
Grapharizer: A Graph-Based Technique for Extractive Multi-Document Summarization
 , , ,
, , ,
Abstract
:Featured Application
Abstract
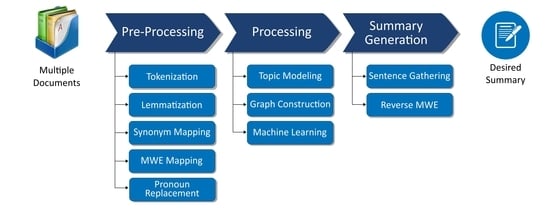
1. Introduction
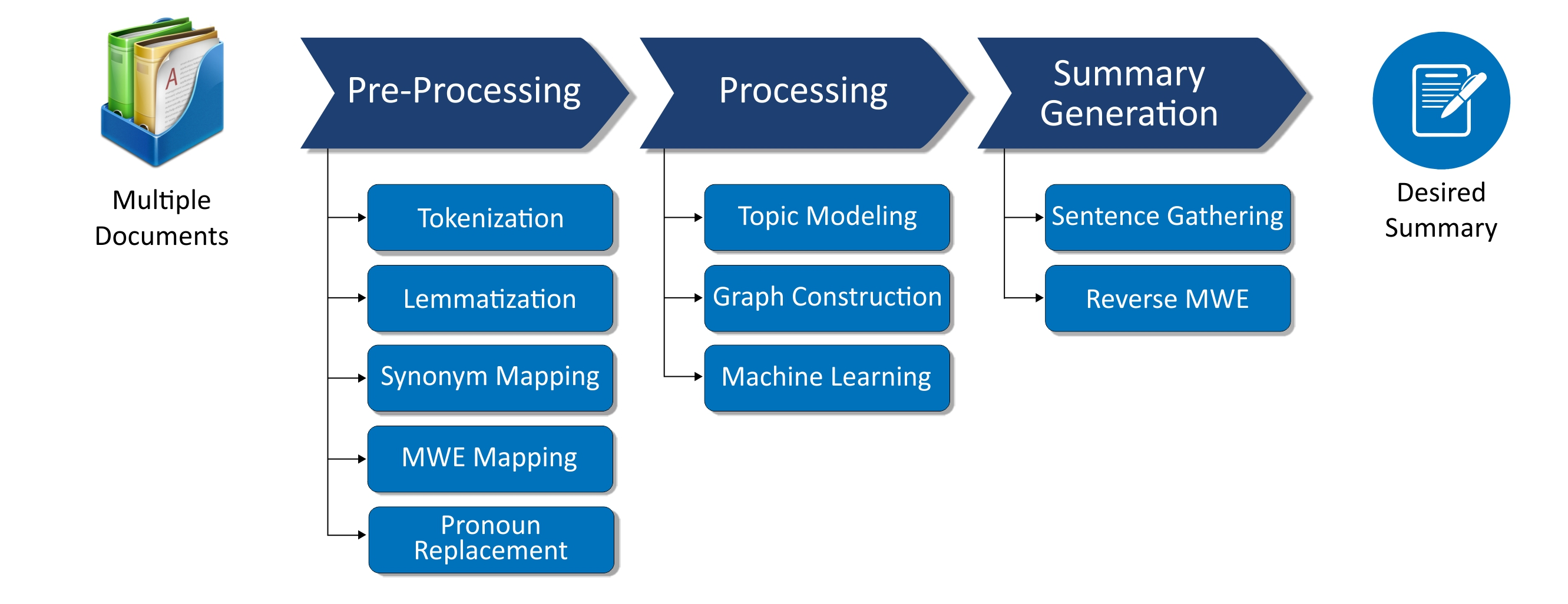
2. State-of-the-Art Multi-Document Summarization Techniques
- Proposing a supervised and domain-independent framework that does not require data to be present in annotated form.
- Developing a dataset named Recent News Articles, to further test the proposed technique for measuring performance.
- Using the LDA topic modeling technique to create a summary that includes all the topics in the input document.
