

Social Recommendation Algorithm Based on Self-Supervised Hypergraph Attention


Abstract
:1. Introduction
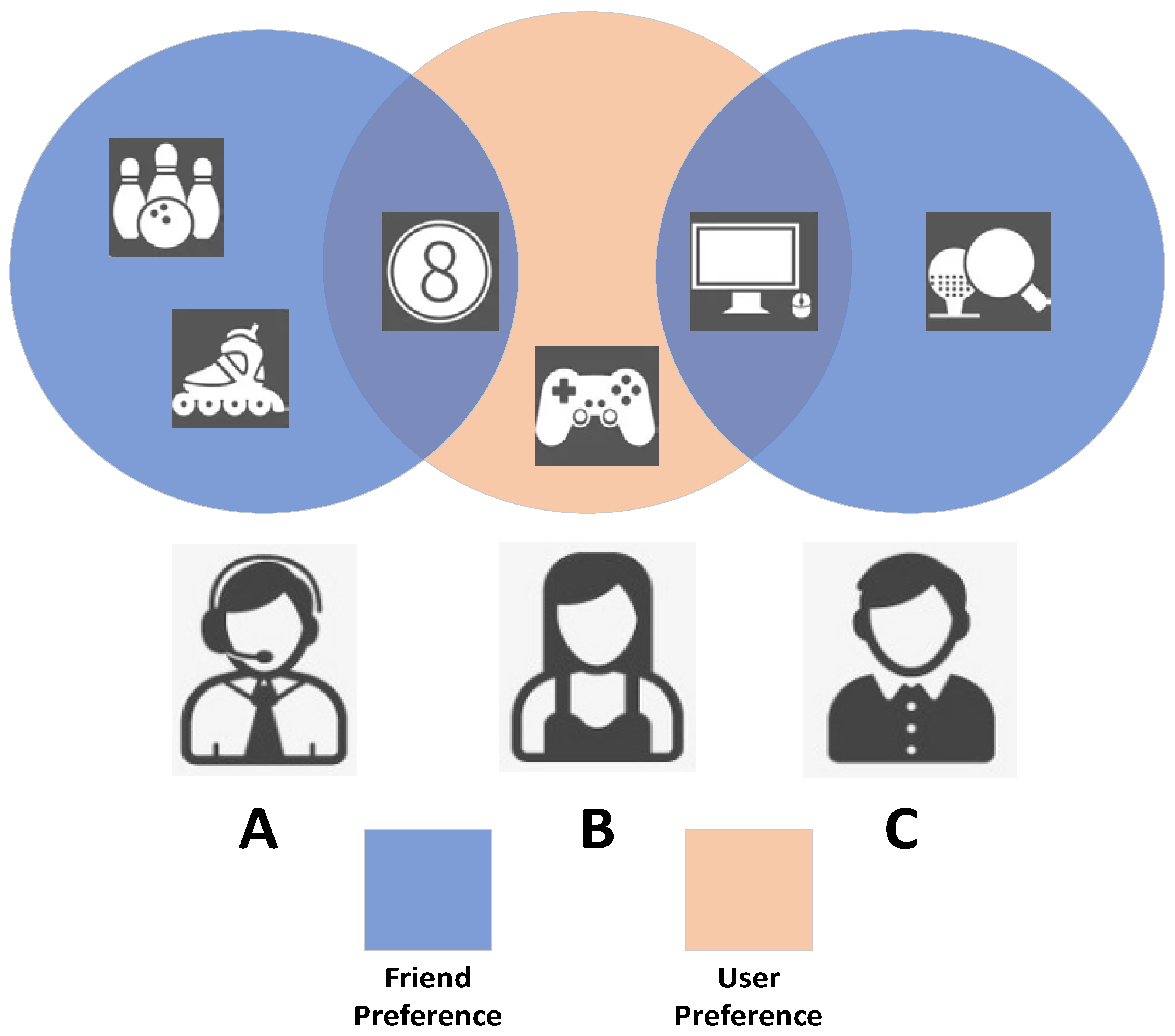
- Most research work in social recommendation assumes that all of the user’s friends have the same influence on them or that they all have similar interests to them. This assumption is too far from the actual real-life situation due to the different types of friends. In real life, different friends have different influences on a user’s decision-making [13]. As shown in Figure 1, user B has two friends; B and A both like to play volleyball and have the same preference for singing as C. B takes A’s suggestion more into account when doing outdoor activities and C’s suggestion more into account when doing indoor activities. Singing and playing volleyball, however, have different degrees of influence on the users. Chen et al. [14] proposed to fuse social influence between users with two attention networks for modeling complex dynamic and general static preferences of users in social recommendations. However, only the importance of friends is considered and the impact on users in different aspects is neglected.
