


A Hybrid Attention Network for Malware Detection Based on Multi-Feature Aligned and Fusion

Abstract
:1. Introduction
- We proposed a stacked double-layer convolution network to extract binary file features, which overcame the limitations of the previous image processing method.
- We adopted the triangular attention algorithm to extract opcodes usage patterns, which could focus on the key subroutine in the program while considering the long-distance relationship between function call.
- We used the cross-attention to realize the fusion of different features by enabling cross-modal connections at different depths, which improved the effect of feature representation and brought considerably improved accuracy.
- We collected and labeled the PE format files for the most recent five years on the Malshare website, and the dataset can be further studied.
2. Related Work
2.1. Traditional Static Detection Method
2.2. Dynamic Detection Method
2.3. Multi-Feature Fusion Detection Method
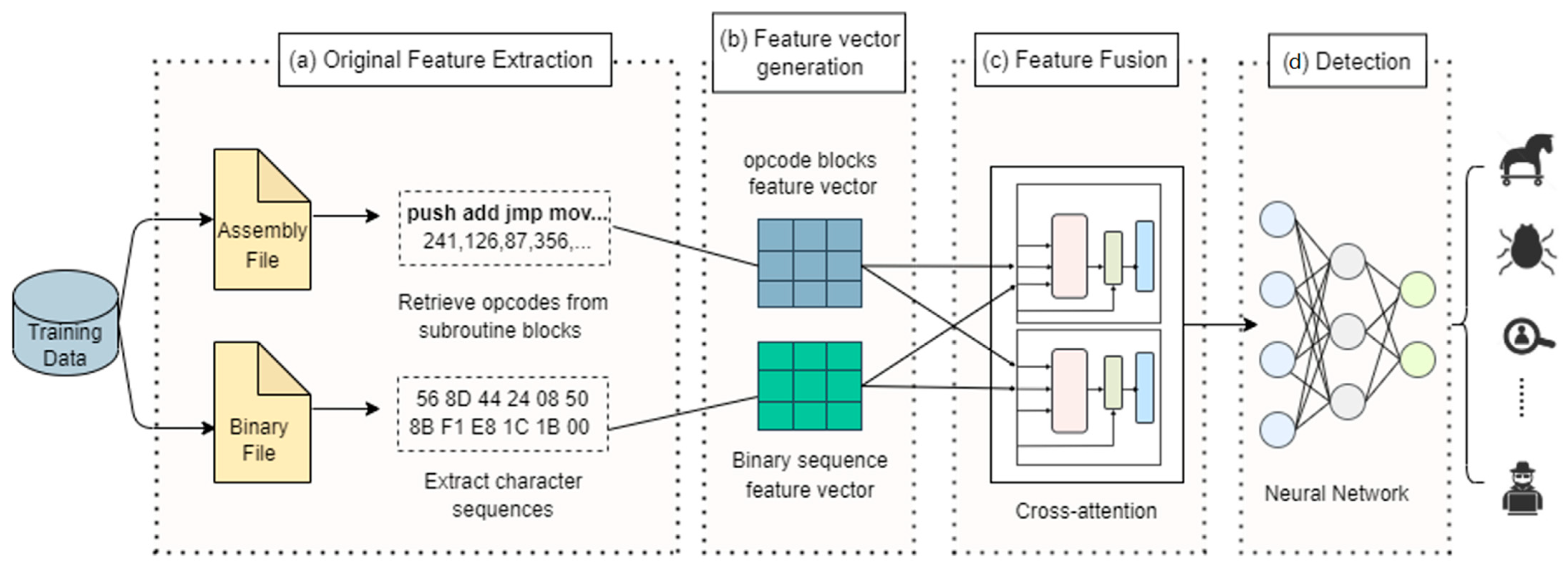
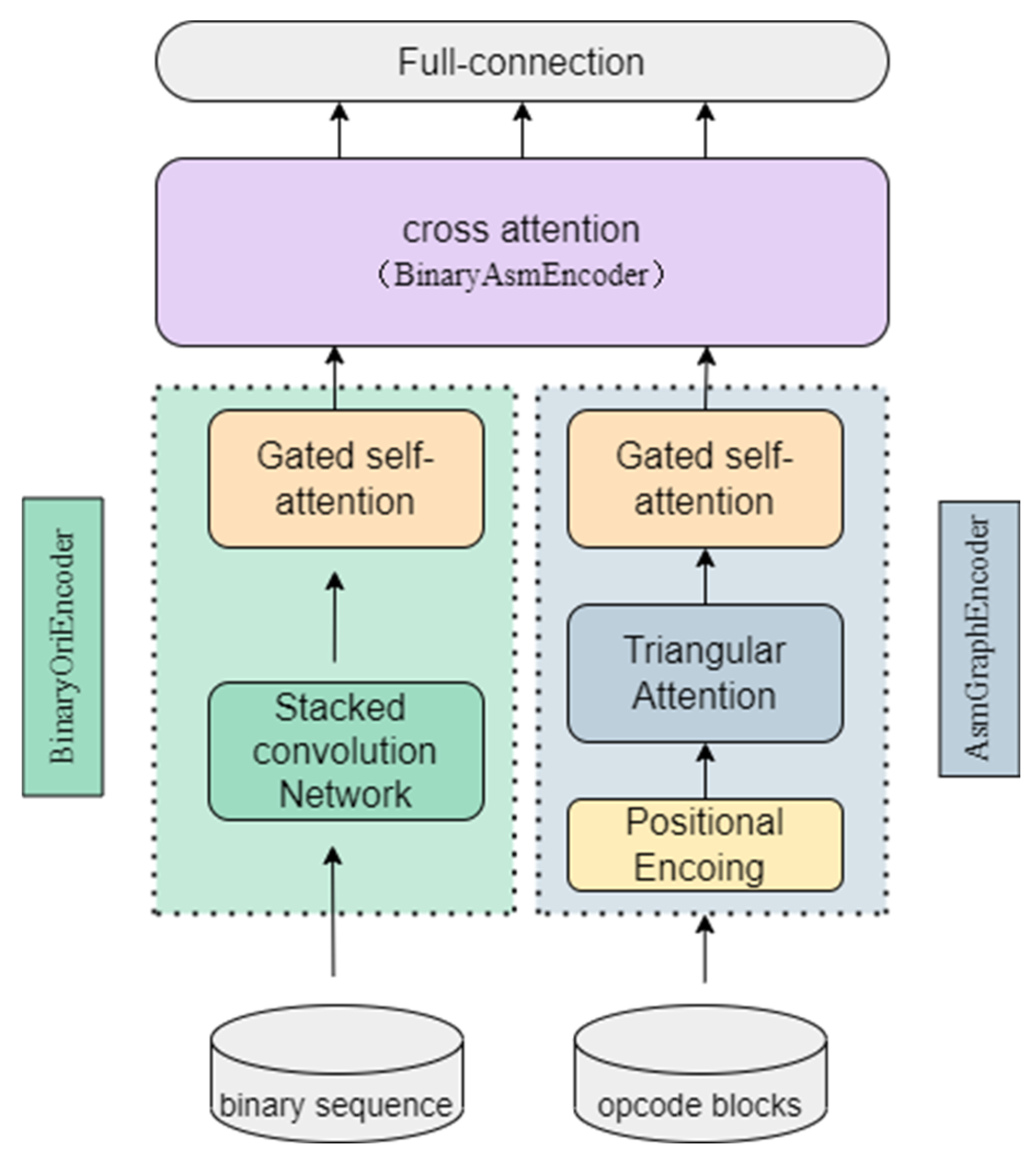
