
Forecasting Significant Stock Market Price Changes Using Machine Learning: Extra Trees Classifier Leads

Abstract
:1. Introduction
2. Methodology
2.1. Training Data Processing
2.2. Technical Indicators
2.2.1. Momentum Indicators
- MACD. The Moving Average Convergence Divergence (MACD) is a technical indicator developed by Gerald Appel [16] that is used to measure the strength and direction of a trend.The formula to calculate the Moving Average Convergence Divergence (MACD) is:where: ;;.In our case, and .
- RSI. The Relative Strength Index (RSI) is a momentum oscillator that compares the magnitude of a stock’s recent gains to the magnitude of its recent losses in an attempt to determine overbought and oversold conditions of an asset.The RSI is calculated by taking the average gains of an asset over a certain number of periods, typically 14, and dividing it by the average losses over the same period. This results in a ratio, which is then converted into a number between 0 and 100. A reading above 70 is typically considered to indicate an overbought condition, while a reading below 30 is considered to indicate an oversold condition. The RSI being above 70 is termed an “overbought condition” because it signals the uptrend is exhausted and due for a reversal. While the asset may seem profitable in the short-term when RSI exceeds 70, the indicator is warning that upside momentum is unsustainable after such a sharp rise without pullbacks. The terminology “overbought” reflects the idea that the asset’s price has been bought up too heavily, making a trend reversal likely ahead despite short-term profits. The formula to calculate the Relative Strength Index (RSI) is:where:;;;is the gain of up periods;is the loss of down periods;n is the number of periods.
- TSI. The True Strength Index (TSI) is used to measure the strength of a trend in a financial market. TSI is similar to the Relative Strength Index (RSI) but it attempts to reduce the lag of the RSI by double-smoothing the data.The TSI is calculated by first taking the rate of change of a security’s closing price and then applying a double-smoothing process to the resulting value. The double-smoothing process involves calculating a simple moving average of the rate of change, and then calculating a second simple moving average of the first moving average.Traders often use the TSI to identify potential overbought and oversold conditions in the market, by looking for bullish or bearish divergences between the TSI and the price action of the financial instrument. Bullish divergences occur when the TSI is making higher lows while the price is making lower lows, indicating that the price is likely to rise. Bearish divergences occur when the TSI is making lower highs while the price is making higher highs, indicating that the price is likely to fall. The TSI is calculated by taking the difference between the current closing price and the exponential moving average of the closing price, divided by the exponential moving average of the closing price, multiplied by 100. This results in an indicator that oscillates around the zero line, with values above zero indicating bullish momentum and values below zero indicating bearish momentum. The formula to calculate the TSI is:where: is the True Strength Index value for period i; is the closing price for period i; is the exponential moving average of the closing price for period i; n is the number of periods.
- SLOPE TSI. The slope of the True Strength Index value is computed as numerical derivative of the True Strength Index. The slope of TSI is useful to identify the trend of the TSI, if it is increasing or decreasing.
- RVGI. The Relative Vigor Index (RVGI) is used to measure the strength of a financial instrument’s price action. The RVGI is calculated by first taking the difference between the current closing price and the previous closing price, and then calculating a moving average of these differences. The resulting value is then divided by the sum of the absolute differences between the current and previous closing prices, multiplied by 100.The formula to calculate the Relative Vigor Index (RVGI) is:where: is the Up period close; is the Down period close; i is the current period; is the previous period.The RVGI indicator is a volatility-adjusted momentum oscillator that oscillates between −1 and 1, with values above 0 indicating bullish momentum and values below 0 indicating bearish momentum.
- STC. The Schaff Trend Cycle (STC) is a combination of three different indicators: the cyclical component of the moving average (MACD), the rate of change (ROC), and a double-smoothed stochastic oscillator.The STC indicator uses the cyclical component of the MACD to identify the underlying trend in the market and the ROC and double-smoothed stochastic oscillator to identify short-term price movements. The indicator generates a signal when the short-term price movements diverge from the underlying trend, which can indicate a potential trend change.
- SLOPE STC. This feature is the slope of the exponential weighted moving average of the STC value.
- Williams %R. The Williams %R [18], also known as the Williams Overbought/Oversold Index, is a momentum oscillator that measures overbought and oversold levels in the stock market. The formula for the Williams %R is given by:where is the highest high for the period being analyzed, is the closing price, and is the lowest low for the period being analyzed. The Williams %R oscillates between 0 and −100, with values close to −100 indicating oversold conditions and values close to 0 indicating overbought conditions. In the following, Williams %R will be referred as WILLR.
