
Locality-Sensitive Hashing of Soft Biometrics for Efficient Face Image Database Search and Retrieval

Abstract
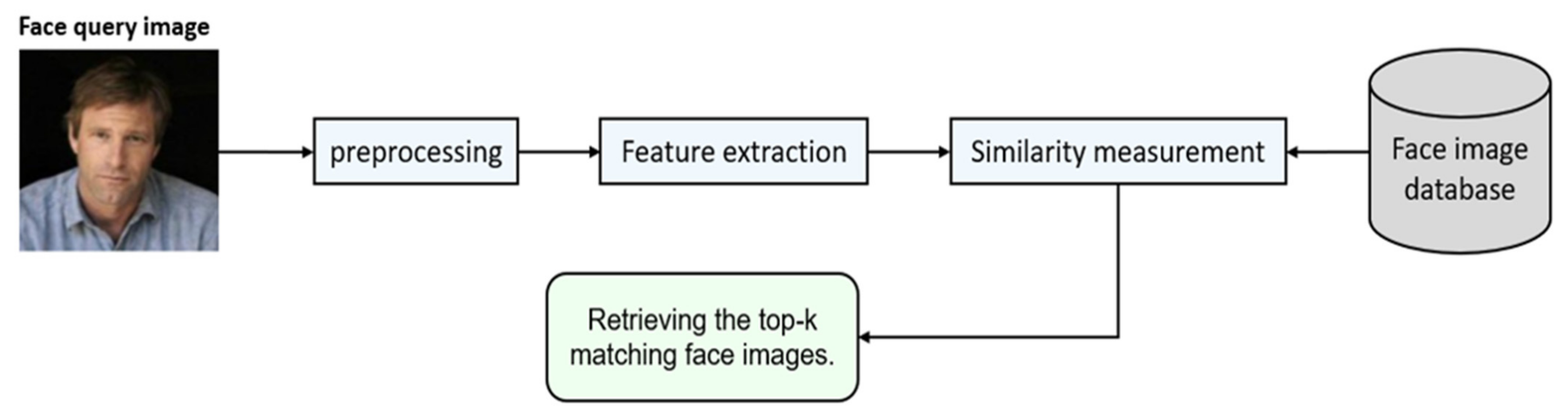
:1. Introduction
2. Literature Review
2.1. Traditional Face Image Retrieval
2.2. Hash Techniques for Biometric Recognition and Retrieval
2.3. Face Image Retrieval Using Face Soft Biometrics
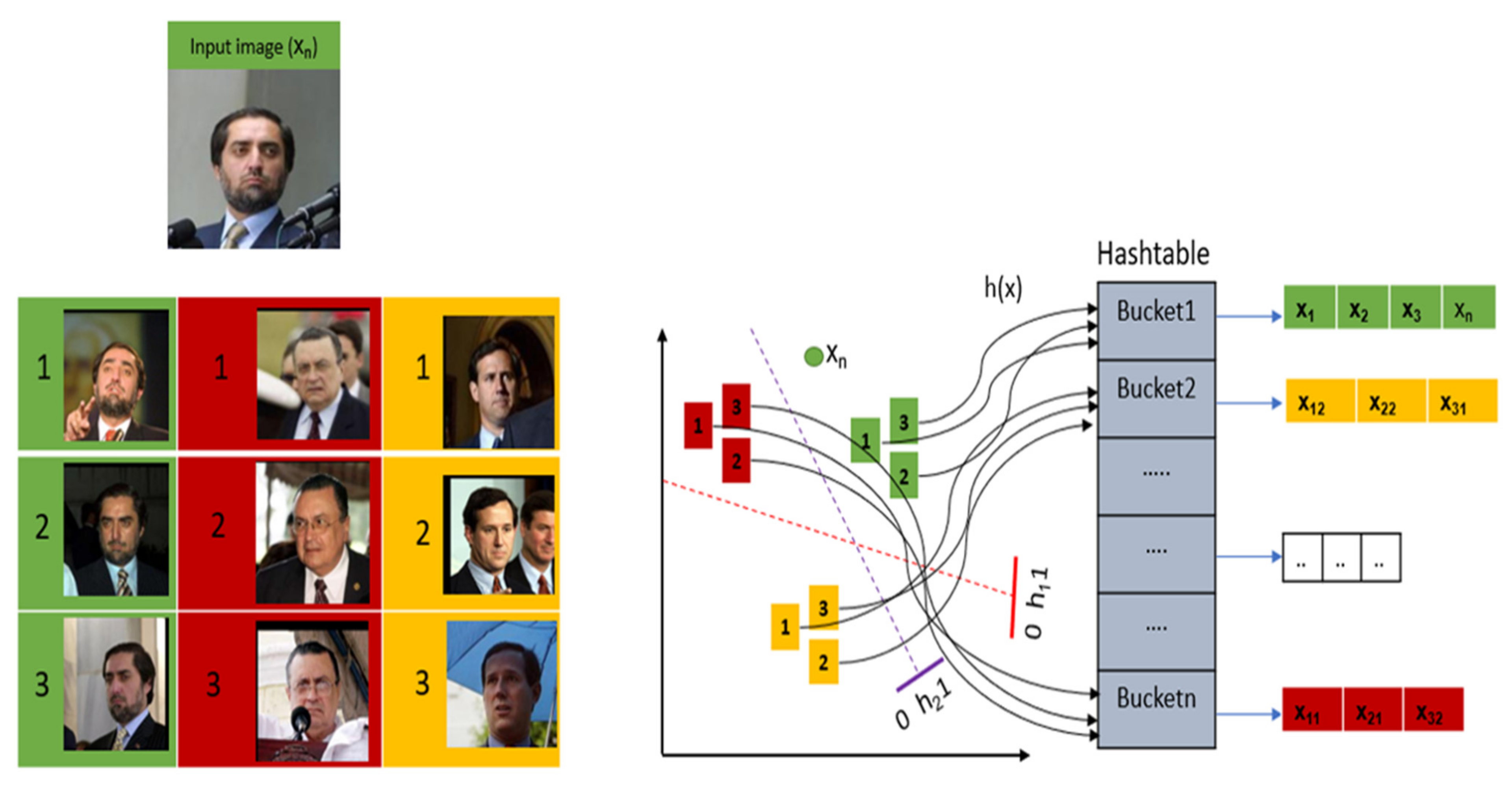
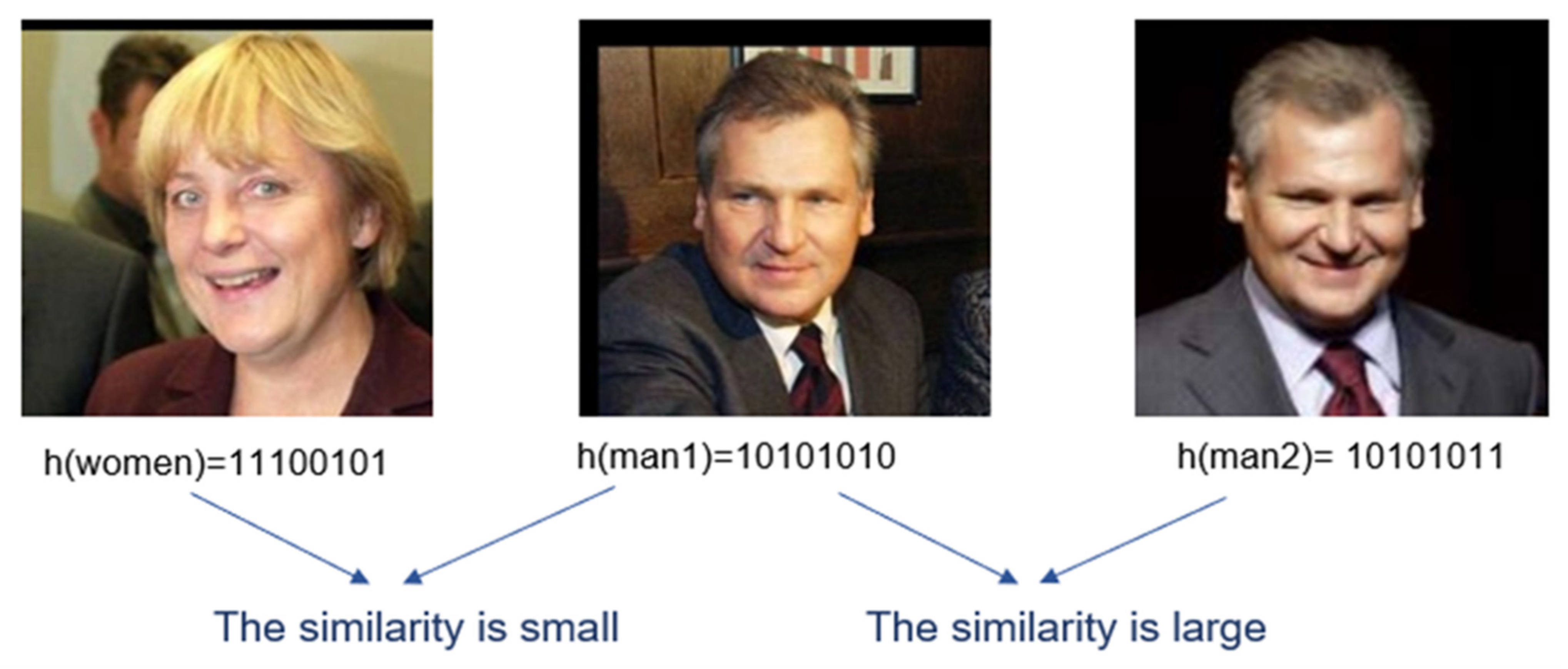
