
A Robust Feature Extraction Method for Underwater Acoustic Target Recognition Based on Multi-Task Learning


Abstract
:1. Introduction
2. Proposed Method
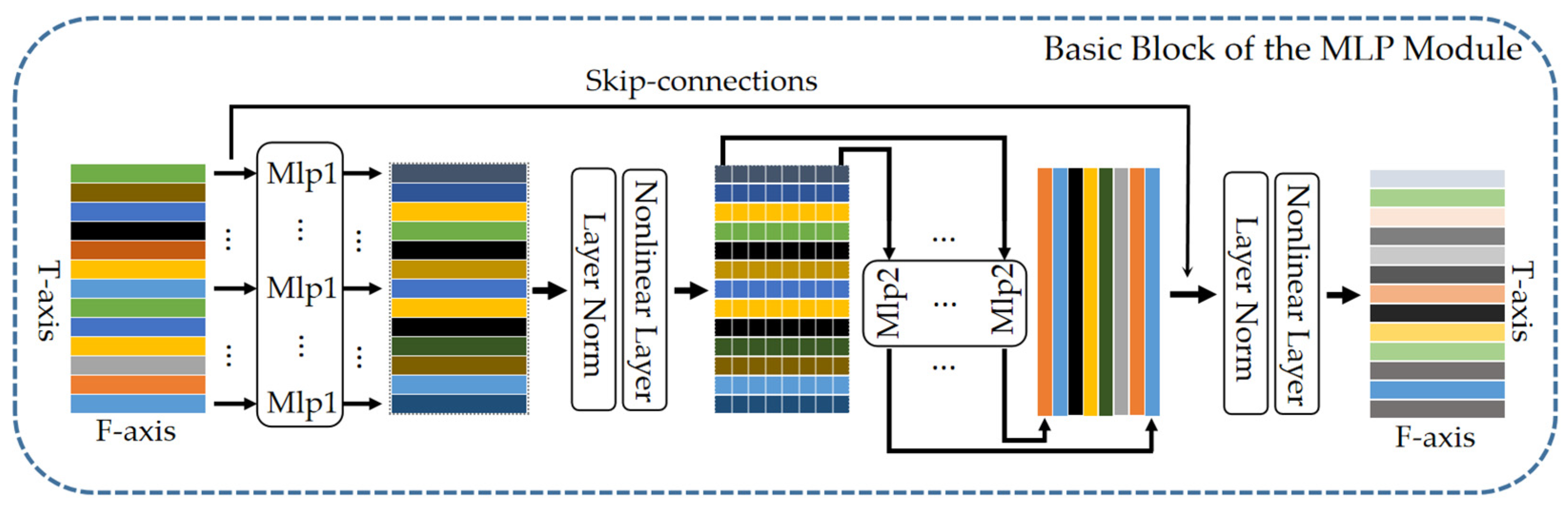
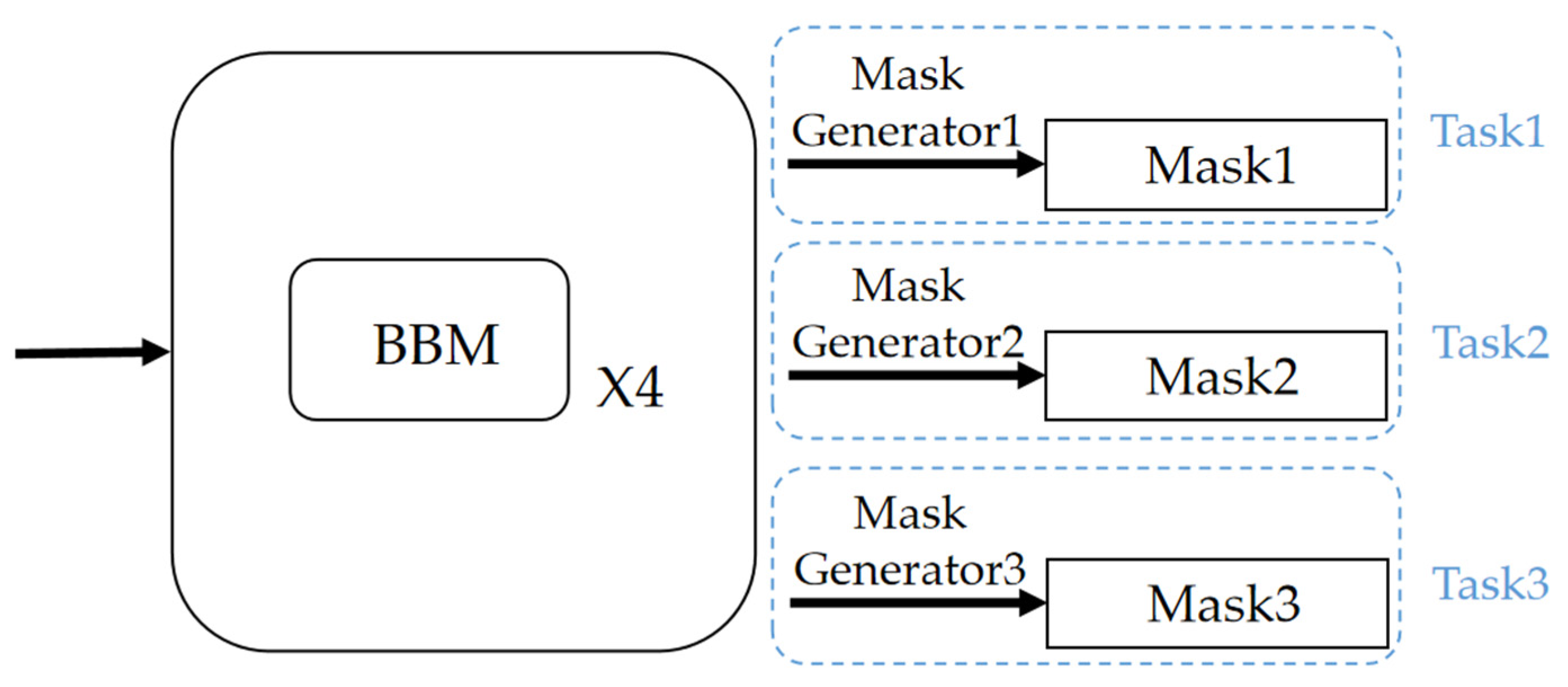
2.1. Basic Block of the MLP Module
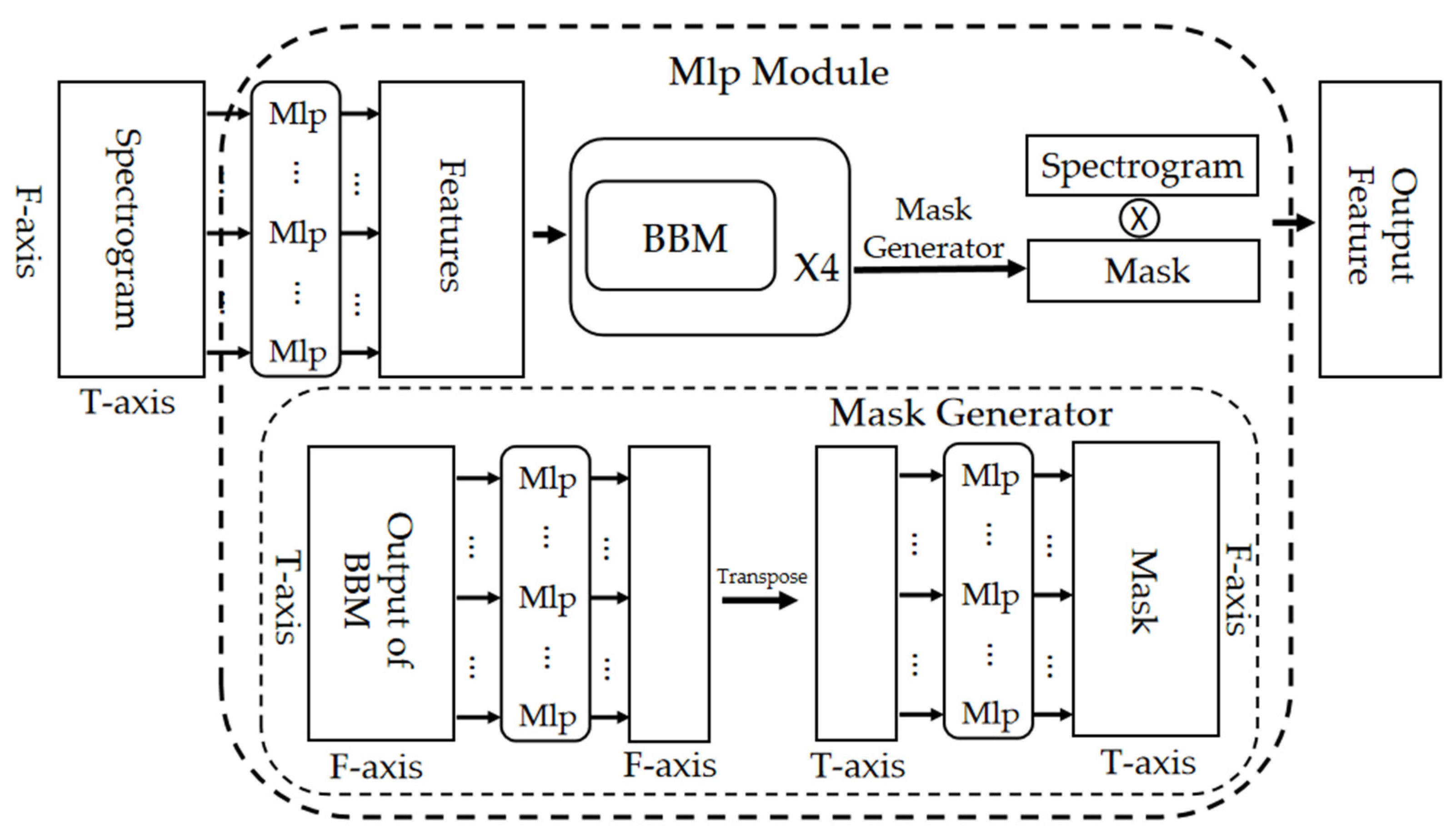
2.2. Robust Feature Extraction Network
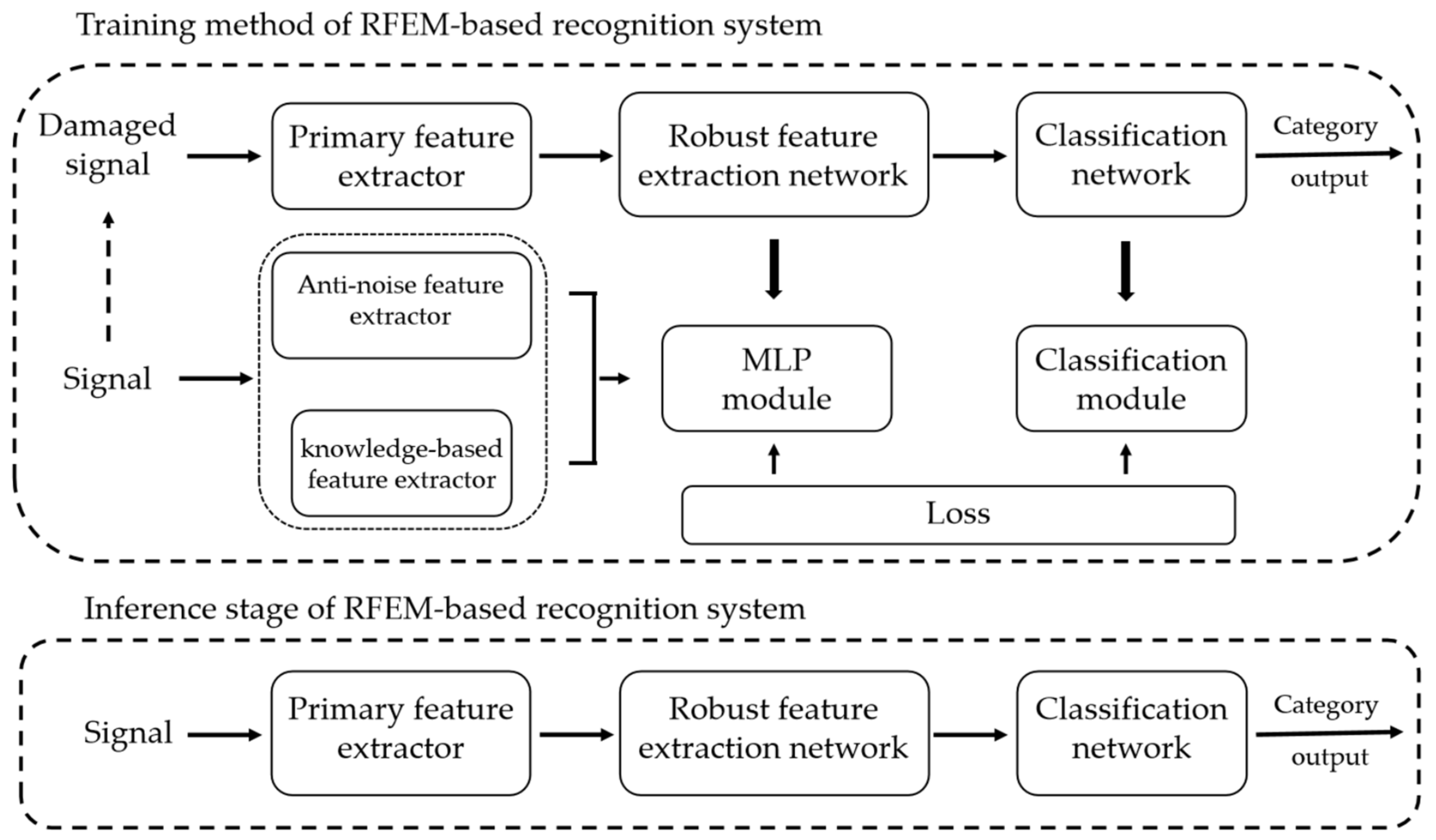
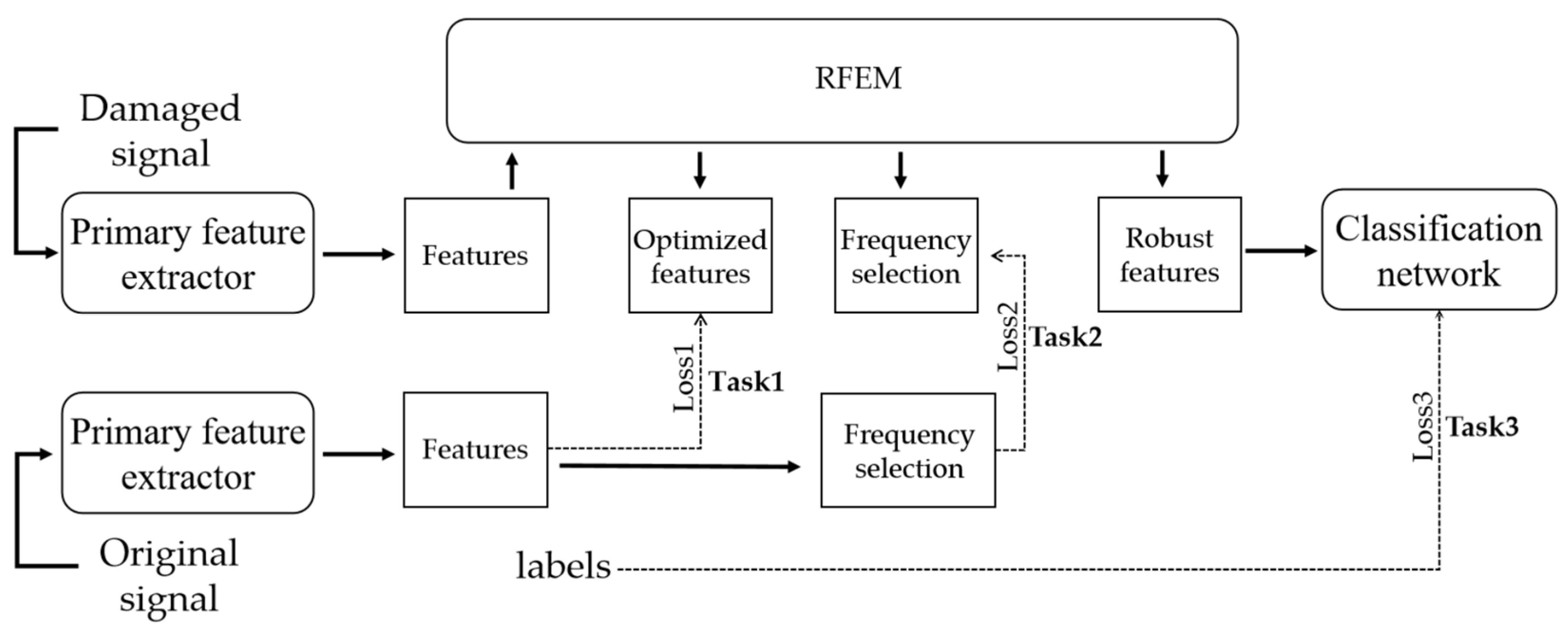
2.3. Training Method of RFEM-Based Recognition Systems
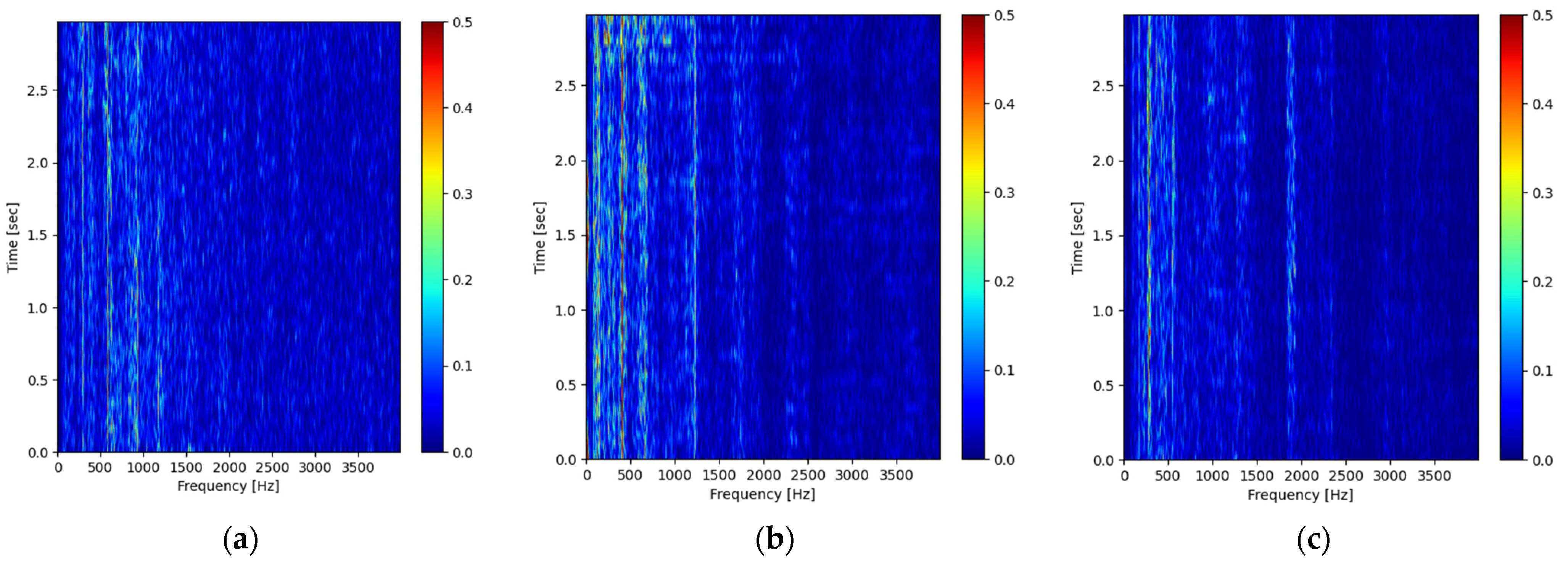
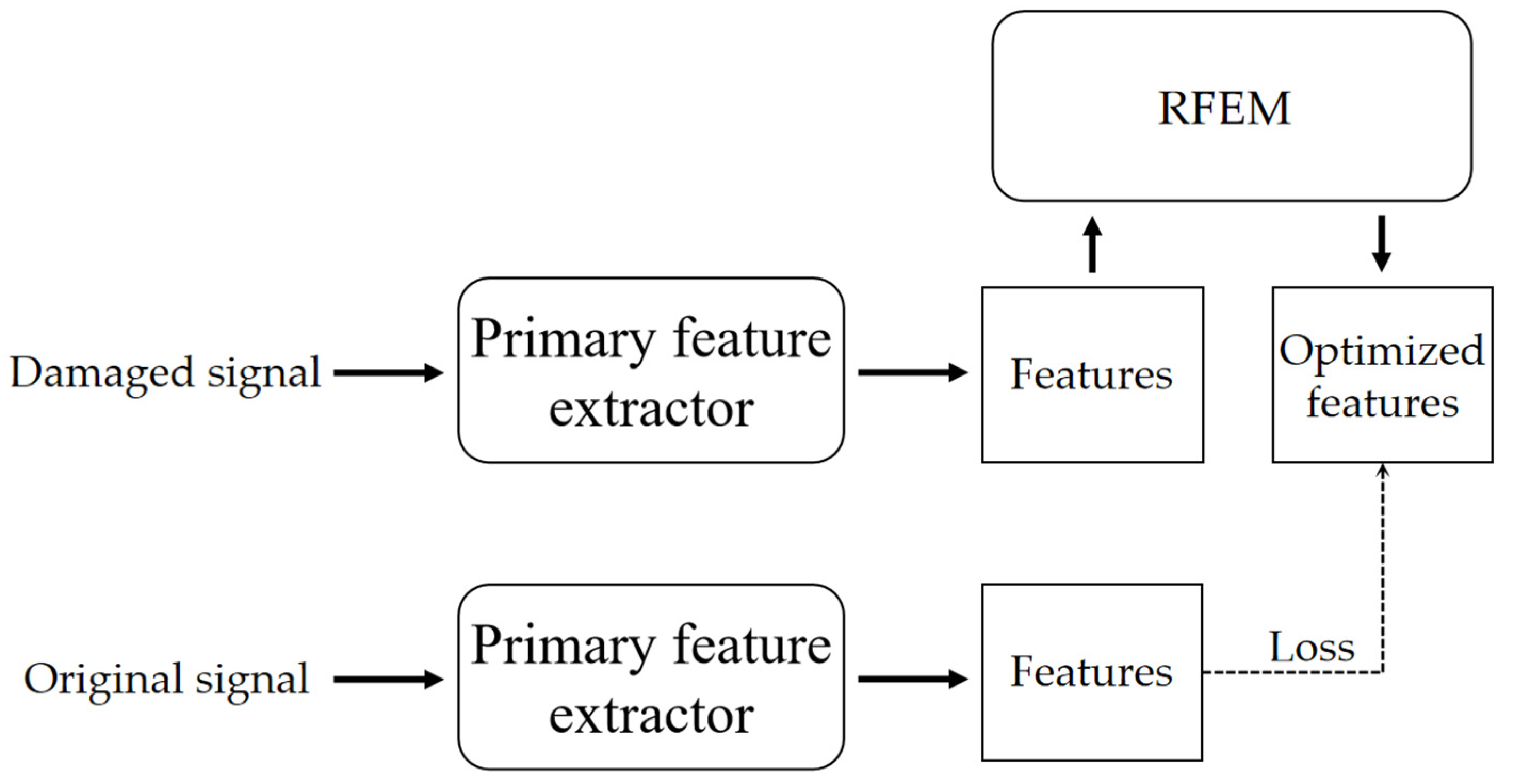
2.3.1. Anti-Noise Task
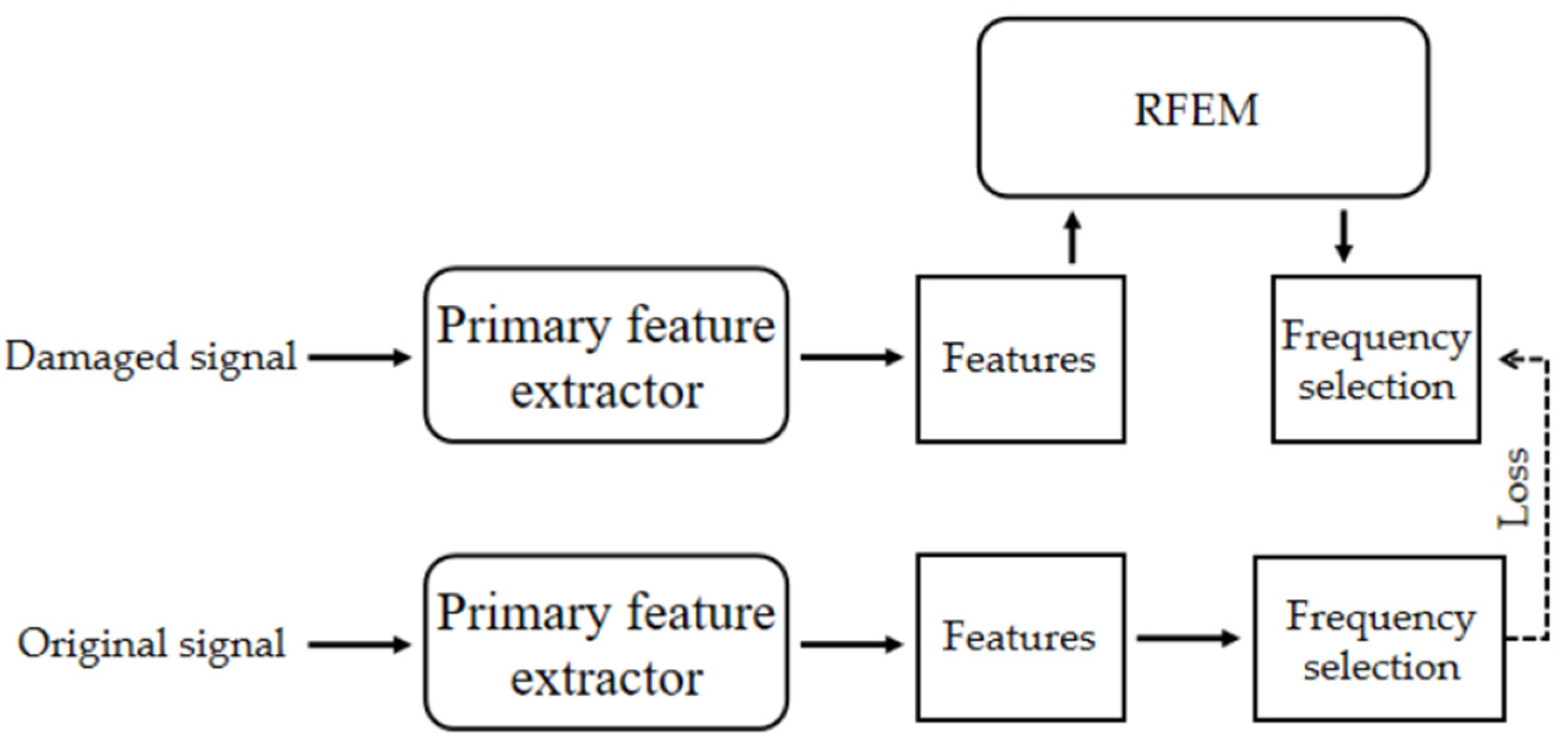
2.3.2. Optimized Frequency-Selection Task
2.3.3. Training Strategy and Loss Function
3. Experiments and Discussion
3.1. Experimental Dataset
3.2. Experimental Setup
3.3. Basic Experiment
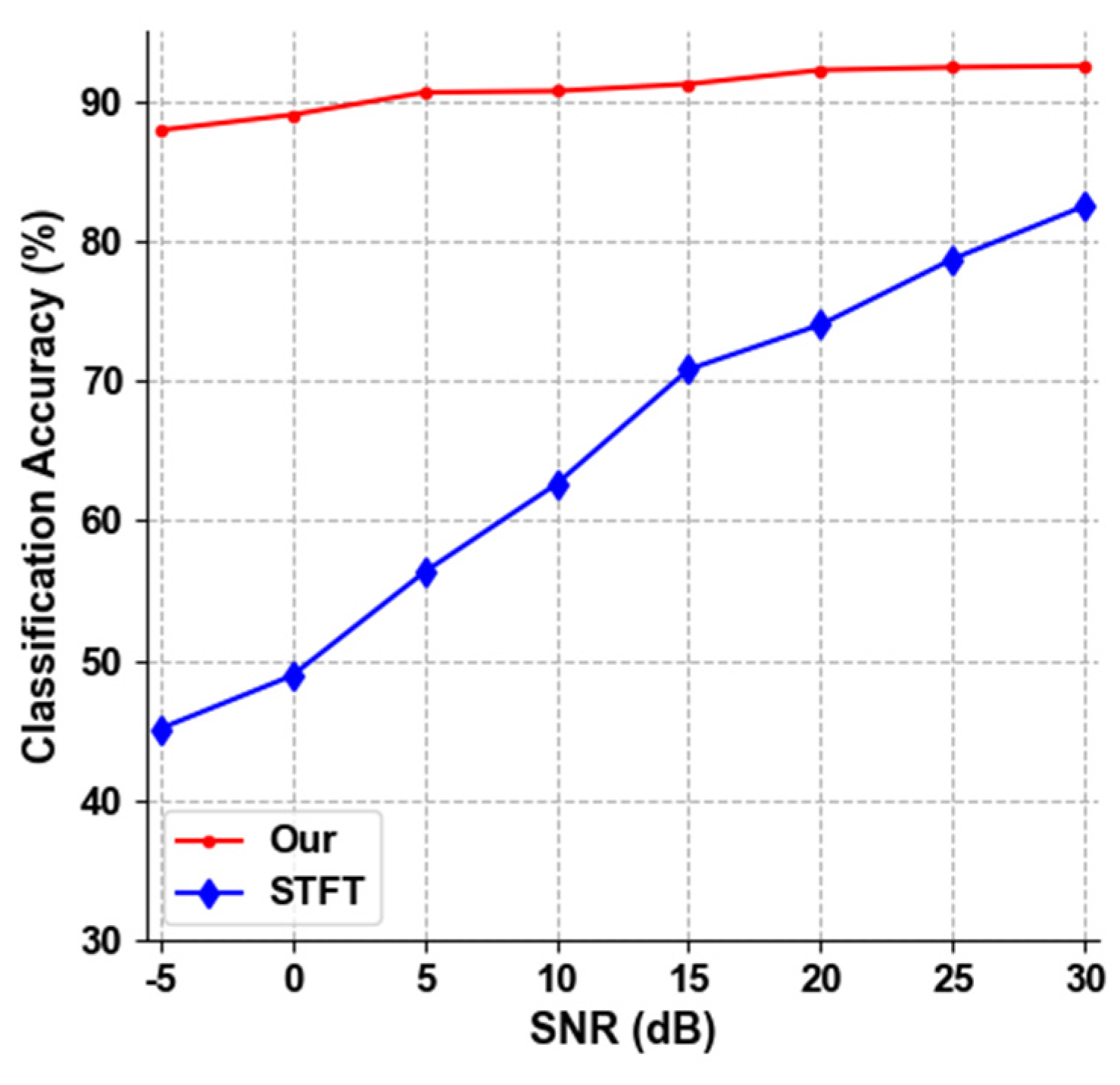
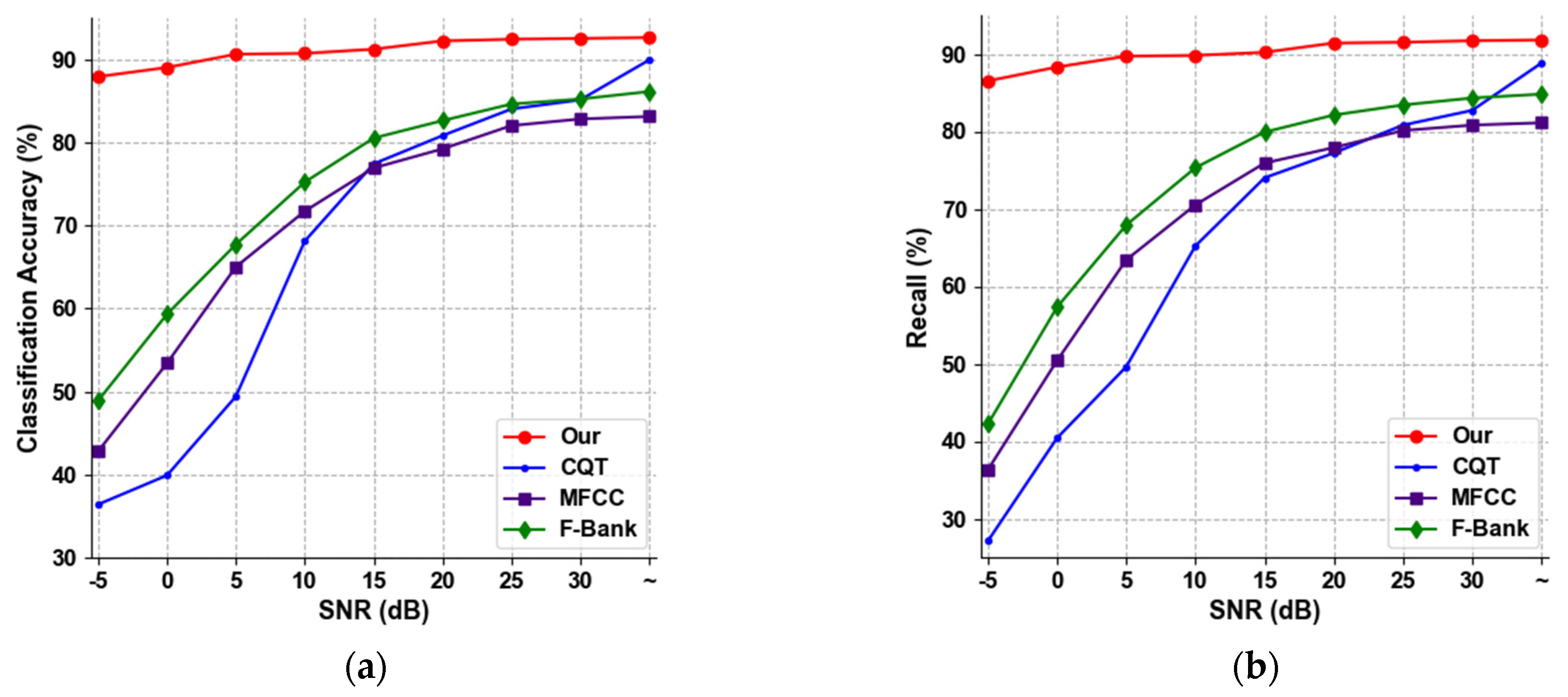
3.4. Comparison of Popular Feature-Based Methods
