



Supervised Contrastive Learning for Voice Activity Detection


Abstract
:1. Introduction
2. Background and Related Work
2.1. Voice Activity Detection
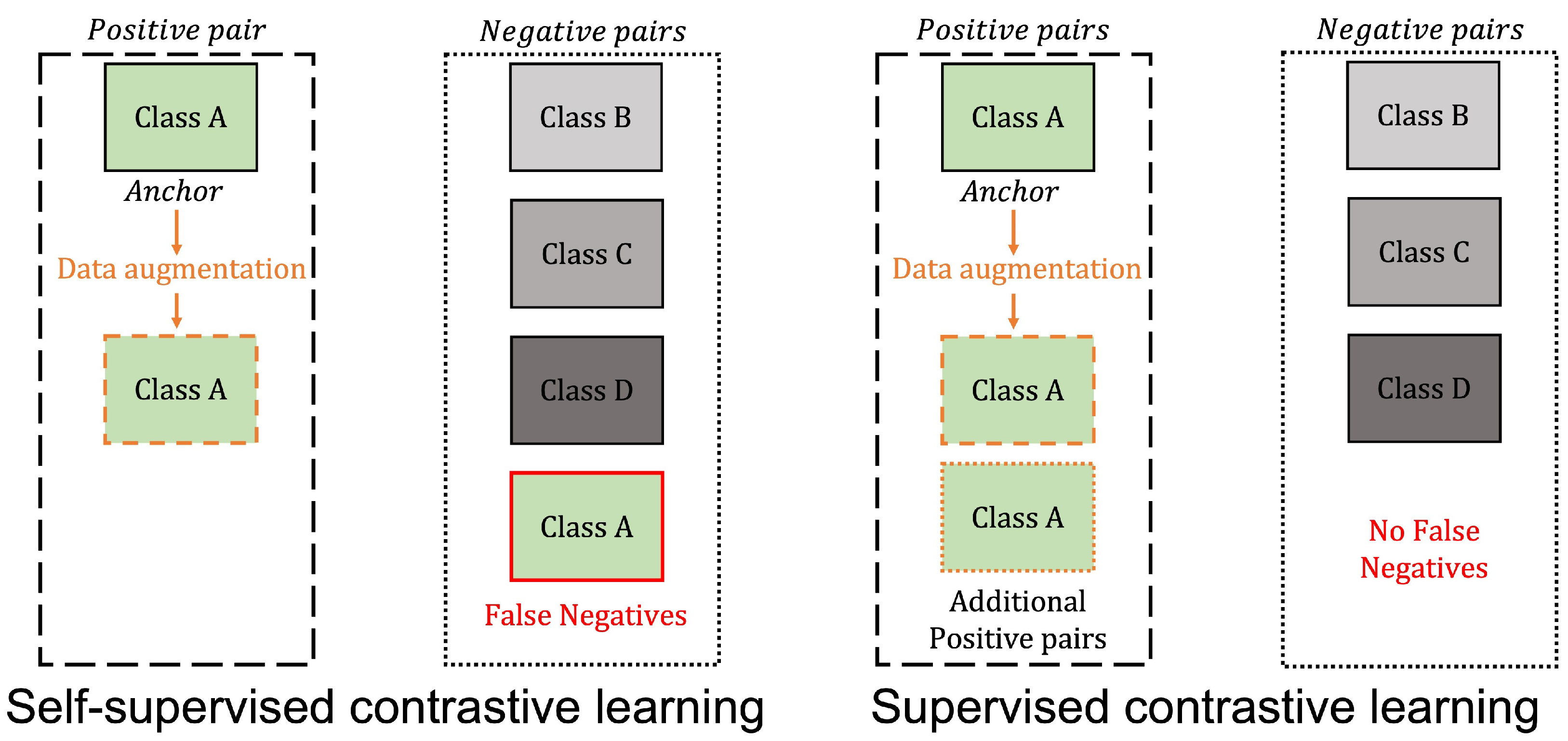
2.2. Supervised Contrastive Learning
3. Proposed Method
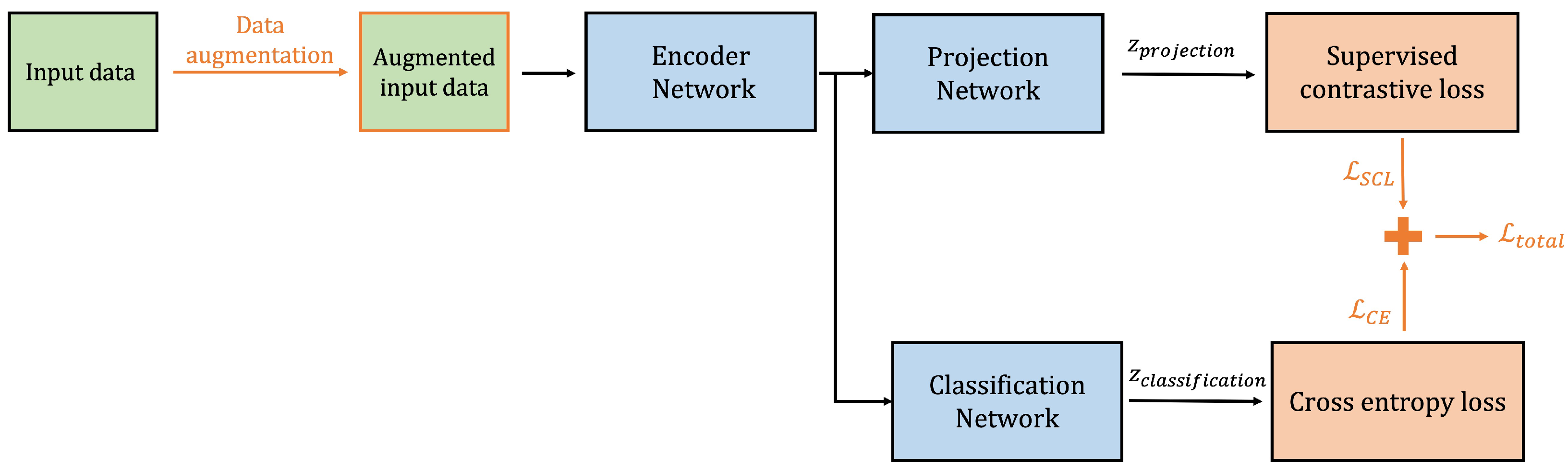
3.1. Proposed Supervised Contrastive Learning-Based Voice Activity Detection Algorithm
| Algorithm 1 Supervised Contrastive Learning for Voice Activity Detection—Model Training Strategy |
Input: Encoder network , projection network , classification network , Hyperparameters, Dataset samples Output: Optimized encoder network and classification network Initialize: Initialization of encoder network , projection network , classification network
|
3.2. Loss Functions
4. Experiments
4.1. Implementation Details
4.2. Training Dataset
4.3. Performance Evaluation
4.4. Data Augmentation
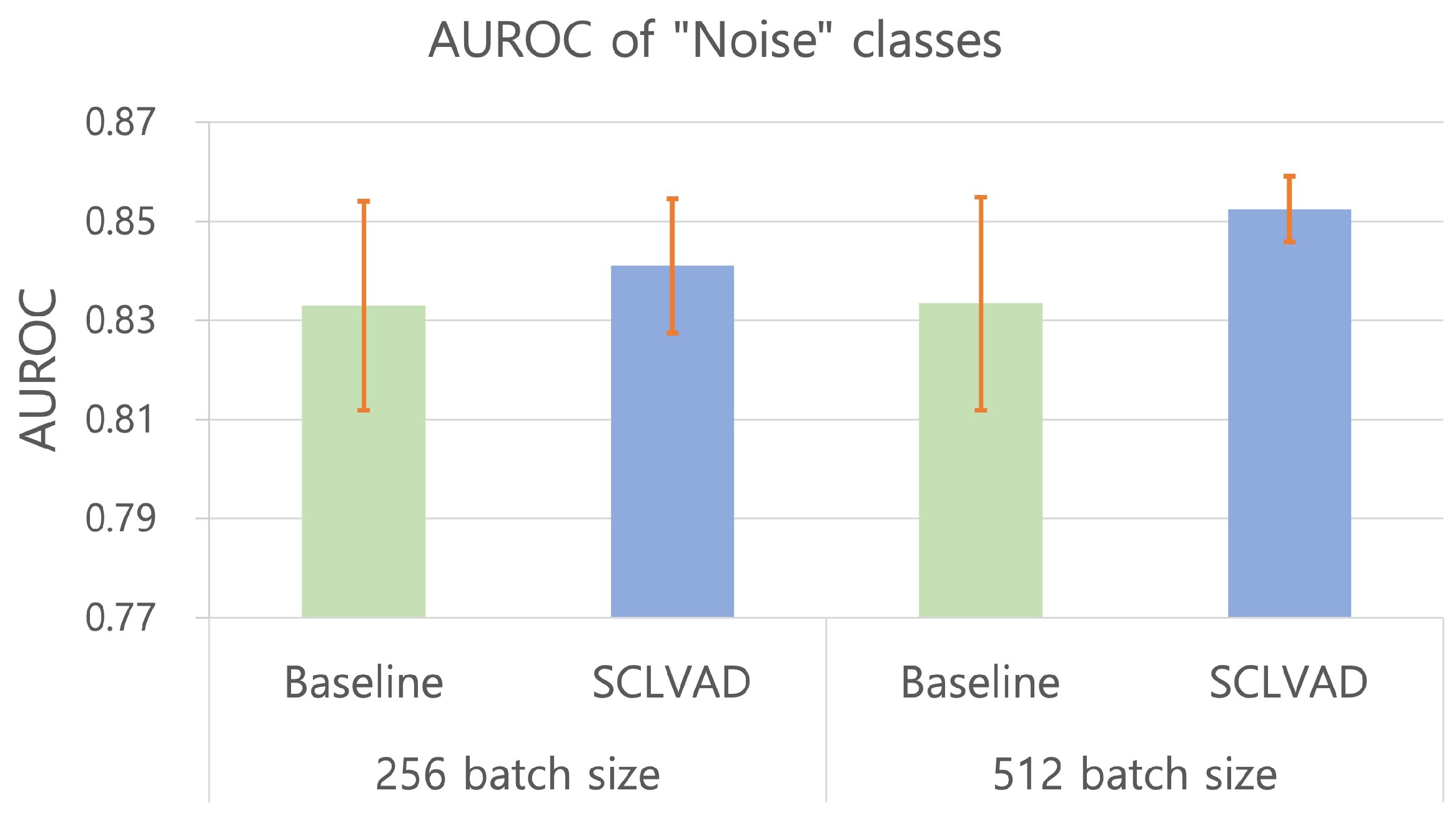
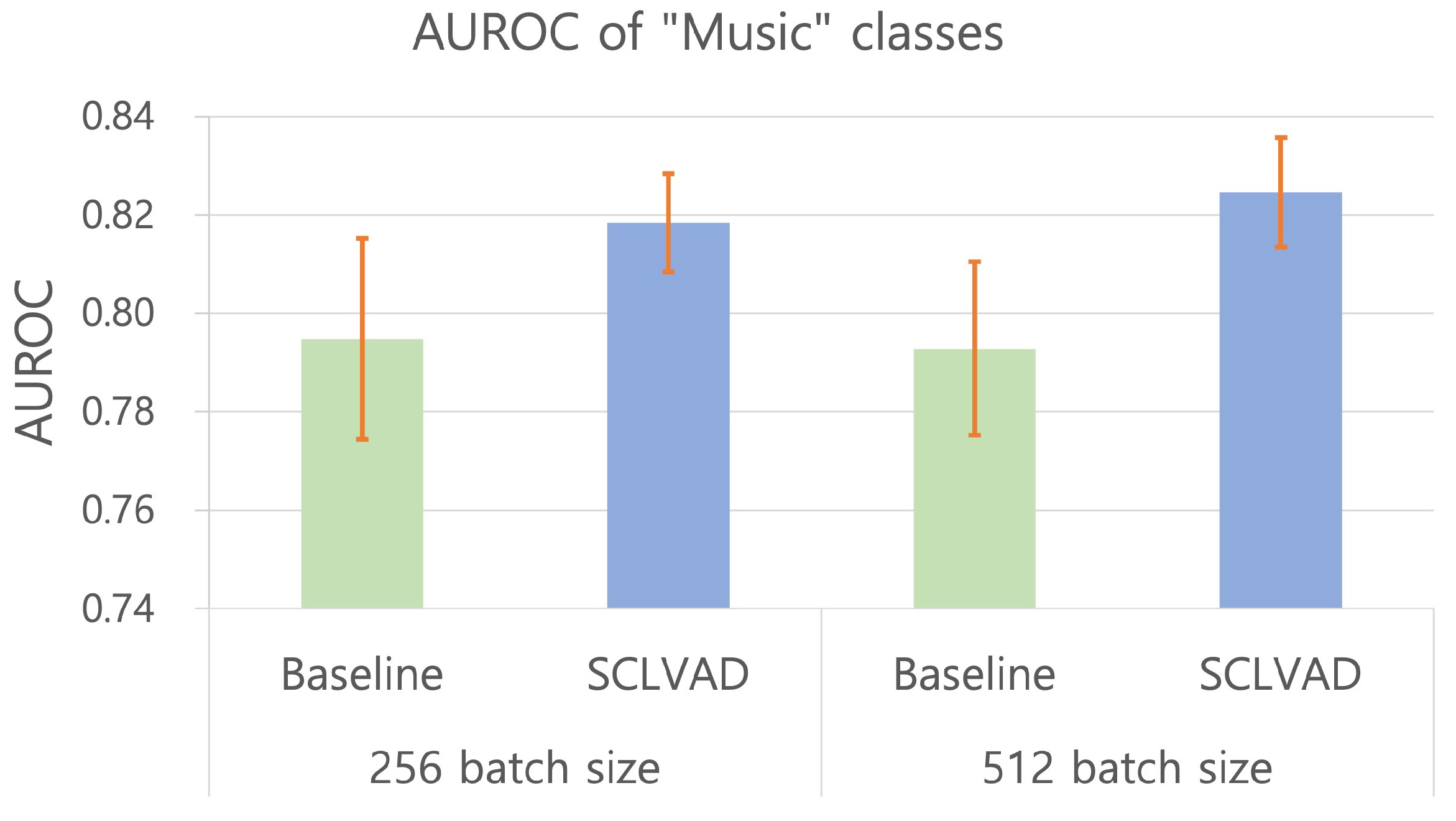
4.5. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sohn, J.; Kim, N.S.; Sung, W. A statistical model-based voice activity detection. IEEE Signal Process. Lett. 1999, 6, 1–3. [Google Scholar] [CrossRef]
- Souden, M.; Chen, J.; Benesty, J.; Affes, S. Gaussian Model-Based Multichannel Speech Presence Probability. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1072–1077. [Google Scholar] [CrossRef]
