1. Introduction
Deep learning models and computer vision are commonly integrated for e-health self-help diagnosis [
1]. As a routine physical examination, abnormal colors and traits of feces typically can help with predicting and evaluating the potential and possible risks of digestive diseases [
2] as well as other diseases such as the assessment and prediction of COVID-19 [
3], chronic diarrhea [
4], and colorectal cancer [
5]. Therefore, accurate, quantitative, automatic, fast and efficient medically assisted examination and diagnosis can definitely help patients to seek medical treatment in a timely manner and reduce the risk of disease deterioration and infection.
Computer-assisted methods for feces diagnosis have three remarkable advantages. First, the examiners do not have to touch feces samples, meaning that the risks of infection and workload are reduced. Second, they can provide reliable results, efficient classification, quantitative analysis, and rapid feedback. Third, computers can work continuously with high intensity.
Feces examination includes macroscopic examination and microscopic examination. While microscopic examination is accurate, it is time-consuming and expensive due to the requirement for professional inspectors and sophisticated instruments. In contrast, macroscopic examination, as a preliminary diagnosis manner in clinical practice, has the advantages of rapid examination and fewer requirements. Therefore, efficient and reliable automatic macroscopic inspection is indispensable [
6].
However, there is currently a lack of e-health self-help diagnosis based on feces medical images. Therefore, this paper develops an accurate, quantitative, automatic, fast, and efficient e-health self-help diagnosis system for feces macroscopic images based on computer vision and pattern recognition. Two attributes of feces, namely, color and trait, are recognized and analyzed by a Convolution Neural Network (CNN) [
7,
8,
9].
Considering the requirements of different application scenarios and different tasks, this paper defines three task types, as shown in
Table 1. There are two different classification criteria for the color classification task. Yellow and brown can be considered as healthy feces colors, and as such are merged into one color category.
In clinical assessment, red and black are regarded as abnormal feces colors. The classification task with four color categories is designed for carrying out pathological analysis in cases where more detailed analysis is a requirement. However, the classification task with three color categories is sufficient for ordinary self-help users, who pay more attention to whether their feces color is healthy or abnormal. For trait classification, liquid and watery samples are regarded as abnormal samples. Samples with different colors and traits are shown in
Figure 1.
In medical scenes, feces samples are collected with special instruments, and the acquisition conditions, including the background and illumination, are fixed. However, in real scenes users capture macroscopic images of the feces by themselves, meaning that the acquisition conditions are not strictly controllable and that the related challenges may degrade the accuracy of diagnosis.
The traditional methods for feces diagnosis are unable to meet the growing demand for rapid automatic diagnosis and for effective epidemic prevention and control. Due to the lack of samples, it is difficult to directly use the existing classification models for feces diagnosis. Therefore, the main contributions and novelty of this paper are summarized as follows. 1. Semi-supervised training is employed, which is suitable and efficient for a small number of samples. 2. As the feces area is too small in certain samples, an adaptive upsampling method is proposed to enlarge the effective area of feces. 3. A real-scene dataset is synthesized to alleviate problems related to the small amount of data, then a diagnosis framework is proposed for real scenes.
The rest of this paper is organized as follows.
Section 2 reviews related works.
Section 3 specifies the methodology.
Section 4 describes our experiments and discusses the results. Finally, our conclusions and the possibilities for future work are provided in
Section 5.
3. Proposed Method
A CAD self-help feces diagnosis approach is proposed in this paper, which consists of three main works, including self-supervised learning (SSL), adaptive up-sampling (AUS), and synthesis of feces image in real scenes. These three main contributions are specified in this section. A three-layer lightweight CNN is utilized as the benchmark structure [
18].
