1. Introduction
The energy sector undergoes significant transformations that impact all its stakeholders, collectively known as “Energy Transition”. This term refers to the shift from fossil-fuel-based energy production, such as oil, natural gas, or coal, to more sustainable and eco-friendly sources like solar energy, wind energy, hydrogen-based energy, or the use of lithium-ion batteries. Indeed, since the Paris Agreement [
1,
2], there is increasing international concern and action taken with regard to climate change and the viability of Earth. More specifically, the Paris Agreement focuses on the design and application of viable, effective, socially acceptable, and fair policies to fight and possibly reverse climate change on a global level [
3].
Energy transition is not restricted to decarbonization only, but it also incorporates multiple social, technological, and environmental targets [
4]. The concept is based on four fundamental principles, known as the 4Ds of the energy sector, which include decarbonization, digitization, decentralization, and democratization.
In more detail, decarbonization is a key pillar of energy transition [
5], referring to the reduction in dependence on carbon for energy production and its gradual replacement with other sources such as renewable energy sources (RESs) [
6]. The ultimate goal of decarbonization is a world economy that does not produce CO
2 emissions. Decentralization is another pillar of energy transition, focusing on the construction of energy production systems near energy consumers, reducing the dependence on fossil fuels and promoting the use of RESs [
7].
The success of decentralization depends on the existence of active consumers, also known as “prosumers,” who produce, store, and manage the energy that they consume [
8]. Democratization follows decentralization, as prosumers and small and medium-sized enterprises gain reliable access to low-cost energy [
9]. Digitization is the fourth pillar, involving the use of electronic tools, systems, and devices to process data and extract meaningful information to optimize energy processes [
10,
11], as energy data exhibit the so-called 5Vs, i.e., very high volume, variety, velocity, veracity, and value [
12,
13].
The shift from a producer/provider-centered energy system to a consumer/household-centered system poses significant challenges [
14]. Fortunately, advancements in artificial intelligence (AI) have provided a powerful tool to facilitate this transition and achieve associated ecological and social objectives [
15]. However, transitioning to autonomous AI-empowered systems requires addressing their impact on stakeholders and understanding how the underlying functions achieve prediction goals [
16]. It is essential for all energy stakeholders to be actively involved in decision making regarding the production, distribution, and management of energy. Stakeholder-tailored decision support systems (DSSs) that provide decision support at various levels and forms need to be developed.
These DSSs need to integrate predictive models and optimization algorithms that rely on state-of-the-art machine learning (ML) and AI technologies. Additionally, they need to incorporate explainable and responsible AI (XAI and RAI, respectively) technologies to be adopted by various user classes and to exclude unacceptable decisions. XAI and RAI technologies provide system users with justification for recommended actions [
17,
18]. As the explainability and responsibility of an AI system are concepts related to a particular audience, i.e., to a class of users or even specific individuals [
17], the identification of various stakeholder classes is necessary.
The pivotal attributes of explainable artificial intelligence (XAI) include fairness, ethics, transparency, privacy, security, accountability, and safety. System transparency is imperative, equally weighed with the demand for data privacy and security [
19]. Ensuring users comprehend the characteristics of utilized models and providing a transparent representation of the deployed algorithms are crucial [
17]. The predominant issue pertains to establishing user trust in machine learning (ML) models for predictions and decision support, while developers must furnish adequate descriptions and decision-making roadmaps [
20].
XAI is deemed vital due to the growing social impact of intelligent systems. Indeed, XAI promotes system adoption and could integrate familiarity with technology and AI literacy into its framework and design process, combining scientific and simplified explanations per user comprehension and mental capacity [
21]. The concept of XAI is divided into global explainability, providing overarching understanding of model predictions, and local explainability, elucidating individual classifier decisions, Both global and local explainability are pivotal for assessing AI system fairness and transparency [
22]. Further divisions of explainability can be assumed with regard to model architecture, benchmarks, and semantic grouping. All of these themes are examined in the following sections.
In view of the above, this paper presents a novel methodology that focuses on developing customized XAI analytics for energy management, which are specifically tailored to meet the needs of various groups of energy stakeholders. This methodology aims to resolve the issue of the “black box” phenomenon associated with AI decision making by ensuring the transparency and interpretability of the analytics results. To support this methodology, the paper introduces an intelligent decision support system (IDSS) that constitutes a software tool consisting of energy services.
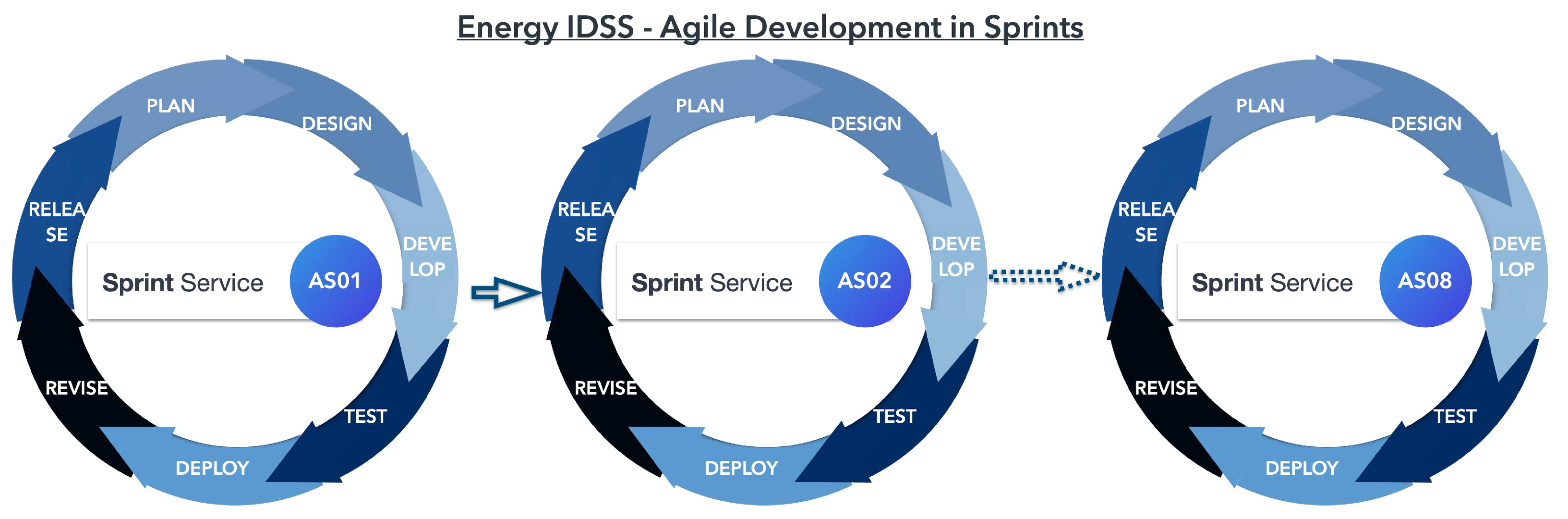
Specifically, the IDSS is developed using an iterative agile life cycle, which is a method for software development that breaks down the work into smaller sprints. The IDSS uses AI and optimization algorithms to provide optimal solutions for energy management and efficiency in buildings under specific constraints. The aim of the IDSS is to help energy stakeholders make informed decisions about energy management and efficiency in buildings by combining AI and optimization algorithms.
The methodology for developing the XAI analytics involves several processes, starting from identifying key stakeholders in the energy sector and conducting an empirical study to determine the usability and explainability needs of the IDSS. This includes creating an appropriate questionnaire, conducting a survey among key stakeholders, and performing a user clustering analysis to define the necessary depth of AI explainability in terms of AI literacy score, acceptance, and perceived usefulness.
Finally, an XAI framework is implemented based on the outcomes of the analysis, which includes XAI clusters and local and global XAI. This framework is designed to ensure a responsible and safe deployment of the AI system, while enabling higher adoption rates by promoting trust and reliability in the analytics results.
The ultimate goal of this methodology is to provide a cutting-edge solution for decision support analytics for energy management and efficiency in buildings that is trustworthy, reliable, and meets the specific needs of energy stakeholders.
In summary, the key contributions of this paper are the following:
Agile development and implementation of an IDSS, prioritizing XAI tailored to specific user needs.
Testing of the methodology on a stacked neural network.
Emphasis on explainability not only as an ethical approach but also as a crucial tool for building user trust and ensuring rapid adoption rates in the energy sector, thus contributing to a more sustainable future.
Utilization of the technology acceptance model (TAM) to cluster stakeholders based on their perceptions of usefulness and ease of use, where:
- –
Perception of usefulness is associated with AI literacy.
- –
Perceived ease of use is linked with usability.
Identification that varying perceptions necessitate different explanation approaches, therefore grouping XAI tools accordingly to ensure broader and accelerated adoption rates.
The main body of the paper is structured as follows:
Section 2 discusses energy-related issues and introduces the IDSS developed through an agile process.
Section 3 introduces a novel methodology for tailored AI explainability in energy management IDSSs.
Section 4 identifies and discusses key energy sector stakeholders.
Section 5 describes the creation of a stakeholder questionnaire, designed considering AI explainability, energy market trends, and the TAM.
Section 6 presents the empirical study and user-based clustering analytics conducted through an actual survey of stakeholders, which specifies requirements for the tailored explainability of energy DSS analytics taking into account AI literacy and levels of abstraction.
Section 7 describes the actual implementation and testing of personalized/tailored XAI in the IDSS, highlighting its utility and adoption implications. Lastly,
Section 8 summarizes the findings and conclusions and proposes future research directions.
3. Overview of the Novel Methodology for Tailored Explainability of AI in Energy Management IDSS
Toward facilitating the adoption of IDSS in energy management applications, the analytic services that they provide need to be more understandable and comprehensible by each associated stakeholder. The methodology described in this paper offers a novel approach to designing a tailored explainability solution for AI analytics services in the energy management sector. It incorporates multiple processes that are informed by the stakeholders’ specific needs and preferences, and it applies established frameworks such as the TAM and human–computer interaction (HCI) principles to ensure the effectiveness of the solution.
One of the key contributions of this methodology is that it takes into account the diverse needs and preferences of stakeholders in the energy management sector. By conducting a survey and analyzing the data, the methodology is able to identify the different clusters of stakeholders with varying levels of AI literacy, acceptance, perceived usefulness and ease of use, and energy market trends. This helps to ensure that the tailored explainability solution is designed to meet the specific needs of each stakeholder group.
