1. Introduction
Since the outbreak of the novel coronavirus in 2019, COVID-19 has become the most widely infected and longest-lasting epidemic disease in the world. There is an incubation period in the initial stage of the virus infection, and there is no obvious infection symptom during the incubation period. If COVID-19 is found, it is basically confirmed. There are still some difficulties in the diagnosis of the virus. Even if the patients show strong symptoms, the nucleic acid test report cannot completely exclude the prevalence of COVID-19 [
1]. The method based on artificial recognition depends on the experience of doctors. The lesion features that can be observed by the naked eye are combined. It leads to the fact thatthe accuracy depends on the subjective judgment of doctors. Therefore, it is necessary to use artificial intelligence (AI) to diagnose COVID-19. Several artificial intelligence, machine learning, and deep learning techniques have been deployed in medical image processing in the context of the COVID-19 disease [
2]. Lorenzo Famiglini [
3] created four models. These may help doctors make better decisions during the care and treatment of patients. M. Raihan [
4] solved the problem of class imbalances of COVID-19 datasets using the Adaptive Synthetic (ADASYN) algorithm. Heidari, A. [
5] extensively evaluated the existing challenges related to AI methods. The necessity of the AI method in the recognition of COVID-19 was emphasized. Ali Bou Nassif [
6] focused mainly on the role of the speech signal and/or image processing in detecting the presence of COVID-19. Three types of experiments were conducted utilizing speech-based, image-based, and speech- and image-based models.
Deep learning (DL) can learn high-level features from a large amount of data adaptively. DL is the most widely used in the field of AI. The features of autonomous learning of deep learning are utilized [
7]. A large number of features in medical images are extracted adaptively in batches, which can effectively implement classification tasks. DL overcomes the limitations of a strong subjectivity and the insufficient observation of features in artificial recognition. A DL-based model is a good method forimage classification and object recognition tasks. At present, there are mainly two datasets of X-ray images and CT images for COVID-19 identification. Ye Qinghao [
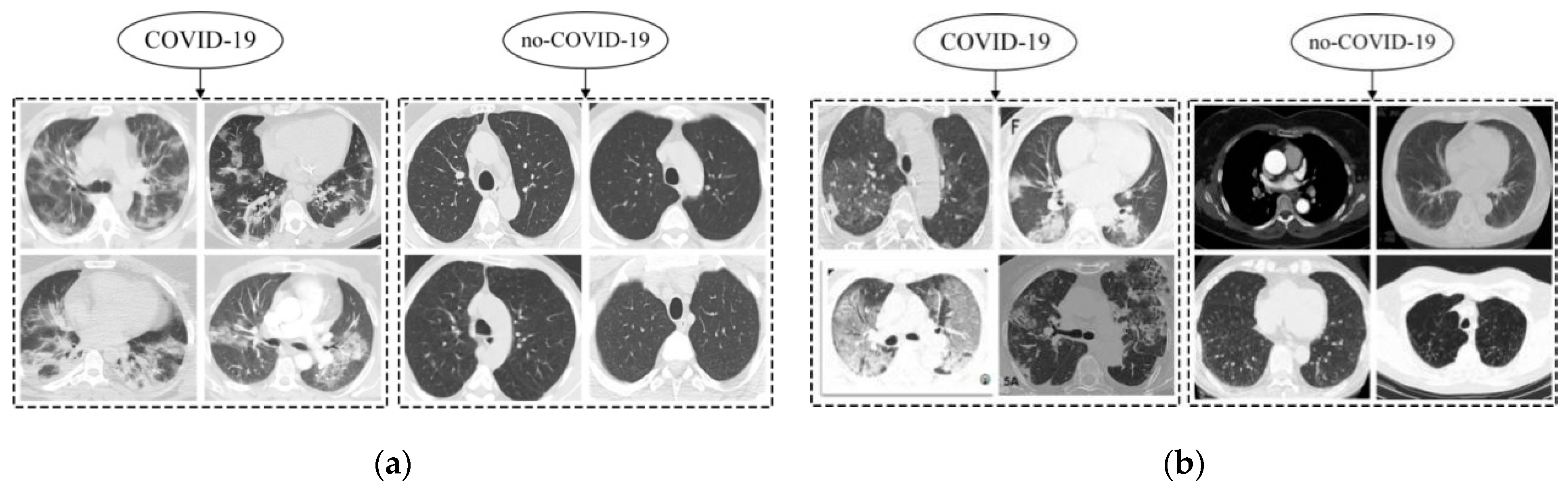
8] pointed out that computed tomography (CT) can detect features such as lung turbidity, consolidation, and pulmonary fibrosis caused by GGO, which is an important tool for the pre-screening and early diagnosis of COVID-19 patients. Song LiPing [
9] extracted low-level features of CT images using depth learning. Then, the diagnosis of COVID-19 was carried out by constructing a fuzzy classifier. The algorithm hoped to detect infected objects by observing and analyzing the CT images of suspected patients. It showed that the use of CT images plays a key role in the diagnosis of COVID-19. Kang Bo [
10] proposed a method to support supercomputing to build an auxiliary system for the comprehensive analysis of COVID-19 CT images. It showed that a lung CT image is one of the main bases for screening for COVID-19. Therefore, the recognition of COVID-19 based on CT images is more accurate and efficient.
The problem of gradient disappearance in the deep network is solved by the residual neural network (ResNet) [
11]. It has the advantages of being a simple network structure and having modularization. In this study, ResNet was selected as the basic network for improvement. At present, ResNet is a hot spot of deep learning and has also obtainedgood achievements in medical image processing. The auxiliary diagnosis of COVID-19 from CT images based on the ResNet model was successfully applied. Zhou [
12] had an in-depth discussion on the integrated deep learning model of COVID-19 CT images. They showed that CT detection is one of the diagnostic criteria for COVID-19 and is of great significance for the treatment of COVID-19. Mamalakis M [
13] proposed a new deep transfer learning model, DenResCov-19. The DenResCov-19 model can diagnose COVID-19, pneumonia, tuberculosis, or healthy patients according to CXR images. Minaee S [
14] used the method based on transfer learning to classify COVID-19 and normal chest images using ResNet18, ResNet50, DenseNet-121 [
15], and other models.
