
Efficient FPGA Binary Neural Network Architecture for Image Super-Resolution
Abstract
:1. Introduction
- When the convolutional kernel size remains constant, a model with insufficient depth leads to a limited receptive field in the generated images. A deeper model inherently brings about a larger receptive field, allowing the network to utilize more contextual information, thus capturing a more comprehensive global mapping.
- Slow convergence during model training.
- The model is limited to handle only a single scale of image super-resolution.
- The deeper model can gain larger receptive fields to capture broader image contextual information.
- The model adopted residual learning with higher learning rates to expedite convergence. However, employing higher learning rates could lead to the problem of vanishing or exploding gradients; thus, they implemented moderate gradient clipping to mitigate these gradient issues.
- The neural network was capable of handling image super-resolution for various scales.
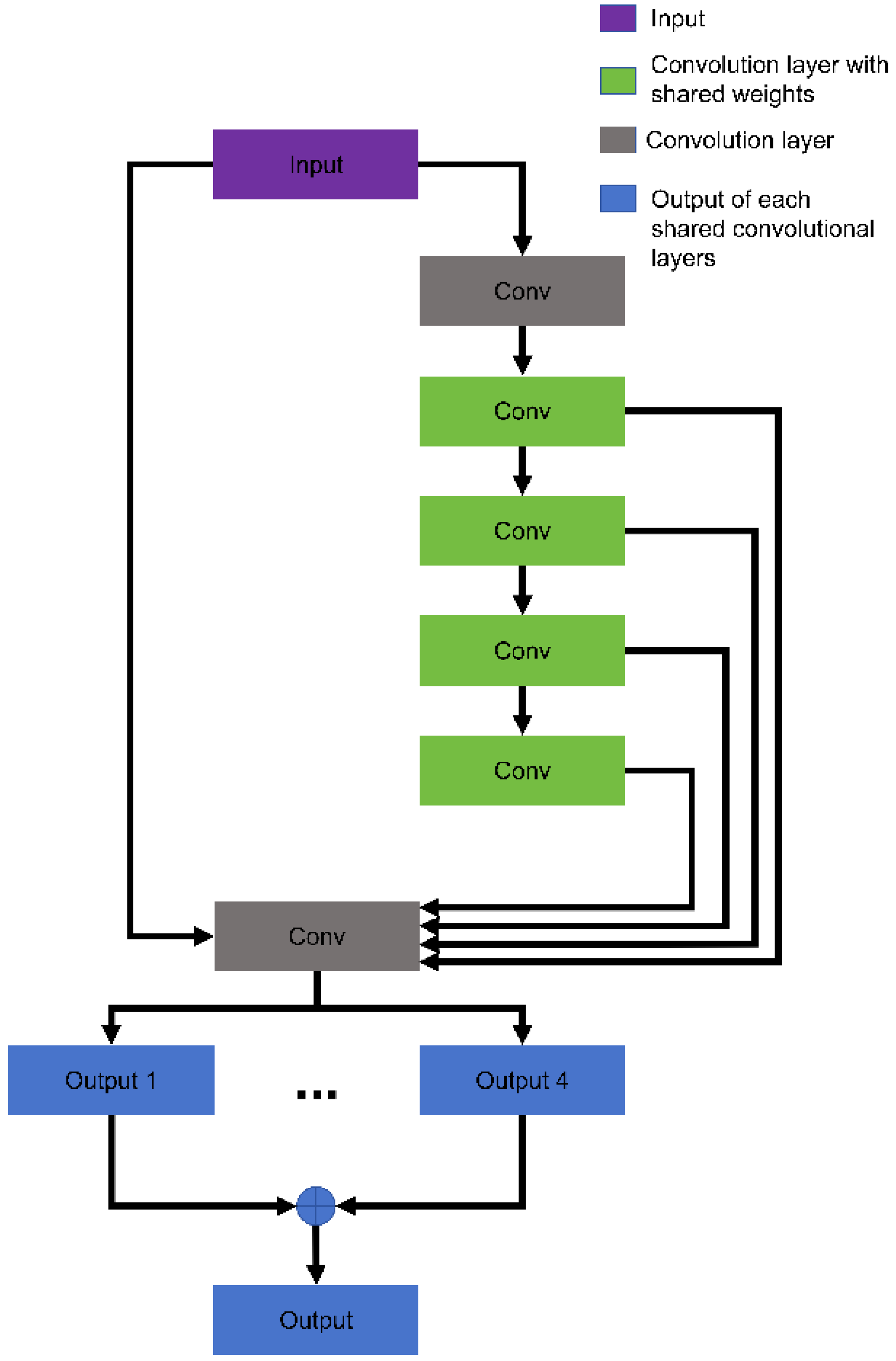
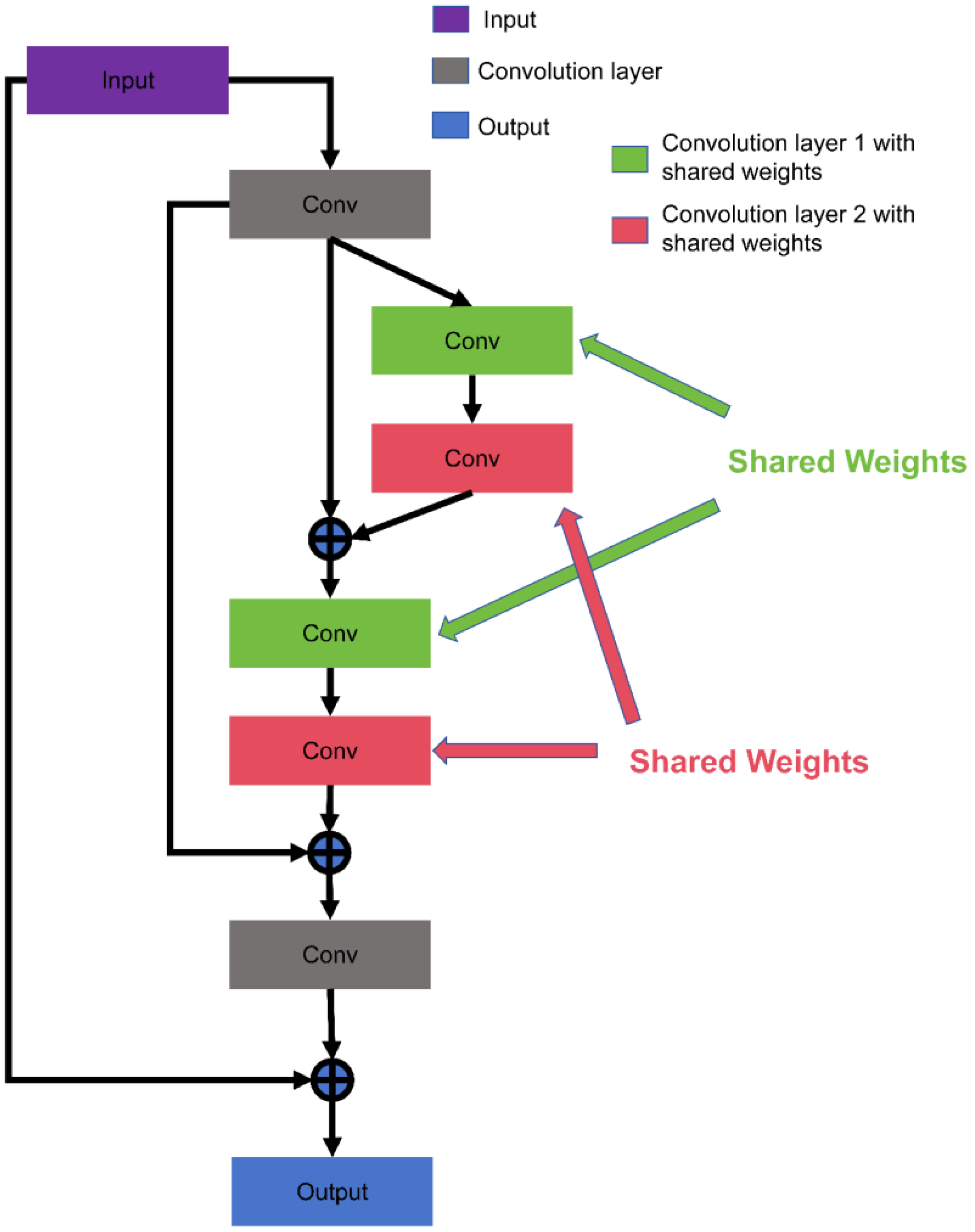
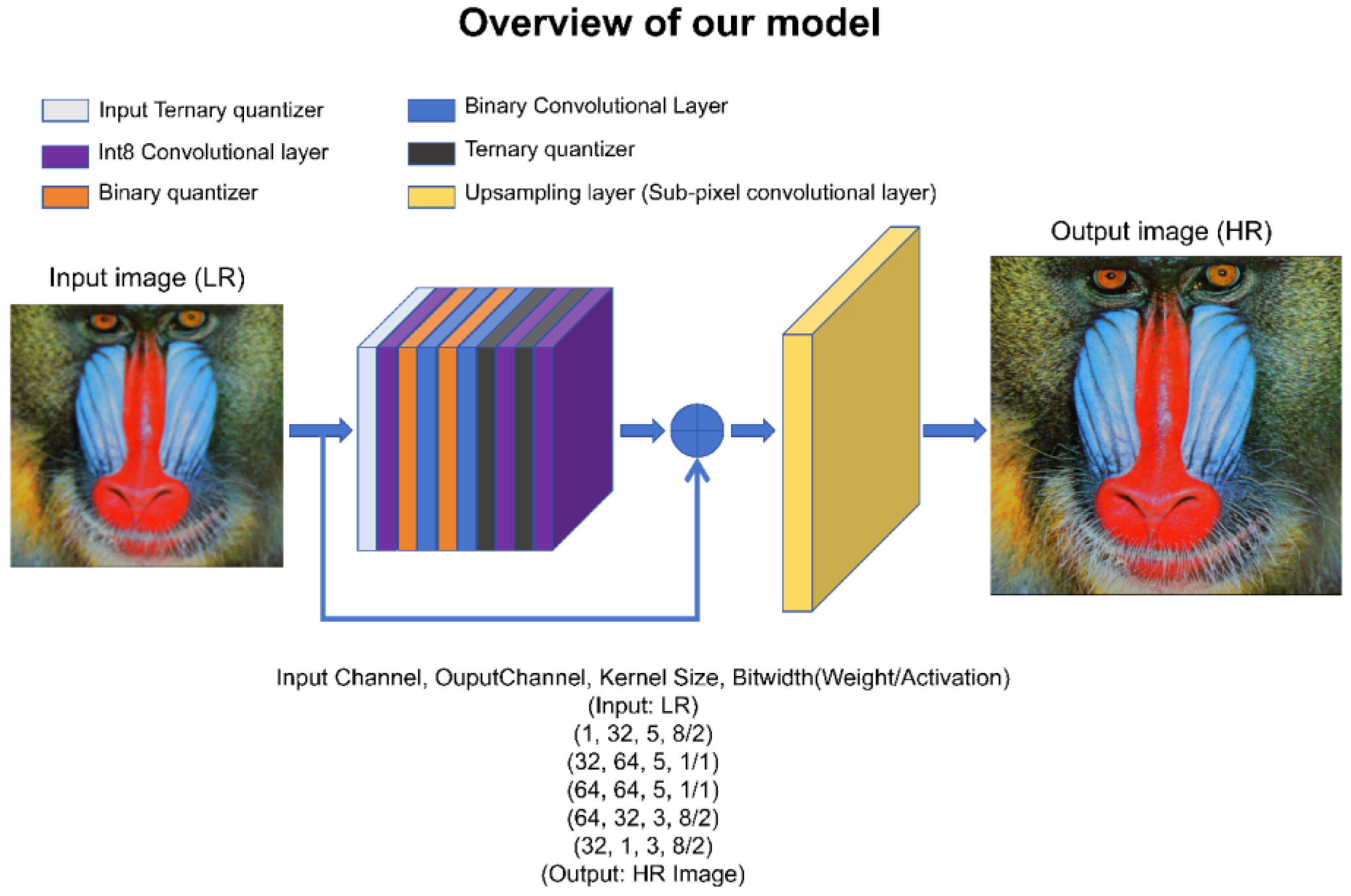
2. Binary Neural Network for Super-Resolution
- The fundamental principle of the design of BNN structures should prioritize the utmost preservation of information.