- GNN-based social recommendation models have shown outstanding performance [15,16,17]. Nevertheless, these models widely exploit only simple pairwise user relationships and overlook the complex higher-order relationships between users. Inspired by hypergraph learning [18], Yu et al. [19] used social information for constructing hypergraphs to model higher-order interactions through multi-channel hypergraph convolution. Problems in constructing multiple levels of hypergraph for fusion, however, cannot take into account the independence of different levels of hypergraph modeling itself.
- By modeling different levels of hypergraphs to enrich user feature expressions, and introducing hypergraphs to dig deeper into the higher-order information among users, we conclude with a description of the transcendent pairwise relationships among users through hypergraph modeling.
- Based on the consideration of social consistency, a new attention framework is proposed to highlight the influence of different friends on the final recommendation results. This framework also deeply highlights the important influence of friends who make important suggestions in a certain aspect on the final recommendation results, which better simulates the real recommendation scenario.
- We propose to integrate the self-supervised learning strategy seamlessly with hypergraph model training to enhance the model’s performance.
- Experiments on two publicly available datasets show that the proposed model HGATH outperforms state-of-the-art social recommendation models.
2. Related Works
2.1. Social Recommendation Based on Attention Mechanism
2.2. Social Recommendation Based on Graph Neural Networks
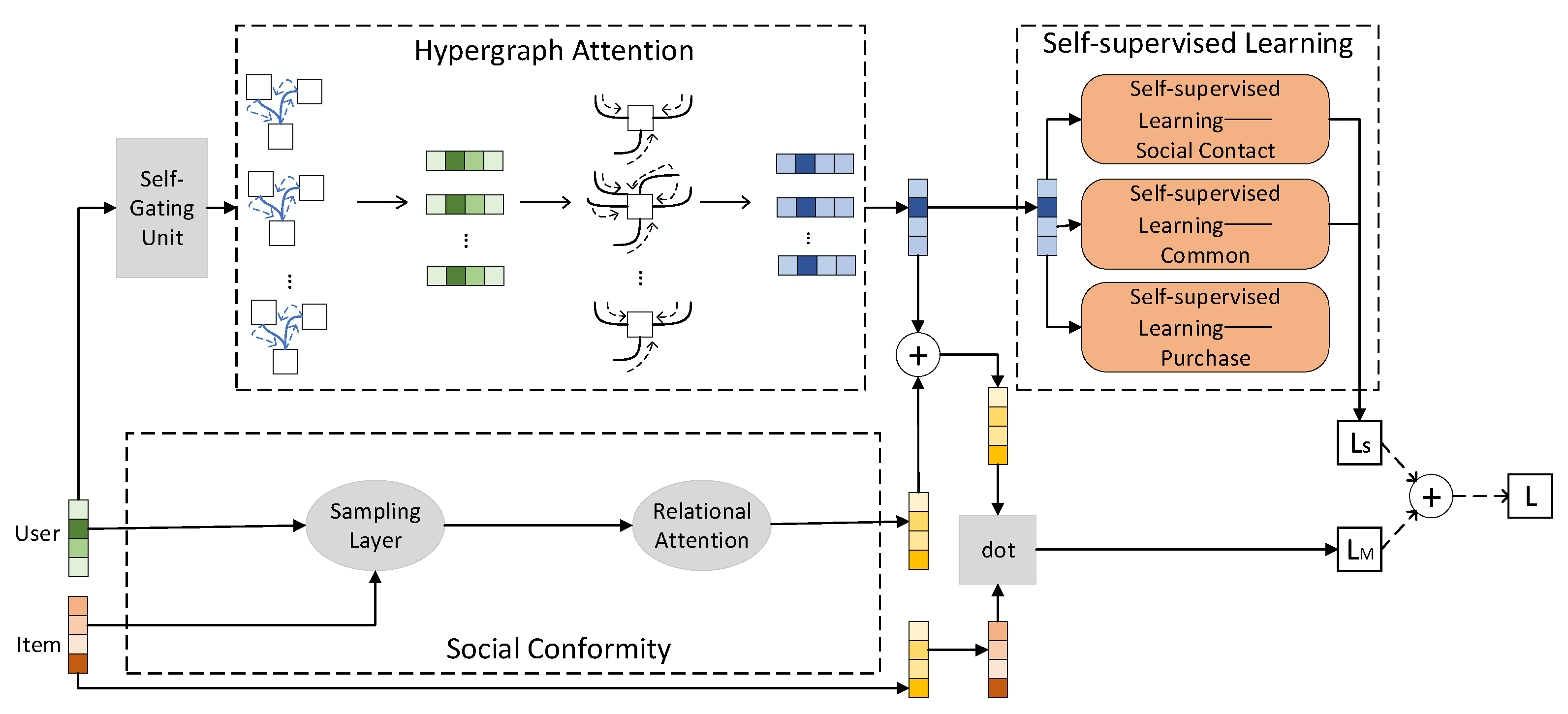
3. Self-Supervised Hypergraph Attention Recommendation Model
3.1. Social Consistency
3.2. Hypergraph Attention Network
3.3. Self-Supervised Learning
3.4. Model Optimization
4. Experiment Comparison and Analysis
4.1. Dataset
4.2. Evaluation Criteria
4.3. Experimental Setting
- We considered a comparison with mainstream advanced algorithms to verify the efficiency and advancement of the algorithm proposed in this module.