3. Proposed Framework
3.1. Original Feature Extraction Module
3.2. Feature Vector Generation Module
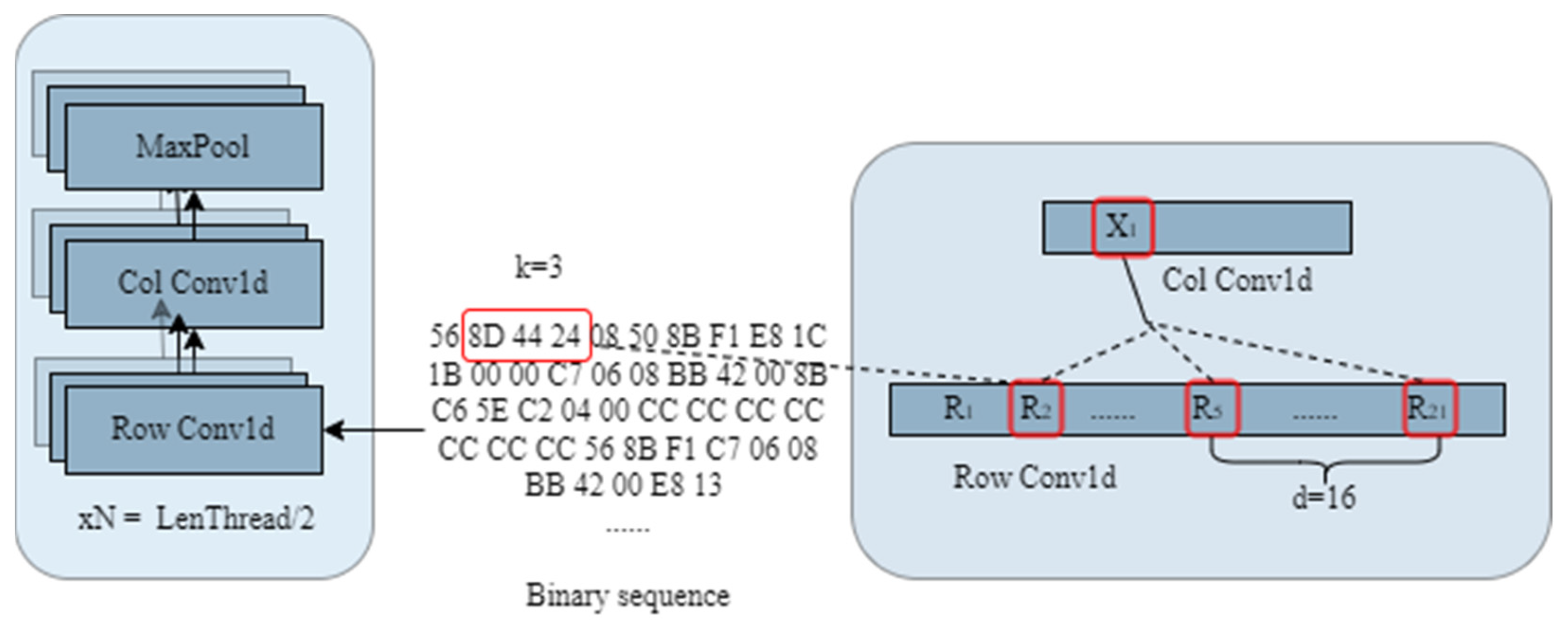
3.2.1. Stacked Convolution Network for Binary Feature Representation
3.2.2. Opcode Embedding
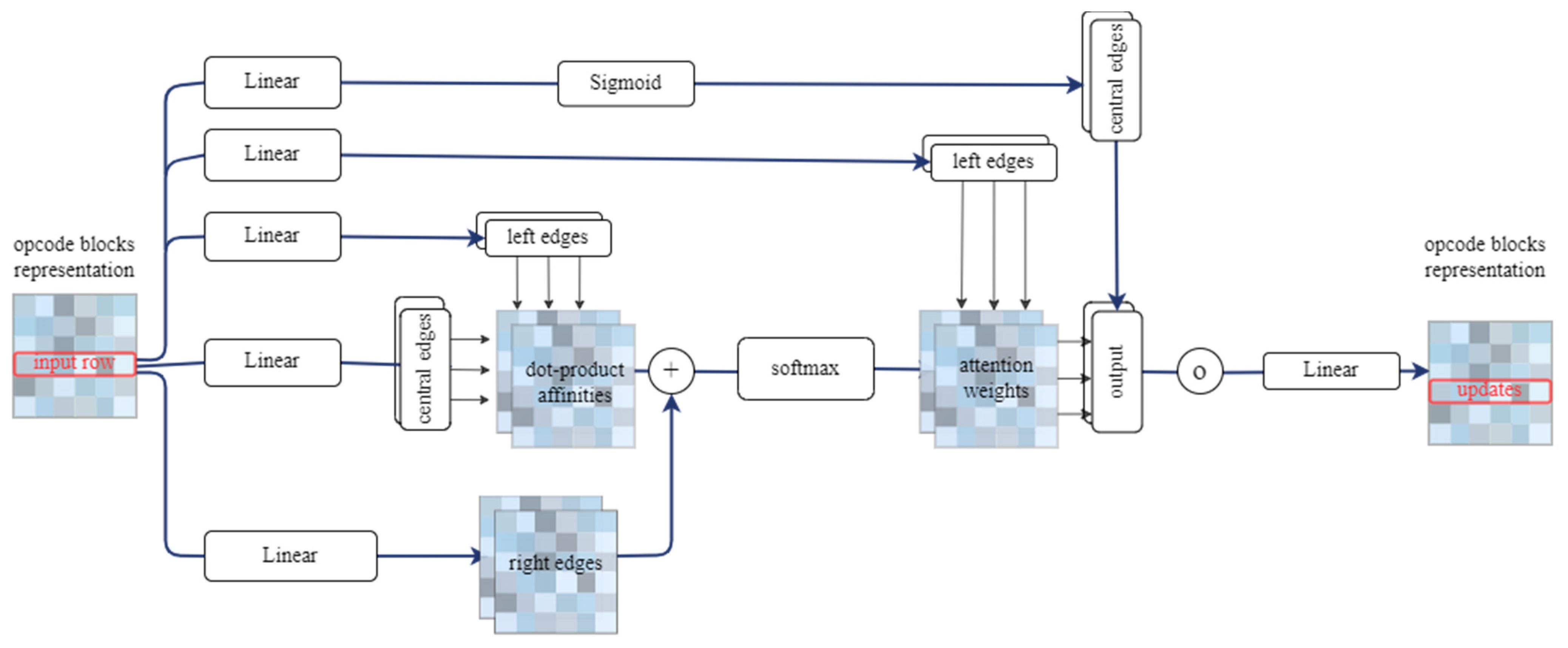
3.2.3. Triangular Attention for Opcode Feature Extracting
3.3. Multi-Feature Fusion Module
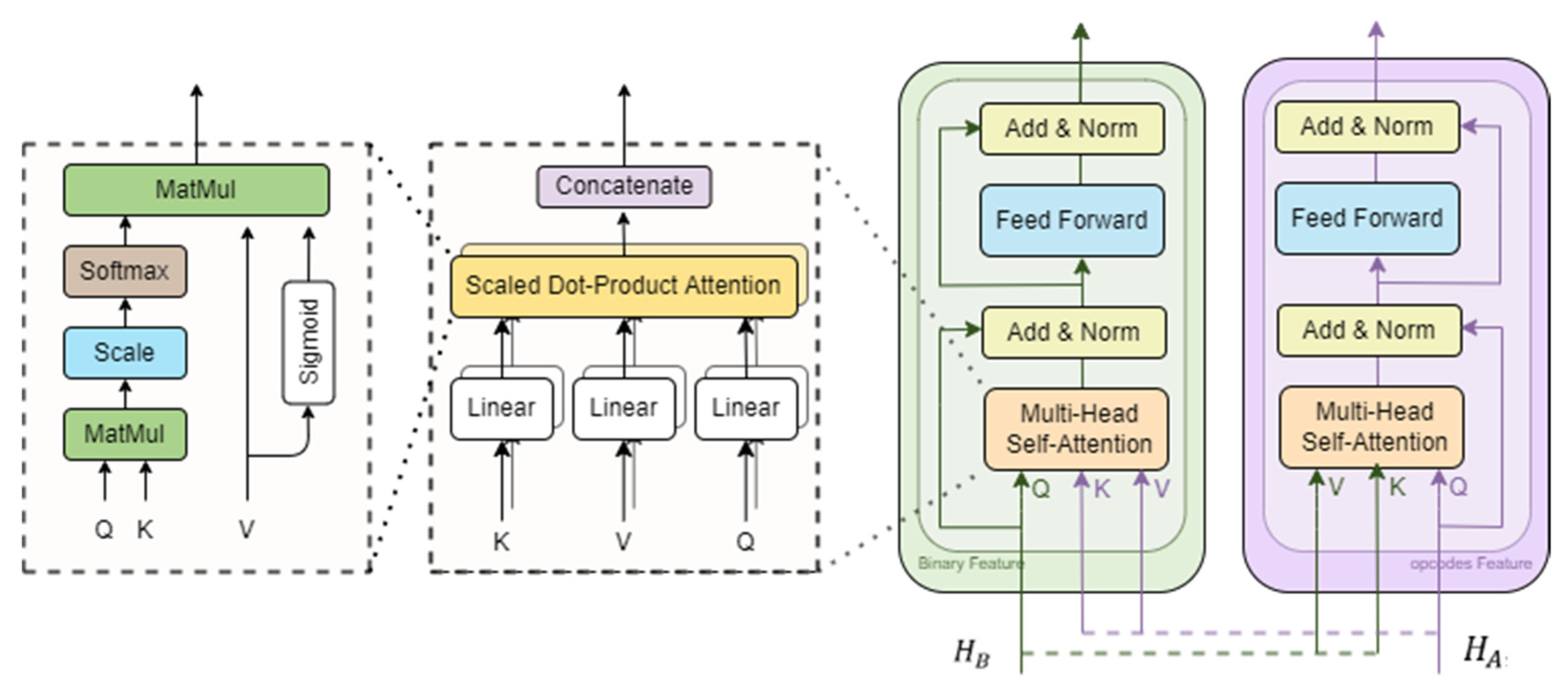
3.3.1. Gated Self-Attention for Further Information Representation
3.3.2. Cross-Attention for Fusion Features Representation
3.4. Detection Model
4. Experiments and Result
4.1. Dataset
4.1.1. Kaggle Malware Classification Challenge
4.1.2. Malshare Dataset
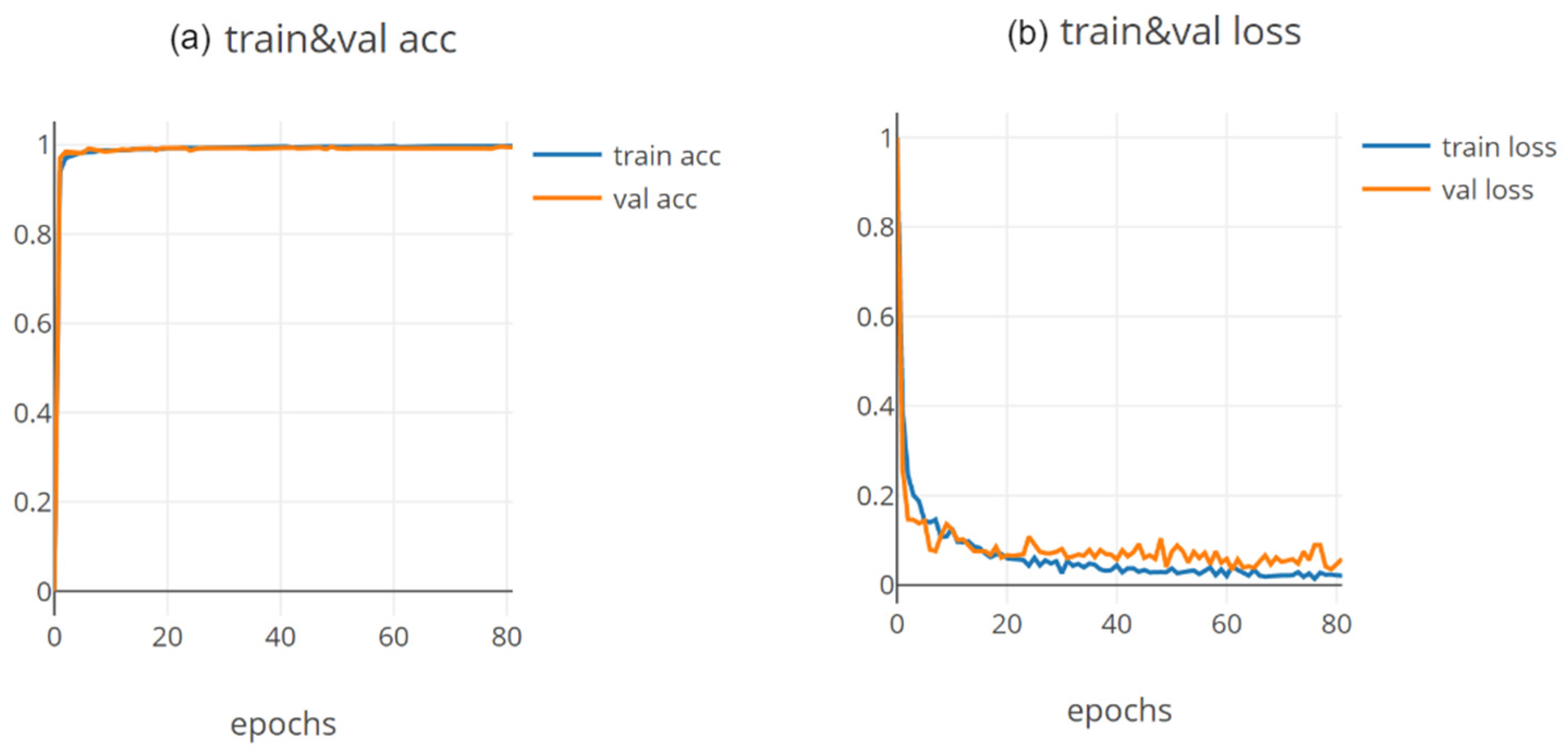
4.2. Experiment Settings
4.3. Evaluation Metrics
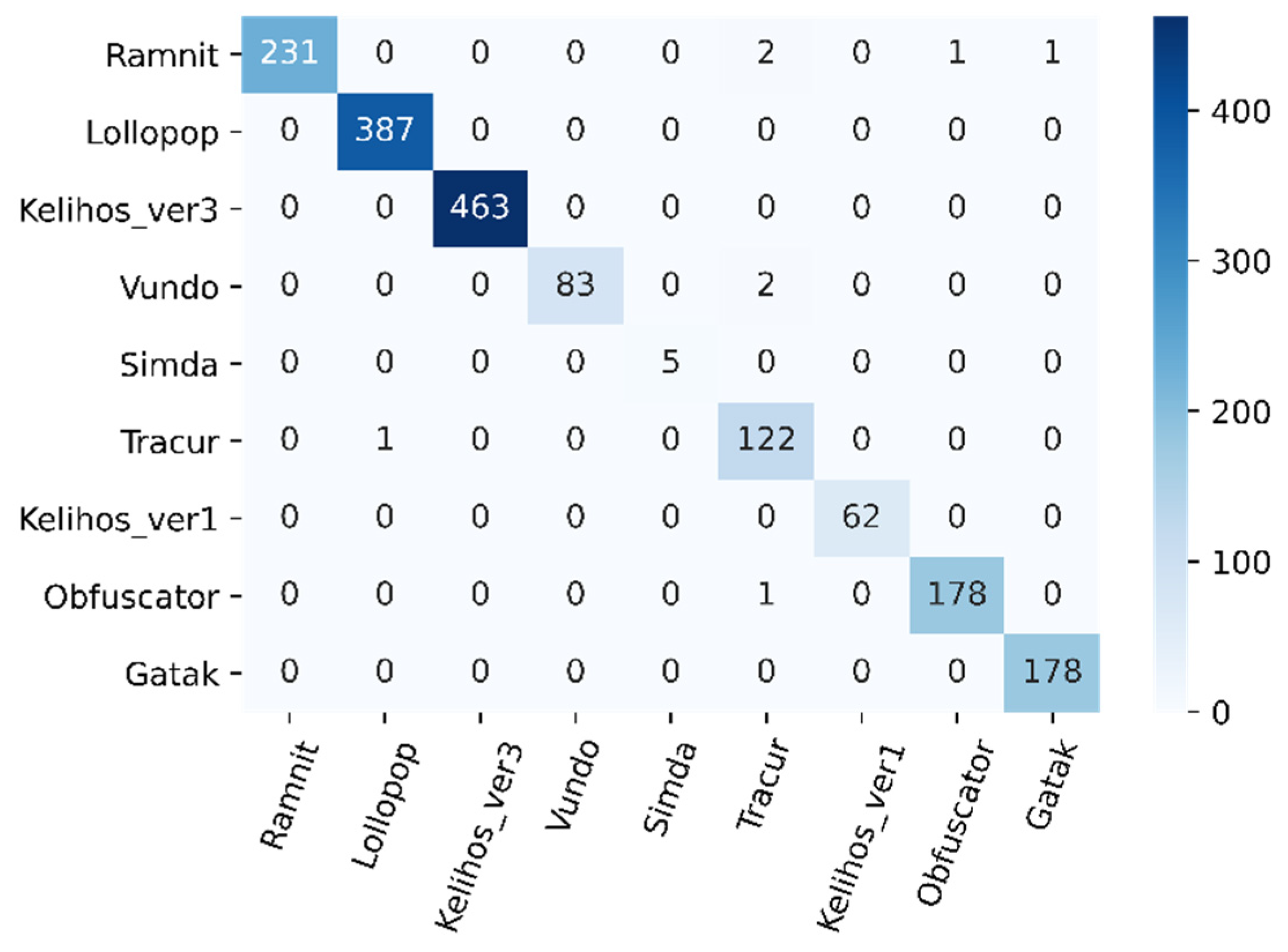
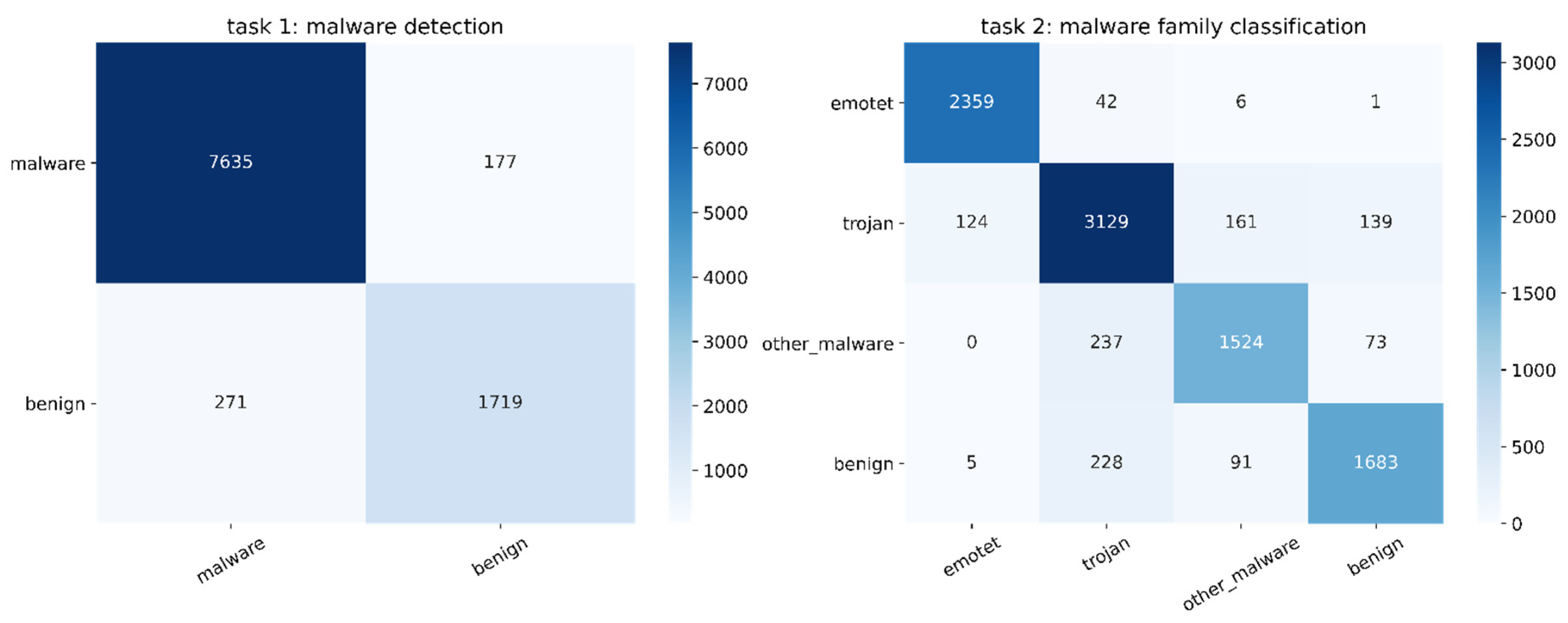
4.4. Malware Family Classification
4.5. Detected Malware from Malshare Website
- Task 1: Identify whether the samples are malware or benign
- Task 2: Identify the family of malware to which the samples belong
5. Discussion
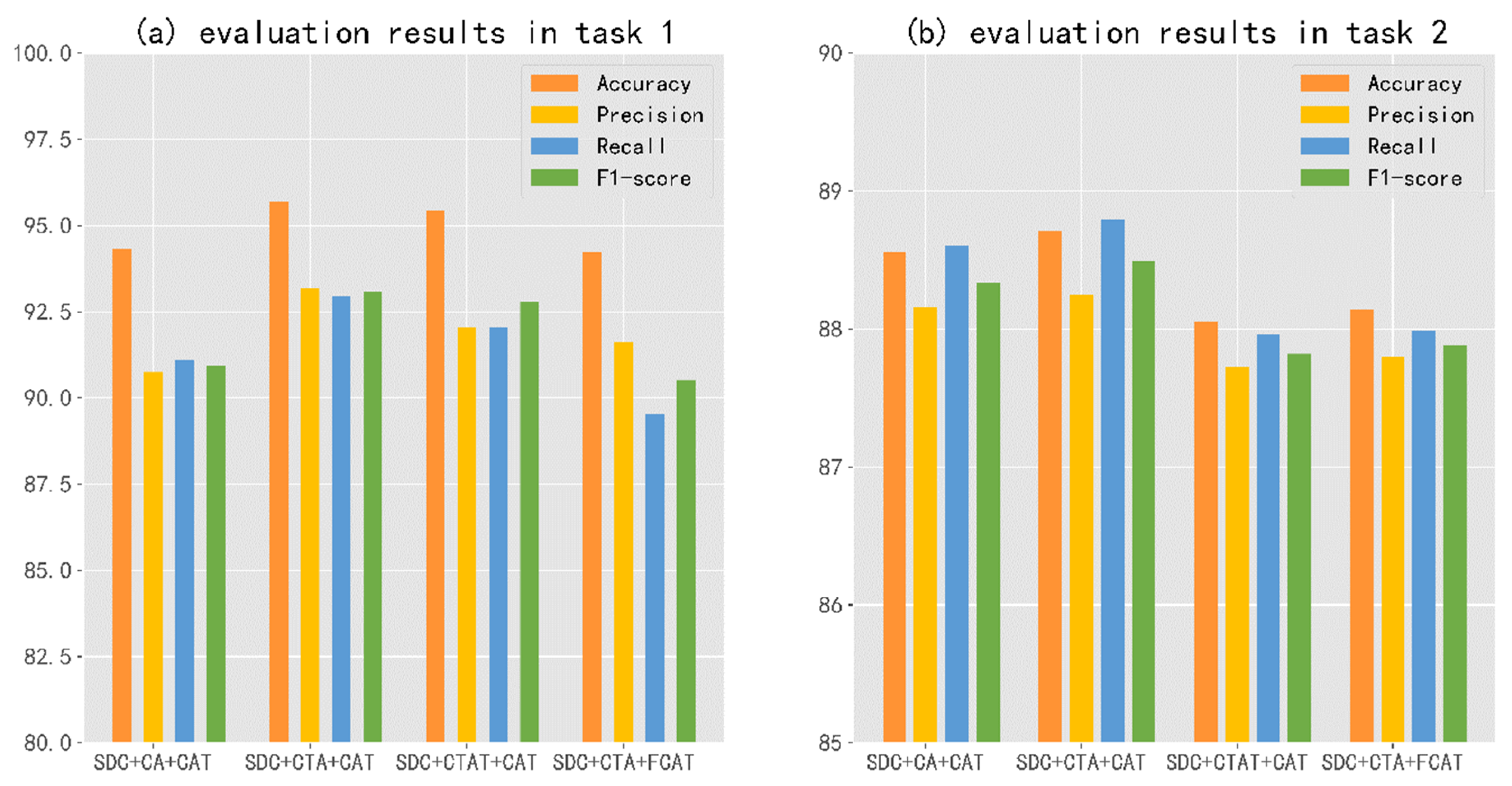