- As much as possible, bottleneck structures should be avoided. Bottleneck structures, characterized by reducing channel numbers and then increasing them, may result in irreversible information loss within BNNs.
- The downsampling layer should keep full precision to avoid mass loss of information by decreased number of channels.
- The shortcut structure can preserve information significantly.
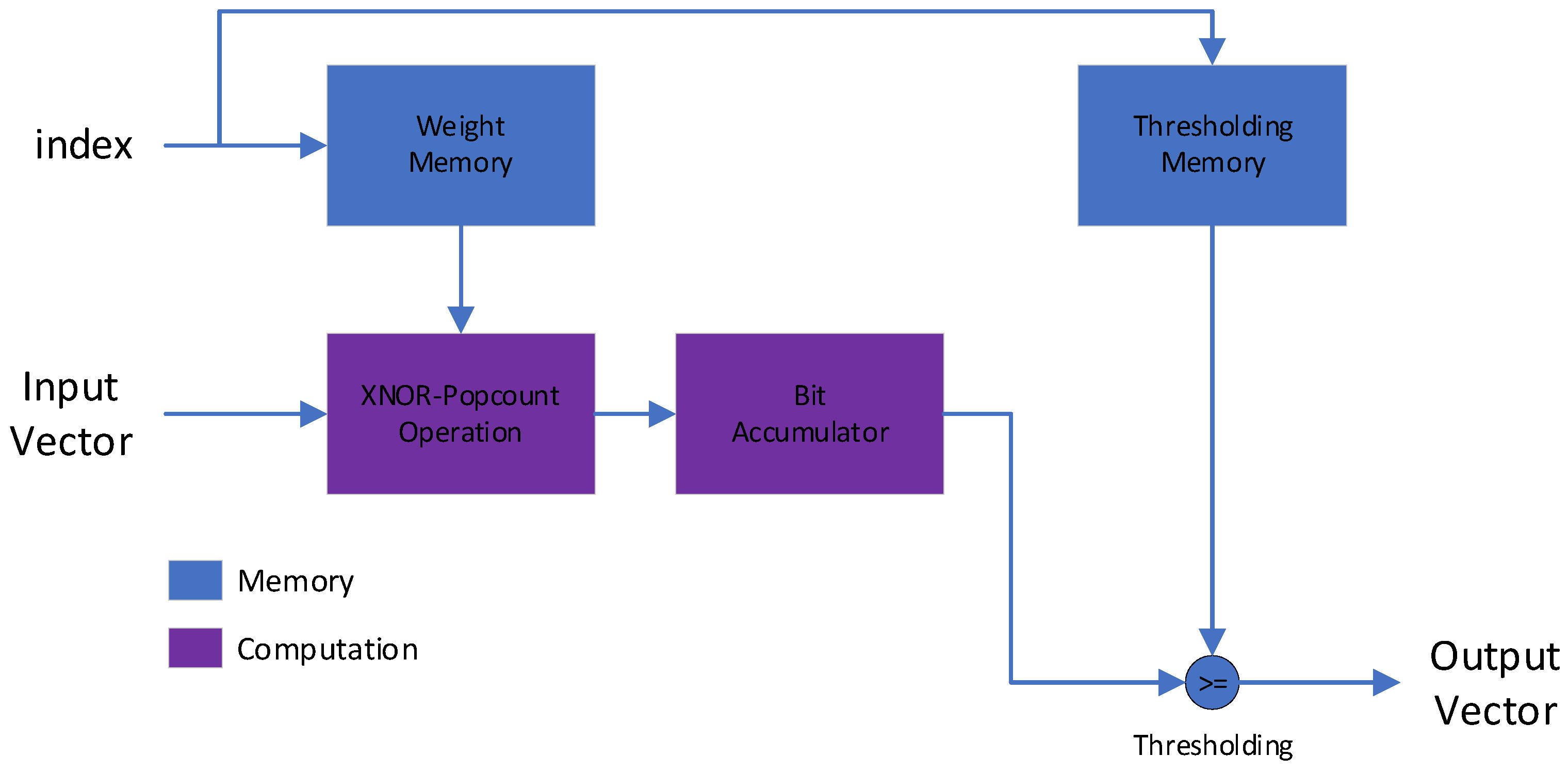
3. FPGA Implementation
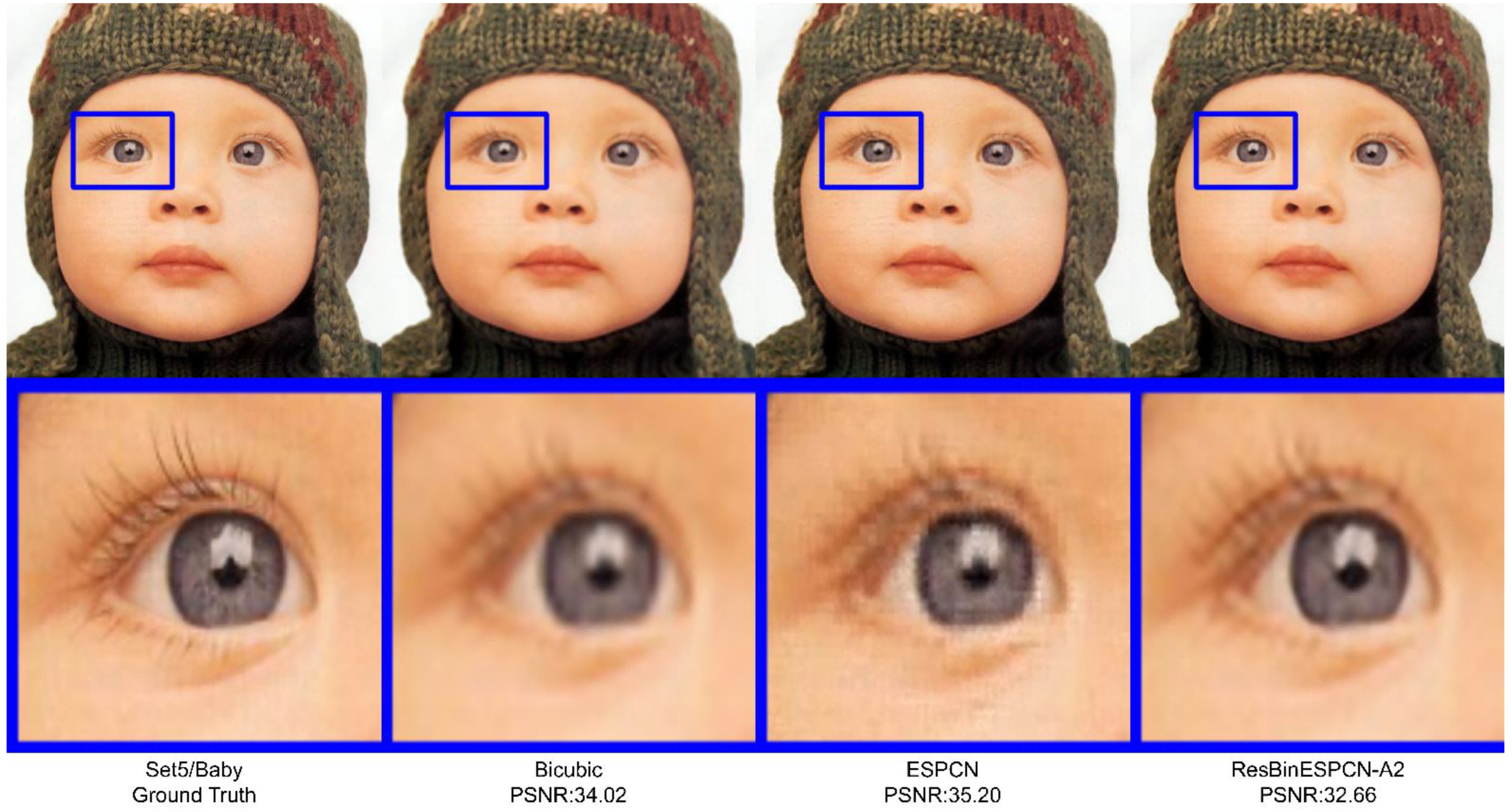
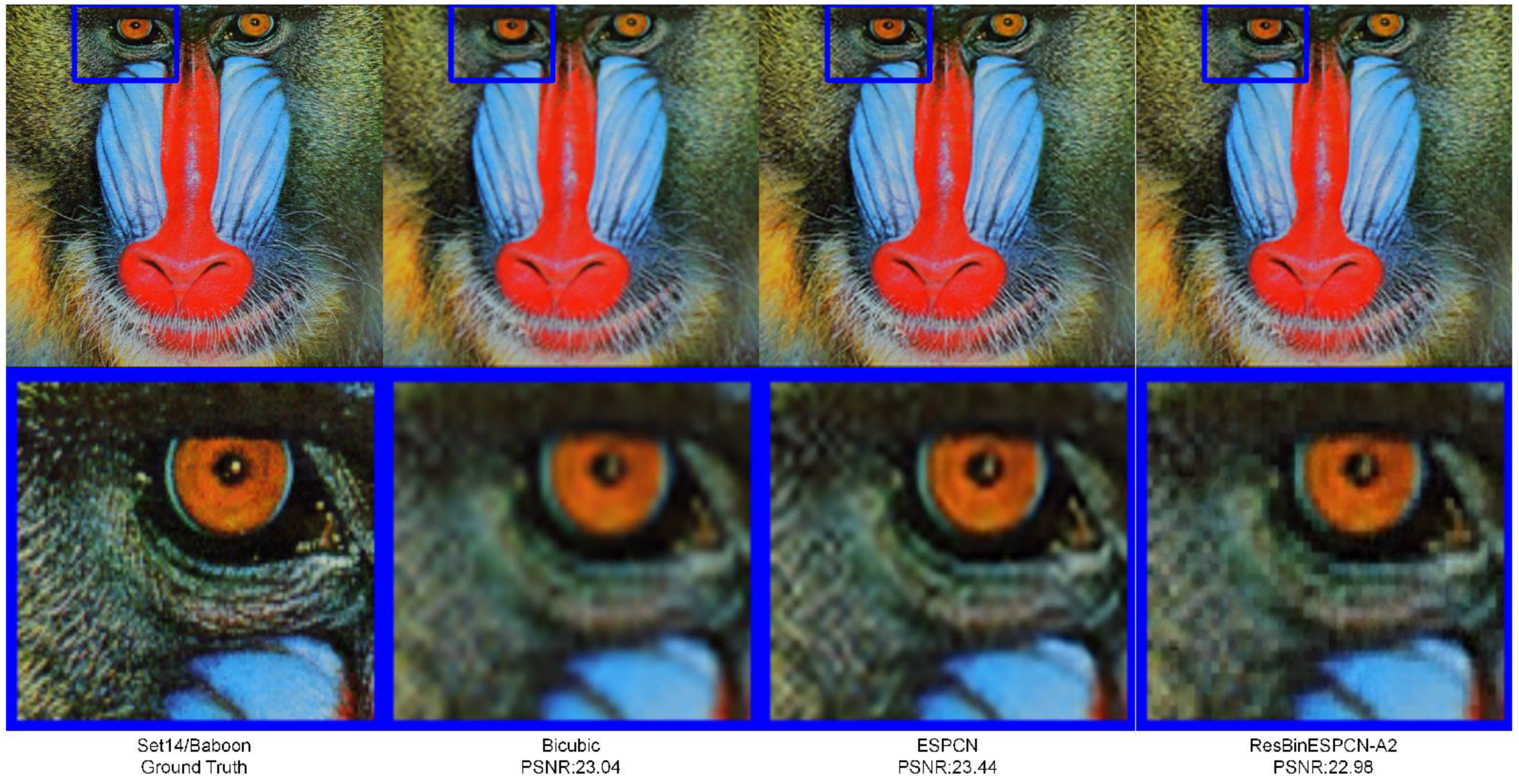
4. Results
5. Conclusions
6. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Heltin Genitha, C.; Vani, K. Super Resolution Mapping of Satellite Images Using Hopfield Neural Networks. In Proceedings of the Recent Advances in Space Technology Services and Climate Change 2010 (RSTS & CC-2010), Chennai, India, 13–15 November 2010; pp. 114–118. [Google Scholar]
- Zhang, H.; Yang, Z.; Zhang, L.; Shen, H. Super-Resolution Reconstruction for Multi-Angle Remote Sensing Images Considering Resolution Differences. Remote Sens. 2014, 6, 637–657. [Google Scholar] [CrossRef]
- Umehara, K.; Ota, J.; Ishida, T. Application of Super-Resolution Convolutional Neural Network for Enhancing Image Resolution in Chest CT. J. Digit. Imaging 2018, 31, 441–450. [Google Scholar] [CrossRef] [PubMed]
- You, C.; Li, G.; Zhang, Y.; Zhang, X.; Shan, H.; Ju, S.; Zhao, Z.; Zhang, Z.; Cong, W.; Vannier, M.W.; et al. CT Super-Resolution GAN Constrained by the Identical, Residual, and Cycle Learning Ensemble(GAN-CIRCLE). IEEE Trans. Med. Imaging 2020, 39, 188–203. [Google Scholar] [CrossRef] [PubMed]
- Shamsolmoali, P.; Zareapoor, M.; Jain, D.K.; Jain, V.K.; Yang, J. Deep Convolution Network for Surveillance Records Super-Resolution. Multimed. Tools Appl. 2019, 78, 23815–23829. [Google Scholar] [CrossRef]