- CFO. The Chande Forecast Oscillator (CFO) is a momentum oscillator that measures the strength of price trends in the financial markets. It is calculated as the difference between the sum of recent gains and the sum of recent losses divided by the sum of all price changes over a given period. The CFO oscillates between positive and negative values, with positive values indicating a bullish market and negative values indicating a bearish market.The formula for the Chande Forecast Oscillator is as follows:where: is the gain of up periods; is the loss of down periods; n is the number of periods.
2.2.2. Overlap Indicators
- SLOPE VWMA. The Volume-Weighted Moving Average (VWMA) is a technical indicator that combines the traditional moving average with volume data to give more emphasis to periods of high trading activity. It is similar to a simple moving average but instead of equal weight to all prices, it gives more weight to periods with higher trading volumes.The VWMA is calculated by taking the sum of the product of the closing price and the volume for each period, divided by the sum of the volume over the same period. This results in an average price that is more representative of the prices that were actually traded during the period.The formula to calculate the Volume Weighted Moving Average (VWMA) is:where: is the closing price for period i; is the trading volume for period i; n is the number of periods.Our feature is the gradient of the VWMA.
- FWMA. The Fractal Weighted Moving Average (FWMA) is a variation of the simple moving average but it gives more weight to fractal patterns in the data. The FWMA is calculated by taking the sum of the product of the closing price and the weight of each fractal for each period, divided by the sum of the weights over the same period.The formula to calculate the Fractal Weighted Moving Average (FWMA) is:where: is the closing price for period i; is the weight of fractal for period i; n is the number of periods.
2.2.3. Trend Indicators
- ADX. The Average Directional Index (ADX) was calculated using a combination of three other indicators: the Plus Directional Indicator (+DI), the Minus Directional Indicator (−DI), and the Average True Range (ATR).The +DI and −DI indicators are used to measure the strength of bullish and bearish movements, respectively, while the ATR is used to measure volatility.They are calculated as follows: First, you need to calculate the True Range (TR) for each period. The True Range is the greatest of the following three values:The Plus Directional Movement measures the upward movement in price. It is calculated as follows:where:ch = current high;ph = previous high;cl = current low;pl = previous low.The Minus Directional Movement measures the downward movement in price. It is calculated as follows:The Average True Range (ATR) measures market volatility and is calculated as an average of the TR values over a specified period.Now we can calculate the Plus Directional Indicator (+DI) and Minus Directional Indicator (−DI) as follows:Here, EMA stands for Exponential Moving Average, and the “14-period” indicates that you typically use a 14-period EMA for these calculations. You calculate EMA by giving more weight to recent data points, which helps to smooth out the values and make the indicators more responsive to recent price movements.The ADX is then calculated by taking the absolute difference between the +DI and −DI and dividing it by the sum of the +DI and -DI, multiplied by the ATR.The formula to calculate the Average Directional Index (ADX) is:where: +DI is the Plus Directional Indicator; −DI is the Minus Directional Indicator; ATR is the Average True Range.The ADX is a measure of the overall trend strength, combining the strength of both bullish and bearish movements while taking market volatility into account using the ATR. It helps traders and analysts identify the strength of a trend and whether it is worth trading.
- AROON. The Aroon is used to measure the strength of a trend and the likelihood of its continuation, and consists of two lines, the Aroon Up line and the Aroon Down line. The Aroon Up line measures the strength of the uptrend, while the Aroon Down line measures the strength of the downtrend.The Aroon Up line is calculated by taking the number of periods since the highest high divided by the total number of periods. The Aroon Down line is calculated by taking the number of periods since the lowest low divided by the total number of periods.Values for Aroon Up and Aroon Down oscillate between 0 and 100, with readings near 100 indicating a strong trend in the direction of the oscillator and readings near 0 indicating a weak trend or no trend at all.Aroon Up and Aroon Down indicators can be used in combination to identify potential trend changes. An increasing Aroon Up and a decreasing Aroon Down indicate a strong uptrend, while a decreasing Aroon Up and an increasing Aroon Down suggest a strong downtrend. A weak trend or no trend at all is indicated when both Aroon Up and Aroon Down decrease.Additionally, a buy signal is generated when Aroon Up crosses Aroon Down from below, and a sell signal is generated when Aroon Down crosses Aroon Up from above.The formula for calculating the Aroon Up line is:where:N is the number of periods;= N − Days Since N − Period Highand Days Since N − Period High is the number of periods that have passed since the highest high within the last N periods. It is calculated by counting the number of periods between the current period and the period when the highest high occurred. In this case, N is set to 14.The formula for calculating the Aroon Down line is:where:N is the number of periods;= N − Days Since N − Period Lowand Days Since N -Period Low is the number of periods since the lowest low. Our feature is computed as:
2.2.4. Volatility Indicators
- Bollinger Bands. Bollinger Bands are used to measure the volatility of a financial instrument. The indicator consists of three lines: the simple moving average line, which is the middle band; and an upper and lower band. The upper band is plotted two standard deviations above the simple moving average, while the lower band is plotted two standard deviations below the simple moving average.Bollinger Bands are often used to identify potential overbought and oversold conditions in the market. When the price of a financial instrument moves above the upper band, it is considered overbought, and when it moves below the lower band, it is considered oversold. Traders can also use Bollinger Bands to identify potential breakouts by looking for price action to break above or below the upper or lower bands.Traders also use Bollinger Bands as a volatility indicator, by using the width between the upper and lower bands. The wider the bands, the higher the volatility, and the narrower the bands, the lower the volatility.The formula to calculate the three Bollinger Bands are:Middle Band =Upper Band =Lower Band =where: is the Simple Moving Average with period n; is the standard deviation of x with period n; n is the number of periods for the moving average. In our case ; k is the number of standard deviations from the moving average to plot the upper and lower bands. In our case .In the following, medium, upper, and lower Bollinger bands will be referred to as BOLL M, BOLL U, and BOLL L.
