
Optimized and Efficient Image-Based IoT Malware Detection Method
 , and
on behalf of the Scientific Research Group
, and
on behalf of the Scientific Research Group
Abstract
:1. Introduction
- Employing the ACO algorithm as a feature selection technique, i.e., selecting a minimum number of features while improving the classification results of an image-based malware detection system using the SVM classifier.
- Determining the best SVM kernel function gives the best results of the proposed method.
- Utilizing the PSO algorithm for tuning the SVM parameters of the best-determined kernel function.
- Integrating bio-inspired and ML techniques in proposing a malware detection approach can be effectively used in the IoT environment.
- Evaluating the proposed approach in terms of various evaluation metrics: accuracy, recall, precision, and F1-score and comparing it with the most related published work.
2. Literature Review
3. Work Preliminaries
3.1. Ant Colony Optimization
3.2. Particle Swarm Optimization (PSO)
3.3. Support Vector Machines
4. The Proposed IoT Malware Detection System
4.1. Pre-Processing Phase
4.2. Feature Extraction Phase
4.3. Feature Selection Phase
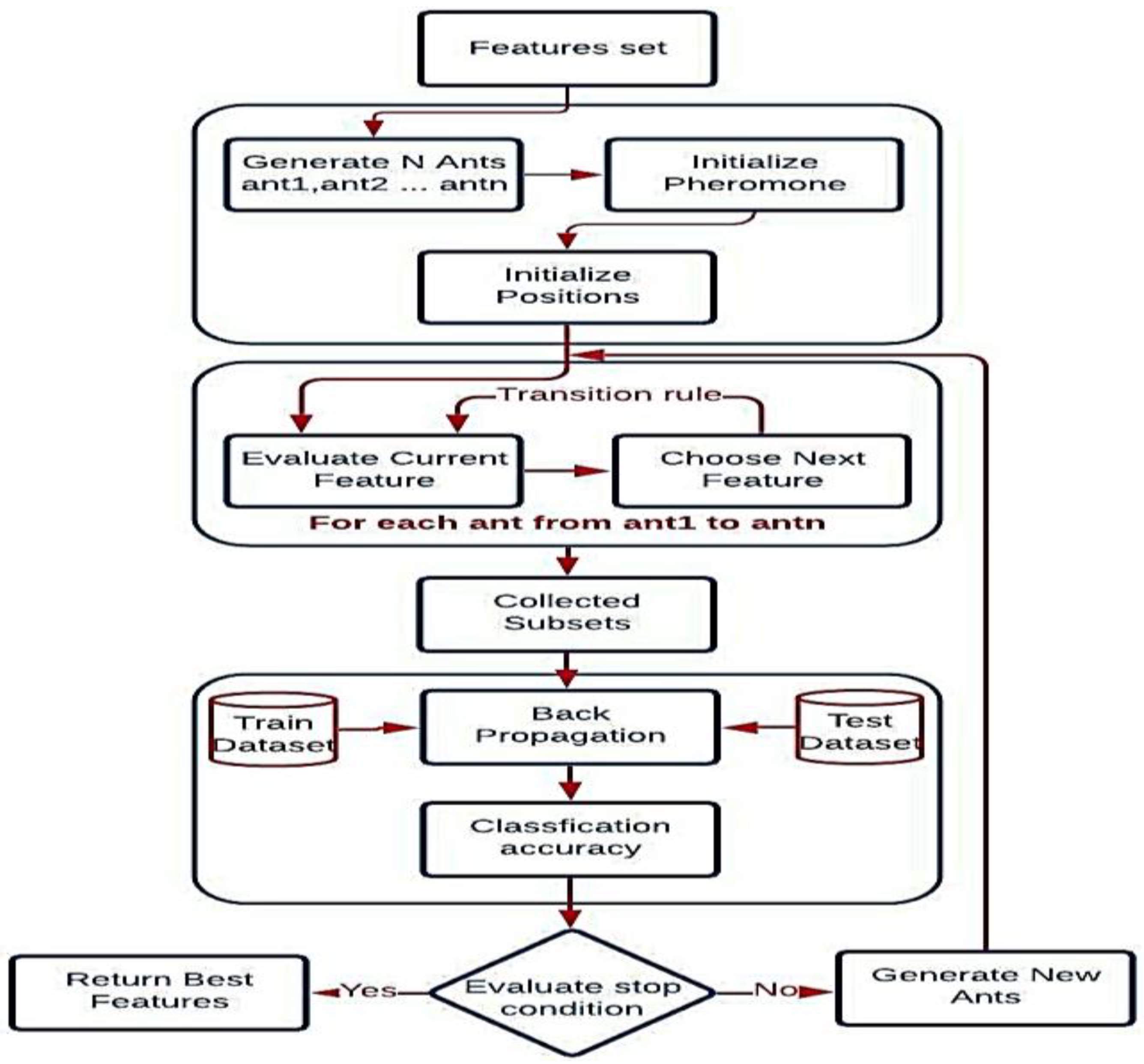
4.3.1. Feature Selection Using ACO
4.3.2. Fitness Function
4.4. PSO-Based SVM Classification Phase
5. Experiments and Results
5.1. Dataset Description
5.2. Evaluation Metrics
5.3. Results and Discussion
5.4. Comparison with Literature
5.5. Deep Learning vs. Classical Machine Learning in IDS
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nobakht, M.; Sivaraman, V.; Boreli, R. A Host-Based Intrusion Detection and Mitigation Framework for Smart Home IoT Using Openflow. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; pp. 147–156. [Google Scholar]
