
SuperDet: An Efficient Single-Shot Network for Vehicle Detection in Remote Sensing Images


Abstract
:1. Introduction
2. Related Work
2.1. Object Detection
2.2. Vehicle Detection in Remote Sensing Images
3. The Proposed Method
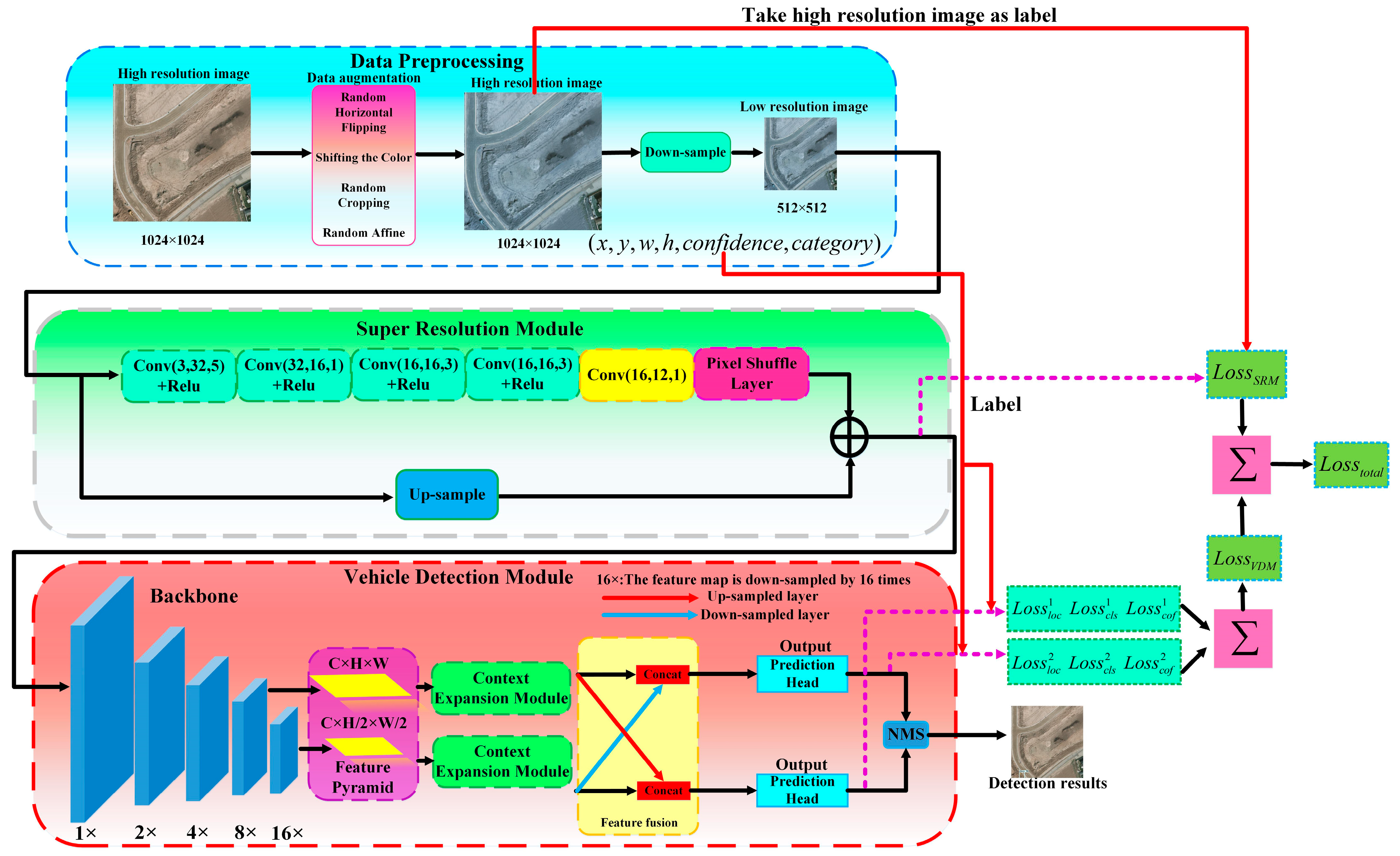
3.1. The Architecture Design of SuperDet
3.1.1. Data Preprocessing
3.1.2. Super Resolution Module
3.1.3. Vehicle Detection Module
3.2. Multi-Task Loss Function
4. Experiments
4.1. Experimental Setup
4.2. Ablation Study
4.3. Experiment on VEDAI
4.4. Experiment on DOTA Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nassim, A.; Haikel, A.; Yakoub, B.; Bilel, B.; Naif, A.; Mansour, Z. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar]
- Nicolas, A.; Le, S.B.; Sébastien, L. Segment-before-detect: Vehicle detection and classification through semantic segmentation of aerial images. Remote Sens. 2017, 9, 368. [Google Scholar]
- Zhou, Y.; Liu, L.; Shao, L.; Mellor, M. DAVE: A Unified Framework for Fast Vehicle Detection and Annotation. arXiv 2016, arXiv:1607.04564. [Google Scholar]
- Wang, L.; Lu, Y.; Wang, H.; Zheng, Y.; Ye, H.; Xue, X. Evolving Boxes for Fast Vehicle Detection. arXiv 2017, arXiv:1702.00254. [Google Scholar]
- Mattyus, G.; Liu, K. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Mou, L.; Zhu, X. Spatiotemporal scene interpretation of space videos via deep neural network and tracklet analysis. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Kopsiaftis, G.; Karantzalos, K. Vehicle detection and traffic density monitoring from very high resolution satellite video data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015. [Google Scholar]
- Cheng, H.Y.; Weng, C.C.; Chen, Y.Y. Vehicle detection in aerial surveillance using dynamic bayesian networks. IEEE Trans. Image Process. 2011, 21, 2152–2159. [Google Scholar] [CrossRef] [PubMed]
- Wen, S.; Wen, Y.; Gang, L.; Jie, L. Car detection from high-resolution aerial imagery using multiple features. In Proceedings of the Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany, 22–27 July 2012; pp. 4379–4382. [Google Scholar]
- Chen, Z.; Wang, C.; Wen, C.; Teng, X.; Chen, Y.; Guan, H.; Luo, H.; Cao, L.; Li, J. Vehicle Detection in High-Resolution Aerial Images via Sparse Representation and Superpixels. IEEE Trans. Geosci. Remote. Sens. 2015, 54, 103–116. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, C.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. Computer Vision and Pattern Recognition (cs.CV). arXiv 2016, arXiv:1512.02325, 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; p. 1. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- van de Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1879–1886. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO 9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Etten, A.V. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Zhou, X.; Wang, D.; Philipp, K. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired key points. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar]
