1. Introduction
Tabular data refers to data that are arranged in the form of a table, in which each row represents a sample, and each column represents a feature. As the most common type of data in real-world applications, tabular data are widely used in many domains, such as network security [
1,
2], financial transaction [
3,
4], industrial manufacturing [
5,
6], marine traffic-cite [
7,
8], etc. Anomalies (also called outlier or novelty), which exist in almost all domain applications, often indicate malfunctions or malicious behavior and may result in property damage or even casualties. Anomaly detection (AD) for tabular data has been a lasting yet active topic in the last few decades, and dozens of methods have been proposed for different tasks.
Due to the rarity of anomalies, most real-world datasets are severely imbalanced, i.e., negative instances (normal samples) account for the vast majority, while positive instances (anomalous samples) account for only a small minority. Therefore, many researchers consider anomaly detection as an unsupervised learning problem, such as proximity-based methods [
9,
10,
11], ensemble-based methods [
12,
13,
14], and neural network-based methods [
15,
16,
17]. In the last decade, a few studies [
18,
19,
20] have pointed out the availability of labeled anomalies in some real-world scenarios. A limited number of positive samples that come from the identification of experts or the accumulation of the system are usually available with trivial cost. In recent years, more and more works have considered anomaly detection as a semi-supervised or weakly-supervised learning problem, leveraging a small set of labeled anomalies and a large-scale unlabeled dataset to train AD models. Unfortunately, most existing works [
18,
19,
20,
21,
22] treat all the samples from the unlabeled dataset as normal for convenience and overlook possible anomalies (also called anomalous contamination). Considering the very large data size, even if the proportion of anomaly samples is extremely low, there would exist quite a few anomalies in the unlabeled dataset. Ignoring these samples may result in a loss of information and then limitations in a model’s performance.
Additionally, most existing deep models for tabular data anomaly detection (TAD) [
18,
19,
20,
22,
23] try to transfer AD approaches from other domains, such as computer vision (CV) or natural language processing (NLP), instead of modeling the characteristics of tabular data. Studies [
24,
25] indicate that deep models that excel in CV or NLP cannot achieve the desired performance on tabular data due to its characteristics, including lack of locality, data sparsity and mixed feature of types. The most notable difference between tabular data and other types of data is the associative relationship between columns. Practices [
26,
27,
28,
29] in Click-Through prediction (CTR) demonstrate that feature interactions, especially high-order feature interactions, are crucial to modeling tabular data. However, to the best of our knowledge, no paper has yet worked on how to apply feature interaction to TAD.
To cope with the problem of anomalous contamination in an unlabeled dataset, we propose a novel method based on deep reinforcement learning (DRL). As can be seen from the name, DRL combines the expression ability of deep learning and the decision-making ability of reinforcement learning (RL). Different from unsupervised learning and semi-supervised learning methods, RL updates parameters by interacting with the environment without requiring data to be given in advance. In this work, we leverage the DRL algorithm to train an anomaly detector that can not only fit the labeled anomalies but also detect possible anomalies from the unlabeled dataset.
To settle the problem that deep models do not model tabular data well, we introduce a tabular data modeling approach named gated adaptive feature interaction network (GAIN) [
29]. GAIN exploits multiple parallel interaction units to learn useful high-order feature interactions. The parallel design guarantees a high-efficiency model, as works [
30,
31] have experimentally demonstrated that parallel architectures can dramatically reduce the processing time of models both on CPUs and on GPUs. GAIN works as a middleware, which can transform raw features into informative representations and can replace the deep module in DRL.
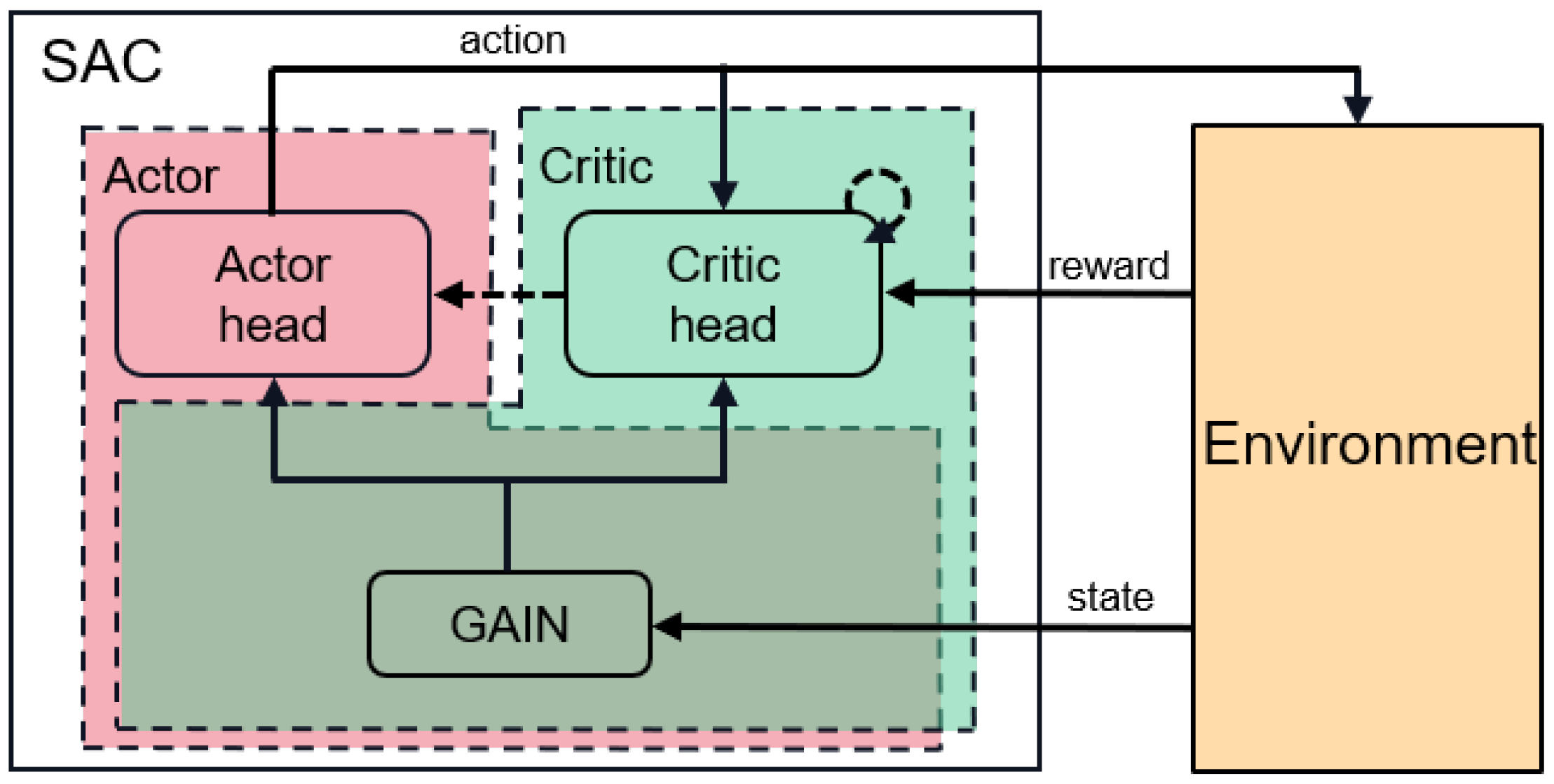
