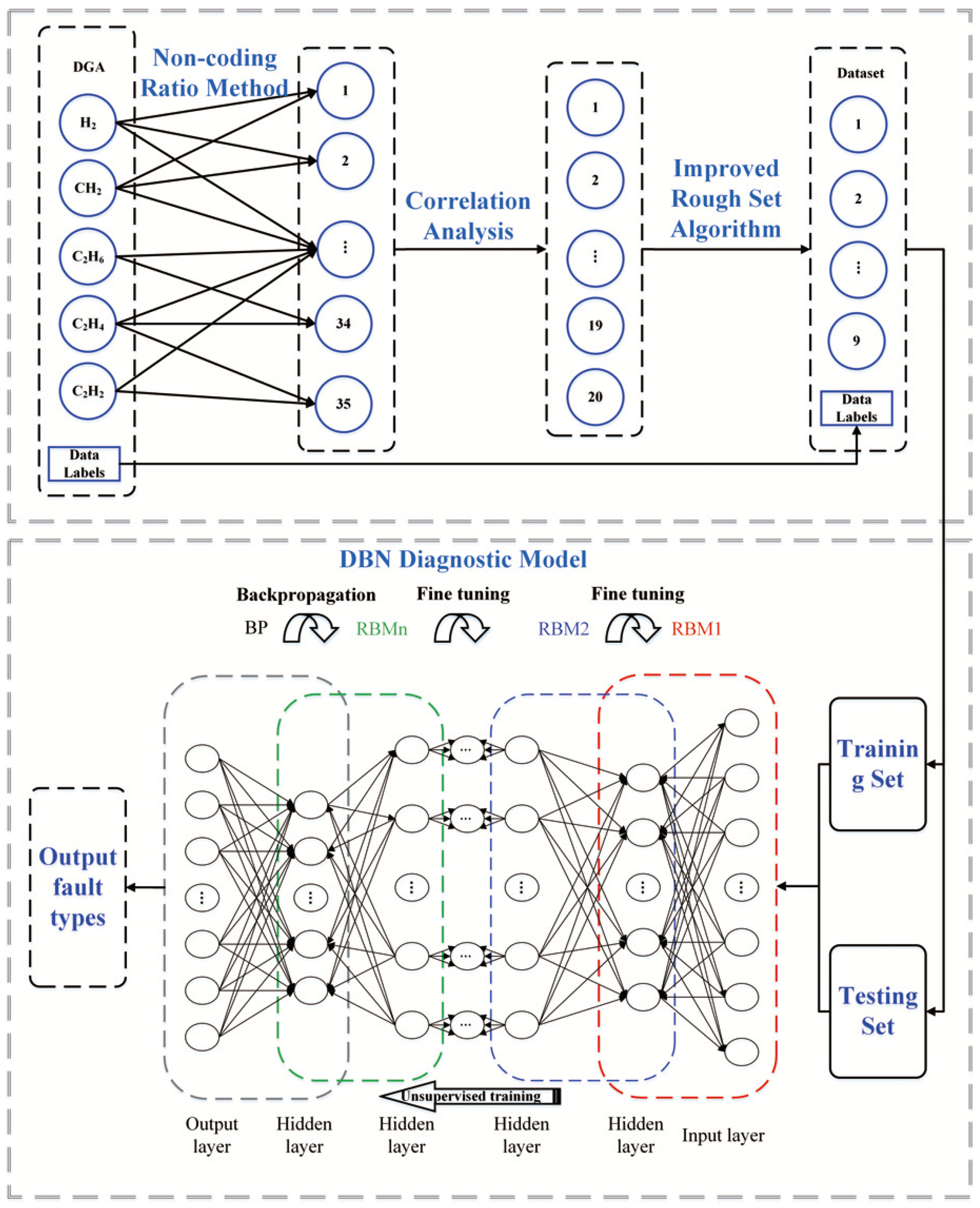
Based on the analysis in the previous section, the fault types of oil-immersed transformers can be summarized as six categories: LED, HED, PD, HTO, MLTO, and Normal. Consequently, the fault diagnosis problem for oil-immersed transformers can be treated as a six-class classification task. To accomplish this classification task, we have constructed a DBN diagnostic model based on the proposed INRS algorithm. The overall framework is illustrated in
Figure 1. DGA data contain historical data on the content of five fault gases in oil-immersed transformers under different fault types, which can be used for model training in transformer fault diagnosis. The DGA data used in this paper can be obtained from
https://github.com/Cliango/DGA.git (accessed on 20 July 2023). The dataset contains a total of 617 samples, including 102 LEDs, 168 HEDs, 47 PDs, 133 HTOs, 77 MLTOs, and 90 Normal samples. The specific distribution of data samples can be found in
Table 3. Each sample consists of gas content of five fault gases:
,
,
,
, and
.