Another contribution of this methodology is that it incorporates both local and global levels of implementation. This ensures that the tailored explainability solution is accessible to all stakeholders who require it. This is particularly important in the energy management sector, where stakeholders may vary significantly in their backgrounds and needs.
In general, the novelty and contribution of this methodology lie in its comprehensive approach to designing a tailored explainability solution for AI analytics services in the energy management sector. By taking into account the stakeholders’ specific needs and preferences and applying established frameworks, the methodology is able to develop an effective solution that meets the diverse needs of stakeholders in this sector.
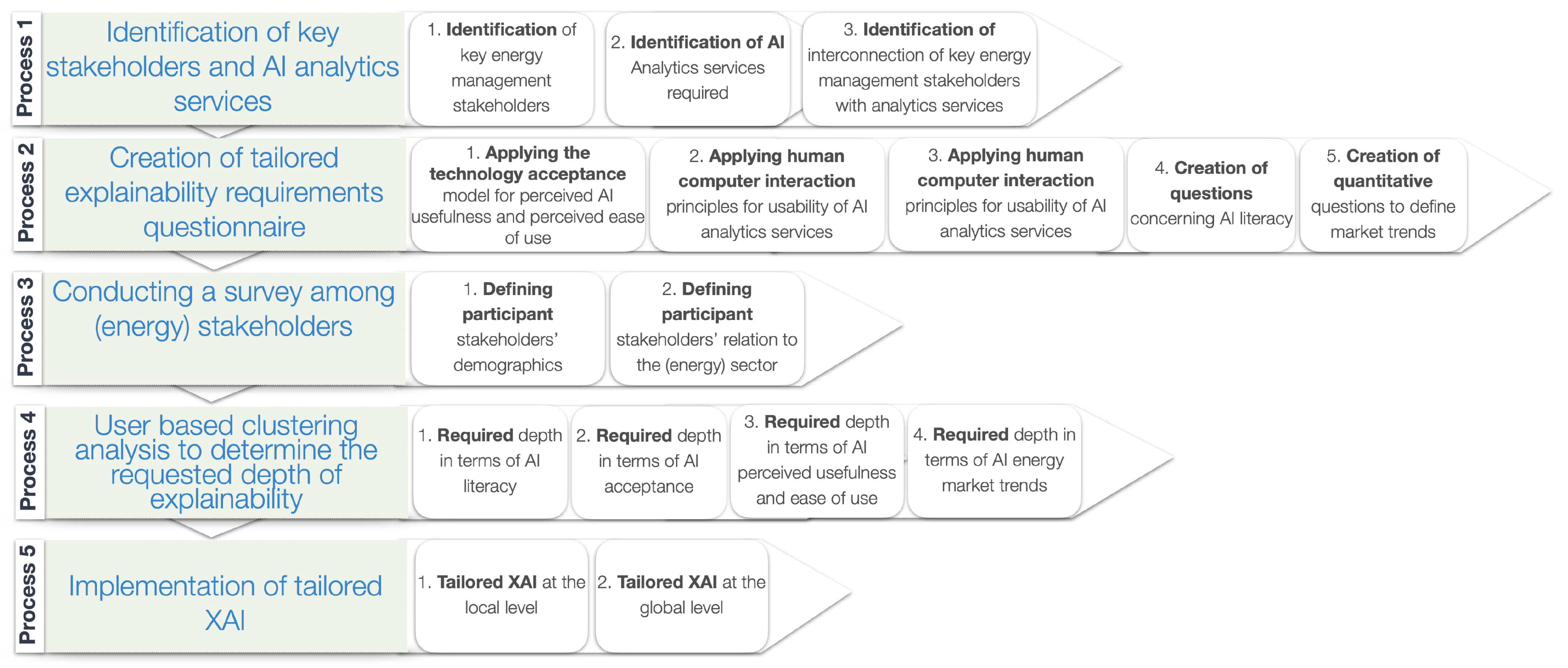
In more detail, the methodology consists of five processes aimed at developing a tailored explainability solution for AI analytics services in the energy management sector, as follows.
Process 1: Identification of key stakeholders and AI analytics services. The first process involves identifying the key stakeholders in the energy management sector and the required AI analytics services. This step is critical because it helps to understand the ecosystem in which the AI analytics services will be deployed and identify the stakeholders who will be impacted by these services. By understanding the interconnection between the stakeholders and the analytics services, it becomes possible to design a tailored explainability solution that addresses their specific needs.
Process 2: Creation of tailored explainability requirements questionnaire. The second process involves creating a tailored questionnaire to gather requirements for explainability. This questionnaire is designed to capture the stakeholders’ perceptions of the ease of use and usability of the AI analytics services, their level of AI literacy, and their understanding of the energy market trends. The questionnaire applies the TAM and HCI principles, which help to ensure that the stakeholders’ needs are fully addressed.
Process 3: Conducting a survey among energy management stakeholders. The third process involves conducting a survey among the energy management stakeholders to collect data on their demographics and relation to the energy sector. The survey is designed to ensure that the tailored explainability solution is informed by the specific needs of the stakeholders. This step also helps to ensure that the stakeholders are involved in the process and that their voices are heard.
Process 4: User-based clustering analysis to determine the required depth of explainability. The fourth process involves user-based clustering analysis to determine the required depth of explainability. This is carried out in terms of the stakeholders’ AI literacy, acceptance, perceived usefulness and ease of use, and energy market trends. By analyzing the survey data, it becomes possible to group the stakeholders based on their needs and preferences. This step helps to ensure that the tailored explainability solution is effective in providing the required level of transparency and understanding.
Process 5: Implementation of tailored XAI. The final process involves implementing the tailored explainability solution for AI analytics services at both the local and global levels. This step involves developing a solution that meets the specific needs of the stakeholders and is effective in providing the required level of transparency and understanding. The solution is implemented at both the local and global levels to ensure that it is accessible to all stakeholders who require it.
This methodology, which is summarized in
Figure 3, is designed to ensure that the explainability of AI analytics services in the energy management sector is tailored to the specific needs of stakeholders and is effective in providing the required level of transparency and understanding. It is a comprehensive approach that involves multiple steps and is informed by data collected from the stakeholders themselves.
4. Identification of Key Energy Stakeholders
In the energy sector, there are various stakeholders with different roles and responsibilities, and each stakeholder group has specific needs and requirements. Therefore, it is essential to identify these stakeholders and understand their interconnection to effectively implement any energy management system.
However, identifying stakeholders can be challenging as they can vary depending on the context, location, and type of project. Additionally, stakeholders may have conflicting interests, which can further complicate the process. Hence, it requires a systematic and comprehensive approach to identify all stakeholders and understand their requirements and needs.
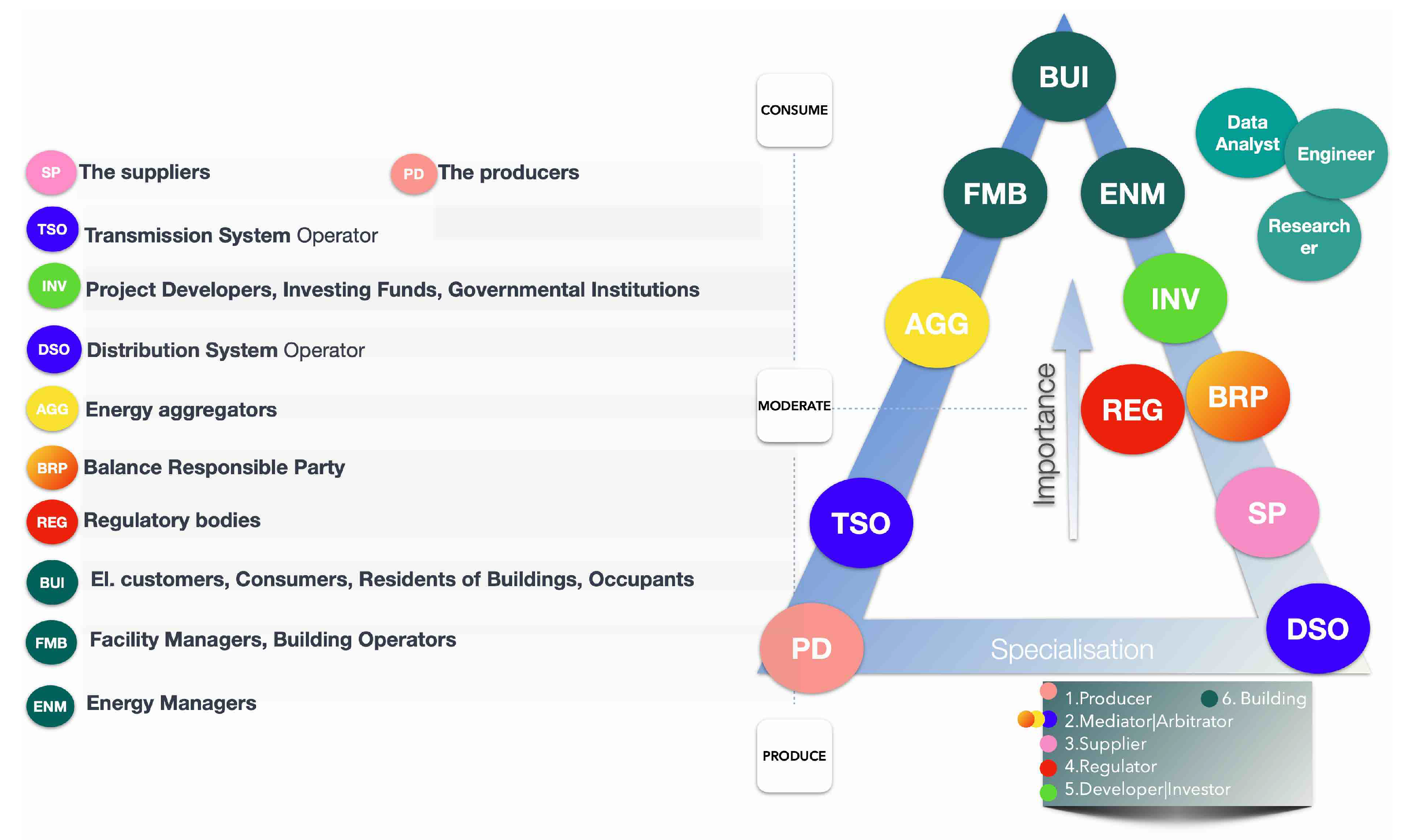
It is important to note that stakeholders range from energy producers, suppliers, balance responsible parties, transmission and distribution system operators, regulatory bodies, electricity customers, consumers, residents of buildings, project developers, investing funds, governmental institutions, aggregators, facility managers, and energy managers. Each stakeholder group plays a significant role in the energy sector and requires different types of analytics services to meet their needs.
