1. Introduction
Frames, shots, and scenes are different entities or units that constitute a movie. A frame is a still image, the basic unit of a movie; a shot consists of a series of frames displaying related action or plot; and a scene is a collection of consecutive shots at the same time or place used to show a coherent movie story line.
Generally, in movie analysis [
1], shot segmentation algorithms [
2,
3] are used to divide movies into thousands of distinct shots to facilitate understanding at the shot level. Unlike action recognition [
4,
5,
6], shot attribute analysis focuses more on common attributes of all shots, such as
scale,
movement, and
angle, which we refer to as the
intrinsic attributes of movie shots.
By extracting and comprehending intrinsic shot attributes, we can semantically index and search movie archives based on cinematographic characteristics. This also facilitates high-level analysis of film styles by identifying patterns in the use of scale, movement, and angle throughout a film. Furthermore, automatic shot attribute analysis can potentially enable AI-assisted editing and intelligent cinematography tools that provide suggestions based on learned film shot patterns and conventions.
In previous shot attribute analysis methods, as shown in
Figure 1, each shot attribute is often treated as an independent classification task, such as
shot movement classification [
7] and
shot scale classification [
8]. These methods utilize task-specific network architectures tailored for predicting each property. Consequently, they are applicable to single-property prediction and cannot be easily generalized to other properties.
Moreover, prior research [
9] has shown that action cues are critical features of shot attribute analysis; thus, most methods [
1,
7,
10,
11] employ pre-trained optical flow networks to extract video optical flow map. However, since the training datasets of optical flow networks [
12,
13,
14,
15] are mostly generated in virtual environments, distortions may occur when extracting optical flow from real movie shots, and the end-to-end training process cannot be achieved using additional optical flow networks.
The above analysis identifies some of the problems in the shot attribute analysis task and points to our main research motivation: how to design a unified architecture for multiple shot attribute analysis, and how to capture the motion cues of a shot without relying on optical flow networks while achieving an end-to-end training process.
Inspired by [
6,
16], we introduce a learnable frame difference generator to replace the pre-trained optical flow network, i.e., using frame difference maps as motion cues, and successfully enable the architecture for end-to-end training. However, certain shot attributes like shot scale are less sensitive to motion cues; thus, overly relying on motion cues when analyzing these attributes may affect the performance [
1]. Therefore, inspired by the dual-stream networks, we balance motion and static features and design a motion and static branch to independently analyze motion cues and static frames, and further quantify the weights of the motion and static feature in the fusion module. Then, given the effectiveness of transformers in computer vision tasks [
17,
18], we attempt to replace traditional convolutional neural networks with them. However, since transformers require a large amount of training data, and the sample size of movie shot datasets [
19,
20,
21,
22] is usually less than 30 K, we introduce transformer models pre-trained by Kinetics 400 [
23], and design a fixed-size adjustment strategy for the motion branch and a keyframe selection strategy for the static branch to adapt to fit the input size; meanwhile, this design also allows our architecture to accommodate shot data inputs at any video sample rate.
We validate our proposed method on two large movie shot datasets, MovieShots [
1] and AVE [
24], and compare the performance with all previous methods. Given the sample imbalance problems of movie shot datasets, we employ Macro-F1 for evaluation in addition to the regular Top-1 accuracy. The results show that our model performs significantly better than other methods while maintaining computational efficiency.
Our contributions are as follows:
1. We summarize the main issues in the task of shot attribute analysis. Building upon these, we propose a unified dual-branch end-to-end architecture capable of analyzing all movie shot attributes, and further quantify the motion/static feature weights of different attributes.
2. We design a learnable frame difference generator to replace the pre-trained optical flow network, and through specific strategies make the network compatible with vision transformer pre-trained models, effectively solving the problem of lacking samples in the movie shot dataset.
3. Experiments on MovieShots and AVE prove that our shot attribute analysis architecture significantly outperforms all previous methods in various shot intrinsic attributes, and exhibits notable advantages in computational efficiency.