5.1. Ablation Studies
- 1.
- Binary file feature extractor
- 2.
- Opcode block feature extractor
- 3.
- Multi-feature fusion method
- 4.
- Single feature method
- 5.
- Comparison experiments
5.2. Visualization of Attention
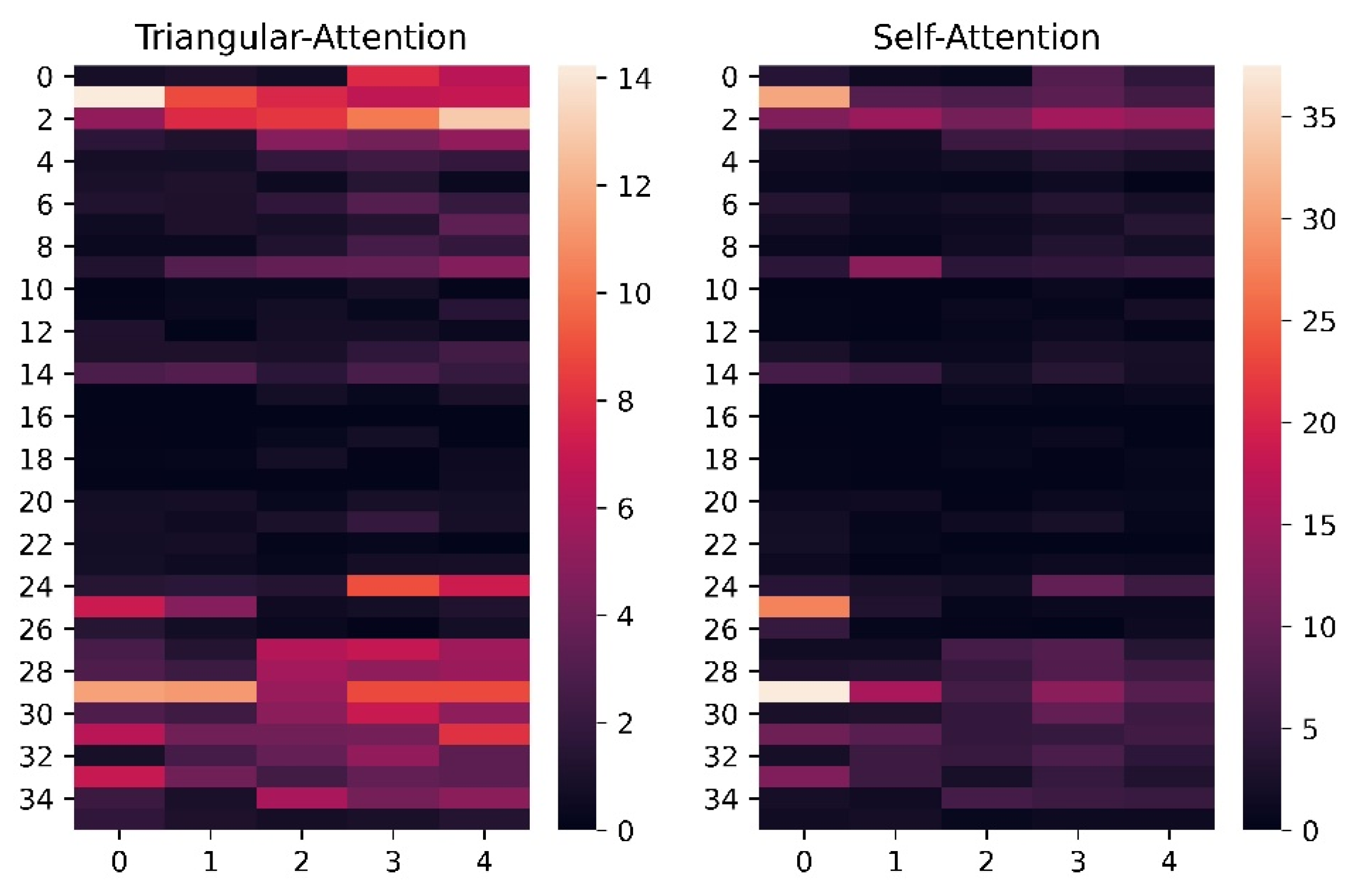
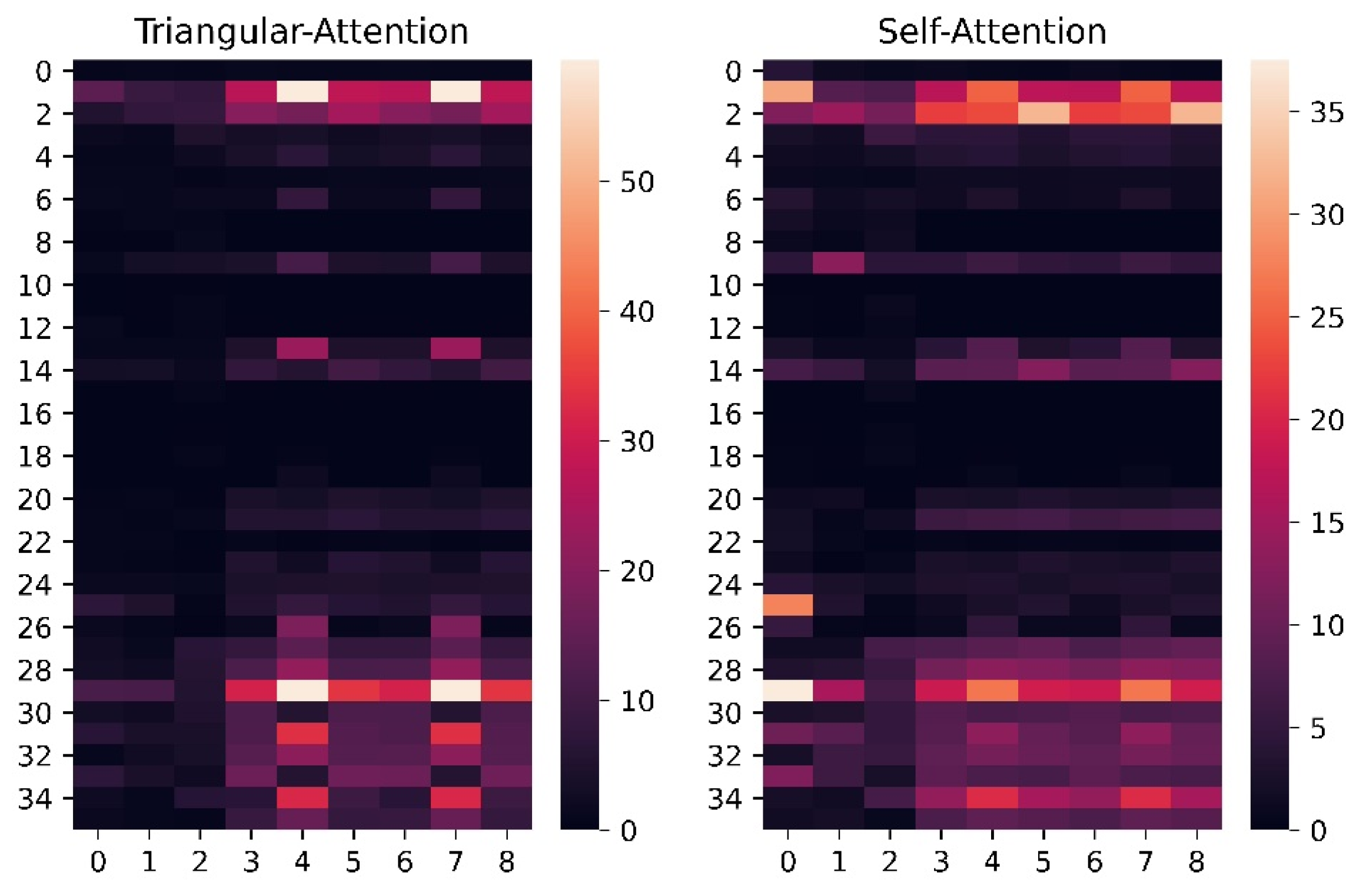
5.2.1. Comparison of Code Block with Attention
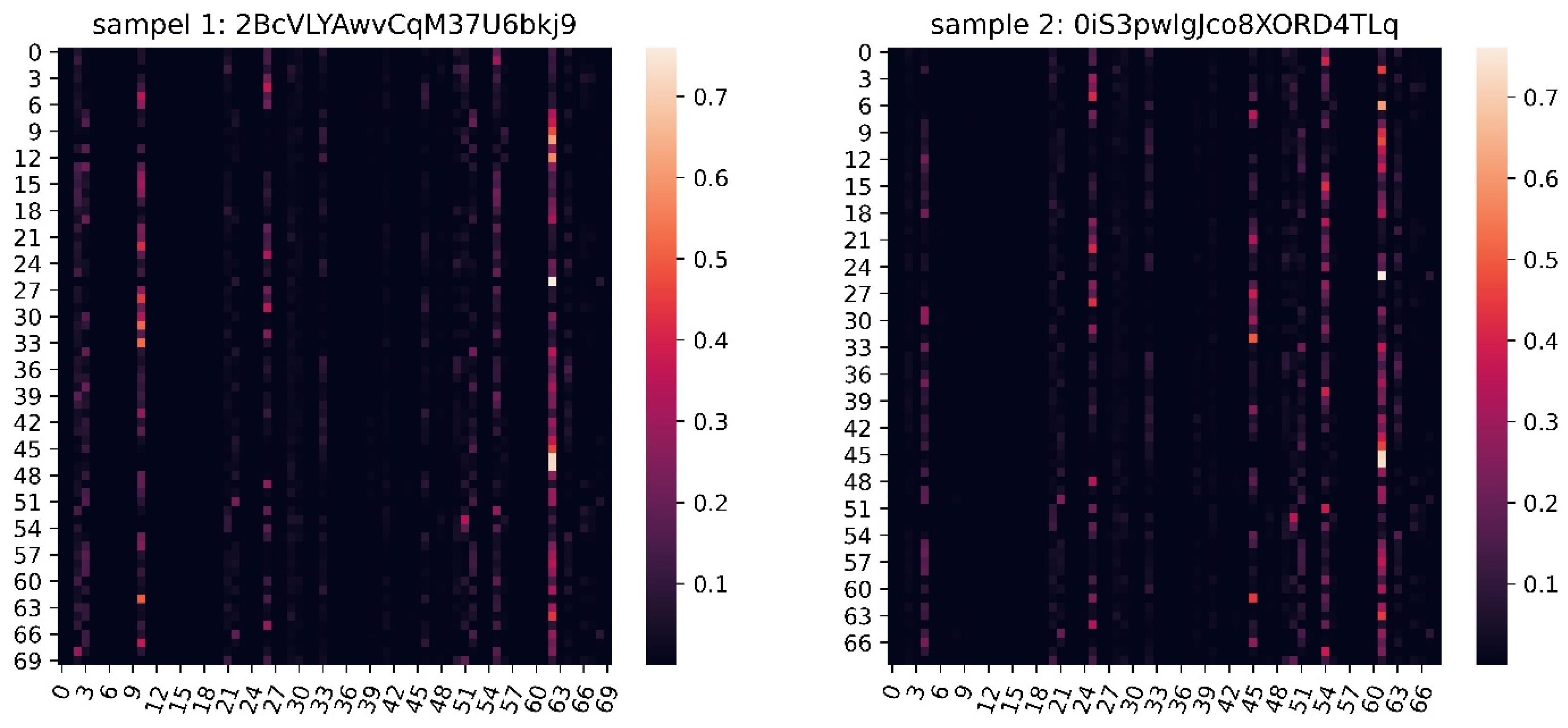
5.2.2. Comparison of Opcode’s Weighting Score
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cohen, M. Scanning memory with yara. Digit. Investig. 2017, 20, 34–43. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, M. Hybrid real-time zero-day malware analysis and reporting system. Int. J. Inf. Technol. Comput. Sci. 2016, 8, 63–73. [Google Scholar] [CrossRef]
- Kolosnjaji, B.; Zarras, A.; Lengyel, T.; Webster, G.; Eckert, C. Adaptive semantics-aware malware classification. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9721, pp. 419–439. [Google Scholar] [CrossRef]