- Statista Research Department. Internet of Things (IoT) Connected Devices Installed Base Worldwide from 2015 to 2025 (In Billions). Available online: https://bit.ly/2DhYEL0 (accessed on 25 November 2019).
- Salloum, S.; Gaber, T.; Vadera, S.; Shaalan, K. Phishing email detection using natural language processing techniques: A literature survey. Procedia Comput. Sci. 2021, 189, 19–28. [Google Scholar] [CrossRef]
- Avast. Avast Smart Home Security Report 2019. Available online: https://bit.ly/2pOSf70 (accessed on 25 November 2019).
- Antonakakis, M.; April, T.; Bailey, M.; Bernhard, M.; Bursztein, E.; Cochran, J.; Durumeric, Z.; Halderman, J.A.; Invernizzi, L.; Kallitsis, M.; et al. Understanding the Mirai Botnet. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canda, 16–18 August 2017; pp. 1093–1110. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDos in the IoT: Mirai and other botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Kambourakis, G.; Kolias, C.; Stavrou, A. The Mirai Botnet and the IoT Zombie Armies. In Proceedings of the MILCOM 2017–2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 267–272. [Google Scholar]
- Madan, S.; Sofat, S.; Bansal, D. Tools and Techniques for Collection and Analysis of Internet-of-Things malware: A systematic state-of-art review. J. King Saud Univ. Comput. Inf. 2022, 34, 9867–9888. [Google Scholar] [CrossRef]
- Gaber, T.; El-Ghamry, A.; Hassanien, A.E. Injection attack detection using machine learning for smart IoT applications. Phys. Commun. 2022, 52, 101685. [Google Scholar] [CrossRef]
- Intrusion Detection and Prevention Systems. Available online: https://bit.ly/37Bxvki (accessed on 25 November 2019).
