
Transformer-Based Integrated Framework for Joint Reconstruction and Segmentation in Accelerated Knee MRI


Abstract
:1. Introduction
- Segmentation-Integrated Unrolled Reconstruction: we proposes a unique cost function for unrolling the reconstruction algorithm that integrates segmentation results into the reconstruction process.
- Enhanced Encoder–Decoder Architecture: this paper employs a Swin Transformer [18,19]-based encoder–decoder architecture for multitask denoising and segmentation. A shared attention mechanism is implemented wherein Query and Key vectors in the self-attention module of the task-specific decoder are computed using the shared encoder’s output.
- Feature Distillation in Multitask Decoders: the proposed model introduces integration of features between decoders through a distillation process by applying spatial attention features from each task that are then incorporated into the other task’s decoder.
2. Materials and Methods
2.1. Background
2.1.1. Compressed Sensing in MRI
2.1.2. Transformers in Medical Imaging
2.1.3. Multi-Task Learning for Dense Predictions
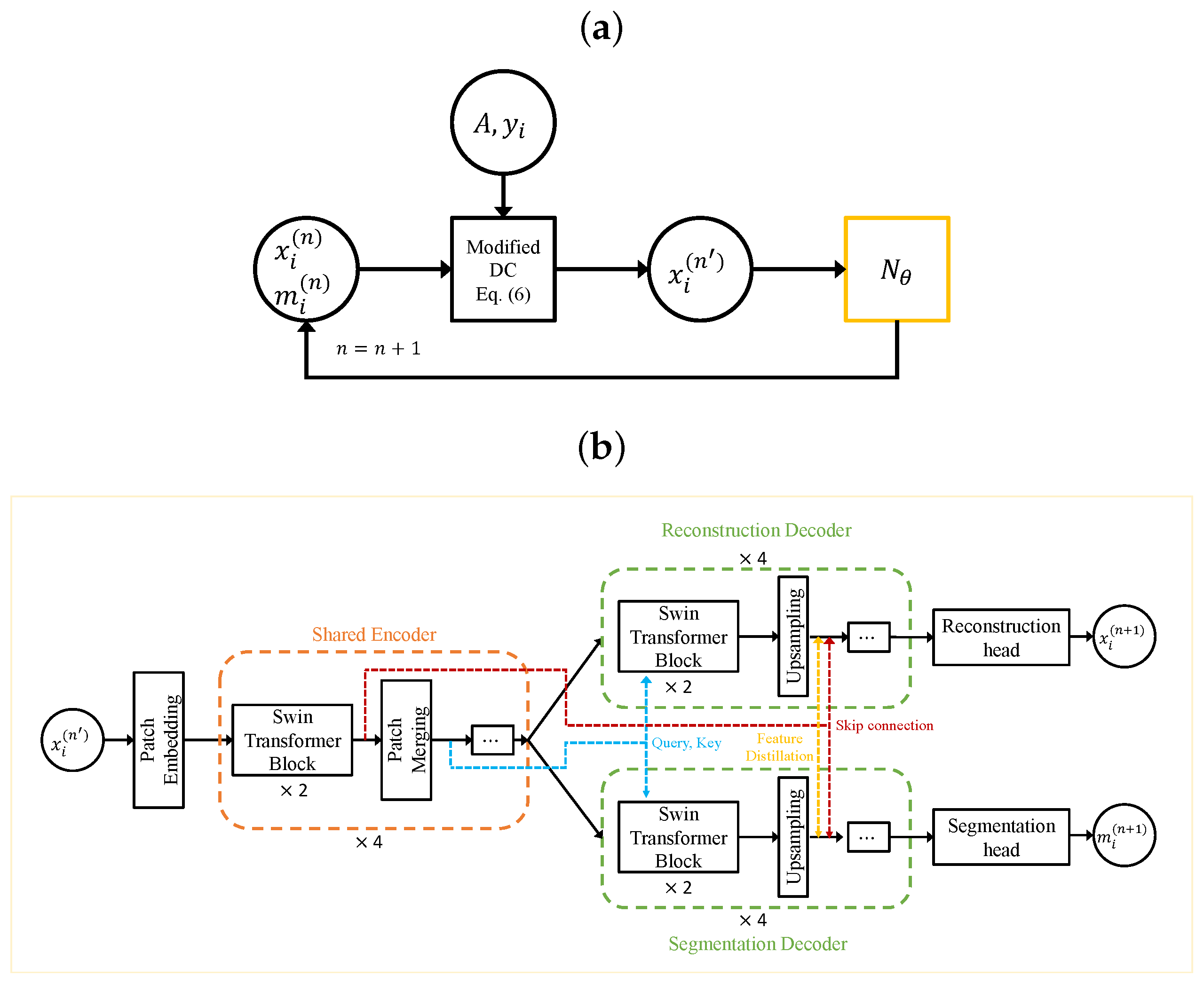
2.2. Proposed Method
2.2.1. Incorporating Segmentation Feedback into the Reconstruction Cost Function
2.2.2. Swin Transformer-Based Encoder–Decoder Approach
2.2.3. Feature Sharing and Distillation across Multitask Decoders
3. Results
3.1. Dataset Details
3.1.1. SKM-TEA Dataset
3.1.2. Data Preprocessing
3.2. Baseline and Comparative Methods
3.3. Details on Implementation and Training
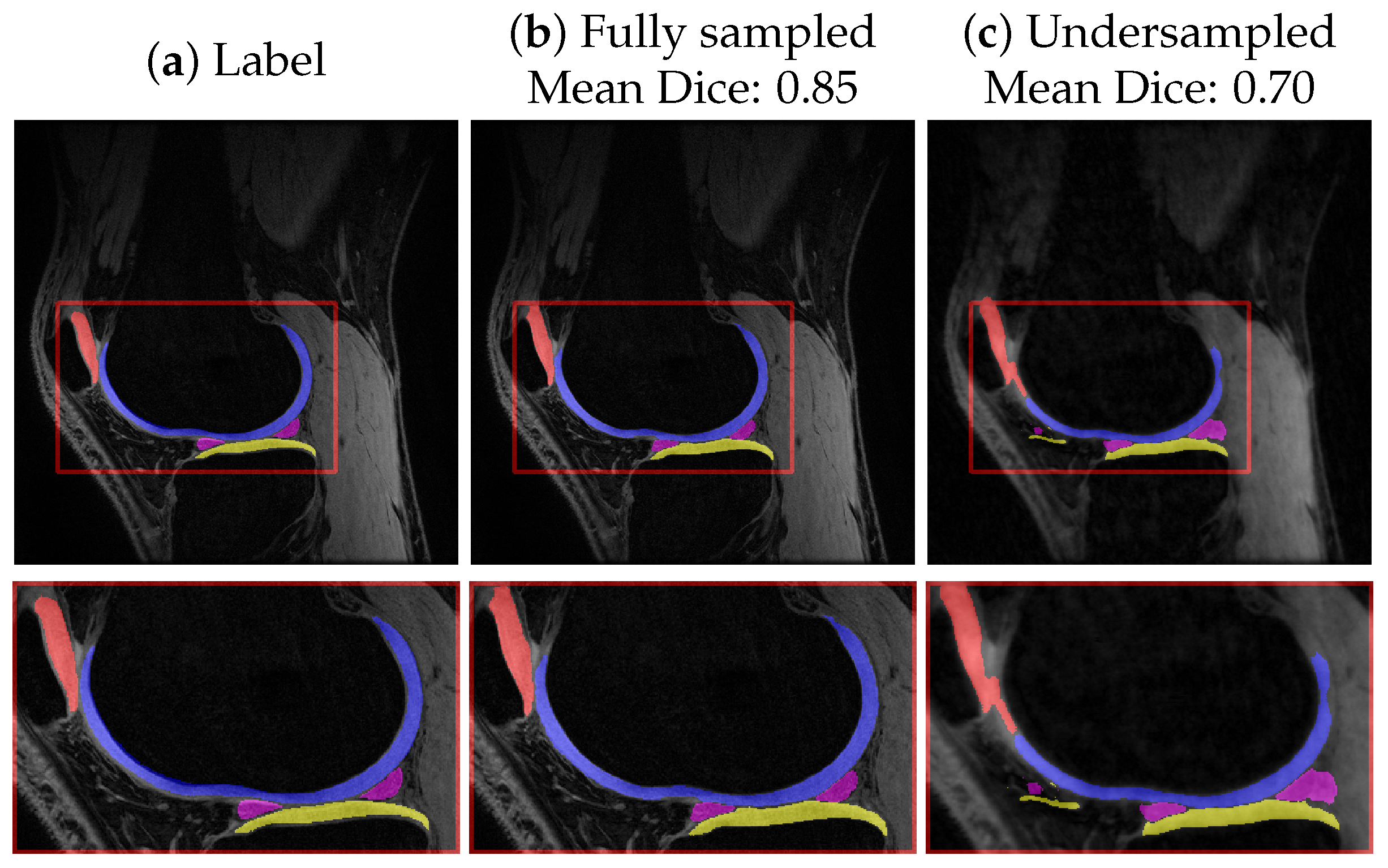
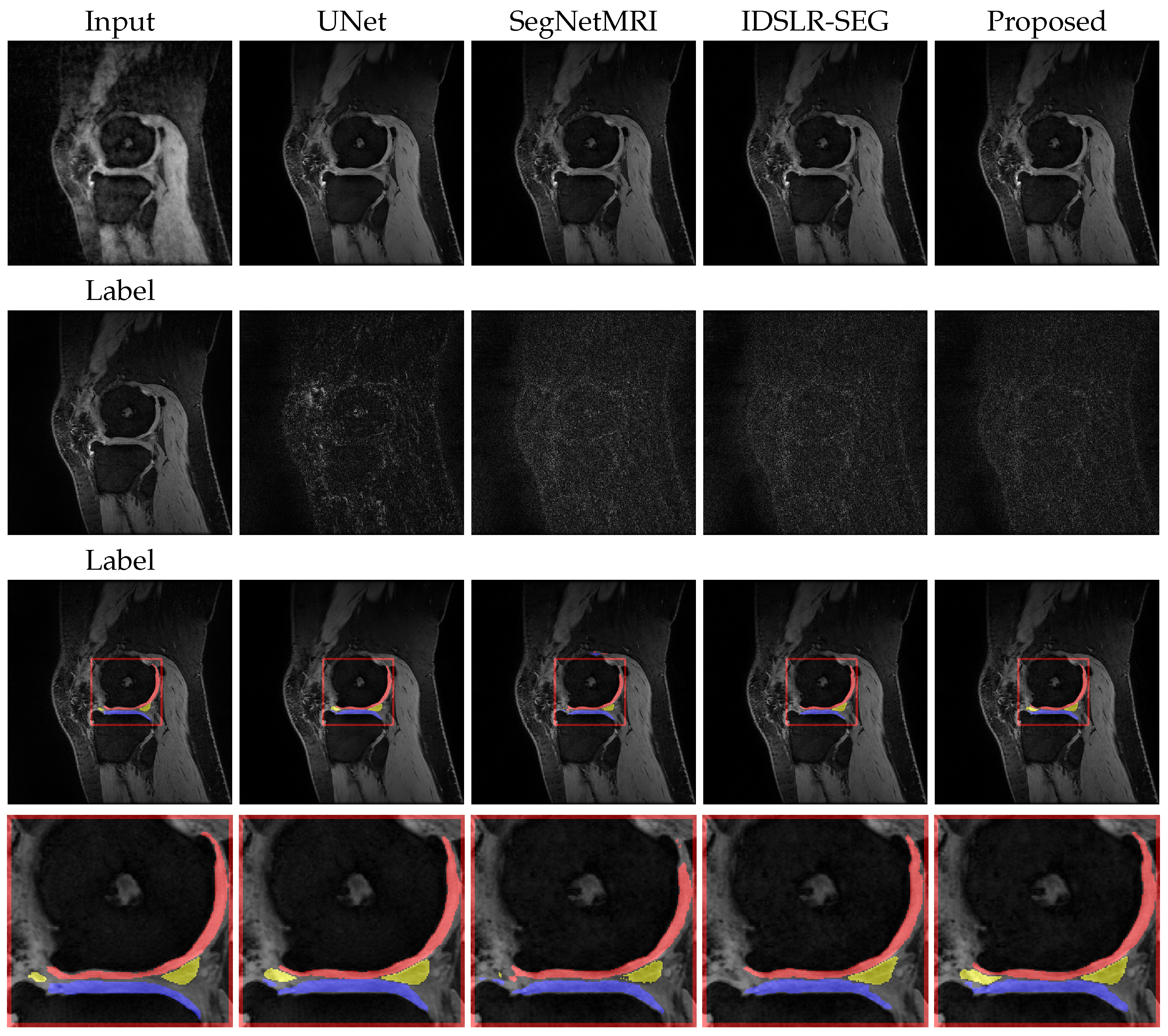
3.4. Results: Quantitative and Qualitative Evaluation
4. Discussion
4.1. Discussion of Reconstruction Results
4.2. Discussion of Segmentation Results
4.3. Ablation Study
4.4. Limitations
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
- The following abbreviations are used in this manuscript:
| MRI | Magnetic Resonance Imaging |
| SKM-TEA | Stanford Knee MRI with Multi-Task Evaluation |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index |
