

Electrical Power Edge-End Interaction Modeling with Time Series Label Noise Learning

Abstract
:1. Introduction
- We propose a time–frequency collaborative classification learning model aimed at tackling issues related to low data quality, including problems like noisy labels and outliers, in electric power time series data. Specifically, our proposed model, in conjunction with a small loss criterion, leverages both time and frequency domain information from each sample to enhance the model’s robustness. Hence, this contributes to the enhancement of edge-end modeling for electric power time series data.
- We introduce a time–frequency contrastive learning module to capture the consistency between the time and frequency domains within each electric power time series. This helps alleviate the adverse effects of missing, anomalous values and noisy labels during model classification training. Furthermore, our model can seamlessly integrate federated learning to support edge-end modeling of electric power time series data, thereby enhancing the model’s robustness for real-world applications.
- Extensive experiments conducted on eight electric power time series datasets and ten different realistic scenario time series datasets demonstrate that our proposed TF-NLC achieves advanced classification performance in various noisy label scenarios. In addition, ablation, visualization, and edge-end interaction with federated learning experiments further indicate the robustness of different components of TF-NLC against noisy labels.
2. Related Work
2.1. Electrical Power Edge-End Interaction Modeling
2.2. Label Noise Learning
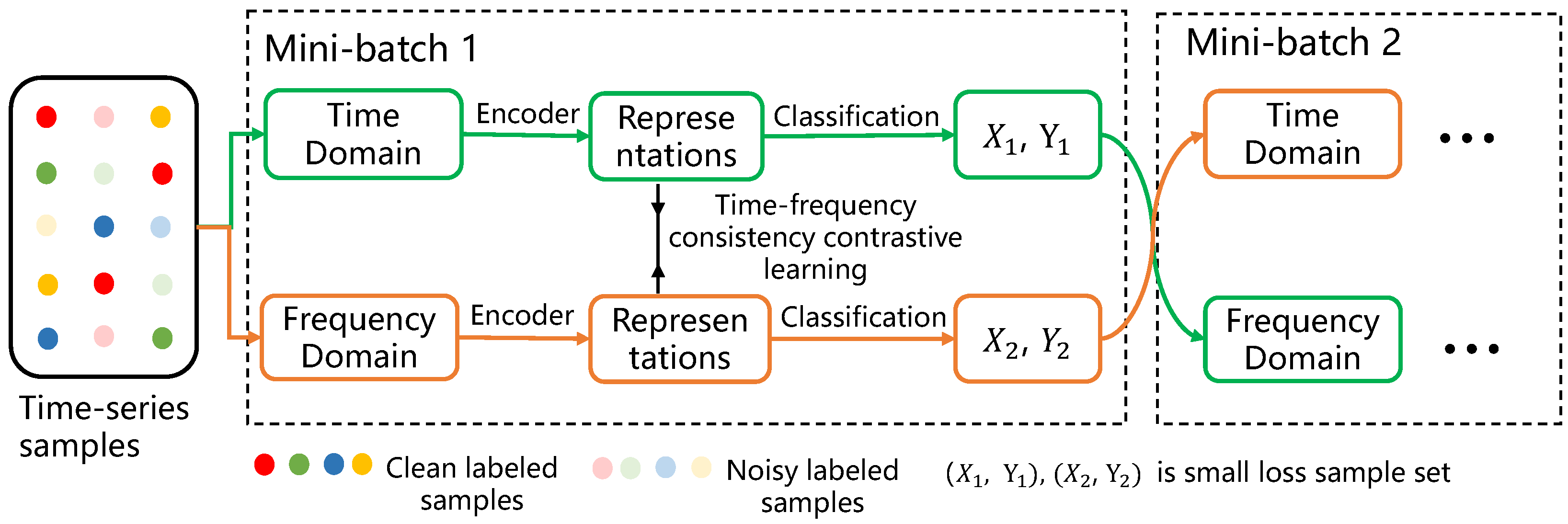
3. Method
3.1. Overall Framework
3.2. Time–Frequency Collaborative Classification Learning
3.3. Time–Frequency Contrastive Learning
3.4. Overall Training Objective
| Algorithm 1 The proposed TF-NLC framework. |
|
4. Experiments
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Architecture
4.1.4. Baselines
- Vanilla: Only the basic network framework is adopted, without using any label noise learning techniques.