- Keegan, N.; Ji, S.Y.; Chaudhary, A.; Concolato, C.; Yu, B.; Jeong, D.H. A survey of cloud-based network intrusion detection analysis. Hum. Cent. Comput. Inf. Sci. 2016, 6, 19. [Google Scholar] [CrossRef] [Green Version]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Baptista, I. Binary visualization for malware detection. Plymouth Stud. Sci. 2018, 11, 223–237. [Google Scholar]
- Bendiab, G.; Shiaeles, S.; Alruban, A.; Kolokotronis, N. IoT Malware Network Traffic Classification Using Visual Representation and Deep Learning. In Proceedings of the 2020 6th IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020; pp. 444–449. [Google Scholar]
- Naeem, H.; Guo, B.; Naeem, M.R. A Lightweight Malware Static Visual Analysis for IoT Infrastructure. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–28 May 2018; pp. 240–244. [Google Scholar]
- Su, J.; Vasconcellos, D.V.; Prasad, S.; Sgandurra, D.; Feng, Y.; Sakurai, K. Lightweight Classification of IoT Malware Based on Image Recognition. In Proceedings of the 2018 IEEE 42Nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 664–669. [Google Scholar]
- Han, K.S.; Lim, J.H.; Kang, B.; Im, E.G. Malware analysis using visualized images and entropy graphs. Int. J. Inf. Secur. 2015, 14, 1–4. [Google Scholar] [CrossRef]
- Thompson, N.C.; Greenewald, K.; Lee, K.; Manso, G.F. Deep Learning’s Diminishing Returns: The Cost of Improvement is Becoming Unsustainable. IEEE Spectr. 2021, 58, 50–55. [Google Scholar] [CrossRef]
- Agarwal, N.; Sondhi, A.; Chopra, K.; Singh, G. Transfer Learning: Survey and Classification. In Smart Innovations in Communication and Computational Sciences; Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 145–155. [Google Scholar]
- Niu, S.; Liu, Y.; Wang, J.; Song, H. A decade survey of transfer learning (2010–2020). IEEE Trans. Artif. Intell. 2020, 1, 151–166. [Google Scholar] [CrossRef]
- Nataraj, L.; Yegneswaran, V.; Porras, P.; Zhang, J. A Comparative Assessment of Malware Classification Using Binary Texture Analysis and Dynamic Analysis. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence 2011, Chicago, IL, USA, 21 October 2011; pp. 21–30. [Google Scholar]
- Makandar, A.; Patrot, A. Malware Class Recognition Using Image Processing Techniques. In Proceedings of the 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI), Pune, India, 24–26 February 2017; pp. 76–80. [Google Scholar]
- Liu, L.; Wang, B. Malware Classification Using Gray-Scale Images and Ensemble Learning. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2016; pp. 1018–1022. [Google Scholar]
- Tuncer, T.; Ertam, F.; Dogan, S. Automated malware identification method using image descriptors and singular value decomposition. Multimed. Tools Appl. 2021, 80, 10881–10900. [Google Scholar] [CrossRef]
- Alani, M.M.; Awad, A.I. AdStop: Efficient flow-based mobile adware detection using machine learning. Comput. Secur. 2022, 117, 102718. [Google Scholar] [CrossRef]
- Acharya, S.; Rawat, U.; Bhatnagar, R. A Low Computational Cost Method for Mobile Malware Detection Using Transfer Learning and Familial Classification Using Topic Modelling. Appl. Comput. Intell. Soft Comput. 2022, 2022, 4119500. [Google Scholar] [CrossRef]
- Zhang, W.; Luktarhan, N.; Ding, C.; Lu, B. Android malware detection using TCN with bytecode image. Symmetry 2021, 13, 1107. [Google Scholar] [CrossRef]
- Al-Fawa’reh, M.; Saif, A.; Jafar, M.T.; Elhassan, A. Malware Detection by Eating a Whole APK. In Proceedings of the 2020 15th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 8–10 December 2020; pp. 1–7. [Google Scholar]
- Peng, T.; Hu, B.; Liu, J.; Huang, J.; Zhang, Z.; He, R.; Hu, X. A Lightweight Multi-Source Fast Android Malware Detection Model. Appl. Sci. 2022, 12, 5394. [Google Scholar] [CrossRef]
