
Procedural- and Reinforcement-Learning-Based Automation Methods for Analog Integrated Circuit Sizing in the Electrical Design Space
 , , , and
, , , and
Abstract
:1. Introduction
1.1. Current State of Analog IC Sizing Automation
1.2. Procedural Analog IC Sizing
1.3. Machine Learning for EDA
1.4. Reinforcement Learning for EDA
1.5. Structure
2. Function Mappings for Circuit Sizing
3. Data Sampling and Training
4. Procedural Design Example
5. Reinforcement Learning Methodology
5.1. Motivation
5.2. Overview
5.3. Environment
5.3.1. States
5.3.2. Actions
5.3.3. Rewards
5.3.4. Goals
5.4. Agents
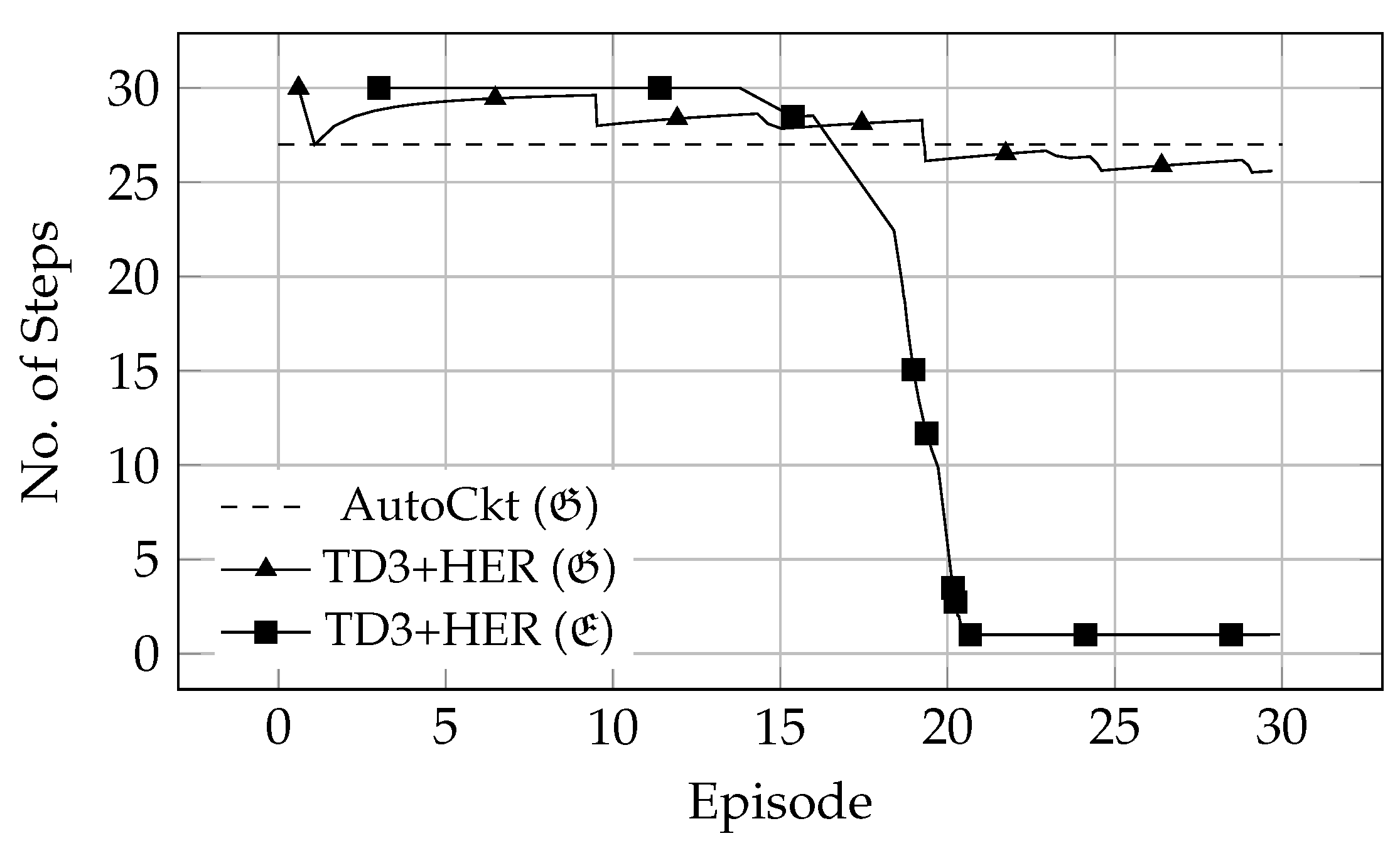
6. Experimental Results
Technology Migration
7. Conclusions
7.1. Knowledge-Based Circuit Sizing
7.2. Learning-Based Circuit Sizing
7.3. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACiD | artificial circuit designer |
| BMBF | German Federal Ministry of Education and Research |
| BO | Bayesian optimization |
| CAN | circuit attention network |
| CNN | convolutional neural network |
| DDPG | deep deterministic policy gradient |
| DL | deep learning |
| DRL | deep reinforcement learning |
| EDA | electronic design automation |
| ES | evolutionary strategy |
| FOM | figure of merit |
| GNN | graph neural network |
| GCN | graph convolutional network |
| HER | hindsight experience replay |
| IC | integrated circuit |
| LUT | look-up table |
| MAE | mean absolute error |
| MDP | Markov decision process |
| ML | machine learning |
| MLP | multilayer perceptron |
| MSE | mean-squared error |
| NN | neural network |
| PDK | process design kit |
| PPO | proximal policy optimization |
| ReLU | rectified linear unit |
| RL | reinforcement learning |
| TD3 | twin delayed deep deterministic policy gradient |
| A0 | DC loop gain |
| Ae | estimated area |
| CMRR | common mode rejection ratio |
| GM | gain margin |
| IDD | current consumption |
| PM | phase margin |
| PSRR | power supply rejection ratio |
| SR | slew rate |
| UGBW | unity gain bandwidth |
| Voff(1σ) | statistical offset |
| SYM | symmetrical amplifier |
| MIL | Miller operational amplifier |
| FCA | folded cascode amplifier |
Appendix A. Circuits


Appendix B. Hyperparameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Optimizer | Adam [52] |
| Learning Rate | |
| Number of Hidden Layers | 7 |
| Number of Hidden Units per Layer | |
| Non-Linearity of Hidden Layers | ReLU [51] |
| Batch Size | 128 |
| Number of Epochs | 24 |
| Parameter | Value |
|---|---|
| Optimizer | Adam [52] |
| Actor Learning Rate | |
| Critic Learning Rate | |
| Discount Factor () | |
| Number of Hidden Layers | 2 |
| Number of Hidden Units per Layer | 256 |
| Non-Linearity of Hidden Layers | ReLU [51] |
| Number of Update Steps (E) | 40 |
| Target Update Interval (d) | 2 |
| Random Exploration Interval | 10 |
| Test Interval | 5 |
| Parallel Environments (P) | 32 |
| Target Smoothing Coefficient () | |
| Noise Clipping (c) | |
| Exploration Policy | |
| Number of Steps per Episode | 30 |
| Buffer Size | |
| Batch Size | 128 |
| Goal Sampling Strategy () | future [41] |
| Number of Additional Goals (k) | 4 |
Appendix C. Reinforcement Learning Algorithm
