
ResE: A Fast and Efficient Neural Network-Based Method for Link Prediction

Abstract
:1. Introduction
- ResE is a newly proposed entity and relation embedding model for knowledge graph completion that is based on deep separable convolutional neural networks. By leveraging the power of deep separable convolutional networks to capture relevant features, ResE effectively enhances the generalization of transition-based embedded models. This approach represents a significant contribution to the field, as it offers a novel solution for improving the performance of knowledge graph completion tasks.
- Our study involved an evaluation of ResE using two widely-accepted benchmark datasets, WN18RR [7] and FB15k-237 [8], to assess its effectiveness in link prediction. Our experimental results demonstrate that ResE outperforms previous embedding models, and it achieves the highest Mean Reciprocal Rank score in most cases when compared to several other state-of-the-art models on these datasets.
2. Related Works
3. Materials and Methods
3.1. Depthwise Separable Convolution
3.2. Channel Attention Mechanisms
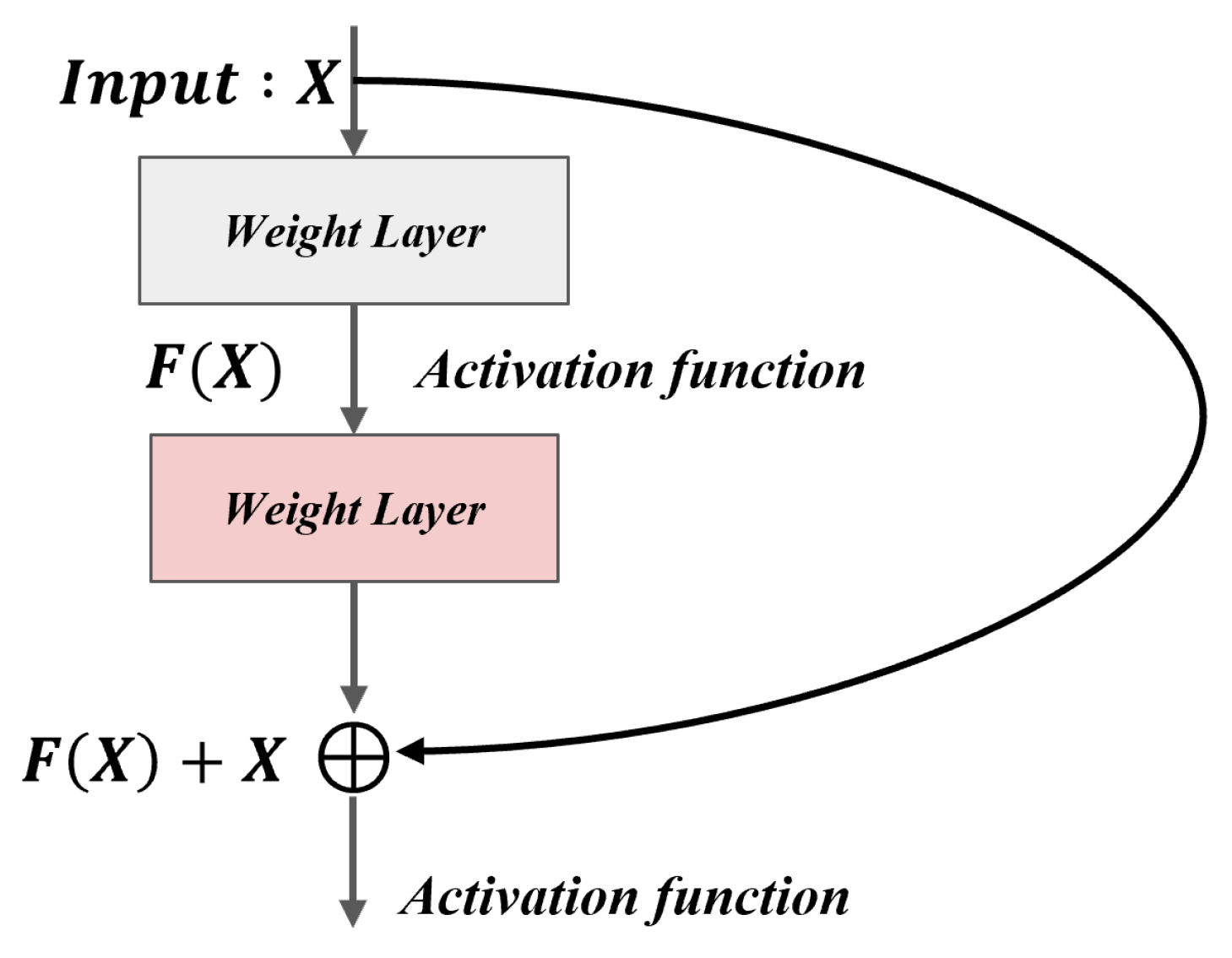
3.3. Residual Network
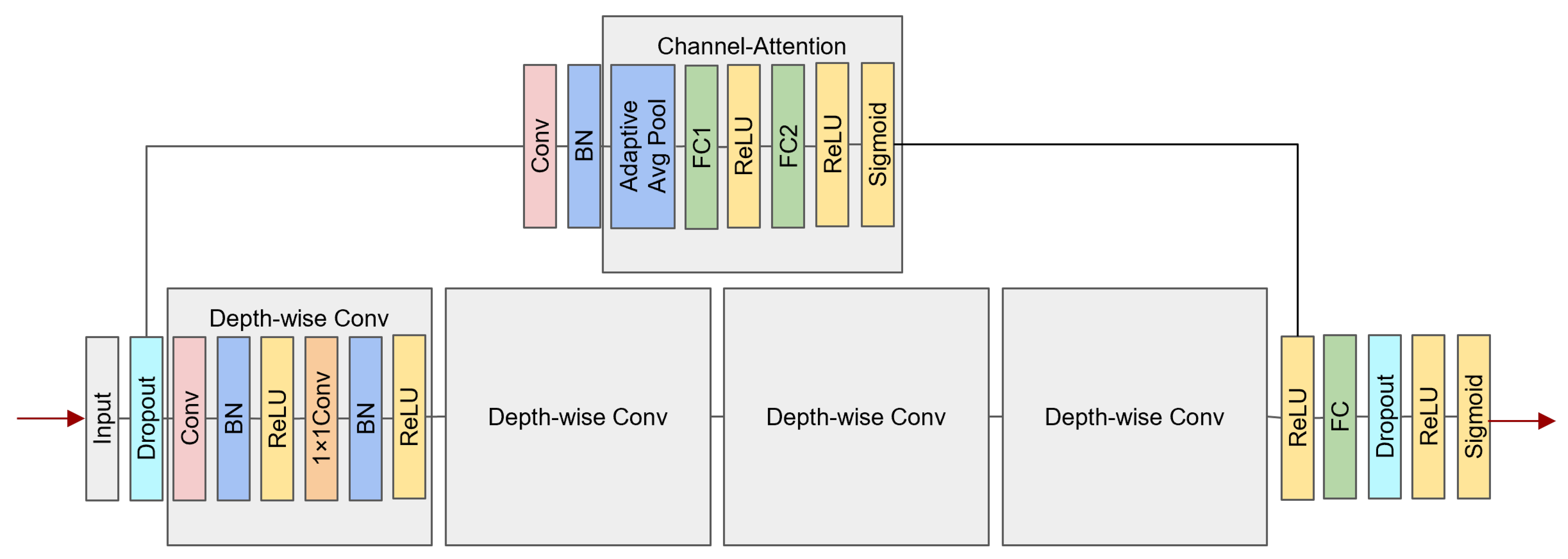
3.4. Our Model
4. Experiments
4.1. Datasets
4.2. Evaluation Criteria
4.3. Training Regime
5. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the The Web Conference, Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167,. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality, Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Beijing, China, 2015; pp. 57–66. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015. [Google Scholar]
- Nguyen, D.Q.; Sirts, K.; Qu, L.; Johnson, M. STransE: A novel embedding model of entities and relationships in knowledge bases. In Proceedings of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge Graph Completion with Adaptive Sparse Transfer Matrix. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical Inference for Multi-relational Embeddings. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2015. [Google Scholar]