- Rasti, P.; Uiboupin, T.; Escalera, S.; Anbarjafari, G. Convolutional Neural Network Super Resolution for Face Recognition in Surveillance Monitoring. In Proceedings of the 9th International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 13–15 July 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 175–184. [Google Scholar]
- Shen, Z.; Xu, Y.; Lu, G. CNN-Based High-Resolution Fingerprint Image Enhancement for Pore Detection and Matching. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 426–432. [Google Scholar]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F.; Farrugia, R.A. Exploring Deep Learning Image Super-Resolution for Iris Recognition. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 2176–2180. [Google Scholar]
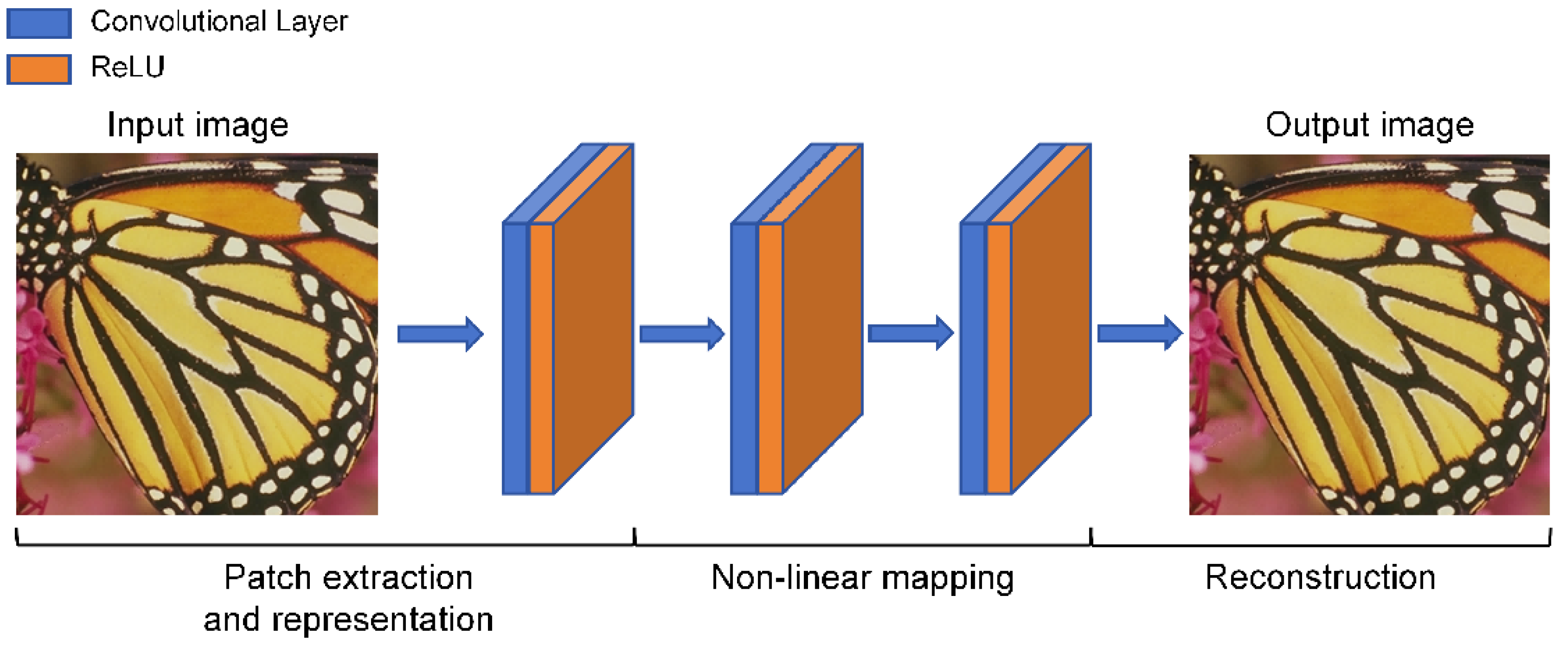
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Tong, C.S.; Leung, K.T. Super-Resolution Reconstruction Based on Linear Interpolation of Wavelet Coefficients. Multidim. Syst. Signal Process. 2007, 18, 153–171. [Google Scholar] [CrossRef]
- Liu, J.; Gan, Z.; Zhu, X. Directional Bicubic Interpolation—A New Method of Image Super-Resolution; Atlantis Press: Amsterdam, The Netherlands, 2013; pp. 463–470. [Google Scholar]
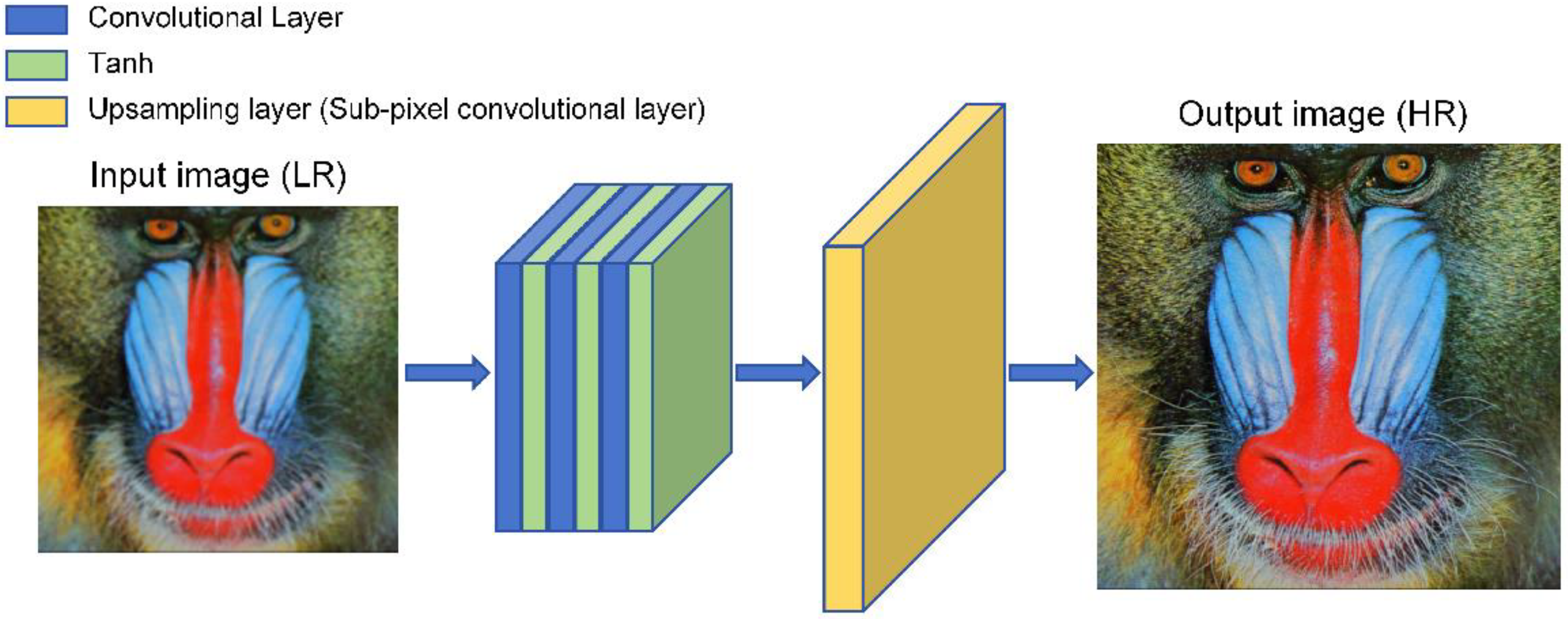
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Convolutional Auto-Encoders with Symmetric Skip Connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2015. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and Accurate Single Image Super-Resolution via Information Distillation Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Song, D.; Xu, C.; Jia, X.; Chen, Y.; Xu, C.; Wang, Y. Efficient Residual Dense Block Search for Image Super-Resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, H.; Yan, C.; Lin, S.; Zheng, X.; Li, Y.; Zhang, B.; Yang, F.; Ji, R. PAMS: Quantized Super-Resolution via Parameterized Max Scale. In Proceedings of the 16th European Conference on Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Jiang, X.; Wang, N.; Xin, J.; Li, K.; Yang, X.; Gao, X. Training Binary Neural Network without Batch Normalization for Image Super-Resolution. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1700–1707. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, N.; Xin, J.; Li, K.; Yang, X.; Li, J.; Gao, X. Toward Pixel-Level Precision for Binary Super-Resolution With Mixed Binary Representation. IEEE Trans. Neural Netw. Learning Syst. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Qin, H.; Cai, Z.; Zhang, M.; Ding, Y.; Zhao, H.; Yi, S.; Liu, X.; Su, H. BiPointNet: Binary Neural Network for Point Clouds. arXiv 2021, arXiv:2010.05501. [Google Scholar]
- Kung, J.; Zhang, D.; van der Wal, G.; Chai, S.; Mukhopadhyay, S. Efficient Object Detection Using Embedded Binarized Neural Networks. J. Signal Process. Syst. 2018, 90, 877–890. [Google Scholar] [CrossRef]
- Ngadiuba, J.; Loncar, V.; Pierini, M.; Summers, S.; Guglielmo, G.D.; Duarte, J.; Harris, P.; Rankin, D.; Jindariani, S.; Liu, M.; et al. Compressing Deep Neural Networks on FPGAs to Binary and Ternary Precision with Hls4ml. Mach. Learn. Sci. Technol. 2020, 2, 015001. [Google Scholar] [CrossRef]
- Fasfous, N.; Vemparala, M.-R.; Frickenstein, A.; Frickenstein, L.; Badawy, M.; Stechele, W. BinaryCoP: Binary Neural Network-Based COVID-19 Face-Mask Wear and Positioning Predictor on Edge Devices. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 108–115. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Liu, Z.; Wu, B.; Luo, W.; Yang, X.; Liu, W.; Cheng, K.-T. Bi-Real Net: Enhancing the Performance of 1-Bit CNNs with Improved Representational Capability and Advanced Training Algorithm. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 722–737. [Google Scholar]
- Sun, R.; Zou, W.; Zhan, Y. “Ghost” and Attention in Binary Neural Network. IEEE Access 2022, 10, 60550–60557. [Google Scholar] [CrossRef]