3. Locality-Sensitive Hashing Technique
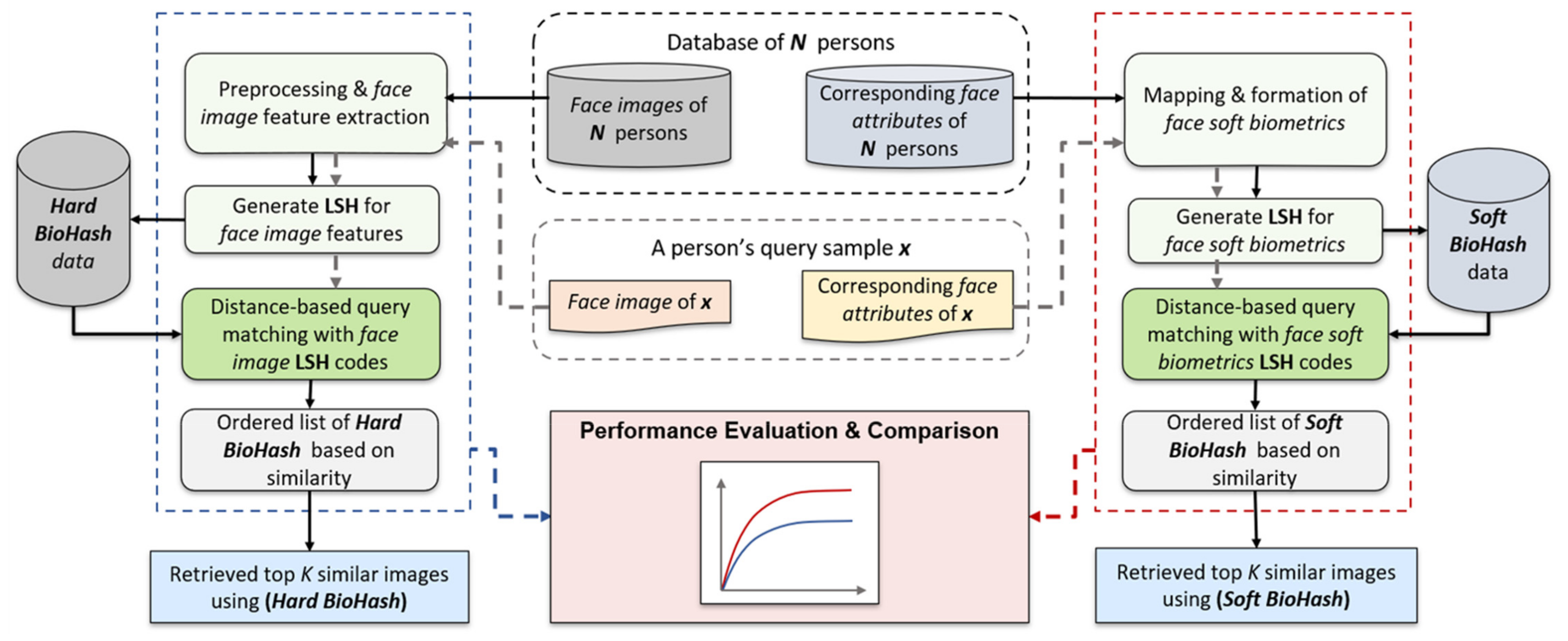
4. Methodology
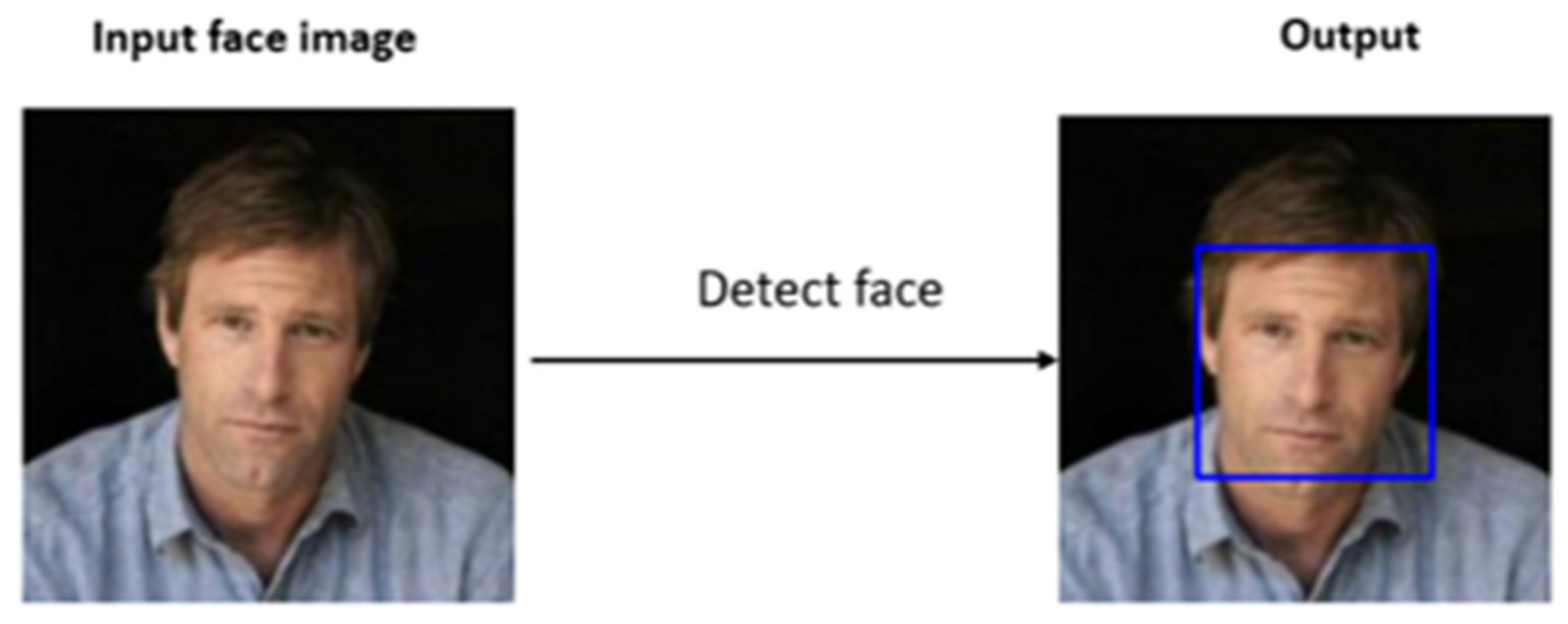
4.1. Data Preprocessing
4.2. Feature Extraction and Hash Generation
4.3. Distance Metric to Retrieve Similar Images
4.4. Performance Evaluation
- Accuracy: The accuracy of a retrieval strategy is a statistical measure of how well it accurately recovers or eliminates a condition, such that it is the proportion of true results (including true positives (TP) and true negatives (TN)) out of the total number of tests run, where (FP) and (FN) denote false positive and false negative, respectively. The accuracy can be computed as follows:
- Precision: This is a metric for a retrieval technique’s ability to positively search and retrieve the correct face image rather than the incorrect one and is defined as follows:
- Recall: This is a metric that measures a retrieval technique’s ability to positively retrieve the proper facial image all the time, and it is defined as follows:
- F1-Score: When precision and recall are both equally weighted, the F1-Score is calculated as follows:
- Execution time (retrieval time): This is a measurement of the average time required by a technique for retrieval. We measure the retrieval time according to the number of retrieved images.
