
Learning Peer Recommendation Based on Weighted Heterogeneous Information Networks on Online Learning Platforms


Abstract
:1. Introduction
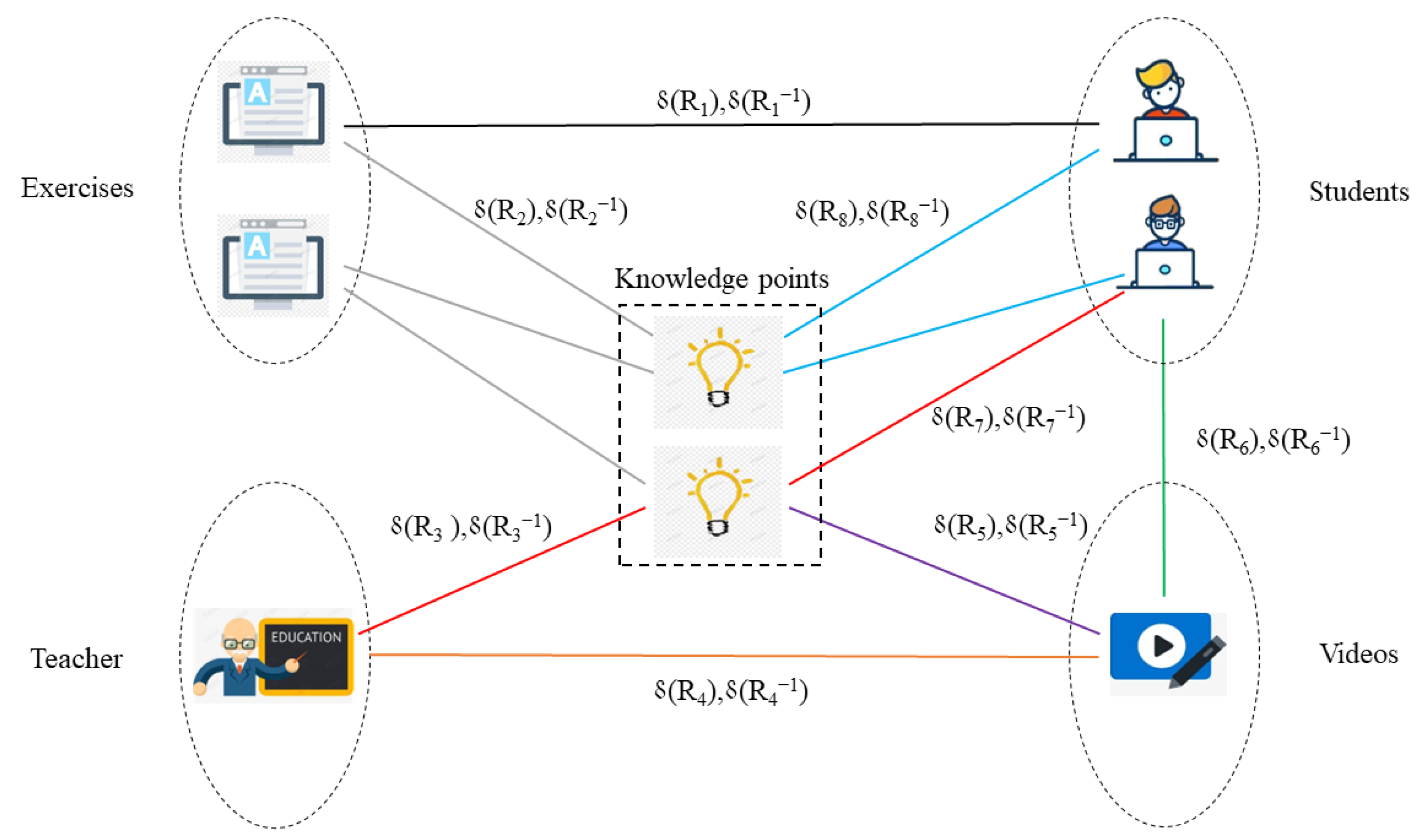
- We construct a weighted heterogeneous information network to retain semantic, structural, and attribute information more comprehensively, which consists of multiple types of objects (e.g., students, teachers, videos, exercises, and knowledge points), relationships between objects (e.g., students-knowledge points, students-videos, and students-exercises) and attribute values on links (e.g., the degrees of student–system interaction, the degrees of student–teacher interaction, the degrees of student–student interaction, and test scores).
- A method for automatically generating meaningful weighted meta-paths is proposed, which makes full use of network structural information to flexibly extract and then effectively identify all meaningful meta-paths for learning peer recommendations.
- The Bayesian Personalized Ranking optimization framework is employed to calculate the personalized weights of target students on selected weighted meta-paths.
2. Related Works
2.1. Content-Based Filtering and Collaborative Filtering Methods
2.2. Hybrid Recommendation Methods
2.3. Network-Based Recommendation Methods
