1. Introduction
With the booming development of the field of IoV [
1], the Internet of Vehicles (IoV)—a deep integration of vehicles and information technology—changes transportation and mobility with an unprecedented speed. The IoV system is a comprehensive system that organically integrates the traditional vehicle self-organizing network and the Internet of Things (IoT). Telematics takes mobile vehicles as the carrier of information perception and utilizes next-generation information and communication technologies, such as sensor network technology [
2] and radio frequency identification technology [
3], to connect vehicles to the Internet. A variety of innovative applications have been realized, including intelligent navigation [
4], remote diagnosis, vehicle automation [
5], and so on. The rapid development of IoV has not only greatly enhanced the driving experience at the technological level but has also positively impacted society in a number of areas, including enhancing road safety, improving transportation efficiency, and contributing to environmental sustainability. In the future, as technology continues to advance, IoV will continue to drive innovation in mobility, bringing even greater improvements in urban mobility and road safety, as well as providing people with more convenient and sustainable mobility options.
In IoV, with the rapid development of connected vehicles and intelligent transportation systems [
6], cybersecurity has become a crucial topic. The complexity and high degree of interconnectivity of connected IoV systems, while enhancing convenience and efficiency, are also accompanied by potential cybersecurity risks. Hackers can utilize potential vulnerabilities to invade IoV systems, thereby threatening road safety, personal privacy, and data security. In recent years, there has been a proliferation of IoV security incidents triggered by vulnerabilities. For example, in March 2022, Mitsui Bussan Secure Directions, a Japanese cybersecurity firm, announced that a group calling itself “Pandora” had threatened to disclose Denso’s trade secrets on the dark web. The group claimed to have stolen more than 157,000 purchase orders, emails, and sketches, totaling 1.4 terabytes of data. Pandora used ransomware to carry out a cyberattack on Denso, which encrypts company data and places companies at risk of data leakage if they do not pay the ransom. Therefore, it has become particularly important to study and solve the problem of IoV vulnerabilities. Network security managers must pay close attention to the vulnerability situation and fix the vulnerabilities in a timely manner in order to safeguard the security of IoV devices and systems.
The uneven distribution of vulnerabilities in the IoV drives a huge challenge for cyber security. IoV integrates information technology and vehicles and involves numerous complex systems and components, from intelligent vehicles to back-end servers, which can be potential targets of vulnerability attacks. The diversity of components and systems leads to the trend of an uneven distribution of vulnerabilities in the IoV; therefore, effective management and application of vulnerability information and keeping up-to-date with the latest vulnerabilities are crucial for securing the cybersecurity of the IoV system [
7]. Although the National Vulnerability Database (NVD), Information Security Vulnerability Portal (VULHUB), and Common Vulnerabilities and Exposures (CVE) have been developed in the U.S., it is not easy for them to manage and apply vulnerability information in a timely manner. Moreover, different vulnerability repositories use different categorization methods and naming conventions, resulting in the same vulnerability taking different forms in each repository [
8]. This makes it necessary for cybersecurity managers to consume a lot of time and effort to collect, integrate, and filter information from multiple vulnerability repositories. Classification of vulnerabilities in IoV [
9] can discover vulnerability information in a timely and effective manner, help cybersecurity managers to quickly recognize vulnerabilities, and also prioritize vulnerabilities so as to target vulnerability remediation and defense strategies to improve the overall security of the IoV system.
Existing vulnerability classification algorithms suffer from a low precision rate, recall rate, and F1 score when dealing with unbalanced sample data. This makes it difficult for them to effectively deal with the large amount of vulnerability information emerging from IoV. Vulnerability classification [
10] is essentially a processing method for vulnerability information, which analyzes and categorizes vulnerabilities based on their characteristics, attributes, etc., by choosing appropriate classification algorithms [
11]. However, there are multiple types of vulnerabilities in the telematics environment [
12,
13,
14], some of which occur less frequently, resulting in their relatively small sample size and incomplete vulnerability information. With such uneven sample data, existing vulnerability classification algorithms may not be able to adequately extract the vulnerability features from the few classes and instead misclassify the samples into the more numerous feature-rich vulnerability classes. Such misclassification may lead to the neglect of important vulnerabilities, thus bringing potential risks to the cybersecurity of telematics. Only through continuous innovation and improvement can vulnerability classification algorithms better address the challenges posed by the massive number of vulnerabilities in the IoV environment, enhance the ability of cybersecurity management, and safeguard user privacy and data security.