3.1. Semi-Supervised Learning (SSL)
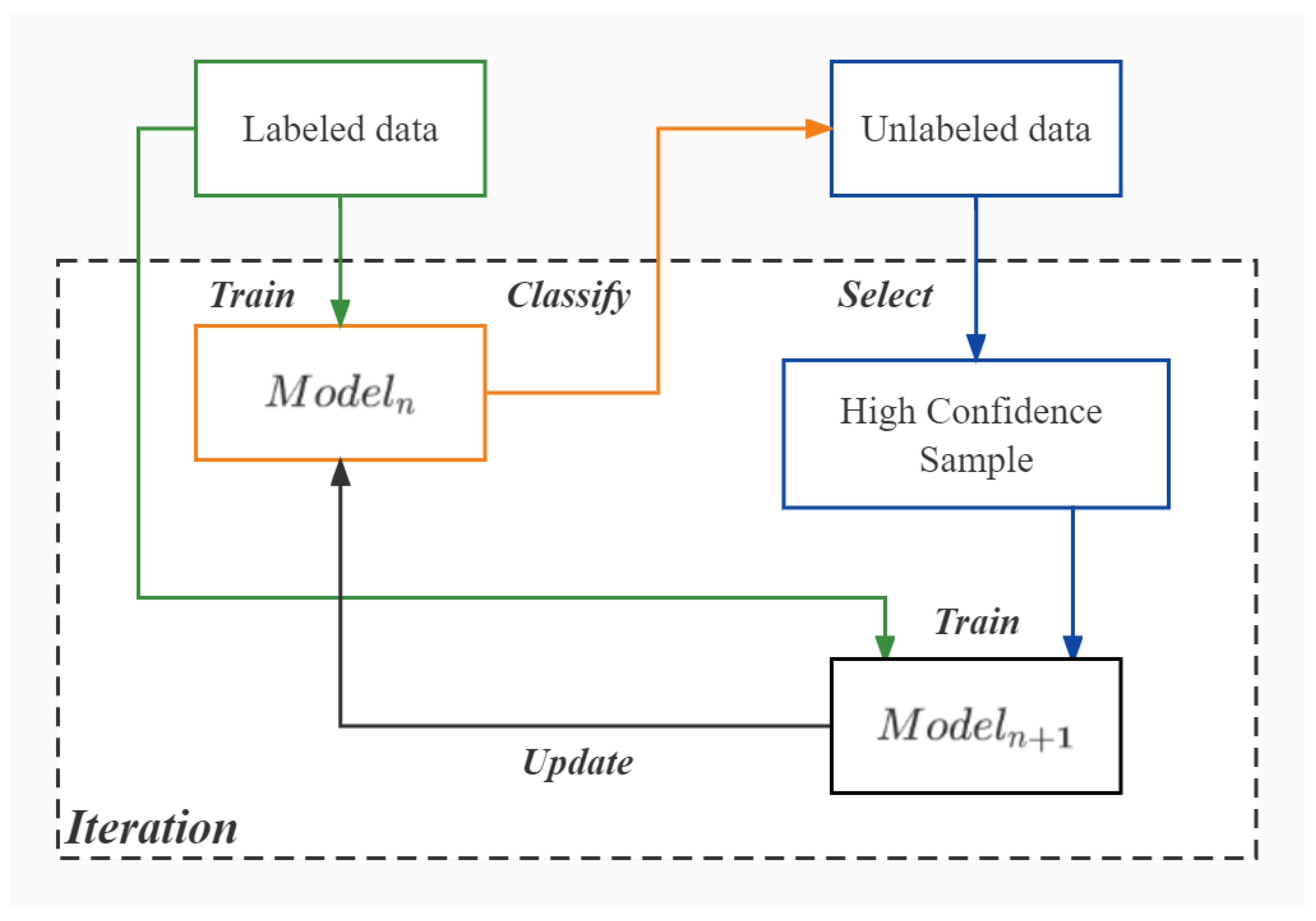
It is hard to collect enough labeled data; therefore, SSL is leveraged, as shown in
Figure 2. High-confidence samples refer to those samples with high logical regression values. There are two relevant parameters, namely, the degree of deviation from expectation
and standard deviation
:
where
is the standard deviation of logits without the corresponding max value and
N is the number of samples, which is the average logits of the samples:
where
, which is a set, and
refers to the probability that
x is classified to the ‘-
’ class where
is the number of classes.
If , then the classification result of this sample can be adopted as a pseudo-label because the model can clearly distinguish this sample; otherwise, the classification result is discarded because the model is not confident about the category to which the sample belongs.