3.5. Comparison of Published Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S. A wave structure based method for recognition of marine acoustic target signals. J. Acoust. Soc. Am. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Rajagopal, R.; Sankaranarayanan, B.; Rao, P.R. Target classification in a passive sonar-an expert system ap-proach. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990. [Google Scholar]
- Boashash, B.; O’Shea, P. A methodology for detection and classification of some underwater acoustic signals using time-frequency analysis techniques. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1829–1841. [Google Scholar] [CrossRef] [Green Version]
- Ferguson, B. Time-frequency signal analysis of hydrophone data. IEEE J. Ocean. Eng. 1996, 21, 537–544. [Google Scholar] [CrossRef]
- Ou, H.; Allen, J.S.; Syrmos, V.L. Automatic classification of underwater targets using fuzzy-cluster-based wavelet signatures. J. Acoust. Soc. Am. 2009, 125, 2578. [Google Scholar] [CrossRef]
- Zeng, X.-Y.; Wang, S.-G. Bark-wavelet Analysis and Hilbert–Huang Transform for Underwater Target Recognition. Def. Technol. 2013, 9, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; He, Y.; Liu, Z.; Xiong, Y. Underwater Target Recognition Based on Line Spectrum and Support Vector Machine. In Proceedings of the 2014 International Conference on Mechatronics, Control and Electronic Engineering (MCE-14), Shenyang, China, 29–31 August 2014. [Google Scholar] [CrossRef] [Green Version]
- Jahromi, M.S.; Bagheri, V.; Rostami, H.; Keshavarz, A. Feature Extraction in Fractional Fourier Domain for Classification of Passive Sonar Signals. J. Signal Process. Syst. 2018, 91, 511–520. [Google Scholar] [CrossRef]
- Tucker, S. Auditory Analysis of Sonar Signals. Ph.D. Thesis, University of Sheffield, Sheffield, UK, 2001. [Google Scholar]
- Li-Xue, Y.; Ke-An, C.; Bing-Rui, Z.; Yong, L. Underwater acoustic target classification and auditory feature identification based on dissimilarity evaluation. Acta Phys. Sin. 2014, 63, 134304. [Google Scholar] [CrossRef]
- Wang, S.; Zeng, X. Robust underwater noise targets classification using auditory inspired time–frequency analysis. Appl. Acoust. 2014, 78, 68–76. [Google Scholar] [CrossRef]