3. Relevant Definitions
3.1. Three Types of Interaction Degrees
3.1.1. The Degree of Student–System Interaction
3.1.2. The Degree of Student–Teacher Interaction
3.1.3. The Degree of Student–Student Interaction
3.2. Weighted Heterogeneous Information Network
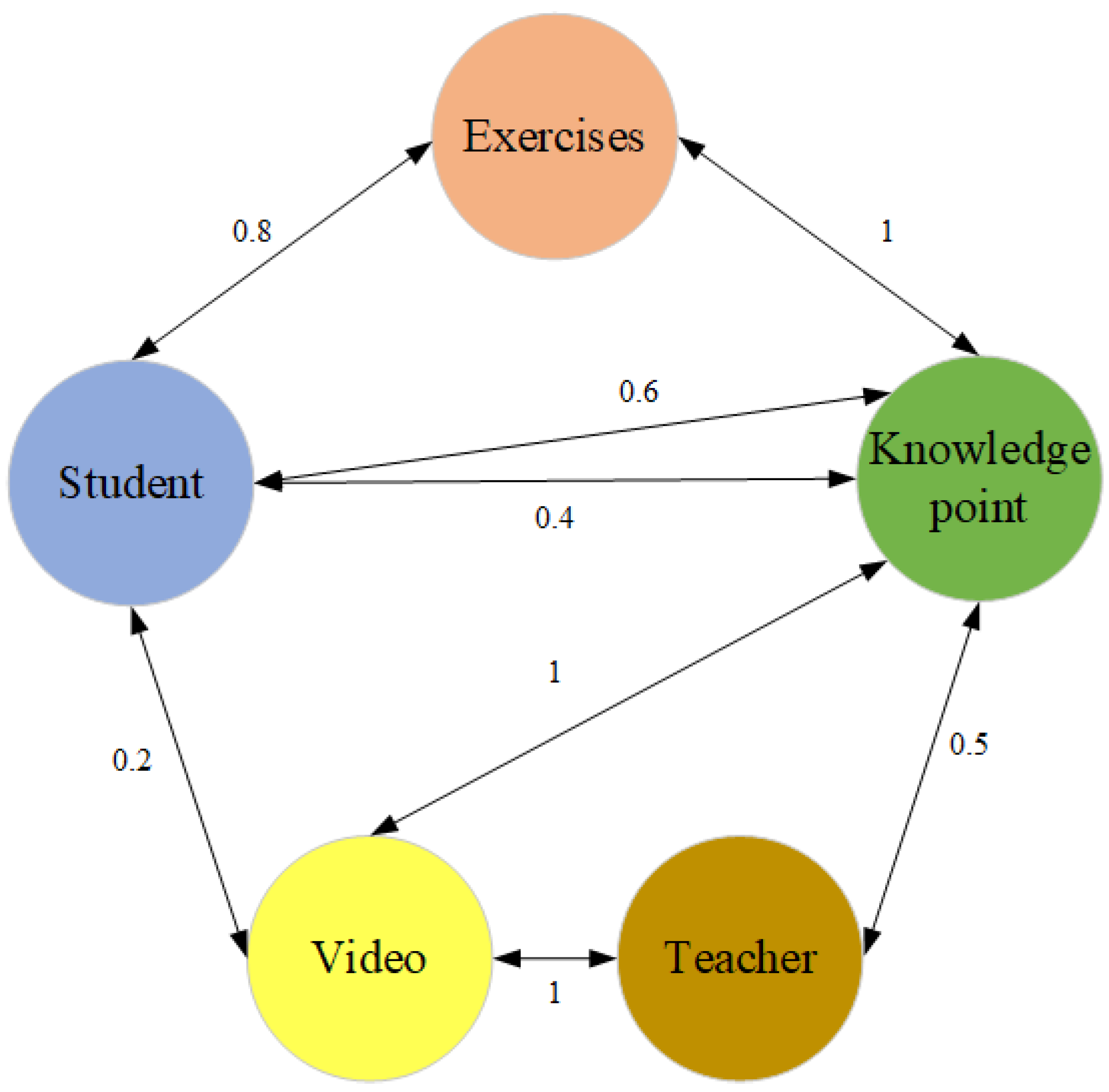
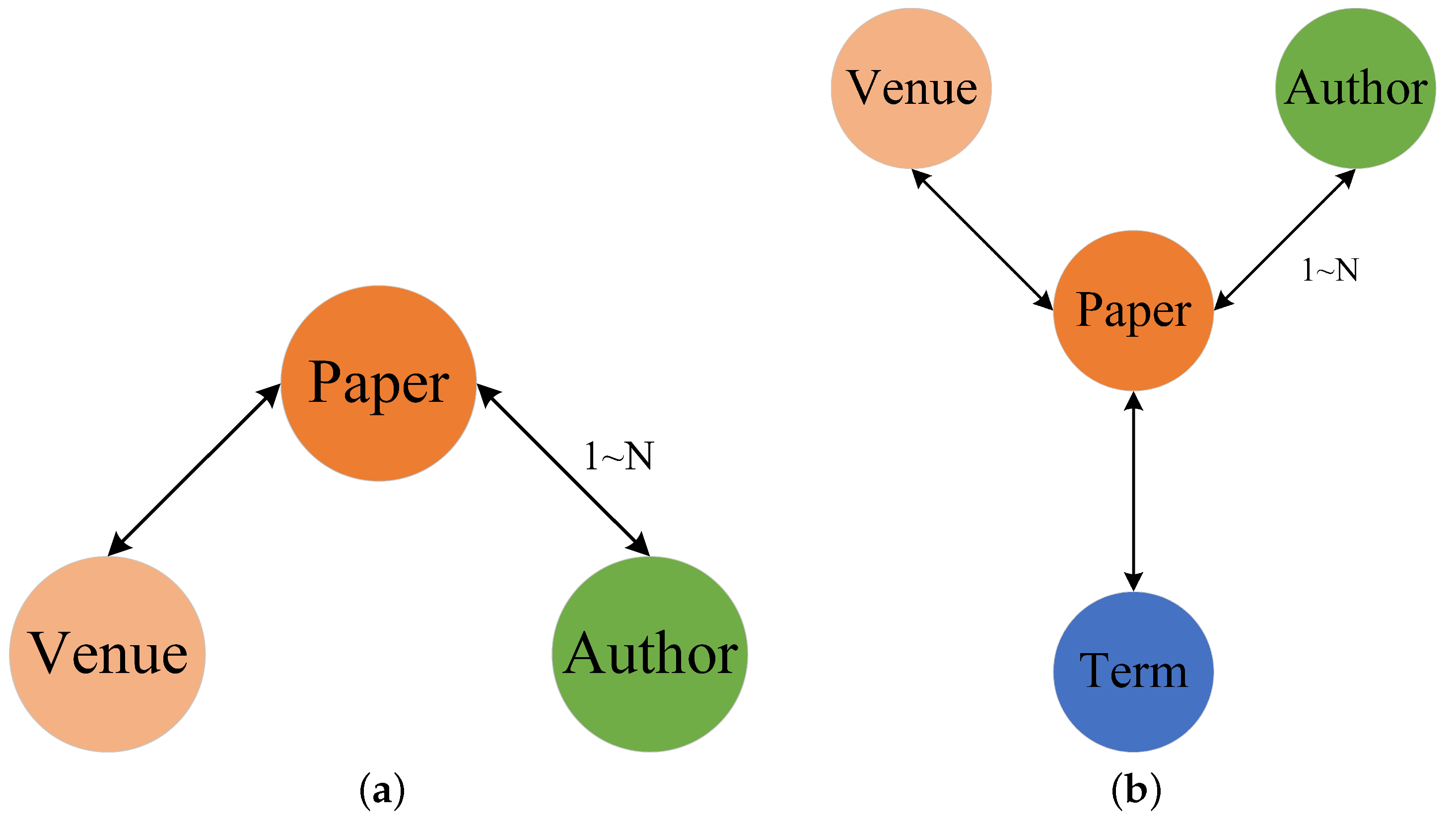
3.3. Network Schema
3.4. Weighted Meta-Path
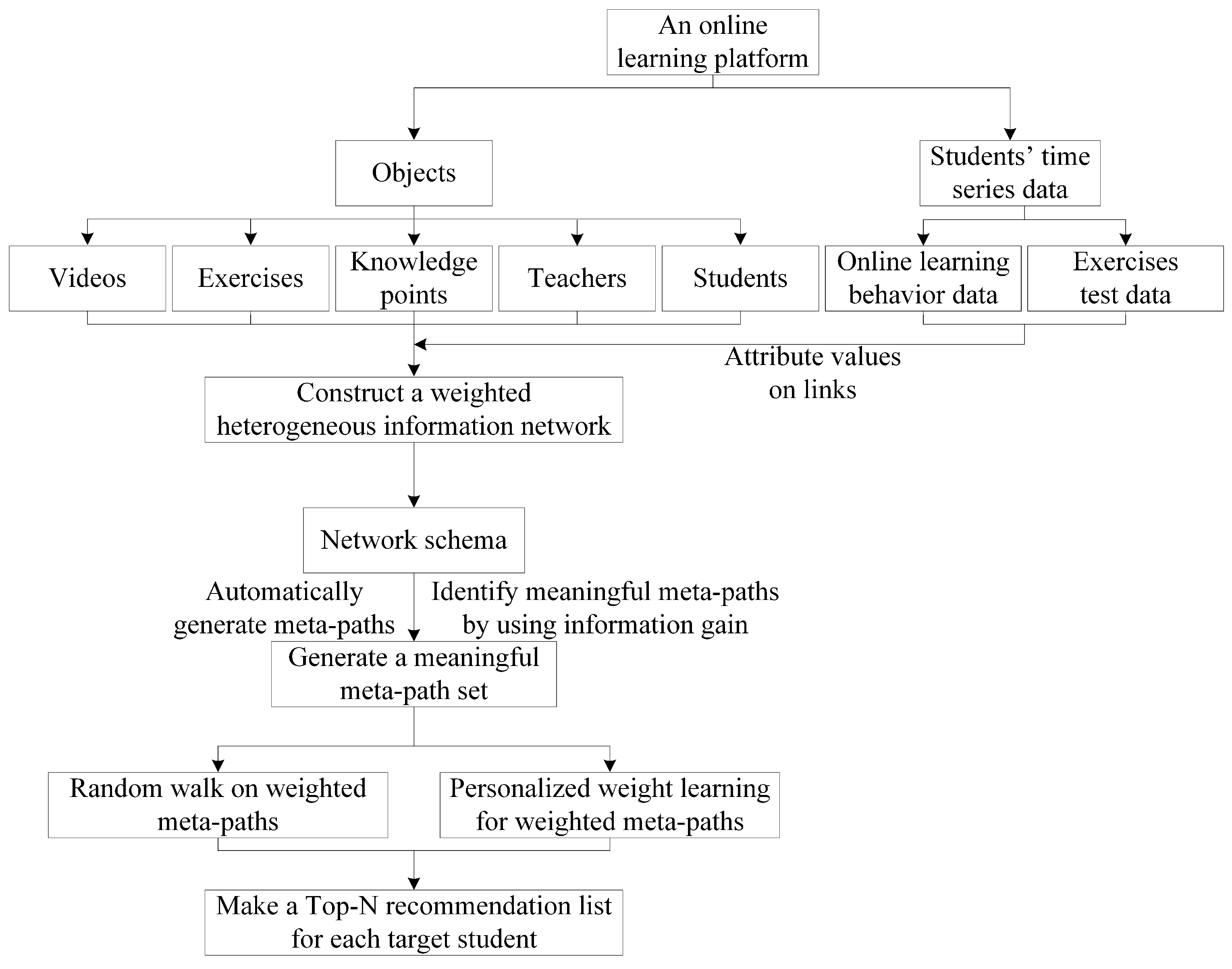
4. Proposed Methodology
4.1. Constructing a Weighted Heterogeneous Information Network
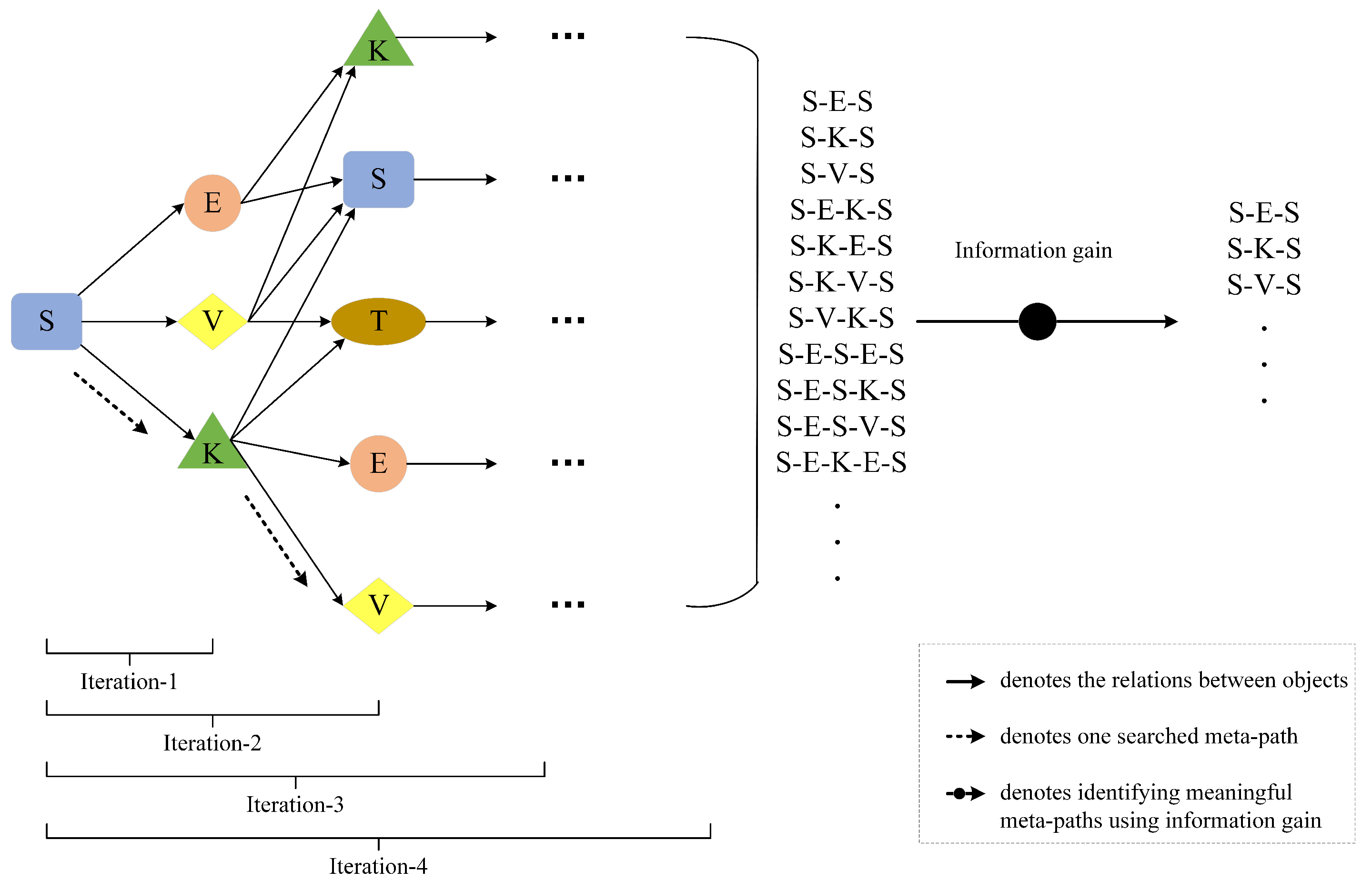
4.2. Generating a Meta-Path Set
4.2.1. Extracting Meta-Paths
4.2.2. Selecting Meaningful Meta-Paths
| Algorithm 1 Procedures of a method for automatically generating meaningful meta-paths. |
Input: =: network schema of heterogeneous information network in adjacency matrix : source object type of a meta-path, where : target object type of a meta-path, where : maximum length for meta-paths to be searched Output: = : set of meta-paths searched from in form of -*- for all do ← for to do ←() //function 1 ←(, ) //function 2 for to length() do if last element of then ∪ end if end for end for end for for to length() do Calculate using Formula (7) Calculate using Formula (6) Calculate using Formula (9) Calculate using Formula (8) Calculate using Formula (5) Calculate using Formula (10) if > 0 then end if end for |
4.3. Recommendation Score Calculation Based on Weighted Meta-Paths
4.4. Personalized Weight-Learning for Weighted Meta-Paths
| Algorithm 2 Personalized weight-learning for weighted meta-paths. |
4.5. Personalized Learning Peer Recommendation Based on Weighted Meta-Paths
5. Experiments and Results Analysis
5.1. Datasets
5.2. Evaluation Metrics
5.2.1. Precision and Recall
5.2.2. The Achievement Degree of Curriculum Objectives
5.3. Baseline Methods
- (1)
- Recommendation Based on the Meta-Path (Metapath) [14]: This method first integrates students’ historical preference information into a heterogeneous information network and generates a meta-path set. Second, the similarity between students is calculated based on the meta-path, and the regularization-based optimization method is introduced to learn the personalized weight on the meta-path.
- (2)
- Paper Recommendation Based on a Heterogeneous Information Network (PRHN) [33]: This method first constructs a heterogeneous information network containing multiple types of objects and relationships. Second, random walks are performed on each meta-path to obtain recommendation scores of candidate students, and personalized weight-learning is performed on each meta-path.