| ML | Machine Learning |
| ROI | Region of Interest |
| FISTA | Fast Iterative Shrinkage–Thresholding Algorithm |
| PMRI | Parallel MRI |
| CLEAR | Calibration-free Locally low-rank EncourAging Reconstruction |
| Swin | Shifted Windows |
| ViT | Vision Transformer |
| BraTS | Brain Tumor Segmentation |
| MTL | Multi-Task Learning |
| CNN | Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
| qMRI | Quantitative MRI |
| DICOM | Digital Imaging and Communications in Medicine |
| SENSE | Sensitivity Encoding |
| JSENSE | Joint Image Reconstruction and Sensitivity Estimation in SENSE |
| qDESS | Double-Echo Steady-State |
| GPU | Graphics Processing Unit |
| 2D | Two-Dimensional |
| 3D | Three-Dimensional |
| DSNA | Denoising and Segmentation Network Architecture |
| SEDSN | Shared Encoder between Denoising and Segmentation Networks |
| SDI | Shared Denoiser across Iterations |
| MSPI | Multiple Segmentation Predictions across Iterations |
| FD | Feature Distillation |
| SF | Segmentation Feedback |
References
- van Beek, E.J.; Kuhl, C.; Anzai, Y.; Desmond, P.; Ehman, R.L.; Gong, Q.; Gold, G.; Gulani, V.; Hall-Craggs, M.; Leiner, T.; et al. Value of MRI in medicine: More than just another test? J. Magn. Reson. Imaging 2019, 49, e14–e25. [Google Scholar] [CrossRef] [PubMed]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Lustig, M.; Donoho, D.; Pauly, J.M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2007, 58, 1182–1195. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression shrinkage and selection via the LASSO. J. R. Stat. Soc. Ser. Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef] [PubMed]
- Desai, A.D.; Schmidt, A.M.; Rubin, E.B.; Sandino, C.M.; Black, M.S.; Mazzoli, V.; Stevens, K.J.; Boutin, R.; Ré, C.; Gold, G.E.; et al. SKM-TEA: A dataset for accelerated MRI reconstruction with dense image labels for quantitative clinical evaluation. arXiv 2022, arXiv:2203.06823. [Google Scholar]