3.1. Non-Coding Ratio Processing
Conventional methods for diagnosing transformer faults using fault gases from DGA data (such as the IEC three-ratio method, Doernenberg ratio method, and Rogers ratio method) have demonstrated the utility of gas ratios in fault diagnosis for oil-immersed transformers. Additionally, there is a close connection between the changes in the proportion of fault gases and the fault types. Hence, gas ratios among the five fault gases can be utilized as features to analyze and determine the internal operational status of the transformer. The five basic fault gases alone cannot fully reflect the fault information of the transformer. To further explore the fault information, a total of 35 gas ratios have been constructed using a non-coding ratio method, as outlined in
Table 4. Here,
represents first-order hydrocarbons (i.e.,
), and
represents the sum of second-order hydrocarbons (i.e.,
).
Although we conducted non-coding ratio processing on five types of fault gases, resulting in 35 ratios indicative of these faults and allowing for a more comprehensive reflection of transformer fault types, it is important to note that these features may exhibit linear relationships among themselves. To avoid introducing redundant feature variables, we performed a correlation analysis among the 35 features, further eliminating highly correlated feature variables to streamline the input features of the model.
Let
represent the dataset obtained after non-coding ratio processing of the DGA data, where
is the
i-th sample,
represents the
j-th feature within the sample
, and
. Using all 35 feature gas ratios as input features may result in high dimensionality, increasing the complexity of the diagnostic model. Moreover, an excessive number of input features can introduce interference from features with low correlation, potentially affecting the diagnostic accuracy. Therefore, before establishing the diagnostic model, feature selection and dimensionality reduction are essential to ensure the model’s efficiency and accuracy while avoiding unnecessary interference. To achieve this, a Pearson correlation analysis is first applied to the data
D, eliminating features that exhibit linear relationships, thereby preventing the introduction of redundant information or multicollinearity. Let data matrix
, where the
i-th row of
X (i.e.,
) represents the
i-th feature of the samples. The correlation coefficient between any two features can be calculated by
where
and
represent the mean and variance of
, respectively. The correlation coefficient
R has a range between −1 and 1. When
R is close to 1 (−1), it indicates a stronger positive (negative) correlation between features
and
. When
R is close to 0, it signifies no linear correlation between the two features. In this paper, we remove the gas ratio features in the data where
. The reason for removing feature gas ratios with correlation coefficients greater than 0.7 is that during the feature selection process, we noticed that coefficients exceeding 0.7 may indicate strong linear relationships among features, thereby introducing multicollinearity, which can affect the model’s robustness and interpretability. However, through a series of experiments, we found that setting the correlation coefficient threshold to 0.7 effectively streamlined the model, maintaining a high diagnostic accuracy while efficiently reducing model complexity by avoiding excessive redundant information. This strategy not only enhanced the model’s interpretive capacity but also improved the overall experimental outcomes and diagnostic precision.
The results indicate that there are 20 gas ratio features with correlation coefficient
, specifically, features numbered 2, 3, 6, 9, 16, 19, 21–23, and 25–35 in
Table 4. These features exhibit strong linear correlations with each other. To avoid introducing redundant information, these features are removed from the dataset
D, resulting in the dataset
, containing 15 gas ratio features. After removing linearly correlated feature gas ratios, there are a total of 15 remaining, as detailed in
Table 5.
3.2. Feature Selection Based on the Improved NRS
Correlation analysis can eliminate redundant information between features, but to comprehensively assess the importance of features, it is essential to examine the relationship between features and the target variable, i.e., the correlation between features and the target variable. In general, features that exhibit a higher correlation with the target variable are more likely to contribute to the predictive capability of the model. The neighborhood rough sets (NRS) algorithm is a data mining algorithm based on rough set theory, used for feature selection and data reduction. It evaluates each attribute by calculating attribute importance, thereby eliminating redundant information and unimportant attributes from the dataset while retaining the most valuable attributes.