- (3)
- Matrix Factorization (MF) [46]: This model maps the interaction between students into a joint latent factor space of dimensionality f, so that the interactions between students are modeled as inner products in this space.
- (4)
- Deep Matrix Factorization (DMF) [47]: This method uses a neural network framework to project target students and candidate students to low-dimensional vectors. In the experiment, the interaction matrix between students is used as input.
5.4. Parameter Settings
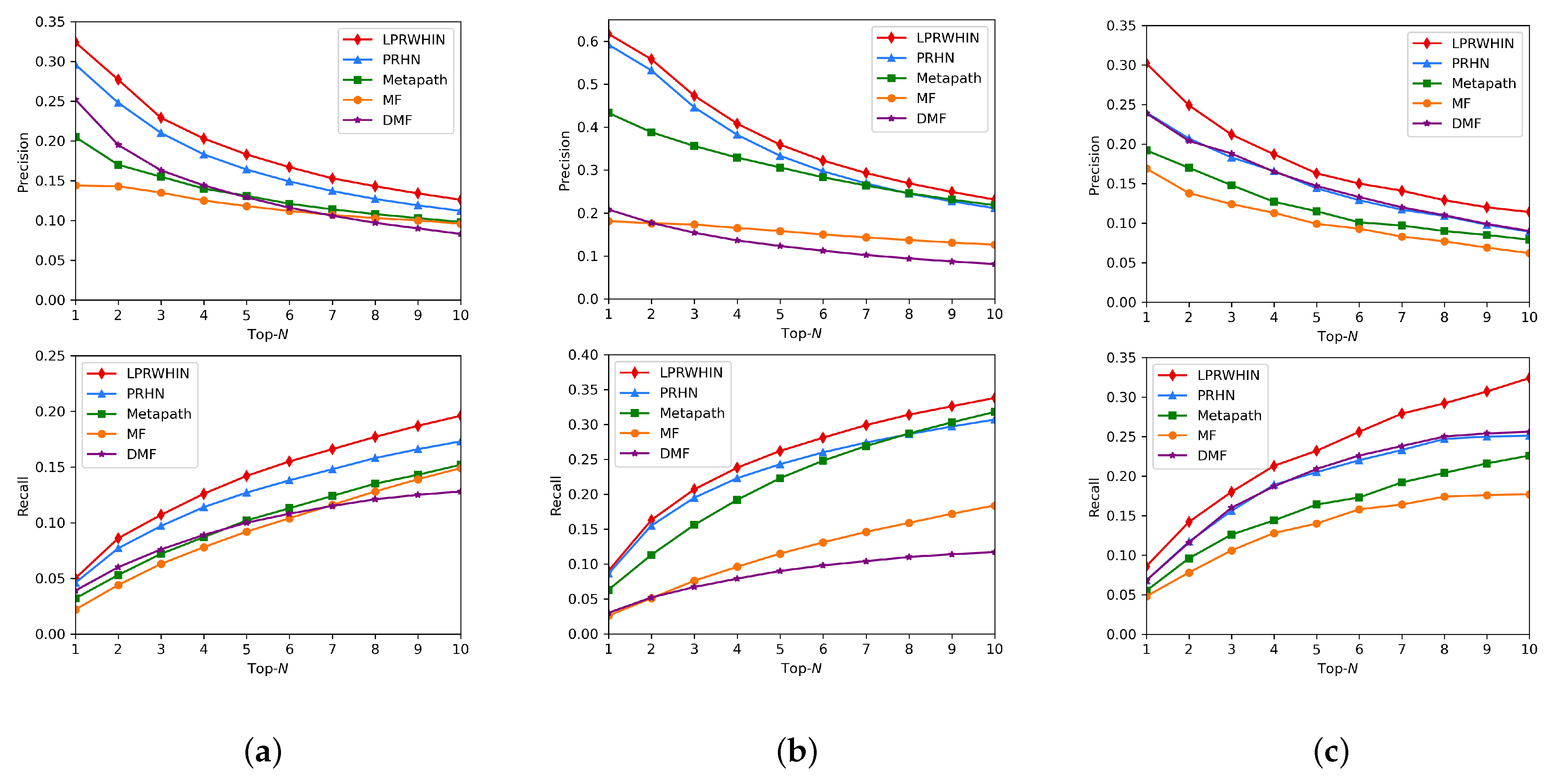
5.5. Results of Comparative Experiments