In this subsection, we outline eleven (11) key stakeholders, which are associated with stakeholders and have been fully implemented.
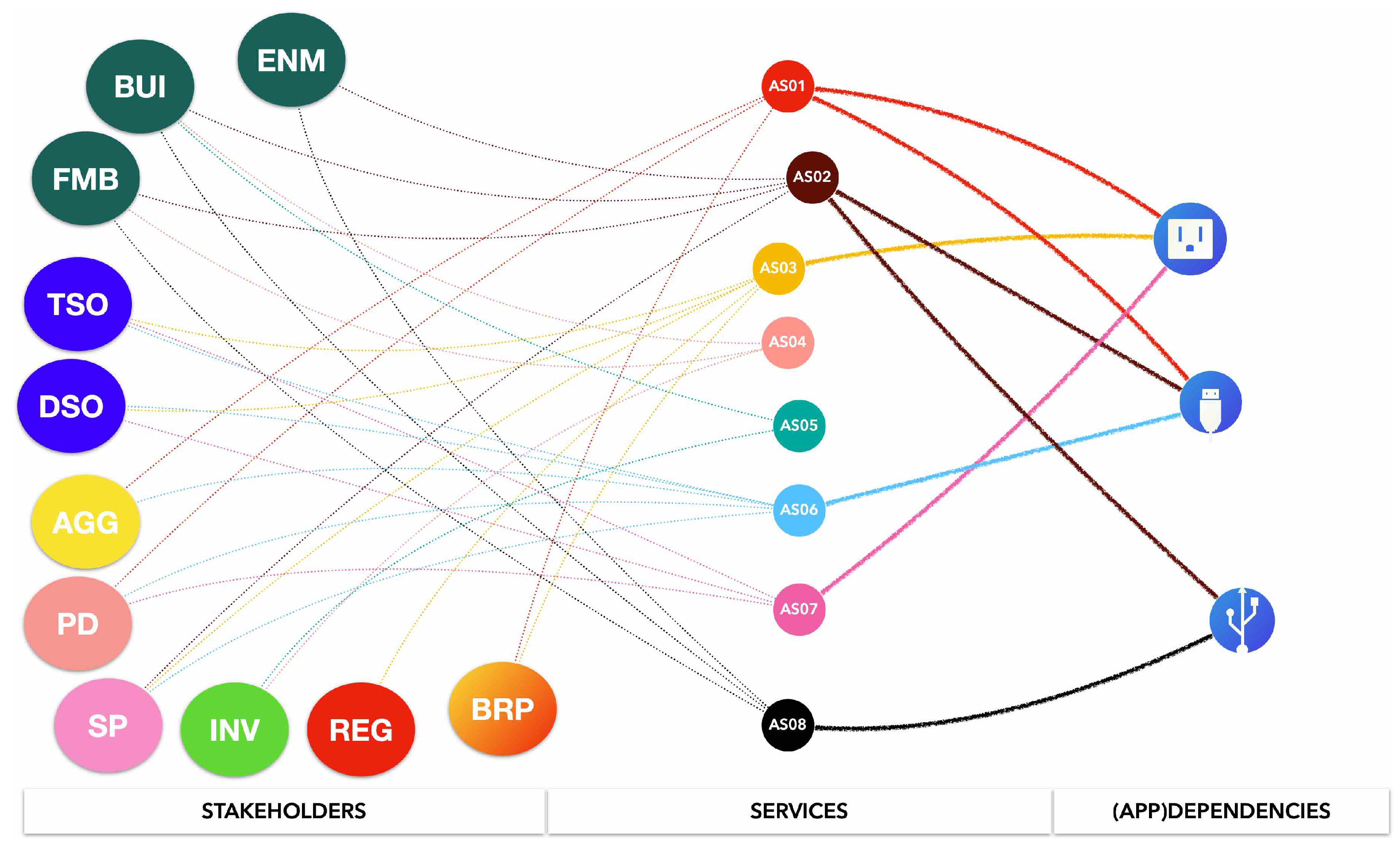
Figure 4 illustrates key energy stakeholders along with their corresponding importance and
Figure 5 illustrates the interconnection between the key stakeholders and the analytics services defined previously. The description and the roles of these stakeholders are analyzed as follows:
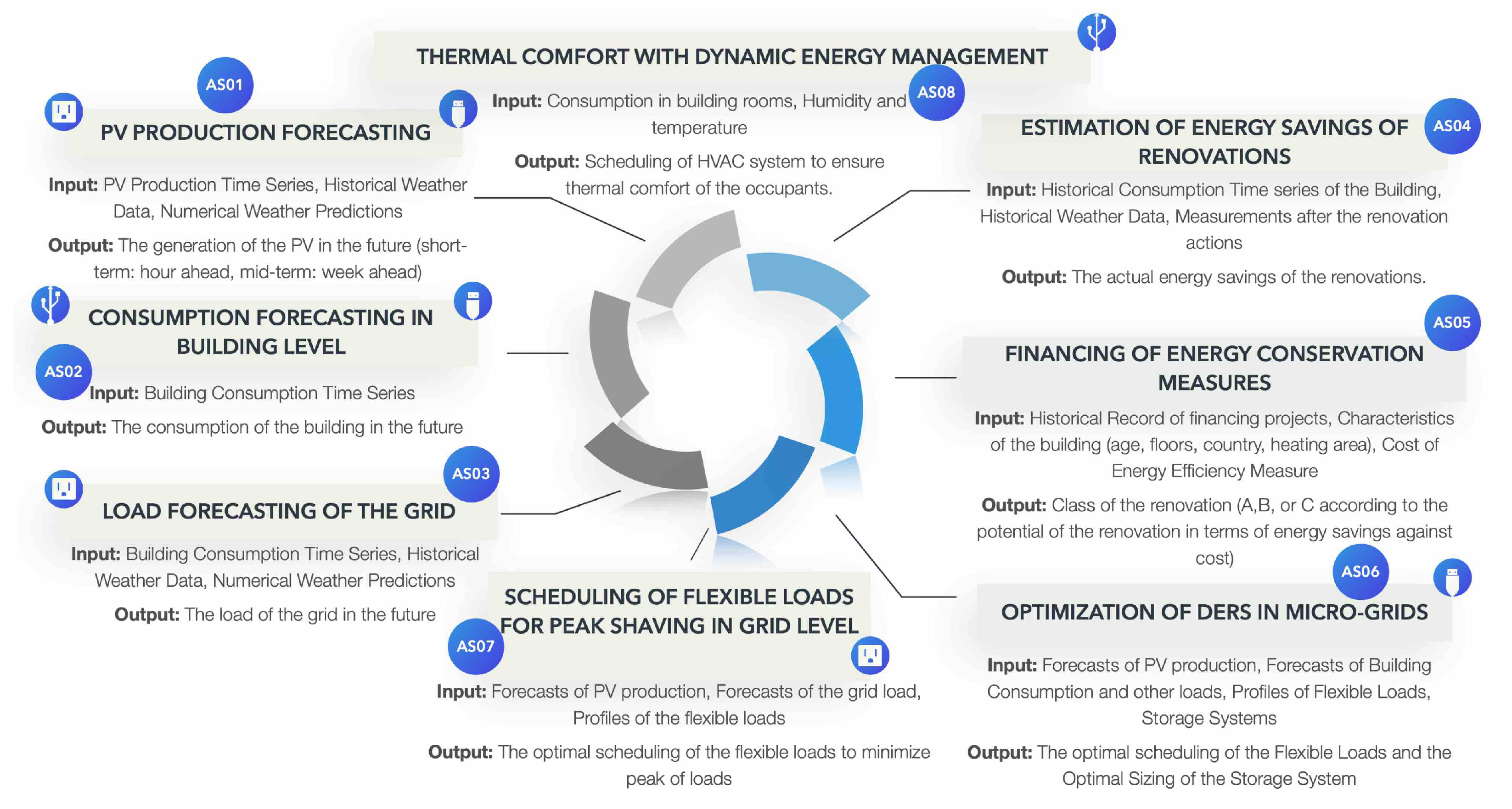
KS01—Producers (PDs): Producers generate energy, either conventionally or through renewable sources, and include entities like individual park owners and aggregators of several production sites.
KS02—Suppliers (SPs): Suppliers sell energy to various consumers and may not necessarily be producers, especially in competitive energy markets.
KS03—Balance Responsible Party (BRP): BRPs oversee the balance of one or more access points to the transmission grid.
KS04—Transmission System Operator (TSO): TSOs transport electricity from producers to distribution networks or direct to consumers and are obliged to ensure the overall balance of the network.
KS05—Distribution System Operators (DSOs): DSOs handle the construction and management of medium- and low-voltage/pressure networks, connecting transmission networks to private properties.
KS06—Regulatory Bodies (REGs): These bodies regulate the energy market, ensuring transparency and competition, defending consumer interests, and certifying energy markets’ operations.
KS07—Electricity Customers, Consumers, Residents of Buildings, Occupants (BUIs): This group consists of entities consuming energy at various scales.
KS08—Project Developers, Investing Funds, Governmental Institutions (INVs): Entities focusing on financing opportunities in energy efficiency projects aiming to reduce carbon emissions at various scales.
KS09—Aggregators (AGGs): Aggregators manage the electricity consumption of a consumer group, responding to total grid demand, and sell flexibility to DSOs, BRPs, and TSOs.
KS10—Facility Managers, Building Operators (FMBs): FMBs manage the heating, cooling, and mechanical equipment of a building to ensure efficient operation.
KS11—Energy Managers (ENMs): ENMs manage the HVAC systems of large buildings to maintain acceptable thermal comfort levels.
Figure 4.
Key energy stakeholders.