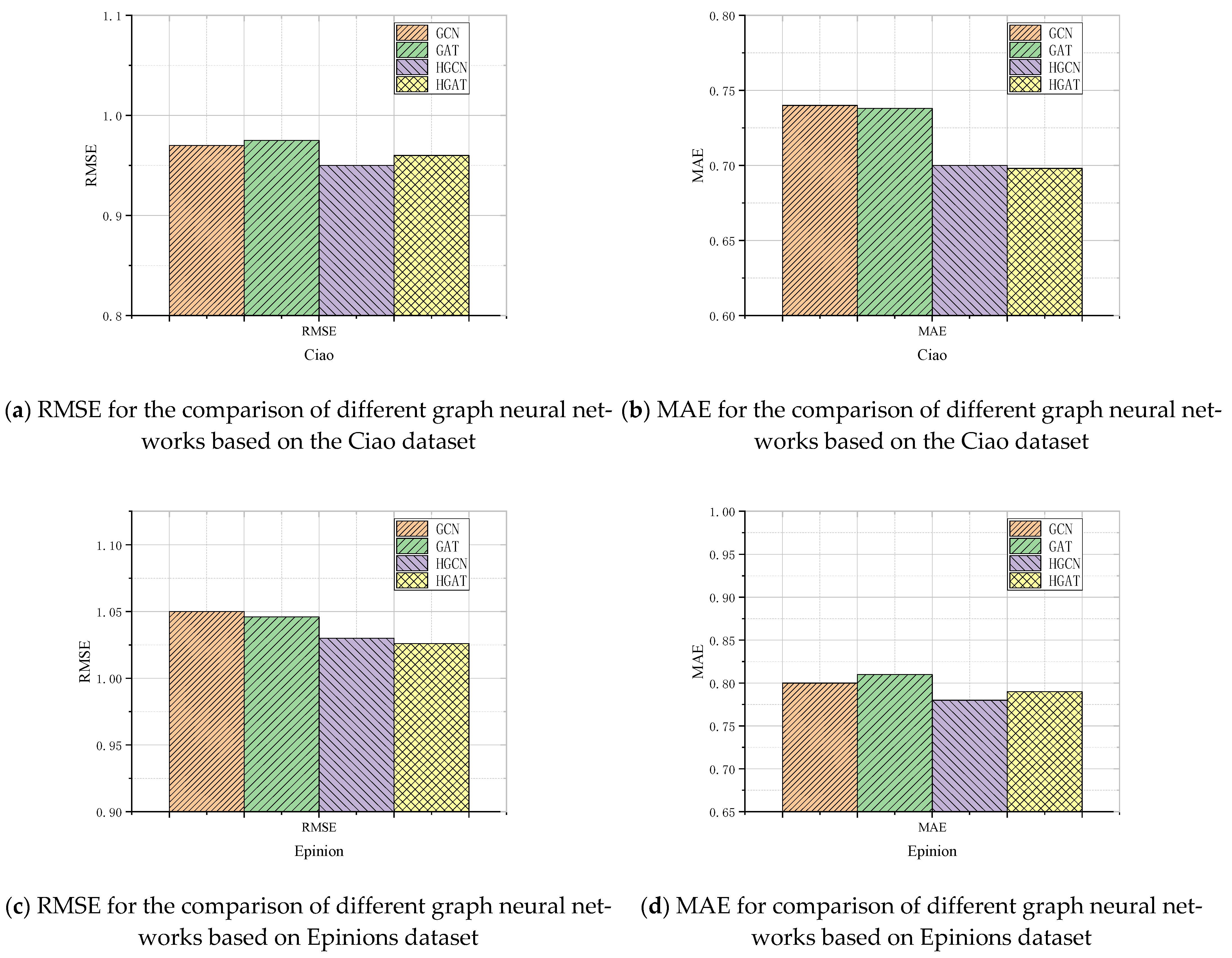
- We compared this model with graph neural networks to verify the effectiveness of the employed hypergraph attention.