- Co-teaching [43]: This method trains two differently initialized networks at the same time, and each network selects small-loss samples to guide the other network to update parameters.
- Mixup-BMM [42]: Mixup-BMM uses the beta mixture model to fit the loss distribution of the data, and combines bootstrapping and mixup for loss correction.
- SIGUA [40]: SIGUA selects clean samples and noisy samples from the training set through the small-loss criterion, uses the loss of clean samples to perform gradient descent updates, and uses the loss of noisy samples to perform gradient ascent updates.
- DivideMix [17]: DivideMix selects clean samples to form a labeled sample set, selects noisy samples to form an unlabeled sample set, and then uses these two sets combined with semisupervised learning techniques to train the network.
- SREA [10]: SREA mainly proposes an effective self-supervised learning paradigm to correct labels for mislabeled samples and uses autoencoders to help the model obtain robust representations of time series.
- Sel-CL [39]: Sel-CL selects trusted samples from the training set to construct trusted sample pairs for supervised contrastive learning, improves the accuracy of sample selection, and forms a positive cycle with the construction of trusted sample pairs.
4.1.5. Implementation Details
4.2. Experiment Results
4.3. Ablation Analysis
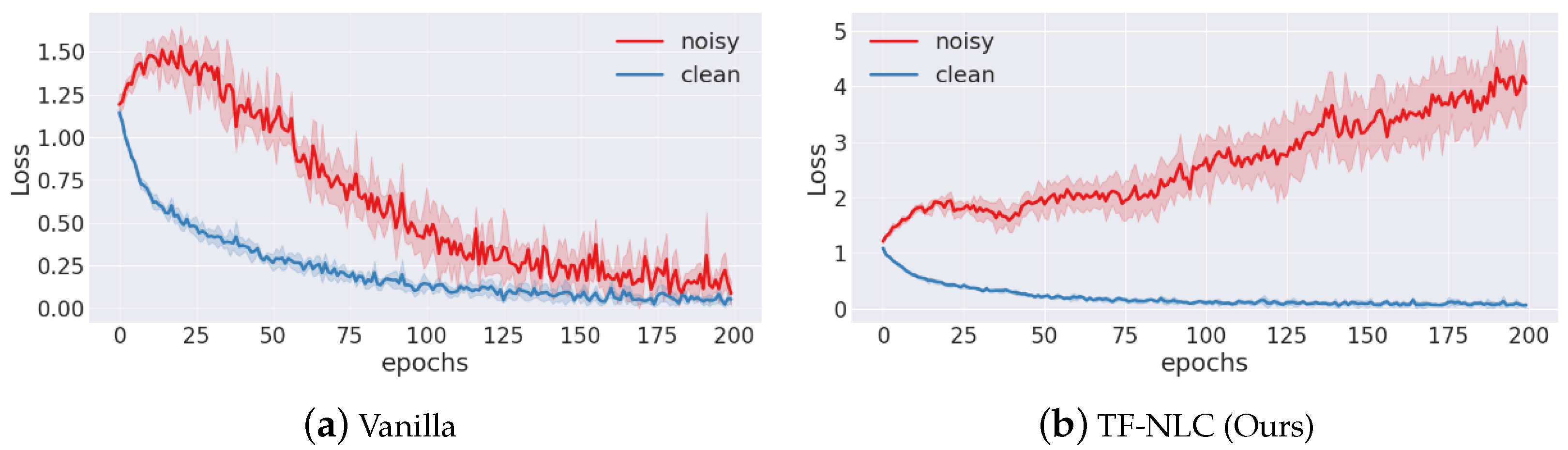
4.4. Loss Analysis
4.5. Edge-End Interaction
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, H.F.; Chen, Y.P.P. Hybrid deep learning and empirical mode decomposition model for time series applications. Expert Syst. Appl. 2019, 120, 128–138. [Google Scholar] [CrossRef]
- Mollik, M.S.; Hannan, M.A.; Reza, M.S.; Abd Rahman, M.S.; Lipu, M.S.H.; Ker, P.J.; Mansor, M.; Muttaqi, K.M. The Advancement of Solid-State Transformer Technology and Its Operation and Control with Power Grids: A Review. Electronics 2022, 11, 2648. [Google Scholar] [CrossRef]
- Zhang, H.; Bosch, J.; Olsson, H.H. Real-time end-to-end federated learning: An automotive case study. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 459–468. [Google Scholar]
- Wu, Q.; Chen, X.; Zhou, Z.; Zhang, J. Fedhome: Cloud-edge based personalized federated learning for in-home health monitoring. IEEE Trans. Mob. Comput. 2020, 21, 2818–2832. [Google Scholar] [CrossRef]
- Chen, R.; Cheng, Q.; Zhang, X. Power Distribution IoT Tasks Online Scheduling Algorithm Based on Cloud-Edge Dependent Microservice. Appl. Sci. 2023, 13, 4481. [Google Scholar] [CrossRef]
- Teimoori, Z.; Yassine, A.; Hossain, M.S. A secure cloudlet-based charging station recommendation for electric vehicles empowered by federated learning. IEEE Trans. Ind. Inform. 2022, 18, 6464–6473. [Google Scholar] [CrossRef]
- Fekri, M.N.; Grolinger, K.; Mir, S. Distributed load forecasting using smart meter data: Federated learning with Recurrent Neural Networks. Int. J. Electr. Power Energy Syst. 2022, 137, 107669. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.; Ma, Q. Category-aware optimal transport for incomplete data classification. Inf. Sci. 2023, 634, 443–476. [Google Scholar] [CrossRef]