Figure 4.
Key energy stakeholders.
Figure 5.
Interconnection between key stakeholders and analytics services.
Figure 5.
Interconnection between key stakeholders and analytics services.
5. TAM for Tailored Questionnaire in an Empirical Study
The next step in the process entails the development of a customized empirical study aimed at obtaining information on explainability requirements. The empirical study is specifically designed to elicit feedback from stakeholders on the user-friendliness and functionality of the AI analytics services, their level of familiarity with AI, and their grasp of current energy market trends. Therefore, the empirical study is based on a survey with a questionnaire that has been created to serve the purposes of the empirical study. As such, the questionnaire is grounded on the principles of the TAM and HCI, which serve to guarantee that the stakeholders’ needs are comprehensively met.
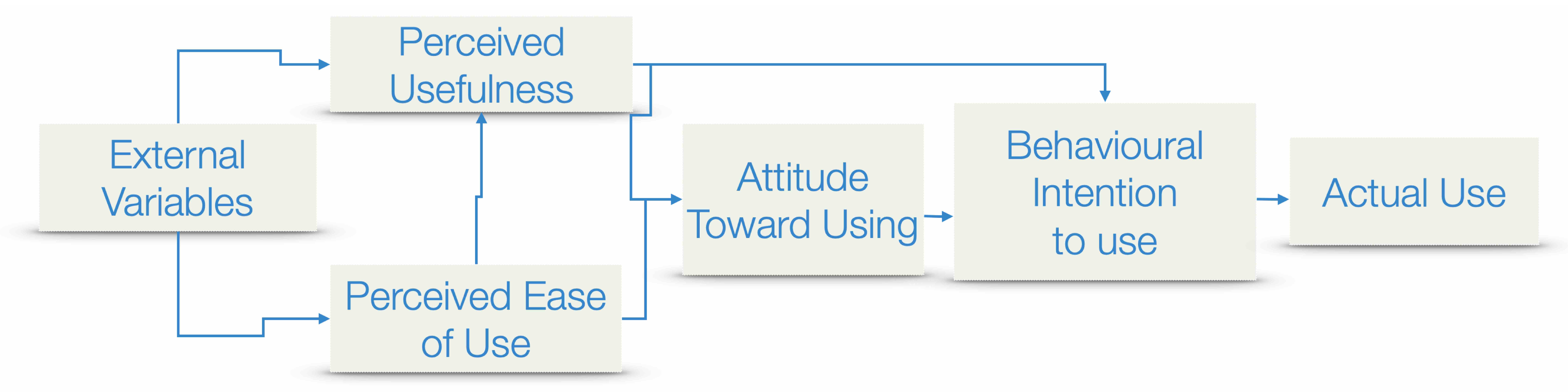
According to the TAM developed by Davis in 1989, the acceptance of a new computer system is linked to two external factors, namely
perceived usefulness and
perceived ease of use. Perceived usefulness refers to the users’ belief that a certain technology can deliver value. Perceived ease of use refers to the level of effort that a user would be required to undertake to use the technology. TAM is extracted from the theory of reasoned action [
42], which assumes that, to predict user behavior, those two external variables should be linked to specific intentions. These factors are viewed as indicators of an individual’s willingness to use a particular technology and, consequently, impact the probability of its adoption.
The TAM is a suitable framework for creating questions aimed at determining energy stakeholders’ willingness to use new technology such as AI. This is because perceived usefulness and perceived ease of use are two factors that align with common concerns that energy stakeholders may have when considering the adoption of AI.
Firstly, energy stakeholders may question the usefulness of AI in energy management because they may not fully understand how the technology works and what benefits it can provide. Additionally, they may have concerns about the reliability and accuracy of AI algorithms and models, as well as potential ethical implications and risks associated with the use of AI in decision-making processes.
In the context of energy management, stakeholders may also be more familiar with traditional methods and practices, and therefore may be skeptical about the effectiveness of AI in improving energy efficiency, reducing costs, or enhancing sustainability. Furthermore, they may have specific requirements and constraints that they believe cannot be addressed by AI technology.
To address these doubts and concerns, it is important to gather stakeholders’ perceptions and expectations about the usefulness of AI in energy management, as well as to educate them about the potential benefits and limitations of the technology. Utilizing a framework such as the TAM can help in assessing stakeholders’ perceptions and in identifying areas where further education and clarification may be needed. The questionnaire designed to gather stakeholders’ perceptions on AI’s usefulness can aid in assessing whether the technology meets the expectations and needs of the stakeholders.
Secondly, stakeholders may be apprehensive about the ease of use of AI. The TAM framework emphasizes that the technology must be perceived as easy to use to ensure its successful adoption. The questionnaire can help in assessing the stakeholders’ perception of the user-friendliness of AI and simplicity of its operations. Therefore, the TAM framework is used in developing a questionnaire that can help to ensure that stakeholders’ concerns and expectations are accurately captured. It can provide valuable insight into the likelihood of the successful adoption of AI technology in the given context of energy management, as illustrated in
Figure 6.
The questionnaire is divided into three sections. The first one is related to the demographic characteristics of the participants, including age, gender, educational level, occupation, and employment space (public, private, or both). The aim of the second section is to define the AI literacy level (perceived usefulness) of the participants, while the third section attempts to define the perceived ease of use of the provided AI tools. In the second and third sections, both qualitative and quantitative questions were included. The quantitative questions were used as scoring components and facilitated the clustering of the specialists that participated in the survey. On the other hand, the qualitative questions were used as descriptors of the market trends and the general attitude toward AI infusion in the energy sector. In
Table 1,
Table 2 and
Table 3, the different questions are separated in a way that reflects the described process.
5.1. Questions Concerning AI Literacy for the Perceived Usefulness
Indeed, we use TAM to align survey outcomes with application deployment requirements to ensure higher adoption rates and smaller learning curves. For that purpose, the survey questionnaire is structured in such a way as to facilitate scoring with regard to usefulness (as related to AI) and perceived ease of use (as associated with a more generic approach to AI capabilities and tools provided by the system). By retrieving valuable input by its main potential users and stakeholders, a more concrete definition is provided of the required depth of system explainability. Recognizing users’ attitude toward AI potential and their level of AI literacy, especially with regard to energy system automation and predictive capabilities of the proposed models, the developer can outline and build with intention and purpose better systems, and, at the same time, deliver tools for the circular economy.
The perceived usefulness of AI is strongly connected to AI literacy, which refers to the ability to understand, use, and critically evaluate AI technologies and their implications. AI can be considered as a new form of technological advances and thus is connected to the concept of technological literacy, which encompasses a wide range of knowledge, skills, and attitudes necessary to adapt and thrive in a rapidly changing technological environment. Technological literacy is considered an essential component of modern education and workforce preparedness by organizations such as the International Technology Education Association [
43] and the National Research Council (NRC) [
44]. Digital literacy, a subset of technological literacy, focuses on the effective and responsible use of digital technologies.
In turn, AI literacy is a subset of digital literacy. AI literacy is defined as a set of competencies that enable individuals to critically evaluate AI technologies, communicate and collaborate effectively with AI, and use AI as a tool online, at home, and in the workplace [
45,
46]. The more AI-literate a person is, the more likely they are to understand the potential benefits and applications of AI technologies, leading to a higher perception of usefulness and adoption. Literacy in a particular domain, such as digital or AI literacy, can influence an individual’s perception of the ease of use and usefulness of related technologies. Energy market trends are another external variable that could impact perceived usefulness and predict technology acceptance.
Perceived usefulness is closely linked to information literacy skills because it is primarily utilized to attain specific objectives that are not naturally associated with the use of the skill itself. Davis provides the definition of perceived usefulness as the extent to which a person believes that the utilization of a particular method or technique would enhance their job performance or routine responsibility, based on the notion that the acquired capacity will improve their performance.
Research studies such as [
47] suggest that pre-service teachers who have a better understanding of the potential benefits and applications of technology are more likely to perceive it as useful and thus demonstrate a higher acceptance of it. This increased acceptance could be attributed to their increased familiarity and competence in using technology as part of their education, leading to a greater understanding and self-efficacy in integrating technology into their teaching practices. Higher literacy in certain domains may result in higher self-efficacy.
Although not directly focused on technology literacy, research studies such as [
48] investigate the relationship between computer self-efficacy, facilitating conditions, and perceived usefulness, which may be related to technology literacy. Additionally, the study in [
49] applies an extended TAM that touches upon the relationship between an individual’s background, experience, and perceived usefulness, which may relate to technology literacy.
More specifically, the following questions were created in the context of AI literacy and the perceived usefulness:
Q1:
Competency level in the English language Competency level in the English language is often deemed necessary for using advanced computer systems, even though efforts have been made to increase accessibility in other languages; therefore, since language is the driver of expression, competency in English is an important variable for perceived usefulness and AI literacy, as lack of knowledge in the primary expressive tool in the digital domain may be considered as a factor of lower related literacy [
50,
51].
Q2: Level of literacy in AI and related expertise This question directly relates to the level of AI literacy.
Q3: Years of experience in the sector As previously mentioned, literacy in a specific technology is positively correlated with acceptance by energy stakeholders and years of experience with the technology is a contributing factor.
Q4: In the system use, were you adequately informed for every change that the system performs? While developing the system, efforts were made to facilitate user navigation, with consideration for the system’s usability for both experts and less experienced users, which led to the inclusion of Q4 in the AI literacy evaluation, although it could also be placed in the usability and perceived ease of use category.
Q5: In the system use, to what extent your previous knowledge on the use of information systems has helped you understand how to use the present system? This considers prior knowledge as a factor in measuring literacy and self-efficacy, while it can also be seen as a variable in assessing perceived usefulness.
Q6: In the system use, to what extent you needed a button for help? One’s AI literacy level can be associated with the perception of AI systems and related capabilities if they require more help, indicating that Q6, while potentially related to usability, is considered a measure of AI literacy.
Q7: To what extent were the system messages informative? As in Q4, at least some attention was given for the facilitation of the user toward navigating the system. For that reason, we considered that, for an expert, navigation should not present major issues. A beginner, however, with lesser capabilities, i.e., a lower AI literacy level, would score lower, and for that we wanted to separate it from the second group of questions, related to usability.