- Increasing the informativity and representativeness of all topics, while mitigating redundancy in the resultant summary.
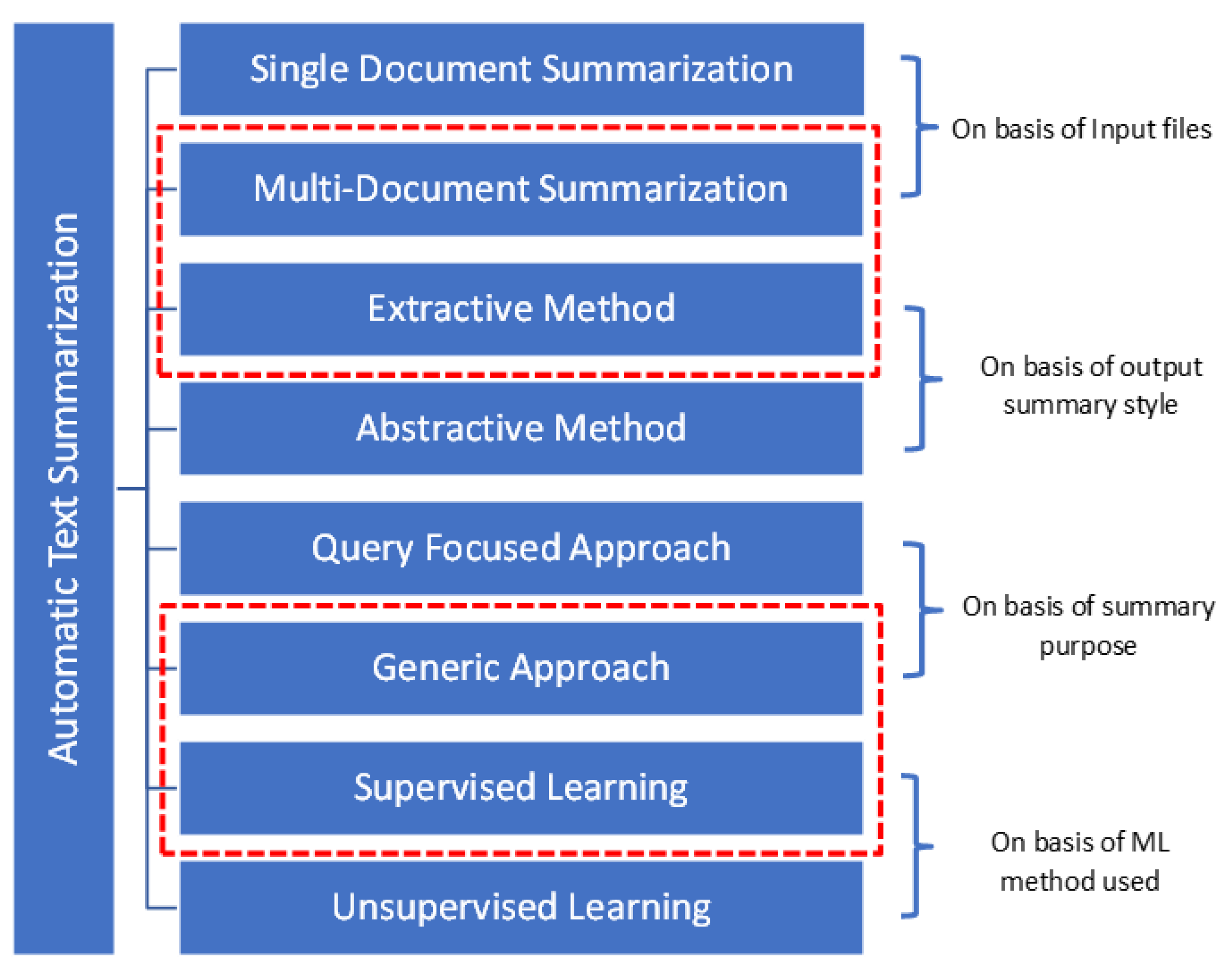
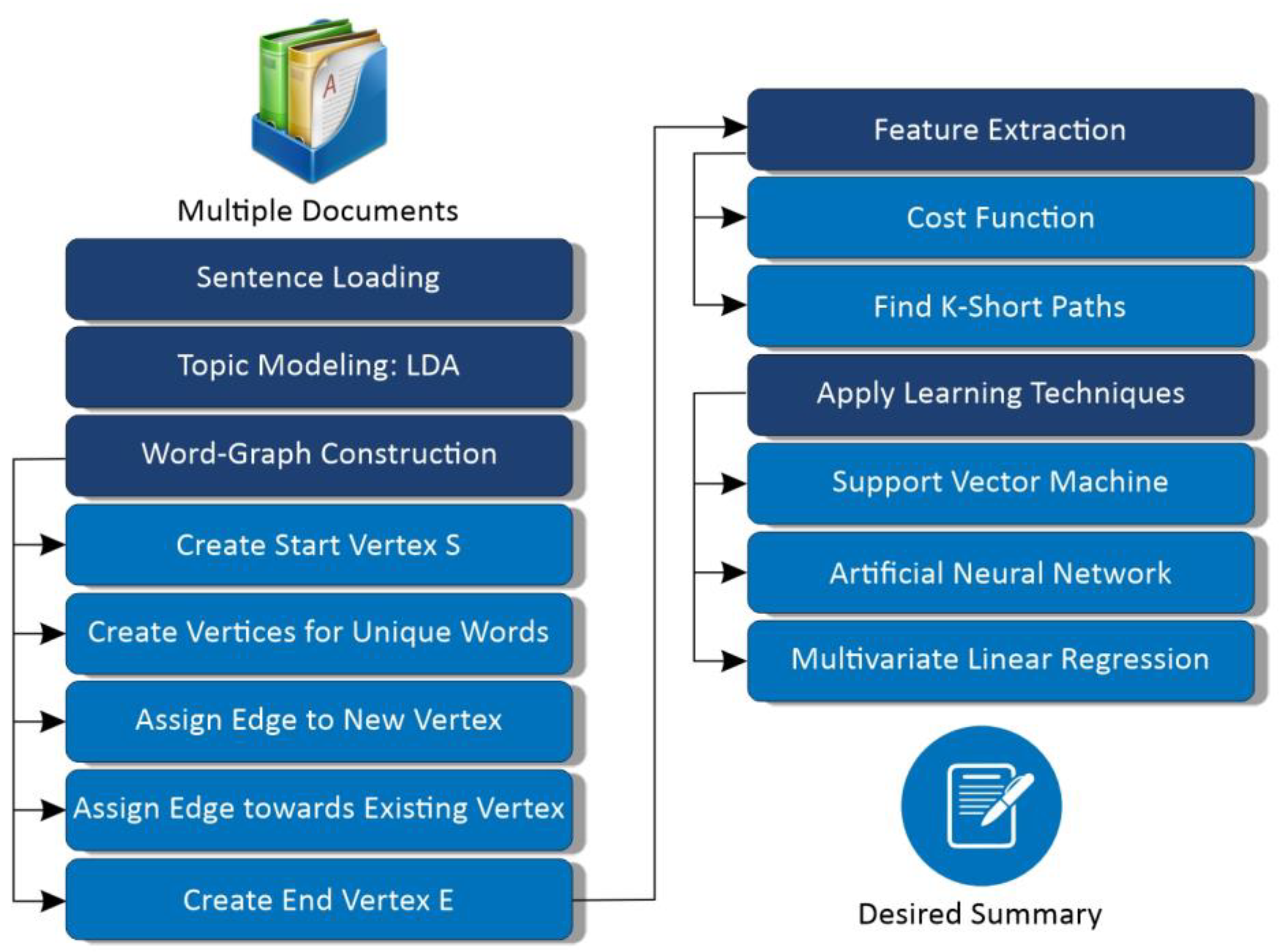
- Using lemmatization, MWE mapping, synonym mapping with novel cross-function, anaphora and cataphora of the pronoun replacement in pre-processing, and reverse-mwe function in post-processing, aiming to increase the grammatical quality of the resultant summary. Figure 2 represents the experiment design of Grapharizer with the description of dependent and independent variables, object, subject, treatments, and the outcome.
