deep representation-based feature extraction and recovering for finger-vein verification. IEEE Trans. Foren. Secur. 2017, 12, 1816–1829. [Google Scholar] [CrossRef]
- Shaheed, K.; Mao, A.; Qureshi, I.; Kumar, M.; Hussain, S.; Zhang, X. Recent advancements in finger vein recognition technology: Methodology, challenges and opportunities. Inf. Fusion 2022, 79, 84–109. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, M. A simple and efficient method for finger vein recognition. Sensors 2022, 22, 2234. [Google Scholar] [CrossRef]
- Lu, H.; Wang, Y.; Gao, R.; Zhao, C.; Li, Y. A Novel ROI Extraction Method Based on the Characteristics of the Original Finger Vein Image. Sensors 2021, 21, 4402. [Google Scholar] [CrossRef]
- Yao, Q.; Song, D.; Xu, X.; Zou, K. A novel finger vein recognition method based on aggregation of radon-like features. Sensors 2021, 21, 1885. [Google Scholar] [CrossRef] [PubMed]
- Hu, N.; Ma, H.; Zhan, T. Finger vein biometric verification using block multi-scale uniform local binary pattern features and block two-directional two-dimension principal component analysis. Optik 2020, 208, 1–16. [Google Scholar] [CrossRef]
- Kono, M.; Ueki, H.; Umemura, S. Near-infrared finger vein patterns for personal identification. Appl. Opt. 2002, 41, 7429–7436. [Google Scholar] [CrossRef] [PubMed]
- Shaheed, K.; Liu, H.; Yang, G.; Qureshi, I.; Gou, J.; Yin, Y. A systematic review of finger vein recognition techniques. Information 2018, 9, 213. [Google Scholar] [CrossRef]
- Huang, J.; Zheng, A.; Shakeel, M.S.; Yang, W.; Kang, W. FVFSNet: Frequency-spatial coupling network for finger vein authentication. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1322–1334. [Google Scholar] [CrossRef]
- Tao, Z.; Zhou, X.; Xinru, X.; Zhixue, L.; Sen, H.; Yalei, W.; Wei, T. Finger-vein recognition using bidirectional feature extraction and transfer learning. Math. Probl. Eng. 2021, 2021, 1–11. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Feature extraction of finger-vein patterns based on repeated line tracking and its application to personal identification. Mach. Vision Appl. 2004, 15, 194–203. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Extraction of finger-vein patterns using maximum curvature points in image profiles. IEICE Trans. Inf. Syst. 2007, 90, 1185–1194. [Google Scholar] [CrossRef]
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2011, 21, 2228–2244. [Google Scholar] [CrossRef] [PubMed]
- Lee, E.C.; Jung, H.; Kim, D. New finger biometric method using near infrared imaging. Sensors 2011, 11, 2319–2333. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional neural network-based finger-vein recognition using NIR image sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef]
- He, C.; Li, Z.; Chen, L.; Peng, J. Identification of finger vein using neural network recognition research based on PCA. In Proceedings of the IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC 2017), Oxford, UK, 26−28 July 2017. [Google Scholar]
- Khellat-Kihel, S.; Cardoso, N.; Monteiro, J.; Benyettou, M. Finger vein recognition using Gabor filter and Support Vector Machine. In Proceedings of the International Image Processing, Applications and Systems Conference, Sfax, Tunisia, 3−5 November 2014. [Google Scholar]
- Mobarakeh, A.K.; Rizi, S.M.; Khaniabadi, S.M.; Bagheri, M.A.; Nazari, S. Applying Weighted K-nearest centroid neighbor as classifier to improve the finger vein recognition performance. In Proceedings of the 2012 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23−25 November 2012. [Google Scholar]
- Kumar, R.P.; Agrawal, R.; Sharma, S.; Dutta, M.K.; Travieso, C.M.; Alonso, J.B. Finger vein recognition using integrated responses of texture features. In Proceedings of the 4th International Work Conference on Bioinspired Intelligence (IWOBI 2015), San Sebastian, Spain, 10–12 June 2015. [Google Scholar]
- Yang, W.; Hui, C.; Chen, Z.; Xue, J.H.; Liao, Q. FV-GAN: Finger vein representation using generative adversarial networks. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2512–2524. [Google Scholar] [CrossRef]
- Qin, H.; El-Yacoubi, M.A. Deep representation for finger-vein image-quality assessment. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1677–1693. [Google Scholar] [CrossRef]
- Das, R.; Piciucco, E.; Maiorana, E.; Campisi, P. Convolutional neural network for finger-vein-based biometric identification. IEEE Trans. Inf. Forensics Secur. 2018, 14, 360–373. [Google Scholar] [CrossRef]
- Tamang, L.D.; Kim, B.W. FVR-Net: Finger Vein Recognition with Convolutional Neural Network Using Hybrid Pooling. Appl. Sci. 2022, 12, 7538. [Google Scholar] [CrossRef]
- Sidiropoulos, G.K.; Kiratsa, P.; Chatzipetrou, P.; Papakostas, G.A. Feature Extraction for Finger-Vein-Based Identity Recognition. J. Imaging 2021, 7, 89. [Google Scholar] [CrossRef]
- Li, H.; Yang, L.; Yang, G.; Yin, Y. Discriminative binary descriptor for finger vein recognition. IEEE Access. 2017, 6, 5795–5804. [Google Scholar] [CrossRef]