- Sater, R.A.; Hamza, A.B. A federated learning approach to anomaly detection in smart buildings. ACM Trans. Internet Things 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Castellani, A.; Schmitt, S.; Hammer, B. Estimating the electrical power output of industrial devices with end-to-end time-series classification in the presence of label noise. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Online, 13–17 September 2021; pp. 469–484. [Google Scholar]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Huang, M.; Liu, Z.; Tao, Y. Mechanical fault diagnosis and prediction in IoT based on multi-source sensing data fusion. Simul. Model. Pract. Theory 2020, 102, 101981. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Ruiz, A.P.; Flynn, M.; Large, J.; Middlehurst, M.; Bagnall, A. The great multivariate time series classification bake off: A review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2021, 35, 401–449. [Google Scholar] [CrossRef]
- Ma, Q.; Liu, Z.; Zheng, Z.; Huang, Z.; Zhu, S.; Yu, Z.; Kwok, J.T. A Survey on Time-Series Pre-Trained Models. arXiv 2023, arXiv:2305.10716. [Google Scholar]
- Lyu, Y.; Tsang, I.W. Curriculum loss: Robust learning and generalization against label corruption. arXiv 2019, arXiv:1905.10045. [Google Scholar]
- Li, J.; Socher, R.; Hoi, S.C. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, X.; Zhang, W.; Trajcevski, G.; Zhong, T.; Zhou, F. Learning latent seasonal-trend representations for time series forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 38775–38787. [Google Scholar]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Kwoh, C.K.; Li, X.; Guan, C. Time-series representation learning via temporal and contextual contrasting. arXiv 2021, arXiv:2106.14112. [Google Scholar]
- Zhang, X.; Zhao, Z.; Tsiligkaridis, T.; Zitnik, M. Self-supervised contrastive pre-training for time series via time-frequency consistency. Adv. Neural Inf. Process. Syst. 2022, 35, 3988–4003. [Google Scholar]
- Dempster, A.; Petitjean, F.; Webb, G.I. ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels. Data Min. Knowl. Discov. 2020, 34, 1454–1495. [Google Scholar] [CrossRef]
- Dempster, A.; Schmidt, D.F.; Webb, G.I. Minirocket: A very fast (almost) deterministic transform for time series classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–17 August 2021; pp. 248–257. [Google Scholar]
- Yue, Z.; Wang, Y.; Duan, J.; Yang, T.; Huang, C.; Tong, Y.; Xu, B. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 August 2022; Volume 36, pp. 8980–8987. [Google Scholar]
- Woo, G.; Liu, C.; Sahoo, D.; Kumar, A.; Hoi, S. CoST: Contrastive learning of disentangled seasonal-trend representations for time series forecasting. arXiv 2022, arXiv:2202.01575. [Google Scholar]
- Liu, Z.; Ma, Q.; Ma, P.; Wang, L. Temporal-Frequency Co-training for Time Series Semi-supervised Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 8923–8931. [Google Scholar]
- Nussbaumer, H.J.; Nussbaumer, H.J. The Fast Fourier Transform; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Gui, X.J.; Wang, W.; Tian, Z.H. Towards understanding deep learning from noisy labels with small-loss criterion. arXiv 2021, arXiv:2106.09291. [Google Scholar]