3. The Proposed Technique
3.1. Motivation
3.2. Grapharizer: The Graph-Based Method
3.2.1. Pre-Processing
- Tokenization: In tokenization, each sentence from the input documents is broken down into the smallest units, called tokens. This is helpful to recognize the words for the later functionalities in the subsequent pre-processing steps and graph generation module. A few tokens from the input text are <Cambodian>, <leader>, <of>, <opposition>, etc.
- Lemmatization: In this step, the given words/tokens are reduced to their root words, called lemmas. While this appears similar to stemming, which simply chops off the words from the tail, in lemmatization the words are reduced to the root word with proper meaning using a dictionary. The reduced words in lemmatization are grammatically meaningful. Since grammatically correct summaries are one of our aims, lemmatization is relevant to our goals for the summarizer. For instance, we achieved the lemma “share” for “sharing”, instead of the stem word “shar”. Secondly, lemmatization is also better than stemming as it helps to avoid the extra post-processing step of reverse-stemming that entails re-use of the route words that were chopped during stemming.
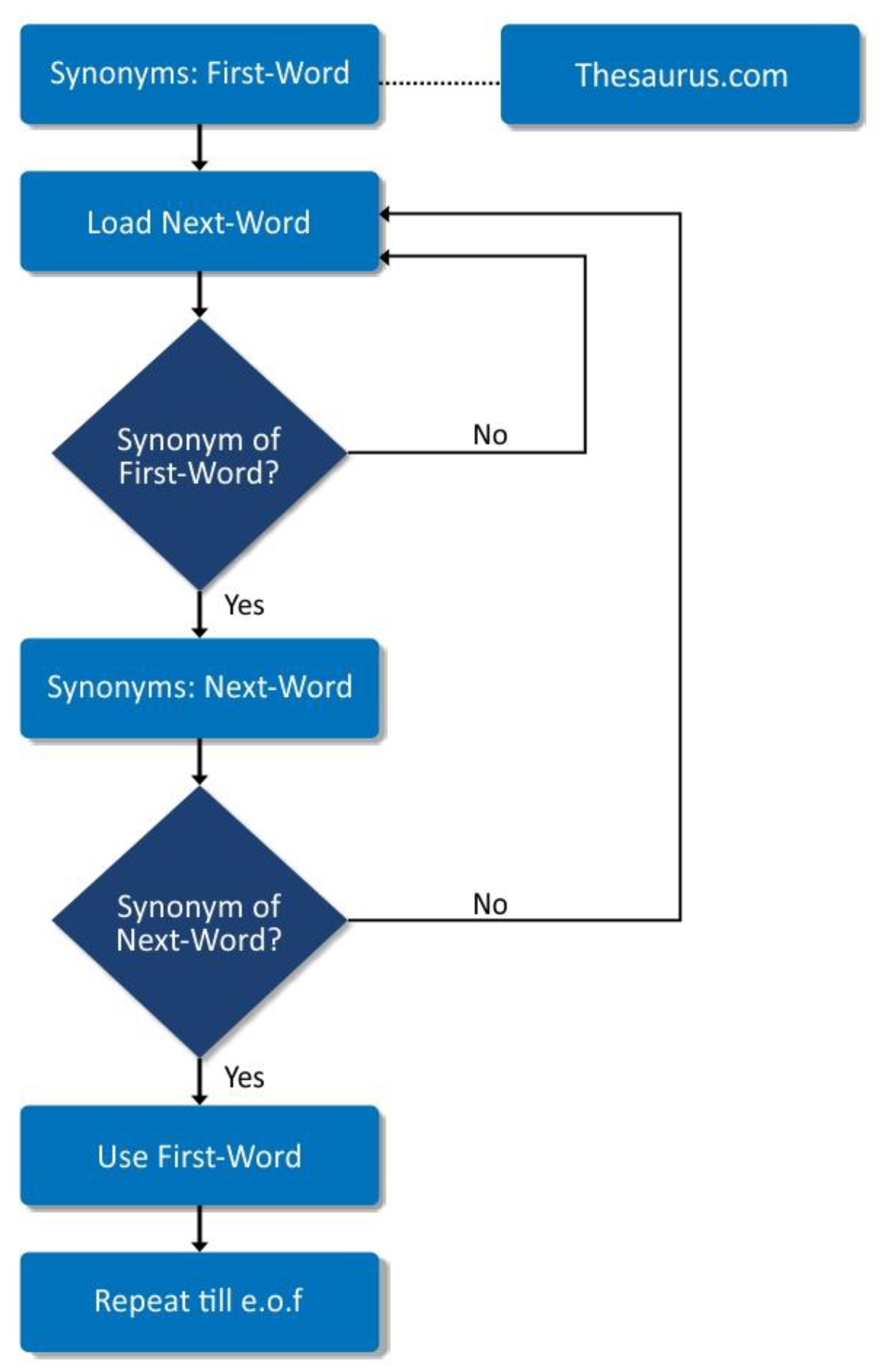
- Synonym Mapping: Since the Grapharizer is based on the word graph technique, the graph it constructs based on multiple documents is going to be too dense. It is important to replace the synonyms to keep the graph simple. Therefore, synonym mapping is the most important step in pre-processing in our system. It keeps the constructed graph under control in terms of the number of vertices by avoiding the creation of unnecessary vertices. We have used Thesaurus.com for synonym mapping through API calls. Thesaurus.com offers several synonyms for a particular word. We have devised a function named cross() to pick the best matching synonyms. For example, we have the word “government” in the document, and then comes another word “regime”. As shown in Figure 4, we must check whether “regime” or its synonyms already exist in the document or not. We check the synonyms of “government”. If “regime” exists in the synonyms of “government” given by Thesaurus.com, we check conversely too by checking the synonyms of “regime”. Thesaurus.com will give a list of synonyms of “regime” as well. Now, if “government” is also a synonym for “regime”, then the condition of the cross() is satisfied, and “regime” can be replaced with “government”. It is worth mentioning that through the cross(), we have managed to obtain the semantic meanings of the synonyms as well. For example, “sentence” is taken as “penalty” instead of “set of words”. The expert evaluation of synonym quality is presented in Section 4.4.