We further instantiate the proposed approach into a model called feature interaction-based reinforcement learning for tabular data anomaly detection (FIRTAD), and the architecture is shown in
Figure 1. We choose the soft Actor–Critic (SAC) [
32] as the main framework of the FIRTAD. The policy network and the Q-network share the same deep module, which is implemented with GAIN. We create a simulation environment to interact with the SAC, which includes labeled anomalies and an unlabeled dataset. To ensure the exploitation of all samples, we propose a novel sampling strategy that prevents repeated sampling from a densely distributed region. To encourage the agent to explore samples, which can bring more novelty, we extend the reward function with an intrinsic reward. More details are discussed in
Section 3.
We summarize the main contributions of this work as follows:
We propose a novel DRL-based anomaly detection approach specifically for tabular data and deliberately devise a simulation environment that allows all samples to be fully explored.
We introduce a feature interaction module (GAIN) into our approach, which can model the characteristics of tabular data by learning interactions between features. To the best of our knowledge, it is the first effort to apply feature interactions to anomaly detection.
We instantiate the proposed approach into a model called FIRTAD and extensively evaluate the model, comparing six baselines on three benchmark datasets. The experimental results demonstrate that our model performs better than state-of-the-art models and exhibits better robustness to class imbalance, label contamination and unknown anomalies.
2. Related Works
2.1. Anomaly Detection Methods
From the perspective of the availability of supervision information (labels), most existing AD methods can be divided into three categories: unsupervised learning, supervised learning and semi-supervised (weakly supervised) learning methods. Due to the high cost of data-labeling processes in real-world scenarios, supervised learning methods are often impractical, and the other two are much more popular.
2.1.1. Unsupervised Anomaly Detection
Unsupervised AD methods are almost based on the assumption that normal samples have different distributions from anomalous samples. Normal samples are densely distributed, while anomalous samples are sparsely distributed and far from normal ones. Some works [
9,
10,
33] treat samples as data points and detect anomalies by calculating the distance or density; Other works [
11,
12,
13] judge the degree of abnormality through comprehensive analysis of the distribution of every single dimension. Ref. [
34] obtains the anomaly scores of samples by calculating the joint distribution of all dimensions. Conventional machine learning methods fail to work effectively when dealing with high-dimensional samples due to the curse of dimensionality. To tackle this problem, deep learning methods are introduced to anomaly detection; the common practice is to exploit deep neural networks (e.g., multi-layer perception (MLP), autoencoder (AE) or generative adversarial network (GAN)) to project samples into a low-dimensional representation space, and then distinguish anomalies from normal samples [
15,
35,
36]. Due to the lack of supervised information, almost all unsupervised methods detect anomalies by modeling normality. Although the unsupervised AD methods have achieved decent results, their performances are still limited because anomalies that can be easily obtained have not been utilized.
2.1.2. Supervised Anomaly Detection
Although supervised AD methods are not as popular as unsupervised and semi-supervised ones, they still attract the attention of many researchers. Traditional supervised methods treat AD as a binary classification problem, and commonly used methods include Naive Bayesian, Support Vector Machine (SVM) and Gradient Boosting Decision Tree (GBDT). Deep learning-based methods train a classifier to detect anomalies on the basis of representation learning; well-known works include MLP, ResNet and FTTransformer [
24]. Both traditional and deep methods have their own drawbacks. Traditional methods do not perform well when processing high-dimensional, heterogeneous or non-independent data. In contrast, the deep methods, although they can handle these problems well, require a large number of labeled samples for training.
