1. Introduction
Images are often damaged by some factors, i.e., light, shaking, and digital devices when they are collected by digital devices, which may cause captured images to be noisy [
1]. To restore these images, image denoising techniques were developed [
2]. Most of these denoising methods implement a denoising function by using a degradation model of
d =
c +
n, where
d expresses a damaged image,
c is a clean image, and
n stands for the predicted noise [
3].
In general, image denoising methods include two categories. The first is model methods and the second is deep learning methods. For the first type of methods, many excellent models have been developed in recent years by improving models and combining new techniques. Specifically, Li et al. [
4] proposed a novel image denoising method that combines non-local means and grey theory. Unlike traditional non-local methods, it analyzes the structural similarity through the grayscale relation of the coefficients and sets similar weight functions accordingly, effectively reducing the time complexity. Zhang et al. [
5] first used a non-local mechanism to up-sample in hierarchical network to obtain features related to self-similarity measurements. Sparse method is also popular in image denoising. For example, Xiao et al. [
6] proposed a hierarchical sparse model that can achieve a good generalization to images with different features in different domains. Shi et al. [
7] proposed a denoising method to reconstruct the high-frequency component and the low-frequency component. The high-frequency part is reconstructed by a sparse representation of the structural similarity based on patches, and the low-frequency part is reconstructed by singular value decomposition (SVD). Theoretically, the sparser the image representation, the better the image recovery, but these sparse methods have the problem that the sparse coefficient is difficult to estimate and the search window is limited, so Zhou et al. [
8] propose a method that combines the non-local clustering sparse representation with the optimization matching strategy of self-similar patches, which effectively retains more image details. In addition, there are many excellent model-based methods, such as median filtering algorithm [
9], and a new anisotropic total-variation-based model [
10].
For the second type of methods, they are currently the most popular denoising method. In particular, the convolutional neural network in deep learning, which has fast execution speed and strong learning ability, is widely used in the field of image denoising [
11]. For nearly 10 years, there have been many excellent CNN-based methods for denoising, such as IRCNN [
12], DnCNN [
13], and complex-valued deep CNN [
14]. However, these methods all have a common problem, which is that the network is too deep to train, so to solve the training problem, Tian et al. [
15] propose an enhanced convolutional neural denoising network (ECNDNet), which combines residual learning (RL) [
16], dilated convolution, and batch normalization (BN) [
17] to accelerate network convergence. In addition, CNN combined with other deep learning methods can also achieve better denoising. For example, Zhao et al. [
18] proposed a hybrid denoising model based on transformer encoder and convolutional decoder network, which effectively used the advantages of the two networks to achieve effective real image denoising. Kumwilaisak et al. [
19] proposed a new method based on a deep convolutional neural network and a multidirectional long short-term memory network to remove pine noise from images. Furthermore, the combination of unsupervised and CNN can also achieve a better application scene. For example, in order to solve the overfitting problem caused by the lack of real images, Pan et al. [
20] proposed an unsupervised depth denoiser. Although the appeal method achieved good results in image denoising, we found that in some cases where the noise level is unknown and the image background is complex, it is challenging to obtain some robust information through CNN.