- Multi-Word Expressions: As discussed in Section 3.2, the MWE are likely to appear since the input documents are unstructured files; therefore, we have given special care to map the MWE with their single-word substitutes. This will make the graph simpler, clearer, and more manageable. We gathered the MWE from the dataset and placed their single-worded synonyms in a spreadsheet so that the word graph processing becomes easier. These MWE contain phrasal verbs (e.g., look out, look after), proper nouns (e.g., New York, Christiano Ronaldo), compound nominals (e.g., credit card), and idioms (e.g., once in a blue moon) [49]. Once the candidate sentences for the summary are selected, we apply a function reverse-mwe() that we have devised to reverse the single-worded synonyms replaced earlier back to their corresponding MWE. This will generate closer results to the gold standard summaries of the benchmark datasets, such as the DUC 2004 and Recent News Articles datasets in our case.
- Pronoun Replacement: In this step, the pronouns are replaced with their corresponding nouns. As stated earlier, in a document, some sentences mention nouns about certain events, and later, they can be referred to by pronouns. This situation is also known as anaphoricity. Sometimes, it also happens that the pronouns are mentioned earlier, and the nouns follow them later in the text. This situation is known as cataphoricity. It is possible that the sentences with a noun mention are not extracted, while the sentences with pronouns are selected. This can cause serious confusion in the summary with respect to what these pronouns are referring to. To solve this problem, we have used pronoun replacement. This phase is mainly inspired by Durrett et al. 2016 [9]. It is important to note that assigning the probabilities for pronoun replacements is adapted from Durrett et al. [9]. The logic and implementation of anaphora and cataphora detection and replacement with appropriate nouns are our own contributions. Algorithm 1 explains this work in detail. The ablation study is reported in Section 4.5 to showcase the effectiveness of the proposed pre/post-processing steps in addition to the Grapharizer.
| Algorithm 1 Pronoun Replacement |
|
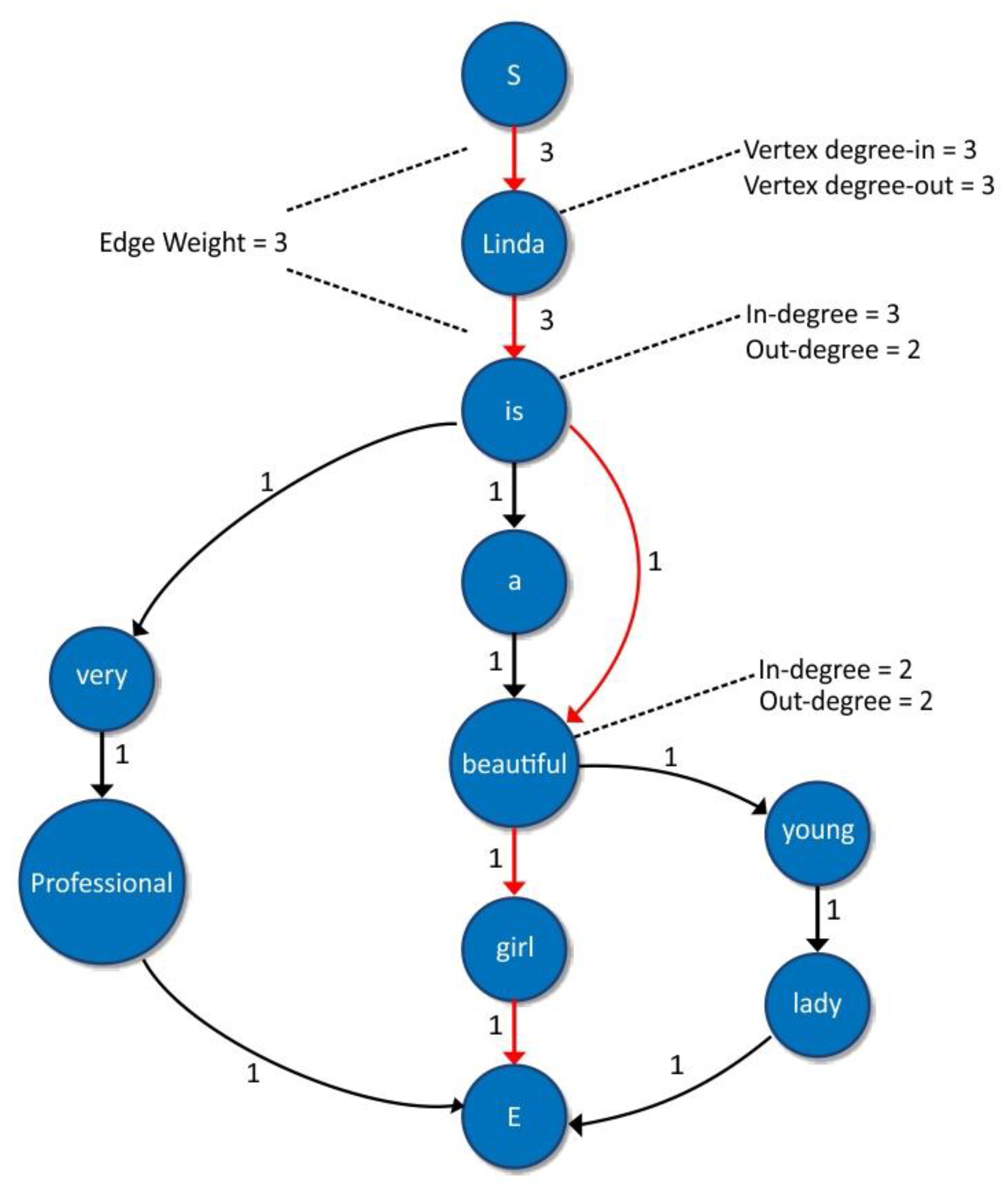
3.2.2. Overview of the Graph Generation Process
| Algorithm 2 Grapharizer |
|
3.2.3. Representativeness
3.2.4. Removing the Redundancy
3.2.5. Grammaticality
3.3. Machine Learning
4. Experiment and Evaluation
4.1. Dataset
4.2. Evaluation Metric
4.3. Baselines
4.4. Synonym Mapping: Expert Evaluation
4.5. Ablation Study
4.6. Time and Space Complexity Analysis of Algorithms
5. Results and Discussion
6. Conclusions and Future Directions
- The major contribution of this research work is facilitation of the process of multi-document text summarization. The output of this research work will be useful in developing news aggregator services, such as Google News, that can summarize news from thousands of news publishers for readers.
