
HCOME: Research on Hybrid Computation Offloading Strategy for MEC Based on DDPG

Abstract
:1. Introduction
2. Related Work
3. System Model and Problem Formulation
3.1. System Model
3.2. Task Model
3.3. Hybrid Computing Model
3.4. Resource Allocation Balancing
3.5. Problem Formulation
4. Hybrid Computational Offloading Algorithm Based on DDPG
4.1. DDPG Framework
- State space: We consider the whole MEC environment as a state space, which mainly includes the state of MEC servers’ computing resources, and the network state, the number of UDs and their computing resource states and the state of tasks. However, in practice, considering state of the whole MEC environment leads to a large system overhead, and it gets larger as the number of UDs and MEC servers increases. Therefore, to reduce the additional system overhead, we define the state asthat is, the system overhead for the whole MEC system.
- Action space: We use the set of each UD computational offloading proportions as the action space, with the purpose of being able to describe well the computational offloading strategy of all UDs, i.e., . Since is a continuous domain, it is easy to choose a reasonable action of arbitrary proportion.
- Reward function: After taking the possible actions in each iteration step, the agent of DDPG can obtain a certain reward, which at this point needs to map the goal of our proposed hybrid computational offloading algorithm, i.e., to minimize the total system overhead and also to balance the network load and the computational load in the MEC system. Thus, when setting the reward function, these two objectives should be considered. In addition, to better analyze the merits of the obtained computational offloading strategy, the reward function needs to become inversely proportional to the total system overhead and load. Thus, the reward function can be expressed aswhere denotes the execution time of the task, denotes the energy consumption of the executed task, denotes the variance of the network load, denotes the variance of the computational load, denotes the weights of each component, i.e., , , and . In other words, to get a lower delay and lower energy consumption of the MEC system, the reward needs to be bigger and the offloading decision more reasonable.
4.2. DDPG Algorithm
| Algorithm 1 DDPG Algorithm |
| 1: Randomly initialize the actor network and the critic network ; |
| 2: Initialize the associated target networks with weights and ; |
| 3: Initialize the replay buffer ; |
| 4: for each episode do |
| 5: Randomly generate an initial state with an action ; |
| 6: for each time slot do |
| 7: Determine the computation offloading strategy according to the actor network and the OU noise ; |
| 8: Execute action at the user agent, and then get reward and observe the next state ; |
| 9: Save the tuple into the replay buffer ; |
| 10: Randomly sample a mini-batch from the replay buffer ; |
| 11: Update the critic network by minimizing the loss with (20); |
| 12: Update the actor network by the sampled policy gradient based on (21); |
| 13: Soft update the target networks by (22); |
| 14: end for |
| 15: end for |
5. Performance Evaluation
5.1. Experimental Setup