3. Approach
In this section, we present a unified end-to-end training architecture suitable for various shot attribute tasks. Despite prior attempts to employ a unified architecture for analyzing multiple shot attributes, adjustments have been made in the structural design to cater to distinct classification tasks (e.g., Var Block in SGNet [
1]). In our architecture, as shown in
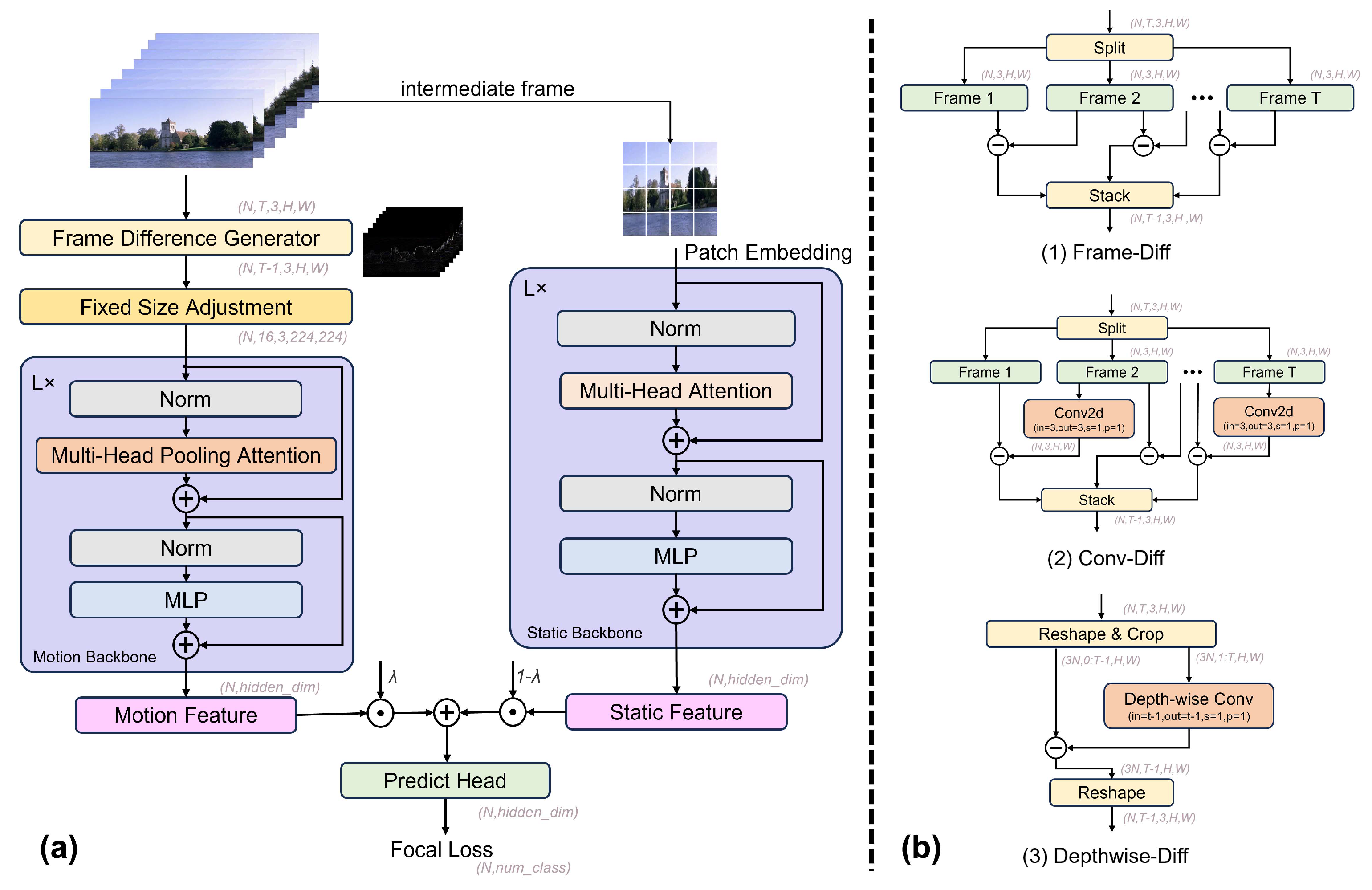
Figure 2a, we conceptualize the analysis tasks as a balance between motion and static aspects, leading to the design of corresponding feature extraction backbones.
In the following four subsections, we first define the lens attribute analysis task with a formula specification in
Section 3.1. Subsequently, we elaborate on the design of the motion and static branches in
Section 3.2 and
Section 3.3. In
Section 3.4, a quantifiable strategy for fusing motion and static features is introduced.
3.1. Problem Definition
Consider a given shot consists of a sequence of frames, where represents the ith frame of the shot, and n denotes the number of frames in the shot. Each frame can be regarded as a 2d image that encompasses the static visual information of the shot. The objective of shot attribute analysis is to identify a set of functions , which can map movie shot S to a pre-defined set of movie shot types . Here, denotes the jth movie shot attribute, while m signifies the total number of the attributes (for instance, in MovieShots, ). The entire process can be expressed by the following equation: , or alternatively as .