For a decision system
, where
U is the universe of discourse,
C represents conditional attributes,
is the set of decision attributes, and
,
denotes the collection of attributes’ values. The information function
represents the mapping relationship between samples, attributes, and attribute values. In this paper, the set composed of feature gases represents the set of conditional attributes, denoted as
C, while the set consisting of the five fault types serves as the set of decision attributes. Let
B be a subset of conditional attributes, specifically, a subset of all feature gases. For any
, the dependency of decision attributes
E on conditional attributes
B is defined as
where
represents the lower approximation of the attribute subset. The formula for calculating the importance of a certain conditional attribute to the decision attribute is
The NRS have certain limitations and drawbacks in feature selection. When the number of samples varies significantly across different classes within the dataset, the NRS might exhibit bias towards classes with larger sample sizes, impacting the feature selection process. Moreover, these methods heavily rely on dataset partitioning, leading to potentially different outcomes based on various data splits, thus affecting the consistency and stability of feature selection. Symmetrical Uncertainty (SU) is a measure based on information theory, designed to quantify the association between features and target variables. As a metric for feature selection, SU aids in assessing the correlation between features and target variables, enabling the identification of influential features impacting the target. By eliminating highly correlated features, it mitigates multicollinearity, reducing the risk of model overfitting and enhancing model generalization. The application of SU facilitates the reduction of feature dimensions while retaining critical features, thus streamlining the model and improving its efficiency. The introduction of SU as an alternative method helps overcome some of the limitations associated with domain rough set methods.
Let
be the data matrix after the correlation analysis in
Section 3.1, where
for
represents the
i-th feature after reduction. The SU value between the 15 gas ratio features and the label vector can be calculated using the following formula:
where
Y is the vector of the class label for sample,
represents information gain, and
represents information entropy. By incorporating the measure of uncertainty (
4) into the attribute importance (
3), we have developed a rough set-based attribute reduction method based on SU
By incorporating SU into the attribute importance assessment within the NRS algorithm, we have developed an improved neighborhood rough set algorithm used to evaluate the correlation between feature variables and the target variable (i.e., label vector).
The main steps of this algorithm are as follows:
Step 1: Data normalization.
Step 2: Calculate the attribute importance SUSIG for 15 attributes according to (
5), and sort the attributes in descending order based on SUSIG,
, and the sorted attributes are denoted as
.
Step 3: Taking the attribute with the highest attribute importance as the initial reduction, denoted as , calculate according to (2), and set .
Step 4: Neighborhood construction. Calculate the standard deviation for each attribute , and construct the neighborhood radius , where is a predetermined parameter used to adjust the neighborhood size, typically ranging from 2 to 4. Based on the importance of attributes, select a set of the most important attributes to form the neighborhood, creating a neighborhood rough set.
