
Communication Time Optimization of Register-Based Data Transfer

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Formal definition of the problem;
- Development of a fast exact algorithm that can be applied to specific instances of the problem, along with a formal proof of its correctness;
- Development of optimization models based on mathematical programming, namely constraint programming (CP) and mixed-integer linear programming (MILP);
- Dedicated implementation of tabu search (TS) metaheuristic,
- Proposal of three new simple deterministic algorithms, namely the greedy (GR1, GR2) and heuristic rule-based (HR);
- Experimental verification and comparison of the proposed approaches;
- Conclusions on the practical applicability of the analyzed optimization techniques.
2. Related Work
2.1. Register Grouping
2.2. Theoretical Analysis
2.3. Performance Analysis
3. Basics of Register-Based Data Transfer
3.1. Problem Statement
- There is a set of registers to be transferred, each is characterized by its address , and these addresses are collected in the set R.
- Each register can be either transferred separately or grouped with preceding and/or following registers into a frame for the block transfer.
- The transfer of a single register takes time .
- The block transfer time depends on the span of the block, i.e., the transfer time of a block amounts to .
- These are the following constraints on a problem–solution:
- (a)
- Each register has to be transferred exactly once (separately or in a block);
- (b)
- A block size cannot exceed a predefined upper limit s; if , then the constraint is omitted and a block can have any size;
- The objective is to find a partition of the register set into separate and block transfers that minimizes the total communication time.
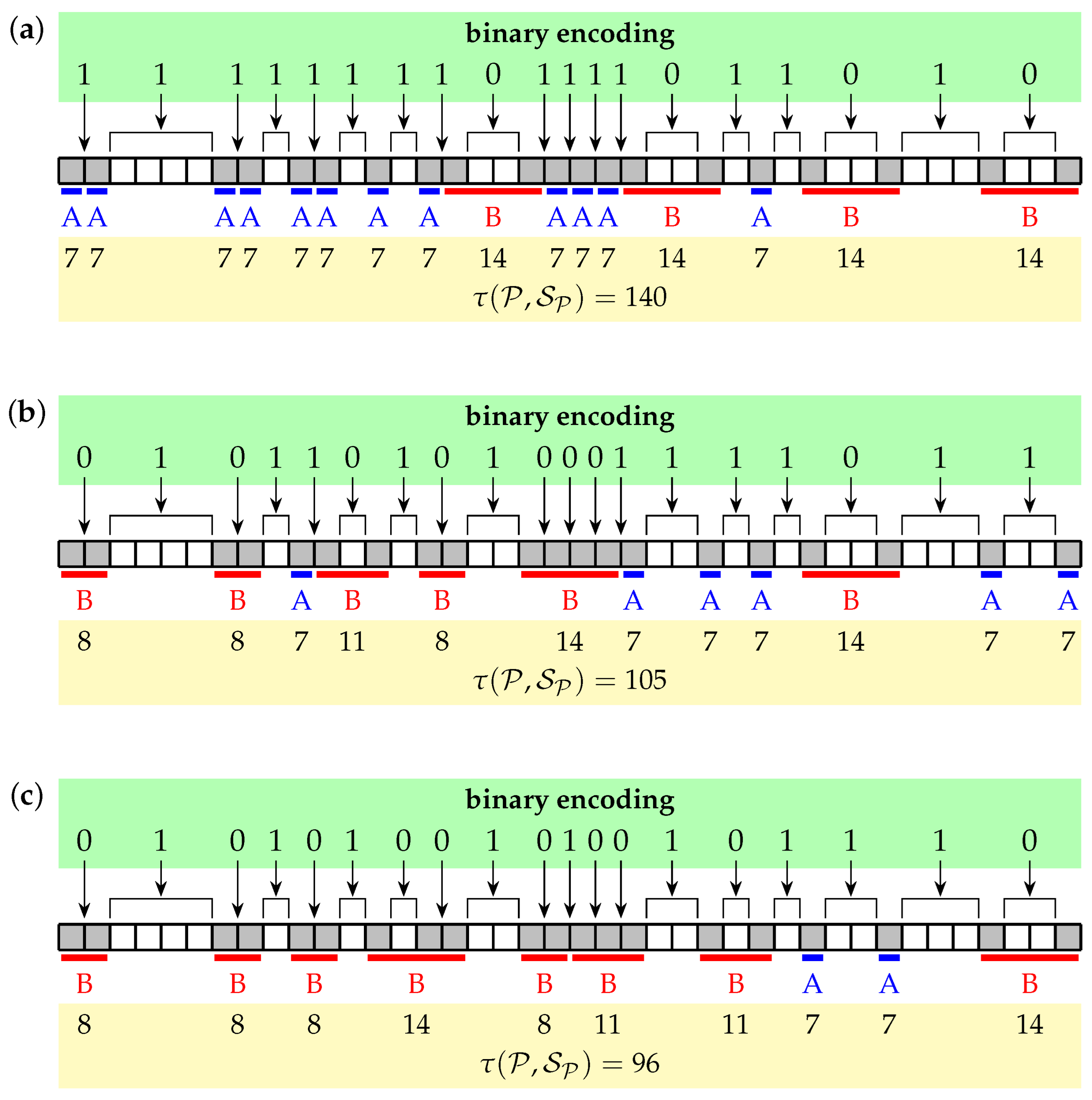
3.2. Binary Solution Encoding
3.3. Exemplary Problem Instance
3.4. Easy Case
| Algorithm 1: Calculation of the time function value |
 |
3.5. General Case
4. Optimization Approaches
4.1. Mixed Integer Linear Programming
- , —equals 1 if, and only if, the register is transmitted in the j-th frame;
- , —equals 1 if and only if the i-th frame is used, i.e., the total number of frames is not less than i;
- , —equals 1 if, and only if, the i-th frame contains exactly one register;
- , —the first and the last register, respectively, transmitted inside the i-th frame;
- , —the size of the i-th frame, i.e., the number of registers it includes;
- , —the time of transmission of the i-th frame.
4.2. Constraint Programming
4.3. Tabu Search
- A solution is coded by binary encoding (Definition 3).
- The binary encoding words are also used as tabu attributes stored in the tabu list.
- The value of the objective function is calculated using the procedure from Algorithm 1. Solutions with an exceeding frame length are dropped, so that the algorithm visits only the feasible solutions.
- The move, i.e., an elementary modification of a solution in the neighborhood, is defined as toggling one bit of the binary encoding word.
- The neighborhood consists of moves based on every encoding bit. In other words, the solution represented by a binary encoding has neighbor solutions in the setwhere is the Kronecker symbol.
- The algorithm does not necessarily use the full neighborhood , but any of its elements are accepted with the probability and rejected otherwise. This improves the stochastic nature of the search and supports escaping from loops, if the tabu mechanism is insufficient.
- The standard aspiration criterion is implemented, meaning that a new solution overperforming the current global optimum is always accepted, even if it is forbidden by the tabu list.
- The initial solution is generated randomly.