- Huda, S.; Miah, S.; Hassan, M.M.; Islam, R.; Yearwood, J.; Alrubaian, M.; Almogren, A. Defending unknown attacks on cyber-physical systems by semi-supervised approach and available unlabeled data. Inform. Sci. 2017, 379, 211–228. [Google Scholar] [CrossRef]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; ACM: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Park, Y.; Reeves, D.S.; Stamp, M. Deriving common malware behavior through graph clustering. Comput. Secur. 2013, 39, 419–430. [Google Scholar] [CrossRef]
- Kolbitsch, C.; Comparetti, P.M.; Kruegel, C.; Kirda, E.; Zhou, X.; Wang, X. Effective and Efficient Malware Detection at the End Host. In Proceedings of the 18th Conference on USENIX Security Symposium (SSYM’09), Montreal, QC, Canada, 10–14 August 2009; Usenix Association: Berkeley, CA, USA, 2009; pp. 351–366. [Google Scholar]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C. Malware Detection by Eating a Whole EXE. arXiv 2017. [Google Scholar] [CrossRef]
- Guen, K.T.; Kang, B.J.; Mina, R.; Sakir, S.; Gyu, I.E. A multimodal deep learning method for android malware detection using various features. IEEE Trans. Inf. Forensics Secur. 2018, 14, 773–788. [Google Scholar] [CrossRef]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018. [Google Scholar] [CrossRef]