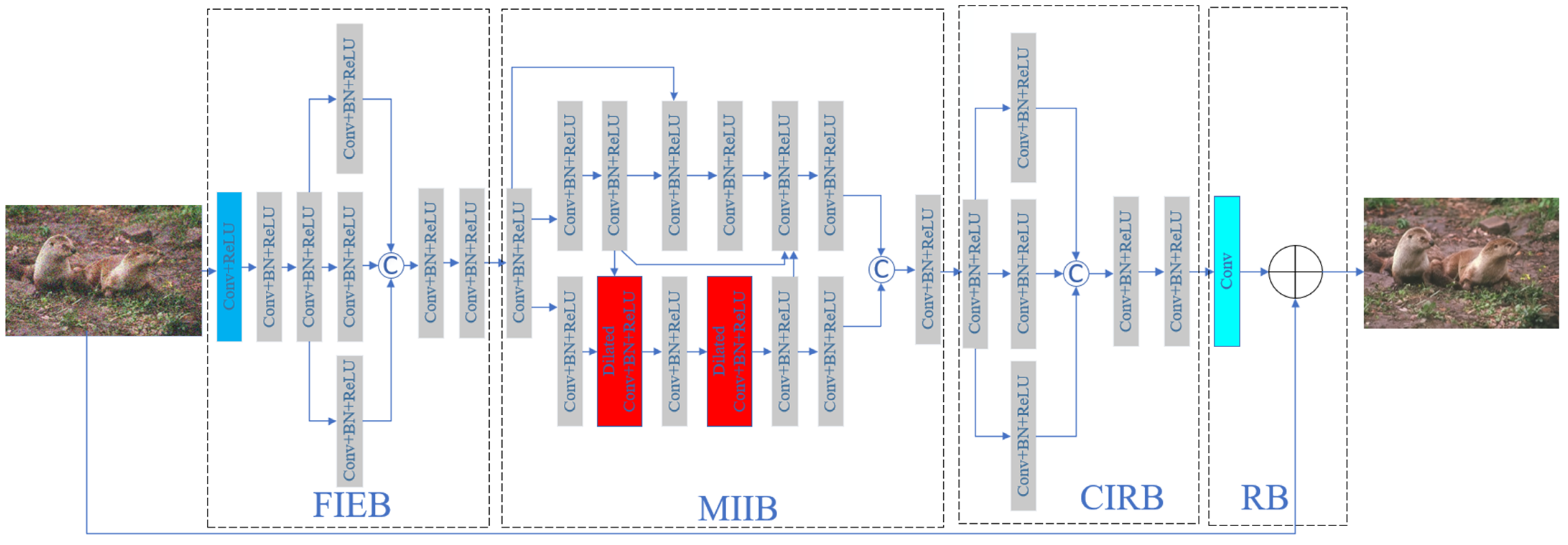
Therefore, in this paper we propose a multi-level information fusion CNN in image denoising (MLIFCNN). It consists of four blocks: a fine information extraction block (FIEB), a multi-level information interaction block (MIIB), a coarse information refinement block (CIRB), and a reconstruction block (RB). FIRB is in charge of extracting wide-channel information through parallel convolution groups. By using a two-layer interaction network, MIIB strengthens the fusion of wide and deep information, which is more conducive to obtaining more robust information. To enhance the stability of the training denoiser, CIRB stacks common and group convolutions to refine and obtain information. Finally, RB uses a residual operation to act in a single convolution to predict and obtain clean images. Our main contributions can be summarized as follows.
- (1)
The proposed MLIFCNN incorporates multi-layer features and effectively improves the denoising performance;
- (2)
FIEB utilizes different groups of odd convolutions to extract wide-channel information and enhance receptive fields to adapt to more complex image backgrounds;
- (3)
MIIB uses dual-network interaction to strengthen the fusion of wide and deep information, which obtains more robust information when the noise level is unknown;
- (4)
CIRB uses common and group convolutions to further enhance the stability of the trained denoiser.
The remainder of this paper is organized as follows.
Section 2 provides related work of image denoising based on deep CNN, group convolution, and CNN-based feature fusion methods.
Section 3 offers the proposed method.
Section 4 shows experimental results.
Section 5 presents the conclusion.
3. Method
In this subsection, we show our proposed denoising network model that consists of FIEB, MIIB, CIRB, and RB. For the design of the network architecture, we changed the form of the traditional grouping convolution [
30] and integrated the residual connection and dilated convolution to better adapt to the image denoising. In order to improve the image denoising effect, we mainly removed the noise through the proposed three blocks of FIEB, MIIB, and CIRB. Specifically, FIEB uses the standard convolutions and parallel group convolutions to extract wide-channel information. To enhance the robustness of the obtained information, MIIB integrates the residual connection, dilated convolution, and standard convolution, and uses the form of dual-network interaction to fuse wide and deep information. To enhance the stability of the training denoiser, CIRB stacks common and group convolutions to refine obtain information.
Below, we properly describe the network model, network modules, and related functions we mentioned.
3.1. Network Model
The paper proposes a network model (MLIFCNN), which is made up of FIEB, MIIB, CIRB, and RB, as shown in
Figure 1. To better clarify the expression process, we express it by the following formula:
where
expresses a predicted clean image,
MLIFCNN denotes the function of MLIFCNN, and
expresses a given noisy image. In addition,
RB,
CIRB,
MIIB, and
FIEB are also functions of RB, CIRB, MIIB, and FIEB, respectively.