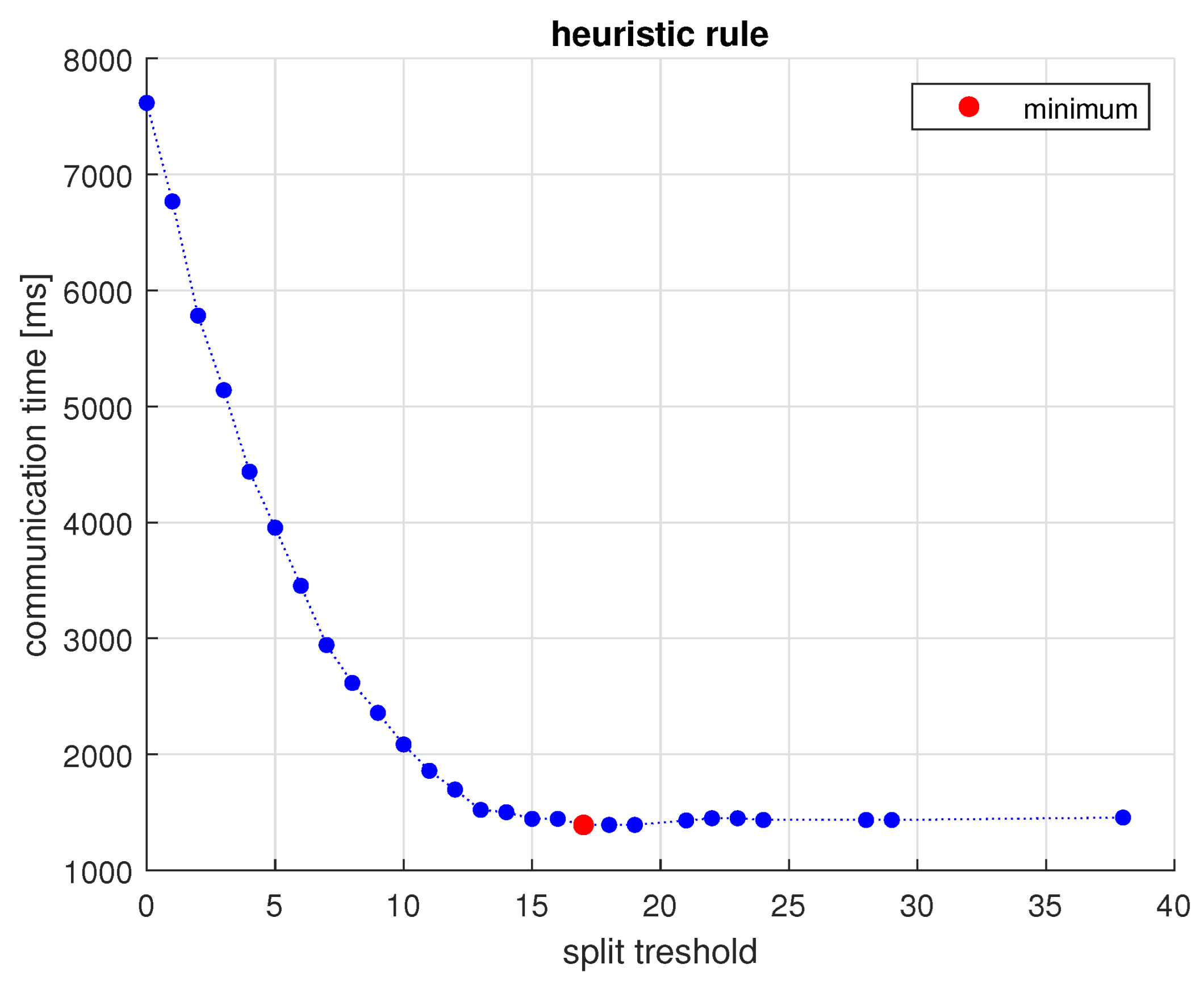
4.4. Deterministic Algorithms
| Algorithm 2: Pseudocode of algorithm GR1 |
 |
| Algorithm 3: Pseudocode of algorithm GR2 |
 |
| Algorithm 4: Pseudocode of algorithm HR |
 |
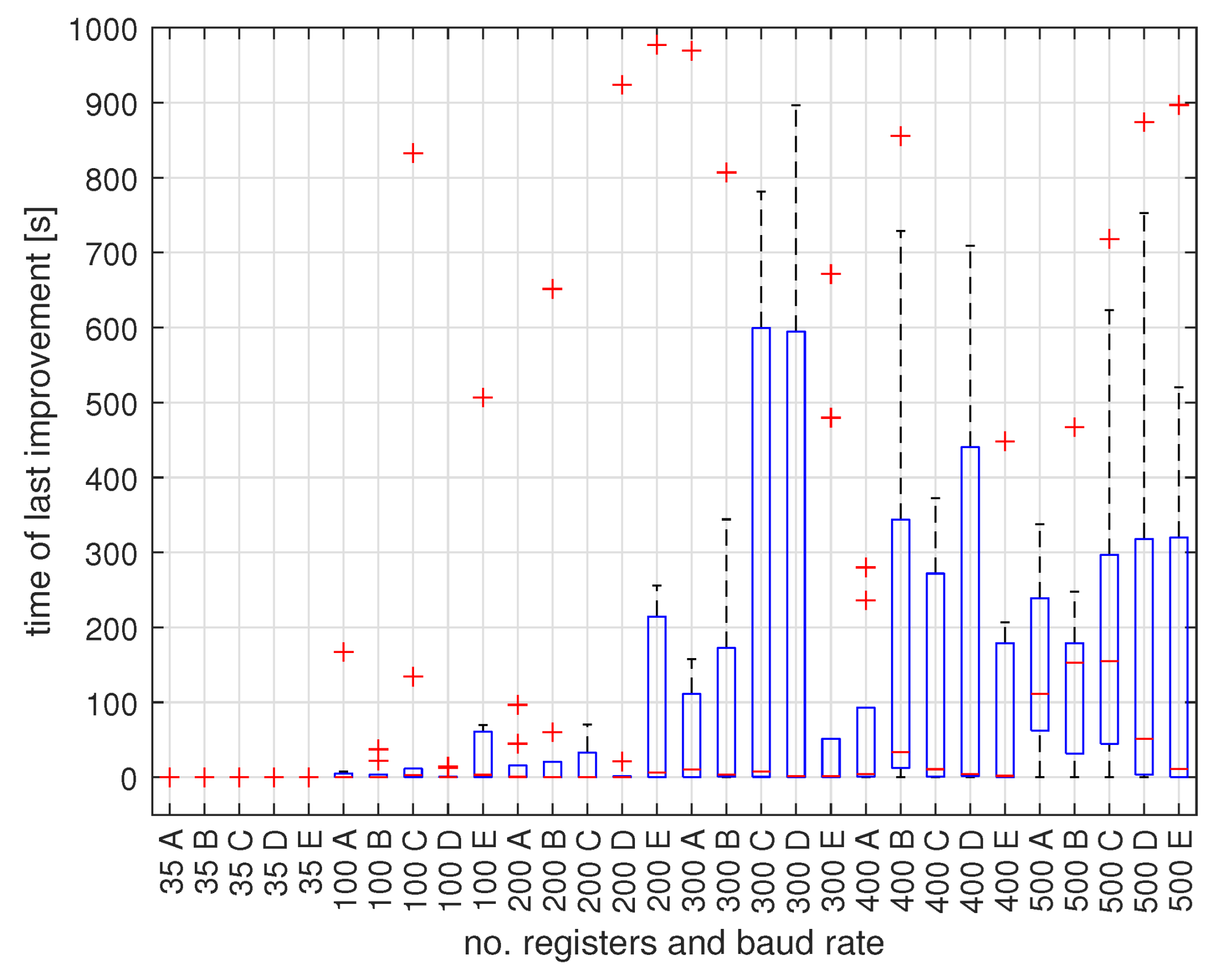
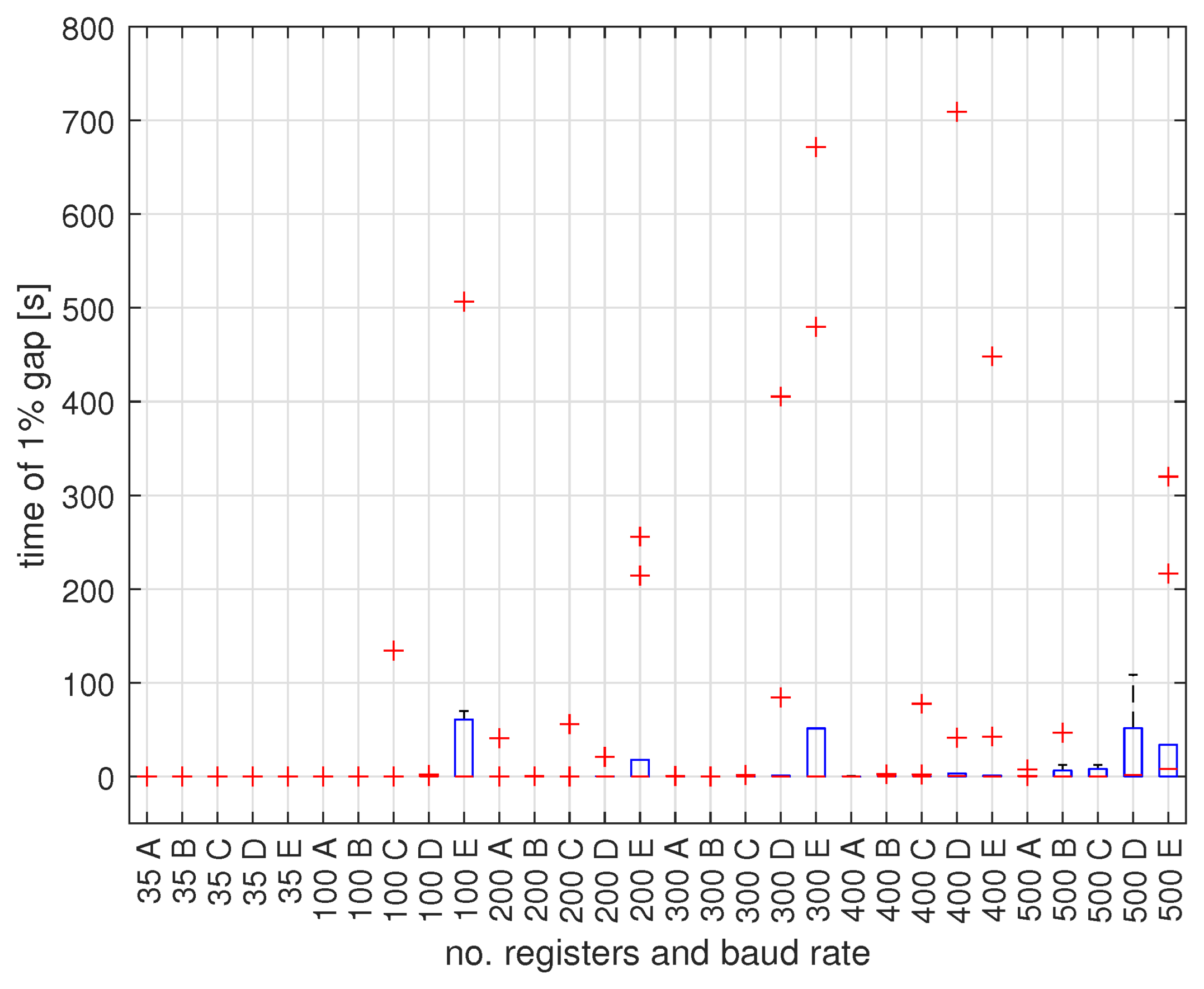
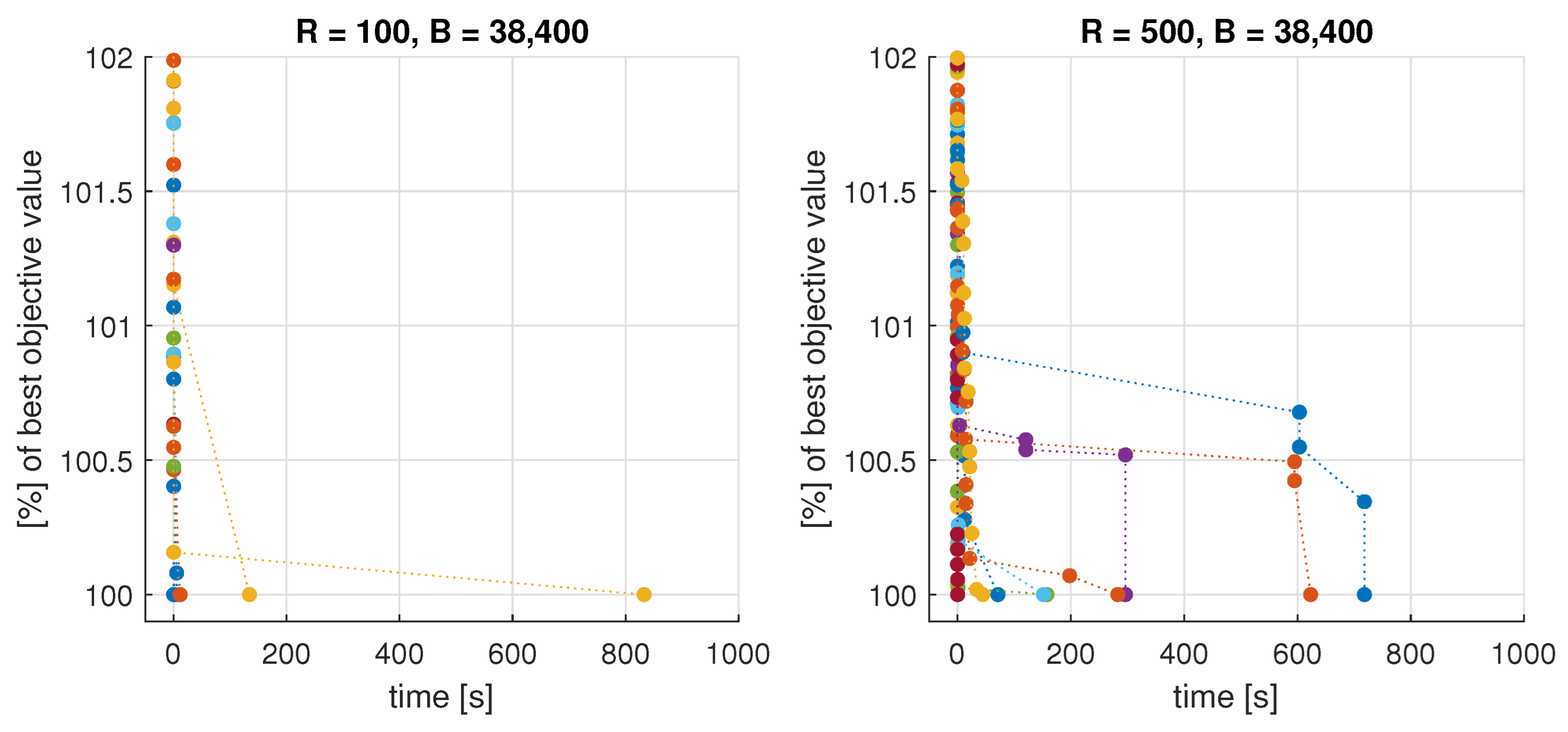
5. Experimental Verification
5.1. Benchmark Instances
5.2. Optimization Tools
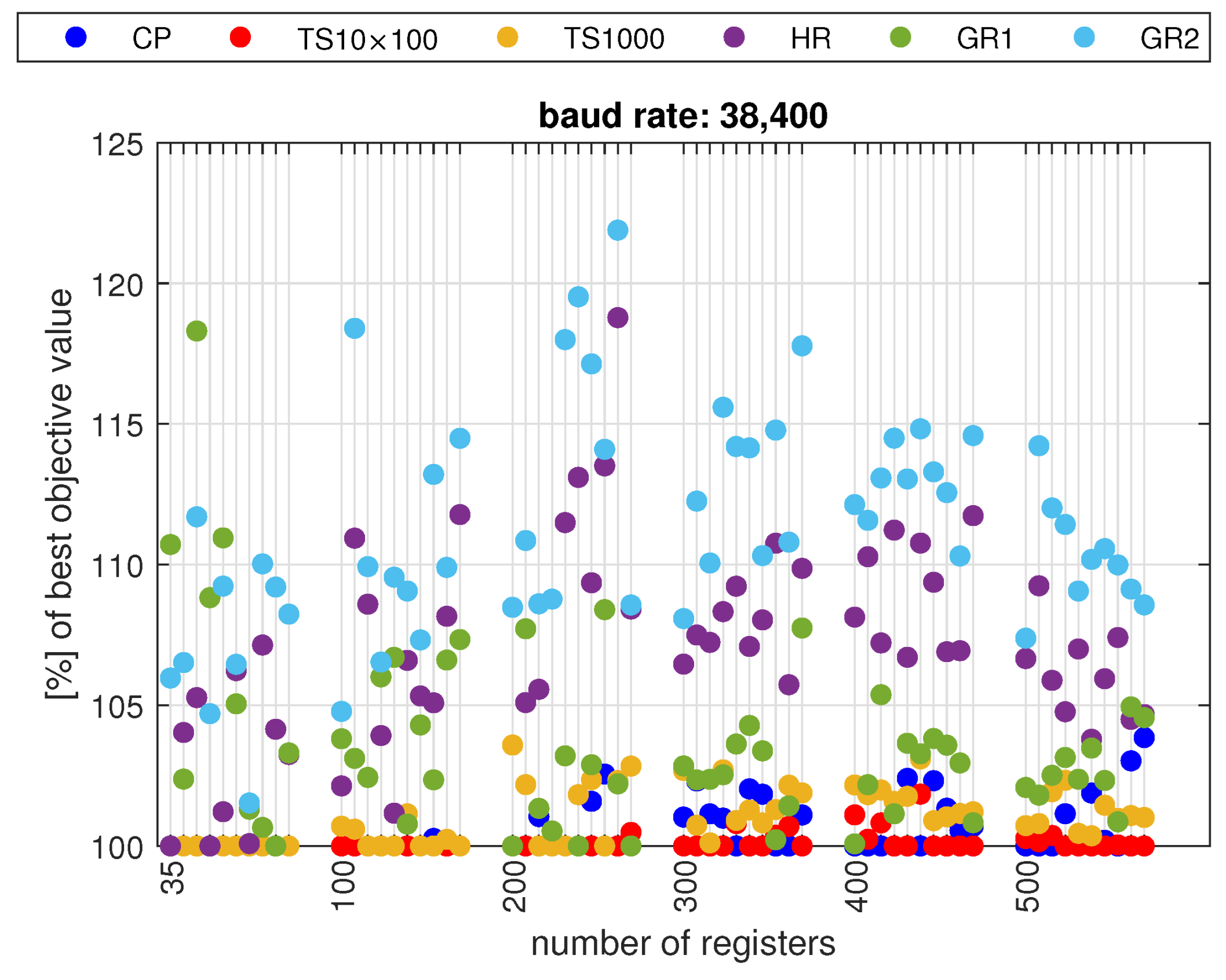
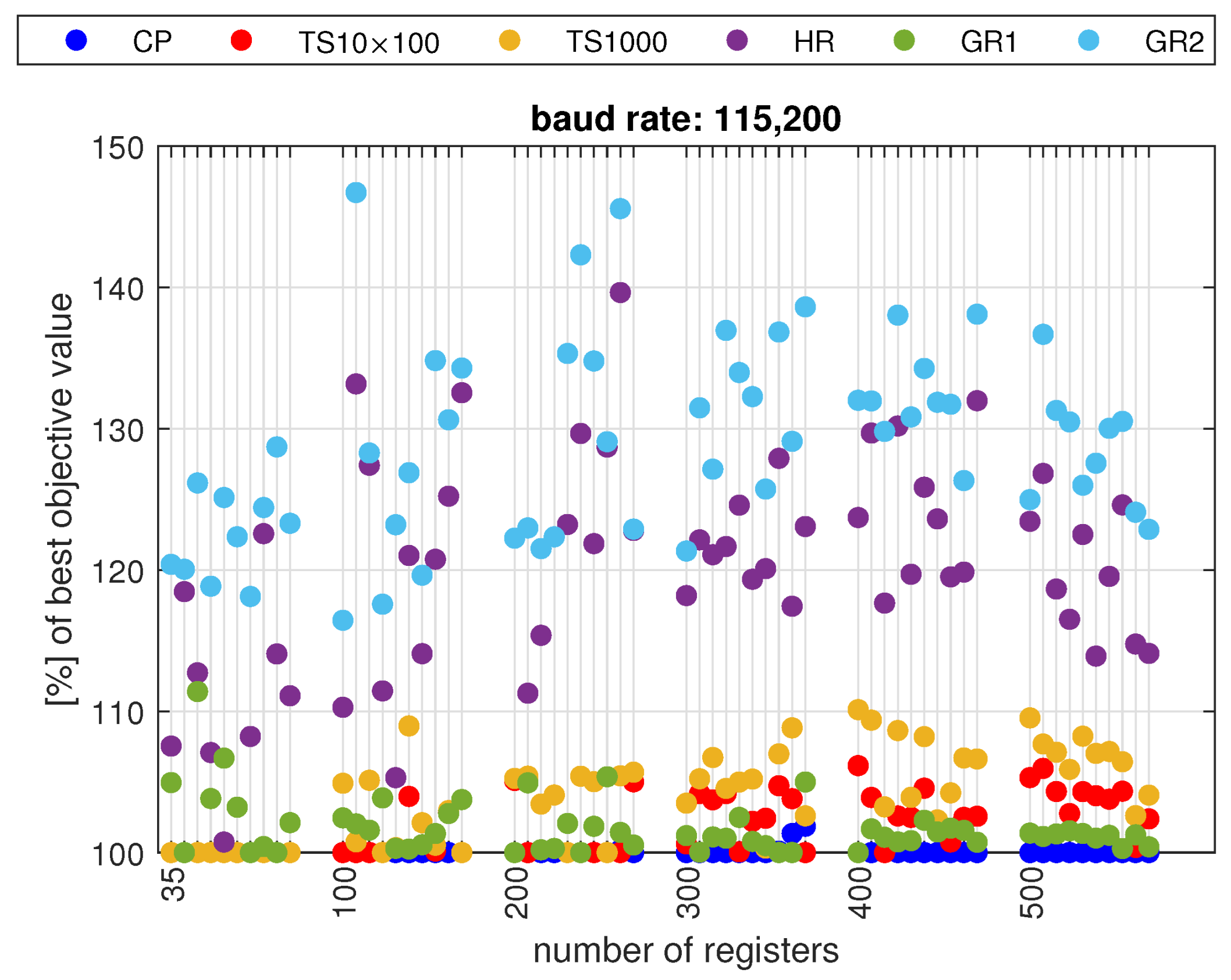
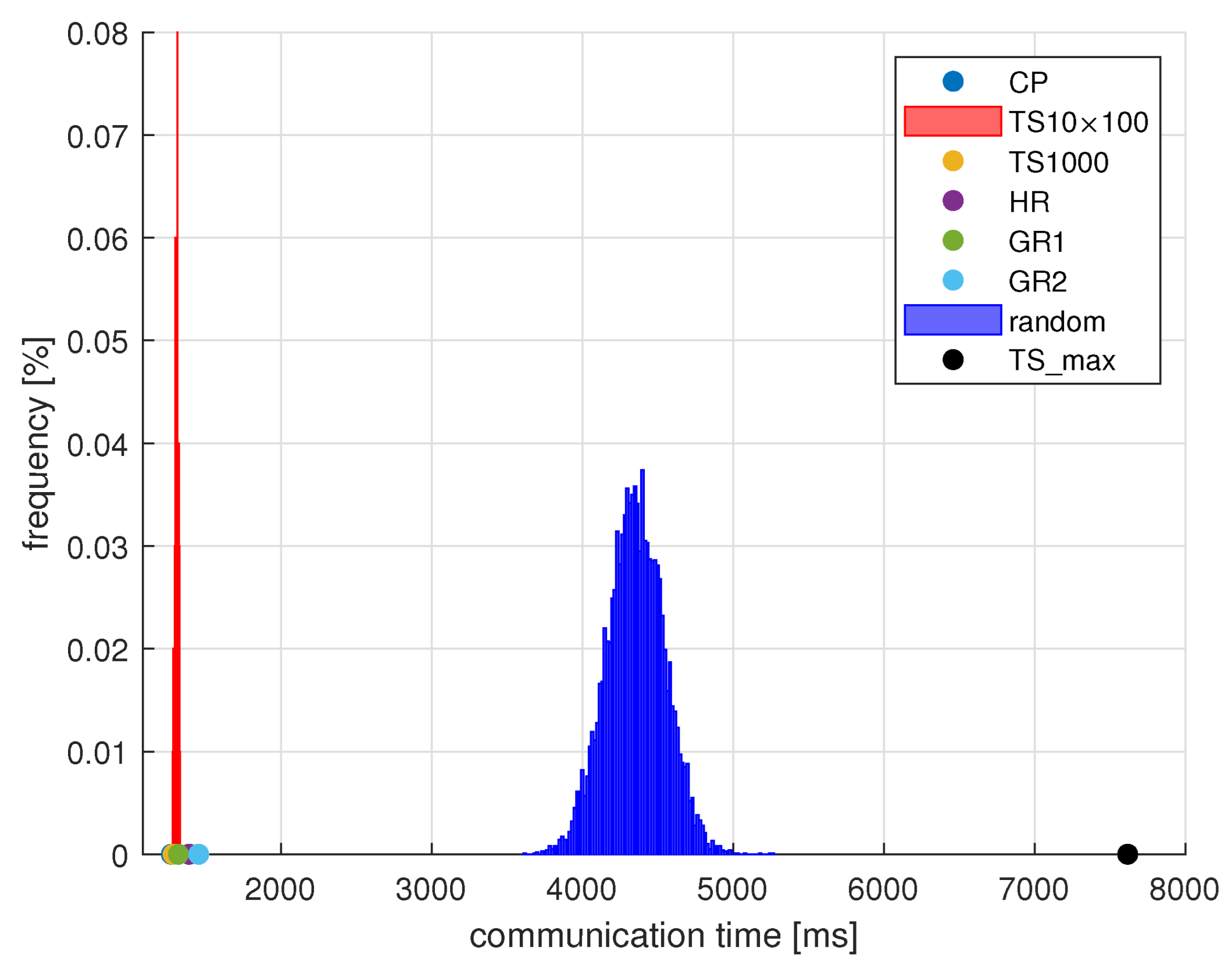
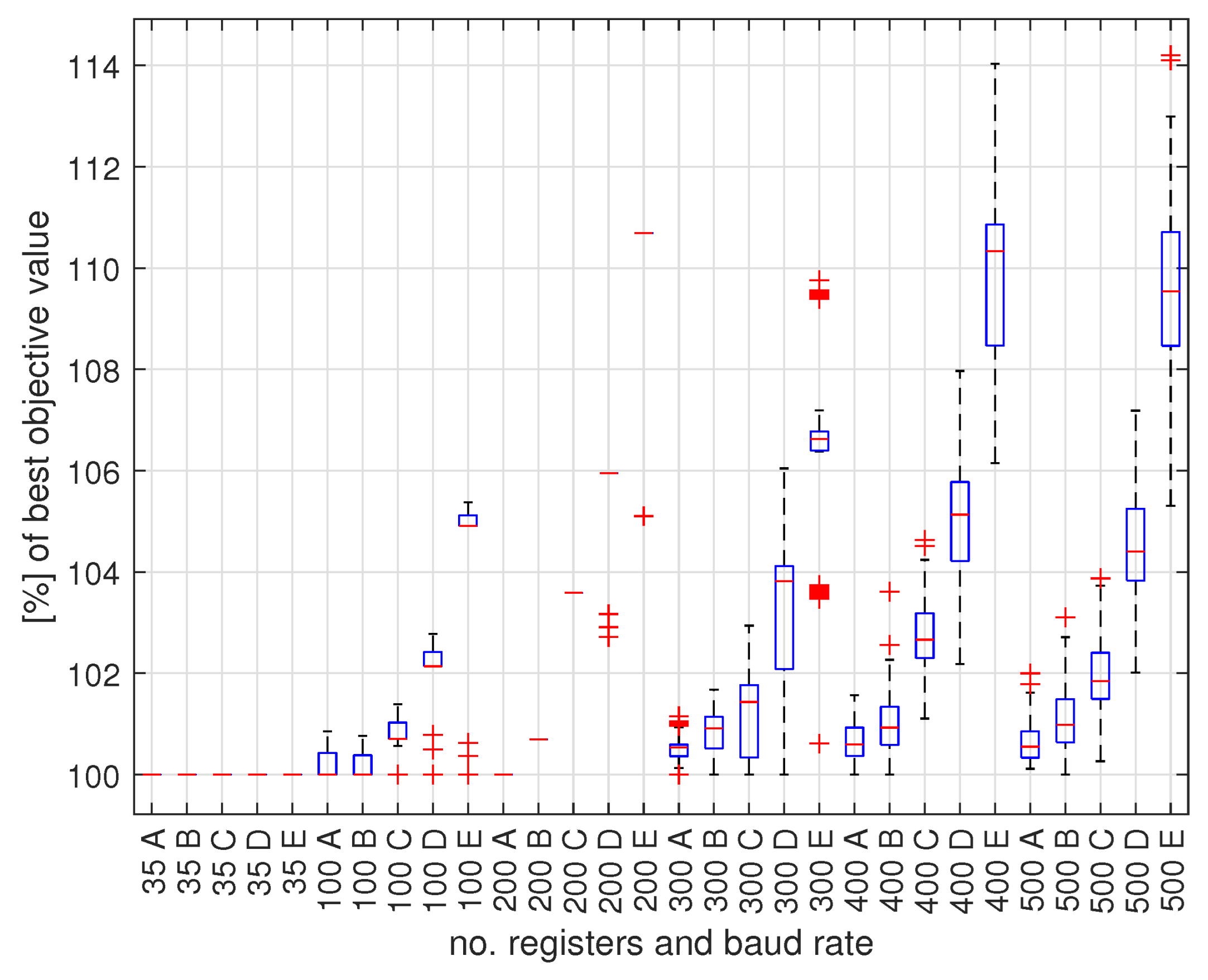
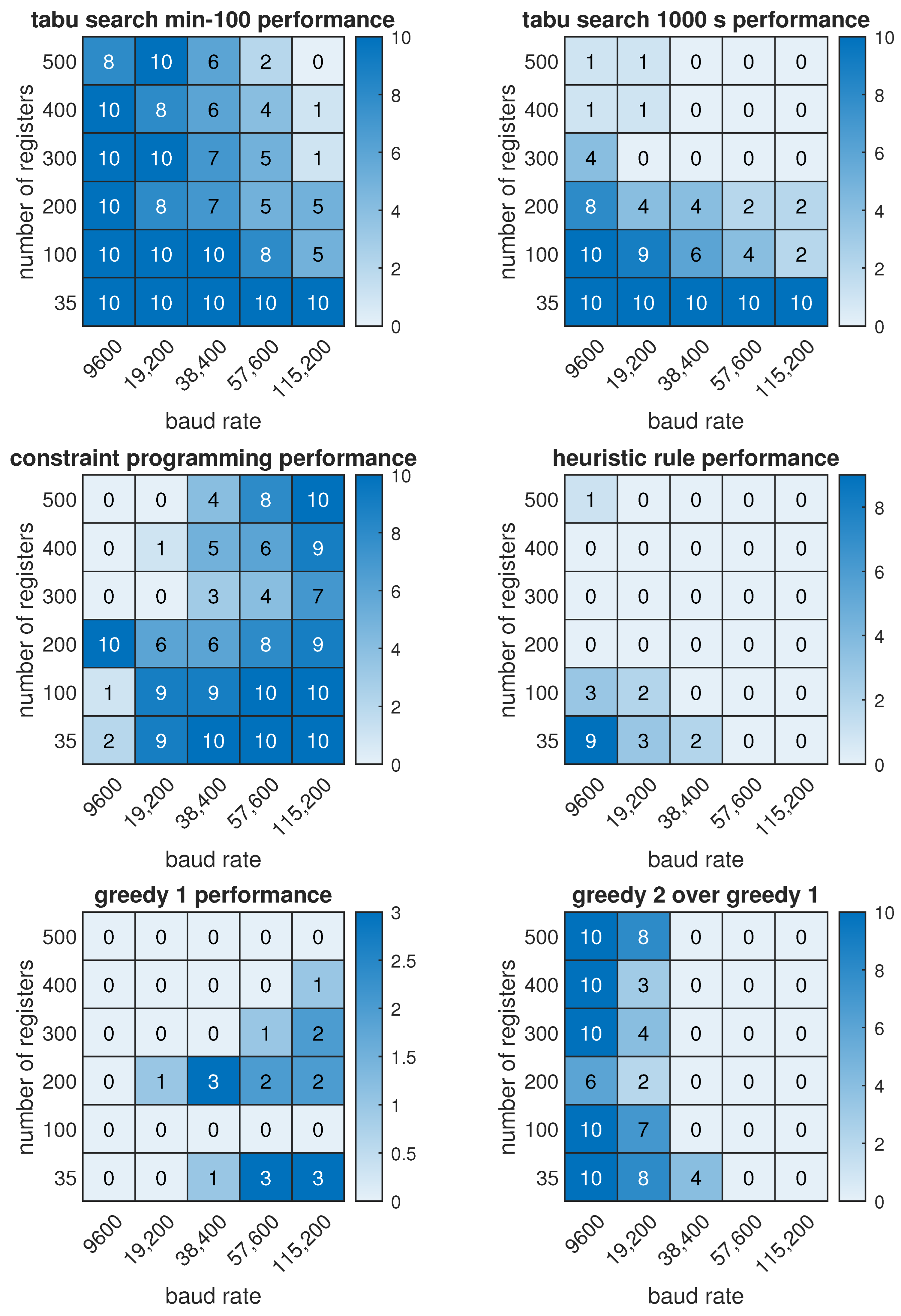
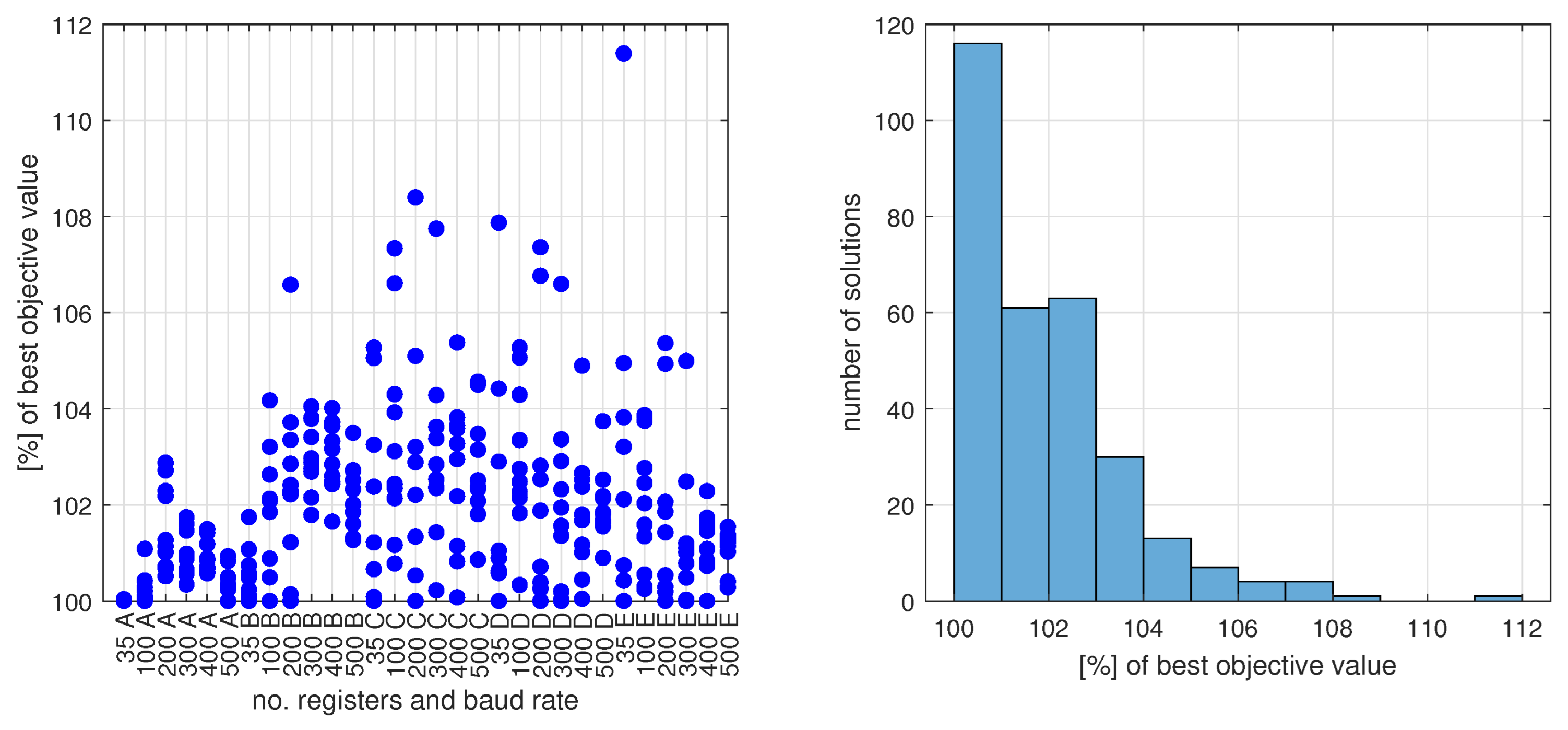
5.3. Results
6. Conclusions
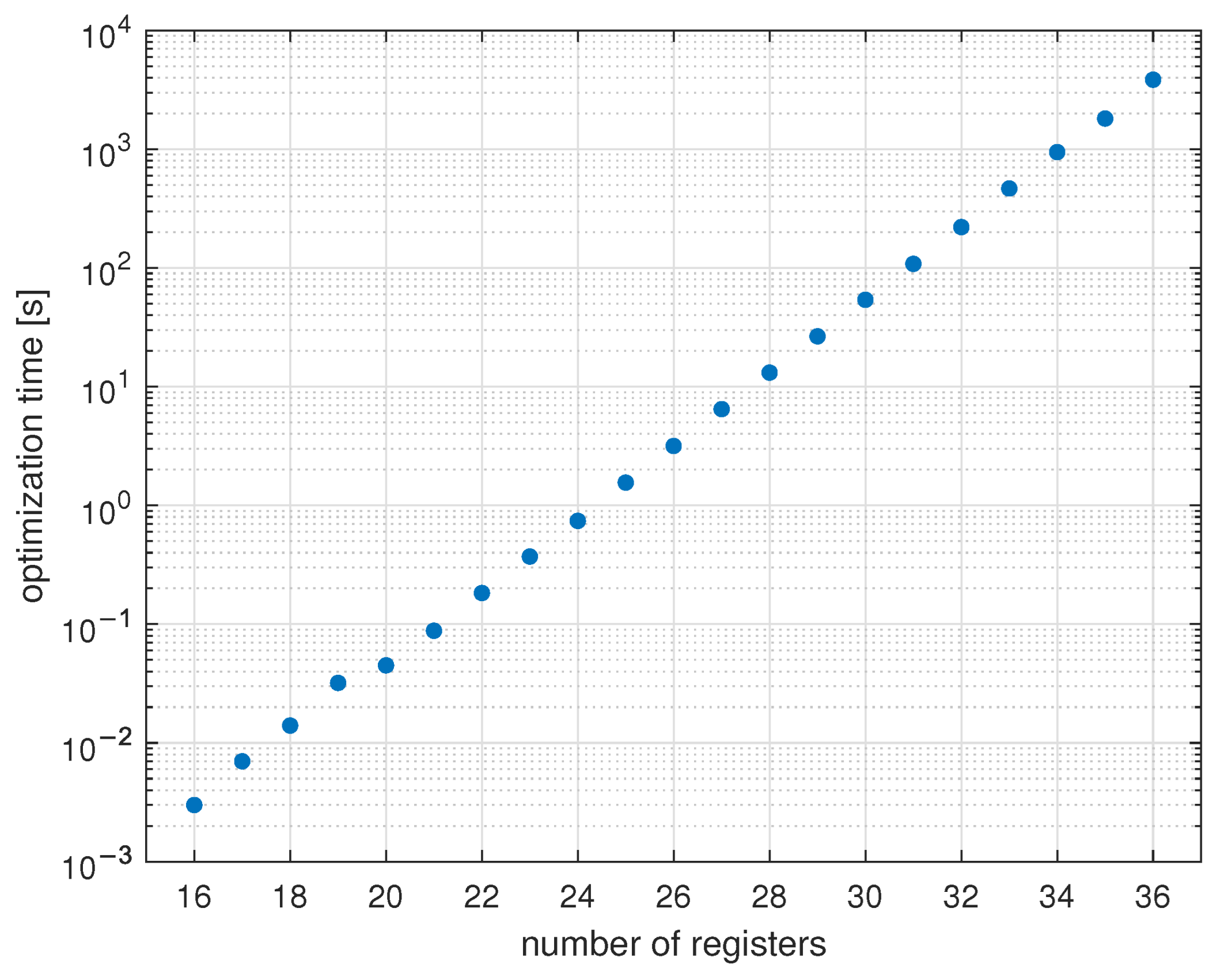
- The exhaustive search algorithm can be practically useful, but only for problems with up to 30…40 registers;
- An optimal solution can be constructed by a simple linear time algorithm described in the statement of Theorem 1, if the parameters of a problem instance meet the conditions and ;