- RVI. The Relative Volatility Index (RVI) is used to measure the volatility of an asset relative to its own recent price history. The RVI formula is defined as follows:where EMA is the Exponential Moving Average, is the closing price at time t, and is the closing price at time . The RVI ranges from 0 to 100 and is typically used to identify overbought and oversold conditions in the market.
- Price from Donchian. The Donchian channel is a moving average of the highest high and the lowest low prices over a certain period of time and is typically plotted on a chart as three lines: the upper line represents the highest high price over the specified time period, the middle line represents the average of the highest high over the specified time period, and the lower line represents the lowest low price over the specified time period.The price of the asset oscillates between these two bands, and when the price breaks above the upper band, it is considered to be in an uptrend, and when it breaks below the lower band, it is considered to be in a downtrend.The two bands are calculated as follows:Upper band =Lower band =where: is the highest price for period i; is the lowest price for period i; n is the number of periods. In our case: .Our feature is the distance of the closing price from the mean of the Donchian channel and is computed as follow:where: is the closing price at time t; is the upper band at time t; is the lower band at time t; is the mean of x and y.In the following, this feature will be referred as PF DONCHIAN.
- Slope of Price from Donchian. This feature is the slope of the previous indicator. In the following, this feature will be referred to as SLOPE PFD.
2.2.5. Volume Indicators
- A/D. Accumulation/Distribution (A/D) measures the buying and selling pressure of a financial instrument. The A/D indicator is calculated by taking the difference between the current close and the previous close, multiplied by the volume. If the current close is above the previous close, the value is positive, indicating that money is flowing into the stock.The formula to calculate the Accumulation/Distribution is:where: is the Accumulation/Distribution value for period i; is the closing price for period i; is the closing price for period ; is the trading volume for period i.This formula calculates the A/D by taking the difference between the current close and the previous close, multiplied by the volume, and adding the result to the previous A/D value. If the current close is above the previous close, the value is positive, indicating that money is flowing into the stock, and therefore it is considered a buying pressure. If the current close is below the previous close, the value is negative, indicating that money is flowing out of the stock, and therefore it is considered a selling pressure.
- SLOPE AD. This feature is the slope of the previous indicator.
- CMF. The Chaikin Money Flow (CMF) is based on the Accumulation/Distribution line and is calculated by taking the difference between the high and low prices for each period, multiplied by the volume, and dividing the sum of these values by the sum of the volume over the same period. This results in an indicator that oscillates around the zero line, with values above zero indicating buying pressure and values below zero indicating selling pressure.The formula to calculate the Chaikin Money Flow (CMF) is:where: is the closing price for period i; is the lowest price for period i; is the highest price for period i; is the trading volume for period i; n is the number of periods. This formula calculates the CMF by taking the difference between the high and low prices for each period, multiplied by the volume, and dividing the sum of these values by the sum of the volume over the same period.
2.2.6. More Indicators
- SLOPE A50. The feature SLOPE A50 is computed applying the Exponentially Weighted Moving Average to the closing prices using a window of 50 days, and calculating the gradient.
- SLOPE A23. Same as the previous feature, with a window of 23 days.
2.3. Exponential Smoothing
- Simple exponential smoothing: This method uses a single smoothing factor to give more weight to recent observations and less weight to older observations.
- Holt’s linear exponential smoothing: This method adds a trend component to simple exponential smoothing, allowing for the prediction of both level and trend in the data.
- Holt–Winters exponential smoothing: This method adds a seasonal component to Holt’s linear exponential smoothing, allowing for the prediction of level, trend, and seasonality in the data.