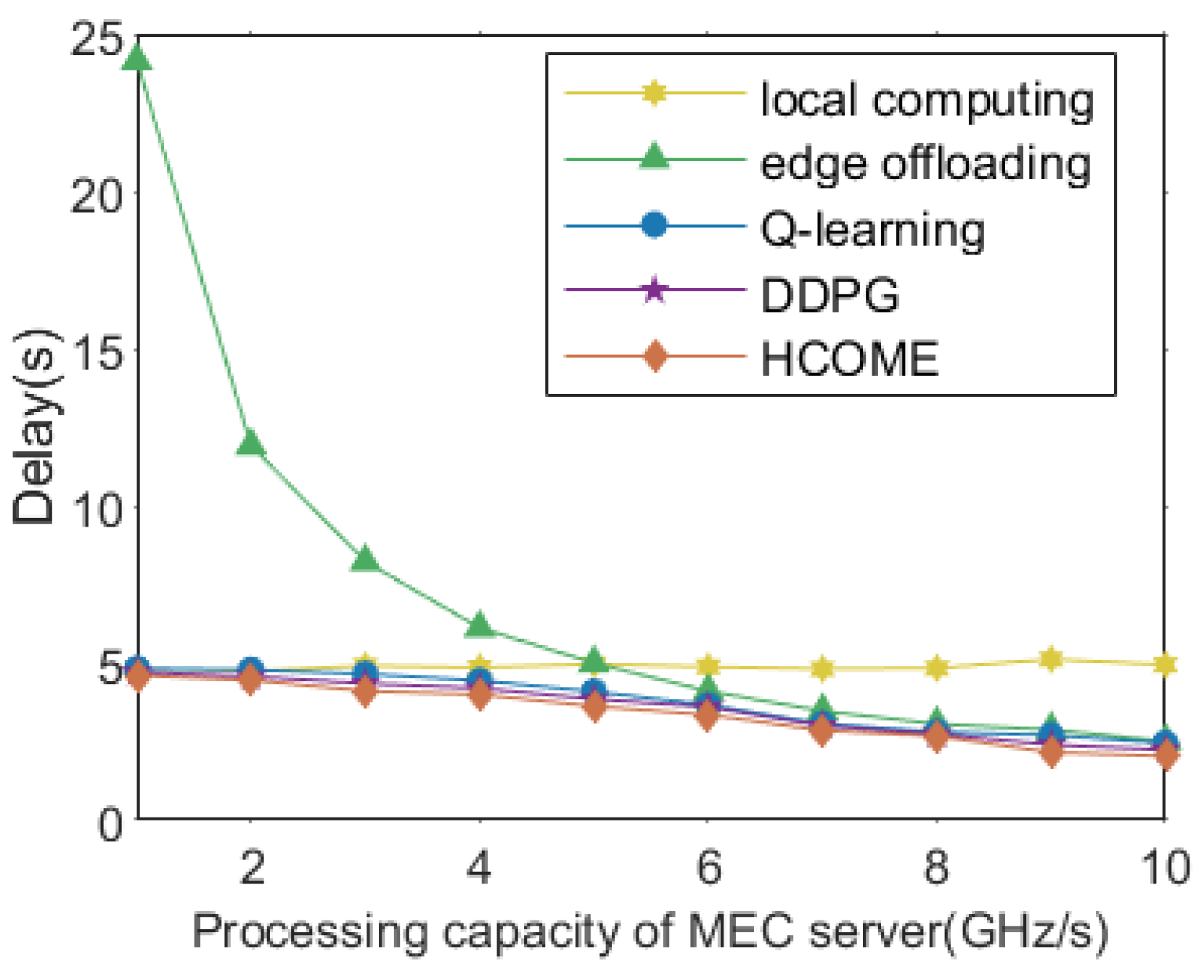
5.2. Experimental Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and resource allocation with general task graph in mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Yuan, Y.; Liu, W.; Wang, T.; Deng, Q.; Liu, A.; Song, H. Compressive sensing-based clustering joint annular routing data gathering scheme for wireless sensor networks. IEEE Access 2019, 7, 114639–114658. [Google Scholar] [CrossRef]
- Hu, S.; Li, G. Dynamic request scheduling optimization in mobile edge computing for IoT applications. IEEE Internet Things J. 2019, 7, 1426–1437. [Google Scholar] [CrossRef]
- Premsankar, G.; Di Francesco, M.; Taleb, T. Edge computing for the Internet of Things: A case study. IEEE Internet Things J. 2018, 5, 1275–1284. [Google Scholar] [CrossRef] [Green Version]
- Yu, R.; Li, P. Toward resource-efficient federated learning in mobile edge computing. IEEE Netw. 2021, 35, 148–155. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, R.; Lai, S.; Fan, L.; Lei, X.; Karagiannidis, G.K. Distributed machine learning for multiuser mobile edge computing systems. IEEE J. Sel. Top. Signal Process. 2022, 16, 460–473. [Google Scholar] [CrossRef]
- Rafique, W.; Qi, L.; Yaqoob, I.; Imran, M.; Rasool, R.U.; Dou, W. Complementing IoT services through software defined networking and edge computing: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 1761–1804. [Google Scholar] [CrossRef]
- Nisar, K.; Jimson, E.R.; Hijazi, M.H.A.; Welch, I.; Hassan, R.; Aman, A.H.M.; Sodhro, A.H.; Pirbhulal, S.; Khan, S. A survey on the architecture, application, and security of software defined networking: Challenges and open issues. Internet Things 2020, 12, 100289. [Google Scholar] [CrossRef]
- Poularakis, K.; Qin, Q.; Nahum, E.M.; Rio, M.; Tassiulas, L. Flexible SDN control in tactical ad hoc networks. Ad Hoc Netw. 2019, 85, 71–80. [Google Scholar] [CrossRef]
- Zarca, A.M.; Bernabe, J.B.; Trapero, R.; Rivera, D.; Villalobos, J.; Skarmeta, A.; Bianchi, S.; Zafeiropoulos, A.; Gouvas, P. Security management architecture for NFV/SDN-aware IoT systems. IEEE Internet Things J. 2019, 6, 8005–8020. [Google Scholar] [CrossRef]
- Akhunzada, A.; Khan, M.K. Toward secure software defined vehicular networks: Taxonomy, requirements, and open issues. IEEE Commun. Mag. 2017, 55, 110–118. [Google Scholar] [CrossRef]
- Tang, F.; Fadlullah, Z.M.; Mao, B.; Kato, N. An intelligent traffic load prediction-based adaptive channel assignment algorithm in SDN-IoT: A deep learning approach. IEEE Internet Things J. 2018, 5, 5141–5154. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.; Tian, Y.C.; Li, K. Resource allocation and computation offloading with data security for mobile edge computing. Future Gener. Comput. Syst. 2019, 100, 531–541. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, J.; Nie, T. Deep Reinforcement Learning Aided Computation Offloading and Resource Allocation for IoT. In Proceedings of the 2020 IEEE Computing, Communications and IoT Applications (ComComAp), Beijing, China, 20–22 December 2020. [Google Scholar]
- Chen, C.; Liu, B.; Wan, S.; Qiao, P.; Pei, Q. An edge traffic flow detection scheme based on deep learning in an intelligent transportation system. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1840–1852. [Google Scholar] [CrossRef]