- Hebbar, R.; Somandepalli, K.; Narayanan, S. Robust Speech Activity Detection in Movie Audio: Data Resources and Experimental Evaluation. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4105–4109. [Google Scholar] [CrossRef]
- Jia, F.; Majumdar, S.; Ginsburg, B. MarbleNet: Deep 1D Time-Channel Separable Convolutional Neural Network for Voice Activity Detection. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6818–6822. [Google Scholar] [CrossRef]
- Köpüklü, O.; Taseska, M. ResectNet: An Efficient Architecture for Voice Activity Detection on Mobile Devices. Proc. Interspeech 2022, 2022, 5363–5367. [Google Scholar] [CrossRef]
- Li, N.; Wang, L.; Unoki, M.; Li, S.; Wang, R.; Ge, M.; Dang, J. Robust Voice Activity Detection Using a Masked Auditory Encoder Based Convolutional Neural Network. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6828–6832. [Google Scholar] [CrossRef]
- Xu, X.; Dinkel, H.; Wu, M.; Yu, K. A Lightweight Framework for Online Voice Activity Detection in the Wild. Proc. Interspeech 2021, 2021, 371–375. [Google Scholar] [CrossRef]
- Hughes, T.; Mierle, K. Recurrent neural networks for voice activity detection. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7378–7382. [Google Scholar] [CrossRef] [Green Version]