- One of the major contributions is the implementation of a framework for pre-processing and post-processing. The novel feature of the double checking of synonyms of the words increased the accuracy and the results were validated through qualitative expert evaluation.
- In addition to anaphora replacement, our system also uses cataphora replacement for resolving the pronoun problems of text.
- Design of a dataset similar to DUC 2004 for testing the performance of Grapharizer. The reference summaries are generated using ChatGPT.
- The efficiency of the system is further enhanced by managing MWE; hence, providing a robust mechanism for adopting modern language expressions.
- Further, the additional validation of results by domain experts added more confidence in the effectiveness and accuracy of our system.
- One of the directions for future work is to validate the results of our system on multiple datasets from various domains. This will help us increase the usability of our system.
- Deep learning-based algorithms, such as CNN and RNN, can be implemented to increase efficiency.
- Similarly, the results of the proposed system can be evaluated with different techniques, such as BERTScores.
- To increase accuracy, manual verification from broader domain experts is envisioned.
- A survey will be conducted with a large number of users to evaluate the usability of the proposed system.
- This study was conducted on the datasets containing news articles in plain text files. A future direction will be to apply the same technique to newspapers and websites to summarize news articles since the layout and structuring of the input are of additional complexity for the summarizer techniques. In these cases, headings / headlines, top sentences, important sentences, and concluding statements will be of additional value in extending Grapharizer.
- It would be interesting to apply Grapharizer to summarize research articles, since they follow a different structure, with the importance of a sentence being directly related to its position in the research article.
- Grapharizer can be utilized in multiple areas. Its usability will be further enhanced by testing it in a multilingual environment. For instance, we are interested in evaluating Grapharizer using Urdu language scripted datasets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- -
- A graph generated on a topic in DUC 2004. Available online: https://drive.google.com/file/d/1CPkB0RvAABgWBAT-hAxbrFuatAIHYn45/view?usp=sharing (accessed on 9 April 2023).
- -
- MWE simplification statistics. Available online: https://docs.google.com/spreadsheets/d/1YlC_HUj2YC2azBsx-bxUVAEQBRjTaNqQ/edit?usp=sharing&ouid=112764386028535750980&rtpof=true&sd=true (accessed on 9 April 2023).
- -
- Topic-specific graphs created after pre-processing and topic modeling. Available online: https://drive.google.com/drive/folders/1WIVfyHIevSrdbfxSVPHeAVCIekY7aIWF?usp=sharing (accessed on 9 April 2023)
- -
- Expert evaluation of synonym mapping. Available online: https://docs.google.com/document/d/1Tv5OAh-f3-UF6B5cH4deTuvIh5owMTez/edit?usp=sharing&ouid=112764386028535750980&rtpof=true&sd=true (accessed on 9 April 2023).
References
- Bidoki, M.; Moosavi, M.R.; Fakhrahmad, M. A semantic approach to extractive multi-document summarization: Applying sentence expansion for tuning of conceptual densities. Inf. Process. Manag. 2020, 57, 102341. [Google Scholar] [CrossRef]
- Sanchez-Gomez, J.M.; Vega-Rodríguez, M.A.; Perez, C.J. A decomposition-based multi-objective optimization approach for extractive multi-document text summarization. Appl. Soft Comput. 2020, 91, 106231. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Mojrian, M.; Mirroshandel, S.A. A novel extractive multi-document text summarization system using quantum-inspired genetic algorithm: MTSQIGA. Expert Syst. Appl. 2021, 171, 114555. [Google Scholar] [CrossRef]
- Siautama, R.; IA, A.C.; Suhartono, D. Extractive hotel review summarization based on TF/IDF and adjective-noun pairing by considering annual sentiment trends. Procedia Comput. Sci. 2021, 179, 558–565. [Google Scholar]
- Jalil, Z.; Nasir, J.A.; Nasir, M. Extractive Multi-Document Summarization: A Review of Progress in the Last Decade. IEEE Access 2021, 9, 130928–130946. [Google Scholar] [CrossRef]
- Uçkan, T.; Karcı, A. Extractive multi-document text summarization based on graph independent sets. Egypt. Inform. J. 2020, 21, 145–157. [Google Scholar] [CrossRef]
- ShafieiBavani, E.; Ebrahimi, M.; Wong, R.; Chen, F. On improving informativity and grammaticality for multi-sentence compression. arXiv 2016, arXiv:1605.02150. [Google Scholar]
- Durrett, G.; Berg-Kirkpatrick, T.; Klein, D. Learning-based single-document summarization with compression and anaphoricity constraints. arXiv 2016, arXiv:1603.08887. [Google Scholar]
- Wu, K.; Li, L.; Li, J.; Li, T. Ontology-enriched multi-document summarization in disaster management using submodular function. Inf. Sci. 2013, 224, 118–129. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Jabeen, S.; Fiori, A.; Shah, S. Multi-document summarization based on the Yago ontology. Expert Syst. Appl. 2013, 40, 6976–6984. [Google Scholar] [CrossRef]
