1. Introduction
Network intrusion detection systems (NIDSs) are crucial for protecting networks and users from security threats [
1,
2]. Therefore, NIDSs have been recently developed using the latest technologies such as machine learning. Accurately detecting an intrusion is a challenging task because with the exponential increase in the amount of data traffic, network intrusion attempts increase, and the types of intrusions become diverse. Therefore, a NIDS that uses deep learning (DL) was proposed [
3,
4,
5,
6,
7].
However, deep-learning-based NIDSs cannot satisfactorily perform real-time processing of large-scale received network traffic [
2,
3,
4,
5,
6,
7] due to two reasons. First, a NIDS with DL generally requires feature creation and classification of the received features, which are time-consuming processes and require considerable memory. Second, collecting sufficient packets belonging to a flow or waiting until the flow ends is a prerequisite for applying DL.
When a NIDS cannot process the incoming packets in real time, detecting network intrusions without delay becomes challenging. Consequently, a novel approach that is different from the existing DL-based NIDS is required to solve this problem. The novel approach proposed in this study has the following characteristics. The proposed method first converts the received packets directly into features using light processing. Although an accurate feature can be created through a sophisticated algorithm and statistical analysis of the received packet, this process inevitably causes delay. Therefore, in the proposed method, the packet is used as a feature value to remove the delay.
In addition, the proposed method does not require the collection of packets belonging to an entire flow; instead, intrusion detection is performed using each received packet. A flow comprises several packets; therefore, it becomes difficult to determine whether a flow is used for intrusion with only a single packet. However, despite this risk, detecting an attack using a single packet significantly reduces the amount of memory required in comparison with the existing methods. Using a single packet to detect intrusions has been used in existing NIDSs, including SNORT; however, in these NIDSs, a pattern-based approach is typically used for each packet to detect malicious traffic [
1,
2]. Recently, single-packet-based NIDSs that do not use pattern-based matching have been proposed, though most of them produce classification models trained biasedly on training datasets [
8,
9]. Such models have a limitation in that the detection accuracy is greatly reduced in a real network where hosts not included in the training dataset exist [
10,
11].
The proposed method differs from the existing single-packet-based NIDSs such that it trains a classifier using a training dataset modified to prevent biased learning and classifies each flow using a single packet as an input to the classifier. In addition, unlike the existing methods, the proposed method reflects the classification result with the highest score among the previous packets to the classification of the current packet, in order to consider not only the characteristics of a single packet but also the overall characteristics of the flow. In addition, a validation model is proposed to prevent false positives of the proposed single-packet-based classification.
The proposed method differs from existing single-packet-based NIDSs such that a single packet is used to classify flows. The method can classify each flow by considering not only the characteristics of the single packet but also the overall characteristics of the flow by reflecting the classification result for the previous packet into the classification for the current packet.
If an existing method using flow data creates a feature for the entire traffic of a flow or collects a certain amount of traffic and subsequently creates a feature using it, a large buffer should be allocated to each flow. The number of simultaneous flows quickly increases in proportion to the size of the network; therefore, the method using a large buffer per flow has considerably low scalability in terms of the total number of concurrent flows.
However, the proposed method can support several flows that cannot be processed in the existing method since it consumes only one word of memory per flow. The major contributions of this study are as follows:
Presenting a DL model for NIDSs with extremely-low feature-creation overhead.
Raw packet data are directly used as features to the classifier, and their output is reused as features for the validation classifier by combining with the packet header, eliminating feature-generation overhead;
Designing a single-packet-based classification algorithm with complexity θ(1) of memory requirement per flow.
Although existing NIDS usually requires hundreds or thousands of bytes of memory to process one flow, the proposed NIDS requires only one-word memory for each flow;
Proposing a NIDS with a high classification accuracy and a very short detection time.
By performing classification on every received packet, it has a short detection time and uses a unique validation model to maintain high classification accuracy.
The remainder of this paper is structured as follows. In
Section 2, we review previous studies. The proposed method is described in
Section 3.
Section 4 presents a comparison of the performance of the proposed method with that of existing methods. Finally, the conclusions are presented in
Section 5.
2. Existing Work
Machine learning (ML)/DL-based NIDSs have been actively studied, and various NIDSs have been proposed. The advantages and disadvantages of these ML/deep-learning-based NIDS are determined based on the features used. Therefore, in this section, ML/deep-learning-based NIDS studies are classified according to their feature characteristics, and each category is explained in detail. According to a study, the features applied to an ML/deep-learning-based NIDS can be largely classified into three types, namely flow, packet, and flow-packet hybrid features. Each type will be described in detail.
2.1. Flow Features
The flow feature quantifies the characteristics of traffic flows between each source and destination node [
12,
13]. Here, a flow is a logical group of traffic distinguished by a quintuple composed of source IP, destination IP, source port, destination port, and protocol. Therefore, all packets with the same quintuple are treated as the same flow.
Intraflow features are created from each flow data and interflow features are created from the data of flows that occur between the same source-destination node. Intraflow collects all traffic from the first packet to the last packet of each flow and subsequently creates a feature using it. Typical features include the flow duration for one flow, the total number of transmitted/received packets, and the total amount of transmitted/received traffic. Whereas the interflow feature reflects the operational characteristics of all flows occurring between the same source-destination node and includes the total number of flows occurring within a specific time, the number of failed flows, and the interflow gap.
The flow feature can effectively distinguish between intrusion detection and normal flows since it compressively expresses all flow characteristics. However, since many flow features require information regarding the entire flow traffic, considerable memory is used to collect them. To solve this problem, a method of storing simple log data for packets instead of received packets is used; however, this method also has a memory complexity of θ(P), where P is the total number of packets constituting a flow. Therefore, the NIDS has a limitation on the maximum number of flows that can be supported. Considering that the number of simultaneous flows that a single NIDS must handle increases rapidly as the network grows, this is a severe limitation.