- Hadiprakoso, R.B.; Kabetta, H.; Buana, I.K.S. Hybrid-Based Malware Analysis for Effective and Efficiency Android Malware Detection. In Proceedings of the 2020 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), Jakarta, Indonesia, 19–20 November 2020; pp. 8–12. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic Android Malware Category Classification Using Semi-Supervised Deep Learning. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Shire, R.; Shiaeles, S.; Bendiab, K.; Ghita, B.; Kolokotronis, N. Malware Squid: A Novel IoT Malware Traffic Analysis Framework Using Convolutional Neural Network and Binary Visualization. In Internet of Things, Smart Spaces, and Next Generation Networks and Systems; Springer: Cham, Switzerland, 2019; pp. 65–76. [Google Scholar]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.; Wang, Y.; Iqbal, F. Malware Classification with Deep Convolutional Neural Networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Cui, Z.; Du, L.; Wang, P.; Cai, X.; Zhang, W. Malicious code detection based on CNNs and multi-objective algorithm. J. Parallel Distrib. Comput. 2019, 129, 50–58. [Google Scholar] [CrossRef]
- Akarsh, S.; Simran, K.; Poornachandran, P.; Menon, V.K.; Soman, K.P. Deep Learning Framework and Visualization for Malware Classification. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 1059–1063. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Z.; Wang, F.; Li, Q. A novel malware detection and family classification scheme for IoT based on DEAM and DenseNet. Secur. Commun. Netw. 2021, 2021, 6658842. [Google Scholar] [CrossRef]
- Moti, Z.; Hashemi, S.; Karimipour, H.; Dehghantanha, A.; Jahromi, A.N.; Abdi, L.; Alavi, F. Generative Adversarial Network to Detect Unseen Internet of Things Malware. In Ad Hoc Networks; Elsevier: Amsterdam, The Netherlands, 2021; Volume 122, p. 102591. [Google Scholar]
- Asam, M.; Khan, S.H.; Akbar, A.; Bibi, S.; Jamal, T.; Khan, A.; Ghafoor, U.; Bhutta, M.R. IoT malware detection architecture using a novel channel boosted and squeezed CNN. Sci. Rep. 2022, 12, 15498. [Google Scholar] [CrossRef]
- Marín, G.; Caasas, P.; Capdehourat, G. Deepmal-Deep Learning Models for Malware Traffic Detection and Classification. In Data Science–Analytics and Applications; Springer Vieweg: Wiesbaden, Germany, 2021; pp. 105–112. [Google Scholar]
- Xu, P.; Eckert, C.; Zarras, A. Falcon: Malware Detection and Categorization with Network Traffic Images. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2021; pp. 117–128. [Google Scholar]
- Ullah, F.; Alsirhani, A.; Alshahrani, M.M.; Alomari, A.; Naeem, H.; Shah, S.A. Explainable malware detection system using transformers-based transfer learning and multi-model visual representation. Sensors 2022, 22, 6766. [Google Scholar] [CrossRef] [PubMed]
- Ullah, F.; Ullah, S.; Naeem, M.R.; Mostarda, L.; Rho, S.; Cheng, X. Cyber-threat detection system using a hybrid approach of transfer learning and multi-model image representation. Sensors 2022, 22, 5883. [Google Scholar] [CrossRef]
- Saridou, B.; Rose, J.R.; Shiaeles, S.; Papadopoulos, B. SAGMAD—A Signature Agnostic Malware Detection System Based on Binary Visualisation and Fuzzy Sets. Electronics 2022, 11, 1044. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M.; Schaefer, G. Cost-sensitive decision tree ensembles for effective imbalanced classification. Appl. Soft Comput. 2014, 14, 554–562. [Google Scholar] [CrossRef] [Green Version]
- Dorigo, M.; Di Caro, G.; Gambardella, L.M. Ant algorithms for discrete optimization. Artif. Life 1999, 5, 137–172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Stefanowski, J. Dealing with Data Difficulty Factors While Learning from Imbalanced Data. In Challenges in Computational Statistics and Data Mining; Springer: Cham, Switzerland, 2016; pp. 333–363. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Dhal, P.; Azad, C. A comprehensive survey on feature selection in the various fields of machine learning. Appl. Intell. 2021, 52, 4543–4581. [Google Scholar] [CrossRef]