- Mach, P.; Becvar, Z. Cloud-aware power control for real-time application offloading in mobile edge computing. Trans. Emerg. Telecommun. Technol. 2016, 27, 648–661. [Google Scholar] [CrossRef]
- Smadi, A.A.; Ajao, B.T.; Johnson, B.K.; Lei, H.; Chakhchoukh, Y.; Abu Al-Haija, Q. A Comprehensive survey on cyber-physical smart grid testbed architectures: Requirements and challenges. Electronics 2021, 10, 1043. [Google Scholar] [CrossRef]
- Wang, Y.; Bennani, I.L.; Liu, X.; Sun, M.; Zhou, Y. Electricity consumer characteristics identification: A federated learning approach. IEEE Trans. Smart Grid 2021, 12, 3637–3647. [Google Scholar] [CrossRef]
- Taïk, A.; Cherkaoui, S. Electrical load forecasting using edge computing and federated learning. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Atkinson, G.; Metsis, V. A Survey of Methods for Detection and Correction of Noisy Labels in Time Series Data. In Proceedings of the Artificial Intelligence Applications and Innovations: 17th IFIP WG 12.5 International Conference, AIAI 2021, Hersonissos, Crete, Greece, 25–27 June 2021; pp. 479–493. [Google Scholar]
- Ravindra, P.; Khochare, A.; Reddy, S.P.; Sharma, S.; Varshney, P.; Simmhan, Y. An Adaptive Orchestration Platform for Hybrid Dataflows across Cloud and Edge. In Proceedings of the International Conference on Service-Oriented Computing, Malaga, Spain, 13–16 November 2017; pp. 395–410. [Google Scholar]
- Li, Z.; Shi, L.; Shi, Y.; Wei, Z.; Lu, Y. Task offloading strategy to maximize task completion rate in heterogeneous edge computing environment. Comput. Netw. 2022, 210, 108937. [Google Scholar] [CrossRef]
- Chung, S.; Zhang, Y. Artificial Intelligence Applications in Electric Distribution Systems: Post-Pandemic Progress and Prospect. Appl. Sci. 2023, 13, 6937. [Google Scholar] [CrossRef]
- Ghosh, A.; Kumar, H.; Sastry, P.S. Robust loss functions under label noise for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7164–7173. [Google Scholar]
- Li, S.; Xia, X.; Ge, S.; Liu, T. Selective-supervised contrastive learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 316–325. [Google Scholar]
- Han, B.; Niu, G.; Yu, X.; Yao, Q.; Xu, M.; Tsang, I.; Sugiyama, M. Sigua: Forgetting may make learning with noisy labels more robust. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 4006–4016. [Google Scholar]
- Charoenphakdee, N.; Lee, J.; Sugiyama, M. On symmetric losses for learning from corrupted labels. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 961–970. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; McGuinness, K. Unsupervised label noise modeling and loss correction. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 312–321. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 8536–8546. [Google Scholar]
- Donders, A.R.T.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Bagnall, A.; Dau, H.A.; Lines, J.; Flynn, M.; Large, J.; Bostrom, A.; Southam, P.; Keogh, E. The UEA multivariate time series classification archive, 2018. arXiv 2018, arXiv:1811.00075. [Google Scholar]
- Xia, X.; Liu, T.; Han, B.; Wang, N.; Gong, M.; Liu, H.; Niu, G.; Tao, D.; Sugiyama, M. Part-dependent label noise: Towards instance-dependent label noise. Adv. Neural Inf. Process. Syst. 2020, 33, 7597–7610. [Google Scholar]