An intrusion is detected after the intrusion is completed since most intraflow features can be created after the flow ends, even if the NIDS receives a flow attempting to infiltrate the network. For a NIDS to safely protect the network, an intrusion must be detected in real time without delay after it has occurred. However, flow-feature-based NIDS cannot perform detection in real time.
In addition to the flows between specific source and destination nodes, features can be extracted from all flows that occur between multiple source nodes and one destination node. This host-specific flow feature is highly advantageous for detecting security threats, such as DDoS, which target a specific node using many nodes. However, this feature adds more computational and memory overhead since it requires an aggregate operation for each host-specific flow. The following
Table 1 summarizes the characteristics of flow-feature-based datasets.
2.2. Packet Features
Flow features inevitably require high-overhead processes, such as collection and classification by traffic flow and feature creation [
12,
13]. However, with the development of highly sophisticated ML/DL models, the algorithms use raw traffic instead of high-quality features through a complex process that has been developed [
2]. In this case, the system structure is considerably simpler than that of the flow features since the DL model automatically generates excellent features from low traffic and performs training and classification. In particular, packet features effectively reflect patterns for intrusion detection in the packets; therefore, they are advantageous for deep packet inspection.
The process of creating features from raw traffic involves removing fields that can create bias, such as the source and destination IPs, dividing the remaining data into bytes or words, and mapping each value to one feature. In this case, when one-hot encoding is applied to each byte value, it may be mapped to a plurality of features; however, the number of features increases, and the time required to create features also increases.
A packet feature is not generated from a single packet, but by receiving and combining multiple packets belonging to the same flow, which is similar to a flow feature. Determining whether a flow is malicious through a single packet results in low reliability because a single packet reflects only a minute portion of the characteristics of the entire flow. Therefore, traffic of a certain number or size should be collected from the beginning of the flow, through which the DL model is learned and the received packet is classified. Therefore, a buffer is required for traffic collection, which is generally “flow total traffic size ≫ buffer size ≫ total flow feature size.” Consequently, since a buffer is allocated to each current active flow, a large amount of memory is consumed. Memory usage can be reduced by reducing the amount of traffic to be collected per flow; however, this reduction may result in lower intrusion detection accuracy, rendering circumvention by an attacker and allowing a successful attack. Furthermore, since intrusion is determined based on a single flow, the detection accuracy may be low in distributed attacks, such as DDoS attacks, in which attack patterns are revealed from the perspective of interflow.
Recently, research on detecting intrusion with only single packet data have been proposed. However, most of them use unmodified training datasets that include host and flow-dependent fields such as source IP, destination IP, source port, and destination port to train the classifier model [
8,
9]. In this case, the classifier learns the attacker’s or victim’s IP or port number as an important feature rather than the distinctive characteristics of intrusions from the packet data. The classifier trained in this way shows very-high detection accuracy for the test dataset built on the same network as the training dataset even with a single packet. However, such classifiers are highly inaccurate to detect intrusions in real networks where the attacker’s or victim’s IP or port number cannot be known in advance [
10,
11].
Unlike the flow feature, in the packet feature, traffic for the entire flow is not used, but only a portion of it; therefore, intrusion can be detected faster than NIDS using the flow feature by performing detection before the flow ends [
2]. However, collecting traffic for the same flow can reduce the efficiency of parallel packet processing. With the increase in the amount of traffic, a parallel processing structure is used in most networks or network security systems to process packets in the lower layer at high speed. However, traffic collection for the same flow in a parallel processing system generates considerable data for transmission and reception for traffic synchronization between parallel devices. This overhead can be maximized in an environment with multiple interfaces. Therefore, the method is not optimized for a modern distributed network traffic-processing method since the flow dependency of traffic to support the parallel processing for flows cannot be completely removed.
2.3. Hybrid Features
Hybrid features are created by including both the flow and packet features [
17]. Although this method has the highest overhead in generating features, it simultaneously considers the characteristics of the entire flow through the flow feature and the pattern through the packet feature to obtain a higher detection performance than a NIDS using a single-feature set. However, intrusion detection is possible only when the flow is terminated due to the limitations of the flow feature. Thus, real-time detection cannot be supported, and applying the parallel processing method is critical. Compared with flow features or packets, limited studies have focused on hybrid features.
Table 2 presents the results of a comparative analysis of research results for each feature.
Recently, many studies have been proposed to solve the limitations of existing NIDS by applying various technologies in addition to research on features.
Table 3 shows each characteristic of studies applying the latest technologies such as fused machine learning, blockchain, and MapReduce [
18,
19,
20].