| Algorithm A1 Artificial circuit designer (ACiD) |
|
References
- Degrauwe, M.G.R.; Nys, O.; Dijkstra, E.; Rijmenants, J.; Bitz, S.; Goffart, B.L.A.G.; Vittoz, E.A.; Cserveny, S.; Meixenberger, C.; van der Stappen, G.; et al. IDAC: An interactive design tool for analog CMOS circuits. IEEE J. Solid-State Circuits 1987, 22, 1106–1116. [Google Scholar] [CrossRef]
- Nye, W.; Riley, D.C.; Sangiovanni-Vincentelli, A.; Tits, A.L. DELIGHT.SPICE: An optimization-based system for the design of integrated circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1988, 7, 501–519. [Google Scholar] [CrossRef]
- Antreich, K.; Koblitz, R. Design centering by yield prediction. IEEE Trans. Circuits Syst. 1982, 29, 88–96. [Google Scholar] [CrossRef]
- Scheible, J.; Lienig, J. Automation of Analog IC Layout: Challenges and Solutions. In Proceedings of the 2015 Symposium on International Symposium on Physical Design, ISPD ’15; Association for Computing Machinery: New York, NY, USA, 2015; pp. 33–40. [Google Scholar] [CrossRef] [Green Version]
- Lyu, W.; Xue, P.; Yang, F.; Yan, C.; Hong, Z.; Zeng, X.; Zhou, D. An Efficient Bayesian Optimization Approach for Automated Optimization of Analog Circuits. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 1954–1967. [Google Scholar] [CrossRef]
- Castejon, F.; Carmona, E.J. Introducing Modularity and Homology in Grammatical Evolution to Address the Analog Electronic Circuit Design Problem. IEEE Access 2020, 8, 137275–137292. [Google Scholar] [CrossRef]
- Scheible, J. Optimized is Not Always Optimal. In Proceedings of the 2022 Symposium on International Symposium on Physical Design, ISPD ’22; Association for Computing Machinery: New York, NY, USA, 2022; pp. 151–158. [Google Scholar] [CrossRef]
- Schweikardt, M.; Scheible, J. Expert Design Plan: A Toolbox for Procedural Analog Integrated Circuit Design. In Proceedings of the SMACD/PRIME 2022, International Conference on SMACD and 17th Conference on PRIME, Villasimius, Italy, 12–15 June 2022; pp. 1–4. [Google Scholar]
- Jespers, P.G.A.; Murmann, B. Systematic Design of Analog CMOS Circuits: Using Pre-Computed Lookup Tables; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar] [CrossRef]
- Silveira, F.; Flandre, D.; Jespers, P.G.A. A gm/ID based methodology for the design of CMOS analog circuits and its application to the synthesis of a silicon-on-insulator micropower OTA. IEEE J. Solid-State Circuits 1996, 31, 1314–1319. [Google Scholar] [CrossRef]
- Ochotta, E.S.; Rutenbar, R.A.; Carley, L.R. Synthesis of high-performance analog circuits in ASTRX/OBLX. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1996, 15, 273–294. [Google Scholar] [CrossRef]
- Marolt, D.; Scheible, G.J. A practical layout module pcell concept for analog IC design. In Proceedings of the CDNLive EMEA 2013, Munich, Germany, 12–13 March 2013. [Google Scholar]
- Graeb, H.; Zizala, S.; Eckmueller, J.; Antreich, K. The sizing rules method for analog integrated circuit design. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design, ICCAD 2001, IEEE/ACM Digest of Technical Papers (Cat. No.01CH37281), San Jose, CA, USA, 4–8 November 2001; pp. 343–349. [Google Scholar]