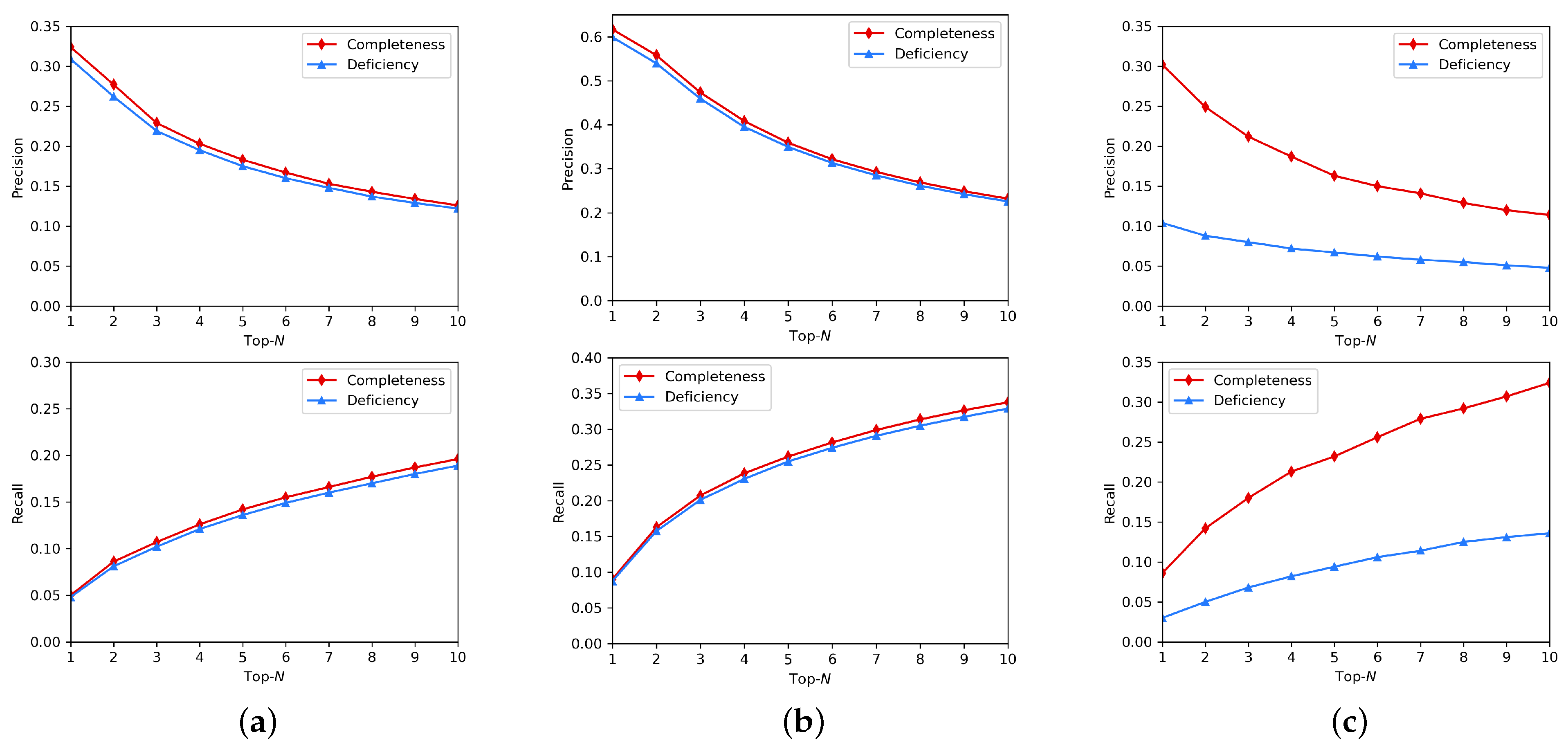
5.5.1. Impact of Different Numbers of Meaningful Meta-Paths
5.5.2. Analysis of Experimental Results
5.6. Case Study
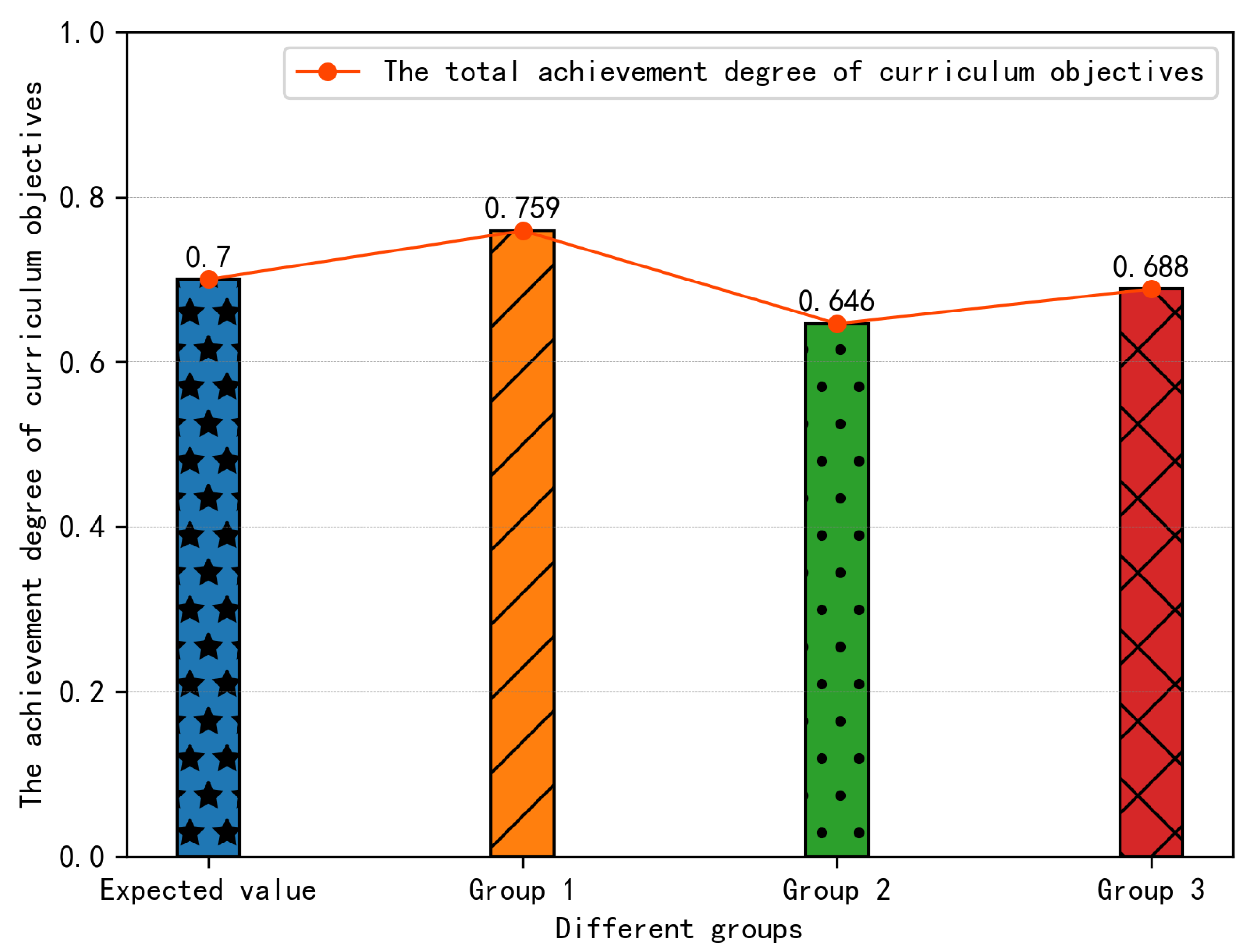
5.6.1. Comparison of the Total Achievement Degree of Curriculum Objectives
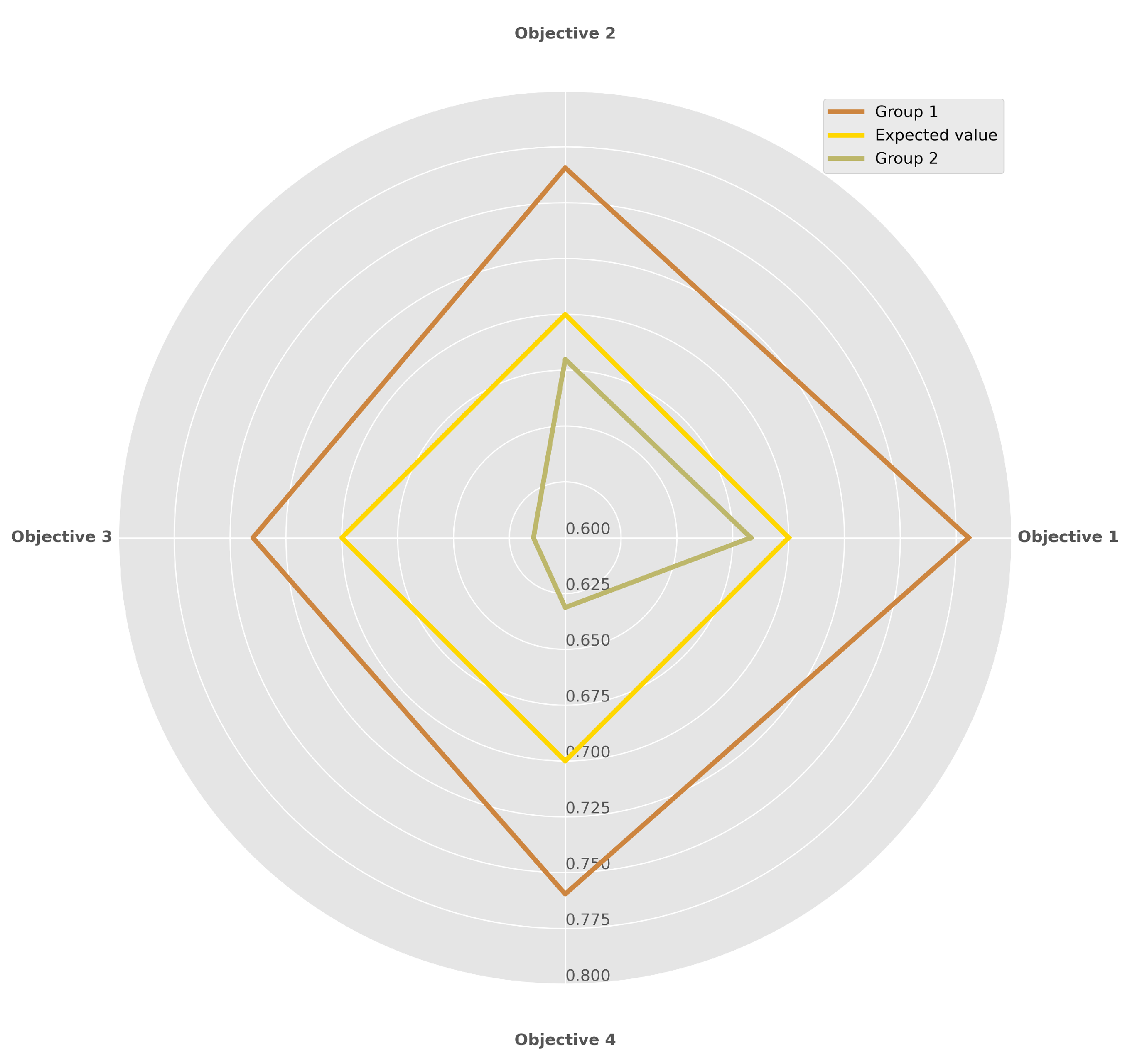
5.6.2. Comparison of the Achievement Degree of the Four Curriculum Objectives
- When some students in Group 1 encounter difficulties, there is less interaction between students and teachers, resulting in insufficient learning of the corresponding difficult knowledge points.