Although the ResNet model has made good achievements in the field of medical image classification, there are still some problems with the recognition of COVID-19 CT images. The lesion size of COVID-19 is smaller, the lesion shape of COVID-19 is more complex, and the lesion tissue of COVID-19 is less different from the normal. It is difficult to extract features of COVID-19 from CT images. The modelhas a difficult time focusing on the lesion area of COVID-19, which brings great challenges to the construction of the classification model [
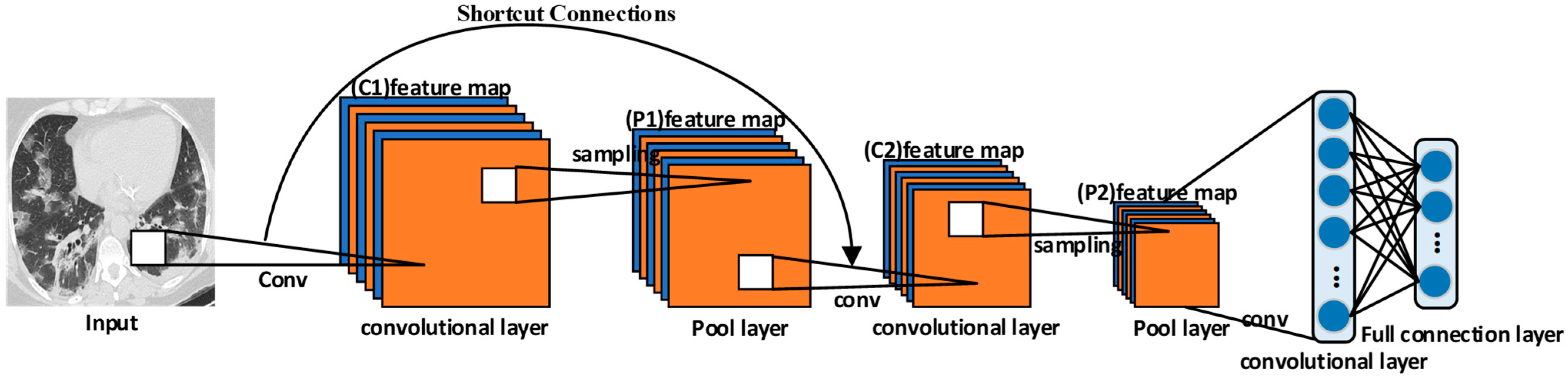
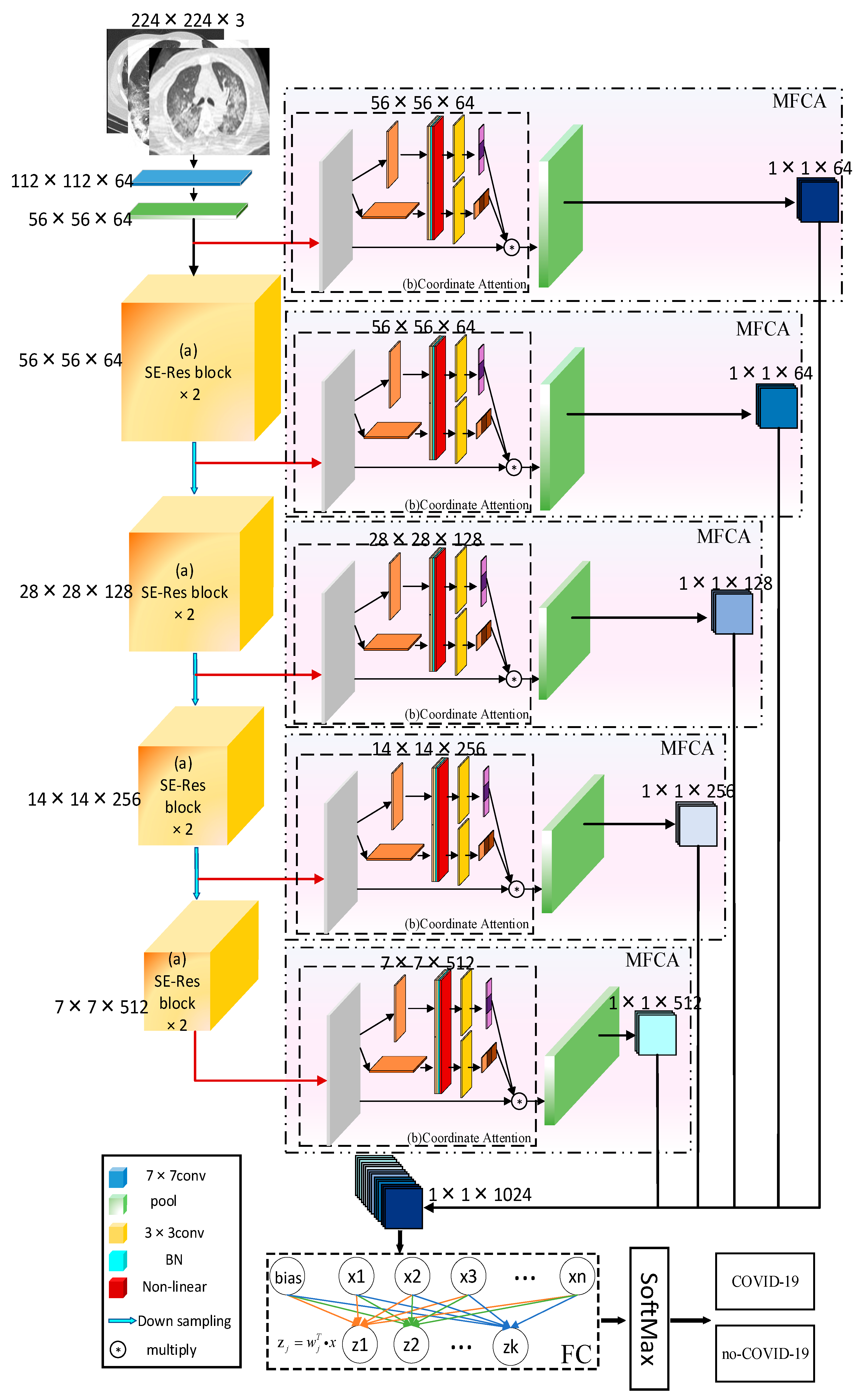
16]. In order to solve these problems, a multilevel feature aggregation attention surplus network model based on ResNet, COVID-ResNet, was proposed. It was used to classify chest CT images and diagnose whether patients were infected with COVID-19. In this study, the main contributions include the following two aspects.