Q8: To what extent did you need to learn new functions to operate the system? The requirement of acquiring new knowledge should be considered part of literacy improvement or a measurement of literacy. Since AI literacy is part of perceived usefulness, Q8 should remain in this group.
Q9: To understand the results, did you need more information that was missing from the system? This question is meant to be considered in conjunction with Q4, Q5, and Q6.
Q10: Did you need more automatic recommendations on how to use the results of the system? A greater understanding and self-efficacy of how technology is incorporated into one’s practice is an indicator of perceived usefulness and related to literacy as also analyzed in the previous sections.
Q11: Did you need more explanations on how the results of the system were generated? This question relates to the “Black Box” concern in the same context as Q10.
Q12: Did you trust the systems results? System trust is a basis of system understanding and thus the ability to understand the system should be considered as related to the users’ literacy in AI and, by association, perception of usefulness.
Q13: Did you cross-check the results using other methods? In the same context as Q12.
Q14: Were the results satisfying? Since the system architecture and especially machine learning models have been peer-reviewed and tested by specialists, the results should be satisfying to those who understand the methods used and the potential of AI in this domain. The extent to which one could describe the methods and that potential is indeed a metric of his/her literacy and, for that reason, Q14 is included here as a variable of perceived usefulness.
In
Table 1, the whole set of questions that were created to identify the AI literacy level relating to the perceived usefulness of stakeholders is summarized.
5.2. Questions about Perceived Ease of Use and Usability
Davis (1989) defined perceived ease of use as the degree to which an individual perceives that using a specific system would be effortless and hassle-free. In line with this, Zhu, Linb, and Hsu emphasized that perceived ease of use signifies the degree to which an individual accepts that using certain technology would be easy and trouble-free, and that system characteristics can influence ease of use and system usage. In [
52], the authors identified several factors that may influence the ease of use of modern resources, such as computer self-efficacy, Internet self-efficacy, and information anxiety, among others [
47]. Information anxiety, in particular, can affect the perceived ease of use, as access to an overwhelming amount of information is a significant challenge in today’s information age. In their study, [
52] extended the TAM to include factors such as experience, voluntariness of use, and objective usability. They indirectly addressed the topic of technology literacy by examining familiarity with technology. Moreover, [
47] proposed a theoretical extension of the TAM based on four longitudinal field studies. In [
53], the authors provide a comprehensive overview of usability engineering methods to evaluate and improve usability. Nielsen argued that designing systems with good usability leads to a higher perceived ease of use, which in turn results in more positive user experiences and increased technology adoption [
54]. Ref. [
55] points out that despite the ongoing research on user interface usability, the fast-paced advancements in AI bring new paradigms and quality demands, such as explainability and trustworthiness, which are often neglected in the AI literature, yet certain usability factors are crucial for human–AI interaction and for ensuring explainability and trustworthiness. This is particularly important as AI technology grows rapidly, using many kinds of algorithms and sophisticated techniques. The whole set of questions that were created to identify the usability level relating to the perceived ease of use of stakeholders relating to the eight analytics services, which were described in previous sections, is summarized in
Table 2.
The group of questions from Q1 to Q6 focuses on evaluating the usability of AI tools within the system, as systems designed with good usability tend to have a higher perceived ease of use, and all questions starting with the phrase “in the system use” investigate the properties and functions of the system as implemented in the analytics services. More specifically, the reasoning underlying each question is presented below:
Q7: Were the results compatible with other external sources and expertise? This question evaluates the system’s compatibility with external sources and the user’s personal experience, which is an indicator of usability and perceived ease of use, as per the TAM literature, that suggests experience, voluntariness of use, and objective usability as components of perceived ease of use.
Q8: Did you find the overall system useful? This question is considered a variable of perceived ease of use in that it assesses the overall usefulness of the system, which includes not just the technology of AI but also its implementation and integration into the system as a whole.
Q9: Did you find the overall system easy to use? This question measures the ease of use of the system.
Q10: Was the experience of using the system satisfying for you? This question evaluates the overall satisfaction of the user’s experience using the system, which contributes to the objective usability of the system.
Q11: Would you use this system in the future? This question assesses the likelihood of the user using the system in the future, which also contributes to the objective usability of the system.
5.3. Qualitative Questions to Define Energy Market
When using TAM to assess the acceptance of a system, it is often necessary to consider additional variables. In this study, we took market trends into account as an external factor closely related to acceptance. Evaluating product placement or more abstract concepts, such as acceptance behavior, requires considering both market trends and macroeconomics, which are interconnected factors that predict TAM. Hence, in the last section of the questionnaire, qualitative questions are created. These questions are qualitative because they ask respondents to mark their beliefs, opinions, and suggestions rather than providing numerical data. They do not involve any numerical or statistical analysis and their results cannot be quantified. Instead, they provide insights into the participants’ perceptions, attitudes, and ideas related to the incorporation of AI in the energy sector and as such they are meant to define energy market trends. The whole set of qualitative questions that were created to define energy market trends is summarized in
Table 3, while the full descriptive statistics are presented in the
Appendix A.
More specifically, the reasoning underlying each question is presented below:
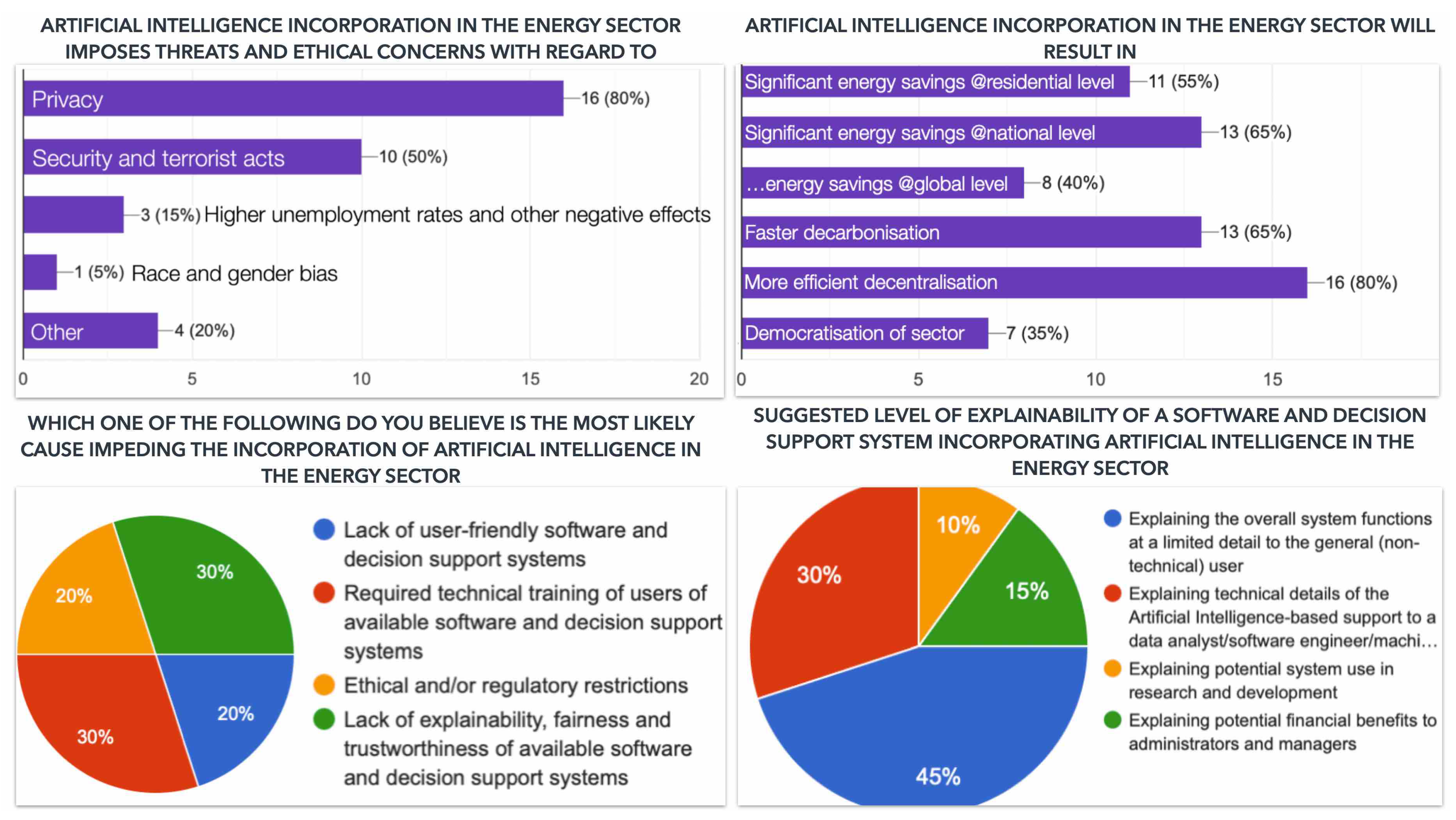
Q1: AI incorporation in the energy sector will result in (mark as many as appropriate) This question is important for identifying the potential benefits of incorporating AI into the energy sector. By understanding the potential benefits, businesses and investors can assess the market opportunity and determine where to allocate resources.
Q2: Suggested level of explainability of a software and decision support system incorporating AI in the energy sector (mark only one) The level of explainability is an important factor in the adoption of AI systems. By understanding what level of explainability is necessary for the energy sector, businesses and regulators can identify what is required for AI systems to be adopted at scale.
Q3: Suggestions of potential actions towards safer, more efficient, user-friendlier, and faster incorporation of AI in the energy sector This question is important for identifying the actions that need to be taken to ensure that AI is adopted safely and efficiently in the energy sector. By understanding the necessary actions, businesses and regulators can work to support the development and adoption of AI in the energy sector.
Q4: AI will radically transform the energy sector (mark only one) This question is important for understanding the potential impact of AI on the energy sector. By understanding the potential for transformation, businesses and investors can identify opportunities for growth and disruption in the market.
Q5: AI incorporation in the energy sector imposes threats and ethical concerns with regard to (mark as many as appropriate) This question is important for identifying the potential risks and ethical concerns associated with the adoption of AI in the energy sector. By understanding these concerns, businesses and regulators can work to mitigate risks and ensure that AI is developed and adopted responsibly.