3.2. Loss Function
In order to make our denoising network more persuasive, we selected mean square error (MSE) as the loss function to train the model parameters. This process can be described by the following formula:
where
and
denote the
i-th noisy images and given clean images, respectively, and
denotes the parameters in training the denoising model. In addition,
N stands for the total of noisy images.
3.3. Peak Signal-to-Noise Ratio (PSNR)
In order to compare the experimental effect of image denoising more fairly, we chose the peak signal-to-noise ratio as our image quality evaluation technique, and its specific expression is as follows:
where
maxval represents the maximum value in the image data. If it is an 8-bit unsigned integer data type,
maxval is 255. From Equation (3), we can see that it is a representation of absolute error in dB.
3.4. Fine Information Extraction Block
The fine information extraction block consists of standard and group convolution and is mainly used to extract wide-channel information. Specifically, the first layer is made up of a standard convolution and ReLU to extract the shallow features. Its kernel size is 3 × 3, and the input and output channels are 1 and 64, respectively. In extraordinary circumstances, if the network is used for denoising of color images, then its input channel is 3. The ReLU is responsible for converting linear features to non-linear features. The back five layers are an odd convolution group to extract the local wide-channel information and enhance the receptive fields. Specifically, the first two layers both consist of Conv + BN + ReLU, which stands for a combination of a convolutional layer, BN, and ReLU, respectively. The BN is an activation function. Their kernel sizes were 3 × 3, and the input and output channels are 64 and 32, respectively. This is to better preserve the global information for the next phase of training. They are then divided into three groups. The three groups are composed of Conv + BN + ReLU. Their kernel sizes are 3 × 3, 5 × 5, and 7 × 7, respectively. Input and output channels are 32. Finally, the three groups are combined into the latter two layers. The structures of the latter two and the first two layers are similar, except that both the input and output channels are increased to 32. To make the process clearer, we describe it using the following formula:
where
CR denotes 3 × 3 kernel size of Conv + ReLU,
CBR stands for the 3 × 3 kernel size of Conv + BN + ReLU,
CBR5 stands for the 5 × 3 kernel size of Conv + BN + ReLU, and
CBR7 stands for the 7 × 7 kernel size of Conv + BN + ReLU.
Cat represents the connection function C in
Figure 1.
is the output of FIEB.
3.5. Multi-Level Information Interaction Block
The multi-level information interaction block integrates the skip connection, dilated convolution, and some standard convolutions, and uses the form of dual-network interaction to fuse wide and deep information, thus, making the obtained information more robust. The first layer is made up of Conv + BN + ReLU. Behind it is a block of dual-network interaction. The upper network consists of 6 layers, and every layer is made up of Conv + BN + ReLU. Their kernel size is 3 × 3. The lower network also consists of 6 layers, but the 1st, 3rd, 5th, and 6th layers are made up of Conv + BN + ReLU. The 2nd and 4th layers are made up of dilated convolution, BN, and ReLU. Then, the two-layer network input is connected to the last layer of this block. The last layer is also made up of a standard convolution, BN, and ReLU. The above description may be expressed as:
where
DCBR2 represents the Conv + BN + ReLU of dilation = 2 and kernel size = 3 × 3, and
DCBR5 represents the Conv + BN + ReLU of dilation = 5 and kernel size = 3 × 3. The
is the output of MIIB.
3.6. Coarse Information Refinement Block
The coarse information refinement block stacks common and group convolutions to refine obtained information. The first layer of the block is made up of Conv + BN + ReLU, and then it is output to three parallel group convolutions. To reduce the computational amount and expand the receptive field, we utilized the size convolution kernel. Thus, we set their kernels size separately to 1 × 1, 5 × 5, and 7 × 7. Finally, the 3 sets of outputs are connected to the last two-layer network of the block. For a clearer description, we express it by the following formula:
where
CBR1 denotes the 1 × 1 kernel size Conv + BN + ReLU. The
is the output of the CIRB.