3.2. Adaptive Up-Sampling (AUS)
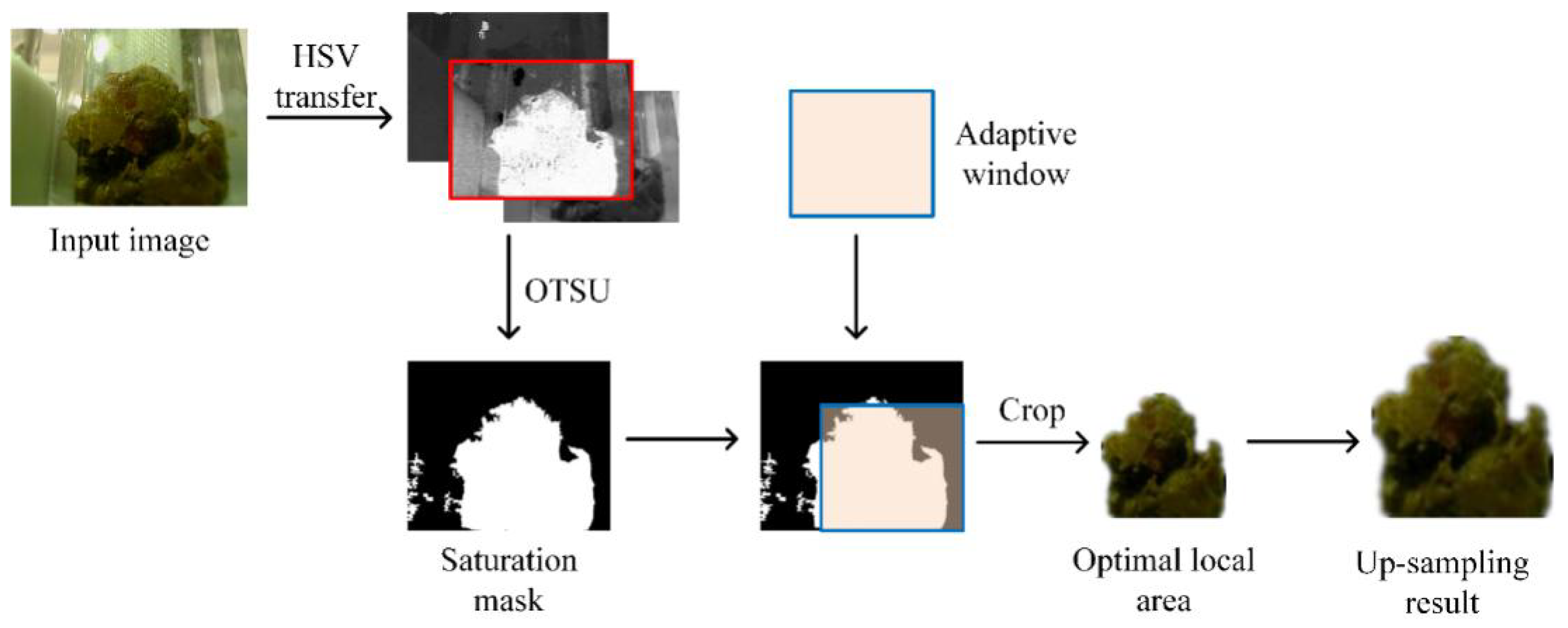
In the image collection of feces samples, the sizes of the region of interest (ROI), i.e., the feces region, are different. Sometimes the ROI is too small, as shown in
Figure 3, which leads to insufficient information and degraded accuracy.
AUS is proposed to adaptively enlarge small ROIs. The three steps are to localize the small ROI, appropriately scale it according to the result of image segmentation, and zoom in the small ROI. The procedure of AUS is shown in
Figure 4.
Step 1: OTSU segmentation is conducted on the saturation channel to segment the ROI [
14]. In each image, the number of foreground pixels is denoted by
, while in a sliding window the proportion of foreground pixels is denoted by
.
Step 2: The percentage of foreground pixels is calculated in all size-adaptive windows, where the sizes are , and the maximum proportion among them is selected.
Step 3: T is used as a threshold to adaptively crop the sample. If , the corresponding sliding windows are upsampled. If , then replace with P and repeat Step 2 until is satisfied.
AUS ensures that all the images have large ROI. To determine the optimal ratio, the accuracies of samples with different foreground ratios are compared in
Table 2. The color and trait networks reach their best results on the training data at foreground ratios of 70–80% and 60–70%, respectively.Therefore, in this paper the threshold for the experiments to determine colors and traits was set as 70–80%.
It can be seen that a very small ROI carries insufficient information, while too large an ROI does not lead to the best effect. For color classification, the color in the ROI may be disturbed by multiple colors. For trait classification, boundary information and texture information are both important, and too large an ROI may contain useless boundary information.
3.3. Synthesized Dataset
A real-scene dataset was synthesized to confirm that the proposed method is effective for use in daily life. Compared with the medical scenes, the backgrounds, illuminations, and morphology are much more complex in a real scene, which can pose severe challenges.