2.1.3. Semi-Supervised Anomaly Detection
Semi-supervised AD methods utilize limited supervised information to improve the ability to identify anomalies. Some works leverage labeled anomalies to enhance existing unsupervised AD models. Ref. [
18] uses supervised information to push anomalies away from the center of a compact hypersphere, which is built using an unsupervised method [
35]. Ref. [
22] introduces anomalous samples to a distance-based method (e.g., K-nearest neighbors [
10]) and identifies anomalies by calculating the knn-distance between the query sample and a random unlabeled subset. Other works introduce labeled anomalies into supervised AD models, and solve the problem of class imbalance through data augmentation, downsampling, etc. Ref. [
37] proposes two strategies to enrich the anomalous samples and distinguishes anomalies using a contrastive learning method. Ref. [
19] builds instance pairs to make the proportion of instance pairs containing anomalies reach 50%. Refs. [
20,
21] train their models on datasets that are equally sampled from both labeled anomalies and unlabeled samples. Ref. [
38] leverages anomalies to obtain a prior anomaly score for each sample and uses the score as supervised information to optimize the AD model. Due to the exploitation of labeled anomalies, semi-supervised methods significantly improve the performance of AD models. However, almost all semi-supervised AD models are based on the assumption that the unlabeled subset contains normal samples only or do not consider the impact of possible anomalies in it.
2.2. Feature Interaction of Tabular Data
Due to the lack of locality and the complexity of features, tabular data cannot be modeled well with prevailing deep models, such as MLP, convolutional neural network (CNN), recurrent neural network (RNN), etc. Most deep anomaly detection approaches project high-dimensional tabular data into a low-dimensional space using MLP, ResNet, AE or GAN. However, these architectures cannot guarantee the preservation of discriminative information because they overlook feature interaction, which is the most prominent difference between tabular data and other data types.
Feature interaction, especially high-order feature interaction, has been proven to be crucial in improving the model’s expressiveness in CTR prediction tasks [
26,
27,
28,
39]. In [
40], Rendle argues that a second-order feature interaction can be represented with the inner product of two latent vectors, each of which represents a single feature, and propose factorization machine (FM) to automatically learn all possible second-order feature interactions. Many works [
26,
27,
28] extend FM to learn higher-order feature interactions. However, these works brutely enumerate all possible feature interactions without differentiating their importance, and the introduction of useless interactions not only increases the computational complexity but also downgrades the model’s performance. Xue et al. [
41] propose AutoHash to adaptively learn useful high-order interactions. In AutoHash, all features are put into
k buckets with randomly initialized probabilities (features can be reused), and every bucket represents a feature interaction. The probabilities are learnable variables that help the buckets preserve useful interactions through training. Liu et al. [
42] propose a two-stage algorithm called automatic feature interaction selection (AutoFIS). In the first stage, the model is trained to drop interactions that contribute little to the final prediction; in the second stage, the model is re-trained to learn the importance pf the retained interactions. Chen et al. [
43] propose a bayesian higher-order feature interaction selection (BH-FIS). BH-FIS implements the enumeration of all feature interactions by using outer-product and masking techniques and employs spike-and-slab priors to distinguish useful feature interactions from useless ones. Liu et al. [
29] propose a gated adaptive feature interaction network (GAIN) that can adaptively learn high-order feature interactions. GAIN consists of a cross-module and a deep module; the former exploits multiple parallel interaction units to explicitly model feature interactions, while the latter leverages an MLP to model feature interactions in an implicit way.
Although the effectiveness of feature interactions has been proven in modeling tabular data, surprisingly, we can hardly find a work that incorporates it into tabular data anomaly detection.
2.3. Deep Reinforcement Learning for Tabular Anomaly Detection
The vanilla DRL algorithm is suitable for time series data due to its dependence on a live environment. Lopez-Martin et al. [
44] make a conceptual modification of the vanilla DRL algorithm to make it feasible for tabular data, replacing the environment with a sampling function and designing a reward function based on the detection error. In addition, the authors make a comparison of several DRL algorithms on network intrusion detection datasets. Vimal et al. [
3] exploit a DQN to tackle the payment fraud detection problem and use the technology of experience replay to improve the efficiency of sampling.
To solve the AD problem with a small set of labeled anomalies and a large-scale unlabeled dataset, Pang et al. [
45] propose an approach called Deep Q-learning with Partially Labeled ANomalies (DPLAN). DPLAN creates an anomaly-biased simulation environment that continuously samples anomalies or suspected anomalies from the whole dataset. Separate sampling functions are designed for the labeled anomaly set and the unlabelled dataset, denoted as
and
, respectively.
selects samples uniformly from the labeled anomaly set, while
selects samples that are likely to be anomalous from the unlabeled dataset.
is defined as
where
denotes a random subset of the unlabeled dataset,
d denotes a function of Euclidean distance and
denotes the agent’s judgment on
.
means the agent identifies
as an anomaly, the sample nearest to
is considered most likely to be anomalous, and is selected as
. In contrast,
means
is identified as a normal sample, and the sample farthest from
is returned to the agent.
DPLAN also designs a combined reward function
. The external reward
is defined based on the prediction error.
will return a positive reward if an anomalous sample is correctly recognized by the agent, no reward will be returned if a normal sample is correctly identified, and a negative reward will be returned if the agent makes a mistake. The external reward function is defined as
where
and
denote the labeled set and the unlabeled dataset, respectively.
The intrinsic reward
is devised to encourage the agent to explore novel anomalies. Hence, samples from lower-density regions receive higher intrinsic rewards as DPLAN assumes that anomalous samples are sparsely distributed and far from normal ones. The iForest [
12] algorithm can indicate the degree of abnormality of a sample and is, therefore, used to calculate the intrinsic reward. The intrinsic reward function is defined as
.