- Hennig, L.; Umbrath, W.; Wetzker, R. An ontology-based approach to text summarization. In Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, Australia, 9–12 December 2008; IEEE: Washington, DC, USA. [Google Scholar]
- Oliveira, H.; Ferreira, R.; Lima, R.; Lins, R.D.; Freitas, F.; Riss, M.; Simske, S.J. Assessing shallow sentence scoring techniques and combinations for single and multi-document summarization. Expert Syst. Appl. 2016, 65, 68–86. [Google Scholar] [CrossRef]
- Alguliev, R.M.; Aliguliyev, R.M.; Hajirahimova, M.S. GenDocSum+ MCLR: Generic document summarization based on maximum coverage and less redundancy. Expert Syst. Appl. 2012, 39, 12460–12473. [Google Scholar] [CrossRef]
- Qiang, J.-P.; Chen, P.; Ding, W.; Xie, F.; Wu, X. Multi-document summarization using closed patterns. Knowl.-Based Syst. 2016, 99, 28–38. [Google Scholar] [CrossRef]
- Canhasi, E.; Kononenko, I. Weighted archetypal analysis of the multi-element graph for query-focused multi-document summarization. Expert Syst. Appl. 2014, 41, 535–543. [Google Scholar] [CrossRef]
- Bollegala, D.; Okazaki, N.; Ishizuka, M. A preference learning approach to sentence ordering for multi-document summarization. Inf. Sci. 2012, 217, 78–95. [Google Scholar] [CrossRef]
- Nasir, J.A.; Karim, A.; Tsatsaronis, G.; Varlamis, I. A knowledge-based semantic kernel for text classification. In International Symposium on String Processing and Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Radev, D.R.; Jing, H.; Styś, M.; Tam, D. Centroid-based summarization of multiple documents. Inf. Process. Manag. 2004, 40, 919–938. [Google Scholar] [CrossRef]
- Zhang, Y.; Xia, Y.; Liu, Y.; Wang, W. Clustering sentences with density peaks for multi-document summarization. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015. [Google Scholar]
- Wang, B.; Zhang, J.; Liu, Y.; Zou, Y. Density peaks clustering based integrate framework for multi-document summarization. CAAI Trans. Intell. Technol. 2017, 2, 26–30. [Google Scholar] [CrossRef]
- Nagwani, N.K. Summarizing large text collection using topic modeling and clustering based on MapReduce framework. J. Big Data 2015, 2, 6. [Google Scholar] [CrossRef]
- Christensen, J.; Soderland, S.; Bansal, G. Hierarchical summarization: Scaling up multi-document summarization. In Proceedings of the 52nd annual meeting of the association for computational linguistics, Baltimore, MD, USA, 23–25 June 2014; Volume 1. Long papers. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Contractor, D.; Guo, Y.; Korhonen, A. Using argumentative zones for extractive summarization of scientific articles. In Proceedings of the COLING 2012, Mumbai, India, 8–15 December 2012. [Google Scholar]
- Gong, Y.; Liu, X. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001. [Google Scholar]
- Ferreira, R.; Lins, R.D.; Simske, S.J.; Freitas, F.; Riss, M. Assessing sentence similarity through lexical, syntactic and semantic analysis. Comput. Speech Lang. 2016, 39, 1–28. [Google Scholar] [CrossRef]
- Marujo, L.; Ling, W.; Ribeiro, R.; Gershman, A.; Carbonell, J.; de Matos, D.M.; Neto, J.P. Exploring events and distributed representations of text in multi-document summarization. Knowl.-Based Syst. 2016, 94, 33–42. [Google Scholar] [CrossRef]
- Carbonell, J.; Goldstein, J. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998. [Google Scholar]
- Lin, J.; Madnani, N.; Dorr, B. Putting the user in the loop: Interactive maximal marginal relevance for query-focused summarization. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010. [Google Scholar]
- Ozsoy, M.; Cicekli, I.; Alpaslan, F. Text summarization of turkish texts using latent semantic analysis. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010. [Google Scholar]
- Chatterjee, N.; Yadav, N. Fuzzy rough set-based sentence similarity measure and its application to text summarization. IETE Tech. Rev. 2019, 36, 517–525. [Google Scholar] [CrossRef]
- Xu, J.; Durrett, G. Neural extractive text summarization with syntactic compression. arXiv 2019, arXiv:1902.00863. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Canhasi, E. Query Focused Multi-document Summarization Based on Five-Layered Graph and Universal Paraphrastic Embeddings. In Proceedings of the Computer Science On-Line Conference; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Baralis, E.; Cagliero, L.; Mahoto, N.; Fiori, A. GRAPHSUM: Discovering correlations among multiple terms for graph-based summarization. Inf. Sci. 2013, 249, 96–109. [Google Scholar] [CrossRef]
- Chali, Y.; Hasan, S.A.; Joty, S.R. Improving graph-based random walks for complex question answering using syntactic, shallow semantic and extended string subsequence kernels. Inf. Process. Manag. 2011, 47, 843–855. [Google Scholar] [CrossRef]
- John, A.; Wilscy, M. Vertex cover algorithm based multi-document summarization using information content of sentences. Procedia Comput. Sci. 2015, 46, 285–291. [Google Scholar] [CrossRef]
- Tzouridis, E.; Nasir, J.A.; Brefeld, U. Learning to summarise related sentences. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014. [Google Scholar]