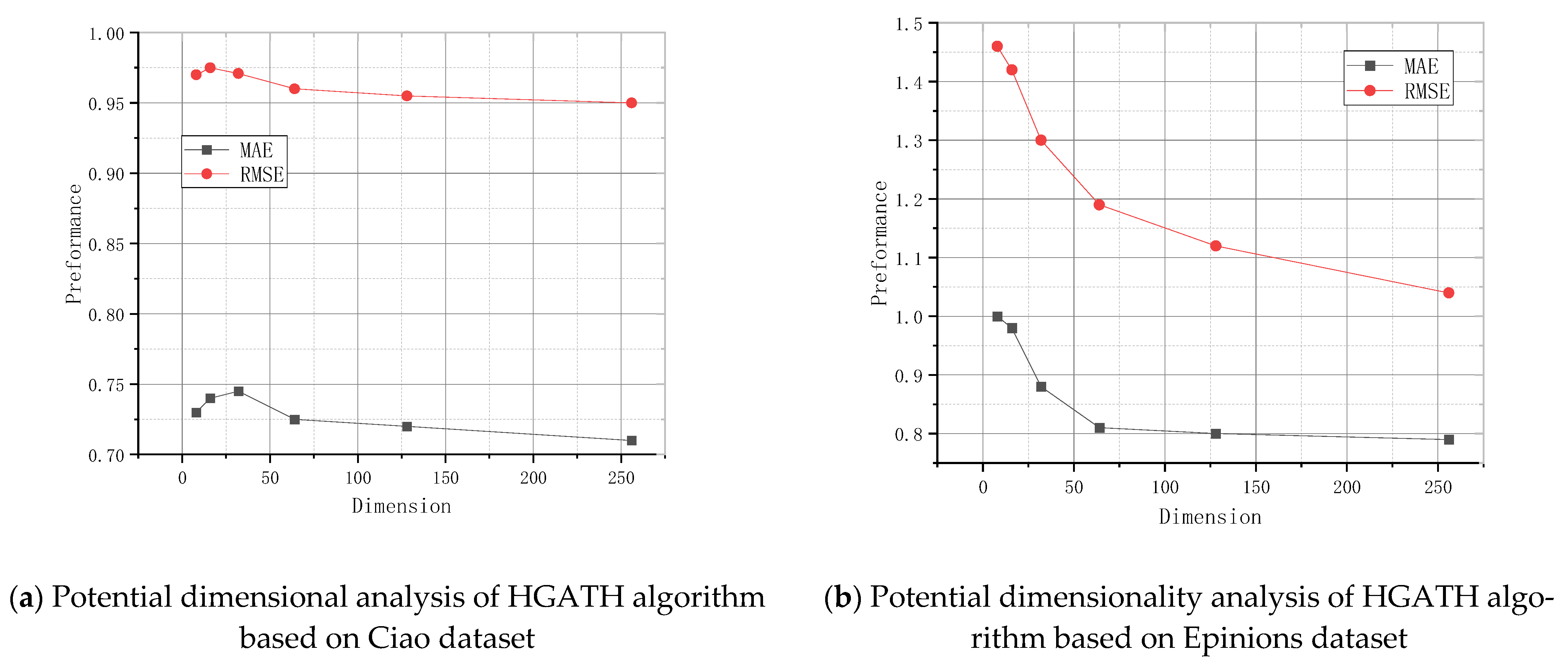
- We considered potential dimensionality factor analysis to test the effective dimensionality in various cases based on differing potential dimensionality factors to verify the robustness of the algorithm proposed in this module.
- SoRec [44] combined social information with matrix decomposition.
- SocialMF [10] proposed a new social recommendation model, which is based on the matrix decomposition model and integrates the user’s trust propagation mechanism to model social networks.
- SoReg [44] proposed a recommendation algorithm based on social relations, which constrained the learning of users’ potential feature vectors in the traditional matrix decomposition by social relations in a way of social regularization, so as to make the potential feature vectors of two users with social relations as similar as possible.
- The collaborative user network embedding (CUNE) [45] proposed to dig deep into the implicit social relationship of users based on user feedback to identify the implicit important friends of users, and eventually realized the ranking of user preferences based on the Matrix Factorization (MF) ranking model.