- Massier, T.; Graeb, H.; Schlichtmann, U. The Sizing Rules Method for CMOS and Bipolar Analog Integrated Circuit Synthesis. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2008, 27, 2209–2222. [Google Scholar] [CrossRef]
- Schweikardt, M.; Uhlmann, Y.; Leber, F.; Scheible, J.; Habal, H. A Generic Procedural Generator for Sizing of Analog Integrated Circuits. In Proceedings of the 2019 15th Conference on Ph.D Research in Microelectronics and Electronics (PRIME), Lausanne, Switzerland, 15–18 July 2019; pp. 17–20. [Google Scholar]
- Zhao, Z.; Zhang, L. Deep Reinforcement Learning for Analog Circuit Sizing. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Mina, R.; Jabbour, C.; Sakr, G.E. A Review of Machine Learning Techniques in Analog Integrated Circuit Design Automation. Electronics 2022, 11, 435. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. Technical Report, 2017, [1706.05587]. Available online: http://xxx.lanl.gov/abs/1706.05587 (accessed on 22 December 2022).
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. Technical report, 2018, [1804.06208]. Available online: http://xxx.lanl.gov/abs/1804.06208 (accessed on 22 December 2022).
- Habal, H.; Tsonev, D.; Schweikardt, M. Compact Models for Initial MOSFET Sizing Based on Higher-order Artificial Neural Networks. In Proceedings of the 2020 ACM/IEEE 2nd Workshop on Machine Learning for CAD (MLCAD), Reykjavik, Iceland, 16–20 November 2020; pp. 111–116. [Google Scholar] [CrossRef]
- Xu, J.; Root, D.E. Artificial neural networks for compound semiconductor device modeling and characterization. In Proceedings of the 2017 IEEE Compound Semiconductor Integrated Circuit Symposium (CSICS), Miami, FL, USA, 22–25 October 2017; pp. 1–4. [Google Scholar]
- Xu, J.; Root, D.E. Advances in artificial neural network models of active devices. In Proceedings of the 2015 IEEE MTT-S International Conference on Numerical Electromagnetic and Multiphysics Modeling and Optimization (NEMO), Ottawa, ON, Canada, 11–14 August 2015; pp. 1–3. [Google Scholar]
- Baker, M.R.; Patil, R.B. Universal Approximation Theorem for Interval Neural Networks. Reliab. Comput. 1998, 4, 235–239. [Google Scholar] [CrossRef]
- Kahraman, N.; Yildirim, T. Technology independent circuit sizing for fundamental analog circuits using artificial neural networks. In Proceedings of the 2008 Ph.D. Research in Microelectronics and Electronics, Istanbul, Turkey, 22 June–25 April 2008. [Google Scholar] [CrossRef]
- Mendhurwar, K.; Sundani, H.; Aggarwal, P.; Raut, R.; Devabhaktuni, V. A new approach to sizing analog CMOS building blocks using pre-compiled neural network models. Analog. Integr. Circuits Signal Process. 2012, 70, 265–281. [Google Scholar] [CrossRef]
- Islamoglu, G.; Cakici, T.O.; Afacan, E.; Dundar, G. Artificial Neural Network Assisted Analog IC Sizing Tool. In Proceedings of the 2019 16th International Conference on Synthesis, Modeling, Analysis and Simulation Methods and Applications to Circuit Design (SMACD), Lausanne, Switzerland, 15–18 July 2019. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning 2013. [arXiv:cs.LG/1312.5602]. Available online: http://xxx.lanl.gov/abs/1312.5602 (accessed on 22 December 2022).