- Deng, X.; Yin, J.; Guan, P.; Xiong, N.N.; Zhang, L.; Mumtaz, S. Intelligent delay-aware partial computing task offloading for multi-user industrial internet of things through edge computing. IEEE Internet Things J. 2021, 80, 8011–8024. [Google Scholar] [CrossRef]
- Tuong, V.D.; Truong, T.P.; Nguyen, T.V.; Noh, W.; Cho, S. Partial Computation Offloading in NOMA-Assisted Mobile Edge Computing Systems Using Deep Reinforcement Learning. IEEE Internet Things J. 2021, 8, 13196–13208. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, L.; Liu, J.; Kato, N. Smart resource allocation for mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Emerg. Top. Comput. 2019, 9, 1529–1541. [Google Scholar] [CrossRef]
- Liu, X.; Yin, J.; Zhang, S.; Ding, B.; Guo, S.; Wang, K. Range-based localization for sparse 3-D sensor networks. IEEE Internet Things J. 2018, 6, 753–764. [Google Scholar] [CrossRef]
- Morabito, R.; Cozzolino, V.; Ding, A.Y.; Beijar, N.; Ott, J. Consolidate IoT edge computing with lightweight virtualization. IEEE Netw. 2018, 32, 102–111. [Google Scholar] [CrossRef]
- Wu, D.; Nie, X.; Deng, H.; Qin, Z. Software Defined Edge Computing for Distributed Management and Scalable Control in IoT Multi-networks. arXiv 2021, arXiv:2104.02426. [Google Scholar]
- Kaur, K.; Garg, S.; Aujla, G.S.; Kumar, N.; Rodrigues, J.J.; Guizani, M. Edge computing in the industrial internet of things environment: Software-defined-networks-based edge-cloud interplay. IEEE Commun. Mag. 2018, 56, 44–51. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Wan, J.; Liu, C.; Imran, M. Adaptive transmission optimization in SDN-based industrial Internet of Things with edge computing. IEEE Internet Things J. 2018, 5, 1351–1360. [Google Scholar] [CrossRef]
- Peng, H.; Ye, Q.; Shen, X.S. SDN-based resource management for autonomous vehicular networks: A multi-access edge computing approach. IEEE Wirel. Commun. 2019, 26, 156–162. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Guo, H.; Liu, J.; Zhang, Y. Task offloading in vehicular edge computing networks: A load-balancing solution. IEEE Trans. Veh. Technol. 2019, 69, 2092–2104. [Google Scholar] [CrossRef]
- Zhang, K.; Leng, S.; He, Y.; Maharjan, S.; Zhang, Y. Mobile edge computing and networking for green and low-latency Internet of Things. IEEE Commun. Mag. 2018, 56, 39–45. [Google Scholar] [CrossRef]
- Liang, C.; He, Y.; Yu, F.R.; Zhao, N. Energy-efficient resource allocation in software-defined mobile networks with mobile edge computing and caching. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Atlanta, GA, USA, 1–4 May 2017; pp. 121–126. [Google Scholar]
- Singh, A.; Aujla, G.S.; Bali, R.S. Intent-based network for data dissemination in software-defined vehicular edge computing. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5310–5318. [Google Scholar] [CrossRef]
- Luo, G.; Zhou, H.; Cheng, N.; Yuan, Q.; Li, J.; Yang, F.; Shen, X. Software-defined cooperative data sharing in edge computing assisted 5G-VANET. IEEE Trans. Mob. Comput. 2019, 20, 1212–1229. [Google Scholar] [CrossRef]