- Graph Convolution Matrix Completion with Spectral Nonlinear (GCMC + SN) [46] proposed a bipartite interactive graph-based graph autoencoder framework for differentiable message passing based on graph structure data.
- Graph Recommendation (GraphRec) [28] developed a new graph neural network framework for social recommendation, which is the first time that a graph neural network was combined with a principled method to model users and projects and the complex interaction between them.
- ConsisRec [15] used a sampling strategy to mine complex relationships among neighbors based on the principle of social consistency, thus modeling neighbors, and uses an attention mechanism to highlight the influence weights of different important users.
4.4. Experimental Analysis
4.4.1. Performance Comparison
- (a)
- On both datasets, CUNE, ConsisRec, and HGATH algorithms work better than SoRec, SocialMF, and SoReg, which shows the superior function of considering the consistency of social relationships shown on the model.
- (b)
- Among the social recommendation-based algorithms, HGATH outperforms the CUNE and ConsisRec algorithms, which indicates that for social recommendation, it is not enough to extract valid social relationships from users’ social relationships. Obviously, the higher-order relationships among users must be considered. Meanwhile, compared with the simple graph structure that can only connect two nodes, the inset attention focuses on more complex relationships and mines richer user interaction information.
- (c)
- HGATH is more effective than GCMC + SN and GraphRec, which means that higher-order information interactions can maximize the inheritance of different aspects of hypergraph information.
- (d)
- On all the evaluation metrics, all comparison algorithms perform better on the Ciao dataset than the Epinions dataset; this is because the Epinions dataset is sparser than the Ciao dataset.
- HGATH beats all baselines, which shows the effectiveness of the proposed method in this paper.
- The graph model-based recommendation algorithms (e.g., GCMC + SN, GraphRec) outperform the social recommendation algorithms that do not employ graph learning methods (e.g., SoRec, SocialMF, SoReg, CUNE), which validates the powerful learning capability of graph models in recommendation scenarios.
- The performance difference between SoRec, SocialMF, and SoReg is not significant, which also validates that all three models are essentially MF-based recommendation models. The same reasoning applies to GCMC + SN and GraphRec.
- The performance of each model based on the Epinion dataset is generally slightly lower than that of the Ciao dataset, which is consistent with the fact that the Ciao dataset is not as sparse as the Epinion one.
4.4.2. Comparative Analysis of Graph Neural Networks
4.4.3. Potential Dimensional Analysis
5. Discussion
- In contrast to other social recommendation work that uses simple graph models to learn user representations, we used hypergraphs to learn user representations. The hypergraphs were used to learn the representation of the user based on multiple aspects of the user. As a complex graph, the hypergraph has the property of linking multiple nodes within one edge, which makes it naturally advantageous for the representation of complex data relationships between nodes. By taking advantage of the supergraph’s superior learning ability to fully learn the user’s representations, the complex relationships between users are well described, while higher-order relationships are accurately modeled. The results in Figure 3 and Figure 4 verify the effectiveness and efficiency of the method in this paper.
- Users are influenced differently by different friends when making decisions. Instead of using the vanilla attention mechanism to distinguish the importance of friends, we designed a hierarchical iterative aggregation to learn the relational attention network of user representations. First, the user’s friend features are dynamically sampled in a single layer based on item features, and then a dynamic aggregation operation is performed based on a relational attention mechanism to learn the user’s representation. Next, each layer takes the previous layer’s user’s embedding as input, which finally outputs the user’s iterative updated embedding. The whole process simulates how the potential embeddings of the users evolve with the dynamic influence of the project until the precise user embeddings are finally generated. In the process of simulated evolution, the attention network proposed in this paper accurately manifests the social consistency principle.
- In order to further contextualize the effect of data sparsity while fully inheriting the rich user representation learned from the hypergraph, we innovatively incorporated self-supervised learning into the training of the recommendation model proposed in this paper. By considering the hypergraphs reflecting different aspects of user representations as different views in the self-supervised contrastive learning considered, the mutual information of these views was maximized to achieve rich user representations in the recommendation task for better performance.