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Amini, A.; Gilitschenski, I.; Phillips, J.; Moseyko, J.; Banerjee, R.; Karaman, S.; Rus, D. Learning robust control policies for end-to-end autonomous driving from data-driven simulation. IEEE Robot. Autom. Lett. 2020, 5, 1143–1150. [Google Scholar] [CrossRef]
- Abbeel, P.; Coates, A.; Quigley, M.; Ng, A. An application of reinforcement learning to aerobatic helicopter flight. Adv. Neural Inf. Process. Syst. 2006, 19, 1–8. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Settaluri, K.; Haj-Ali, A.; Huang, Q.; Hakhamaneshi, K.; Nikolic, B. AutoCkt: Deep Reinforcement Learning of Analog Circuit Designs, 2020. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Wang, H.; Wang, K.; Yang, J.; Shen, L.; Sun, N.; Lee, H.S.; Han, S. GCN-RL Circuit Designer: Transferable Transistor Sizing with Graph Neural Networks and Reinforcement Learning, 2020. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016; Bengio, Y., LeCun, Y., Eds.; Microtome Publishing: Brookline, MA, USA, 2016. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 278–287. [Google Scholar]
- Li, Y.; Lin, Y.; Madhusudan, M.; Sharma, A.; Sapatnekar, S.; Harjani, R.; Hu, J. A Circuit Attention Network-Based Actor-Critic Learning Approach to Robust Analog Transistor Sizing. In Proceedings of the 2021 ACM/IEEE 3rd Workshop on Machine Learning for CAD (MLCAD), Raleigh, NC, USA, 30 August–3 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. Technical Report. 2018. Available online: http://xxx.lanl.gov/abs/1802.09477 (accessed on 22 December 2022).
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight Experience Replay. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Schweikardt, M.; Scheible, J. Improvement of Simulation-Based Analog Circuit Sizing using Design-Space Transformation. In Proceedings of the SMACD/PRIME 2021, International Conference on SMACD and 16th Conference on PRIME, Online, 19–22 July 2021; pp. 1–4. [Google Scholar]
- Youssef, A.A.; Murmann, B.; Omran, H. Analog IC Design Using Precomputed Lookup Tables: Challenges and Solutions. IEEE Access 2020, 8, 134640–134652. [Google Scholar] [CrossRef]
- Uhlmann, Y.; Essich, M.; Schweikardt, M.; Scheible, J.; Curio, C. Machine Learning Based Procedural Circuit Sizing and DC Operating Point Prediction. In Proceedings of the SMACD/PRIME 2021, International Conference on SMACD and 16th Conference on PRIME, Online, 19–22 July 2021; pp. 1–4. [Google Scholar]
- Uhlmann, Y.; Essich, M.; Bramlage, L.; Scheible, J.; Curio, C. Deep Reinforcement Learning for Analog Circuit Sizing with an Electrical Design Space and Sparse Rewards. In Proceedings of the 2022 ACM/IEEE Workshop on Machine Learning for CAD, MLCAD ’22; Association for Computing Machinery: New York, NY, USA, 2022; pp. 21–26. [Google Scholar] [CrossRef]
- Liu, W.; Jin, X.; Chen, J.; Jeng, M.C.; Liu, Z.; Cheng, Y.; Chen, K.; Chan, M.; Hui, K.; Huang, J.; et al. BSIM 3v3.2 MOSFET Model Users’ Manual; Technical Report UCB/ERL M98/51; EECS Department, University of California: Berkeley, CA, USA, 1998. [Google Scholar]
- Liu, W.; Cao, K.; Jin, X.; Hu, C. BSIM 4.0.0 Technical Notes; Technical Report UCB/ERL M00/39; EECS Department, University of California: Berkeley, CA, USA, 2000. [Google Scholar]
- Iskander, R.; Louërat, M.M.; Kaiser, A. Automatic DC operating point computation and design plan generation for analog IPs. In Proceedings of the Analog Integrated Circuits and Signal Processing—Volume 56; Springer US: Boston, MA, USA, 2008; pp. 717–740. [Google Scholar] [CrossRef]
- Efraimidis, P.; Spirakis, P. Weighted Random Sampling. In Encyclopedia of Algorithms; Kao, M.Y., Ed.; Springer US: Boston, MA, USA, 2008; pp. 1024–1027. [Google Scholar] [CrossRef]
- Box, G.E.P.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. (Methodol.) 1964, 211–243. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics; Proceedings of Machine Learning Research. Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization; Conference Track Proceedings, 2015. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Head, T.; Kumar, M.; Nahrstaedt, H.; Louppe, G.; Shcherbatyi, I. Scikit-Optimize. 2021. Available online: https://scikit-optimize.github.io/stable/ (accessed on 22 December 2022).