- Sukumar, P.; Gayathri, K. Semantic based Sentence Ordering Approach for Multi-Document Summarization. Int. J. Recent Technol. Eng. 2014, 3, 71–76. [Google Scholar]
- Christensen, J.; Soderland, S.; Etzioni, O. Towards coherent multi-document summarization. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 9–14 June 2013. [Google Scholar]
- Chen, J.; Zhuge, H. Extractive summarization of documents with images based on multi-modal RNN. Future Gener. Comput. Syst. 2019, 99, 186–196. [Google Scholar] [CrossRef]
- Celikkale, B.; Erdogan, G.; Erdem, A.; Erdem, E. Generating visual story graphs with application to photo album summarization. Signal Process. Image Commun. 2021, 90, 116033. [Google Scholar] [CrossRef]
- Shingrakhia, H.; Patel, H. SGRNN-AM and HRF-DBN: A hybrid machine learning model for cricket video summarization. Vis. Comput. 2022, 38, 2285–2301. [Google Scholar] [CrossRef]
- Radarapu, R.; Gopal, A.S.S.; Madhusudhan, N. Video summarization and captioning using dynamic mode decomposition for surveillance. Int. J. Inf. Technol. 2021, 13, 1927–1936. [Google Scholar] [CrossRef]
- Marzijarani, S.B.; Sajedi, H. Opinion mining with reviews summarization based on clustering. Int. J. Inf. Technol. 2020, 12, 1299–1310. [Google Scholar] [CrossRef]
- Abdi, A.; Hasan, S.; Shamsuddin, S.M.; Idris, N.; Piran, J. A hybrid deep learning architecture for opinion-oriented multi-document summarization based on multi-feature fusion. Knowl.-Based Syst. 2021, 213, 106658. [Google Scholar] [CrossRef]
- Pontes, E.L.; Huet, S.; Torres-Moreno, J.-M.; Linhares, A.C. Compressive approaches for cross-language multi-document summarization. Data Knowl. Eng. 2020, 125, 101763. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. EdgeSumm: Graph-based framework for automatic text summarization. Inf. Process. Manag. 2020, 57, 102264. [Google Scholar] [CrossRef]
- Wang, D.; Liu, P.; Zheng, Y.; Qiu, X.; Huang, X.-J. Heterogeneous graph neural networks for extractive document summarization. arXiv 2020, arXiv:2004.12393. [Google Scholar]
- Tomer, M.; Kumar, M. Multi-document extractive text summarization based on firefly algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2021, 34, 6057–6065. [Google Scholar] [CrossRef]
- Davoodijam, E.; Ghadiri, N.; Shahreza, M.L.; Rinaldi, F. MultiGBS: A multi-layer graph approach to biomedical summarization. J. Biomed. Inform. 2021, 116, 103706. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Wang, T.; Wan, X. Multi-granularity interaction network for extractive and abstractive multi-document summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Van Lierde, H.; Chow, T.W. Query-oriented text summarization based on hypergraph transversals. Inf. Process. Manag. 2019, 56, 1317–1338. [Google Scholar] [CrossRef]
- Li, X.; Wu, P.; Zou, C.; Xie, H.; Wang, F.L. Sentiment Lossless Summarization. Knowl.-Based Syst. 2021, 227, 107170. [Google Scholar] [CrossRef]
- Mallick, C.; Das, A.K.; Dutta, M.; Das, A.K.; Sarkar, A. Graph-based text summarization using modified TextRank. In Soft Computing in Data Analytics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 137–146. [Google Scholar]
- Filippova, K. Multi-sentence compression: Finding shortest paths in word graphs. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Teh, Y.; Jordan, M.; Beal, M.; Blei, D. Hierarchical dirichlet processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Swapna, B.; Anuradha, T. Achieving Higher Ranking to Webpages Through Search Engine Optimization. In Proceedings of the International Conference on Computational Intelligence and Data Engineering, online, 12–13 August 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Rani, R.; Lobiyal, D.K. An extractive text summarization approach using tagged-LDA based topic modeling. Multimed. Tools Appl. 2021, 80, 3275–3305. [Google Scholar] [CrossRef]
- Issam KA, R.; Patel, S. Topic modeling based extractive text summarization. arXiv 2021, arXiv:2106.15313. [Google Scholar] [CrossRef]
- Noor, U. A Data-Driven Approach to Automated Analysis of Cyber Threat Intelligence [Doctoral dissertation, NUST]. Pakistan Research Repository. 2020. Available online: http://prr.hec.gov.pk/jspui/handle/123456789/18922 (accessed on 1 November 2022).
- Hirao, T.; Isozaki, H.; Maeda, E.; Matsumoto, Y. Extracting important sentences with support vector machines. In Proceedings of the COLING 2002: The 19th International Conference on Computational Linguistics, Taipei, Taiwan, 26–30 August 2002. [Google Scholar]
- Saura, J.R. Using data sciences in digital marketing: Framework, methods, and performance metrics. J. Innov. Knowl. 2021, 6, 92–102. [Google Scholar] [CrossRef]
- Kianmehr, K.; Gao, S.; Attari, J.; Rahman, M.M.; Akomeah, K.; Alhajj, R.; Rokne, J.; Barker, K. Text summarization techniques: SVM versus neural networks. In Proceedings of the 21th International Conference on Information Integration and Web-Based Applications & Services, Munich, Germany, 2–4 December 2019; pp. 487–491. [Google Scholar]
- Sinha, A.; Yadav, A.; Gahlot, A. Extractive text summarization using neural networks. arXiv 2018, arXiv:1802.10137. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Ferrigno, G.; Del Sarto, N.; Piccaluga, A.; Baroncelli, A. Industry 4.0 Base Technologies and Business Models: A Bibliometric Analysis. In Academy of Management Proceedings; Academy of Management: Briarcliff Manor, NY, USA, 2020; p. 10510. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | DUC 2004 | Recent News Articles |