- Self-supervised learning is a fresh direction in the future recommendation field. However, graph learning-based recommendation models in self-supervised learning tasks mostly arbitrarily employ operations such as item cropping and masking to improve the variability among views in the self-supervised comparative learning process. Such operations also bring about the problem of creating more sparse training data. In the future, we will further investigate how to perform robust self-supervised learning while preserving the original data.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Forouzandeh, S.; Aghdam, A.; Forouzandeh, S.; Xu, S. Addressing the cold-start problem using data mining techniques and improving recommender systems by cuckoo algorithm: A case study of Facebook. Comput. Sci. Eng. 2020, 40, 62–73. [Google Scholar] [CrossRef]
- Beshley, M.; Veselý, P.; Pryslupskyi, A.; Beshley, H.; Kyryk, M.; Romanchuk, V.; Kahalo, I. Customer-Oriented Quality of Service Management Method for the Future Intent-Based Networking. Appl. Sci. 2020, 10, 8223. [Google Scholar] [CrossRef]
- Forouzandeh, S.; Rostami, M.; Berahmand, K. A hybrid method for recommendation systems based on tourism with an evolutionary algorithm and topsis model. Fuzzy Inf. Eng. 2022, 24, 26–40. [Google Scholar] [CrossRef]
- Rostami, M.; Muhammad, U.; Forouzandeh, S.; Berahmand, K.; Farrahi, V.; Oussalah, M. An effective explainable food recommendation using deep image clustering and community detection. Intell. Syst. Appl. 2022, 16, 200157. [Google Scholar] [CrossRef]
- De Meo, P.; Fotia, L.; Messina, F.; Rosaci, D.; Sarné, G.M. Providing recommendations in social networks by integrating local and global reputation. Inf. Syst. 2018, 78, 58–67. [Google Scholar] [CrossRef]
- Przystupa, K.; Beshley, M.; Hordiichuk-Bublivska, O.; Kyryk, M.; Beshley, H.; Pyrih, J.; Selech, J. Distributed Singular Value Decomposition Method for Fast Data Processing in Recommendation Systems. Energies 2021, 14, 2284. [Google Scholar] [CrossRef]
- Guo, Z.; Yu, K.; Li, Y.; Srivastava, G.; Lin, J.C.-W. Deep learning-embedded social internet of things for ambiguity-aware social recommendations. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1067–1081. [Google Scholar] [CrossRef]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar]
- Jamali, M.; Ester, M. Trustwalker: A random walk model for combining trust-based and item-based recommendation. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, June 28–1 July 2009; pp. 397–406. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Social attentional memory network: Modeling aspect- and friend-level differences in recommendation. In Proceedings of the 20th ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 177–185. [Google Scholar]
- Tao, Y.; Li, Y.; Zhang, S.; Hou, Z.; Wu, Z. Revisiting graph based social recommendation: A Distillation Enhanced Social Graph Network. In Proceedings of the World Wide ACM Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 2830–2838. [Google Scholar]
- Abu-Salih, B.; Wongthongtham, P.; Zhu, D.; Chan, K.Y.; Rudra, A. Social Big Data Analytics; Springer: Singapore, 2021. [Google Scholar]
- Sun, P.; Wu, L.; Wang, M. Attentive recurrent social recommendation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 185–194. [Google Scholar]
- Xu, F.; Lian, J.; Han, Z.; Li, Y.; Xu, Y.; Xie, X. Relation-aware graph convolutional networks for agent-initiated social E-commerce recommendation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 529–538. [Google Scholar]
- Wu, J.; Fan, W.; Chen, J.; Liu, S.; Li, Q.; Tang, K. Disentangled contrastive learning for social recommendation. In Proceedings of the 31st ACM International Conference on Information and Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 4570–4574. [Google Scholar]
- Du, J.; Ye, Z.; Yao, L.; Guo, B.; Yu, Z. Socially-aware dual contrastive learning for cold-start recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1927–1932. [Google Scholar]
- Yang, Y.; Huang, C.; Xia, L.; Liang, Y.; Yu, Y.; Li, C. Multi-behavior hypergraph-enhanced transformer for sequential recommendation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2263–2274. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-supervised multi-channel hypergraph convolutional network for social recommendation. In Proceedings of the World Wide Web Conference 2021, Ljubljana, Slovenia, 12–16 April 2021; pp. 413–424. [Google Scholar]
- Yang, L.; Liu, Z.; Dou, Y.; Ma, J.; Yu, P.S. Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, Canada, 11–15 July 2021; pp. 2141–2145. [Google Scholar]