- Reynolds, J.C. Definitional Interpreters for Higher-Order Programming Languages. In Proceedings of the ACM Annual Conference—Volume 2, ACM ’72; Association for Computing Machinery: New York, NY, USA, 1972; pp. 717–740. [Google Scholar] [CrossRef]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal Value Function Approximators. In Proceedings of the 32nd International Conference on Machine Learning; Proceedings of Machine Learning Research; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 1312–1320. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Cadence Design Systems, Inc.Spectre Simulation Platform. Technical Report. 2020. Available online: https://www.cadence.com/content/dam/cadence-www/global/en_US/documents/tools/custom-ic-analog-rf-design/spectre-simulation-platform-ds.pdf (accessed on 22 December 2022).
- Huang, A.; Hashimoto, J.; Stites, S.; Scholak, T. HaskTorch. 2017. Available online: http://hasktorch.org/ (accessed on 22 December 2022).
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on Machine Learning; Proceedings of Machine Learning Research; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 387–395. [Google Scholar]





| Parameter | VDD | Vin,cm | Vout,cm | IB0 | CL |
| Specification | 3.30 V | 1.65 V | 1.65 V | 3.00 μA | 10.00 pF |
| Parameter | Unit | Target | Result |
|---|---|---|---|
| DC loop gain () | dB | >60.00 | 60.70 |
| unity gain bandwidth (UGBW) | MHz | > 7.50 | 7.80 |
| common mode rejection ratio (CMRR) | dB | >100.00 | 118.47 |
| power supply rejection ratio (PSRR) | dB | >80.00 | 80.61 |
| Slew Rate (SR) | V/μs | >4.00 | 4.52 |
| phase margin (PM) | ° | >80.00 | 80.03 |
| statistical offset () | mV | <5.00 | 4.71 |
| Environment | 350 nm (Trained) | 180 nm (Evaluated) | ||||
|---|---|---|---|---|---|---|
| First | First | Success | Success | |||
| SYM () | 100.00% | 82.29% | ||||
| MIL () | 97.92% | 75.00% | ||||
| FCA () | 100.00% | 100.00% | ||||
| Parameter | Unit | g | 350 nm | 180 nm | ||
|---|---|---|---|---|---|---|
| s0 | st | s0 | st | |||
| dB | ≥75.0 | |||||
| UGBW | ≥2.5 | N/A | N/A | |||
| SR | / | ≥500 | N/A | N/A | ||
| PM | ≥80.0 | 0 | 0 | |||
| CMRR | dB | ≥120.0 | ||||
| PSRR | dB | ≥100.0 | ||||
| ≤1.5 | ||||||
| ≤25.0 | ||||||
| 2 | ≤6.0 | |||||
| t | – | <30 | 0 | 2 | 0 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uhlmann, Y.; Brunner, M.; Bramlage, L.; Scheible, J.; Curio, C. Procedural- and Reinforcement-Learning-Based Automation Methods for Analog Integrated Circuit Sizing in the Electrical Design Space. Electronics 2023, 12, 302. https://doi.org/10.3390/electronics12020302
Uhlmann Y, Brunner M, Bramlage L, Scheible J, Curio C. Procedural- and Reinforcement-Learning-Based Automation Methods for Analog Integrated Circuit Sizing in the Electrical Design Space. Electronics. 2023; 12(2):302. https://doi.org/10.3390/electronics12020302
Chicago/Turabian StyleUhlmann, Yannick, Michael Brunner, Lennart Bramlage, Jürgen Scheible, and Cristóbal Curio. 2023. "Procedural- and Reinforcement-Learning-Based Automation Methods for Analog Integrated Circuit Sizing in the Electrical Design Space" Electronics 12, no. 2: 302. https://doi.org/10.3390/electronics12020302