3. Proposed Algorithm
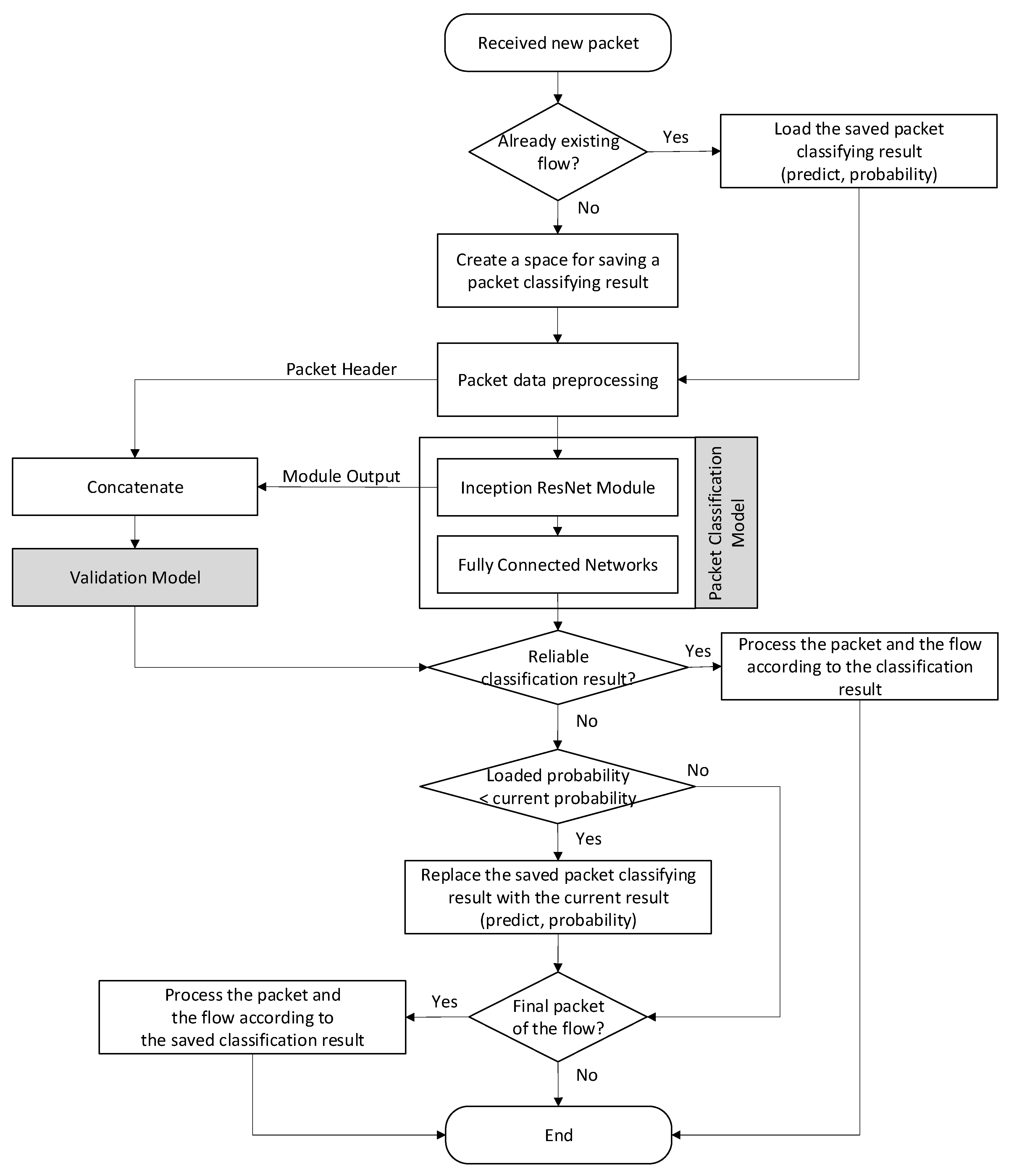
In the proposed method, packet data are used as a feature to determine the network intrusion whenever a single packet is received. Detecting network intrusions using a single packet is extremely difficult and the detection reliability is low. Therefore, each detection result was verified, and if the result was unreliable, the detection was attempted again when the next packet of the same flow was received. The previous detection result was included as an additional input feature when classifying the next packet. However, using considerable memory to store existing detection results is a great burden for increasing the number of concurrent NIDS flows. Therefore, the existing detection results are stored with minimal information, enabling large-capacity concurrent-flow processing.
Figure 1 illustrates the overall structure of the proposed model, which determines whether a single packet is malicious by using a packet classifier composed of an Inception response and a fully connected network (FCN). In general, a NIDS creates flow entries matched for each currently active flow, to collect information about the flow and applies policies to the flow. The proposed method extends the flow entry to store the intermediate classification result, i.e., class ID and score. Whenever the NIDS receives a new packet, it searches for a matching flow entry. If found, it indicates that the packet belongs to an existing flow. On the other hand, if the search fails, a new entry is created to process a new flow.
In the proposed method, whenever a packet is received, the previous classification results in the flow entry and packet data are combined into the input of the packet classifier called the Inception-ResNet classifier. The output of Inception-ResNet and the packet header are combined into the input to another classifier called the validation model. The output of Inception-ResNet is again given as an input to the FCN and the classification result is obtained. If the output of the validation model is that the classification result is reliable, the result is stored in the flow entry as the final classification result.
On the other hand, if the output is that it is unreliable, and the current classification score is higher than the score stored in the entry, the stored result is updated with the current one. If every output of the validation model is that it is unreliable until the flow ends, the terminated flow is classified as the class stored in the entry.
When determining the network intrusion for an entire flow with only one packet, a high probability of misclassifying the packet exists owing to the lack of flow information. In the proposed method, three strategies are used to compensate for this weakness. Now, each strategy used in the proposed method will be described in detail.
First, only the class and probability values among the classification results of the packets prior to the currently received packet are stored, and this classification class is used as an additional feature to classify the current packet. This phenomenon improves the accuracy when determining a flow with only a single packet. Moreover, in this method, only the classification class and probability value are stored for one flow with considerable memory saved compared with the method of storing existing packet data or the entire classification result with a large dimension. Only approximately 40 MB of memory is required to support 10 M concurrent flows due to the additional usage of approximately four bytes per flow. Therefore, the total memory size required to classify one flow is the sum of four bytes from the flow entry and the packet-buffer size to store the current received packet.
Second, the proposed method verifies the reliability of the classification results of the received packet using a validation model, which is implemented as a one-class model and determines whether to trust the classification results. If the validation model is determined to be trustworthy, the received packet and corresponding flow are processed according to the results of the packet-classification model. However, if the validation model determines the result is unreliable, then the result of the packet-classification model is stored for the classification of the next packet, and the received packet is forwarded.