- MILP is ineffective for the considered problem. For a large number of registers, it is unable to find a solution in a reasonable time;
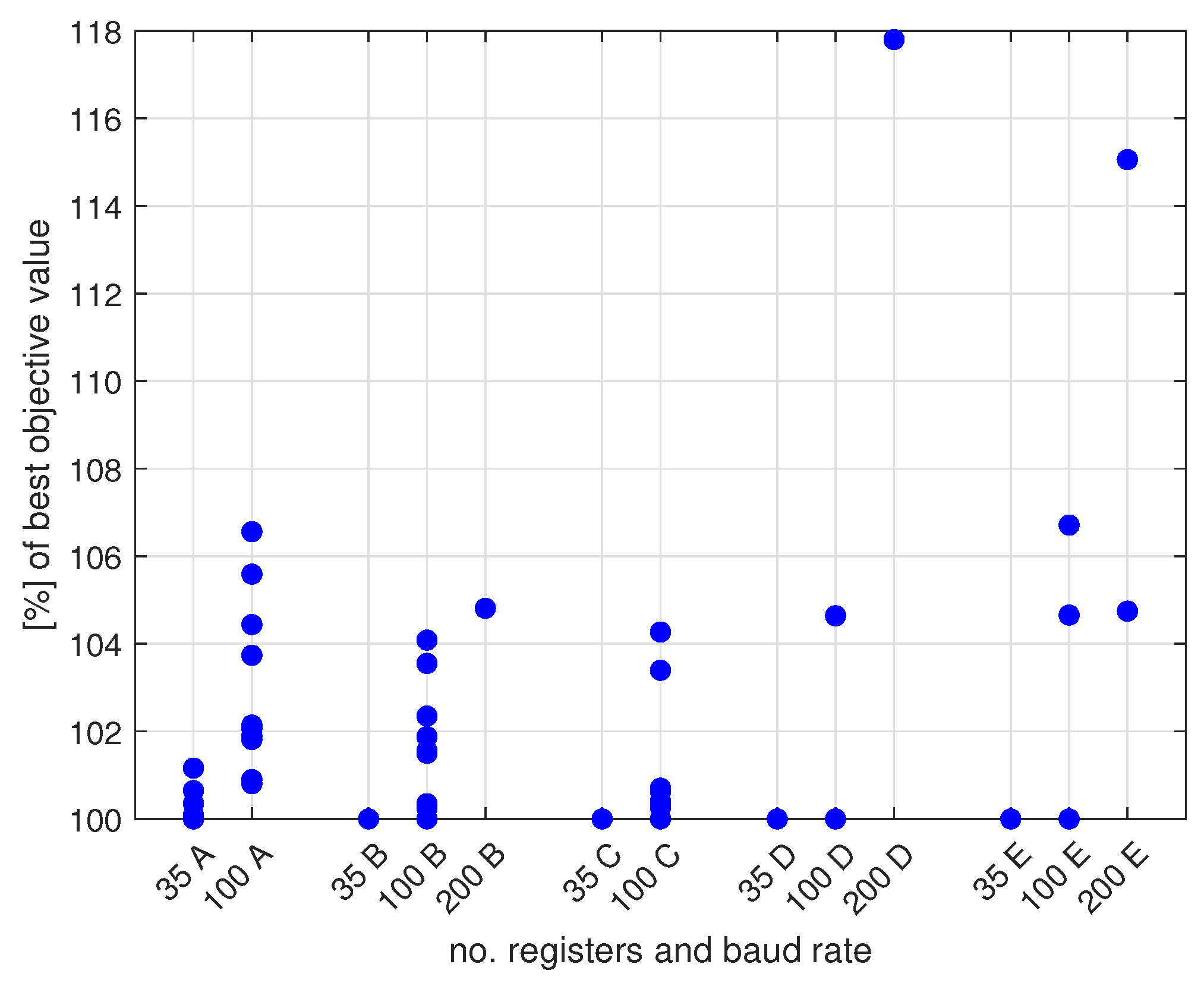
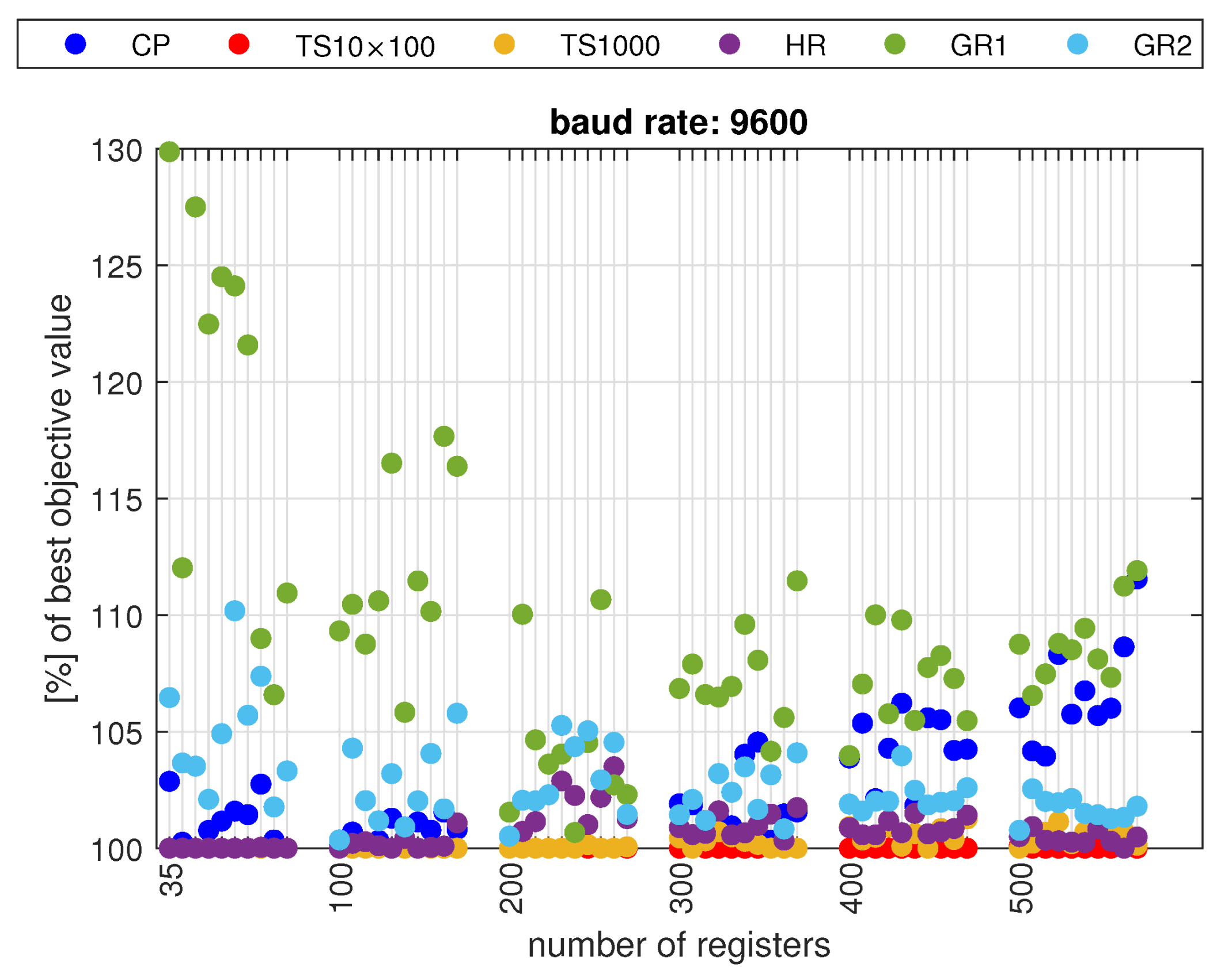
- The constraint programming (CP) provides better results for high transmission speeds, and the tabu search (TS) for low transmission speeds;
- It is more beneficial to run TS multiple times for a short time, with different random initial values, than to run it once for a longer time;
- CP and TS algorithms require significant computing power. They can be run on a PC, but not on a PLC;
- The proposed deterministic algorithms (greedy or heuristic) provide slightly worse results than CP and TS, but they require little computing power, so they can be implemented on a PLC;
- In some applications, the ability to quickly find a suboptimal solution on the PLC, which is slightly worse than the unknown optimal solution, will be sufficient.