Splicing synthesis was used to generate the synthesized real-scene feces images. This approach preserves the color and texture features of the ROI. The synthesized dataset can be rotated at different angles in order to further expand it. The synthesized real-scene feces images should meet the following requirements: 1. diversity, such as different backgrounds, illuminations, etc; 2. the feces regions should be large enough; and 3. naturalness, that is, the synthesized images should be similar to those collected from real scenes.
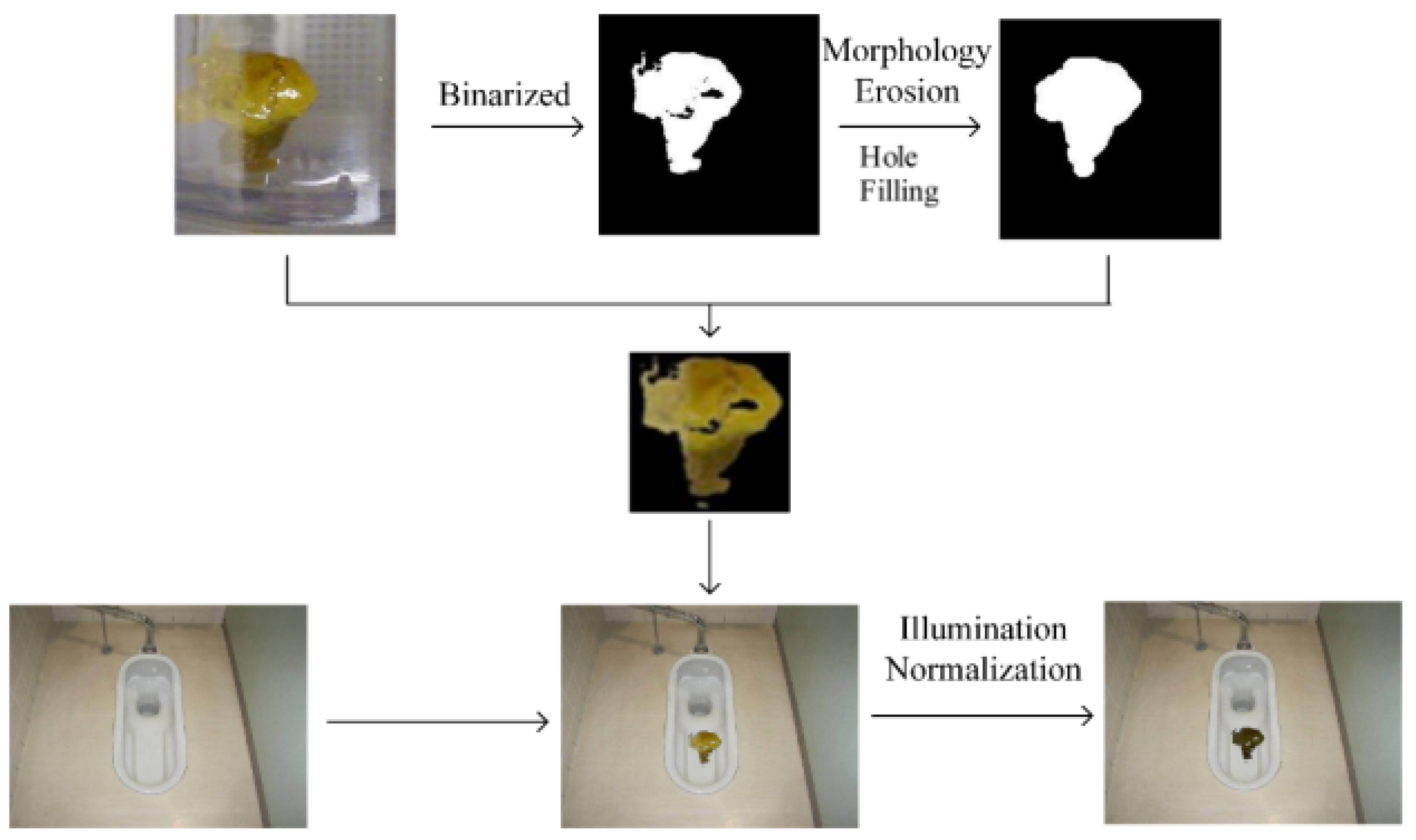
The synthesis procedure is shown in
Figure 5. The binary mask labels the locations of the feces pixels (foreground pixels) that are stitched with a real-scene toilet image. The synthesized real-scene feces images have good naturalness. Because OTSU commonly produces a larger feces region, which leads to dark boundaries in the synthesized images, morphological corrosion is used to suppress the dark boundaries.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}