Finally, in the proposed method, all received packets are classified through a packet classifier and validation model; however, even the last packet of a flow can be determined as unreliable by the validation model. In this case, the classification result with the highest probability for all packets was selected as the final result. Classification failure is avoided by selecting the class with the highest probability among unreliable results. Therefore, if the validation model determines that the classification result for the currently received packet is unreliable, the probability value of the previously stored classification result is compared with that of the current result. The previously stored classification result is updated as the current classification result only when the current probability value is high. Each module of the proposed method is described in detail. Algorithm 1 shows how the proposed method classifies a flow for packets belonging to a flow. It sequentially shows how the Inception-ResNet classifier uses each packet and preclassified class as input features, validates the classifier’s results with DeepSVDD, and finally returns the validated classification result or the classification result with the highest score for the flow. Each module of the proposed method is further described in detail.
| Algorithm 1: Proposed Flow Classification |
Input: Packets belonging to a flow,
Output: Class ID for the flow,
|
1 stored_ = 0
2 stored_
= Null
3 For i = 1 to n
4
5
6 If > Threshold
7 Return
8 EndIf
9 If
10 stored_
11 stored_
12 EndIf
13 EndFor
14 Return |
3.1. Packet-Classification Model
The packet-classification model consists of a stem block, Inception-ResNet module, reduction module, and FCN. The Inception-ResNet v1 model has a small number of parameters and is suitable for NIDS since it has high accuracy and improved learning speed compared with existing inception models [
21]. In the Inception-ResNet module, convolutional filters of various sizes are combined with residual connections. Such connections not only improve the structure-induced performance degradation of DL but also reduce the overall training time. The following figure details the structure of the packet-classification model.
As displayed in
Figure 2, the Inception-ResNet module consists of A, B, and C, and the reduction module consists of A and B. Inception-ResNet modules A and C were connected in a three-unit structure, whereas modules B and B were connected in a five-unit structure. The reduction module was placed between the Inception-ResNet modules to reduce the data dimension. Each module of the packet-classification model is described in detail.
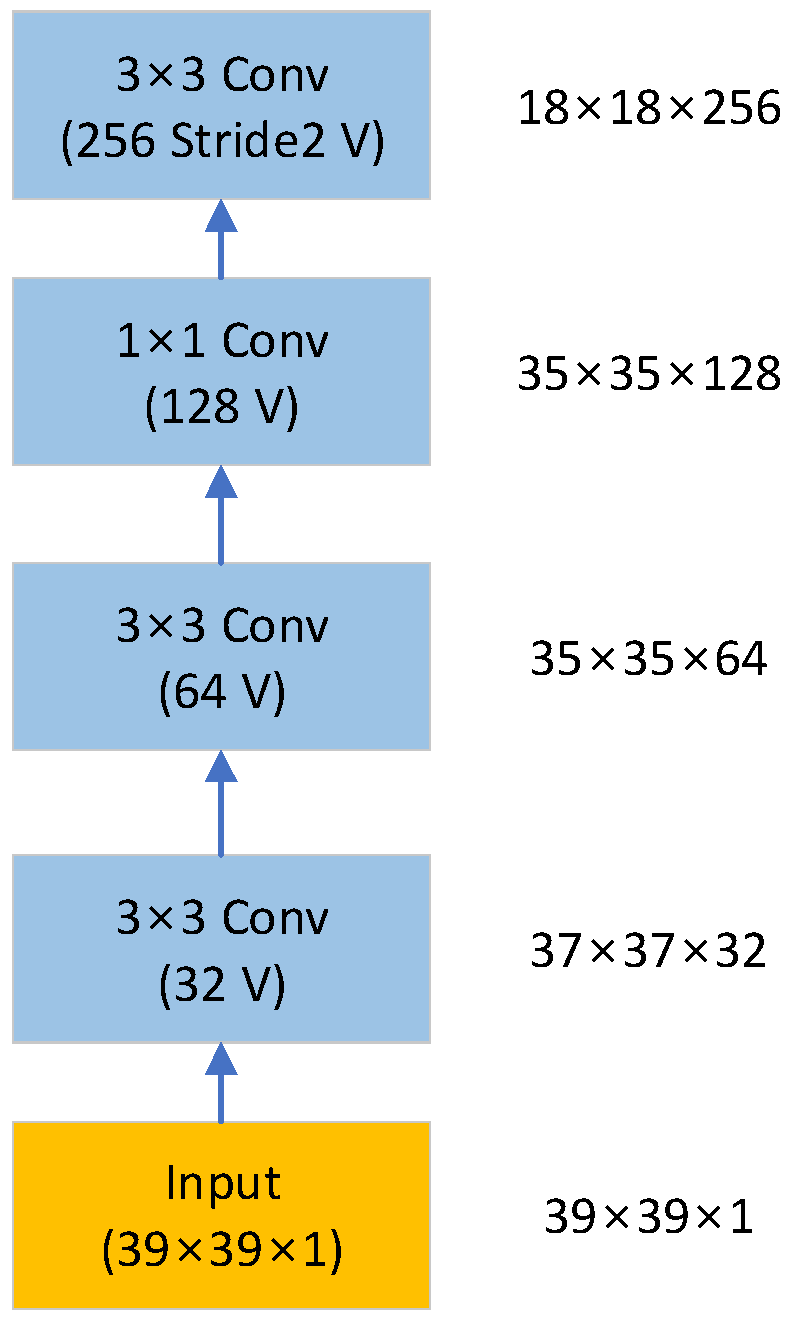
3.1.1. Stem Block
As displayed in
Figure 3, the stem block is the data-input part of the model and receives 39
39
1-dimension data. By contrast, the output of the stem block is in the form of 18
18
256. A block comprises four 2D convolution layers, all of which use ReLU as the activation function. The stride is set to two in the last convolution layer, which is the output part of the stem block, and to one layer in the other layers.
Figure 3 displays the structure of the entire layer. The right-hand side of the figure shows the output data dimensions of each layer. All convolution layers of the stem block set the padding option to be valid (V).
3.1.2. Inception-ResNet Module and Reduction Module
As displayed in
Figure 2, three Inception-ResNet modules exist in the proposed packet-classification model. All Inception-ResNet A modules had the same input and output data types. The reduction module is connected to the Inception-ResNet module and reduces the data dimension.