In order to overcome the limitations of vulnerability classification algorithms in the face of imbalanced samples, a new vulnerability classification algorithm, KG-KNN, is proposed, which is based on weighted Euclidean distance and a feature knowledge graph, which improves the classification of imbalanced vulnerability samples. The algorithm employs knowledge graph to assist vulnerability classification, which transforms the correlation relationship between feature words into the shortest path between feature word nodes in the knowledge graph. Considering that a few categories of samples cannot fully extract feature values, the concept of association distance is introduced to improve the traditional Euclidean distance algorithm [
15], and a weighted Euclidean distance algorithm is proposed. The algorithm adds the association distance between features to the Euclidean distance calculation and calculates the similarity between loophole features from multiple dimensions. Then, the similarity between features is applied to the K-nearest neighbor (KNN) classification algorithm to classify vulnerability information. To obtain the optimal features, the features describing the text are extracted using the term frequency–inverse document frequency (TF-IDF) algorithm. In addition, to integrate vulnerability information and obtain the correlation distance between features, this paper proposes that multiple information sources can be integrated so a unified knowledge graph of vulnerabilities in IoV can be established, and the vulnerability information and the correlation relationship between feature words can be stored in the knowledge graph to form a more complete knowledge system. Classifying vulnerability information through the above steps can help security managers manage vulnerabilities and effectively respond to various network security threats.
The main contributions of this paper are as follows:
We propose a new vulnerability classification algorithm. To improve the classification performance of imbalanced samples, we offer a new vulnerability classification algorithm, KG-KNN, based on weighted Euclidean distance and the feature knowledge graph. This algorithm increases the correlation distance between features in a similarity calculation, achieving a multi-dimensional similarity calculation and overcoming the limitations of imbalanced sample classification.
Construct the feature knowledge graph based on the optimal feature word set. This paper integrates vulnerability information from multiple sources, extracts the optimal feature word set, and constructs a feature knowledge graph to solve the problem of dispersed vulnerability information of the IoV and obtain the association distance.
We propose a weighted Euclidean distance algorithm. This paper introduces the concept of association distance, improves the traditional Euclidean distance algorithm, and presents a weighted Euclidean distance algorithm to solve the problem that the samples of a few categories cannot fully extract the feature values.
The structure of this article is as follows.
Section 2 reviews the related research at home and abroad.
Section 3 provides the background knowledge.
Section 4 introduces the design strategy of the algorithm.
Section 5 describes the process of vulnerability classification and proposes an improved vulnerability classification algorithm.
Section 6 outlines the conclusion of this paper.
3. Background
This section will introduce the main tools used in KG-KNN, including the knowledge graph, K-nearest neighbor classification algorithm, and vulnerability classification.
3.1. Knowledge Graph
Google formally introduced the concept of knowledge graph [
31] (KG) in 2012, aiming to realize a more intelligent search engine, and then KG began to be widely used in academia. Its core idea is to organize knowledge into a graphical structure, where nodes represent entities and edges define relationships between entities. This graphic structure makes the associations between knowledge intuitive and easy to understand. The construction of a knowledge graph typically involves several key steps, including knowledge extraction, knowledge fusion, knowledge storage, and other related processes [
32]. The construction process is shown in
Figure 1.
Knowledge extraction is the first step in building a knowledge graph. Different processing methods are used for different types of data. For semi-structured data, entities, relationships, and attributes need to be further extracted to transform the information into structured information. Unstructured data needs to be processed by natural language processing technology. In the knowledge fusion stage, knowledge from different data sources needs to be integrated to eliminate conflicts, duplications, and inconsistencies. This involves the alignment of various entities, the disambiguation of entities with the same name, the merging of relationships, etc., to provide more complete and accurate data for building knowledge graphs.