- Pal, A.; Rathi, Y. A review and experimental evaluation of deep learning methods for MRI reconstruction. J. Mach. Learn. Biomed. Imaging 2022, 1, 001. [Google Scholar] [CrossRef]
- Caballero, J.; Bai, W.; Price, A.N.; Rueckert, D.; Hajnal, J.V. Application-driven MRI: Joint reconstruction and segmentation from undersampled MRI data. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2014: 17th International Conference, Boston, MA, USA, 14–18 September 2014; Proceedings, Part I 17. Springer: Berlin/Heidelberg, Germany, 2014; pp. 106–113. [Google Scholar]
- Bien, N.; Rajpurkar, P.; Ball, R.L.; Irvin, J.; Park, A.; Jones, E.; Bereket, M.; Patel, B.N.; Yeom, K.W.; Shpanskaya, K.; et al. Deep-learning-assisted diagnosis for knee magnetic resonance imaging: Development and retrospective validation of MRNet. PLoS Med. 2018, 15, e1002699. [Google Scholar] [CrossRef]
- Liu, Z.; Tong, L.; Chen, L.; Jiang, Z.; Zhou, F.; Zhang, Q.; Zhang, X.; Jin, Y.; Zhou, H. Deep learning based brain tumor segmentation: A survey. Complex Intell. Syst. 2023, 9, 1001–1026. [Google Scholar] [CrossRef]
- Sun, L.; Fan, Z.; Ding, X.; Huang, Y.; Paisley, J. Joint CS-MRI reconstruction and segmentation with a unified deep network. In Proceedings of the Information Processing in Medical Imaging: 26th International Conference, IPMI 2019, Hong Kong, China, 2–7 June 2019; Proceedings 26. Springer: Berlin/Heidelberg, Germany, 2019; pp. 492–504. [Google Scholar]
- Pramanik, A.; Jacob, M. Joint calibrationless reconstruction and segmentation of parallel MRI. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 437–453. [Google Scholar]
- Huang, Q.; Yang, D.; Yi, J.; Axel, L.; Metaxas, D. FR-Net: Joint reconstruction and segmentation in compressed sensing cardiac MRI. In Proceedings of the Functional Imaging and Modeling of the Heart: 10th International Conference, FIMH 2019, Bordeaux, France, 6–8 June 2019; Proceedings 10. Springer: Berlin/Heidelberg, Germany, 2019; pp. 352–360. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Trzasko, J.D.; Manduca, A. CLEAR: Calibration-free parallel imaging using locally low-rank encouraging reconstruction. Proc. Int. Soc. Magn. Reson. Med. 2012, 517. [Google Scholar]