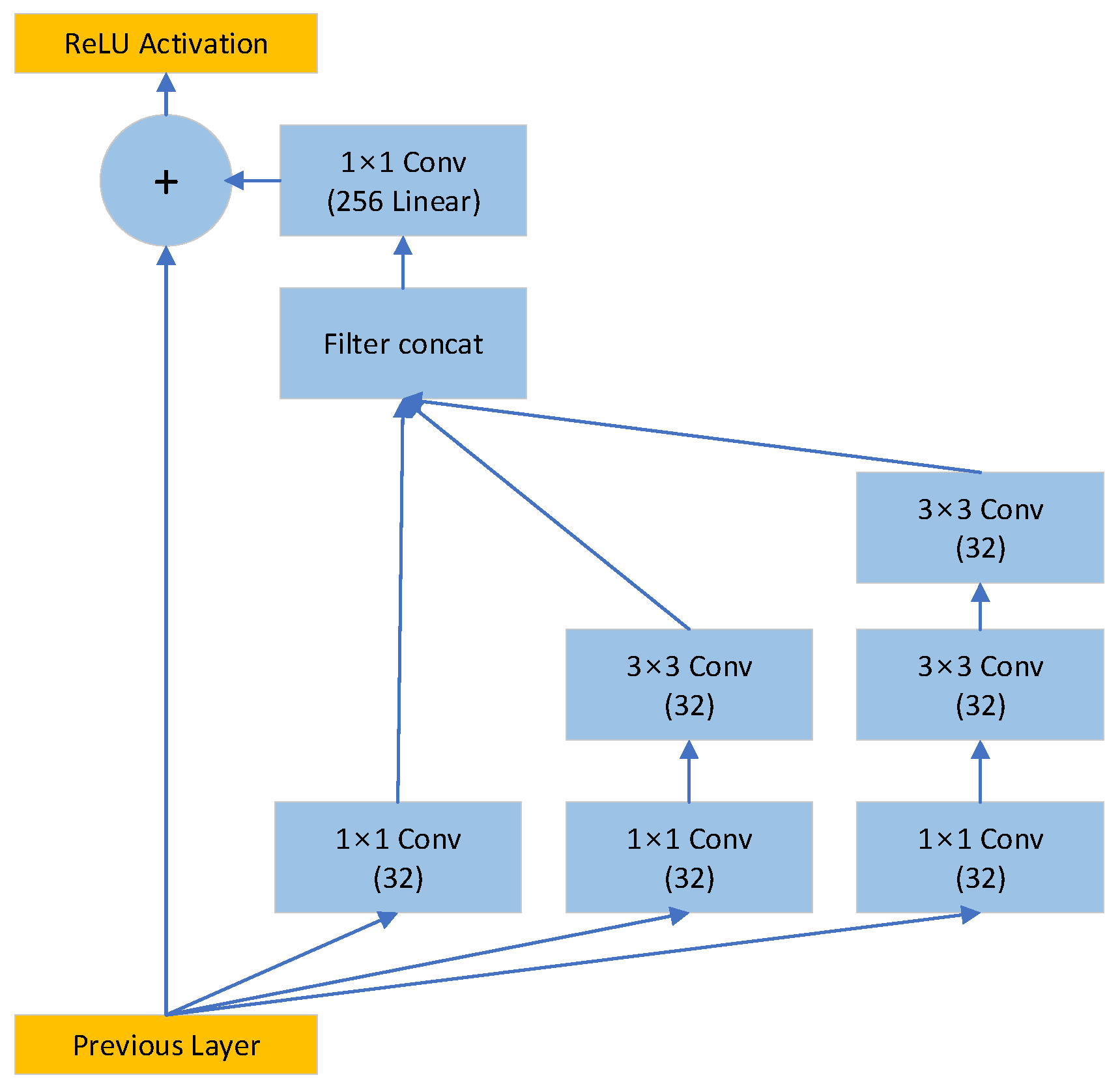
3.1.3. Inception-ResNet A
The Inception-ResNet A module uses the stem output in the packet-classification model as the input (referred to as
). Therefore, both the input and output of module A have dimensions of 18
18
256. The input of the Inception-ResNet A module was replicated into three types of convolutional hidden layers and used as input values. The three output values were used as inputs to the convolution layer without an activation function after passing through the concatenate layer. The output value of this convolutional layer performed an additional operation with the first input value of the module. The final result of the module was the value obtained by applying the ReLU function to the result of the addition operation [
22]. All three types of convolutional hidden layers in the module use ReLU as an activation function and the same option for padding. In this study, three Inception-ResNet modules were stacked and used.
Figure 4 displays the structure of the module.
Let us say that the input of the module is , and the output is . The outputs of the three hidden layers are expressed as follows:
,
,
The ReLU activation function was applied to the convolution layers of
,
, and
. If the output of the convolution layer without an activation function is
, then it is defined as follows:
Finally,
is formulated as follows:
3.1.4. Reduction A
The Reduction A module is connected to the output after repeating the Inception-ResNet A module three times, which reduces the form of the data from 18
18, the output form of Inception-ResNet A, to 8
8. Inside the module, the input data are duplicated and transmitted to three types of hidden layers, and the output of each hidden layer is merged and output through the concatenated layer. As displayed in
Figure 5, the input shape was 18
18
256, and the output shape was 8
8
896.
Let us assume that the module input is and the module output is . The hidden layers are expressed as follows:
,
,
The output of Reduction A is expressed as follows:
3.1.5. Inception-ResNet B
The Inception-ResNet B module provides the output of the Reduction A module as the input in the packet-classification model. Therefore, the input and output of module B had the same 8
8
896 shape. The input of the Inception-ResNet B module was replicated into two types of convolutional hidden layers and used as input values. Subsequently, the two output values were used as the input values of the convolutional layer without an activation function after passing through the concatenate layer, and the output values become the input values of the module and the addition operation. The result of the module was the value obtained by applying the ReLU activation function to the result of the addition operation. In all three types of convolutional hidden layers in the module. ReLU was used as an activation function and the same option for padding. Five Inception-ResNet B modules were stacked and used.
Figure 6 illustrates the structure of the module.