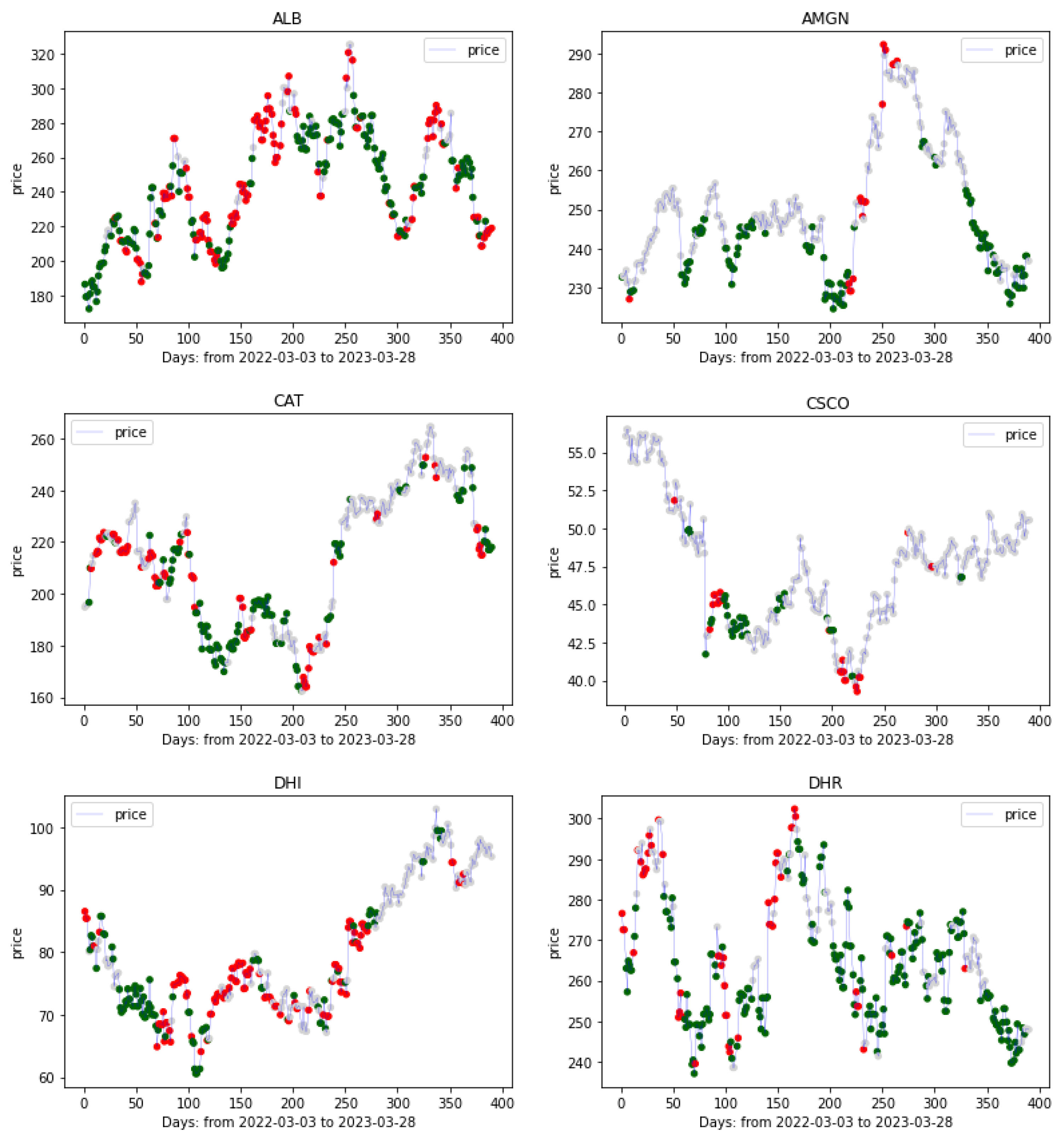
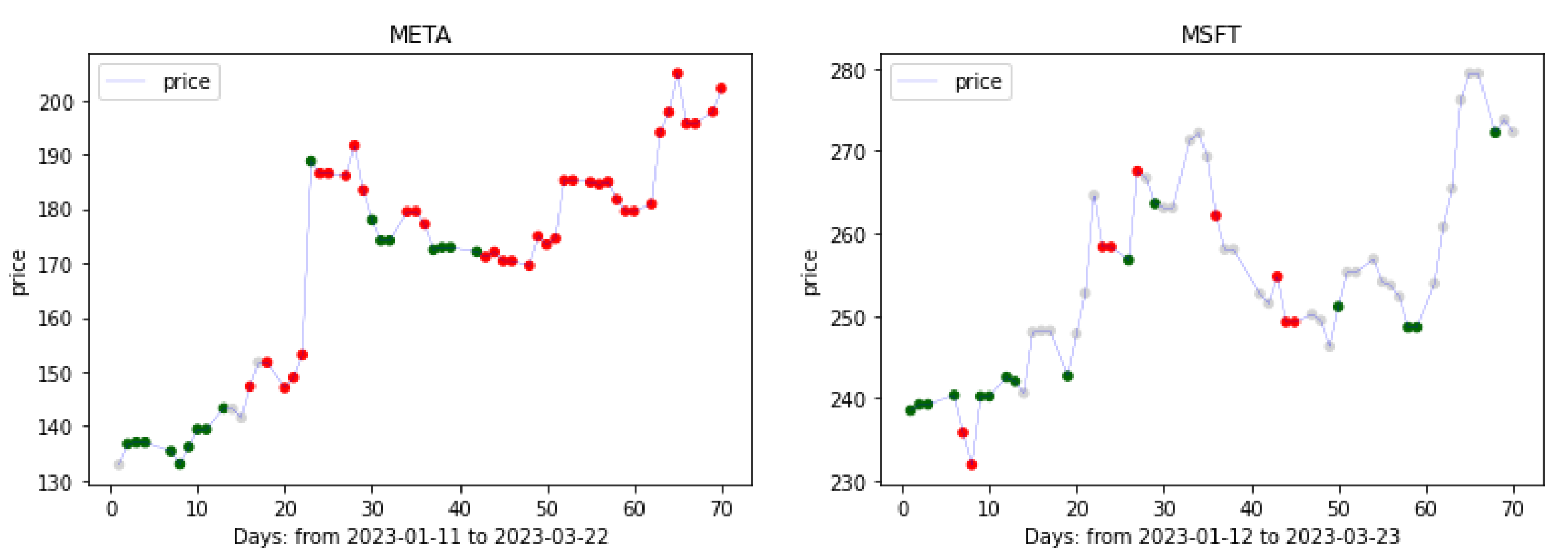
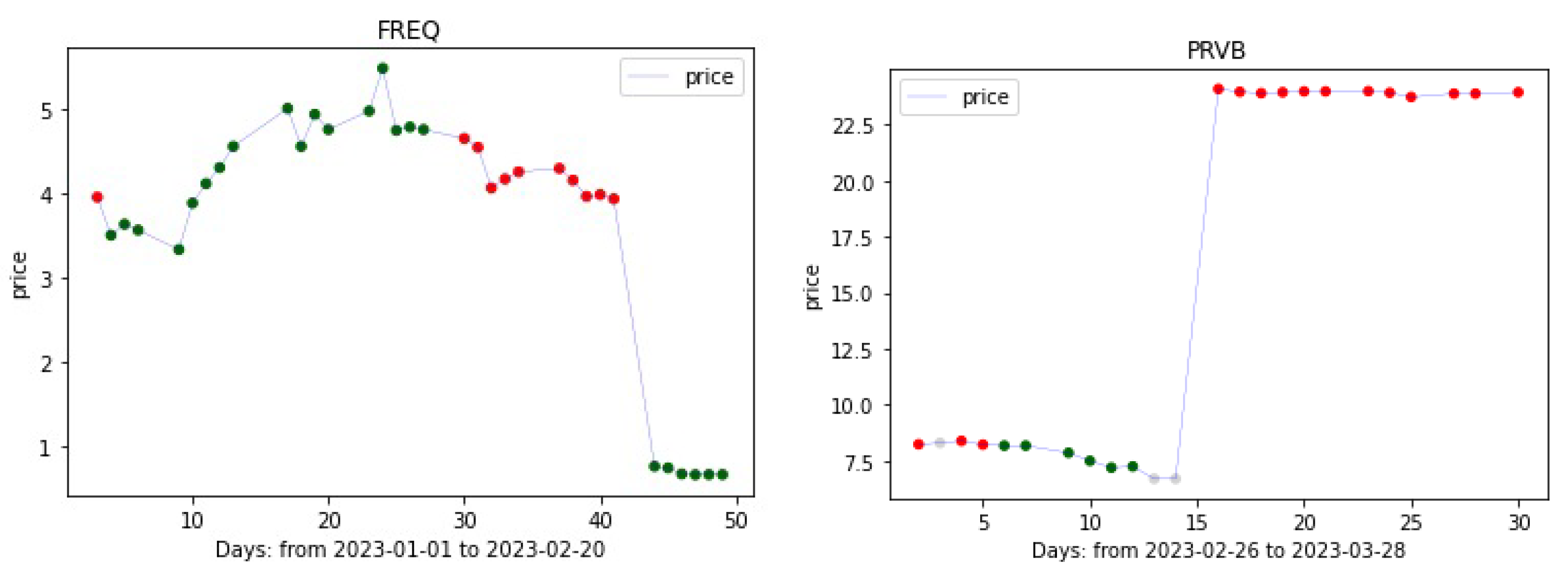
3. Data Set
4. Strategy
- The first bin includes all values less than , which corresponds to a loss in closing price after 10 trading days of more than 3%. In this bin, the resulting strategy would be to sell.