3.7. Reconstruction Block
The reconstruction block uses a residual operation to act as a single convolution to predict and obtain clean images, and the process can be explained by the following formula:
where
C stand for the 3 × 3 kernel size convolution, − stands for a residual operation, as represented ⊕ in
Figure 1.
4. Experiment
In this section, we present the datasets we selected and the settings of some experimental parameters, analyze and discuss ablation experiments and comparative experiments, and present the corresponding experimental data and denoising images.
4.1. Datasets
4.1.1. Training Datasets
We used different training sets for different types of images. For the grey synthetic noise images, we used 400 images with a size of 180 × 180 from the Berkeley Segmentation Dataset (BSD) [
38] to train. For the color synthetic noise images, we used 432 color images with a size of 481 × 321 from BSD [
38] for training. In addition, for further image feature description, we randomly divided gray training image into patches of size 40 × 40 and color training image into patches of size 50 × 50. For real noisy images, we used 100 real noisy images with a size of 512 × 512 from the benchmark dataset [
39] to train the model. Also, to increase the diversity of the training sample, we enhanced the image by rotation of the image, such as rotating by 90° counterclockwise, horizontal flip, and rotating by 180° counterclockwise.
4.1.2. Test Datasets
To test the training effect of our model, we chose BSD68 [
40] and Set12 [
41] for the grey image test set, CBSD68 [
40] for the color image test set, and CC [
42] for the real image test set. Their number of images is 68, 12, 68, and 15, respectively.
4.2. Implementation Details
Among the parameters required by our model, the batch size is 128, the initial learning rate is 1 × 10−3, and the number of epochs is 120 and 70 for training the gray images and the color images, respectively. The learning rates vary from 1 × 10−3 to 1 × 10−5 with an increasing epoch. To accelerate the training speed, our experiments were all conducted on a GPU of Nvidia GeForce RTX 3090. Also, its CUDA was 11.7, and cuDNN was 8.0.4. Specifically, we used Pytorch 1.7.0, torchvision 0.8.1, and Python 3.8.13 to train and test our model MLIFCNN.
4.3. Network Analysis
The proposed denoising model (MLIFCNN) includes FIEB, MIIB, CIRB, and RB, and below we specifically describe their rationality and effectiveness.
FIEB: As mentioned in the above method, it is a module that extracts the wide-channel information and enhances receptive fields. Due to grouping convolution [
30], it can achieve good results by reducing the number of model parameters; we propose a parallel group convolution in FIEB. We set three different odd kernel sizes convolutions, of 3, 5, and 7. The benefits of such a setup can be illustrated by
Table 1 and
Table 2 from the ablation experiment. In
Table 1, we find MLIFCNN has a higher PSNR result than MLIFCNN without group convolutions in FIEB. From
Table 2, we can see that the setting of this parameter has a higher PRNR value. Therefore, the proposed parallel group convolutions are effective in image denoising.
MIIB: It is a double-layer interaction module. In general, the interaction between different modules is conducive to the complementarity of global information and local information, increasing horizons and improving model learning ability [
35]. Inspired by this, we used a six-layer Conv + BN + ReLU in the upper network and combined it with the jump connection to interact with the lower network. Also, we used two-layer dilated Conv + BN + ReLU and four-layer standard Conv + BN + ReLU in lower networks to obtain more contextual information. We can clearly see in
Table 1 that MLIFCNN has higher PSNR values than MLIFCNN without residual connection and dilated convolution in MIIB. Therefore, the interaction network that we improve is beneficial to denoising.
CIRB: It is a module used to enhance the stability of the training denoiser. We used a group convolution similar to the FIEB module, except for the convolution kernel sizes of 1, 5, and 7 upon grouping. As can be seen in
Table 1, MLIFCNN has a higher PSNR result than MLIFCNN without group convolutions in CIRB. From
Table 2, we can see that the setting of this parameter has a higher PRNR value. This shows that the group convolutions do enhance the denoising performance.
RB: To output the clear image that we want to predict, we use a residual operation to act as a single convolution, with the effect shown in
Figure 1.