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Silva, M.; Pereira, F.; Soares, F.; Leão, C.P.; Machado, J.; Carvalho, V. An Overview of Industrial Communication Networks. In Proceedings of the New Trends in Mechanism and Machine Science; Flores, P., Viadero, F., Eds.; Springer: Cham, Switzerland, 2015; pp. 933–940. [Google Scholar]
- Thomesse, J. Fieldbus Technology in Industrial Automation. Proc. IEEE 2005, 93, 1073–1101. [Google Scholar] [CrossRef]
- Gaj, P.; Jasperneite, J.; Felser, M. Computer Communication Within Industrial Distributed Environment—A Survey. IEEE Trans. Ind. Inform. 2013, 9, 182–189. [Google Scholar] [CrossRef]
- IEC 61158; Industrial Communication Networks—Fieldbus Specifications. IEC: Geneva, Switzerland, 2007.
- Scanzio, S.; Wisniewski, L.; Gaj, P. Heterogeneous and dependable networks in industry—A survey. Comput. Ind. 2021, 125, 103388. [Google Scholar] [CrossRef]
- Titaev, A. Reducing update data time for exchange via MODBUS TCP protocol by controlling a frame length. Autom. Control Comput. Sci. 2017, 51, 357–365. [Google Scholar] [CrossRef]