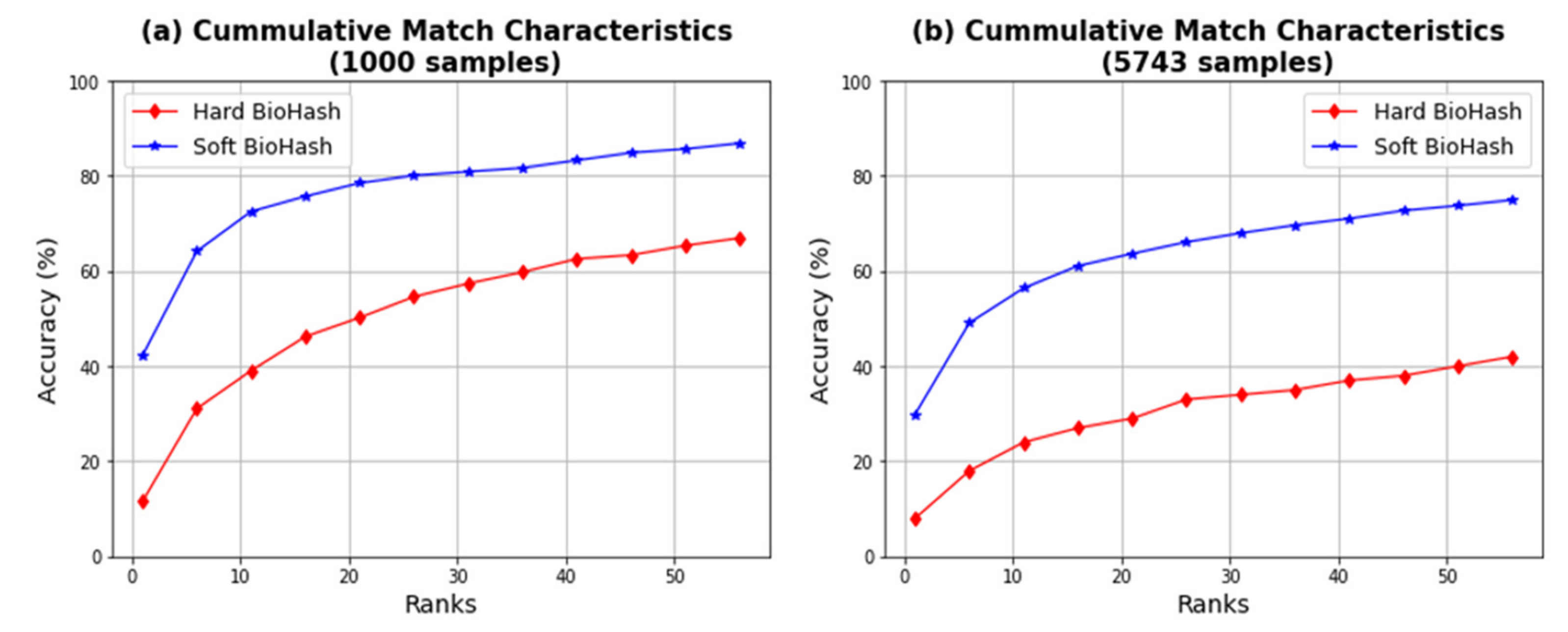
- Cumulative match characteristic (CMC): The CMC curve is a statistic for evaluating the success of a biometric identification algorithm based on each rank’s precision. Subsequently, identification performance is determined based on the relative ordering of match scores.