- Gelly, G.; Gauvain, J.L. Optimization of RNN-Based Speech Activity Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 646–656. [Google Scholar] [CrossRef]
- Eyben, F.; Weninger, F.; Squartini, S.; Schuller, B. Real-life voice activity detection with LSTM Recurrent Neural Networks and an application to Hollywood movies. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 483–487. [Google Scholar] [CrossRef]
- Wilkinson, N.; Niesler, T. A Hybrid CNN-BiLSTM Voice Activity Detector. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6803–6807. [Google Scholar] [CrossRef]
- Alam, T.; Khan, A. Lightweight CNN for Robust Voice Activity Detection. In Speech and Computer; Karpov, A., Potapova, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–12. [Google Scholar]
- Nasiri, A.; Hu, J. SoundCLR: Contrastive learning of representations for improved environmental sound classification. arXiv 2021, arXiv:2103.01929. [Google Scholar]
- López-Espejo, I.; Tan, Z.H.; Jensen, J. A Novel Loss Function and Training Strategy for Noise-Robust Keyword Spotting. IEEE/ACM Trans. Audio Speech Lang. Proc. 2021, 29, 2254–2266. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Chaudhuri, S.; Roth, J.; Ellis, D.P.W.; Gallagher, A.; Kaver, L.; Marvin, R.; Pantofaru, C.; Reale, N.; Guarino Reid, L.; Wilson, K.; et al. AVA-Speech: A Densely Labeled Dataset of Speech Activity in Movies. Proc. Interspeech 2018, 2018, 1239–1243. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d‘Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Font, F.; Roma, G.; Serra, X. Freesound Technical Demo. In Proceedings of the 21st ACM International Conference on Multimedia MM ’13, Barcelona, Spain, 21 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 411–412. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pros | Cons | Features |
|---|---|---|---|
| MarbleNet [4] | Compact model size | Lack of noise robustness | 1D time-channel separable convolution |
| CNN-TD [3] | High classification accuracy | Large model size | VGG-16-based neural network |
| Supervised contrastive learning [15] | Highly improves classification accuracy | Additional neural network | Modified contrastive learning to use labeled dataset |
| SoundCLR [13] | High classification accuracy | Additional neural network | Supervised contrastive learning for environmental sound classification task |
| Batch Size = 256 | TPR for FPR = 0.315 | AUROC | |||
|---|---|---|---|---|---|