- Torabi, M.; Udzir, N.I.; Abdullah, M.T.; Yaakob, R. A review on feature selection and ensemble techniques for intrusion detection system. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 538–553. [Google Scholar] [CrossRef]
- Aghdam, M.H.; Kabiri, P. Feature selection for intrusion detection system using ant colony optimization. Int. J. Netw. Secur. 2016, 18, 420–432. [Google Scholar]
- Ibrahim, N.M.; Zainal, A. A feature selection technique for Cloud IDS using Ant Colony Optimization and Decision Tree. Adv. Sci. Lett. 2017, 23, 9163–9169. [Google Scholar] [CrossRef]
- Sokkalingam, S.; Ramakrishnan, R. An intelligent intrusion detection system for distributed denial of service attacks: A support vector machine with hybrid optimization algorithm-based approach. Concurr. Comput. Pract. Exp. 2022, 34, e7334. [Google Scholar] [CrossRef]
- Kunhare, N.; Tiwari, R.; Dhar, J. Particle swarm optimization and feature selection for intrusion detection system. Sādhanā 2020, 45, 109. [Google Scholar] [CrossRef]
- Cho, M.Y.; Hoang, T.T. Feature selection and parameters optimization of SVM using particle swarm optimization for fault classification in power distribution systems. Comput. Intell. Neurosci. 2017, 2017, 4135465. [Google Scholar] [CrossRef] [PubMed]
- Ab Wahab, M.N.; Nefti-Meziani, S.; Atyabi, A. A comprehensive review of swarm optimization algorithms. PLoS ONE 2015, 10, e0122827. [Google Scholar] [CrossRef] [Green Version]
- Haidar, A.; Field, M.; Sykes, J.; Carolan, M.; Holloway, L. PSPSO: A package for parameters selection using particle swarm optimization. SoftwareX 2021, 15, 100706. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Advances in Computer Vision, Proceedings of the Science and Information Conference, Tokyo, Japan, 16–19 March 2019; Springer: Cham, Switzerland, 2019; pp. 128–144. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Feature Extraction | Classifier | Dataset | Testing Results | Limitation |
|---|---|---|---|---|---|---|
| Nataraj [21] | 2011 | GIST | KNN | Host-Rx Reference, Host-Rx Application, Malhuer Reference, Malheur Application, VXHeavens | 97.18% accuracy | High computational overhead can be beaten by attackers. |
| Robert [32] | 2019 | CNN | CNN | Self-collected dataset | 91.32% accuracy | Limited samples did not consider encrypted traffic |
| Bendiab [14] | 2020 | CNN | CNN | Self-collected dataset | 94.5% accuracy | Low accuracy rate |
| Naeem [15] | 2018 | D-SIFT and GIST | SVM | Collected from the vision research lab of the University of California | 97.4% accuracy | Windows-based malware, high computation time |
| Su [16] | 2018 | CNN | CNN | IoT DDoS malware dataset newly collected by IoTPOT | 94% accuracy | The limited dataset in size and diversity |
| Makandar [22] | 2017 | GIST and Discrete Wavelet Transform | SVM and KNN | Malimg Dataset | 98.84% and 98.88% accuracy | Limited samples |
| Liu [23] | 2016 | Local mean | Ensemble learning based on K-means and bagging | Self-collected dataset | 98.2% accuracy | Cannot deal with packet encryption, compression, deformation |
| Han [17] | 2015 | Entropy Graphs | The similarity between Entropy Graphs | Self-collected dataset from VX Heavens http://vx.netlux.org/index.html (accessed on 1 December 2022) | 97.9% accuracy | Works for windows PE files, cannot deal with packed samples |
| Kalash [33] | 2018 | CNN | CNN | Malimg and Microsoft Datasets | 98.52% accuracy | The network architecture of CNN(VGG16) requires a long training time. |
| Cui [35] | 2019 | CNN | CNN | Image dataset from Vision Research Lab. | 97.6% accuracy | Not appropriate with bigger scale images, long training time |
| Akarsh [35] | 2019 | CNN-LSTM | CNN-LSTM | Malimg dataset | 94.4% accuracy | Low accuracy rate, result comparison based on one literature. |
| Turker [25] | 2021 | hybrid LBP-SVD-LTPNet | LDA | Malimg dataset | 88.08% accuracy | Lower accuracy rate compared with CNN+LSTM model. |