Step 5: Set and . Calculate according to (2) and set . If , then and proceed to the next step; otherwise, stop.
Step 6: Data reduction. Utilize the neighborhood rough set for data reduction, eliminating redundant information and unimportant attributes from the dataset while retaining the most valuable attributes.
In order to minimize the reduced features, we set the parameter
. Subsequently, the algorithm steps described above are applied to the dataset
, leading to the removal of low-importance gas ratio features. The result is a set of 8 gas ratio features that exhibit high correlation with the fault labels, as detailed in
Table 6.
3.3. Transformer Diagnostic Model Based on DBN
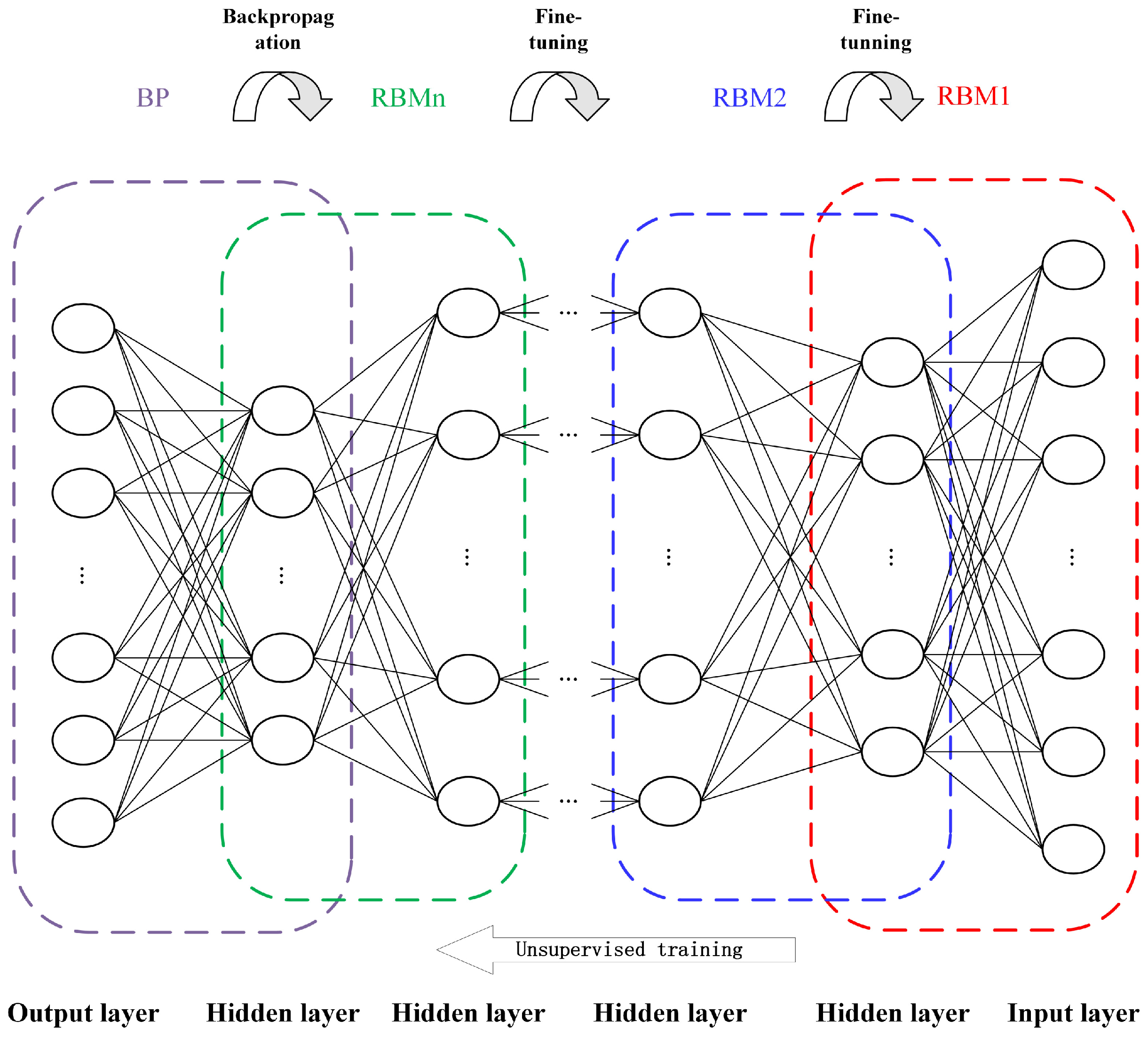
DBN is a deep learning model constructed by stacking multiple Restricted Boltzmann Machines (RBM). The network structure is illustrated in
Figure 2.
Each RBM consists of two layers of neurons, with the visible layer receiving input data and the hidden layer used to capture abstract features of the data. The training process of a DBN comprises two phases: unsupervised pre-training and fine-tuning.
Unsupervised Pre-Training: Starting from the bottom, each RBM is trained layer by layer. The hidden layer’s output of each RBM is used as the visible layer input for the next RBM. Through parameter updates, it reconstructs the distribution of the input data. During this process, network connection weights between neurons with the smallest reconstruction error are chosen, resulting in a new hidden layer for RBM1. This new hidden layer is then employed as the visible layer for training RBM2. This process continues, stacking multiple layers of RBMs to extract data features. The goal is to make the final feature representation as close as possible to the distribution of the original input data. Throughout the pre-training process, no labels of the data are used, making this phase an unsupervised learning process. The pseudocode in Algorithm 1 describes the training process of the DBN model.
| Algorithm 1: Deep Belief Network (DBN) |
- 1:
DBN Initialize: - 2:
Initialize weights and biases for each layer - 3:
Set learning rate and other hyperparameters - 4:
Train RBM Layer: - 5:
for each RBM layer do - 6:
Train RBM with input data - 7:
Update weights and biases - 8:
end for - 9:
Build DBN: - 10:
for each layer in DBN do - 11:
Train RBM layer with input data - 12:
end for - 13:
Fine-Tune DBN: - 14:
Fine-tune the entire DBN using backpropagation or other optimization algorithms - 15:
Update all weights and biases
|
Fine-Tuning: While the DBN model can establish initial deep features through layer-wise pre-training, it cannot guarantee the attainment of globally optimal deep feature representations since each RBM is trained independently to minimize the reconstruction error. To further optimize the entire DBN model and ensure the acquisition of superior deep feature representations, it is common to add a back-propagation network connected to a classifier at the end of the DBN. This is conducted for fine-tuning. The fine-tuning process employs supervised learning, using labeled data to adjust the parameters of the entire DBN, including the weights and biases, in order to minimize the classifier’s loss function. This way, the entire DBN model can better adapt to a specific classification task and obtain improved feature representations.