- Rzonca, D. Performance Improvement of PLC—HMI Communication in CPDev Engineering Environment. Pomiary Autom. Robot. 2020, 24, 35–40. [Google Scholar] [CrossRef]
- Rzonca, D. Acceleration of Modbus Data Exchange between PLC and HMI Using the CPDev Engineering Environment. Pomiary Autom. Robot. 2022, 26, 85–89. [Google Scholar] [CrossRef]
- Găitan, V.G.; Zagan, I. Modbus Protocol Performance Analysis in a Variable Configuration of the Physical Fieldbus Architecture. IEEE Access 2022, 10, 123942–123955. [Google Scholar] [CrossRef]
- Zagan, I.; Găitan, V.G. Enhancing the Modbus Communication Protocol to Minimize Acquisition Times Based on an STM32-Embedded Device. Mathematics 2022, 10, 4686. [Google Scholar] [CrossRef]
- Găitan, V.G.; Zagan, I. Experimental Implementation and Performance Evaluation of an IoT Access Gateway for the Modbus Extension. Sensors 2021, 21, 246. [Google Scholar] [CrossRef] [PubMed]
- Bednarek, M.; Będkowski, L.; Dąbrowski, T. The selected functions of supervision and therapeutic system in a communication system. Diagnostyka 2005, 34, 31–36. [Google Scholar]
- Dutertre, B. Formal Modeling and Analysis of the Modbus Protocol. In Proceedings of the Critical Infrastructure Protection; Goetz, E., Shenoi, S., Eds.; Springer: Boston, MA, USA, 2008; pp. 189–204. [Google Scholar]
- Twaróg, B.; Gomółka, Z.; Żesławska, E. Time Analysis of Data Exchange in Distributed Control Systems Based on Wireless Network Model. In Proceedings of the Analysis and Simulation of Electrical and Computer Systems; Mazur, D., Gołębiowski, M., Korkosz, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 333–342. [Google Scholar] [CrossRef]
- Künzel, G.; Corrêa Ribeiro, M.A.; Pereira, C.E. A Tool for Response Time and Schedulability Analysis in Modbus Serial Communications. In Proceedings of the 2014 12th IEEE International Conference on Industrial Informatics (INDIN), Porto, Portugal, 27–30 July 2014; pp. 446–451. [Google Scholar] [CrossRef]