- Most of the students in Group 2 only have little interaction, and even many students do not complete the learning of course knowledge points.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BPR | Bayesian Personalized Ranking | An Optimization Framework is Employed to Build the Objective Function |
| COVID-19 | Corona Virus Disease 2019 | Respiratory Diseases Caused by the Corona Virus |
| LPR | Learning Peer Recommendation | A Method for Learning Peer Recommendation |
| CNN | Convolutional Neural Network | A Kind of Feedforward Neural Network with Convolution Calculation and |
| Deep Structure | ||
| RiPPLE | Open-Source Course-Level | An Online Learning Platform for Anyone |
| Recommendation Platform | ||
| LPRWHIN | Learning Peer Recommendation | Our Proposed Methodology for Learning Peer Recommendation |
| Method Based on a Weighted | ||
| Heterogeneous Information Network | ||
| MOOC | Massive Open Online Courses | Free Online Courses are Available for Anyone |
| DNN | Deep Neural Networks | A Technology in the Field of Machine Learning |
| Online | Online Learning Platform Dataset | A Dataset for Learning Peer Recommendation |
| DBLP | DBLP Dataset | A Dataset for Evaluating Performance |
| Aminer | Aminer Dataset | A Dataset for Evaluating Performance |
| TF-IDF | Term Frequency Inverse Document | A Commonly Used Weighting Technique |
| Frequency | for Information Retrieval and Data Mining | |
| Metapath | Recommendation Based on the | A Method for Scholar-Friend Recommendation |
| Meta-Path | ||
| PRHN | Paper Recommendation Based on a | A Method for Paper Recommendation |
| Heterogeneous Information Network | ||
| MF | Matrix Factorization | The Method of Decomposing a Matrix into the Products of Several Matrices |
| DMF | Deep Matrix Factorization | A Deep Matrix Factorization Model for Recommender Systems |
References
- Butnaru, G.I.; Niță, V.; Anichiti, A.; Brînză, G. The effectiveness of online education during covid 19 pandemic—A comparative analysis between the perceptions of academic students and high school students from romania. Sustainability 2021, 13, 5311. [Google Scholar] [CrossRef]
- Runtian, Z. The Game and Integration between Online Education and Traditional School Education. In Proceedings of the 2020 11th International Conference on E-Education, E-Business, E-Management, and E-Learning, Osaka, Japan, 10–12 January 2020; pp. 121–124. [Google Scholar] [CrossRef]
- Bai, Y.; Li, Z.; Zhao, F.; Jiang, Y. Strategies, methods and problems of online education in China during the epidemic. In Proceedings of the 2020 Ninth International Conference of Educational Innovation through Technology (EITT), Porto, Portugal, 13–17 December 2020; pp. 30–34. [Google Scholar] [CrossRef]
- Chang, J. Online Instruction and Offline Classroom Teaching: A Study on Parallel Education Systems. In Proceedings of the 2021 9th International Conference on Information and Education Technology (ICIET), Okayama, Japan, 7–29 March 2021; pp. 157–160. [Google Scholar] [CrossRef]
- Mrhar, K.; Douimi, O.; Abik, M. A dropout predictor system in MOOCs based on neural networks. J. Autom. Mob. Robot. Intell. Syst. 2021, 42, 72–80. [Google Scholar] [CrossRef]
- Xu, B.; Yang, D. Study partners recommendation for xMOOCs learners. Comput. Intell. Neurosci. 2015, 2015, 15. [Google Scholar] [CrossRef] [PubMed]
- Hu, Q.; Han, Z.; Lin, X.; Huang, Q.; Zhang, X. Learning peer recommendation using attention-driven CNN with interaction tripartite graph. Inf. Sci. 2019, 479, 231–249. [Google Scholar] [CrossRef]
- Bouchet, F.; Labarthe, H.; Yacef, K.; Bachelet, R. Comparing peer recommendation strategies in a MOOC. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 129–134. [Google Scholar] [CrossRef]
- Yang, D.; Wen, M.; Rose, C. Peer influence on attrition in massively open online courses. In Proceedings of the Educational data mining 2014, London, UK, 4–7 July 2014. [Google Scholar]
- Bouchet, F.; Labarthe, H.; Bachelet, R.; Yacef, K. Who wants to chat on a MOOC? Lessons from a peer recommender system. In Proceedings of the European Conference on Massive Open Online Courses, Madrid, Spain, 22–26 May 2017; Springer: Cham, Switzerland, 2017; pp. 150–159. [Google Scholar] [CrossRef]
- Potts, B.A.; Khosravi, H.; Reidsema, C.; Bakharia, A.; Belonogoff, M.; Fleming, M. Reciprocal peer recommendation for learning purposes. In Proceedings of the 8th international conference on learning analytics and knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 226–235. [Google Scholar] [CrossRef]
- Prabhakar, S.; Spanakis, G.; Zaiane, O. Reciprocal recommender system for learners in massive open online courses (MOOCs). In Proceedings of the International Conference on Web-Based Learning, Cape Town, South Africa, 20–22 September 2017; Springer: Cham, Switzerland, 2017; pp. 157–167. [Google Scholar] [CrossRef]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2016, 29, 17–37. [Google Scholar] [CrossRef]
- Xu, Y.; Zhou, D.; Ma, J. Scholar-friend recommendation in online academic communities: An approach based on heterogeneous network. Decis. Support Syst. 2019, 119, 1–13. [Google Scholar] [CrossRef]
- Liu, X.; Wu, K.; Liu, B.; Qian, R. HNERec: Scientific collaborator recommendation model based on heterogeneous network embedding. Inf. Process. Manag. 2023, 60, 103253. [Google Scholar] [CrossRef]
- Karnyoto, A.S.; Sun, C.; Liu, B.; Wang, X. Augmentation and heterogeneous graph neural network for AAAI2021-COVID-19 fake news detection. Int. J. Mach. Learn. Cybern. 2022, 13, 2033–2043. [Google Scholar] [CrossRef]
- Wu, Z.; Liang, Q.; Zhan, Z. Course Recommendation Based on Enhancement of Meta-Path Embedding in Heterogeneous Graph. Appl. Sci. 2023, 13, 2404. [Google Scholar] [CrossRef]