3.2. Motion Branch
3.2.1. Drawbacks of Optical Flow
When analyzing motion clues in movie shots, previous shot attribute analysis methods [
1,
7,
10,
11] often employ optical flow maps as the motion cue, which show the differences between successive frames through pixel-level displacement vectors. However, the extraction of optical flow maps requires the introduction of additional optical flow pre-trained networks [
13] and consumes a substantial amount of time for optical flow calculation, making it unsuitable for the end-to-end architecture. Moreover, we point out that since the datasets [
12,
14] used to train the optical flow network are generated in virtual environments, it might not fully and accurately simulate various complex scenes and object movements in the real world, especially in dynamic and variable movie shots. If there is any distortion in the obtained optical flow maps it may affect the accuracy of the analysis results.
3.2.2. Frame Difference Generator
In the motion branch, we build a unique frame difference generator module. This module accurately represents the dynamic variations between consecutive frames by generating frame difference maps. As shown in
Figure 2b, we propose three methods for this module: (1)
Frame-Diff: Firstly, we split the input clip into separate frames, subtract the latter frame from the former frame sequentially, and stitch the result directly. This method is advantageous as it directly showcases the differences between adjacent frames. (2)
Conv-Diff: This function also entails splitting the input into separate parts, but the subsequent frame is first passed through a single convolutional layer (kernel size = 3, stride = 1, padding = 1) before being subtracted from the previous frame. This process allows the resulting features to represent motion changes while considering local feature information. (3)
Depthwise-Diff: In this method, we first truncate the input data for transformation and rearrangement, combine the channel dimension with the batch dimension, and then extract frames 0 to T − 1 and frames 1 to T for the preceding and subsequent frames, respectively. The latter is processed through a depthwise separable convolutional [
34] layer and then subtracted from the former, followed by one deformation layer for output transformation.
Among these three methods, we particularly emphasize the Depthwise-Diff method, and subsequent experimental results in
Section 4 have demonstrated the efficiency of this method. Firstly, in terms of implementation, this method is equivalent to processing each frame independently through a convolution block with only one convolution kernel. During this process, due to the dimension transformation that has already occurred, the convolution operation will be performed along the time dimension (dim = 2), which significantly differs from the typical operation along the channel dimension. This design allows for the parallel processing of all input frames, resulting in higher computational efficiency and parameter utilization compared to the other two methods. Additionally, it provides a more comprehensive way to capture and understand the temporal dependency features in dynamic motion cues. The entire process can be expressed as
, where
represents the difference maps and