- Mohankumar, K.; Supriya, M.H.; Pillai, P.S. Bispectral Gammatone Cepstral Coefficient based Neural Network Classifier. In Proceedings of the IEEE Underwater Technology, Chennai, India, 23–25 February 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sens. 2016, 2016, 7864213. [Google Scholar] [CrossRef] [Green Version]
- Niu, H.; Gong, Z.; Ozanich, E.; Gerstoft, P.; Wang, H.; Li, Z. Deep-learning source localization using multi-frequency magnitude-only data. J. Acoust. Soc. Am. 2019, 146, 211–222. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Niu, H.; Li, Z. A multi-task learning convolutional neural network for source localization in deep ocean. J. Acoust. Soc. Am. 2020, 148, 873–883. [Google Scholar] [CrossRef]
- Cao, H.; Wang, W.; Su, L.; Ni, H.; Gerstoft, P.; Ren, Q.; Ma, L. Deep transfer learning for underwater direction of arrival using one vector sensor. J. Acoust. Soc. Am. 2021, 149, 1699–1711. [Google Scholar] [CrossRef]
- Li, C.; Huang, Z.; Xu, J.; Yan, Y. Underwater target classification using deep learning. In OCEANS 2018 MTS/IEEE Charleston; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Oikarinen, T.; Srinivasan, K.; Meisner, O.; Hyman, J.B.; Parmar, S.; Fanucci-Kiss, A.; Desimone, R.; Landman, R.; Feng, G. Deep