Q6: Which one of the following do you believe is the most likely cause impeding the incorporation of AI in the energy sector (mark only one)? This question is important for identifying the barriers to the adoption of AI in the energy sector. By understanding the most significant barriers, businesses and regulators can work to address these issues and support the development and adoption of AI in the energy sector.
7. Incorporation and Implementation of Tailored XAI in the DSS
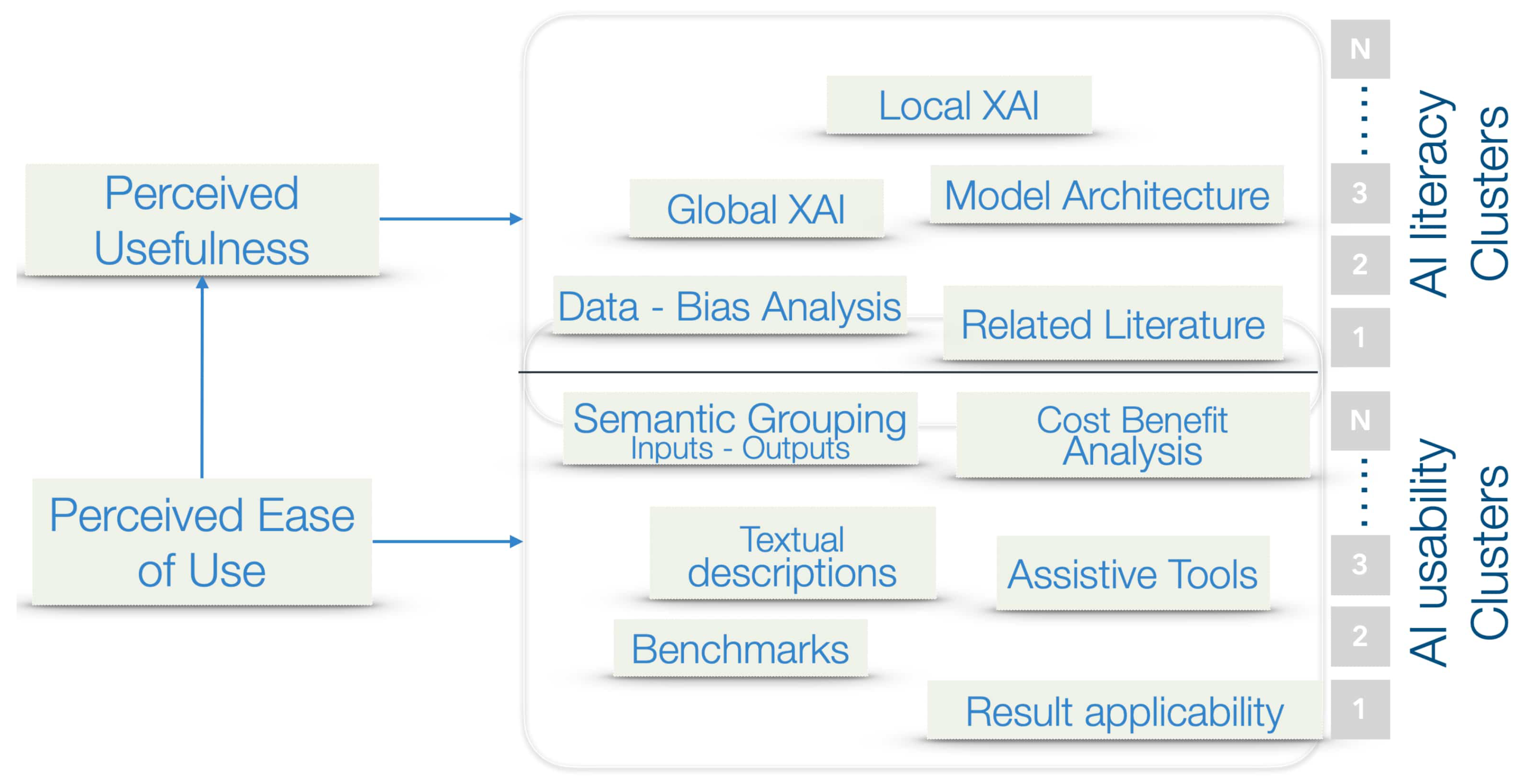
According to TAM, analyzed in the previous sections, the perceived ease of use (AI usability) and perception of usefulness (AI literacy level) are communicating vessels, interconnected in the users’ consciousness. We have identified two different clusters in our data, related to their analytical experience, and have quantified their AI literacy level. More clusters have been proposed based on the perceived ease of use, where some key points were identified and should be addressed via design modifications. In
Figure 11, the generalization of our methodology can be seen. The different XAI tools are provided depending on a defined personalization.
For each cluster, different tools are proposed with some tools overlapping with regard to AI explainability. For Cluster 1, a technical analysis of the ML models should be provided, using local and global XAI, bias analysis, and model architecture characteristics. The related literature should also be provided. Cluster 2, which consists of less experienced users, should have access to basic textual description of the process. A semantic grouping of inputs and output [
61] combined with cost benefit analysis and contribution to the circular economy via AI applicability in the sector should provide incentives and build trust while simultaneously overcoming validation and regulation challenges.
To address the problem of perceived usefulness and perceived ease of use, following the proposed methodology outlined in
Figure 11, we offer a preview of screens used to explain the predictive technology used for one of the developed applications, incorporating the presented technologies.
7.1. Model Architecture and Benchmarks
In this subsection, we present a concrete example of a practical application of our proposed tailored XAI methodology. Specifically, we apply our methodology with regard to analytic service AS04 (
Figure 2). From
Figure 2,
Figure 4 and
Figure 5, it is clear that AS04 is to be used by stakeholders BUI (consumers, customers, residents of buildings, occupants), FMB (facility managers, building operators), and INV (project developers, investing funds). These stakeholders have very different backgrounds, preferences, skills, and abilities, and thus different perceptions of ease of use and usefulness of service AS04. Those differences require different explanation approaches to ensure greater and faster adoption rates. It should be mentioned though that even though stakeholders are in defined groups, within the groups, people with different abilities and skills exist. For that, we employ TAM to have a better understanding of those abilities and provide accurate personalization.