- The second bin includes all values between and 0.04, which corresponds to a price change within the range of −3% to +4%. In this bin, the resulting strategy would be to hold.
- The third bin includes all values greater than 0.04, which corresponds to a gain in closing price after 10 trading days of more than +4%. In this bin, the resulting strategy would be to buy.
5. Prediction Models
5.1. Random Forest
5.2. Extra Trees
5.3. A Comparison of Models
- Bagging Classifier (Bootstrapped Aggregating) is an ensemble machine learning technique that combines the predictions of multiple models to improve the stability and accuracy of the prediction. The method involves training multiple models on randomly sampled subsets of the training data, and then averaging the predictions of each model.
- Decision Tree Classifier is a supervised learning algorithm used for classification problems. It models decisions and decision making by learning from the data to construct a tree-like model of decisions and their possible consequences. The algorithm works by recursively splitting the data into subsets based on the feature that results in the largest information gain and assigning a class label to each leaf node in the tree. The final class label of a sample is determined by traversing the tree from the root to a leaf node. Decision trees are simple to understand, interpret, and visualize and can handle both categorical and numerical data.
- NuSVC is a Support Vector Machine (SVM) classifier which uses a nu-parameter to control the number of support vectors. It works by finding the optimal hyperplane that separates the data points of different classes with the maximum margin. The nu-parameter controls the trade-off between margin size and number of support vectors. NuSVC is useful when dealing with large datasets as it uses a subset of training points, known as support vectors, in the decision function.
- XGB Classifier is an implementation of gradient boosting algorithm for classification problems. It builds a sequence of decision trees to make the final prediction. The algorithm works by iteratively adding new trees to the model, with each tree trained to correct the errors of the previous ones. The XGB Classifier also includes regularization techniques, such as L1 and L2 regularization, to prevent overfitting.
- KNeighbors Classifier is a type of instance-based learning algorithm, which uses a non-parametric method to classify new data points based on the similarity of their features to those of the training data. It works by assigning a class label to a new data point based on the class labels of its k-nearest neighbors in the training set. The value of k is chosen by the user and determines the number of neighbors to consider when making a prediction. KNeighbors Classifier is simple to implement and works well for small datasets with few dimensions.
- LGBM Classifier is a gradient boosting framework that uses tree-based learning algorithms. It stands for Light Gradient Boosting Machine, and it is a scalable and efficient implementation of gradient boosting specifically designed to handle large datasets.
- Quadratic Discriminant Analysis (QDA) is a linear classification method that assumes a Gaussian distribution of the features within each class and estimates the class covariance matrices. QDA uses these covariance matrices to calculate the discriminant function that separates the classes. Unlike Linear Discriminant Analysis (LDA), QDA does not assume equal covariance between the classes and therefore provides a more flexible boundary between the classes. It is effective in cases where the class covariance matrices are different and the classes are well-separated.
5.4. Random Forest vs. Extra Trees
5.5. Feature Importances
5.6. Another Features Importance Estimation
5.7. Selected Features
5.8. Hyperparameter Tuning
- n estimators number of decision trees in the Random Forest;
- max features maximum number of features that are considered at each split in the decision tree;
- max depth maximum depth of the decision trees in the Random Forest;
- min samples split minimum number of samples required to split an internal node in the decision tree;
- minimum samples leaf minimum number of samples required to be at a leaf node in the decision tree;
- bootstrap: Bootstrapping in Machine Learning involves creating multiple subsets of training data by randomly sampling with replacement from the original dataset. This technique is used to train multiple decision trees, each on a different subset of the training data. The “bootstrap” hyperparameter is a Boolean value that determines whether bootstrapping is applied during tree construction. When set to “True”, bootstrapping is used to create diverse training subsets for each decision tree, aiding in reducing overfitting and enhancing generalization. Conversely, when set to “False”, each decision tree is trained on the entire dataset.
- n estimators ;
- max features = auto; the algorithm automatically chooses the appropriate number of features to consider, based on a square root of the total number of features available in the dataset;
- max depth ;
- min samples split ;
- min samples leaf ;
- bootstrap = False.