- Fan, J.; Guan, C.; Ren, K.; Cui, Y.; Qiao, C. Spabox: Safeguarding privacy during deep packet inspection at a middlebox. IEEE/ACM Trans. Netw. 2017, 25, 3753–3766. [Google Scholar] [CrossRef]
- Zhang, B.; Yin, J.; Hao, J.; Zhang, D.; Wang, S. Malicious codes detection based on ensemble learning. In International Conference on Autonomic and Trusted Computing; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Shabtai, A.; Moskovitch, R.; Feher, C.; Dolev, S.; Elovici, Y. Detecting unknown malicious code by applying classification techniques on OpCode patterns. Secur. Inform. 2012, 1, 1. [Google Scholar] [CrossRef]
- Sharif, M.I.; Yegneswaran, V.; HSaïdi Porras, P.A.; Lee, W. Eureka: A framework for enabling static malware analysis. In European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Elhadi, A.A.; Maarof, M.A.; Barry, B. Improving the detection of malware behaviour using simplified data dependent api call graph. Int. J. Secur. Its Appl. 2015, 7, 29–42. [Google Scholar] [CrossRef]
- Bidoki, S.M.; Jalili, S.; Tajoddin, A. Pbmmd: A novel policy based multi-process malware detection. Eng. Appl. Artif. Intell. 2017, 60, 57–70. [Google Scholar] [CrossRef]
- Trinius, P.; Willems, C.; Holz, T.; Rieck, K. A malware instruction set for behavior-based analysis. In Sicherheit 2010. Sicherheit, Schutz und Zuverlässigkeit; Freiling, F.C., Ed.; Gesellschaft für Informatik e.V.: Berlin, Germany, 2010; pp. 205–216. [Google Scholar]
- Vasilescu, M.; Gheorghe, L.; Tapus, N. Practical malware analysis based on sandboxing. In Proceedings of the 2014 RoEduNet Conference 13th Edition: Networking in Education and Research Joint Event RENAM 8th Conference, Chisinau, Moldova, 11–13 September 2014. [Google Scholar] [CrossRef]
- Ghiasi, M.; Sami, A.; Salehi, Z. Dynamic VSA: A framework for malware detection based on register contents. Eng. Appl. Artif. Intell. 2015, 44, 111–122. [Google Scholar] [CrossRef]
- Li, S.; Zhou, Q.; Zhou, R.; Lv, Q. Intelligent malware detection based on graph convolutional network. J. Supercomput. 2022, 78, 4182–4198. [Google Scholar] [CrossRef] [PubMed]
- Chai, Y.; Qiu, J.; Su, S.; Zhu, C.; Yin, L.; Tian, Z. LGMal: A Joint Framework Based on Local and Global Features for Malware Detection. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 463–468. [Google Scholar] [CrossRef]
- de Oliveira, A.S.; Sassi, R.J. Behavioral Malware Detection Using Deep Graph Convolutional Neural Networks. TechRxiv 2019. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. A Hierarchical Convolutional Neural Network for Malware Classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- O’Shaughnessy, S.; Sheridan, S. Image-based malware classification hybrid framework based on space-filling curves. Comput. Secur. 2022, 116, 102660. [Google Scholar] [CrossRef]
- Kim, J.; Cho, S. Obfuscated Malware Detection Using Deep Generative Model based on Global/Local Features. Comput. Secur. 2022, 112, 102501. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. arXiv 2021. [Google Scholar] [CrossRef]
- IDA Pro. Available online: https://www.hex-rays.com/products/ida (accessed on 1 September 2017).