- Ashish, V.; Noam, S.; Niki, P. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1–11. [Google Scholar]
- Pei, W.; Yang, J.; Sun, Z.; Zhang, J.; Bozzon, A.; Tax, D.M. Interacting attention-gated recurrent networks for recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1459–1468. [Google Scholar]
- Zhang, C.; Wang, Y.; Zhu, L.; Song, J.; Yin, H. Multi-graph heterogeneous interaction fusion for social recommendation. ACM Trans. Inf. Syst. 2022, 4, 1–26. [Google Scholar] [CrossRef]
- Yu, J.; Yin, H.; Li, J.; Gao, M.; Huang, Z.; Cui, L. Enhancing social recommendation with adversarial graph convolutional networks. IEEE Trans. Knowl. Data Eng. 2022, 34, 3727–3739. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, H.; Yu, L. Inductive contextual relation learning for personalization. ACM Trans. Inf. Syst. 2022, 39, 1–22. [Google Scholar] [CrossRef]
- Xia, L.; Huang, C.; Xu, Y.; Dai, P.; Zhang, X.; Yang, H.; Pei, J.; Bo, L. Knowledge-enhanced hierarchical graph transformer network for multi-behavior recommendation. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; pp. 4486–4493. [Google Scholar]
- Xia, L.; Xu, Y.; Huang, C.; Dai, P.; Bo, L. Graph meta network for multi-behavior recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtually, Canada, 11–15 July 2021; pp. 757–766. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 417–426. [Google Scholar]
- Wu, L.; Sun, P.; Fu, Y.; Hong, R.; Wang, X.; Wang, M. A neural influence diffusion model for social recommendation. In Proceedings of the 42nd international ACM SIGIR Conference on Research and development in information retrieval, Paris, France, 21–25 July 2019; pp. 235–244. [Google Scholar]
- Wu, L.; Li, J.; Sun, P.; Hong, R.; Ge, Y.; Wang, M. Diffnet++: A neural influence and interest diffusion network for social recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4753–4766. [Google Scholar] [CrossRef]
- Song, W.; Xiao, Z.; Wang, Y.; Charlin, L.; Zhang, M.; Tang, J. Session-based social recommendation via dynamic graph attention networks. In Proceedings of the 20th ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 555–563. [Google Scholar]
- Wu, Q.; Zhang, H.; Gao, X.; He, P.; Weng, P.; Gao, H.; Chen, G. Dual graph attention networks for deep latent representation of multifaceted social effects in recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2091–2102. [Google Scholar]
- Jin, B.; Cheng, K.; Zhang, L.; Fu, Y.; Yin, M.; Jiang, L. Partial relationship aware influence diffusion via a multi-channel encoding scheme for social Recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 585–594. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. In Proceedings of the 33th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3558–3565. [Google Scholar]
- Tan, S.; Guan, Z.; Cai, D.; Qin, X.; Bu, J.; Chen, C. Mapping users across networks by manifold alignment on hypergraph. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Quebec, QC, Canada, 27–31 July 2014; pp. 159–165. [Google Scholar]
- Ji, S.; Feng, Y.; Ji, R.; Zhao, X.; Tang, W.; Gao, Y. Dual channel hypergraph collaborative filtering. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 2020–2029. [Google Scholar]
- Zheng, X.; Luo, Y.; Sun, L.; Ding, X.; Zhang, J. A novel social network hybrid recommender system based on hypergraph topologic structure. World Wide Web J. 2018, 21, 985–1013. [Google Scholar] [CrossRef]
- Yang, D.; Qu, B.; Yang, J.; Cudre-Mauroux, P. Revisiting user mobility and social relationships in lbsns: A hypergraph embedding approach. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 2147–2157. [Google Scholar]
- Chai, Y.; Jin, S.; Hou, X. Highway transformer: Self-gating enhanced self-attentive networks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6887–6900. [Google Scholar]
- Ding, K.; Wang, J.; Li, J.; Li, D.; Liu, H. Be more with less: Hypergraph attention networks for inductive text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 4927–4936. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Fang, M.-T.; Przystupa, K.; Chen, Z.-J.; Li, T.; Majka, M.; Kochan, O. Examination of Abnormal Behavior Detection Based on Improved YOLOv3. Electronics 2021, 10, 197. [Google Scholar] [CrossRef]
- Jun, S.; Przystupa, K.; Beshley, M.; Kochan, O.; Beshley, H.; Klymash, M.; Wang, J.; Pieniak, D. A Cost-Efficient Software Based Router and Traffic Generator for Simulation and Testing of IP Network. Electronics 2020, 9, 40. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the 4th ACM International Conference on Web Search and Data Mining, Hong Kong, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Zhang, C.; Yu, L.; Wang, Y.; Shah, C.; Zhang, X. Collaborative user network embedding for social recommender systems. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 381–389. [Google Scholar]