convolutional network for animal sound classification and source attribution using dual audio recordings. J. Acoust. Soc. Am. 2019, 145, 654–662. [Google Scholar] [CrossRef]
- Wang, X.; Liu, A.; Zhang, Y.; Xue, F. Underwater Acoustic Target Recognition: A Combination of Multi-Dimensional Fusion Features and Modified Deep Neural Network. Remote Sens. 2019, 11, 1888. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Togneri, R.; Zhang, X.; Yu, Y. Convolutional Neural Network with Second-Order Pooling for Underwater Target Classification. IEEE Sens. J. 2018, 19, 3058–3066. [Google Scholar] [CrossRef]
- Wang, N.; He, M.; Sun, J.; Wang, H.; Zhou, L.; Chu, C.; Chen, L. ia-PNCC: Noise Processing Method for Underwater Target Recognition Convolutional Neural Network. Comput. Mater. Contin. 2019, 58, 169–181. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Liu, Z.; Ren, J.; Wang, W.; Xu, J. A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification. Sensors 2020, 20, 5429. [Google Scholar] [CrossRef]
- Tian, S.; Chen, D.; Wang, H.; Liu, J. Deep convolution stack for waveform in underwater acoustic target recognition. Sci. Rep. 2021, 11, 9614. [Google Scholar] [CrossRef]
- Doan, V.-S.; Huynh-The, T.; Kim, D.-S. Underwater Acoustic Target Classification Based on Dense Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, Q.; Da, L.; Zhang, Y.; Hu, Y. Integrated neural networks based on feature fusion for underwater target recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar] [CrossRef]
- Luo, X.; Feng, Y.; Zhang, M. An Underwater Acoustic Target Recognition Method Based on Combined Feature with Automatic Coding and Reconstruction. IEEE Access 2021, 9, 63841–63854. [Google Scholar] [CrossRef]
- Ke, X.; Yuan, F.; Cheng, E. Underwater Acoustic Target Recognition Based on Supervised Feature-Separation Algorithm. Sensors 2018, 18, 4318. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. arXiv 2021, arXiv:2105.01601. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Li, P.; Wu, J.; Wang, Y.; Lan, Q.; Xiao, W. STM: Spectrogram Transformer Model for Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2022, 10, 1428. [Google Scholar] [CrossRef]