- Zhang, J.; Wen, Y. Malware Detection Based on Opcode Dynamic Analysis. EAI Endorsed Trans. Secur. Saf. 2020, 7, e4. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP, ACL, Doha, Qatar, 26–28 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Santana, K.; Ketkar, E. Deep Learning with Python 1; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Tunyasuvunakool, K.; Adler, J.; Wu, Z.; Green, T.; Zielinski, M.; Žídek, A.; Bridgland, A.; Cowie, A.; Meyer, C.; Laydon, A.; et al. Highly accurate protein structure prediction for the human proteome. Nature 2021, 596, 590–596. [Google Scholar] [CrossRef]
- Zhu, S.; Shi, J.; Yang, L.; Qin, B.; Zhang, Z.; Song, L.; Wang, G. Measuring and modeling the label dynamics of online anti-malware engines. In Proceedings of the 29th USENIX Conference on Security Symposium (SEC’20), Online, 12–14 August 2020; USENIX Association: Berkeley, CA, USA; pp. 2361–2378. [Google Scholar]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaeviius, R. An efficient densenet-based deep learning model for malware detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef]
- Roseline, S.A.; Geetha, S.; Kadry, S.; Nam, Y. Intelligent Vision-Based Malware Detection and Classification Using Deep Random Forest Paradigm. IEEE Access 2020, 8, 206303–206324. [Google Scholar] [CrossRef]
- Jian, Y.; Kuang, H.; Ren, C.; Ma, Z.; Wang, H. A novel framework for image-based malware detection with a deep neural network. Comput. Secur. 2021, 109, 102400. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Features | Method |
|---|---|---|
| Static detection | n-gram binary sequence [12] | Probabilistic neural network technique |
| Features set of opcode patterns [13] | K-means and random forest | |
| API calls of Windows System32 files [14] | Support vector machine classifier | |
| API call of malware [15] | Longest common subsequence (LCS) technique | |
| Dynamic detection | Log directory and execution information of binary file [17] | Cuckoo sandbox |
| Contents of CPU registers [19] | Propose an algorithm to find similarities of run-time behaviors | |
| API calls [22] | Depth map convolution neural network | |
| Multi-feature fusion detection | Assemble opcodes and functions [23] | Two-level convolution neural network |
| Assemble opcodes and binary sequence [20] | Convolution neural network | |
| Feature image [24] | Convolution neural network |
| Type | Opcode |
|---|---|
| Operation | ‘jmp’, ‘mov’, ‘push’, ‘pop’, ‘xor’, ‘retn’, ‘sub’, ‘inc’, ‘dec’, ‘add’, ‘imul’, ‘or’, ‘shr’, ‘cmp’, ‘call’, ‘shl’, ‘neg’, ‘jnb’, ‘jb’, ‘jbe’, ‘jz’, ‘lea’, ‘movzx’, ‘test’ |
| Variable | ‘short’, ‘word’, ‘byte’ |
| Register | ‘edx’, ‘esi’, ‘eax’, ‘ebx’, ‘ecx’, ‘edi’, ‘ebp’, ‘esp’ |
| Network | Parameter Setting | Layer | ||
|---|---|---|---|---|
| Stacked Convolution Network (receiving length = 256) | Row conv. | Kernel size: 3 Stride: 1 | repeat time = 1 | input (1000,64) |
| output:(998,64) | ||||
| repeat time = 2 | input (435,64) | |||
| output:(433,64) | ||||
| Col conv. | Kernel size: 3 Stride: 1 Dilation: 64 | repeat time = 1 | input (998,64) | |
| output (870,64) | ||||
| repeat time = 2 | input (433,64) | |||
| output:(305,64) | ||||
| Pool | Kernel size: 2 | repeat time = 1 | input (870,64) | |
| output (435,64) | ||||
| repeat time = 2 | input (305,64) | |||
| output:(152,64) | ||||
| Triangular attention | Head num: 4 | input (20, 36) | ||
| output (20,64) | ||||
| Cross attention | Head num: 4 | input ((20,64), (152,64)) | ||
| output (20,64) | ||||
| Softmax classification | input (20,64) | |||
| output (9) | ||||
| Malware Family | Number of Samples | Description | |
|---|---|---|---|
| Train | Test | ||
| Ramnit | 1301 | 231 | Worm |
| Lollipop | 2081 | 388 | Adware |
| Kelihos ver3 | 2473 | 463 | Backdoor |
| Vundo | 363 | 83 | Trojan |
| Simda | 29 | 5 | Backdoor |
| Tracur | 605 | 127 | Trojan downloader |
| Kelihos ver.1 | 325 | 62 | Backdoor |
| Obfuscator.ACY | 998 | 179 | Obfuscated malware |
| Gatak | 825 | 188 | Backdoor |
| Label | Malware/Benign | Number of Samples |
|---|---|---|
| Emotet | Malware | 6235 |
| Trojan | Malware | 9022 |
| Other malware | Malware | 4529 |
| Benign | Benign | 4837 |
| Total | 34,426 | |
| Authors | Technique | Features | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| Raff et al. 2017 [8] | MalConv | binary sequence | 96.87 | 97.05 | 89.98 | 92.05 |
| Hemalatha et al. 2021 [34] | DenseNet-based | grey image | 98.46 | 98.58 | 97.84 | 98.21 |
| Roseline et al. 2020 [35] | Vision-based | grey image | 97.2 | 96.61 | 96.79 | 97.20 |
| Kim et al. 2022 [25] | Deep Generative model | grey image and binary codes | 97.47 | - | - | - |
| Jian et al. 2021 [36] | Deep Neural Network | binary sequence and opcode | 98.31 | 98.68 | 97.93 | 98.30 |
| Our method | binary sequence and opcode | 99.54 | 99.40 | 99.41 | 99.40 | |
| Method | Task 1: Malware Detected | Task 2: Malware Family Classification | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| MalConv | 88.72 | 82.38 | 80.52 | 81.39 | 83.25 | 84.06 | 82.26 | 83.05 |
| MalConv plus | 87.08 | 82.32 | 82.40 | 75.75 | 78.32 | 80.02 | 79.39 | 78.85 |
| GRU-CNN | 88.96 | 86.09 | 75.93 | 79.56 | 81.44 | 81.48 | 81.42 | 81.34 |
| BiGRU-CNN | 89.04 | 84.48 | 78.13 | 80.71 | 79.98 | 82.26 | 77.47 | 79.28 |
| ResGRU-CNN | 87.87 | 81.15 | 78.46 | 79.68 | 78.72 | 79.36 | 80.40 | 79.13 |
| Our method | 95.44 | 92.06 | 93.62 | 92.81 | 88.71 | 88.25 | 88.79 | 88.49 |
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Model 1: ImgVIT + CA + Add | 98.32 | 97.25 | 98.02 | 97.42 |
| Model 2: ImgVIT + CA + CAT | 98.73 | 97.62 | 97.96 | 97.35 |
| Model 3: SDC + CA + CAT | 99.59 | 99.34 | 99.36 | 99.42 |
| Model 4 (proposed model): SDC + CTA + CAT | 99.54 | 99.40 | 99.41 | 99.40 |
| Model 5: SDC + CTAT + CAT | 99.30 | 99.16 | 99.30 | 99.22 |
| Model 6: SDC + CTA + FCAT | 99.36 | 99.27 | 97.13 | 98.08 |
| Model 7: SDC + MLP | 97.33 | 97.15 | 97.33 | 97.23 |
| Model 8: CTA + MLP | 95.92 | 96.29 | 96.40 | 96.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yang, D.; Li, Y. A Hybrid Attention Network for Malware Detection Based on Multi-Feature Aligned and Fusion. Electronics 2023, 12, 713. https://doi.org/10.3390/electronics12030713
Yang X, Yang D, Li Y. A Hybrid Attention Network for Malware Detection Based on Multi-Feature Aligned and Fusion. Electronics. 2023; 12(3):713. https://doi.org/10.3390/electronics12030713
Chicago/Turabian StyleYang, Xing, Denghui Yang, and Yizhou Li. 2023. "A Hybrid Attention Network for Malware Detection Based on Multi-Feature Aligned and Fusion" Electronics 12, no. 3: 713. https://doi.org/10.3390/electronics12030713