|---|---|---|
| Total topics | 50 | 25 |
| Number of documents (per topic) | 10 | 10 |
| Total number of documents | 500 | 250 |
| News/data source | TRD, TREC collection newswire | News articles |
| Without Pre-Processing | ||||
|---|---|---|---|---|
| ROUGE-Type | Recall | Precision | F-Score | Improvement |
| Rouge-1 | 0.12567 | 0.16509 | 0.14271 | - |
| Rouge-2 | 0.00368 | 0.005 | 0.00424 | - |
| Rouge-L | 0.13274 | 0.16111 | 0.14555 | - |
| Rouge-SU4 | 0.03745 | 0.04251 | 0.03982 | - |
| With pronoun replacement | ||||
| Rouge-1 | 0.18188 | 0.19841 | 0.18979 | 0.04708 |
| Rouge-2 | 0.00831 | 0.00806 | 0.00818 | 0.00394 |
| Rouge-L | 0.15956 | 0.17857 | 0.16853 | 0.02298 |
| Rouge-SU4 | 0.05296 | 0.04836 | 0.05056 | 0.01074 |
| With synonym mapping | ||||
| Rouge-1 | 0.15872 | 0.1822 | 0.16965 | 0.02694 |
| Rouge-2 | 0.02082 | 0.02155 | 0.02118 | 0.01694 |
| Rouge-L | 0.15627 | 0.15741 | 0.15684 | 0.01129 |
| Rouge-SU4 | 0.04616 | 0.04474 | 0.04544 | 0.00562 |
| With MWE mapping | ||||
| Rouge-1 | 0.17216 | 0.19915 | 0.18467 | 0.04196 |
| Rouge-2 | 0.01703 | 0.01724 | 0.01714 | 0.0129 |
| Rouge-L | 0.1612 | 0.16827 | 0.16466 | 0.01911 |
| Rouge-SU4 | 0.05045 | 0.04912 | 0.04978 | 0.00996 |
| With reverse-mwe() | ||||
| Rouge-1 | 0.32949 | 0.24722 | 0.28249 | 0.13978 |
| Rouge-2 | 0.09168 | 0.0618 | 0.07383 | 0.06959 |
| Rouge-L | 0.23338 | 0.17958 | 0.20297 | 0.05742 |
| Rouge-SU4 | 0.11458 | 0.07159 | 0.08812 | 0.0483 |
| With all pre-processing | ||||
| Rouge-1 | 0.53864 | 0.27392 | 0.36316 | 0.22045 |
| Rouge-2 | 0.14068 | 0.06731 | 0.09105 | 0.08681 |
| Rouge-L | 0.25621 | 0.21212 | 0.23209 | 0.08654 |
| Rouge-SU4 | 0.0978 | 0.07267 | 0.08338 | 0.04356 |
| Methods | ||||||||
|---|---|---|---|---|---|---|---|---|
| ROUGE Evaluation METRICES | TextRank [69] | LexRank [34] | KUSH [7] | Grapharizer | ANN Grapharizer | MLR Grapharizer | SVM Grapharizer | |
| Rouge 1 | Recall | 0.39893 | 0.32206 | 0.38072 | 0.41875 | 0.54775 | 0.55257 | 0.53864 |
| Precision | 0.33462 | 0.30458 | 0.34019 | 0.21292 | 0.28415 | 0.28659 | 0.27392 | |
| F-Score | 0.36292 | 0.31255 | 0.35879 | 0.28230 | 0.37418 | 0.37742 | 0.36316 | |
| Rouge 2 | Recall | 0.07977 | 0.05439 | 0.08277 | 0.09816 | 0.14276 | 0.14812 | 0.14068 |
| Precision | 0.06831 | 0.05170 | 0.07373 | 0.04710 | 0.06985 | 0.07230 | 0.06731 | |
| F-Score | 0.07338 | 0.05292 | 0.07786 | 0.06366 | 0.09381 | 0.09717 | 0.09105 | |
| Rouge L | Recall | 0.30685 | 0.25785 | 0.29037 | 0.24236 | 0.23239 | 0.24563 | 0.25621 |
| Precision | 0.25868 | 0.24444 | 0.25945 | 0.19924 | 0.20700 | 0.20503 | 0.21212 | |
| F-Score | 0.27991 | 0.25053 | 0.27364 | 0.20195 | 0.20164 | 0.20200 | 0.23209 | |
| Rouge W | Recall | 0.10436 | 0.08957 | 0.09908 | 0.10615 | 0.09890 | 0.10853 | 0.10059 |
| Precision | 0.16113 | 0.15517 | 0.16197 | 0.05581 | 0.09220 | 0.10118 | 0.09197 | |
| F-Score | 0.12622 | 0.11334 | 0.12278 | 0.07502 | 0.09543 | 0.10473 | 0.09609 | |
| Rouge SU | Recall | 0.13998 | 0.09532 | 0.13062 | 0.17619 | 0.20000 | 0.20000 | 0.19524 |
| Precision | 0.09683 | 0.08421 | 0.10372 | 0.08371 | 0.11197 | 0.10345 | 0.09904 | |
| F-Score | 0.11328 | 0.08884 | 0.11493 | 0.11350 | 0.13636 | 0.13630 | 0.13141 | |
| ROUGE Evaluation Metrices | Recent News Articles | ||||
|---|---|---|---|---|---|
| Grapharizer | ANNGrapharizer | MLRGrapharizer | SVMGrapharizer | ||
| Rouge 1 | Recall | 0.42018 | 0.49439 | 0.49429 | 0.50159 |
| Precision | 0.13863 | 0.22926 | 0.21694 | 0.22280 | |
| F-Score | 0.20848 | 0.31325 | 0.30154 | 0.30855 | |
| Rouge 2 | Recall | 0.04846 | 0.12351 | 0.11074 | 0.12604 |
| Precision | 0.01484 | 0.05373 | 0.04603 | 0.05252 | |
| F-Score | 0.02273 | 0.07488 | 0.06503 | 0.07415 | |
| Rouge L | Recall | 0.14574 | 0.18948 | 0.18948 | 0.20292 |
| Precision | 0.06627 | 0.10179 | 0.09828 | 0.10517 | |
| F-Score | 0.09111 | 0.13243 | 0.12943 | 0.13854 | |
| Rouge W | Recall | 0.10299 | 0.08647 | 0.07991 | 0.07991 |
| Precision | 0.08422 | 0.07543 | 0.06754 | 0.06385 | |
| F-Score | 0.09238 | 0.08058 | 0.07321 | 0.07098 | |
| Rouge SU | Recall | 0.19608 | 0.15686 | 0.16177 | 0.15686 |
| Precision | 0.06309 | 0.07049 | 0.06933 | 0.06751 | |
| F-Score | 0.09547 | 0.09727 | 0.09706 | 0.09439 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jalil, Z.; Nasir, M.; Alazab, M.; Nasir, J.; Amjad, T.; Alqammaz, A. Grapharizer: A Graph-Based Technique for Extractive Multi-Document Summarization. Electronics 2023, 12, 1895. https://doi.org/10.3390/electronics12081895
Jalil Z, Nasir M, Alazab M, Nasir J, Amjad T, Alqammaz A. Grapharizer: A Graph-Based Technique for Extractive Multi-Document Summarization. Electronics. 2023; 12(8):1895. https://doi.org/10.3390/electronics12081895
Chicago/Turabian StyleJalil, Zakia, Muhammad Nasir, Moutaz Alazab, Jamal Nasir, Tehmina Amjad, and Abdullah Alqammaz. 2023. "Grapharizer: A Graph-Based Technique for Extractive Multi-Document Summarization" Electronics 12, no. 8: 1895. https://doi.org/10.3390/electronics12081895