- Pramanik, A.; Aggarwal, H.K.; Jacob, M. Deep generalization of structured low-rank algorithms (Deep-SLR). IEEE Trans. Med. Imaging 2020, 39, 4186–4197. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 21–24 June 2022; pp. 12009–12019. [Google Scholar]
- Fessler, J.A. Optimization methods for magnetic resonance image reconstruction: Key models and optimization algorithms. IEEE Signal Process. Mag. 2020, 37, 33–40. [Google Scholar] [CrossRef] [PubMed]
- Sandino, C.M.; Cheng, J.Y.; Chen, F.; Mardani, M.; Pauly, J.M.; Vasanawala, S.S. Compressed sensing: From research to clinical practice with deep neural networks: Shortening scan times for magnetic resonance imaging. IEEE Signal Process. Mag. 2020, 37, 117–127. [Google Scholar] [CrossRef]
- Combettes, P.L.; Pesquet, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Mardani, M.; Sun, Q.; Donoho, D.; Papyan, V.; Monajemi, H.; Vasanawala, S.; Pauly, J. Neural proximal gradient descent for compressive imaging. Adv. Neural Inf. Process. Syst. 2018, 31, 9596–9606. [Google Scholar]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging 2018, 38, 394–405. [Google Scholar] [CrossRef]
- Diamond, S.; Sitzmann, V.; Heide, F.; Wetzstein, G. Unrolled optimization with deep priors. arXiv 2017, arXiv:1705.08041. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. Adv. Neural Inf. Process. Syst. 2019, 32, 68–80. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. Med. Image Anal. 2023, 88, 102802. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.M.; Yan, Y.; Chen, G.; Xu, Y.; Hu, Y.; Shao, L.; Fu, H. Multi-modal transformer for accelerated MR imaging. IEEE Trans. Med. Imaging 2022, 42, 2804–2816. [Google Scholar] [CrossRef] [PubMed]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in MRI images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 272–284. [Google