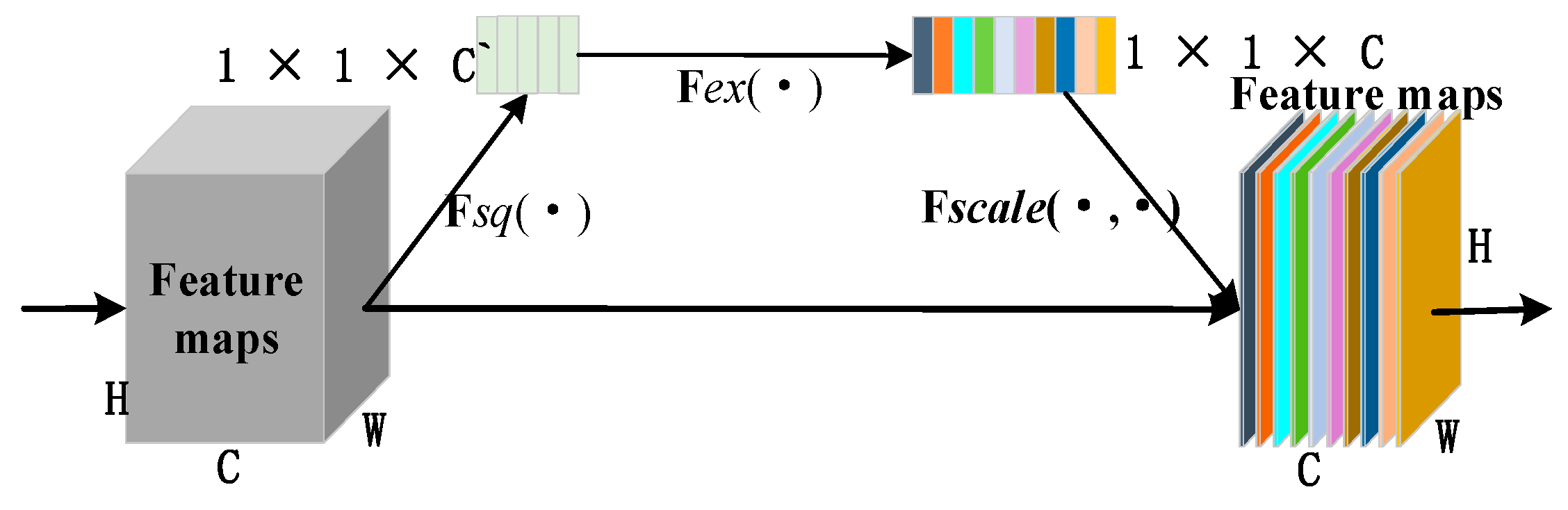
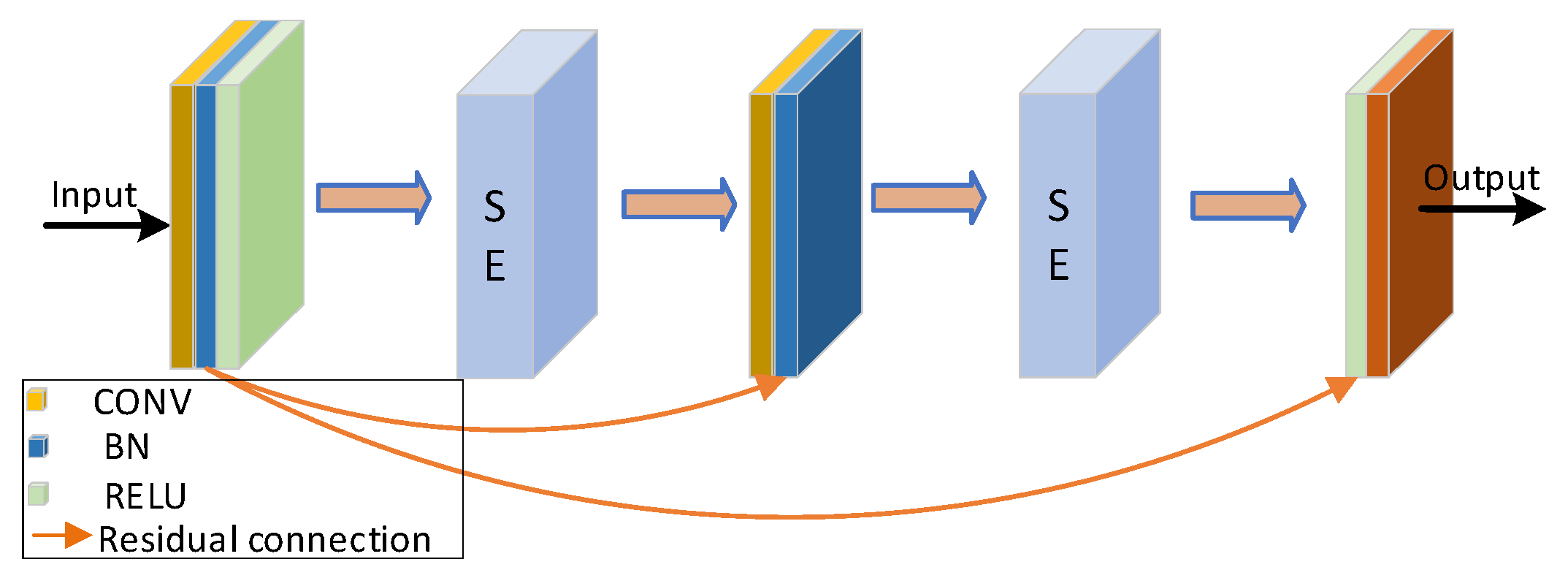
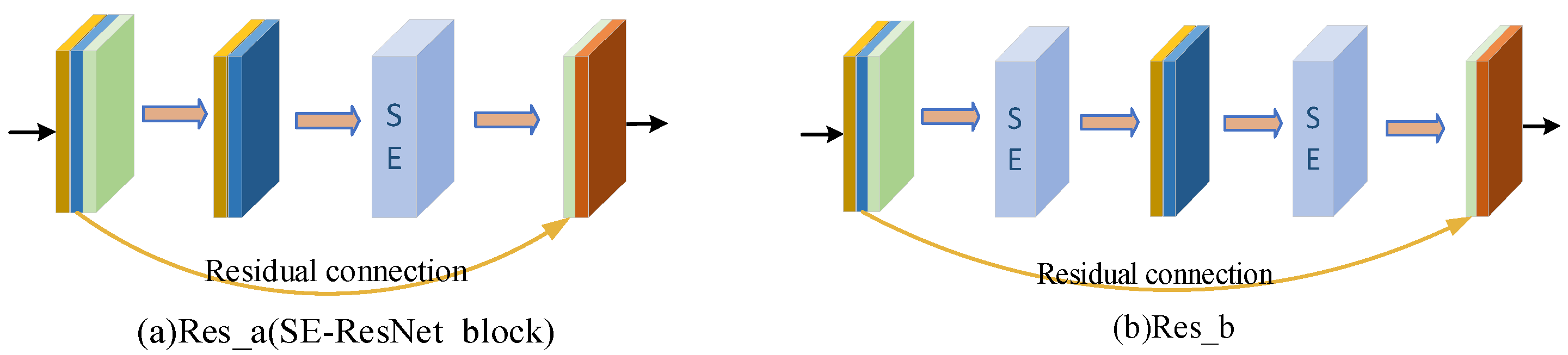
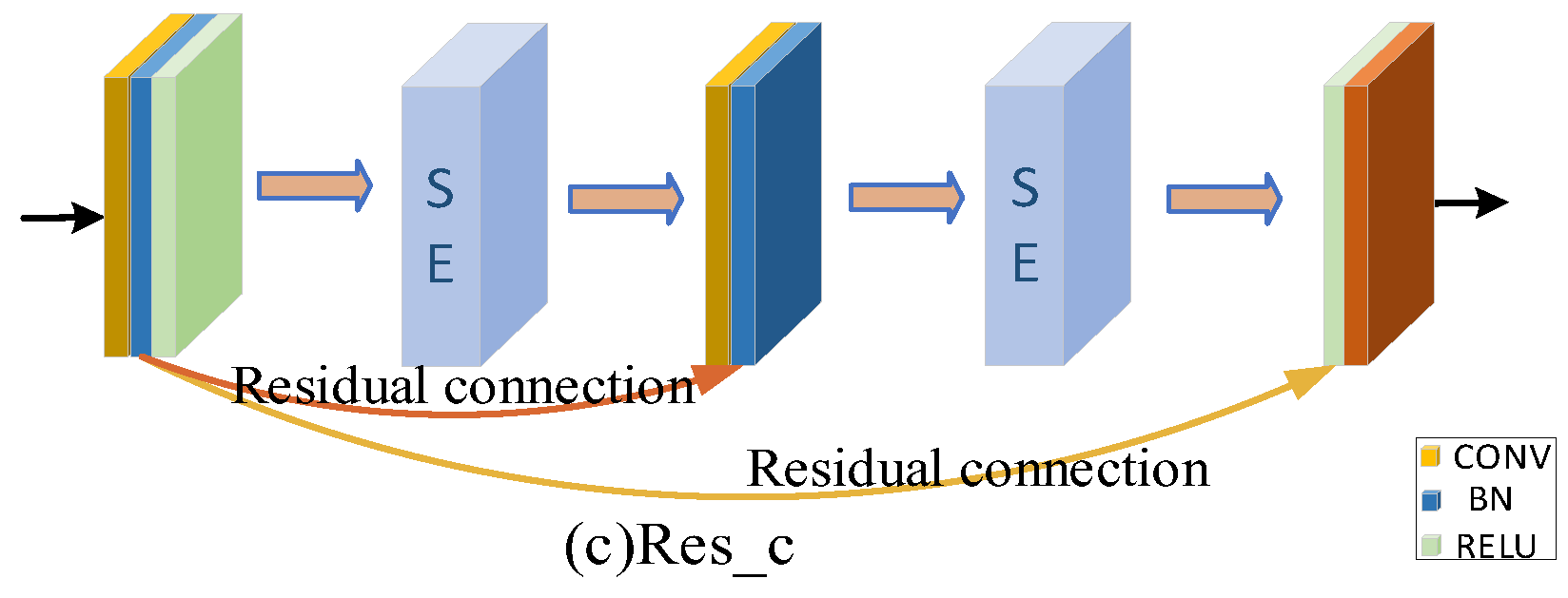
Firstly, according to the analysis of the sample characteristics, the samples with correct classification were more focused on the lesion area. The samples with the wrong classification were more focused on the background or other areas. In order to further improve the screening ability of the network for channels of the feature map, we focused on channels that had more information about the lesion area. The extrusion excitation module was introduced into the residual block and the residual connection was added. We focused on the high response channel of COVID-19 to improve the robustness of the model.