- Liu, C.; Ding, W.; Chen, P.; Zhuang, B.; Wang, Y.; Zhao, Y.; Zhang, B.; Han, Y. RB-Net: Training Highly Accurate and Efficient Binary Neural Networks With Reshaped Point-Wise Convolution and Balanced Activation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6414–6424. [Google Scholar] [CrossRef]
- Bethge, J.; Yang, H.; Bornstein, M.; Meinel, C. BinaryDenseNet: Developing an Architecture for Binary Neural Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1951–1960. [Google Scholar]
- Ding, R.; Liu, H.; Zhou, X. IE-Net: Information-Enhanced Binary Neural Networks for Accurate Classification. Electronics 2022, 11, 937. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. XNOR-Net++: Improved Binary Neural Networks. arXiv 2019, arXiv:1909.13863. [Google Scholar]
- Liu, Z.; Shen, Z.; Savvides, M.; Cheng, K.-T. ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions. In Proceedings of the 16th European Conference on Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 143–159. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and Backward Information Retention for Accurate Binary Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2247–2256. [Google Scholar]
- Tu, Z.; Chen, X.; Ren, P.; Wang, Y. AdaBin: Improving Binary Neural Networks with Adaptive Binary Sets. In Proceedings of the 17th European Conference on Computer Vision–ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Zhang, J.; Su, Z.; Feng, Y.; Lu, X.; Pietikäinen, M.; Liu, L. Dynamic Binary Neural Network by Learning Channel-Wise Thresholds. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 1885–1889. [Google Scholar]
- Ma, Y.; Xiong, H.; Hu, Z.; Ma, L. Efficient Super Resolution Using Binarized Neural Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 694–703. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xin, J.; Wang, N.; Jiang, X.; Li, J.; Huang, H.; Gao, X. Binarized Neural Network for Single Image Super Resolution. In Proceedings of the 16th European Conference on Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; Volume 12349, pp. 91–107, ISBN 978-3-030-58547-1. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Blott, M.; Preusser, T.; Fraser, N.; Gambardella, G.; O’Brien, K.; Umuroglu, Y. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. ACM Trans. Reconfigurable Technol. Syst. 2018, 11, 1–23. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Proceedings of the 12th Asian Conference on Computer Vision—ACCV 2014, Singapore, 1–5 November 2014; Springer International Publishing: Cham, Switzerland, 2015; pp. 111–126. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, M.A. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the 2012 British Machine Vision Conference, Surrey, UK, 3–7 September 2012; British Machine Vision Association: Surrey, UK, 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up Using Sparse-Representations. In Proceedings of the 7th International Conference on Curves and Surfaces, Avigbion, France, 24–30 June 2010; Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input Shape | BOPs/MAC | Total Number of Bits for Layer Parameters | Estimated Total Size (MB) |
|---|---|---|---|---|
| SRCNN | Bicubic (1, 1, 255, 255) | 590.42 | 18.30 | 50.95 |
| ESPCN | LR (1, 1, 85, 85) | 167.38 | 7.23 | 6.19 |
| DRRN | Bicubic (1, 1, 255, 255) | 51,271 | 236 | 3397.83 |
| RDN | LR (1, 1, 85, 85) | 160,590 | 713.46 | 670.5 |
| Z7P (XCZU7EV-2FFVC1156-MPSoC) | |
|---|---|
| System Logic Units | 504 K |
| DSPs | 1728 |
| LUTs | 230.4 K |
| LUTRAM | 101.76 K |
| FF | 460.8 K |
| Block Ram (BRAM) | 312 |
| Dataset | Scale | Bicubic | ESPCN | BinESPCN | ResBinESPCN-A1 | ResBinESPCN-A2 | VDSR BAM | SRResNet BAM | BSRN |
|---|---|---|---|---|---|---|---|---|---|
| Set5 | 3 | 30.46 | 32.29 | 25.20 | 27.30 | 29.82 | 32.52 | 33.33 | - |
| Set14 | 27.59 | 28.90 | 24.28 | 25.60 | 27.33 | 29.17 | 29.63 | - | |