In the knowledge storage stage, structured semantic network data are mainly stored in the database. The general storage medium is various types of graph databases. Neo4j is a typical, high-performance graph database. Compared with other non-relational databases, it supports ACID transactions and has all the characteristics of a mature database. It can solve the vulnerability areas of low data value density and large quantity questions.
Knowledge application refers to applying the constructed knowledge graph to actual scenarios to support various intelligent applications and decision-making needs. The knowledge graph obtained through the above steps can provide rich knowledge support and semantic associations for various fields.
3.2. K-Nearest Neighbor Classification Algorithm
The K-nearest neighbor classification algorithm (also known as the KNN algorithm) [
33], a traditional pattern recognition method, is widely used in text automatic classification research and is accurate. The idea is that for each sample, the K-nearest neighbors can be taken as the basis for classifying this sample. Among the commonly used methods to calculate the distance are the Euclidean distance [
34], Manhattan distance [
35], cosine distance [
36], Chebyshev distance [
37], and so on.
Euclidean distance is a commonly used distance metric to measure the similarity or distance between samples. It calculates the straight-line distance between two points in Euclidean space, also known as Euclidean distance. The main steps are to compute the difference between two vectors in each dimension, then square the difference and sum it, and finally square the sum of squares to obtain the Euclidean distance. For two n-dimensional vectors
and
, the equation for Euclidean distance is shown below:
Here, denotes the Euclidean distance between vector x and vector y.
The procedure of the KNN algorithm is as follows:
Divide the preprocessed samples into a training sample set and a test sample set;
Choose an appropriate distance equation to calculate the distance between the word vectors in the test samples and the word vectors in each training sample;
Sort the word vectors of the training samples in the order of distance from most petite to most significant;
Setting the value of parameter k and selecting the top K-word vectors from the previously sorted queue as the set of neighbors;
Calculate the frequency of occurrence of the first K vectors and record it;
Return the category with the highest frequency of occurrence of the first K vectors as the predicted classification of the test sample.
The KNN algorithm is simple to operate and has high accuracy; however, the algorithm has some problems in calculating similarity using Euclidean distance. When the target samples are highly imbalanced, the minority class samples are easily affected by the majority class samples when determining the categories, which leads to a poorer classification effect, resulting in a bias in the prediction results.
3.3. Vulnerability Classification
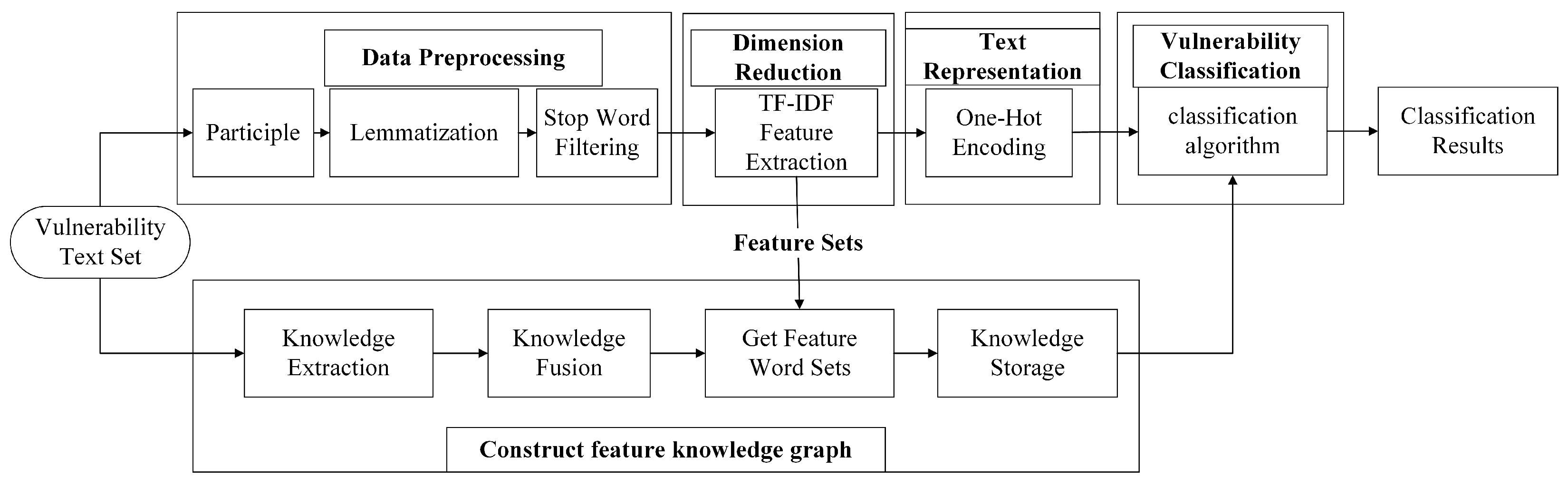
Vulnerability classification is the process of categorizing and labeling known vulnerability information according to a developed system or standard and then organizing the vulnerability information into one or more categories. This process is mainly completed automatically by computer. The detailed operation of vulnerability classification is illustrated in