Due to the special design of the anomaly-biased sampling function and the combined reward, the agent of DPLAN is encouraged to explore the unlabeled dataset for possible anomalies. However, the DPLAN still has three main drawbacks. First, the discrete action space, i.e., , severely limits the model’s performance. The identification ability of the agent is gradually improved through training. Before the model converges, the agent’s actions are usually undetermined. However, the discrete action space cannot express the uncertainty accurately, and the step changes between 0 and 1 would hinder the model from learning useful information. Secondly, the external rewards are designed to be too coarse-grained to cover all situations, e.g., when the agent takes an ambiguous action. Thirdly, the anomaly-biased sampling function may result in excessive exploration of anomalies and insufficient exploration of normal samples, which will be sub-optimal.
3. Our Proposed Method
3.1. Problem Definition
Given a training dataset , where and denote a small labeled anomalous subset and a large-scale unlabeled subset, respectively. The size of is much smaller than that of , and the ratio of their sizes usually does not exceed 10%. The vast majority of the samples in are normal, and only a very small number of samples are anomalous, part of which may come from unknown classes (i.e., classes that have not appeared in ). We aim to find out hidden anomalies from by taking full advantage of the whole dataset D. Note that D is a tabular dataset in which all samples are independent of each other, and there is no temporal relationship between samples.
To apply a DRL algorithm to anomaly detection, we formulate the binary classification problem as a sequential decision-making problem. The agent receives a sample from the environment at time t, and takes an action . The environment gives a reward and a new sample to the agent according to and . The interaction between the agent and the environment can be represented with a Markov Decision Process (MDP), which is defined as below:
State space. The whole dataset D (including unlabeled dataset and labeled anomalies ) is defined as the state space. Each denotes the state received from the environment at time t.
Action space. Different from the existing works, we define a continuous action space . Therefore, the action can also be regarded as the anomaly probability of . The closer is to 1, the more likely is an anomaly and vice versa.
State transition. After the agent takes an action , the environment renders a new state to the agent. Different from the anomaly-biased strategy used by DPLAN, which is dedicated to sampling anomalous states, we propose a novel sampling strategy that fully explores the entire data space.
Reward. Similar to DPLAN, our proposed method leverages a combined reward function. We design a continuous extrinsic reward function to be compatible with the continuous action space. When comes from , the agent will obtain a large penalty if it fails to recognize . When comes from , identifying as an anomaly should not be given a large penalty as anomalies may be hidden in . In addition, we design a curiosity-driven intrinsic reward function to encourage the agent to explore the entire state space. The reward function is defined as , where is a scalar weighting the relevance of the intrinsic reward, and it takes a value from .
3.2. Agent
3.2.1. Foundation of the Proposed Approach
The agent of our proposed model is implemented with a SAC, which is a stochastic policy algorithm that can deal with continuous action space. Different from other DRL algorithms that aim to learn a policy to maximize the cumulative rewards, the SAC augments the objective with an entropy regularization term to concurrently maximize the entropy of the agent’s action. The introduction of the maximum entropy can not only promote the exploration but also prevent premature convergence. The objective of the SAC is represented as
where
represents the policy network,
represents the discounting factor,
represents the entropy function, and
is the trade off coefficient.
To improve the utilization of data, the SAC maintains an experience replay buffer
to store historical transitions (i.e.,
) so that the minibatch can be sampled from the buffer during training. The SAC incorporates an Actor–Critic architecture, in which the Q-network and the policy network can be updated by temporal difference and policy gradient, respectively. To tackle the problem of overestimation brought by bootstrapping, the SAC adopts the technique of target network. For faster and more stable training, the SAC exploits two Q-networks and chooses the minimum Q-value. The loss function for the Q-networks is represented as
where
represents the parameters of the Q-network. The target
y is represented as
where
represents the parameters of the policy network, and
represents the next action sampled by updated policy. The loss function of the policy network is represented as
where
represents a random number sampled from the standard normal distribution. In addition, the target networks of SAC conduct a soft update, i.e., update slowly toward the main networks in each step rather than updating periodically.
3.2.2. Feature Interaction-Based Policy Network and Q-Network
Feature interactions, especially high-order feature interactions, have been proven effective and efficient in modeling tabular data by many studies. In this work, we introduce a feature interaction module to extract expressive vectors from tabular data. Among dozens of feature interaction models that have emerged in recent years, GAIN is chosen by our work due to its effectiveness in learning high-order interactions and computational efficiency.