4.4. Comparison with the State-of-the-Art Denoising Methods
In this section, in order to test denoising performance of MLIFCNN, we performed the analysis from both quantitative and qualitative perspectives. For the quantitative analysis, we compared the PSNR, running time, and complexity with many competitive denoising methods, such as: MLP [
43], CNLNet [
44], BM3D [
45], enhanced convolutional neural denoising network (ECNDNet) [
15], DnCNN [
13], TNRD [
46], FFDNet [
47], a hybrid denoising CNN (HDCNN) [
48], EPLL [
49], image restoration CNN (IRCNN) [
12], weighted nuclear norm minimization (WNNM) [
50], attention-guided CNN (ADNet) [
51], RDDCNN [
52], cascade of shrinkage fields (CSF) [
53], MemNet [
54], residual encoder decoder network (RED30) [
55], deep universal blind denoiser (DUBD) [
56], contourlet-transform-based CNN (CTCNN) [
57], adaptively tuned denoising network (ATDNet) [
58], CBM3D [
59], neat image (NI) [
60], and TID [
61]. We mainly denoise the synthetic noise images and real images. Synthetic noise images include gray and color synthetic noise images, and their noise levels include a specific value and vary from 0 to 55. Noise images with different noise levels are called blind noise images. Therefore, we performed the following comparative experiments.
To test the denoising performance of MLIFCNN on gray Gaussian synthetic noisy images, we compared PSNR with certain competitive methods on the datasets BSD68 and Set12. The experimental results are shown in
Table 3 and
Table 4. We can see from
Table 3 and
Figure 2 that our PSNR results are both the highest in the denoising levels of 15, 25, and 50. Similarly, we can see from
Table 4 that the average PSNR values are the best at the denoising levels 15 and 25, and are also better at 50.
To test the denoising performance of MLIFCNN in color Gaussian synthetic noisy image, we compared PSNR with some better methods on the dataset CBSD68, and its experimental results are shown in
Table 5. From
Figure 3, we can see that our method has a very good PSNR results on the dataset CBSD68, and that it is optimal at the noise levels of 25 and 50. Second, from
Table 5, we also find that the blind denoising PSNR value of our color images is better than the partial method under specific noise conditions. This shows that our method is very effective in color blind denoising.
Moreover, our proposed MLIFCNN is excellent on the real-world noisy image dataset CC. As shown in
Table 6, our average PSNR value is 0.51 dB higher than ADNet and 2.34 dB higher than DnCNN. This shows that our denoising method performs well in real noisy images.
We can see from
Table 7 that we selected 10 excellent methods for comparison to test the denoise run-time from noise images of different sizes (i.e., 256 × 256, 512 × 512, and 1024 × 1024). Compared to these methods, the running time is very short. Also, we tested the complexity of the model, as shown in
Table 8. We find that the parameters of our model are still relatively few.
In terms of qualitative analysis, we apply some visual figures from BSD68, Set12, and CBSD68 to present the denoising effect of different methods. We can see the visual effect of the grey image being denoised from
Figure 4 and
Figure 5. Moreover, as shown in
Figure 6, we can see the effect of the color image denoising. From these Figures, we choose a predictive image area to amplify as the observed area, and find that our method is clearer than some state-of-the-art denoising methods. In order to denoise the results more clearly in the table, we use red and blue lines to express the best and second-best PSNR values, respectively. According to the above experimental analysis, our denoising model is very efficient.
5. Conclusions
In this paper, we propose a multi-level information fusion CNN (MLIFCNN) for image denoising. MLIFCNN mainly denoises through three blocks: FIEB, MIIB, and CIRB. Specifically, FIEB uses parallel group convolution to extract wide-channel information and enhance receptive fields to adapt to more complex image backgrounds. The MIIB realizes the interaction of wide and deep information through two sub-networks, which better adapts it to the distribution of different noise levels and enhances the robustness of obtained information. The CIRB further enhances the stability of the training denoiser and improves the denoising performance by combining the size convolutional kernel and group convolution. After performing the above three blocks, RB uses a residual operation to act as a single convolution to predict and obtain clean images. Experimental results show that our proposed MLIFCNN is very effective in both quantitative and qualitative evaluation.
Although we show that the multi-level information fusion CNN method can indeed achieve image denoising well, we can also combine transformers or some heterogeneous network fusion methods in the future to further enhance the performance of real image denoising.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}