5. Experimental Results and Analysis
5.1. Face Image Database Description
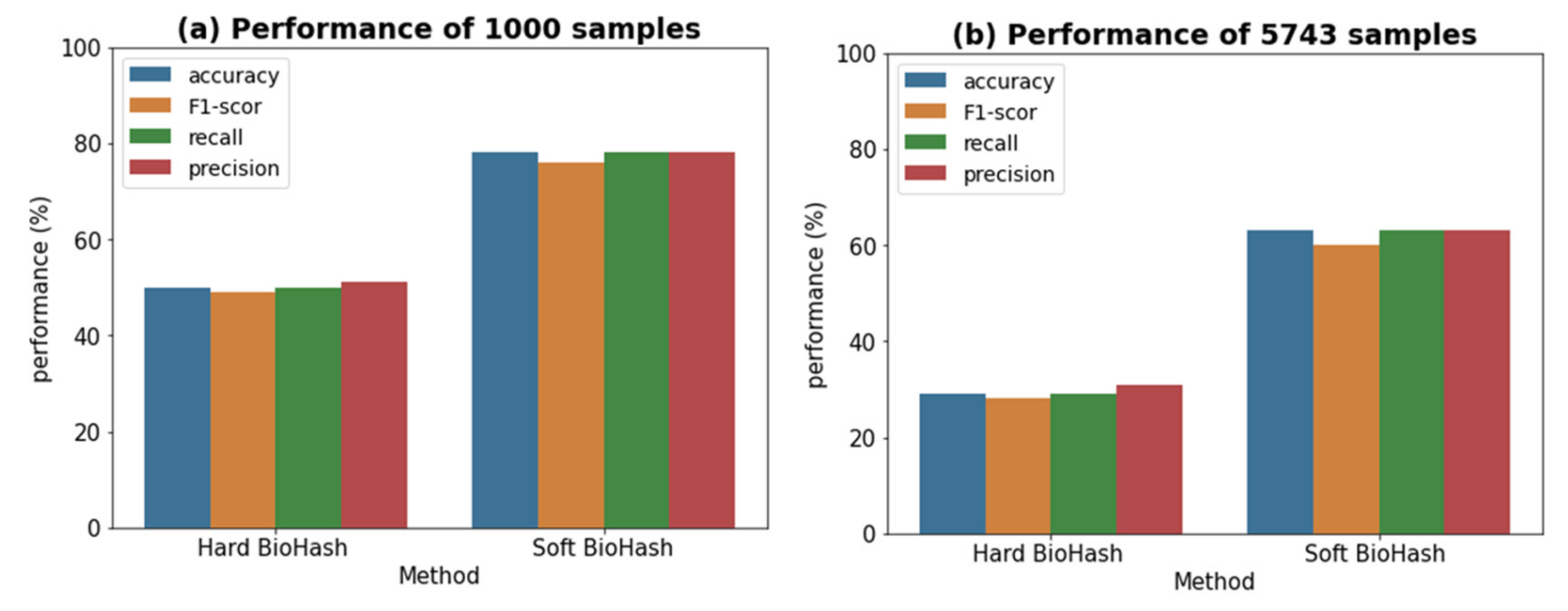
5.2. Results
5.3. Comparative Analyses
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Member, S.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inform. 2022, 18, 4361–4371. [Google Scholar] [CrossRef]
- Liu, T.; Yang, B.; Liu, H.; Ju, J.; Tang, J.; Subramanian, S.; Zhang, Z. GMDL: Toward precise head pose estimation via Gaussian mixed distribution learning for students’ attention understanding. Infrared Phys. Technol. 2022, 122, 104099. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Chen, Y.; Zhang, Z.; Li, Y.F. EHPE: Skeleton Cues-based Gaussian Coordinate Encoding for Efficient Human Pose Estimation. In IEEE Transactions on Multimedia; IEEE: New York, NY, USA, 2022; pp. 1–12. [Google Scholar]
- Talreja, V.; Taherkhani, F.; Valenti, M.C.; Nasrabadi, N.M. Using deep cross modal hashing and error correcting codes for improving the efficiency of attribute guided facial image retrieval. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; Volume 3, pp. 564–568. [Google Scholar]
- Sivakumar, M.; Saravana Kumar, N.M.; Karthikeyan, N. An Efficient Deep Learning-based Content-based Image Retrieval Framework. Comput. Syst. Sci. Eng. 2022, 43, 683–700. [Google Scholar] [CrossRef]
- Greeshma, P.; Palguna Rao, K. Efficient Retrieval of Face Image from Large Scale Database Using Sparse Coding and Reranking. Int. J. Sci. Res. 2014, 3, 275–277. [Google Scholar]
- Nithya, K.; Rajamani, V. Triplet Label Based Image Retrieval Using Deep Learning in Large Database. Comput. Syst. Sci. Eng. 2023, 44, 2655–2666. [Google Scholar] [CrossRef]
- Kharoud, G.; Malhotra, S.A. A Review: Use of Facial Marks For Twins Face Identification and Image Retrieval. Int. J. Adv. Res. Comput. Sci. 2015, 6, 84–87. [Google Scholar]
- Suchitra, S. Face image retrieval of efficient sparse code words and multiple attribute in binning image. Braz. Arch. Biol. Technol. 2017, 60, e17160480. [Google Scholar]
- Qin, J.; Cao, Y.; Xiang, X.; Tan, Y.; Xiang, L.; Zhang, J. An encrypted image retrieval method based on simhash in cloud computing. Comput. Mater. Contin. 2020, 63, 389–399. [Google Scholar] [CrossRef]
- Taherkhani, F.; Talreja, V.; Valenti, M.C.; Nasrabadi, N.M. Error-corrected margin-based deep cross-modal hashing for facial image retrieval. IEEE Trans. Biometrics Behav. Identity Sci. 2020, 2, 279–293. [Google Scholar] [CrossRef]
- Dixit, U.D.; Shirdhonkar, M.S. Face-based Document Image Retrieval System. Procedia Comput. Sci. 2018, 132, 659–668. [Google Scholar] [CrossRef]
- Somnathe, A.; Suriya, A.; Kishor, S.B. A novel content-based facial image retrieval approach using different similarity measurements. PalArch’s J. Archaeol. Egypt/Egyptol. 2021, 18, 1686–1692. [Google Scholar]
- Zeng, Y.; Li, Y.; Hu, Q.; Tang, Y. Rapid face image retrieval for large scale based on spark and machine learning. J. Phys. Conf. Ser. 2021, 2026, 012026. [Google Scholar] [CrossRef]
- Khanam, Z.; Ahsan, M.N. Implementation of the pHash algorithm for face recognition in a secured remote online examination system. Int. J. Adv. Sci. Res. Eng. 2018, 4, 1–5. [Google Scholar] [CrossRef]