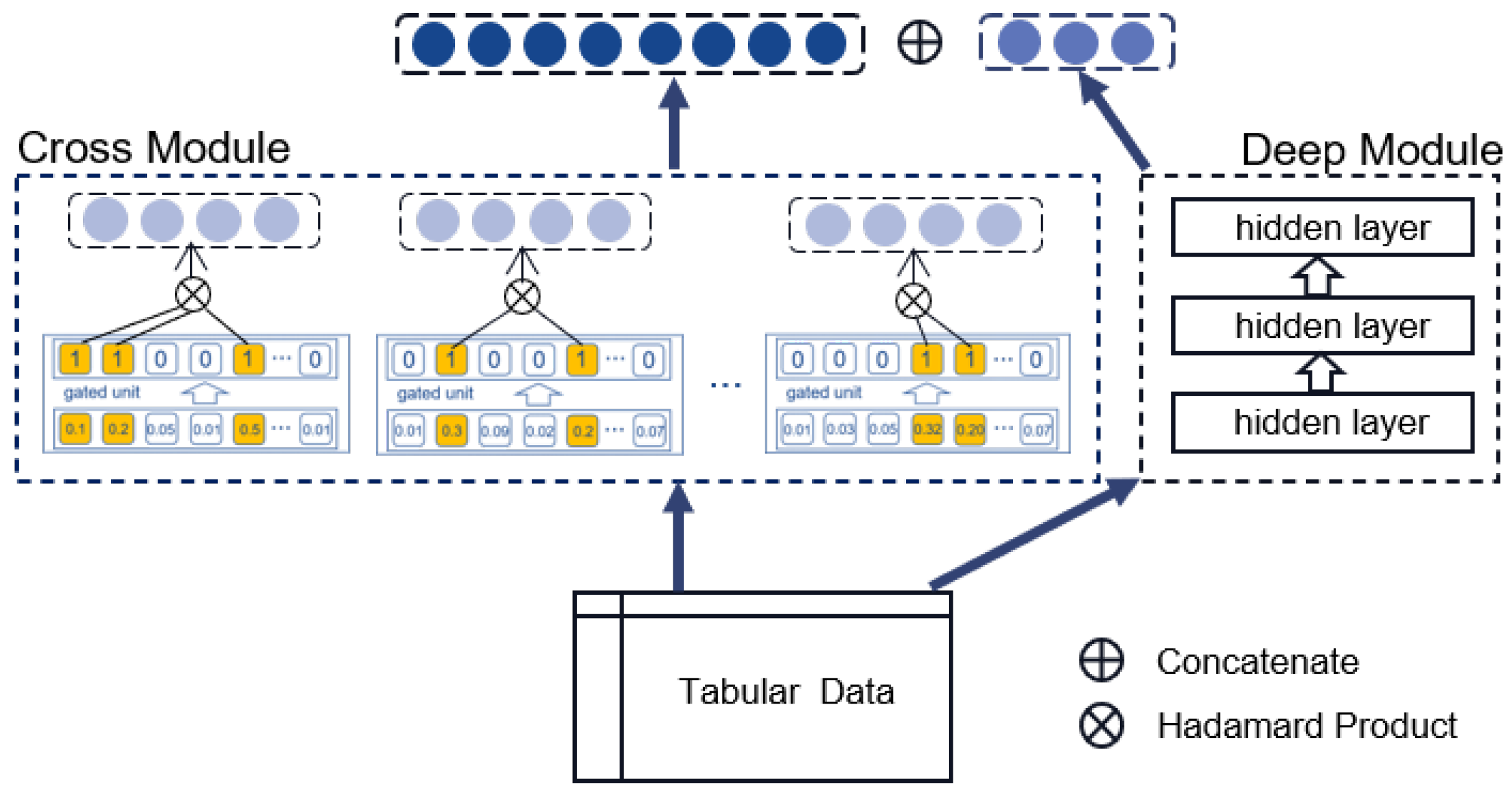
The structure of a GAIN is shown in
Figure 2. GAIN takes raw features of samples as input and outputs a low-dimensional representation vector. GAIN is composed of two main modules: a cross-module and a deep module. The cross-module consists of multiple interaction units, each of which maintains a gate for every feature, and each gate only has two statuses, closed or open. Whether a feature can participate in an interaction is determined by the status of its corresponding gate. Each unit represents a feature interaction, and the interaction order is the number of gates that are open. The statuses of the gates are randomly initialized and dynamically adjusted. Through training, the statuses are gradually stabilizing, and meaningful feature interactions will be preserved. The deep module is implemented with an MLP. The outputs of the two modules concatenate to form the output of the GAIN. In our proposed model, GAIN is used as a middleware learning useful high-order feature interactions. To improve the training efficiency and reduce the parameters, the GAIN is shared by both the policy network and the Q-network.
In addition to learning higher-order feature interactions, the GAIN can also be seen as a transformer that projects the original features into a low-dimensional representation space. The benefits are twofold. On the one hand, the dimensionality reduction can avoid the curse of dimensionality. On the other hand, low-dimensional vectors facilitate the consequent distance calculation of states. In this work, the low-dimensional representation of the state s is called the abstract state, and it is denoted as . For the sake of brevity, we will not distinguish the two terms of state and abstract state in this paper unless necessary.
3.3. Knight Sampling Strategy
With respect to the distribution of samples, AD models typically make the following assumptions. Normal samples are large in number, and most of them are densely distributed, while anomalous samples are relatively scarce and are distributed far away from normal ones.
During the interaction between the environment and the agent, states need to be continuously sampled from the environment. The selection of a state is determined by the sampling strategy, which may affect the training efficiency. A suitable strategy could significantly improve the convergence speed of the model, while an inappropriate strategy would extend the training time or make the model converge to a local optimum. The random strategy adopted by [
44] uniformly samples states from the entire state space, in which the probability of a class being selected is proportional to the proportion of states of that class in all states. Considering the severe class imbalance in the state space, normal states have much higher probabilities of being selected, and it will take more steps for the agent to encounter all anomalous states, which might result in much longer training times. To tackle the inefficient sampling of anomalous states, [
45] proposes an anomaly-biased strategy, where states that are more likely to be anomalous have higher priorities to be selected. However, repeated exploitation of anomalous states would lead to overfitting of the model. Meanwhile, insufficient exploration of normal samples would also limit the model’s performance.