- Persechini, M.A.M.; Mendes, L.T.S. Performance analysis among different acquisition systems for process control. ISA Trans. 2020, 97, 86–92. [Google Scholar] [CrossRef]
- Kim, B.; Lee, D.; Choi, T. Performance evaluation for Modbus/TCP using Network Simulator NS3. In Proceedings of the TENCON 2015–2015 IEEE Region 10 Conference, Macao, China, 1–4 November 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Robert, J.; Georges, J.P.; Rondeau, E.; Divoux, T. Minimum cycle time analysis of Ethernet-based real-time protocols. Int. J. Comput. Commun. Control 2012, 7, 743–757. [Google Scholar] [CrossRef]
- Bożek, A.; Werner, F. Flexible job shop scheduling with lot streaming and sublot size optimisation. Int. J. Prod. Res. 2017, 56, 6391–6411. [Google Scholar] [CrossRef]
- Bożek, A. Energy Cost-Efficient Task Positioning in Manufacturing Systems. Energies 2020, 13, 5034. [Google Scholar] [CrossRef]
- Glover, F. Tabu Search—Part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M.; Martí, R. Principles and Strategies of Tabu Search. In Handbook of Approximation Algorithms and Metaheuristics, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 361–377. [Google Scholar] [CrossRef]
- Anand, R.; Aggarwal, D.; Kumar, V. A comparative analysis of optimization solvers. J. Stat. Manag. Syst. 2017, 20, 623–635. [Google Scholar] [CrossRef]
- Laborie, P.; Rogerie, J.; Shaw, P.; Vilím, P. IBM ILOG CP optimizer for scheduling. Constraints 2018, 23, 210–250. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bożek, A.; Rzonca, D. Communication Time Optimization of Register-Based Data Transfer. Electronics 2023, 12, 4917. https://doi.org/10.3390/electronics12244917
Bożek A, Rzonca D. Communication Time Optimization of Register-Based Data Transfer. Electronics. 2023; 12(24):4917. https://doi.org/10.3390/electronics12244917
Chicago/Turabian StyleBożek, Andrzej, and Dariusz Rzonca. 2023. "Communication Time Optimization of Register-Based Data Transfer" Electronics 12, no. 24: 4917. https://doi.org/10.3390/electronics12244917