- Ji, H.; Gao, Z.; Mei, T.; Li, Y. Improved Faster R-CNN with multiscale feature fusion and homography augmentation for vehicle detection in remote sensing images. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 1761–1765. [Google Scholar] [CrossRef]
- Tayara, H.; Soo, K.G.; Chong, K.T. Vehicle detection and counting in high-resolution aerial images using convolutional regression neural network. IEEE Access 2017, 6, 2220–2230. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Zhu, X.X. Vehicle instance segmentation from aerial image and video using a multi-task learning residual fully convolutional network. arXiv 2018, arXiv:1805.10485. [Google Scholar]
- Mandal, M.; Shah, M.; Meena, P.; Devi, S.; Vipparthi, S.K. AVDNet: A Small-Sized Vehicle Detection Network for Aerial Visual Data. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 494–498. [Google Scholar] [CrossRef] [Green Version]
- Zhong, J.; Lei, T.; Yao, G. Robust vehicle detection in aerial images based on cascaded convolutional neural networks. Sensors 2017, 17, 2720. [Google Scholar] [CrossRef] [Green Version]
- Du Terrail, J.O.; Jurie, F. Faster RER-CNN: Application to the detection of vehicles in aerial images. arXiv 2018, arXiv:1809.07628. [Google Scholar]
- Lin, Z.; Wu, Q.; Fu, S.; Wang, S.; Kong, Y. Dual-NMS: A method for autonomously removing false detection boxes from aerial image object detection results. Sensors 2019, 19, 4691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Liu, Y.; Liu, T.; Lin, Z.; Wang, S. DAGN: A Real-Time UAV Remote Sensing Image Vehicle Detection Framework. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 1884–1888. [Google Scholar] [CrossRef]
- Darehnaei, Z.G.; Fatemi, S.; Mirhassani, S.M.; Fouladian, M. Ensemble deep learning using faster r-cnn and genetic algorithm for vehicle detection in uav images. IETE J. Res. 2021, 1–10. [Google Scholar] [CrossRef]
- Tan, Q.; Ling, J.; Hu, J.; Qin, X.; Hu, J. Vehicle Detection in High Resolution Satellite Remote Sensing Images Based on Deep Learning. IEEE Access 2020, 8, 153394–153402. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ju, M.; Luo, J.; Liu, G.; Luo, H. A real-time small target detection network. Signal Image Video Process. 2021, 15, 1265–1273. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. Proc. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2999–3007. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. arXiv 2018, arXiv:1711.10398. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector | Advantage | Disadvantage |
|---|---|---|
| [25] | Apply homography data augmentation to improve the generalization ability | Not fit for real-time vehicle detection |
| HRPN | 1. Design combination of hierarchical feature maps 2. Reducing false detection by negative example mining | Not fit for real-time vehicle detection |