- Al Kobaisi, A.; Wocjan, P. MaxHash for fast face recognition and retrieval. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 652–656. [Google Scholar]
- Taherkhani, F.; Talreja, V.; Kazemi, H.; Nasrabadi, N. Facial Attribute Guided Deep Cross-Modal Hashing for Face Image Retrieval. In Proceedings of the 2018 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 26–28 September 2018; pp. 1–6. [Google Scholar]
- Dehghani, M.; Moeini, A.; Kamandi, A. Experimental Evaluation of Local Sensitive Hashing Functions for Face Recognition. In Proceedings of the 2019 5th International Conference on Web Research (ICWR), Tehran, Iran, 24–25 April 2019; pp. 184–195. [Google Scholar]
- Shahreza, H.O.; Hahn, V.K.; Marcel, S. On the Recognition Performance of BioHashing on state-of-The-Art Face Recognition models. In Proceedings of the 2021 IEEE International Workshop on Information Forensics and Security (WIFS), Montpellier, France, 7–10 December 2021. [Google Scholar]
- Becerra-Riera, F.; Morales-González, A.; Méndez-Vázquez, H. Facial marks for improving face recognition. Pattern Recognit. Lett. 2018, 113, 3–9. [Google Scholar] [CrossRef]
- Sikkandar, H.; Thiyagarajan, R. Soft biometrics-based face image retrieval using improved Grey Wolf optimisation. IET Image Process 2020, 14, 451–461. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human-Computer Interaction. IEEE Trans. Ind. Inform. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2022, 24, 2449–2460. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, L.; Yu, Z.; Shi, Y.; Mu, C.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Jaha, E.S. Augmenting Gabor-based face recognition with global soft biometrics. In Proceedings of the 2019 7th International Symposium on Digital Forensics and Security (ISDFS), Barcelos, Portugal, 10–12 June 2019; pp. 1–5. [Google Scholar]
- Fang, Y.; Yuan, Q. Attribute-enhanced metric learning for face retrieval. Eurasip J. Image Video Process. 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Fang, Y.; Xiao, Z.; Zhang, W.; Huang, Y.; Wang, L.; Boujemaa, N.; Geman, D. Attribute prototype learning for interactive face retrieval. IEEE Trans. Inf Forensics. Secur. 2021, 16, 2593–2607. [Google Scholar] [CrossRef]
- Jafari, O.; Nagarkar, P. Experimental Analysis of Locality Sensitive Hashing Techniques for High-Dimensional Approximate Nearest Neighbor Searches. In Databases Theory and Applications; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 12610, pp. 62–73. [Google Scholar]
- Jin, Z.; Hwang, J.Y.; Lai, Y.L.; Kim, S.; Teoh, A.B.J. Ranking-Based Locality Sensitive Hashing-Enabled Cancelable Biometrics: Index-of-Max Hashing. IEEE Trans. Inf. Forensics. Secur. 2018, 13, 393–407. [Google Scholar] [CrossRef]
- Aydar, M.; Ayvaz, S. An improved method of locality-sensitive hashing for scalable instance matching. Knowl. Inf. Syst. 2019, 58, 275–294. [Google Scholar] [CrossRef]
- Luo, Y.; Li, W.; Ma, X.; Zhang, K. Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism. Information 2022, 13, 446. [Google Scholar] [CrossRef]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. 2008, pp. 1–11. Available online: https://hal.inria.fr/inria-00321923/ (accessed on 1 February 2023).