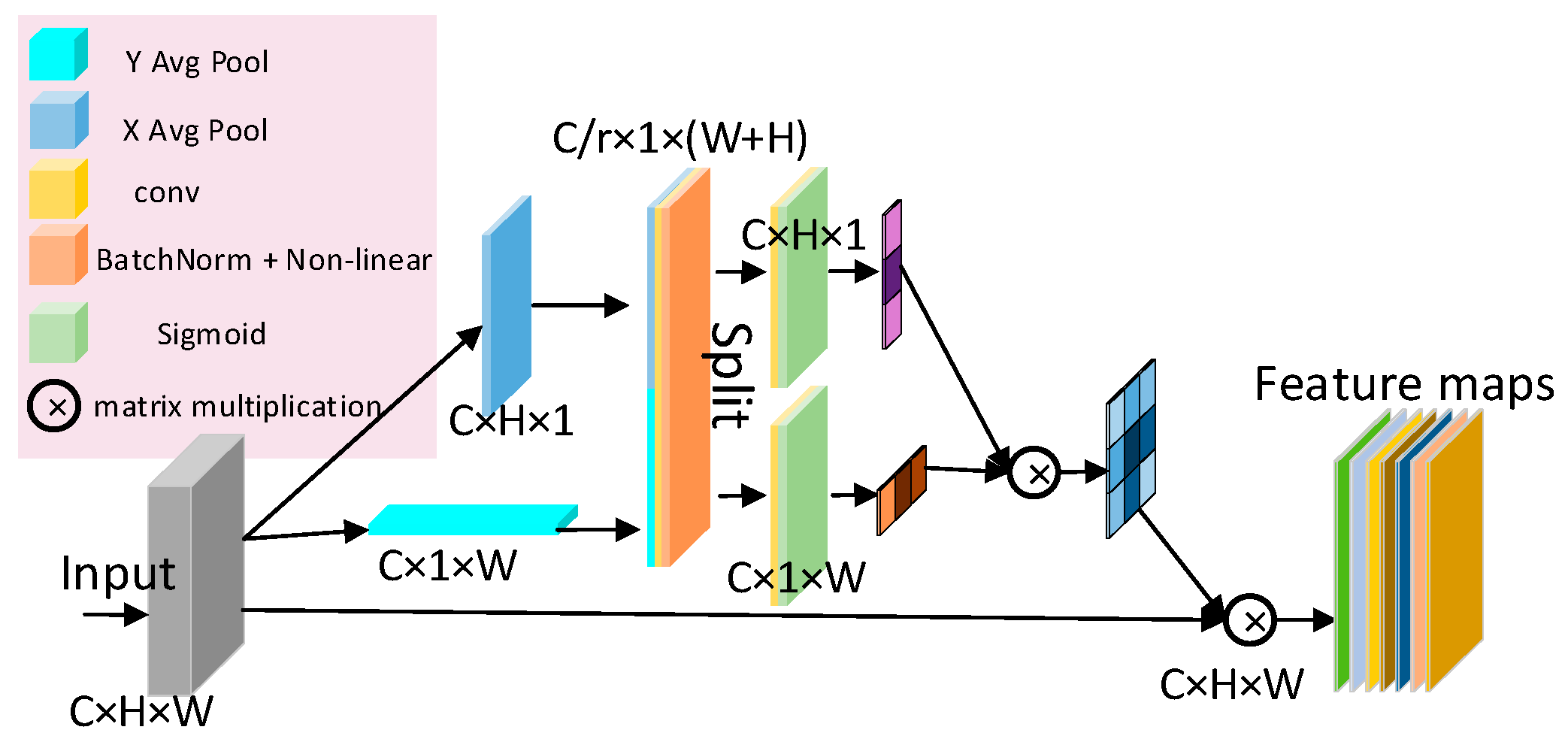
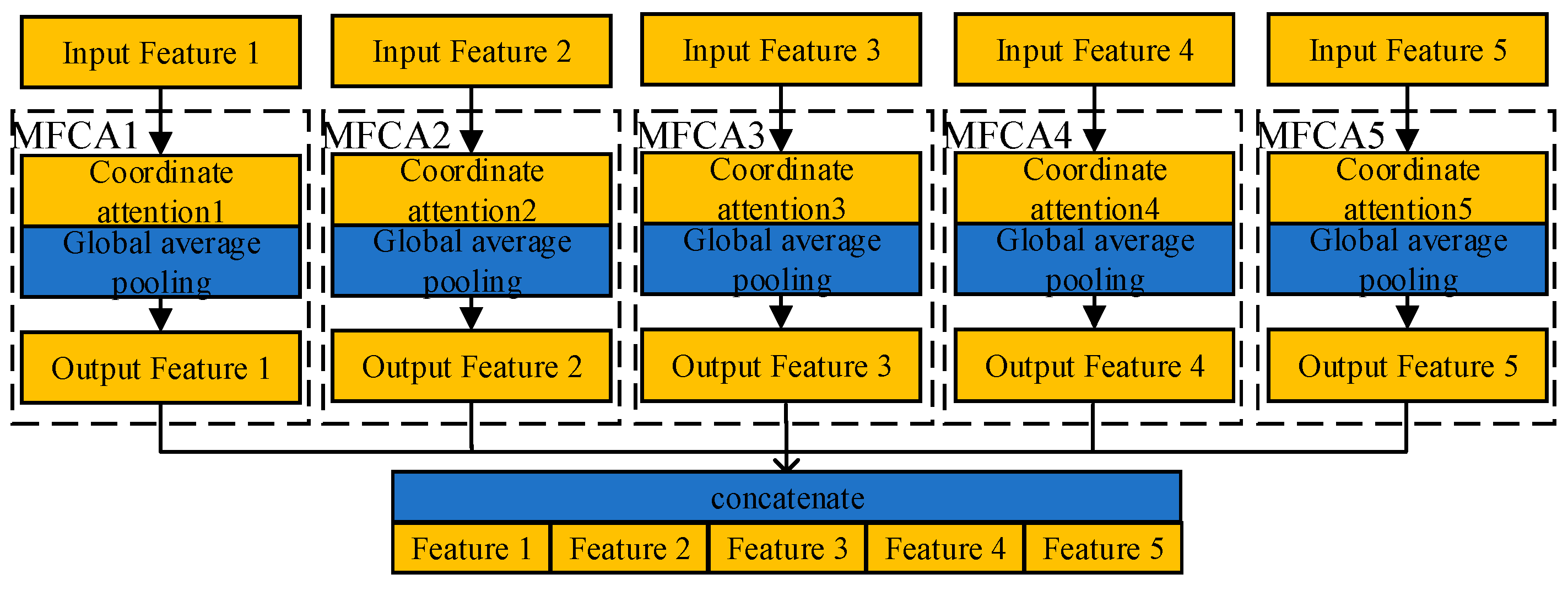
Secondly, most of the lesion areas in the CT images of COVID-19 were widely distributed structures. Deep learning was not enough for the direction feature extraction when featuring extraction. For this reason, a Multi-layer Feature Converge Attention (MFCA) module was proposed. It focused on the direction feature of the COVID-19 lesion area with coordinated attention and enhanced the extraction ability of focus features. It input the features of different levels into the deep layer and gathered the shallow features and deep features. It realized information complementation and avoided overfitting.
The work was organized as follows:
Section 2 sketches the structure of ResNet and introduces the COVID-ResNet and all its internal components.
Section 3 describes various experiments and ablation experiments for different COVID-19 screening tasks. Results and their discussion are presented in
Section 4. Conclusions and future work are presented in
Section 5.