Figure 2. Initially, the vulnerability text undergoes preprocessing, after which the data is dimensionally reduced to obtain low-dimensional data for vector representation. The vector representation of the dataset is divided into a training set and a test set. The training set is input into the classifier for training to obtain the appropriate classifier parameters, and then the test set is input into the classifier to obtain the classification results.
Text preprocessing: Before classifying the vulnerability text, preprocessing operations are necessary. These typically involve removing punctuation, splitting words, reducing linguistic complexity, and applying deactivation filtering.
Dimensionality reduction processing: Dimensionality reduction processing techniques are used to filter irrelevant or redundant features and retain the most distinguishable and relevant features to form the optimal set of features;
Text representation: The classifier cannot recognize the form of the above feature set, and it needs to be converted into a declaration that the machine learning algorithm can identify to carry out the next classification task;
Classification: According to the characteristics of the vulnerability text, select the appropriate classification algorithm, use the training set for training, obtain the proper classifier parameters, and then input the test set into the classifier to obtain the classification results.
5. Methodology
In this section, we will describe the specific steps involved in classifying vulnerability data using the vulnerability classification algorithm proposed in this paper.
Figure 4 illustrates the flowchart of this section.
This section is divided into five blocks to introduce the steps in detail: data preprocessing, dimensionality reduction processing, constructing the feature knowledge graph, text representation, and the vulnerability classification algorithm based on the feature knowledge graph (KG-KNN).
5.1. Data Preprocessing
Data preprocessing is a crucial step for vulnerability classification, which refers to the processing and conversion of the original vulnerability data to make it better adapted to the vulnerability classification algorithm. In this paper, there is a large amount of text data in the vulnerability description text set that is not useful for vulnerability classification, and this text data has a significant impact on the efficiency and accuracy of feature extraction, so it is necessary to preprocess the text data before vulnerability classification.
This paper mainly divides the vulnerability description text preprocessing into three steps: word division, word shape reduction, and deactivation word filtering.
Participle. The purpose of word separation is to cut the continuous text sequence into separate words or lexical units, which provides the basis for the subsequent text-processing tasks. With its diverse segmentation patterns and wide range of application areas, Jieba word segmentation has become the most commonly used Chinese text segmentation tool in China. In this paper, we use the precise mode of stuttering participle, which will try to cut the text into the most reasonable word combinations according to the dictionary and algorithm.
Lemmatization. The purpose of lexical reduction is to reduce different forms of words to their root forms to reduce the vocabulary’s diversity and dimensionality. This paper uses the NLTK natural language processing tool library for the word form reduction operation. After decomposing each text into a list of words, we perform word form reduction on each word by referencing the word form relations in the WordNet database to convert the terms into their original forms or stems.