represents the generation method.
3.2.3. Motion Backbone
For the choice of the backbone in the motion branch, we deviate from the commonly used ResNet50 [
35] in previous methods, and instead opt for introducing the vision transformer [
36,
37,
38,
39,
40] backbone. Initially, we conduct preliminary experiments using several self-attention blocks on two movie shot datasets. After practical experimentation and analysis (we elaborate the process in detail in
Section 4.3), we choose the Multiscale Visual Transformer [
40] (MViT) with a multiscale feature hierarchies structure as our motion backbone.
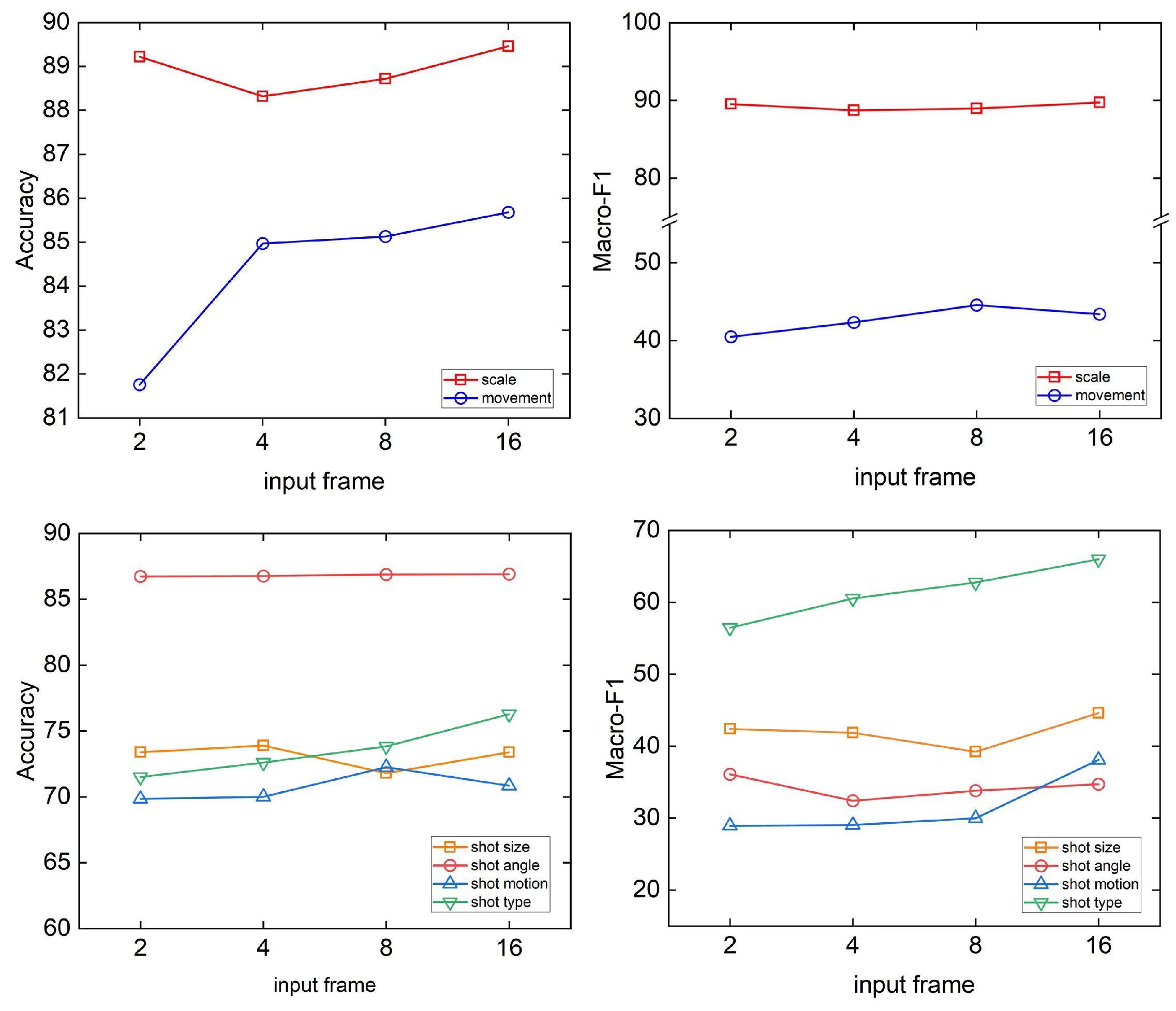
The MViT backbone is a relatively optimal choice determined after extensive experimentation. Simultaneously, we discover that not all video transformer architectures can serve as suitable motion backbones. For the task of shot attribute analysis, whether utilizing motion cues as input or directly employing frame sequences as input, the most critical aspect is the low-level semantic information. This observation might have been overlooked in prior related studies. Subsequent ablation experiments in
Section 4.5 can further substantiate our conclusion.
The entire MViT Backbone can be represented by the following equation:
where
denotes the frame difference map after fixed-size adjustment;
,
,
denote the query, key and value in the self-attention operator;
,
,
denote the corresponding weight matrix;
denotes the pooling attention; and
denotes the obtained motion feature vector.
3.2.4. Fixed-Size Adjustment
Training a vision transformer requires a large-scale annotated dataset. in the design of the motion backbone, movie shot datasets usually have a lack of shot samples (<10 K), which is insufficient to support training a transformer backbone from scratch. To better utilize various backbones pre-trained by Kinetics 400, we set as the standard backbone input size. Then, we introduce a fixed-size adjustment module to resize the frame difference map D to this size. Specifically, we used linear interpolation to adjust D, ensuring that the input size of the motion backbone matches the input size of the pre-trained model. This process can be represented as . Additionally, the fixed-size adjustment module indicates that our architecture can use shot clips of arbitrary length and sample rate as input.
3.3. Static Branch
Based on practical experience, for some intrinsic attributes of shots, such
scale, we can directly judge whether it is a close-up or a medium shot from any frame of the shot. Therefore, for the static branch, we believe that using the entire sequence of frames as input, like a traditional two-stream network, would introduce a significant amount of redundant information. Instead, it is common to select key frames from the shot as input. However, we have found that in movie shots, there are rarely meaningless frames; thus, utilizing one keyframe to represent static information within a shot is a highly intuitive solution. In our method, we directly select the intermediate frame of the shot as the static input. For the static backbone, we choose ViT [
17] pre-trained by Image21K. The process of the static branch can be expressed as
, where
denotes the static feature outputted from the static branch.