3.1.6. Reduction B Module
The Reduction B module is connected to the output after repeating the Inception-ResNet B module five times and reduces the output of Inception-ResNet B from 8
8 to 3
3. Inside the module, input data are duplicated and transmitted to four types of hidden layers, and the output of each hidden layer is merged and output through the concatenate layer. As displayed in
Figure 7, the input and output shapes of the module were 8
8
896 and 3
3
1792, respectively.
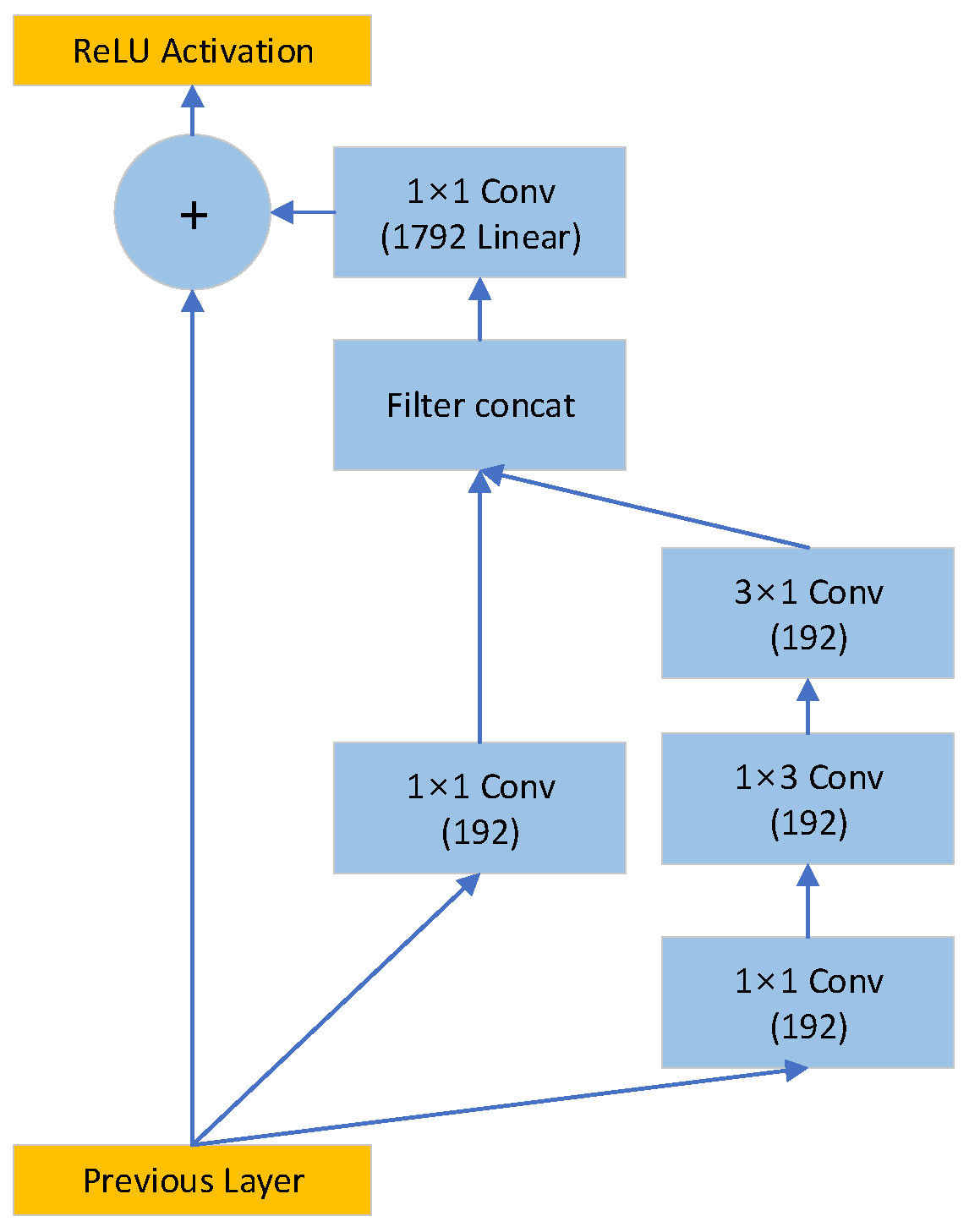
3.1.7. Inception-ResNet C Module
In the Inception-ResNet C module, the output of the reduction module is used as the input to the packet-classification model. Therefore, the input and output of module C had the same shape of 3
3
1792. The input of the Inception-ResNet C module was replicated with two types of convolutional hidden layers and used as input values. The two output values were used as input values for the convolution layer without an activation function after passing through the concatenated layer. The output values of the entire module were added to the input values of the module. The final result of the module is the value of applying the ReLU activation function after addition. All four types of convolutional hidden layers in the module used ReLU as an activation function as well as the same option for padding. Three Inception-ResNet C modules were stacked and used.
Figure 8 illustrates the overall structure. In the convolution layer, the ReLU activation function was used, whereas the convolution layer, after the filter concat layer, did not use the activation function.
3.1.8. FCN Block
The FCN block was in the output part of the packet-classification model. After Inception-ResNet C, the shape of the input data, 3
3
1792, was converted to 1792 using the global average pooling layer before the data was delivered to the FCNs as shown in
Figure 9 [
23]. After passing through the four dense layers after the pooling layer, the result revealed whether the current packet is normal or malicious. The internal dropout rate was 20%, and the dense layer used the ReLU activation function and had as many outputs as the number of labels in the classification dataset. Finally, the Softmax activation function was used [
24].
3.2. Validation Model
The validation model determines the reliability of the result of the packet-classification model and determines whether to classify the corresponding flow according to the classification result of the current packet or postpone the classification until the next packet is received. Specifically, the validation model assists the packet classifier in classifying a flow with high accuracy by deferring classification to early packets that are likely to be misjudged.