- Kumar, N.; Berg, A.C.; Belhumeur, P.N.; Nayar, S.K. Attribute and simile classifiers for face verification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 365–372. [Google Scholar]
- Ghasemi, M.; Hassanpour, H. A three-stage filtering approach for face recognition using image hashing. Int. J. Eng. Trans. B Appl. 2021, 34, 1856–1864. [Google Scholar]
- Khoi, P.; Huu, L.; Hoai, V. Face Retrieval Based on Local Binary Pattern and Its Variants: A Comprehensive Study. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 249–258. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Samples | Accuracy of Rank 20 | Average Accuracy up to Rank 20 | Average Accuracy up to Rank 60 | Average Time (in Seconds) |
|---|---|---|---|---|---|
| Hard BioHash | 1000 | 0.498 | 0.364 | 0.522 | 0.89 |
| 5743 | 0.294 | 0.214 | 0.317 | 58.7 | |
| Soft BioHash | 1000 | 0.784 | 0.684 | 0.780 | 0.14 |
| 5743 | 0.628 | 0.530 | 0.647 | 0.50 |
| Evaluation Metrics | 1000 Samples | 5743 Samples | ||
|---|---|---|---|---|
| Hard BioHash | Soft BioHash | Hard BioHash | Soft BioHash | |
| Accuracy | 0.498 | 0.784 | 0.294 | 0.628 |
| F1-score | 0.453 | 0.762 | 0.275 | 0.598 |
| Recall | 0.498 | 0.784 | 0.294 | 0.628 |
| Precision | 0.504 | 0.779 | 0.307 | 0.627 |
| Study | Database | Number of Images | Selected and Used Subsets | Uncontrolled Environment | Hard BioHash | Soft BioHash |
|---|---|---|---|---|---|---|
| [18] | ORL, AR face, Stirling faces. | 400, 2600, and 315, respectively. | All images of (ORL, AR face, and Stirling faces). | × | √ | × |
| [35] | FERET, ORL, and AR. | 14,126, 400, and over 4000, respectively. | The FERET dataset contains two unique image subsets (1980 and 4017), 100 images of ORL, and 98 images of AR. | × | √ | × |
| [36] | Combination of CF1999 and TDF (CF), the database of faces (TDF), Caltech Faces 1999 (CF1999), Labeled Faces in the Wild (LFW) | Not mentioned, 400, 447, and 13,233, respectively. | 500 to 12,000 images from different datasets. | √ | √ | × |
| Our work | LFW, LFW-attributes. | Over 13,233 and 13,143. | 5743 of LFW and 5743 of LFW-attributes. | √ | √ | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshahrani, A.A.; Jaha, E.S. Locality-Sensitive Hashing of Soft Biometrics for Efficient Face Image Database Search and Retrieval. Electronics 2023, 12, 1360. https://doi.org/10.3390/electronics12061360
Alshahrani AA, Jaha ES. Locality-Sensitive Hashing of Soft Biometrics for Efficient Face Image Database Search and Retrieval. Electronics. 2023; 12(6):1360. https://doi.org/10.3390/electronics12061360
Chicago/Turabian StyleAlshahrani, Ameerah Abdullah, and Emad Sami Jaha. 2023. "Locality-Sensitive Hashing of Soft Biometrics for Efficient Face Image Database Search and Retrieval" Electronics 12, no. 6: 1360. https://doi.org/10.3390/electronics12061360