4. Discussion
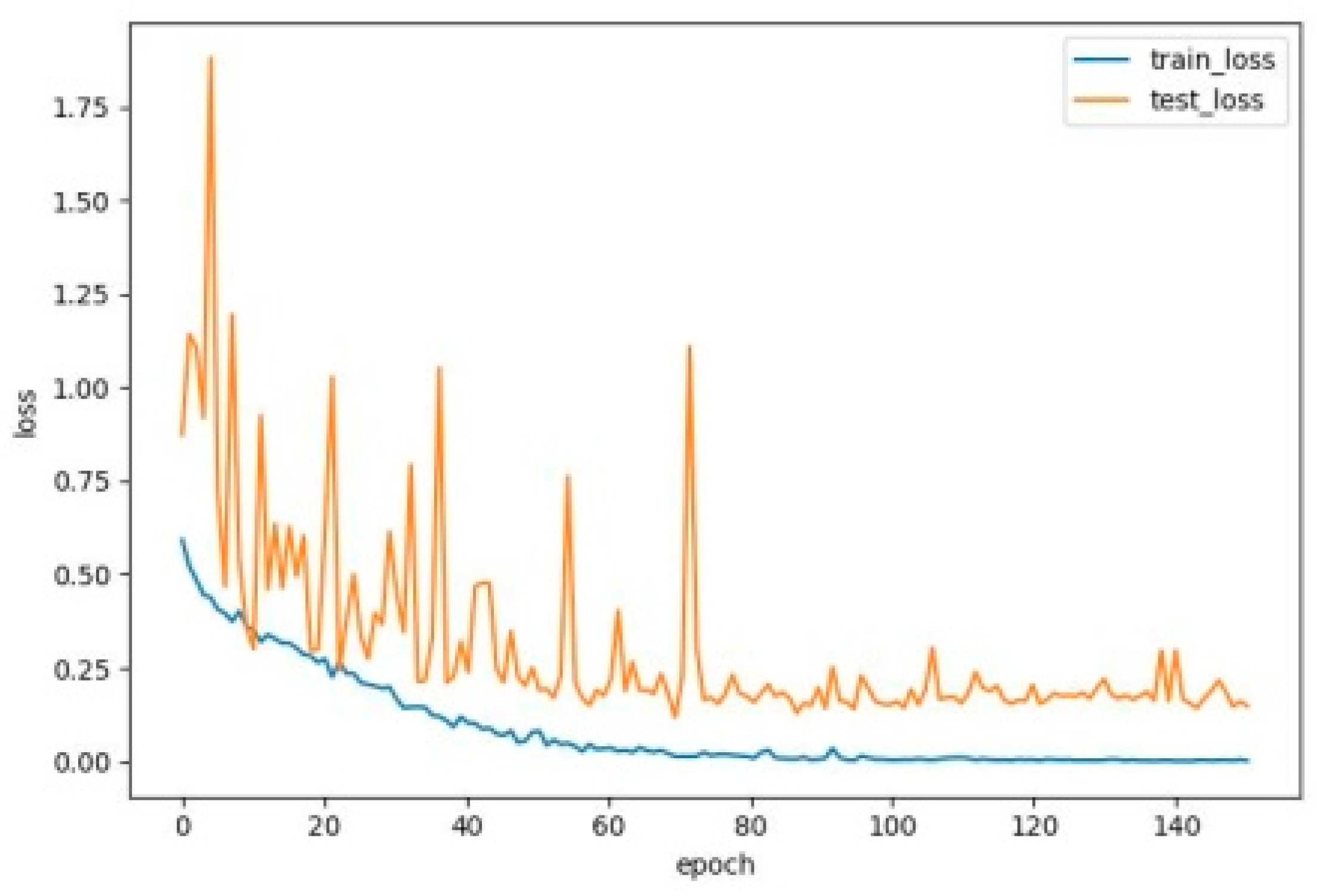
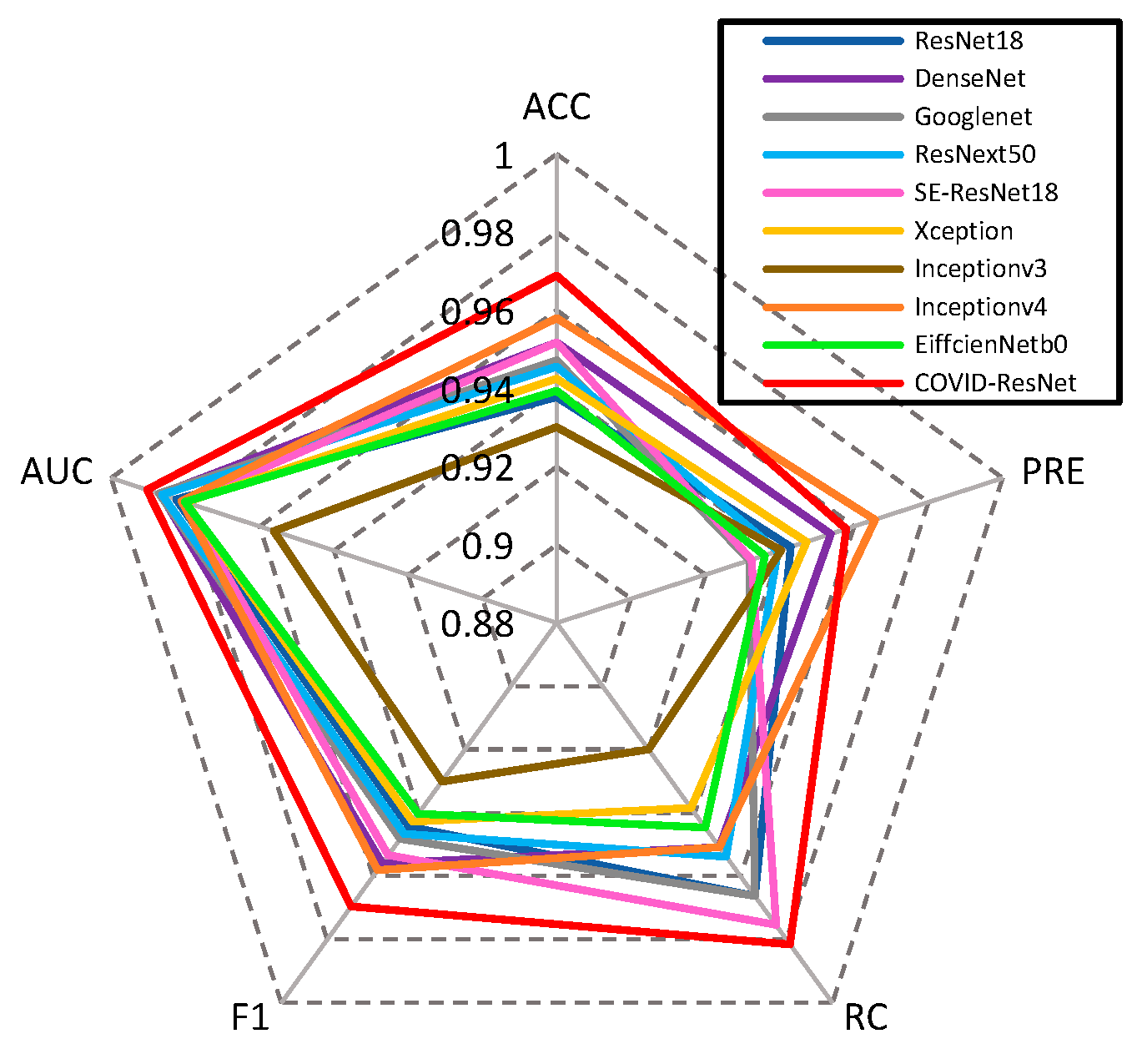
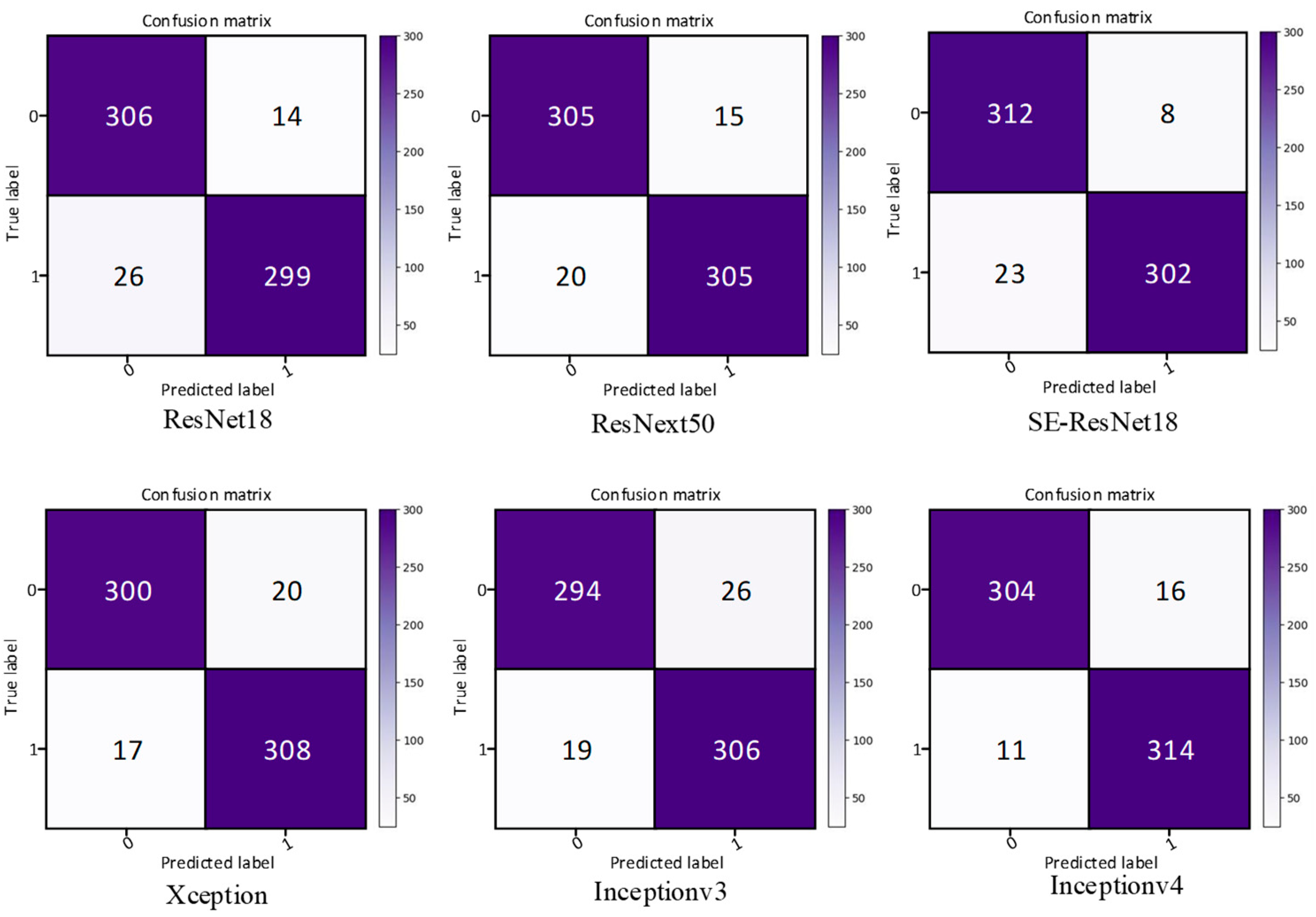
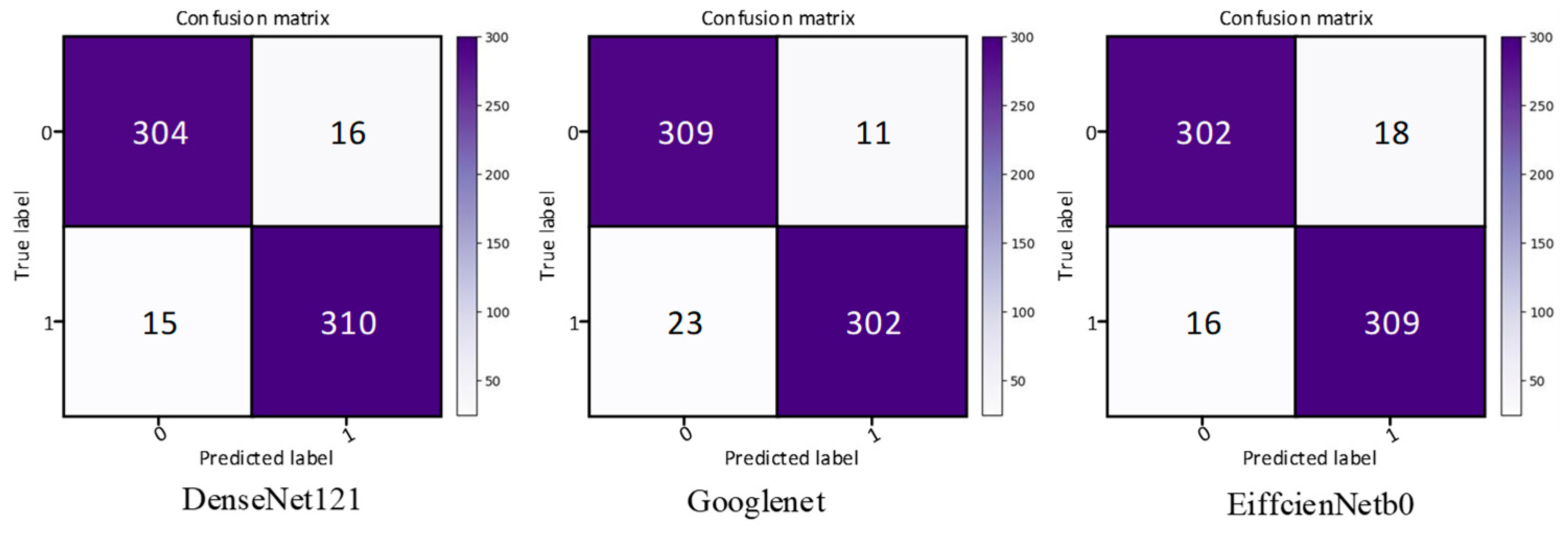
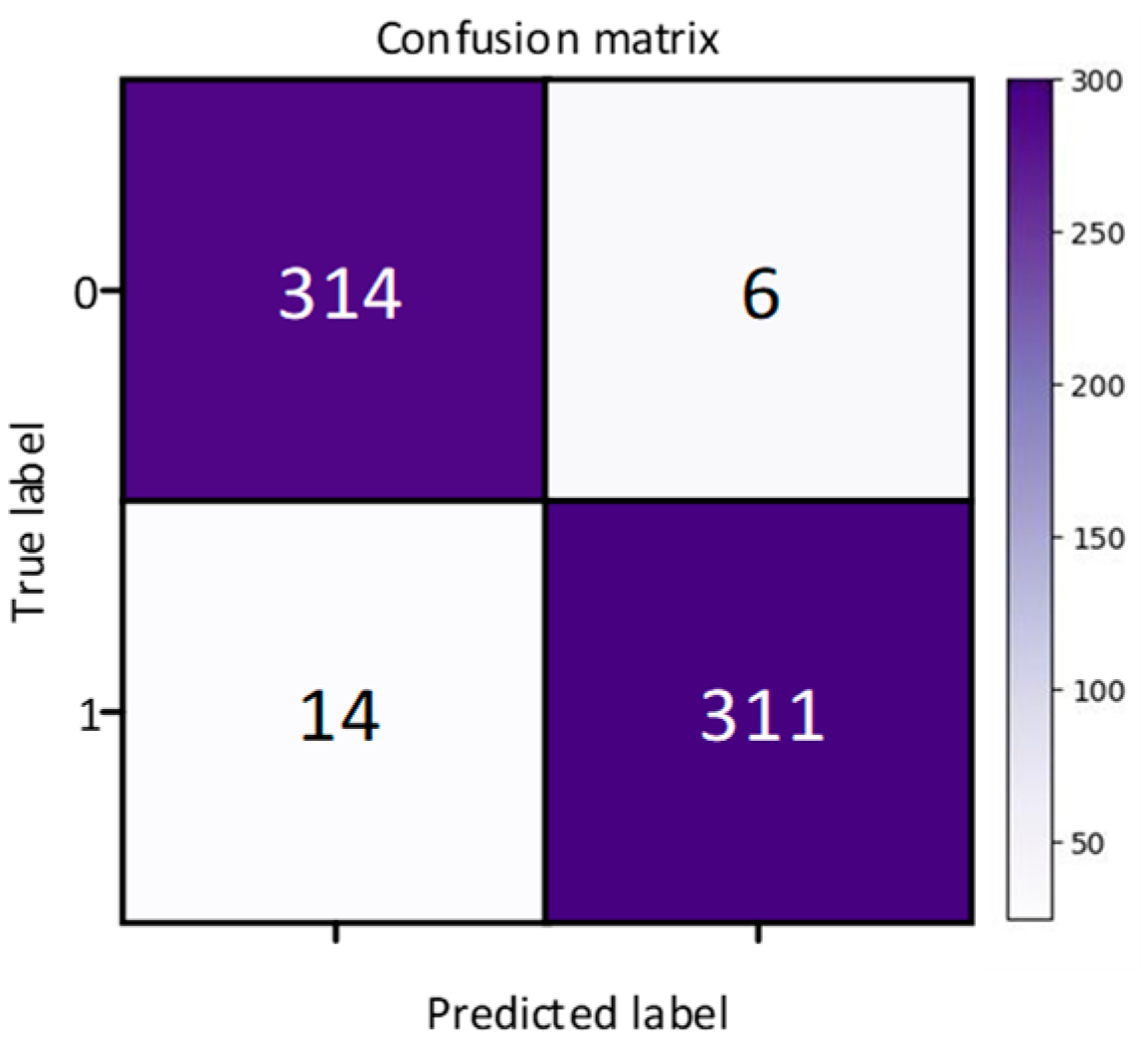
In order to solve the problem of computer aided diagnosis, a CT image diagnosis model based on improved attention ResNet was proposed. Firstly, the SE block was introduced into the residual neural network based on the semantic correlation of features with different channels of COVID-19 CT images. It improved the ability of the network to filter channels, so as to focus on the highly responsive channels of COVID-19. Secondly, in order to extract the directional features of COVID-19, the coordinated attention was introduced to improve the recognition ability of lesion features. Then, the MFCA module was proposed. The MFCA module transferred the features extracted from multiple coordinates into the deep layer for multilevel feature aggregation to make up for the feature loss caused by downsampling. It made the information complementary and further improved the recognition effect. Finally, the features were classified to identify whether they were infected with COVID-19. The COVID-ResNet was used to classify and recognize the CT image dataset of COVID-19. The accuracy, recall rate, F1 score, and AUC value could reach 96.89%, 98.15%,96.96%, and 99.04%, separately. The experimental results showed that the performance of COVID-ResNet was better than similar networks. The results of ablation experiments showed that the accuracy of recognition could be greatly improved by adding the SE block and coordinate attention model. At the same time, the combination of deep features and shallow features for information complementation could significantly improve the recognition rate. The classification based on the CT image dataset of COVID-19 had certain clinical application value for aiding the diagnosis of COVID-19. COVID-ResNet can effectively assist doctors with identifying COVID-19, improve doctors’ work efficiency, and reduce misdiagnosis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