Scholar]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S.; et al. The RSNA-ASNR-MICCAI BRATS 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Van Gansbeke, W.; Proesmans, M.; Dai, D.; Van Gool, L. Multi-task learning for dense prediction tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3614–3633. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Standley, T.; Zamir, A.; Chen, D.; Guibas, L.; Malik, J.; Savarese, S. Which tasks should be learned together in multi-task learning? In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 9120–9132. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Chen, Z.; Badrinarayanan, V.; Lee, C.Y.; Rabinovich, A. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 794–803. [Google Scholar]
- Lu, Y.; Kumar, A.; Zhai, S.; Cheng, Y.; Javidi, T.; Feris, R. Fully-adaptive feature sharing in multi-task networks with applications in person attribute classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5334–5343. [Google Scholar]
- Guo, P.; Lee, C.Y.; Ulbricht, D. Learning to branch for multi-task learning. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 3854–3863. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3994–4003. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-to-end multi-task learning with attention. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1871–1880. [Google Scholar]
- Vandenhende, S.; Georgoulis, S.; Van Gool, L. MTI-net: Multi-scale task interaction networks for multi-task learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 527–543. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Bhattacharjee, D.; Zhang, T.; Süsstrunk, S.; Salzmann, M. Mult: An end-to-end multitask learning transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12031–12041. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ying, L.; Sheng, J. Joint image reconstruction and sensitivity estimation in SENSE (JSENSE). Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2007, 57, 1196–1202. [Google Scholar] [CrossRef]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.P.