Stop word filtering. The purpose of deactivation word filtering is to reduce the noise and redundant information in the text to improve the efficiency and accuracy of the subsequent text analysis task. In this paper, we utilize the TF-IDF algorithm to filter out stop words, and we apply Equation (
9) to identify and exclude frequently occurring words that do not contribute significantly to the classification task. These words are then incorporated into the Chinese stop words list to create a specialized stop words list tailored to the characteristics of vulnerability data.
Following the data preprocessing steps outlined above, we can mitigate the impact of extraneous information, thereby enhancing the efficiency and precision of feature extraction. Consequently, we can furnish more refined input data to bolster the performance of the subsequent classification task.
5.2. Dimension Reduction
Dimension reduction is crucial to the effectiveness of vulnerability classification algorithms, which mainly reduces the computational complexity by reducing the number of feature dimensions. In this section, we apply the TF-IDF algorithm to extract features from the vulnerability description text and identify more significant keywords for vulnerability classification.
The following describes the specific steps of dimensionality reduction processing.
5.3. Construct Feature Knowledge Graph
Constructing a feature knowledge graph is a necessary step before vulnerability classification. In this study, we employ a feature knowledge graph as a vital tool to integrate IoT vulnerability information, depict the interrelationships among features, and provide a more precise and comprehensive feature similarity metric within the vulnerability classification process. This approach significantly enhances the effectiveness of vulnerability classification.
The construction of the feature knowledge graph mainly involves the following steps.
Knowledge extraction. The first step in constructing a knowledge graph is knowledge extraction. This paper obtains a large amount of structured data after the automated extraction of IoV vulnerability data from vulnerability repositories such as NVD, VULHUB, and CVE. Each data column is considered a specific entity, attribute, and relationship, and the table structure and data in the vulnerability repositories are converted into RDF graphs through direct mapping.
Knowledge fusion. After executing the knowledge extraction operation, the next crucial step involves integrating the IoV vulnerability data sourced from different vulnerability repositories. This integration process aims to resolve conflicts, eliminate duplications, and rectify inconsistencies, encompassing essential tasks such as entity alignment, entity disambiguation, and attribute alignment. The refined and processed data will be stored in documents, serving as a robust and precise basis for the subsequent construction of the knowledge graph.
Get feature word sets. After fusing the vulnerability data, we proceed with the preprocessing and dimensionality reduction of the vulnerability description text to extract the most relevant features and their correlations. Simultaneously, we store the generated optimal feature vocabulary and associated vulnerability information in a CSV file. We have elucidated the detailed steps of these preprocessing and dimensionality reduction operations in
Section 5.1 and
Section 5.2.
Knowledge storage. We have selected the Neo4j graph database for storing vulnerability data. We reserved the above-mentioned integrated data in CSV files and imported them into Neo4j. We constructed entities and relationships using the Cypher query language, ultimately creating the feature knowledge graph. As illustrated in
Figure 5, CVE-2021-43963 is the assigned vulnerability number, categorized as having a medium risk level, falling under the information exposure type, and matching the keyword ‘mode’.
5.4. Text Representation
In vulnerability classification algorithms, it is imperative to convert textual data into computationally tractable vectors via text representation techniques, facilitating the execution of subsequent tasks. The standard text representation methods are one-hot encoding, bag-of-words model, word2vec, etc. Since the category labels in this paper are discrete features, we use one-hot encoding to represent the filtered features in binary form to ensure the efficiency of vector construction. The one-hot encoding extends the discrete attribute feature values of each vulnerability text into the Euclidean distance, and the importance of the attribute features corresponds to a certain point in the Euclidean distance to realize the vulnerability text’s representation.
The specific steps are as follows:
Determine the categorization variables. First, it is necessary to determine which features are categorization variables, i.e., the number of elements;
Establish a vocabulary. A vocabulary needs to be built for each categorical variable, listing all its possible values and assigning a unique index or number to each matter;
One-hot encoding. For each sample categorical variable, map its raw fetches to the corresponding vocabulary index and convert that index to a binary vector. In this vector, the element corresponding to the index position is 1, and the rest of the parts are 0. The vector representation of the partial vulnerability description text is shown in
Table 2.