- Irfan, M.; Jiangbin, Z.; Ali, S.; Iqbal, M.; Masood, Z.; Hamid, U. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Syst. Appl. 2021, 183, 115270. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Liu, M.; Zhang, Y.; Zhang, B.; Xu, K.; Zou, B.; Huang, Z. Imbalanced Underwater Acoustic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network. Remote Sens. 2022, 14, 4103. [Google Scholar] [CrossRef]
- Escalera, S.; Pujol, O.; Radeva, P. Separability of ternary codes for sparse designs of error-correcting output codes. Pattern Recognit. Lett. 2009, 30, 285–297. [Google Scholar] [CrossRef]
- Wu, H.; Song, Q.; Jin, G. Deep Learning based Framework for Underwater Acoustic Signal Recognition and Classification. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 385–388. [Google Scholar] [CrossRef]
- Jiang, J.; Shi, T.; Huang, M.; Xiao, Z. Multi-scale spectral feature extraction for underwater acoustic target recognition. Measurement 2020, 166, 108227. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Targets |
|---|---|
| Class-A | Ocean noise |
| Class-B | Fishing boats, trawlers, mussel boats, tugboats and dredgers |
| Class-C | Motorboats, pilot boats, sailboats |
| Class-D | Passenger liners |
| Class-E | Ocean liners and Ro-Ro vessels |
| Model | STFT | Our |
|---|---|---|
| Precision | 0.874 | 0.923 |
| Recall | 0.862 | 0.918 |
| F1-score | 0.867 | 0.920 |
| Accuracy | 0.875 | 0.926 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Liu, F.; Shen, T.; Chen, L.; Zhao, D. A Robust Feature Extraction Method for Underwater Acoustic Target Recognition Based on Multi-Task Learning. Electronics 2023, 12, 1708. https://doi.org/10.3390/electronics12071708
Li D, Liu F, Shen T, Chen L, Zhao D. A Robust Feature Extraction Method for Underwater Acoustic Target Recognition Based on Multi-Task Learning. Electronics. 2023; 12(7):1708. https://doi.org/10.3390/electronics12071708
Chicago/Turabian StyleLi, Daihui, Feng Liu, Tongsheng Shen, Liang Chen, and Dexin Zhao. 2023. "A Robust Feature Extraction Method for Underwater Acoustic Target Recognition Based on Multi-Task Learning" Electronics 12, no. 7: 1708. https://doi.org/10.3390/electronics12071708