- Lops, P.; Gemmis, M.d.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 73–105. [Google Scholar] [CrossRef]
- Huang, R.; Lu, R. Research on Content-based MOOC Recommender Model. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 676–681. [Google Scholar] [CrossRef]
- Campos, R.; dos Santos, R.P.; Oliveira, J. A Recommendation System based on Knowledge Gap Identification in MOOCs Ecosystems. In Proceedings of the XVI Brazilian Symposium on Information Systems, São Bernardo do Campo, Brazil, 3–6 November 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Pang, Y.; Wang, N.; Zhang, Y.; Jin, Y.; Ji, W.; Tan, W. Prerequisite-related MOOC recommendation on learning path locating. Comput. Social Netw. 2019, 6, 1–16. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, B. Application of Personalized Recommendation Technology in MOOC System. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Vientiane, Laos, 11–12 January 2020; pp. 720–723. [Google Scholar] [CrossRef]
- Çano, E.; Morisio, M. Hybrid recommender systems: A systematic literature review. Intell. Data Anal. 2017, 21, 1487–1524. [Google Scholar] [CrossRef]
- Safarov, F.; Kutlimuratov, A.; Abdusalomov, A.B.; Nasimov, R.; Cho, Y.I. Deep Learning Recommendations of E-Education Based on Clustering and Sequence. Electronics 2023, 12, 809. [Google Scholar] [CrossRef]
- Wu, L. Collaborative filtering recommendation algorithm for MOOC resources based on deep learning. Complexity 2021, 2021. [Google Scholar] [CrossRef]
- Liu, J.; Yin, C.; Li, Y.; Sun, H.; Zhou, H. Deep Learning and Collaborative Filtering-Based Methods for Students’ Performance Prediction and Course Recommendation. Wirel. Commun. Mobile Comput. 2021, 2021, 2157343. [Google Scholar] [CrossRef]
- Gong, J.; Wang, S.; Wang, J.; Feng, W.; Peng, H.; Tang, J.; Yu, P.S. Attentional graph convolutional networks for knowledge concept recommendation in moocs in a heterogeneous view. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 79–88. [Google Scholar] [CrossRef]
- Uddin, I.; Imran, A.S.; Muhammad, K.; Fayyaz, N.; Sajjad, M. A systematic mapping review on MOOC recommender systems. IEEE Access 2021, 9, 118379–118405. [Google Scholar] [CrossRef]
- Urdaneta-Ponte, M.C.; Mendez-Zorrilla, A.; Oleagordia-Ruiz, I. Recommendation Systems for Education: Systematic Review. Electronics 2021, 10, 1611. [Google Scholar] [CrossRef]
- Li, Y.; Liu, J.; Ren, J. Social recommendation model based on user interaction in complex social networks. PLoS ONE 2019, 14, e0218957. [Google Scholar] [CrossRef]
- Ma, X.; Dong, L.; Wang, Y.; Li, Y.; Liu, Z.; Zhang, H. An enhanced attentive implicit relation embedding for social recommendation. Data Knowl. Eng. 2023, 145, 102142. [Google Scholar] [CrossRef]
- Paleti, L.; Radha Krishna, P.; Murthy, J. User opinions driven social recommendation system. Int. J. Knowl.-Based Intell. Eng. Syst. 2021, 25, 21–31. [Google Scholar] [CrossRef]
- Li, Y.; Wang, R.; Nan, G.; Li, D.; Li, M. A personalized paper recommendation method considering diverse user preferences. Decis. Support Syst. 2021, 146, 113546. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Li, G.; Gao, R.; Yan, L. Expert Recommendation in Community Question Answering via Heterogeneous Content Network Embedding. Comput. Mater. Contin. 2023, 75, 1687–1709. [Google Scholar] [CrossRef]
- Shou, Z.; Wen, Y.; Chen, P.; Zhang, H. Personalized Knowledge Map Recommendations based on Interactive Behavior Preferences. Int. J. Perform. Eng. 2021, 17, 36–49. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, Y.; Tian, F.; Ni, Y.; Wu, K.; Chen, Y.; Zheng, Q. A cross-curriculum video recommendation algorithm based on a video-associated knowledge map. IEEE Access 2018, 6, 57562–57571. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, Z.; Ji, Y.; Wang, W.; Yu, P.S.; Shi, Z. SemRec: A personalized semantic recommendation method based on weighted heterogeneous information networks. World Wide Web 2019, 22, 153–184. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, C.; Wang, H.; Qiu, R.; Li, Y.; Mu, K. A semantic path-based similarity measure for weighted heterogeneous information networks. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Changchun, China, 17–19 August 2018; Springer: Cham, Switzerland, 2018; pp. 311–323. [Google Scholar] [CrossRef]
- Lu, M.; Wei, X.; Ye, D.; Dai, Y. A unified link prediction framework for predicting arbitrary relations in heterogeneous academic networks. IEEE Access 2019, 7, 124967–124987. [Google Scholar] [CrossRef]
- Vahedian, F.; Burke, R.; Mobasher, B. Multirelational recommendation in heterogeneous networks. ACM Trans. Web 2017, 11, 1–34. [Google Scholar] [CrossRef]
- Meilian, L.; Danna, Y. HIN_DRL: A random walk based dynamic network representation learning method for heterogeneous information networks. Expert Syst. Appl. 2020, 158, 113427. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Pham, T.A.N.; Li, X.; Cong, G.; Zhang, Z. A general recommendation model for heterogeneous networks. IEEE Trans. Knowl. Data Eng. 2016, 28, 3140–3153. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. Arnetminer: Extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 990–998. [Google Scholar] [CrossRef]
- Katawazai, R. Implementing outcome-based education and student-centered learning in Afghan public universities: The current practices and challenges. Heliyon 2021, 7, e07076. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep matrix factorization models for recommender systems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, VIC, Australia, 19–25 August 2017; Volume 17, pp. 3203–3209. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weighted Meta-Path | Path Instance | Semantic Meaning |
|---|---|---|
| Student Exercises Student | Liu Binary tree Li | Liu and Li have the same test score of 0.6 on the binary tree |