In the proposed method, the validation model is implemented using DeepSVDD, a DL-based one-class classifier [
25]. When DeepSVDD is trained with data consisting of one class, DeepSVDD’s DNN is trained such that the data are mapped as close to the central point of the hypersphere as possible. Therefore, data other than those in the learned class tended to be outside the hypersphere. Using these characteristics, the proposed method determines whether the classified result from the packet classifier is reliable by learning DeepSVDD using packets misclassified by the packet-classification model.
The input data of DeepSVDD have a total size of 1822 bytes by adding the Inception output value (1792 bytes) of the packet-classification model and the header (30 bytes) of the current packet.
where the current packet is
and the Inception output value is
(
).
Figure 10 illustrates the detailed DNN structure of DeepSVDD [
26].
After the packet-classification model completes learning, it classifies the training data and generates training data for verification (), which comprises misclassified data. The radius of the hypersphere is selected such that the validation model that has learned the validation model with this training data has the highest F1-score.
4. Performance Evaluation
To analyze the performance of the proposed method in detail, two datasets, namely CIC-IDS2017 and CSE-IDS2018, were used and compared with existing algorithms in terms of memory usage, detection accuracy, and detection time [
27]. In the conventional method, the rotation forest, which is a representative of the ML algorithm, along with DNN and CNN, which are the most well-known DL models, were selected [
28,
29]. We will describe the experimental environment and show the comparison results for the performance of each algorithm in terms of memory requirement, detection accuracy, and detection time.
4.1. Evaluation Environment
The number of flows and packets for each dataset are shown in
Table 4 and
Table 5. Source IP, destination IP, source port, and destination port fields were removed to avoid generating biased trained models from all datasets. For each dataset, training, validation, and test datasets were created at a ratio of 6:2:2 to evaluate the performance. We only show the results for test datasets due to the similarity between each result, and we will show other results when needed. The packets stored in the packet capture file included in each dataset were classified into each flow according to the quintuple using CICFlowmeter, and all packets belonging to the same flow were assigned the same label as that of the flow [
30].
The detailed learning method for the proposed model is as follows: the cross-entropy loss model is used in the packet-classification model, and the ReduceLROnPlateau callback function is used to dynamically adjust the learning rate. The learning rate starts from , and if the learning accuracy does not improve, it decreases by 0.1 to . ADAM was used as the optimization function for learning, and the batch size was set to 256. In the validation model, the batch size was set to 256, which was the same as that of the packet-classification model, and the learning rate was set to . The validation model also used ADAM as the optimization function.
4.2. Memory Requirements
Since the existing method creates a feature for a flow after storing all packets, a space equal to the total traffic of the flow per flow is used. However, the proposed method requires only four bytes to store the class and probability information to be used when classification fails for all packets as well as memory to process the currently received packet. Therefore, the memory required per flow is equal to the size of the largest packet in the flow.
Figure 11 and
Figure 12 display the memory usage of the proposed method and the existing method according to the flow length.
In
Figure 11, the existing method consumes 351 bytes on average for entire flow lengths, while the proposed method requires only 80 bytes on average for the CIC-IDS2017 dataset. In
Figure 12, the existing and proposed methods consume 450 bytes and 103 bytes on average, respectively, for CSE-CIC-IDS2018. Therefore, we can conclude that our approach reduces the memory requirement by 77% on average.
As displayed in
Figure 11 and
Figure 12, the average amount of memory used according to the flow length tends to increase overall in the case of the existing algorithms. However, the proposed method does not exceed a certain size because the maximum memory requirement per flow is the largest single packet size within the flow. The amount of memory required to process one flow is critical for processing numerous concurrent flows. Therefore, the proposed method is advantageous for processing large-capacity concurrent flows since it can support the same concurrent flows with less memory.
In addition, the proposed method is advantageous for parallel processing. In a parallel-processing-based NIDS, where several proposed classifiers run on different processors, we assume that one classifier processes one received packet, and the classifier requires a classification result for the previous packet. The synchronization of the classification result of the previous packet is required between processors, and the overhead is small since the amount of data to be synchronized in the proposed method is as small as one word. Therefore, unlike other existing methods, the proposed method has excellent scalability since it is optimized for parallel processing.