| Wang [36] | 2021 | CNN | CNN | Malimg dataset, Microsoft malware classification challenge dataset (BIG 2015) | 97.3% accuracy | No data balancing |
| Moti [37] | 2021 | GAN with CNN | CNN, LSTM | Standard Windows and IoT malware datasets. | accuracy: 97.56 F1 score: 97.61 | Computational training time complexity |
| Asam [39] | 2022 | CNN | CNN | Self-collected IoT dataset | accuracy: 97.93%, F1-Score: 93.94%, precision: 98.64%, recall: 88.73%, | Low recall and F1 score values |
| Marin [39] | 2021 | 1D-CNN + LSTM | 1D-CNN + LSTM | [44] | 98.60% | Large number of features |
| Xu [40] | 2021 | LSTM | RF | Android Malware CICMal2017 | 97.16% | Long time feature preparation |
| Ullah [41] | 2022 | Features from Accelerated Segment Test+ Binary Robust Independent Elementary Features + CNN | Ensemble model | CICMalDroid 2020 CIC-InvesAndMal2019 | 97.76% 98.44% | complex multi-stage feature engineering |
| Ullah [42] | 2022 | (SIFTs) and oriented fast and rotated brief transforms + CNN | Ensemble model | CIC-AAGM2017 CICMalDroid 2020 | 94.11% 99.00% | No data augmentation |
| Saridou [43] | 2022 | Hilbert BinVis + H-curve SAGMAD | CNN | Self-collected and combined dataset | 94.50% | Low detection performance |
| Metric | Equation |
|---|---|
| Accuracy (A) | |
| Precision (P) | |
| Recall (R) | |
| F-score (F1) |
| Method | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|
| linear | 84.59% | 78.97% | 74.81% | 82.90% |
| quadratic | 85.82% | 80.00% | 76.05% | 84.27% |
| polynomial | 90.63% | 89.10% | 88.64% | 90.43% |
| rbf | 86.19% | 80.88% | 77.53% | 84.86% |
| Method | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|
| linear | 92.22% | 92.98% | 88.24% | 89.55% |
| quadratic | 86.67% | 85.48% | 73.53% | 80.65% |
| polynomial | 90.56% | 96.12% | 94.12% | 88.28% |
| rbf | 91.67% | 93.69% | 89.71% | 89.05% |
| Method | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|
| linear | 85.20% | 79.42% | 75.31% | 83.56% |
| quadratic | 87.18% | 81.86% | 78.77% | 85.98% |
| polynomial | 90.75% | 89.13% | 88.64% | 90.54% |
| rbf | 87.05% | 81.95% | 79.01% | 85.91% |
| Method | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|
| linear | 93.89% | 94.69% | 91.18% | 91.85% |
| quadratic | 95% | 95.58% | 92.65% | 93.33% |
| polynomial | 91.67% | 97.09% | 95.59% | 89.66% |
| rbf | 92.22% | 93.75% | 89.71% | 89.71% |
| SVM Parameter | Min Value | Max Value |
|---|---|---|
| C | 1 | 50 |
| gamma | 1 | 10 |
| degree | 0 | 6 |
| kernel | [linear, rbf, poly] | |
| Method | Accuracy | Recall | Precision | F1_Score |
|---|---|---|---|---|
| SVM-linear | 95.56% | 96.43% | 94.12% | 95.26% |
| Reference | Feature Extraction | Classifier | Evaluation Metrics |
|---|---|---|---|
| [5] | D-SIFT and GIST | SVM | 97.4% (accuracy) |
| [7] | GIST and Discrete Wavelet Transform | SVM and KNN | SVM 98.84% (accuracy) and KNN 98.88% (accuracy) |
| [8] | Local mean | Combination of Bagging and K-means | 98.2% (accuracy) |
| [9] | Entropy Graphs | The similarity between Entropy Graphs | 97.9% (accuracy) |
| Proposed system | Statistical texture features | SVM with a linear kernel function | 95.56% (accuracy) 96.43% (Recall) 94.12% (Precision) 95.26% (F1-score) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Ghamry, A.; Gaber, T.; Mohammed, K.K.; Hassanien, A.E., on behalf of the Scientific Research Group. Optimized and Efficient Image-Based IoT Malware Detection Method. Electronics 2023, 12, 708. https://doi.org/10.3390/electronics12030708
El-Ghamry A, Gaber T, Mohammed KK, Hassanien AE on behalf of the Scientific Research Group. Optimized and Efficient Image-Based IoT Malware Detection Method. Electronics. 2023; 12(3):708. https://doi.org/10.3390/electronics12030708
Chicago/Turabian StyleEl-Ghamry, Amir, Tarek Gaber, Kamel K. Mohammed, and Aboul Ella Hassanien on behalf of the Scientific Research Group. 2023. "Optimized and Efficient Image-Based IoT Malware Detection Method" Electronics 12, no. 3: 708. https://doi.org/10.3390/electronics12030708