| BSDS100 | 27.26 | 28.16 | 24.37 | 25.53 | 27.03 | - | - | - | |
| Set5 | 4 | 28.48 | 28.80 | 23.80 | 26.00 | 28.11 | 30.31 | 31.24 | 31.35 |
| Set14 | 25.92 | 26.16 | 22.69 | 24.46 | 25.78 | 27.46 | 27.97 | 28.04 | |
| BSDS100 | 26.02 | 26.21 | 22.99 | 24.73 | 25.87 | - | - | - |
| Model | Parameters | MACs | BOPs/MACs | Total Number of Bits for Layer Outputs | Total Number of Bits for Layer Parameters |
|---|---|---|---|---|---|
| ESPCN | 23 K | 0.163 | 167.38 | 242.76 | 7.23 |
| VDSR_BAM | 668 K | 616.9 | - | - | - |
| SRResNet BAM | 1547 K | 127.9 | - | - | - |
| BSRN | 1216 K | 85 | - | - | - |
| BinESPCN | 349 K | 1.2433 | 3.50 | 464.71 | 3.01 |
| ResBinESPCN-A1 | 349 K | 1.2435 | 3.53 | 464.71 | 3.01 |
| ResBinESPCN-A2 | 349 K | 1.2435 | 36.38 | 464.71 | 3.01 |
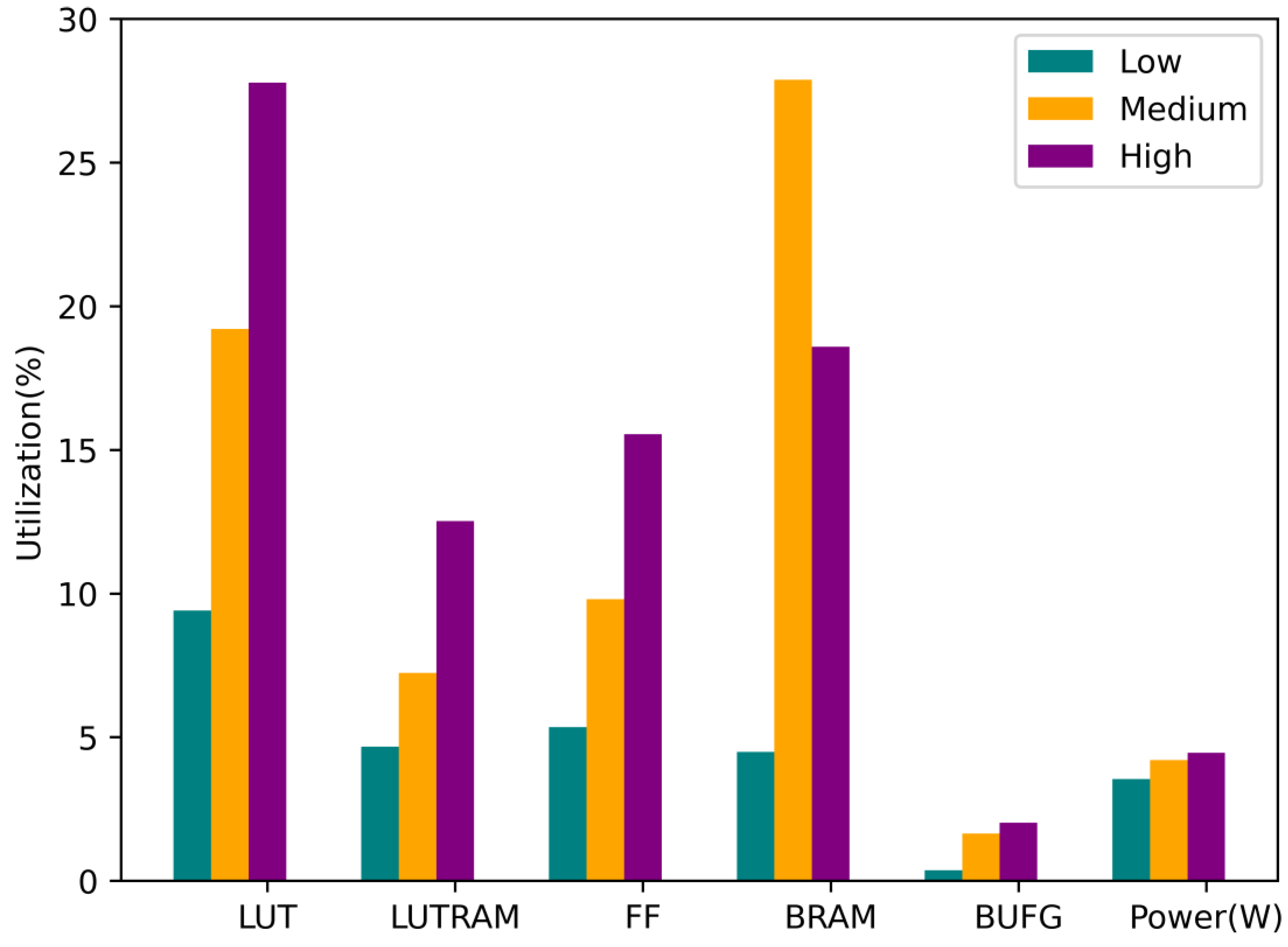
| Board | Model | Parallelism | LUT (Utilization) | LUTRAM | FF | BRAM | BUFG | Power (W) |
|---|---|---|---|---|---|---|---|---|
| Z7P | ResBinESPCN-A2 | Low | 21,685 (9.41%) | 4752 (4.67%) | 24,653 (5.35%) | 14 (4.49%) | 2 (0.37%) | 3.545 |
| Medium | 44,255 (19.21%) | 7372 (7.24%) | 45,144 (9.8%) | 87 (27.88%) | 9 (1.65%) | 4.207 | ||
| High | 64,015 (27.78%) | 12,736 (12.52%) | 70,154 (15.55%) | 58 (18.59%) | 11 (2.02%) | 4.452 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Y.; Seng, K.P.; Smith, J.; Ang, L.M. Efficient FPGA Binary Neural Network Architecture for Image Super-Resolution. Electronics 2024, 13, 266. https://doi.org/10.3390/electronics13020266
Su Y, Seng KP, Smith J, Ang LM. Efficient FPGA Binary Neural Network Architecture for Image Super-Resolution. Electronics. 2024; 13(2):266. https://doi.org/10.3390/electronics13020266
Chicago/Turabian StyleSu, Yuanxin, Kah Phooi Seng, Jeremy Smith, and Li Minn Ang. 2024. "Efficient FPGA Binary Neural Network Architecture for Image Super-Resolution" Electronics 13, no. 2: 266. https://doi.org/10.3390/electronics13020266