| Student Knowledge point Teacher | Wu Stack Zhang | Wu puts into interacting with Zhang on the stack, and the degree of student–teacher interaction is 0.5 |
| Datasets | Objects | Number | Links | Number |
|---|---|---|---|---|
| papers | 23,607 | paper-venues | 23,607 | |
| DBLP | venues | 1796 | paper-authors | 80,535 |
| authors | 4524 | - | - | |
| papers | 16,358 | paper-venues | 16,358 | |
| Aminer | venues | 3765 | paper-authors | 59,343 |
| authors | 3925 | paper-terms | 81,790 | |
| terms | 10,928 | - | - | |
| students | 1055 | videos-teachers | 207 | |
| videos | 207 | students-exercises | 427,478 | |
| teachers | 1 | students-videos | 283,061 | |
| Online | exercises | 163 | students-knowledge points | 310,090 |
| knowledge points | 207 | exercises-knowledge points | 7505 | |
| - | - | videos-knowledge points | 207 | |
| - | - | teachers-knowledge points | 10,490 |
| DBLP | ||||||||||
| Recommendation methods | Pre@1 | Pre@2 | Pre@3 | Pre@4 | Pre@5 | Pre@6 | Pre@7 | Pre@8 | Pre@9 | Pre@10 |
| LPRWHIN | 0.324 | 0.277 | 0.229 | 0.203 | 0.183 | 0.167 | 0.153 | 0.143 | 0.134 | 0.126 |
| PRHN | 0.296 | 0.248 | 0.210 | 0.183 | 0.164 | 0.149 | 0.137 | 0.127 | 0.119 | 0.112 |
| Metapath | 0.205 | 0.170 | 0.155 | 0.140 | 0.131 | 0.122 | 0.114 | 0.108 | 0.103 | 0.098 |
| MF | 0.144 | 0.143 | 0.135 | 0.125 | 0.118 | 0.112 | 0.107 | 0.103 | 0.100 | 0.096 |
| DMF | 0.252 | 0.195 | 0.163 | 0.144 | 0.129 | 0.116 | 0.106 | 0.097 | 0.090 | 0.083 |
| Aminer | ||||||||||
| Recommendation methods | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre |
| LPRWHIN | 0.617 | 0.558 | 0.473 | 0.408 | 0.359 | 0.322 | 0.293 | 0.269 | 0.249 | 0.231 |
| PRHN | 0.592 | 0.532 | 0.446 | 0.382 | 0.333 | 0.297 | 0.269 | 0.245 | 0.227 | 0.211 |
| Metapath | 0.433 | 0.388 | 0.356 | 0.329 | 0.306 | 0.283 | 0.264 | 0.246 | 0.231 | 0.218 |
| MF | 0.181 | 0.176 | 0.173 | 0.165 | 0.158 | 0.150 | 0.143 | 0.137 | 0.131 | 0.126 |
| DMF | 0.208 | 0.177 | 0.154 | 0.136 | 0.123 | 0.112 | 0.102 | 0.094 | 0.087 | 0.081 |
| Online | ||||||||||
| Recommendation methods | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre | Pre |
| LPRWHIN | 0.302 | 0.249 | 0.212 | 0.187 | 0.163 | 0.150 | 0.141 | 0.129 | 0.120 | 0.114 |
| PRHN | 0.240 | 0.207 | 0.183 | 0.166 | 0.144 | 0.129 | 0.117 | 0.109 | 0.098 | 0.089 |
| Metapath | 0.192 | 0.170 | 0.148 | 0.127 | 0.115 | 0.101 | 0.097 | 0.090 | 0.085 | 0.079 |
| MF | 0.169 | 0.138 | 0.124 | 0.113 | 0.099 | 0.093 | 0.083 | 0.077 | 0.069 | 0.062 |
| DMF | 0.239 | 0.204 | 0.188 | 0.165 | 0.147 | 0.133 | 0.120 | 0.110 | 0.099 | 0.090 |
| DBLP | ||||||||||
| Recommendation methods | Rec@1 | Rec@2 | Rec@3 | Rec@4 | Rec@5 | Rec@6 | Rec@7 | Rec@8 | Rec@9 | Rec@10 |
| LPRWHIN | 0.050 | 0.086 | 0.107 | 0.126 | 0.142 | 0.155 | 0.166 | 0.177 | 0.187 | 0.196 |
| PRHN | 0.046 | 0.077 | 0.097 | 0.114 | 0.127 | 0.138 | 0.148 | 0.158 | 0.166 | 0.173 |
| Metapath | 0.032 | 0.053 | 0.072 | 0.087 | 0.102 | 0.113 | 0.124 | 0.135 | 0.143 | 0.152 |
| MF | 0.022 | 0.044 | 0.063 | 0.078 | 0.092 | 0.104 | 0.116 | 0.128 | 0.139 | 0.149 |
| DMF | 0.039 | 0.060 | 0.076 | 0.089 | 0.100 | 0.108 | 0.115 | 0.121 | 0.125 | 0.128 |
| Aminer | ||||||||||
| Recommendation methods | Rec@1 | Rec@2 | Rec@3 | Rec@4 | Rec@5 | Rec@6 | Rec@7 | Rec@8 | Rec@9 | Rec@10 |
| LPRWHIN | 0.090 | 0.163 | 0.207 | 0.238 | 0.262 | 0.281 | 0.299 | 0.314 | 0.326 | 0.338 |
| PRHN | 0.086 | 0.155 | 0.195 | 0.223 | 0.243 | 0.260 | 0.274 | 0.286 | 0.297 | 0.307 |
| Metapath | 0.063 | 0.113 | 0.156 | 0.192 | 0.223 | 0.248 | 0.269 | 0.287 | 0.303 | 0.318 |
| MF | 0.026 | 0.051 | 0.076 | 0.096 | 0.115 | 0.131 | 0.146 | 0.159 | 0.172 | 0.184 |
| DMF | 0.030 | 0.052 | 0.067 | 0.079 | 0.090 | 0.098 | 0.104 | 0.110 | 0.114 | 0.117 |
| Online | ||||||||||
| Recommendation methods | Rec@1 | Rec@2 | Rec@3 | Rec@4 | Rec@5 | Rec@6 | Rec@7 | Rec@8 | Rec@9 | Rec@10 |
| LPRWHIN | 0.086 | 0.142 | 0.180 | 0.213 | 0.232 | 0.256 | 0.279 | 0.292 | 0.307 | 0.324 |
| PRHN | 0.068 | 0.117 | 0.156 | 0.189 | 0.205 | 0.220 | 0.233 | 0.247 | 0.250 | 0.251 |
| Metapath | 0.055 | 0.096 | 0.126 | 0.144 | 0.164 | 0.173 | 0.192 | 0.204 | 0.216 | 0.226 |
| MF | 0.048 | 0.078 | 0.106 | 0.128 | 0.140 | 0.158 | 0.164 | 0.174 | 0.176 | 0.177 |
| DMF | 0.068 | 0.116 | 0.160 | 0.187 | 0.209 | 0.226 | 0.238 | 0.250 | 0.254 | 0.256 |
| Assessment Method 1 | Assessment Method 2 | Assessment Method 3 | Target Score | Equivalent Score | |
|---|---|---|---|---|---|
| Curriculum objective 1 | 20 | 20 | 20 | 60 | 20 |
| Curriculum objective 2 | 20 | 20 | 20 | 60 | 20 |
| Curriculum objective 3 | 30 | 30 | 30 | 90 | 30 |
| Curriculum objective 4 | 30 | 30 | 30 | 90 | 30 |
| Total | 100 | 100 | 100 | 300 | 100 |
| Curriculum Objective 1 | Curriculum Objective 2 | Curriculum Objective 3 | Curriculum Objective 4 | |
|---|---|---|---|---|
| Expected values | 0.700 | 0.700 | 0.700 | 0.700 |
| Group 1 | 0.781 | 0.766 | 0.740 | 0.760 |
| Group 2 | 0.683 | 0.680 | 0.614 | 0.631 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shou, Z.; Shi, Z.; Wen, H.; Liu, J.; Zhang, H. Learning Peer Recommendation Based on Weighted Heterogeneous Information Networks on Online Learning Platforms. Electronics 2023, 12, 2051. https://doi.org/10.3390/electronics12092051
Shou Z, Shi Z, Wen H, Liu J, Zhang H. Learning Peer Recommendation Based on Weighted Heterogeneous Information Networks on Online Learning Platforms. Electronics. 2023; 12(9):2051. https://doi.org/10.3390/electronics12092051
Chicago/Turabian StyleShou, Zhaoyu, Zhixuan Shi, Hui Wen, Jinghua Liu, and Huibing Zhang. 2023. "Learning Peer Recommendation Based on Weighted Heterogeneous Information Networks on Online Learning Platforms" Electronics 12, no. 9: 2051. https://doi.org/10.3390/electronics12092051