Therefore, a novel sampling strategy needs to be devised so that all regions of the state space can be explored fully and evenly. Inspired by the Knight’s Tour problem [
46], we propose a novel sampling strategy. A knight-like sampler is devised that can leap to a distant state. Leaping not only make the sampler visit every part of the state space but also help the sampler escape from a cluster. An intuitive idea is to choose the farthest state from the
k-nearest neighbors. However, considering the high computational consumption of the KNN algorithm, we take a subset instead. First, a subset
is randomly sampled; Secondly, a Euclidean distance is calculated between
and each state in
; Thirdly, the state that is farthest from
is selected to be
. Selecting the furthest state from a random subset ensures that the entire state space can be explored and prevents the sampler from being trapped in a certain region. We name the proposed strategy as Knight Sampling Strategy.
3.4. Combined Reward Function
To make a trade-off between exploration and exploitation, we design a combined reward, , where and represent extrinsic and intrinsic reward, respectively. The former encourages the agent to exploit known information, while the latter stimulates the agent to explore novelty in the environment. is the trade-off coefficient.
3.4.1. Extrinsic Reward Function
Extrinsic reward is an immediate reward given by the simulation environment according to the state-action pair. Since
may come from either
or
, the extrinsic reward function should be designed separately according to the different sources of
. If
comes from
, a large
should be given a positive reward. In contrast, a small
should be given a negative reward as a penalty. Hence,
should be proportional to
(the anomaly probability) when
is sampled from
. If
comes from
,
is inversely proportional to
. Considering the possible anomalies in
, to prevent the agent from easily identifying a sample from
as normal, we should give a minor reward if
. Similarly, if
, a minor penalty is more feasible since a large penalty would discourage the agent from detecting hidden anomalies. A coefficient,
, is utilized to scale the reward, and the value of
is usually specified as the ratio of the sizes of
and
. To be compatible with the continuous action space, a continuous extrinsic reward function is required, which is defined below.
3.4.2. Intrinsic Reward Function
Inspired by human experiences in playing games that the highest score can only be obtained if the environment is fully explored, we design a curiosity-driven intrinsic reward function to encourage the agent to explore states with high novelty. Intuitively, the novelty of a state will decrease if it is sampled several times. In addition, the same happens with repeated sampling of nearby states. Therefore, the intrinsic reward of a state-action pair is inversely proportional to the visits to the region where the state is located. We exploit a Gaussian kernel function to approximately calculate the number of visits, which is represented as
where
returns a Euclidean distance, and
is a hyper-parameter, which is discussed in
Section 5.6. If two states are close to each other,
tends to be 1. In contrast, if two states are far away from each other,
tends to be 0.
We define an episodic memory
to store the states before time step
t. Since the kernel function can convert the distance of two states between 0 and 1, we calculate
of
and each state in
M and take the reduction sum as the approximate counts. The intrinsic reward function is represented as:
5. Experiments
5.1. Datasets
To verify the validity of our proposed model, three datasets from different application scenarios are selected for our experiments. NSL-KDD is a dataset from the domain of web security, and each sample in it represents a network traffic record that consists of 40 features. The value of
normal in feature
attack_type indicates benign connections, while other values indicate malicious ones. Credit card is a dataset from the domain of finance, which contains credit card transactions conducted by cardholders in Europe over two days in September 2013. Each sample in the dataset represents a transaction record, which consists of 30 features. The value of 1 in
Class indicates an anomalous transaction, while the value of 0 indicates the opposite. Census is a dataset from the domain of sociology, which contains weighted data extracted from the 1994 and 1995 current population surveys conducted by the U.S. Census Bureau. The dataset contains 40 features, including demographic and employment information, in which the record with
income “50,000+.” are regarded as anomalies. The details of the three datasets are listed in
Table 1.
The three datasets are very representative for their different composition of features, i.e., NSL-KDD contains 7 categorical features and 33 numerical features, census contains 33 categorical features and 7 numerical features, and credit card only contains numerical features. Recall the assumptions in
Section 3.1 that a dataset for AD task consists of a small labeled subset of anomalies and a large-scale unlabeled subset. To make the dataset of NSL-KDD fit our assumption, a downsampling technique is employed to reduce the anomaly ratio. NSL-KDD contains four types of anomalies, each with a large variation in sample size, i.e.,
dos: 45927,
r2l: 11656,
probe: 995,
u2r: 52. Considering the severe intra-imbalance of anomalies, we keep all samples from
probe and
u2r, and retain only 11–12% samples from
dos and
r2l. The downsampling operation reduces the anomaly ratio from 48.12% to 10.06%.
We select six competing methods to perform a performance comparison with our proposed model. In their official implementations, raw features are not preprocessed in the same manner, e.g., iForest directly removes all categorical features, CatBoost converts categorical features to continuous values, Deep SAD transforms all features to a low-dimensional vector, FT-Transformer transforms all features to embedding vectors with the same length, etc. To reduce the impact of different preprocessing methods on performance, we use the same data preprocessing for all models. First, numerical features are discretized into categorical features; Secondly, all categorical features are embedded into a vector with the same length.
5.2. Competing Methods
Dozens of methods have been proposed to tackle the TAD problems in recent years. According to the difference in the leveraging of supervisory information, those methods can be divided into four categories, such as unsupervised learning methods (UN), supervised learning methods (SU), semi-supervised learning methods (SS) and reinforcement learning methods. In this work, two state-of-the-art methods from each category are selected as the baselines.
iForest [
12]. iForest (UN) determines a sample’s anomaly degree based on the distribution of each feature value in its feature field. It assumes that the feature values of anomalies are sparsely distributed and, therefore, can be easily distinguished from that of normal samples. A split tree is built for each feature field, and the depth of the feature value represents the anomaly score of a single feature. By combining the anomaly scores of multiple features, the anomaly score of a sample can be obtained.