5.5. Vulnerability Classification Algorithm Based on Feature Knowledge Graph (KG-KNN)
This subsection proposes a new vulnerability classification algorithm (KG-KNN) based on the weighted Euclidean distance algorithm and feature knowledge graph. It adds the correlation distance between features to the similarity computation, which realizes the multi-dimensional calculation for a few categories and improves the vulnerability classification effect.
Below, we will introduce the specific process of classification using KG-KNN, and
Figure 6 illustrates the flowchart.
Data preprocessing. The obtained vulnerability description text set is subjected to preprocessing operations such as word splitting, word shape reduction, and deactivation word filtering on the training and test text sets. The detailed steps are described in
Section 5.1.
Dimension reduction. Use the TF-IDF algorithm to reduce dimensionality on the training text set and test text set after the preprocessing operations to form the training text feature set and test text feature set. The detailed steps are described in
Section 5.2.
Text representation. The text representation is of the training text feature set and test text feature set using solo thermal coding to obtain the feature representation set. The detailed steps are described in
Section 5.3.
Partition the dataset. Following an 8:2 split, the feature representation set is divided into two mutually exclusive parts. One part serves as the training text feature set, while the remaining data is designated as the test text feature set.
Calculate the word vector distance. Let is the n-dimensional vector after the text representation of the test text feature set and is the n-dimensional sample vector in the training set . Calculate the distance between the word vectors in the test text and the word vectors in each training text as follows:
- –
Set two-word vectors and and use them to represent the similarity distance between the test text set and the training text set;
- –
Calculate the Euclidean distance between word vectors
using Equation (
1);
- –
Obtain the shortest path length of the two-word vectors corresponding to the feature words in the feature knowledge graph, where when ;
- –
Calculate the average value of the sum of the shortest path lengths of all feature words in the sample vector in the knowledge graph according to Equation (
10), called the association distance
, where m represents the number of feature words with the shortest path not being 0;
- –
According to Equation (
11), use the correlation distance to weigh the Euclidean distance and obtain the final sample distance
.
Training data sorting. Sort the vectors of training data in the order of final sample distances from the most minor to the most significant;
Select k neighbors. Set the size of parameter k and select the top k vectors from the above-sorted queue as the set of neighbors;
Calculate frequency. Calculate the frequency of occurrence of the first k vectors and sort them in descending order;
Return prediction results. Return the category with the highest frequency as the predicted classification of the test data.
7. Conclusions
To improve the classification effect of imbalanced samples, this article proposes an improved vulnerability classification algorithm. This algorithm uses the calculation principle of Euclidean distance and combines the critical path algorithm of the knowledge graph to calculate the correlation distance and the weighted operation of Euclidean distance. It effectively utilizes the correlation between vulnerability features to improve the performance of the classification algorithm. Through experiments with three classic classification models and comparing the results of the macro average and weighted average, it was found that the vulnerability classification algorithm based on the feature knowledge graph is better than other models in terms of precision, recall rate, and F1 score. The experimental results reflect that the algorithm can better classify imbalanced samples and verify the effectiveness of the algorithm proposed in this article. This algorithm is expected to play an important role in the field of vulnerability research and security protection, providing useful exploration and practice for improving system security and reducing potential risks.
The limitation of our current research lies in the reliance on the TF-IDF algorithm for vulnerability feature extraction, which predominantly considers the impact of features at a global level while neglecting their concurrent influence at the local level. It makes the algorithm have certain shortcomings in capturing local information, specific context, and subtle differences. Future research directions need to explore feature extraction methods that are more adaptable to complex contexts to better capture global and local information and improve the model’s performance. CNN’s proficiency in capturing spatial hierarchies and complex patterns will alleviate the lack of consideration of the local effects in current models, allowing for more detailed and comprehensive analyses. Therefore, future work plans to introduce CNN into this model, use CNN to extract local features of vulnerabilities, and combine global features with local features to better optimize the classification model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}