- Hou, X.; Ren, Z.; Wang, J.; Cheng, W.; Ren, Y.; Chen, K.C.; Zhang, H. Reliable computation offloading for edge-computing-enabled software-defined IoV. IEEE Internet Things J. 2020, 7, 7097–7111. [Google Scholar] [CrossRef]
- Li, M.; Si, P.; Zhang, Y. Delay-tolerant data traffic to software-defined vehicular networks with mobile edge computing in smart city. IEEE Trans. Veh. Technol. 2018, 67, 9073–9086. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zomaya, A.Y.; Georgalas, N. Fast adaptive task offloading in edge computing based on meta reinforcement learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 242–253. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Luo, Q.; Li, C.; Luan, T.H.; Shi, W. Collaborative data scheduling for vehicular edge computing via deep reinforcement learning. IEEE Internet Things J. 2020, 7, 9637–9650. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Peng, H.; Shen, X. Deep reinforcement learning based resource management for multi-access edge computing in vehicular networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 2416–2428. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International conference on machine learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Cao, Y.; Jiang, T.; Wang, C. Optimal radio resource allocation for mobile task offloading in cellular networks. IEEE Netw. 2014, 28, 68–73. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Description |
|---|---|---|
| 900 M–1100 M | The number of CPU cycles required for task | |
| 300 kbit–500 kbit | The data size of task | |
| The computational power of UD | ||
| The computational power of the MEC server | ||
| The bandwidth of the wireless channel | ||
| The transmission power of the UD’s data upload | ||
| The channel noise of complex Gaussian. | ||
| actor learning rate | 0.0002 | Learning rate of actor network |
| critic learning rate | 0.001 | Learning rate of critic network |
| 0.005 | Update factor for soft update | |
| 0.99 | Reward discount factor | |
| batch size | 64 | Sample size in the empirical buffer |
| buffer size | 50,000 | Size of the experience buffer |
| Number of UD | Number of UDs to Be Offloaded | |||
|---|---|---|---|---|
| HCOME | 5 | 5 | 0.2944 | 0.0776 |
| 5 | 4 | 0.3252 | 0.0960 | |
| 5 | 3 | 0.3384 | 0.1408 | |
| Q-learning | 5 | 5 | 0.3103 | 0.0845 |
| 5 | 4 | 0.5161 | 0.1316 | |
| 5 | 3 | 0.6508 | 0.1693 | |
| DDPG | 5 | 5 | 0.4169 | 0.3695 |
| 5 | 4 | 0.2894 | 0.5000 | |
| 5 | 3 | 0.3835 | 0.7330 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, S.; Chen, S.; Chen, H.; Zhang, H.; Zhan, Z.; Zhang, W. HCOME: Research on Hybrid Computation Offloading Strategy for MEC Based on DDPG. Electronics 2023, 12, 562. https://doi.org/10.3390/electronics12030562
Cao S, Chen S, Chen H, Zhang H, Zhan Z, Zhang W. HCOME: Research on Hybrid Computation Offloading Strategy for MEC Based on DDPG. Electronics. 2023; 12(3):562. https://doi.org/10.3390/electronics12030562
Chicago/Turabian StyleCao, Shaohua, Shu Chen, Hui Chen, Hanqing Zhang, Zijun Zhan, and Weishan Zhang. 2023. "HCOME: Research on Hybrid Computation Offloading Strategy for MEC Based on DDPG" Electronics 12, no. 3: 562. https://doi.org/10.3390/electronics12030562