CBLOF [
47]. CBLOF (UN) is a cluster-based anomaly detection method that assumes that anomalies count for a small proportion of the total size and that the samples far away from the large cluster can be considered anomalies. First, a clustering method (e.g., K-Means clustering) is used to cluster samples; Secondly, large clusters are distinguished from small ones; Lastly, distances between samples and large clusters are calculated as anomaly scores.
CatBoost [
48]. CatBoost (SU) uses gradient boosting on decision trees. It is an ensemble algorithm that creates a strong learner from an ensemble of multiple weak learners. As its name suggests, CatBoost is capable of handling categorical data. In addition, it solves the problems of gradient bias and prediction shift.
FT-Transformer [
24]. FT-Transformer (SU) is a deep model that adapts transformer architecture to tabular data. All features are first transformed to an embedding vector and then passed to a stack of transformer layers to get the prediction.
Deep SAD [
18]. Deep SAD (SS) tries to learn a neural network that maps samples to a low-dimensional space in which normal samples cluster in a compact hypersphere while anomalous ones are located outside the hypersphere. A few labeled anomalies can be used in Deep SAD to improve the model’s predictive accuracy.
DevNet [
20]. DevNet (SS) is an end-to-end semi-supervised method that leverages a limited number of labeled anomalies as prior knowledge to predict anomaly scores. It is based on the assumption that there exists significant statistical deviation between normal samples and anomalous ones.
5.3. Evaluation Metrics
Two popular and complementary metrics, AUC-ROC (Area Under Receiver Operating Characteristic Curve) and AUC-PR (Area Under Precision-Recall Curve), are chosen as the evaluation metrics in this work. AUC-ROC, which summarizes the ROC curve of true positives against false positives, is used to evaluate the classification performance of a model. However, AUC-ROC cannot truly reflect the classification performance when the classes of samples are severely imbalanced. Whereas AUC-PR, which summarizes the ROC curve of precision against the recall and focuses on the performance of anomaly class, is more suitable for this work. A larger AUC-ROC or AUC-PR value reflects better performance.
5.4. Performance Comparison with Competing Models
To verify the effectiveness of our proposed model, comparative experiments are conducted on the three datasets, and the results are presented in
Table 2. Our proposed FIR-TAD performs consistently better than its competitors no matter in datasets with more categorical features or in the dataset with more numerical features. In addition, several observations can be obtained from the results. First, unsupervised methods cannot outperform supervised or semi-supervised methods. On the one hand, the absence of labels reduces the information available. On the other hand, unsupervised methods are usually based on the assumption that anomalous samples are significantly different from normal ones in distribution, which may not provide sufficient accuracy. Secondly, semi-supervised methods perform slightly better than supervised methods due to the exploitation of labeled anomalies. Thirdly, the DRL methods show strong competitiveness compared with other deep methods, especially FIR-TAD achieves substantially better performance. We attribute this to the introduction of feature interactions and the exploration ability of SAC.
5.5. Test on Robustness
Robustness with regard to anomaly ratio. To study the robustness of all models on datasets containing different numbers of anomalies, we create five datasets with different proportions (10%, 5%, 1%, 0.5%, 0.1%) of anomalies based on the NSL-KDD. Comparative experiments are performed on the five datasets, and the results are shown in
Figure 5a. We choose AUC-PR as the only evaluation metric in the following because the results of AUC-ROC are often over-optimistic in the case of imbalanced classes. As shown in
Figure 5a, the performance of all models degrades with the decrease in the proportion of anomalies, and the unsupervised methods are less affected as they distinguish anomalies based on differences in the distribution of normal samples and are not sensitive to the number of anomalous samples. With the reduction in supervised information, the supervised methods experience significant performance degradation due to their reliance on supervisory information. Although the semi-supervised methods are less affected by the decrease in the ratio of anomalies, we note that the performance of the semi-supervised methods is significantly weaker than that of the unsupervised method when the ratio drops below 0.5%. In contrast, our proposed method shows better robustness in all cases.
Robustness with regard to label contamination. To test the robustness of all models under label-contaminated conditions, which is very common in real-world scenarios, we define five datasets by sampling incremental numbers of labeled anomalies, removing their labels and blending them into the unlabeled samples. The contamination rates of the five datasets are 0%, 2%, 5%, 10% and 20%, respectively. All models are evaluated on these five datasets, and the experimental results in
Figure 5b show that the increase in label contamination rate has almost no impact on the unsupervised method. The supervised methods suffer the most due to the decrease in data quality. The semi-supervised methods consistently perform better than the unsupervised methods, proving their good robustness to label contamination. Our proposed model exhibits the best robustness, and we attribute it to the design of the extrinsic reward function, which encourages the exploration of anomalies in normal samples.
Robustness with regard to unknown anomalies.For some online anomaly detection systems, the training and test sets usually have inconsistent sample distributions, i.e., the test set may contain anomalies that never appear in the training set. To compare the robustness of different methods in the face of unknown anomalies, we define a dataset in which the training and test set contains only one type of anomaly and four additional test sets by adding new anomaly types to the test set in turn. We evaluate the trained model on the five test sets and present the results in
Figure 5c. The performance of all models decreases with the increase in anomaly types, with the unsupervised methods being the least affected and the supervised methods being the most affected. The semi-supervised methods still exhibit good robustness. Our proposed model performs significantly better than its competitors. The introduction of feature interaction allows our model to learn useful discriminative information, and the exploitation of the DRL algorithm gives our model the ability to explore the unknown. These two factors give our model very good robustness to unknown anomalies.