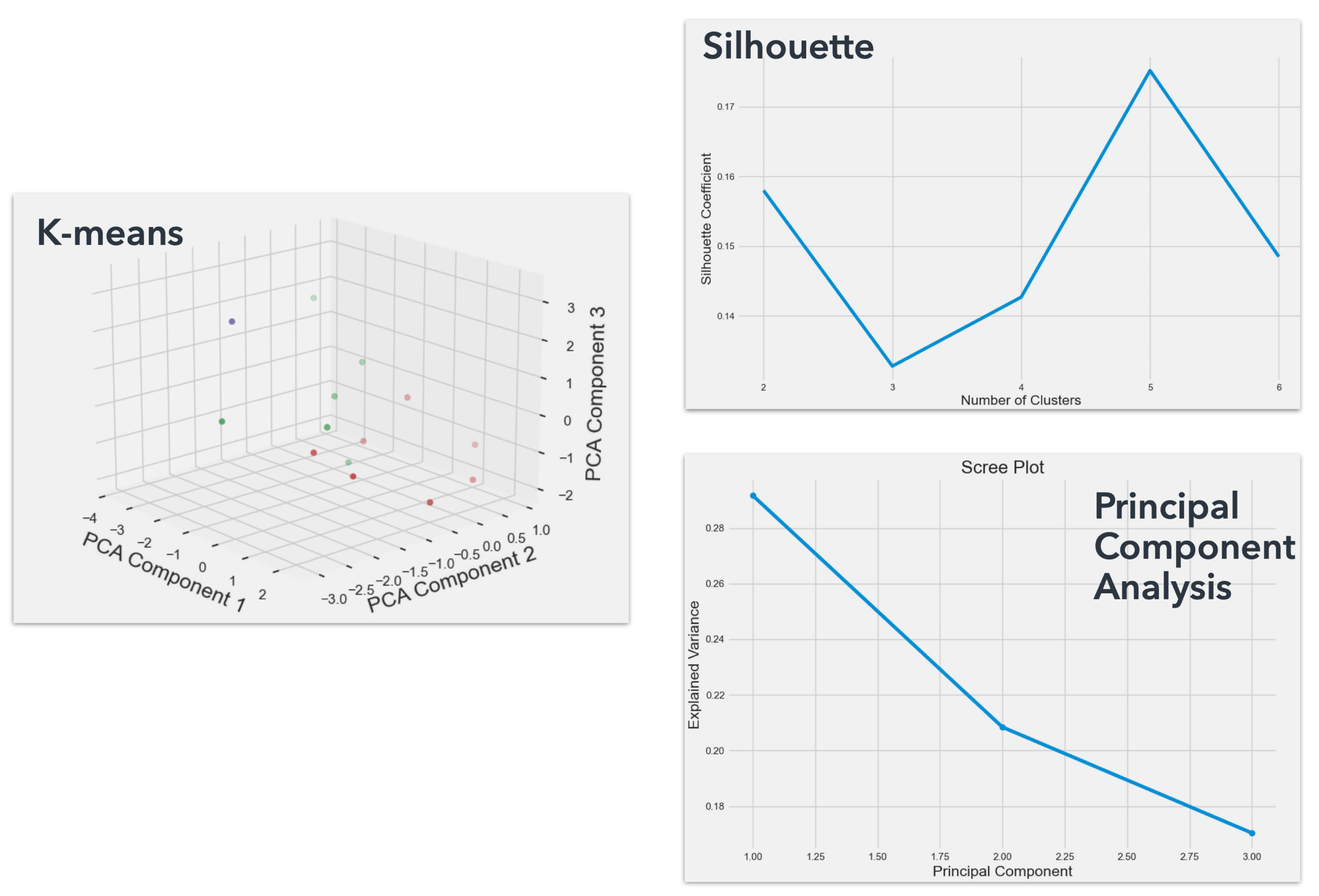
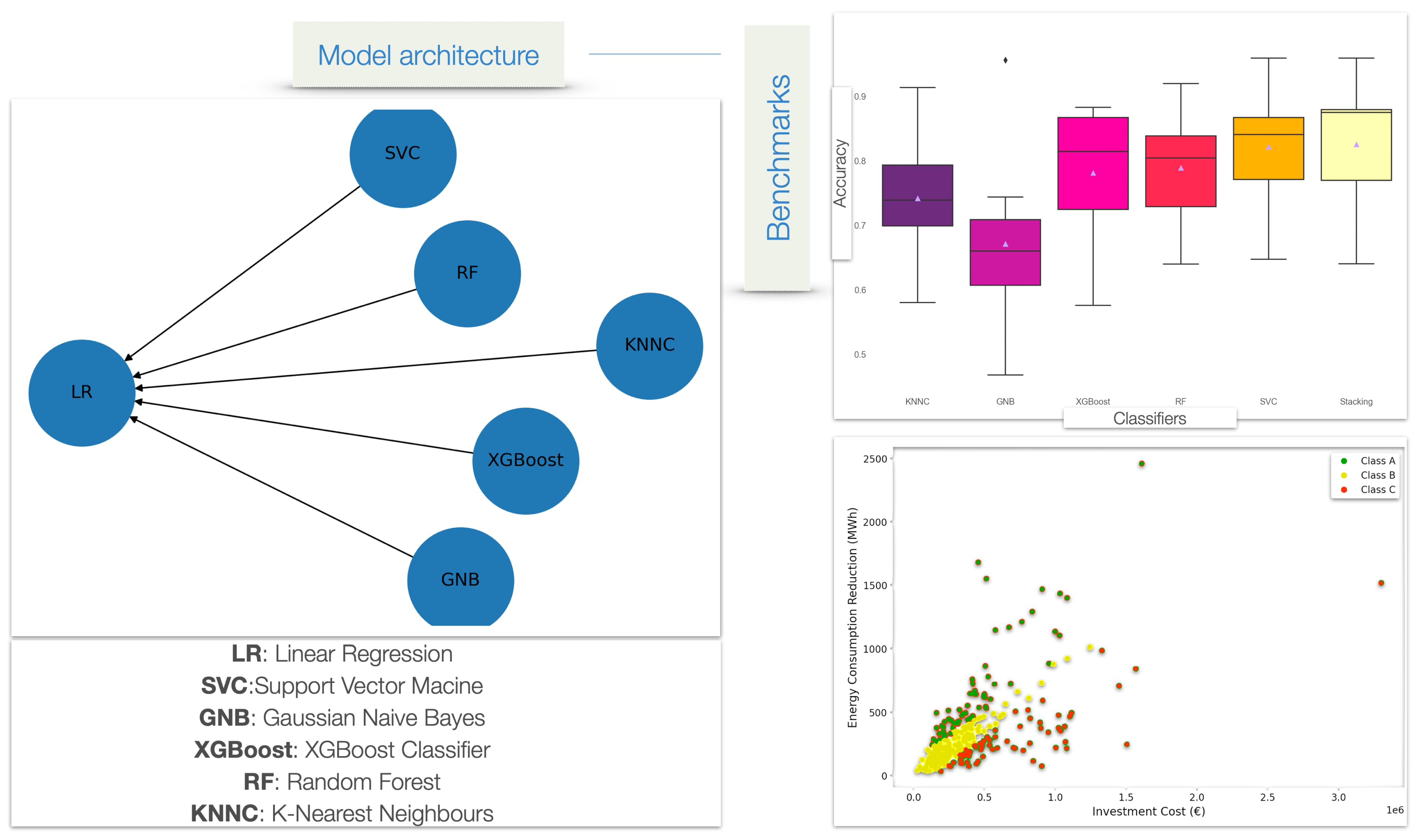
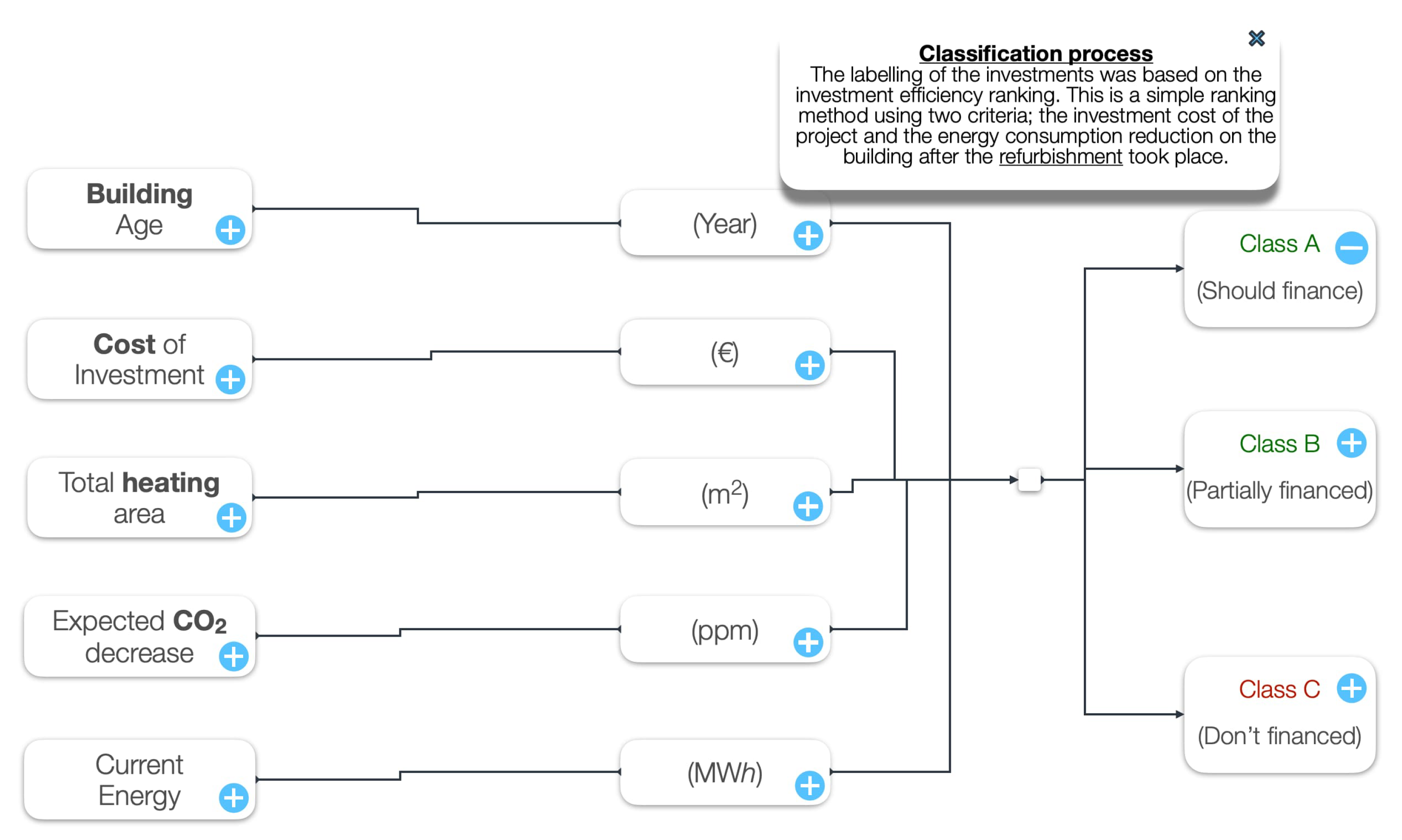
In
Figure 12, the model architecture of AS04 is presented. An ensemble of key models is used to make predictions based on a probability of a three-class outcome, using as feature inputs (1) the energy consumption before renovation, (2) the cost of renovation, (3) the planned CO
2 reduction as detailed by the constructor specifications, (4) the building age in years, and (5) the total heating area defined by the building envelope [
40].
Next, the overall model outputs the probabilities for each class. Based on the investment potential, which is the relationship between energy consumption reduction and cost of investment, the model considers three classes. For Class A, the potential for investment is optimum, while for Class B it is medium and the project should be only partially financed. For Class C, the project should not be financed. The different models are stacked and use linear regression as the activation function to make predictions.
Using an ensemble of models, an average prediction is provided, ensuring optimized results for a given problem using different algorithms for a better definition and boosted solution overall. In the benchmark section, the accuracy of each model is calculated, alongside the final result of the stacked model. Finally, the correlation between energy consumption and investment cost for each class is shown. In this section, we look into the proposed methods outlined in
Figure 12, where the model architecture for Cluster 1 and benchmarks for Cluster 2 are touched upon.
7.2. Textual Descriptors—Semantic Grouping
Textual descriptions are comments for users to understand the reasoning behind the development of an application and the personal and macro-economic benefits of using it. Some key points that have been analyzed in this paper are used as descriptors of usefulness, such as the idea of circular economics and the semantic grouping of applications and stakeholders. The relation between inputs and outputs [
61] is also an important factor that can increase adoption, add trust to the system, and clarify the system results. In
Figure 13, the semantic relation of inputs and outputs is presented [
40]. In the middle section, the data structure of each input is introduced. Each element has more information attached to it for the user to explore, thus offering an in-depth look at how the system analyzes data and outputs predictions.