| ResFCN | Design for vehicle instance segmentation | Not fit for real-time vehicle detection |
| AVDNet | Alleviate the problem of vanishing features for smaller objects by introducing ConvRes blocks at multiple scales | Not fit for vehicle detection with multi-scales |
| Cascaded CNNs | Improve performance by combining two independent convolutional neural networks | Not fit for real-time vehicle detection |
| CorrNet | Remove the false detection boxes using dual non-maximum suppression Improve the extraction ability of the overall features with dilated convolution guidance structure | Not fit for real-time vehicle detection |
| Faster RER-CNN | Handle the rotation equivariance inherent to any aerial image task | Not fit for real-time vehicle detection |
| DAGN | Accelerate the proposed model by introducing the depthwise-separable convolutions | No addressing the low resolution of vehicles in remote sensing images |
| [34] | Improve performance by ensemble deep transfer learning | Not fit for real-time vehicle detection |
| Baseline | With Context Expansion Module | With Feature Fusion | With SRM | mAP | FPS |
|---|---|---|---|---|---|
| √ | 70.0% | 53.9 | |||
| √ | √ | 72.1% | 47.7 | ||
| √ | √ | √ | 73.5% | 41.3 | |
| √ | √ | √ | √ | 77.6% | 29.3 |
| Detector | SSD | Faster RCNN | YOLO V2 | YOLO V3 | CorrNet | Faster RER-CNN | DAGN | SuperDet |
|---|---|---|---|---|---|---|---|---|
| Input | 512 × 512 | 512 × 512 | 512 × 512 | 512 × 512 | 512 × 512 | 512 × 512 | 512 × 512 | 512 × 512 |
| FPS | 22.0 | 6.3 | 55.2 | 31.5 | 10.0 | 2.7 | 25.1 | 29.3 |
| mAP (%) | 46.1 | 67.0 | 50.3 | 61.6 | 68.05 | 70.8 | 67.1 | 77.6 |
| Detector | Car | Pickup | Camping | Truck | Boat | Van | Other | Tractor | Plane | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster RER-CNN | 80.2 | 77.0 | 72.8 | 72.3 | 65.3 | 74.1 | 51.0 | 67.8 | 77.4 | 70.8 |
| DAGN | 81.3 | 66.1 | 72.0 | 32.9 | 41.5 | 78.6 | 53.9 | 85.3 | 78.2 | 67.1 |
| SuperDet | 88.6 | 82.4 | 77.3 | 70.0 | 64. 1 | 93.8 | 47.2 | 77.9 | 99.8 | 77.6 |
| Detector | YOLO V2 | Tiny-YOLO V3 | YOLO V3 | ARFFDet | SuperDet |
|---|---|---|---|---|---|
| Input | 512 × 512 | 512 × 512 | 512 × 512 | 256 × 256 | 256 × 256 |
| FPS | 58.3 | 76.4 | 14.7 | 130.0 | 95.3 |
| mAP (%) | 72.7 | 73.2 | 88.3 | 89.0 | 91.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, M.; Niu, B.; Jin, S.; Liu, Z. SuperDet: An Efficient Single-Shot Network for Vehicle Detection in Remote Sensing Images. Electronics 2023, 12, 1312. https://doi.org/10.3390/electronics12061312
Ju M, Niu B, Jin S, Liu Z. SuperDet: An Efficient Single-Shot Network for Vehicle Detection in Remote Sensing Images. Electronics. 2023; 12(6):1312. https://doi.org/10.3390/electronics12061312
Chicago/Turabian StyleJu, Moran, Buniu Niu, Sinian Jin, and Zhaoming Liu. 2023. "SuperDet: An Efficient Single-Shot Network for Vehicle Detection in Remote Sensing Images" Electronics 12, no. 6: 1312. https://doi.org/10.3390/electronics12061312