- Zhang, R.; Yin, Y.; Deng, W.; Li, C.; Zhang, J. Deep learning for finger vein recognition: A brief survey of recent trend. arXiv 2022, arXiv:2207.02148. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21−26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18−23 June 2018. [Google Scholar]
- Asaari, M.S.M.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- Ton, B.T.; Veldhuis, R.N. A high quality finger vascular pattern dataset collected using a custom designed capturing device. In Proceedings of the 6th IAPR International Conference on Biometrics (ICB 2013), Madrid, Spain, 4–7 June 2013. [Google Scholar]
- Lu, Y.; Xie, S.J.; Yoon, S.; Wang, Z.; Park, D.S. An available database for the research of finger vein recognition. In Proceedings of the 6th International Congress on Image and Signal Processing (CISP 2013), Hangzhou, China, 16−18 December 2013. [Google Scholar]
- Yin, Y.; Zhang, R.; Liu, P.; Deng, W.; He, S.; Li, C.; Zhang, J. Artificial Neural Networks for Finger Vein Recognition: A Survey. arXiv 2022, arXiv:2208.13341. [Google Scholar]
- Yao, Q.; Song, D.; Xu, X. Robust finger-vein ROI localization based on the 3σ criterion dynamic threshold strategy. Sensors 2020, 20, 3997. [Google Scholar] [CrossRef] [PubMed]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Justusson, B. Median filtering: Statistical properties. In Two-Dimensional Digital Signal Processing II: Transforms and Median Filters; Huang, T.S., Ed.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 161–196. [Google Scholar]
- Zhu, R.; Wang, Y. Application of Improved Median Filter on Image Processing. J. Comput. 2012, 7, 838–841. [Google Scholar] [CrossRef]
- Bradley, D.; Roth, G. Adaptive thresholding using the integral image. J. Graphics Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Roy, P.; Dutta, S.; Dey, N.; Dey, G.; Chakraborty, S.; Ray, R. Adaptive thresholding: A comparative study. In Proceedings of the 2014 International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), Kanyakumari, India, 10–11 July 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tong, Z.; Tanak, G. Hybrid pooling for enhancement of generalization ability in deep convolutional neural networks. Neurocomputing 2019, 333, 76–85. [Google Scholar] [CrossRef]
- Platt, J.C. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, H.; Dey, D.; Del, G.A.; Hebert, M.; Bagnell, J. Log-DenseNet: How to Sparsify a DenseNet. arXiv 2017, arXiv:1711.00002. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Input Size | Output Size | |
|---|---|---|---|
| Input | 100 × 300 × 1 | 100 × 300 × 1 | |
| 5 × 5 conv | 100 × 300 × 1 | 48 × 148 × 64 | |
| 3 × 3 HP | 48 × 148 × 64 | 23 × 73 × 128 | |
| Dense Block 1 | 23 × 73 × 128 | 23 × 73 × 320 | |
| Transitional Block | 23 × 73 × 320 | 11 × 36 × 320 | |
| Dense Block 2 | 11 × 36 × 320 | 11 × 36 × 704 | |
| Transitional Block | 11 × 36 × 704 | 5 × 18 × 704 | |
| Dense Block 3 | 5 × 18 × 704 | 5 × 18 × 2240 | |
| Transitional Block | 5 × 18 × 2240 | 2 × 9 × 2240 | |
| Dense Block 4 | 2 × 9 × 2240 | 2 × 9 × 3264 | |
| Classification Layer | Global average pooling, 2D | 2 × 9 × 3264 | (None, 3264) |
| Fully connected layer, SoftMax | (None, 3264) | S | |
| Method | Datasets | Recognition Accuracy (%) | |
|---|---|---|---|
| Good Quality | Poor Quality | ||
| P-SVM [44] | FVUSM | 66.48 | 65.71 |
| HKPU | 80.57 | 79.04 | |
| NN [45] | FVUSM | 62.35 | 55.00 |
| HKPU | 81.44 | 81.82 | |
| DNN [24] | FVUSM | 69.33 | 68.57 |
| HKPU | 84.59 | 83.64 | |
| FVR-Net [26] | FVUSM | 97.84 | 97.22 |
| HKPU | 93.18 | 88.97 | |
| DenseNet | FVUSM | 99.56 | 98.00 |
| HKPU | 86.57 | 80.20 | |
| DenseNet-HP | FVUSM | 99.56 | 99.23 |
| HKPU | 92.53 | 84.08 | |
| SE-DenseNet-HP | FVUSM | 99.35 | 99.23 |
| HKPU | 93.28 | 88.16 | |
| Method | Cardinality | FVUSM | HKPU | UTFVP | MMCBNU_6000 |
|---|---|---|---|---|---|
| SE-DenseNet-HP (no cardinality) | − | 0.03 | 1.81 | 0.43 | 1.80 |
| SE-DenseNet-HP-16 | 16 | 0.10 | 2.11 | 0.16 | 2.17 |
| SE-DenseNet-HP-32 | 32 | 0.10 | 2.67 | 0.30 | 2.34 |
| Log-SE-DenseNet-HP (no cardinality) | − | 0.13 | 2.26 | 0.42 | 1.95 |
| Log-SE-DenseNet-HP-16 | 16 | 0.06 | 2.59 | 0.59 | 2.29 |
| Log-SE-DenseNet-HP-32 | 32 | 0.07 | 2.56 | 0.44 | 2.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devkota, N.; Kim, B.W. Finger Vein Recognition Using DenseNet with a Channel Attention Mechanism and Hybrid Pooling. Electronics 2024, 13, 501. https://doi.org/10.3390/electronics13030501
Devkota N, Kim BW. Finger Vein Recognition Using DenseNet with a Channel Attention Mechanism and Hybrid Pooling. Electronics. 2024; 13(3):501. https://doi.org/10.3390/electronics13030501
Chicago/Turabian StyleDevkota, Nikesh, and Byung Wook Kim. 2024. "Finger Vein Recognition Using DenseNet with a Channel Attention Mechanism and Hybrid Pooling" Electronics 13, no. 3: 501. https://doi.org/10.3390/electronics13030501