7.3. Local XAI
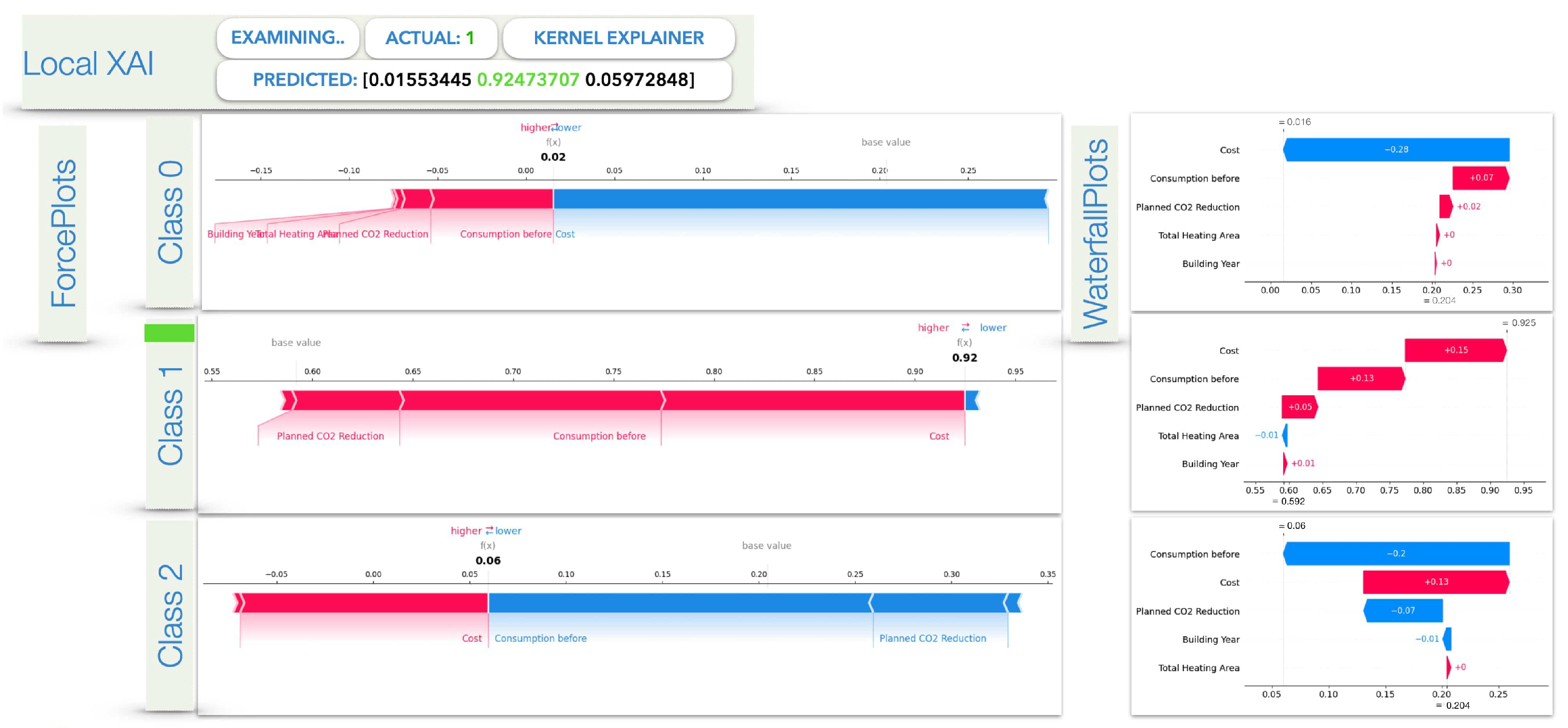
In
Figure 14, selected graphs show how the different features contribute to each decision for a specific observation from the analyzed dataset. We have used Shapley values to determine the different outcomes and the SHAP Python libraries to create an explainability framework for the examined case [
62]. According to the observation analyzed, the true actual value refers to Class B or Class 1. The predicted array, titled as predicted in
Figure 14, shows the probabilities for each class as they are extracted by the stacked model. For Class 0, the probabilities are equal to 0.16 (0.0155), while for Class 1 they are equal to 0.924 and for Class 2 they are equal to 0.06 (0.0597). Our model has correctly predicted the class as 1.
To see how the different features contributed to the prediction, we have used SHAP force and waterfall plots. In the force plot, the different interactions between the features and the decision per class is outlined, arriving at the predicted solution probability of outcome, symbolized as f(x). On the other hand, the waterfall plots similarly show the different responses of each parameter. At the bottom of the graph, the expected output is shown, while the top of the graph indicates how the different features contributed to the actual prediction extracted by the model. Since Class 1 was indeed the correct output, in both graphs, all features in Class 1 point to the right result and the proposed investment should be only partially funded.
7.4. Global XAI
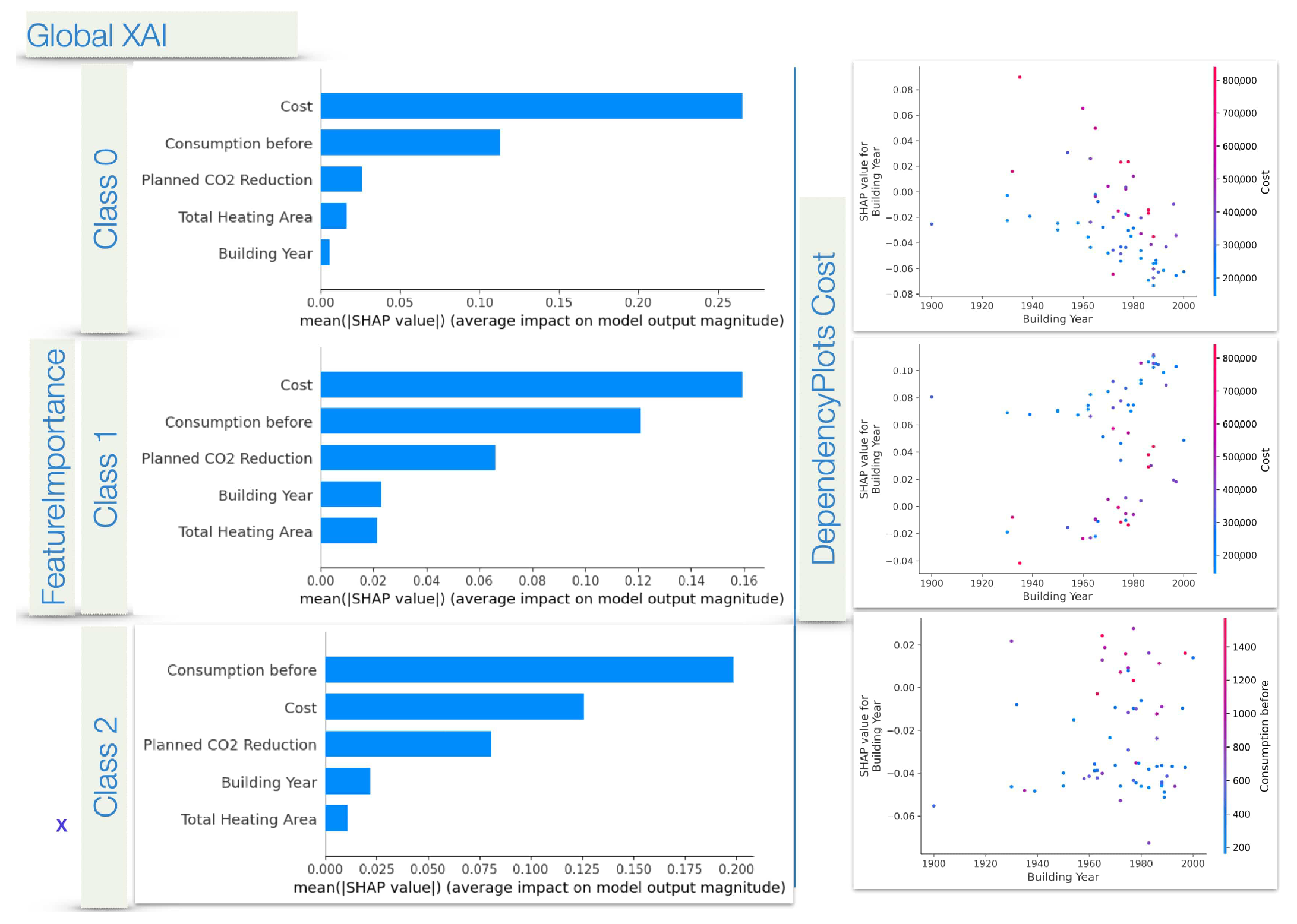
In
Figure 15, selected graphs show how the different features contribute to the final prediction for each class. Again, Shapley values have been utilized, alongside the SHAP Python libraries for explaining the results visually. Feature importance is first analyzed for each class for all inputs. Cost is the highest contributing factor in all cases, but the contribution of other factors varies for the different classes.
The dependency plots are then utilized to summarize the dependence between the actual cost and the actual contribution of the cost to the decision eventually made by the model, labeled as SHAP value for cost on the y-axis of each scatter graph. The SHAP value for the examined variable shows the extent to which knowing this particular variable affects the prediction of the model. On the opposite side of the y-axis, a feature that is closely related to the examined variable is tracked and the extent of the effect to the examined variable is differentiated by color.
7.5. User Interactions and Provide Outcomes
For the global and local XAI, where, in the provided examples, Shapley values were extracted, Algorithms A4 and A5 were utilized (see
Appendix A). Via an interactive environment and depending on the personalization options, the user can choose any datapoint used in the training process of the neural networks (NNs) utilized for the analytical services. Datapoints are embedded objects of the NNs and thus can be called upon and examined. Examples of this process were provided in the previous subsections. For each datapoint, an explanation is always returned and errors logged during the testing are not associated with missing datapoints or the inability of the system to compute.
8. Summary, Conclusions, and Future Work
In conclusion, this paper proposes a novel methodology for designing a tailored explainability solution for AI analytics services in the energy management sector. The methodology is based on multiple processes that take into account the specific needs and preferences of stakeholders, as well as established frameworks such as the TAM and HCI principles. The methodology is comprehensive and involves identifying key stakeholders and AI analytics services, creating a tailored explainability requirements questionnaire, conducting a survey among energy management stakeholders, performing a user-based clustering analysis to determine the required depth of explainability, and implementing the tailored XAI solution at both the local and global levels. The contribution of this methodology lies in its ability to develop an effective solution that meets the diverse needs of stakeholders in the energy management sector. The methodology is tested on a stacked neural network for the AS04 analytic service, which estimates energy savings from renovations, and aims to increase adoption rates and benefit the circular economy. The significance of AI explainability is emphasized as an ethical approach and a tool to build user trust and ensure faster adoption rates, especially in the energy sector, where AI can provide a more sustainable future.
In summary, the contributions of this research are the following: firstly, the agile development of an IDSS considers XAI as a main feature and ensures that it is tailored to specific user needs. Secondly, to facilitate that personalization, TAM was used to cluster stakeholders based on the perception of usefulness and ease of use. Perception of usefulness was associated with AI literacy and perceived ease of use with usability. These different perceptions require different explanation approaches to ensure greater and faster adoption rates and, for that, XAI tools were grouped accordingly. The limitation to be addressed in our future work is the evaluation of our methodology with real-life data as per adoption, user satisfaction, and an increase in application utilization. Future work can also extend the methodology to other AI applications in the energy sector and other industries, evaluate it on various metrics such as efficiency, effectiveness, scalability, and interpretability, provide more in-depth explanations to users, and examine the impact of explainability on the adoption rate of AI systems in other industries. This can help build more responsible and safe spaces for the deployment of AI systems.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