| Method | Clean | Noise | Music | All | All |
| No Augmentation | |||||
| Baseline [4] | |||||
| SCLVAD | |||||
| Batch Size = 256 | TPR for FPR = 0.315 | AUROC | |||
|---|---|---|---|---|---|
| Method | Clean | Noise | Music | All | All |
| No Augmentation + overlap 87.5% | |||||
| Baseline + overlap 87.5% [4] | |||||
| SCLVAD + overlap 87.5% | |||||
| Batch Size = 512 | TPR for FPR = 0.315 | AUROC | |||
|---|---|---|---|---|---|
| Method | Clean | Noise | Music | All | All |
| Baseline [4] | |||||
| SCLVAD | |||||
| Batch Size = 512 | TPR for FPR = 0.315 | AUROC | |||
|---|---|---|---|---|---|
| Method | Clean | Noise | Music | All | All |
| Baseline + overlap 87.5% [4] | |||||
| SCLVAD + overlap 87.5% | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heo, Y.; Lee, S. Supervised Contrastive Learning for Voice Activity Detection. Electronics 2023, 12, 705. https://doi.org/10.3390/electronics12030705
Heo Y, Lee S. Supervised Contrastive Learning for Voice Activity Detection. Electronics. 2023; 12(3):705. https://doi.org/10.3390/electronics12030705
Chicago/Turabian StyleHeo, Youngjun, and Sunggu Lee. 2023. "Supervised Contrastive Learning for Voice Activity Detection" Electronics 12, no. 3: 705. https://doi.org/10.3390/electronics12030705