5.6. Impacts of Hyperparameters
In this section, we mainly focus on the impacts of the hyperparameters using the NSL-KDD dataset.
Impacts of representation dimensionality of each feature (
d). In a deep model, the representation vector with a longer length carries more information; hence, it is common to improve the expressiveness of a model by increasing the representation dimensionality of the input. Nevertheless, it is a double-edged sword, as an increase in the dimension of the representation vector would lead to an increase in memory consumption and a decrease in model efficiency. We choose
and plot the AUC-PR in
Figure 6a. Apparently, the performance improves as the length of the vector increases. Concretely, when
d changes from 8 to 16, the AUC-PR improves from 0.9175 to 0.9437, with an improvement of 2.86%. However, as the length of the vector continues to increase, the improvement in model performance becomes very limited. The AUC-PR improves from 0.9437 to 0.9439 when
d increases from 16 to 32. Considering the consequent doubling of memory consumption and computation time,
seems to be a more reasonable option, which creates a balance between effectiveness and efficiency.
Impacts of coefficient of intrinsic reward (
). As discussed in
Section 3.4,
is leveraged to provide a tradeoff between exploitation and exploration, which represents the weight factor corresponding to the intrinsic reward. We choose
from
, in which different values correspond to different extensions of exploration, e.g.,
represents a deprecation of exploration, while
represents the opposite. The experimental results are plotted in
Figure 6b. We can tell from the results that the introduction of intrinsic rewards does improve the model’s performance, while a high weight may cause the model to converge prematurely to suboptimal solutions. As shown in
Figure 6b,
is the most suitable option.
Impacts of counting radius (
). To encourage the agent to explore unknown regions in the environment, we designed the intrinsic reward to score the novelty of a region. The number of samplings from a region is approximately counted by a Gaussian kernel function, in which
can be regarded as the counting radius. For a specific region that has been visited a certain number of times, increasing the radius will lead to an increase in novelty and vice versa. We choose the value of
from
and plot the results in
Figure 6c. Intrinsically, a small radius would result in large intrinsic rewards for new samples, even if similar ones have been sampled many times, which might hinder the agent from exploring unknown regions. Moreover, a large radius would result in small intrinsic rewards for samples from sparse regions, which might result in insufficient exploration of known regions. Both of the above conditions would reduce convergence speed or make the model converge to a suboptimum, and this intuition is verified by the experimental results. As shown in
Figure 6c,
is the most reasonable option.
5.7. Ablation Study
To investigate the effects of different components in our proposed model, we propose several variants based on FIRTAD and conduct ablation experiments on all three datasets.
MLP-SAC. MLP-SAC replaces the feature interaction module (GAIN) with an MLP. To reduce the number of parameters and accelerate model convergence, the MLP is shared by the Actor and Critic.
FIR-DDPG. FIR-DDPG replaces the SAC with the Deep Deterministic Policy Gradient (DDPG), which is an Actor–Critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces.
FIR-AB. FIR-AB replaces the knight sampling strategy with the anomaly-biased strategy used in [
45].
Table 3 shows the results of our original model, FIRTAD, and its variants. In the following, we analyze the effects of components in our model. First, compared to the original model, MLP-SAC shows a significant drop in performance on NSL-KDD and census. This implies that the feature interaction module indeed enhances our model’s ability for anomaly detection. Further, we note that MLP-SAC achieves comparable results to the original model on credit card, suggesting that GAIN has no advantage in dealing with data consisting entirely of numerical features. Secondly, although both SAC and DDPG are off-policy algorithms for continuous action space, SAC has a stronger exploratory capability than DDPG due to its exploitation of stochastic policy. The comparison result between FIR-DDPG and FIRTAD validates this view and prove the effectiveness of the SAC module. Thirdly, the performance gaps between FIR-AB and FIRTAD in the three datasets indicate that the knight sampling strategy may outperform the anomaly-biased sampling strategy.
6. Conclusions
In this paper, we propose a novel anomaly detection method for tabular data called FIRTAD, which incorporates feature interaction techniques into a deep reinforcement learning framework. The innovative aspects of this article are manifested in the following dimensions: (1) It is an anomaly detection system specifically designed for tabular data; (2) It employs the SAC algorithm to generalize the discrete action space into a continuous space, thereby enhancing the model’s expressive power; (3) It creates a simulation environment by devising a novel sampling strategy and a combined reward function; (4) As far as we know, it is the first effort to apply feature interaction to anomaly detection tasks. The experiments demonstrate that our proposed model not only outperforms state-of-the-art models in terms of performance but also exhibits good robustness in situations involving varying anomaly ratios, label contamination and unknown anomalies. Our model is applicable to real-world anomaly detection scenarios, particularly in domains that have accumulated some anomalies. This work serves as an attempt to apply deep reinforcement learning to anomaly detection task and may provide some inspiration to relevant researchers.
Despite the encouraging results, our proposed FIRTAD still has some limitations. First, our model relies heavily on large amounts of data for training, so its performance advantages may not be apparent when only dealing with a small dataset. Second, the anomaly detection capability of our model gradually improves during the interaction between the agent and the environment, which leads to an increased demand for computational resources and training time. Third, the experiments demonstrate that the performance advantages of our model on the balanced dataset are not significant, which limits the applicability of the model.
Future work will consider using multiprocessing for model training and the study of anomaly interpretability.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}