- Liu, X.; He, J.; Duddy, S.; O’Sullivan, L. Convolution-consistent collective matrix completion. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2209–2212. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Details | Gaps |
|---|---|---|
| Attention network-based modeling | The combination of attention mechanisms with different neural network models has yielded fruitful results in social recommendation models, including gated neural network approaches [22], meta-paths [23], and especially joint work with hypergraphs [24] and the application of multilayer attention networks in so cial recommendation models [25]. | User representation modeling |
| Simple graph-based modeling | Different graph neural network models have achieved fruitful results in social recommendation models, including the graph convolution approach [28], graph diffusion approach [29,30,31], etc. | User representation modeling based on different diffusion ideas |
| Hypergraph-based modeling | The application of hypergraphs in social recommendation models has yielded fruitful results, for example, in the literature [34,35,36], especially work on the combination of hypergraphs and matrix decomposition techniques [37] and the combination of hypergraphs and random roaming strategies in social recommendation models [38]. | High-order relations between users and complex relations between users and items |
| Symbol | Description |
|---|---|
| User data. | |
| Item data. | |
| , | User embedding. |
| , | Item embedding. |
| Query embedding. | |
| Embedding of the nodes and . | |
| ReLU activation function. | |
| Encoding function. | |
| Initial embedding of node . | |
| Node embedding of node i at layer . | |
| Importance of the i-th neighbor sampled. | |
| Q | Sum of the neighbors sampled. |
| Relationship of edge . | |
| Relational embedding of relation . | |
| Trainable parameter. | |
| Attention weight. | |
| Embeddings of . | |
| Embeddings of . | |
| Original user embedding. | |
| Original item embedding. | |
| Training weight parameter. | |
| Bias parameter. | |
| Different hypergraph channels. | |
| Sigmoid function. | |
| Trainable weight matrix. | |
| Feature information of node in the lth layer of the neural network. | |
| Weight parameter. | |
| Correlation of node on the hyperedge . | |
| Different weights when super-edge aggregation. | |
| Updated feature information of node . | |
| Weight matrix. | |
| Attention coefficient of node on the hyperedge . | |
| Weight parameter. | |
| Correlation of super-edges at node . | |
| User embedding vector after averaging. | |
| Potential feature vector of the user. | |
| Adjacency matrix. | |
| Row vector of . | |
| Number of the sub-hypergraph. | |
| Readout function. | |
| Discriminant function. | |
| Rating error (RMSE) between and the true value for all pairs in . | |
| Predicted value. | |
| True value. |
| Dataset | Ciao | Epinions |
|---|---|---|
| #of Users | 6776 | 15,210 |
| #of Items | 101,415 | 233,929 |
| #of Interactions | 271,573 | 644,715 |
| Interaction Density | 0.0395% | 0.0181% |
| SoRec | SocialMF | SoReg | CUNE | GCMC + SN | GraphRec | ConsisRec | HGATH | |
|---|---|---|---|---|---|---|---|---|
| Recal@5 | 0.217 | 0.215 | 0.221 | 0.233 | 0.241 | 0.249 | 0.255 | 0.261 |
| Recal@10 | 0.259 | 0.263 | 0.257 | 0.271 | 0.282 | 0.287 | 0.297 | 0.323 |
| NDCG@5 | 0.183 | 0.187 | 0.178 | 0.192 | 0.211 | 0.209 | 0.212 | 0.224 |
| NDCG@10 | 0.198 | 0.207 | 0.211 | 0.228 | 0.241 | 0.238 | 0.249 | 0.267 |
| SoRec | SocialMF | SoReg | CUNE | GCMC + SN | GraphRec | ConsisRec | HGATH | |
|---|---|---|---|---|---|---|---|---|
| Recall@5 | 0.229 | 0.235 | 0.234 | 0.244 | 0.257 | 0.261 | 0.271 | 0.271 |
| Recall@10 | 0.274 | 0.277 | 0.275 | 0.291 | 0.322 | 0.318 | 0.326 | 0.347 |
| NDCG@5 | 0.186 | 0.191 | 0.188 | 0.201 | 0.222 | 0.226 | 0.237 | 0.243 |
| NDCG@10 | 0.208 | 0.211 | 0.215 | 0.233 | 0.251 | 0.256 | 0.266 | 0.275 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Przystupa, K.; Kochan, O. Social Recommendation Algorithm Based on Self-Supervised Hypergraph Attention. Electronics 2023, 12, 906. https://doi.org/10.3390/electronics12040906
Xu X, Przystupa K, Kochan O. Social Recommendation Algorithm Based on Self-Supervised Hypergraph Attention. Electronics. 2023; 12(4):906. https://doi.org/10.3390/electronics12040906
Chicago/Turabian StyleXu, Xiangdong, Krzysztof Przystupa, and Orest Kochan. 2023. "Social Recommendation Algorithm Based on Self-Supervised Hypergraph Attention" Electronics 12, no. 4: 906. https://doi.org/10.3390/electronics12040906