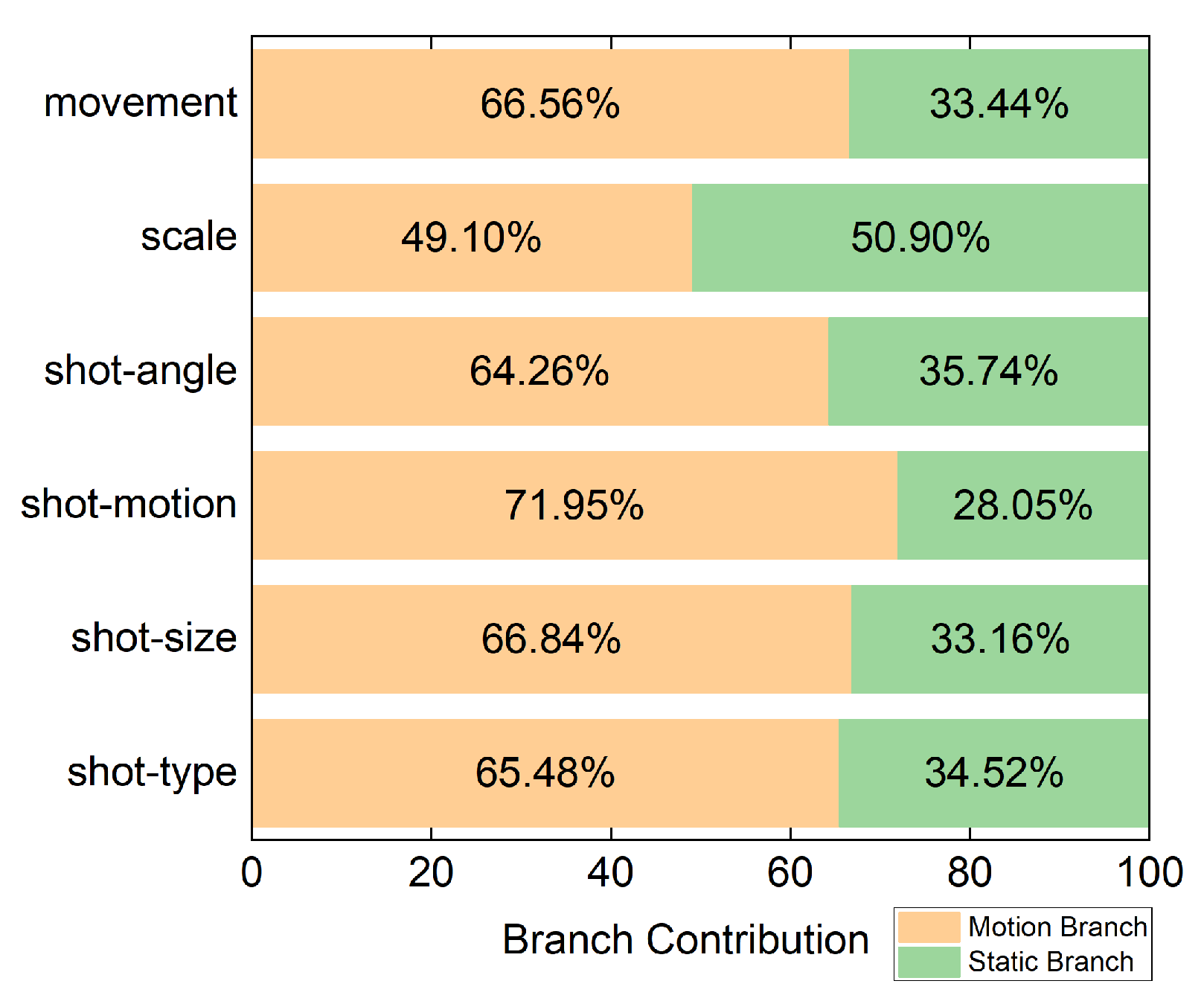
3.4. Quantitative Feature Fusion
Upon obtaining the motion feature
and the static feature
, a direct approach would involve concatenating these two vectors and then passing them through a classification layer to obtain predictive outcomes. However, we point out that this could lead to interference between two features (as the weight parameters of the fully connected layer would be applied to all elements of both vectors simultaneously). In order to maintain the independence of motion and static information, while also quantitatively assessing the contribution from the branches, we add a trainable parameter that allows the network to automatically learn the contribution weights of the branches (refer to results in
Section 4.4). The entire process can be expressed using the following formula:
, where
denotes the trainable parameter.







{kind=link}
{kind=link}
{kind=link}
{kind=link}