6. Results
6.1. Evaluation Metrics
6.2. Experimental Results
6.3. Trading Recommendations
7. Discussion
8. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. List of Stocks Used for Training the Model
References
- Malkiel, B.G.; Fama, E.F. Efficient capital markets: A review of theory and empirical work. J. Financ. 1970, 25, 383–417. [Google Scholar] [CrossRef]
- Jensen, M.C. Some anomalous evidence regarding market efficiency. J. Financ. Econ. 1978, 6, 95–101. [Google Scholar] [CrossRef]
- Avery, C.N.; Chevalier, J.A.; Zeckhauser, R.J. The CAPS prediction system and stock market returns. Rev. Financ. 2016, 20, 1363–1381. [Google Scholar] [CrossRef]
- Christoffersen, P.F.; Diebold, F.X. Financial asset returns, direction-of-change forecasting, and volatility dynamics. Manag. Sci. 2006, 52, 1273–1287. [Google Scholar] [CrossRef]
- Hellstrom, T.; Holmstromm, K. Predictable Patterns in Stock Returns; Technical Report Series IMa-TOM, 1997-09; 1998. Available online: https://api.semanticscholar.org/CorpusID:150923793 (accessed on 3 November 2023).
- Saha, S.; Routh, S.; Goswami, B. Modeling Vanilla Option prices: A simulation study by an implicit method. J. Adv. Math. 2014, 6, 834–848. [Google Scholar]
- Widom, J. Research problems in data warehousing. In Proceedings of the Fourth International Conference on Information and Knowledge Management, CIKM ’95, Baltimore, MD, USA, 29 November–2 December 1995; ACM: New York, NY, USA, 1995; pp. 25–30. [Google Scholar]
- Kumbure, M.M.; Lohrmann, C.; Luukka, P.; Porras, J. Machine learning techniques and data for stock market forecasting: A literature review. Expert Syst. Appl. 2022, 197, 116659. [Google Scholar] [CrossRef]
- Kara, Y.; Boyacioglu, M.A.; Baykan, C. Predicting direction of stock price index movement using artificial neural networks and support vector machines: The sample of the Istanbul stock exchange. Expert Syst. Appl. 2011, 38, 5311–5319. [Google Scholar] [CrossRef]
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C. Comparison of ARIMA and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 2014, 614342. [Google Scholar] [CrossRef]
- de Faria, E.L.; Albuquerque, M.P.; Gonzalez, J.L.; Cavalcante, J. Predicting the Brazilian stock market through neural networks and adaptive exponential smoothing methods. Expert Syst. Appl. 2009, 36, 12506–12509. [Google Scholar] [CrossRef]
- Basak, S.; Kar, S.; Saha, S.; Khaidem, L.; Dey, S.R. Predicting the direction of stock market prices using tree-based classifiers. N. Am. J. Econ. Financ. 2019, 47, 552–567. [Google Scholar] [CrossRef]
- Bruno, A.; Pagliaro, A.; La Parola, V. Application of Machine and Deep Learning Methods to the Analysis of IACTs Data. In Intelligent Astrophysics; Zelinka, I., Brescia, M., Baron, D., Eds.; Emergence, Complexity and Computation, Volume 39; Springer: Berlin/Heidelberg, Germany, 2021; pp. 115–136. [Google Scholar]
- Pagliaro, A.; Cusumano, G.; La Barbera, A.; La Parola, V.; Lombardi, S. Application of Machine Learning Ensemble Methods to ASTRI Mini-Array Cherenkov Event Reconstruction. Appl. Sci. 2023, 13, 8172. [Google Scholar] [CrossRef]
- Twopirllc. Pandas-TA: Technical Analysis Indicators for Pandas. Available online: https://twopirllc.github.io/pandas-ta/ (accessed on 3 November 2023).
- Appel, G. The MACD Momentum Indicator. Tech. Anal. Stock. Commod. 1985, 3, 84–88. [Google Scholar]
- ProRealCode. Schaff Trend Cycle (STC). Available online: https://www.prorealcode.com/prorealtime-indicators/schaff-trend-cycle2/ (accessed on 3 November 2023).