We use a DBN to perform the classification task of oil-immersed transformer fault types. The six fault types, namely, LED, HED, PD, HTO, MLTO, and Normal, are encoded as (1, 0, 0, 0, 0, 0), (0, 1, 0, 0, 0, 0), (0, 0, 1, 0, 0, 0), (0, 0, 0, 1, 0, 0), (0, 0, 0, 0, 1, 0), and (0, 0, 0, 0, 0, 1), respectively. The nine gas ratio features, which have been reduced through correlation analysis and the INRS algorithm as discussed in
Section 3.2, are used as the input layer for the DBN, while the five fault type encodings serve as the output layer. The complete steps for oil-immersed transformer fault diagnosis are as follows:
Step 1: Collect the dissolved gas analysis data of various fault gases during the operation of oil-immersed transformers.
Step 2: Conduct non-coding ratio processing for the fault gases in the data to obtain 35 gas ratio features.
Step 3: Remove redundant features through correlation analysis and normalize the data. Utilize the Neighborhood Rough Sets algorithm for feature selection to eliminate features that have minimal contributions to fault types, optimizing the feature set.
Step 4: Split the processed data into training and testing sets in a certain proportion to ensure the independence of model training and evaluation.
Step 5: Use the selected gas ratio features and binary-encoded fault types as the input and output layers of the DBN, respectively. Determine the DBN network parameters, including the number of network layers, learning rate, and the number of neurons in the hidden layers.
Step 6: Pre-train and fine-tune the DBN network until reaching the specified number of training iterations or the desired error threshold to complete the DBN fault diagnosis model. Input the test data into the model to obtain the output results.
When training a DBN, it is necessary to set and select network parameters such as the number of network layers, learning rate, and the number of neurons in the hidden layers, as mentioned in Step 5. Properly configuring these network parameters can optimize the DBN model and improve its performance and effectiveness. Since there are no fixed rules or criteria to determine the best parameters, experimentation and practical trials are required to continuously try and optimize to find the most suitable parameter configuration.
According to
Figure 2, in the processed data, each class of samples is divided into a testing set and a training set in a 7:3 ratio, with 70% of the data used for training and 30% for testing the model’s performance. In the model, the learning rate for RBMs is set to 0.01. This learning rate is used during the pre-training process and controls the rate at which the RBM network weights are updated to gradually converge to better feature representations. In the BP fine-tuning algorithm, dynamic learning rates are generally used, with an initial value set to 0.01. Dynamic learning rates are an adaptive learning rate strategy that allow for the dynamic adjustment of the learning rate during training based on the model’s performance. The purpose of this approach is to use a larger learning rate in the early stages of training to expedite convergence and gradually reduce the learning rate in the later stages to stabilize the convergence process of the model.
The number of neurons in the hidden layer is equivalent to the number of nodes in the hidden layer. When the number of hidden layers is determined, the number of neurons in the hidden layer also becomes a significant factor affecting diagnostic accuracy. If the number of neurons is much larger than the number of input and output nodes, it may result in overfitting during the feature extraction process, causing the original data’s features to overly disperse, thereby failing to capture the essential characteristics. Conversely, if the number of neurons is too small compared to the number of input and output nodes, it might lead to insufficient learning of the original signal’s features. Currently, there are four main approaches for determining the number of neurons: fixed-value combination, concave–convex combination, decreasing-value combination, and increasing-value combination. There are empirical formulas for selecting the number of neurons, which are as follows:
where
m represents the number of neurons in the input layer,
n represents the number of neurons in the output layer,
p denotes the number of neurons in the hidden layer, and
d stands for an additional compensatory value, typically within the range of [0, 10].
To determine the optimal number of hidden layers and hidden layer nodes, nine different configurations of DBN network models based on (
6) were set up: 8-5-6, 8-10-6, 8-15-6, 8-5-5-6, 8-10-10-6, 8-15-15-6, 8-5-5-5-6, 8-10-10-10-6, and 8-15-15-15-6. Each model was experimented with 10 times, and the average diagnostic accuracy was calculated. The specific results are shown in
Table 7.
From
Table 7, it can be observed that as the number of neurons in the hidden layers increases, the diagnostic accuracy of the DBN model gradually improves. This is because having more neurons allows for better feature extraction, enhancing the model’s fitting capacity. However, when the number of hidden layers increases to 2 or more, the diagnostic accuracy of the DBN model starts to decline. The reason for this could be that for a specific DGA dataset, when the number of hidden layers exceeds 2, the DBN network may become too complex and may not generalize well to unseen data, resulting in a decrease in diagnostic accuracy. Based on this analysis, we adopt a 3-layer DBN network structure.






{kind=link}
{kind=link}
{kind=link}
{kind=link}