4.3. Detection Rate
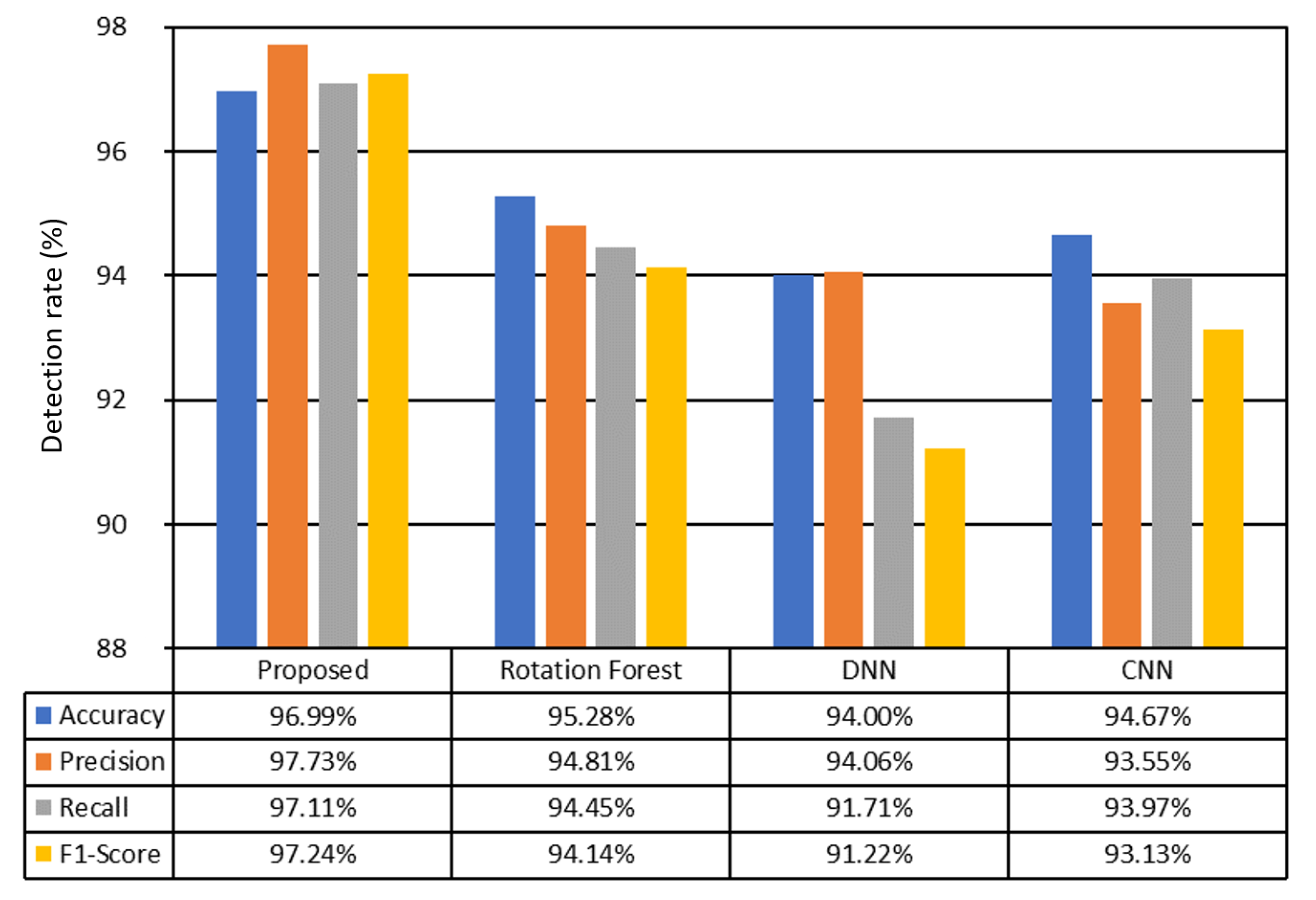
Figure 13 shows the average classification accuracy for the learning, validation, and test datasets when using CIC-IDS2017 and CSE-CIC-IDS2018. All NIDSs provide similar performance for the three datasets, indicating that all classifiers used in the performance evaluation are well trained. In addition, it is confirmed that the proposed method can provide very stable and high detection performance by showing the highest accuracy regardless of the type of dataset.
Detecting intrusions using packet features is more challenging than detecting intrusions using flow features. Moreover, achieving a high detection performance is difficult compared with the conventional method that detects intrusion using all packets in a flow since the proposed method detects intrusion for each received packet. Nevertheless,
Figure 14 and
Figure 15 reveal that the proposed method achieves an equivalent or higher detection accuracy than the existing methods. In particular, CSE-CIC-IDS2018 achieved the highest F1 score with a large performance difference. Therefore, on average as shown in
Figure 16, an F1-score that is at least 1.5
higher than those of the existing three methods, namely rotation forest, DNN, and CNN, was achieved. This result indicated that the proposed Inception-ResNet-based packet classification and validation models are effective for intrusion detection.
4.4. Detection Time
Because the detection time is a value that depends on interpacket arrival time, this parameter is not suitable for performance comparison. For example, suppose an intrusion is detected 10 s after the flow starts. If the interpacket arrival time of the flow is reduced in half, the flow will be detected in 5 s.
Therefore, in this experiment, the number of packets received until classifying the flow was compared as a new metric for the detection time. Let us call the metric average packet count. Since the average packet count is independent of the interpacket arrival time, it is more advantageous to compare and analyze detection times. The smaller average packet count means that the NIDS has a shorter detection time.
Figure 17 and
Figure 18 detail the detection times of the existing flow-based method and the proposed method for each class. With the exception of a few classes, the proposed method can detect most intrusions using only three or fewer packets. In the case of the SSH-Patator of CIC-IDS2017, the proposed method detects 12 times faster than the existing flow-based methods. Furthermore, the proposed method detected BruteForce XSS 63 times faster in the CSE-CIC-IDS2018 dataset. For the entire datasets for CIC-IDS2017 and CSE-CIC-IDS2018, the proposed method reduces the detection time by 73% and 92% on average, respectively, compared to the existing method.
Unlike existing NIDS, the proposed method performs intrusion detection on every incoming packet, which improves detection time. However, flow classification based on a single packet is prone to false detection since the amount of information used for classification is insufficient. To solve this problem, the proposed method uses the classification result of the previous packet to classify the current packet and verify the classification result again to prevent accuracy degradation. Considering that the proposed method shows a detection rate almost similar to that of the rotation forest in previous experiments, the proposed approach has a strong advantage in detecting intrusions without delay, avoiding sacrificing the detection rate.
5. Conclusions
Detecting intrusions in every received packet and simultaneously minimizing the amount of memory required to process each flow are critical to detect an intrusion in real time in NIDSs. Although studies have been conducted on improving the detection accuracy of the existing ML-based NIDS, few studies have focused on the short detection time, or the amount of memory, required for detection. Therefore, in this study, we proposed a DL-based NIDS that supports fast detection and minimizes memory requirements. The proposed method has the same or higher detection accuracy than existing methods. Furthermore, the proposed method can protect the network since it has a very-short detection time that simultaneously detects intrusions within three packets on average. Furthermore, existing flow-based NIDSs require a large amount of memory to store packet data, whereas the proposed method requires only one-word memory to store information on past traffic. Moreover, the proposed method can significantly increase the maximum number of simultaneous flows handled by one NIDS since the memory requirement for each flow is constant, regardless of the length of the flow. As the network size and number of users increase, the NIDS should handle more traffic and concurrent flows. Additionally, with the emergence of various security attacks, more sophisticated and complex classifiers are required for fast and accurate intrusion detection. Parallel processing is essential in the NIDS to support such high performance. The proposed method is suitable for parallel processing with a low synchronization overhead. Therefore, this study can resolve the technical problems associated with NIDSs.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}