- Williams, L. How I Made One Million Dollars Last Year Trading Commodities; FutureBooks: Singapore, 1973. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy |
|---|---|
| Extra Trees Classifier | 0.75 |
| Random Forest Classifier | 0.73 |
| Bagging Classifier | 0.67 |
| Decision Tree Classifier | 0.63 |
| NuSVC | 0.57 |
| XGB Classifier | 0.55 |
| KNeighbors Classifier | 0.54 |
| LGBM Classifier | 0.52 |
| Quadratic Discriminant Analysis | 0.44 |
| Features | Importance |
|---|---|
| PF DONCHIAN | 0.0523 |
| BOLL L | 0.0489 |
| BOLL M | 0.0464 |
| A/D | 0.0459 |
| FWMA | 0.0457 |
| BOLL U | 0.0454 |
| ADX | 0.0451 |
| MACD | 0.0434 |
| CFO | 0.0415 |
| SLOPE A50 | 0.0413 |
| RVGI | 0.0409 |
| CMF | 0.0400 |
| TSI | 0.0397 |
| AROON | 0.0397 |
| SLOPE A23 | 0.0388 |
| SLOPE PFD | 0.0383 |
| STC | 0.0379 |
| RVI | 0.0369 |
| RSI | 0.0364 |
| SLOPE VWMA | 0.0364 |
| WILLR | 0.0363 |
| SLOPE STC | 0.0349 |
| SLOPE TSI | 0.0342 |
| SLOPE AD | 0.0327 |
| RANDOM | 0.0028 |
| Number of Features | Occurrences |
|---|---|
| 15 | 30 |
| 16 | 11 |
| 23 | 9 |
| 20 | 8 |
| 17 | 7 |
| Results | |
|---|---|
| Training score | 0.9989 |
| Testing score | 0.8608 |
| Accuracy (test data set) | 0.8608 |
| Precision (test data set) | 0.8614 |
| Recall (test data set) | 0.8608 |
| Balanced Accuracy (test data set) | 0.8608 |
| F1 score (test data set) | 0.8610 |
| Specificity (test data set) | 0.8403 |
| Features Importances | |
|---|---|
| BOLL L | 0.0748 |
| BOLL M | 0.0718 |
| ADX | 0.0717 |
| BOLL U | 0.0716 |
| FWMA | 0.0712 |
| TSI | 0.0710 |
| MACD | 0.0708 |
| PF DONCHIAN | 0.0682 |
| A/D | 0.0668 |
| SLOPE50 | 0.0651 |
| CFO | 0.0624 |
| SLOPE23 | 0.0624 |
| SLOPE STC | 0.0611 |
| SLOPE PFD | 0.0574 |
| SLOPE AD | 0.0536 |
| Stock | Invested | Asset Trading | Asset Hold | Trading Strategy Return | Hold Return | % Difference |
|---|---|---|---|---|---|---|
| ALB | $10,000 | $10,846.27 | $10,692.00 | +8.46% | +6.92% | +1.54% |
| CAT | $10,000 | $10,681.18 | $10,471.57 | +6.81% | +4.72% | +2.09% |
| CSCO | $10,000 | $9102.07 | $8319.10 | -8.98% | −16.81% | +7.83% |
| DHI | $10,000 | $10,244.50 | $9661.74 | +2.45% | −3.38% | +5.83% |
| DHR | $10,000 | $11,303.50 | $8695.91 | +13.04% | −13.04% | +26.08% |
| DPZ | $10,000 | $10,399.20 | $7508.25 | +3.99% | −24.92% | +28.91% |
| ENPH | $10,000 | $14,904.29 | $14,835.93 | +49.04% | +48.36% | +0.68% |
| IDXX | $10,000 | $9806.33 | $9228.05 | −1.94% | −7.72% | +5.02% |
| LRCX | $10,000 | $12,559.28 | $7043.93 | +25.59% | −29.56% | +55.15% |
| MCD | $10,000 | $10,959.96 | $10,470.60 | +9.60% | +4.71% | +4.89% |
| MU | $10,000 | $8490.96 | $6202.22 | −15.09% | −37.98% | +22.89% |
| PG | $10,000 | $11,616.68 | $8926.82 | +16.17% | −10.73% | +26.90% |
| TGT | $10,000 | $10,158.78 | $7555.11 | +1.59% | −24.45% | +26.04% |
| TWTR 1 | $10,000 | $16,841.23 | $14,396.78 | +68.41% | +43.97% | +24.44% |
| XOM | $10,000 | $15,445.01 | $15,212.10 | +54.45% | +52.12% | +2.15% |
| Total | $150,000 | $178,638.89 | $157,116.46 | +19.09% | +4.74% | +14.35% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pagliaro, A. Forecasting Significant Stock Market Price Changes Using Machine Learning: Extra Trees Classifier Leads. Electronics 2023, 12, 4551. https://doi.org/10.3390/electronics12214551
Pagliaro A. Forecasting Significant Stock Market Price Changes Using Machine Learning: Extra Trees Classifier Leads. Electronics. 2023; 12(21):4551. https://doi.org/10.3390/electronics12214551
Chicago/Turabian StylePagliaro, Antonio. 2023. "Forecasting Significant Stock Market Price Changes Using Machine Learning: Extra Trees Classifier Leads" Electronics 12, no. 21: 4551. https://doi.org/10.3390/electronics12214551