- Duvenaud, D.K.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.D.; Aspuru-Guzik, A.; Adams, R.P. Convolutional Networks on Graphs for Learning Molecular Fingerprints. arXiv 2015, arXiv:1509.09292. [Google Scholar]
- tau Yih, W.; Toutanova, K.; Platt, J.C.; Meek, C. Learning Discriminative Projections for Text Similarity Measures. In Proceedings of the Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning semantic representations using convolutional neural networks for web search. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural Language Processing (Almost) from Scratch. arXiv 2011, arXiv:1103.0398. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Definition |
|---|---|
| , | Channel attention mechanism weight matrices |
| r | Dimension of the fully connected layer |
| Sigmoid function | |
| ReLU function |
| Benchmarks | Entities | Relations |
|---|---|---|
| WN18RR | 40,943 | 11 |
| FB15k-237 | 14,541 | 237 |
| Methods | MR | MRR | Hit@10 |
|---|---|---|---|
| TransE | 3385 | 0.226 | 50.1 |
| DisMult | 5110 | 0.431 | 48.9 |
| ComplEX | 5261 | 0.429 | 51.2 |
| ConvE | 5277 | 0.462 | 48.3 |
| ConvKB | 2554 | 0.248 | 52.5 |
| ResE | 3485 | 0.512 | 58.4 |
| Benchmarks | Entities | Relations | |
|---|---|---|---|
| TransE | 347 | 0.294 | 46.5 |
| DisMult | 254 | 0.241 | 41.9 |
| ComplEX | 339 | 0.247 | 42.8 |
| ConvE | 246 | 0.316 | 49.1 |
| ConvKB | 257 | 0.396 | 51.7 |
| ResE | 198 | 0.363 | 53.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yang, H.; Yang, C. ResE: A Fast and Efficient Neural Network-Based Method for Link Prediction. Electronics 2023, 12, 1919. https://doi.org/10.3390/electronics12081919
Li X, Yang H, Yang C. ResE: A Fast and Efficient Neural Network-Based Method for Link Prediction. Electronics. 2023; 12(8):1919. https://doi.org/10.3390/electronics12081919
Chicago/Turabian StyleLi, Xuexiang, Hansheng Yang, and Cong Yang. 2023. "ResE: A Fast and Efficient Neural Network-Based Method for Link Prediction" Electronics 12, no. 8: 1919. https://doi.org/10.3390/electronics12081919