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Desai, A.D.; Ozturkler, B.M.; Sandino, C.M.; Vasanawala, S.; Hargreaves, B.A.; Re, C.M.; Pauly, J.M.; Chaudhari, A.S. Noise2Recon: A Semi-Supervised Framework for Joint MRI Reconstruction and Denoising. arXiv 2021, arXiv:2110.00075. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Model | DSNA | SEDSN | SDI | MSPI |
|---|---|---|---|---|
| SegNetMRI | U-Net | Yes | No | Yes |
| IDSLR-Seg | U-Net | Yes | Yes | No |
| Proposed | Transformer | Yes | Yes | Yes |
| Method | Reconstruction | Segmentation | ||
|---|---|---|---|---|
| PSNR (dB) | SSIM | DICE | Hausdorff (mm) | |
| UNet | 33.153 (0.977) | 0.765 (0.027) | 0.824 (0.053) | 5.25 (3.27) |
| SegNetMRI | 35.322 (1.025) | 0.834 (0.022) | 0.821 (0.051) | 13.62 (17.37) |
| IDSLR-Seg | 35.139 (1.002) | 0.828 (0.022) | 0.826 (0.056) | 6.68 (8.42) |
| Proposed | 35.550 (1.012) | 0.834 (0.021) | 0.825 (0.055) | 4.63 (3.14) |
| Proposed Method | Reconstruction | Segmentation | |||
|---|---|---|---|---|---|
| FD | SF | PSNR (dB) | SSIM | DICE | Hausdorff (mm) |
| No | No | 35.524 (1.024) | 0.836 (0.021) | 0.826 (0.054) | 4.70 (2.55) |
| No | Yes | 35.554 (1.016) | 0.840 (0.020) | 0.819 (0.057) | 5.23 (3.42) |
| Yes | Yes | 35.550 (1.012) | 0.834 (0.021) | 0.825 (0.055) | 4.63 (3.14) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, H. Transformer-Based Integrated Framework for Joint Reconstruction and Segmentation in Accelerated Knee MRI. Electronics 2023, 12, 4434. https://doi.org/10.3390/electronics12214434
Lim H. Transformer-Based Integrated Framework for Joint Reconstruction and Segmentation in Accelerated Knee MRI. Electronics. 2023; 12(21):4434. https://doi.org/10.3390/electronics12214434
Chicago/Turabian StyleLim, Hongki. 2023. "Transformer-Based Integrated Framework for Joint Reconstruction and Segmentation in Accelerated Knee MRI" Electronics 12, no. 21: 4434. https://doi.org/10.3390/electronics12214434