- Arpit, D.; Jastrzębski, S.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Bengio, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 233–242. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial intelligence and statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| X | Original dataset |
| N | The size of the original dataset |
| T | The sequence length of time series |
| F | The number of variables of time series |
| Samples selected by the time domain network | |
| Labels of the samples selected by the time domain network | |
| Samples selected by the frequency domain network | |
| Labels of the samples selected by the frequency domain network | |
| The input of the i-th sample in the time domain network | |
| The input of the i-th sample in the frequency domain network | |
| j | The imaginary unit |
| The observed label of the i-th sample | |
| The network’s prediction for the i-th sample | |
| The noise rate of the original dataset | |
| The time domain feature representation of the i-th sample | |
| The frequency domain feature representation of the i-th sample | |
| The time–frequency contrastive learning loss | |
| The optimization objective of the time domain classifier | |
| The optimization objective of the frequency domain classifier | |
| The overall optimization objective | |
| The weight of |
| Dataset | #Class | #Instances | #Dimensions | #Length | Type |
|---|---|---|---|---|---|
| ArrowHead | 3 | 211 | 1 | 251 | IMAGE |
| CBF | 3 | 930 | 1 | 128 | SIMULATED |
| FaceFour | 4 | 112 | 1 | 350 | IMAGE |
| MelbournePedestrian | 10 | 3650 | 1 | 24 | Traffic |
| OSULeaf | 6 | 442 | 1 | 427 | IMAGE |
| Plane | 7 | 210 | 1 | 144 | SENSOR |
| Symbols | 6 | 1020 | 1 | 398 | IMAGE |
| Trace | 4 | 200 | 1 | 275 | SENSOR |
| Epilepsy | 4 | 275 | 3 | 207 | HAR |
| NATOPS | 6 | 360 | 24 | 51 | HAR |
| C1P1 | 2 | 63 | 1 | 96 | SENSOR |
| C1P2 | 2 | 97 | 1 | 96 | SENSOR |
| C1P3 | 2 | 139 | 1 | 96 | SENSOR |
| C2P1 | 2 | 220 | 1 | 96 | SENSOR |
| C2P2 | 2 | 98 | 1 | 96 | SENSOR |
| C3P1 | 2 | 412 | 1 | 96 | SENSOR |
| C3P2 | 2 | 42 | 1 | 96 | SENSOR |
| C3P3 | 2 | 420 | 1 | 96 | SENSOR |
| Vanilla | SIGUA | Co-Teaching | BMM | Dividemix | Sel-CL | SREA | TF-NLC | ||
|---|---|---|---|---|---|---|---|---|---|
| Clean | 0 | 0.947 | 0.942 | 0.954 | 0.872 | 0.462 | 0.832 | 0.961 | 0.956 |
| Sym | 15% | 0.863 | 0.868 | 0.906 | 0.879 | 0.591 | 0.793 | 0.924 | 0.921 |
| 30% | 0.748 | 0.777 | 0.847 | 0.822 | 0.605 | 0.768 | 0.858 | 0.882 | |
| 45% | 0.579 | 0.655 | 0.699 | 0.716 | 0.53 | 0.722 | 0.706 | 0.768 | |
| 60% | 0.397 | 0.5 | 0.509 | 0.559 | 0.41 | 0.637 | 0.546 | 0.585 | |
| Asym | 10% | 0.897 | 0.899 | 0.931 | 0.882 | 0.572 | 0.804 | 0.93 | 0.932 |
| 20% | 0.821 | 0.838 | 0.892 | 0.848 | 0.572 | 0.795 | 0.881 | 0.898 | |
| 30% | 0.734 | 0.776 | 0.812 | 0.8 | 0.568 | 0.763 | 0.806 | 0.841 | |
| 40% | 0.594 | 0.648 | 0.723 | 0.696 | 0.541 | 0.679 | 0.688 | 0.723 | |
| IDN | 30% | 0.69 | 0.743 | 0.781 | 0.78 | 0.577 | 0.765 | 0.802 | 0.828 |
| 40% | 0.609 | 0.658 | 0.71 | 0.703 | 0.546 | 0.735 | 0.72 | 0.759 |
| Vanilla | SIGUA | Co-Teaching | BMM | Dividemix | Sel-CL | SREA | TF-NLC | ||
|---|---|---|---|---|---|---|---|---|---|
| Clean | 0 | 3.4 | 4.8 | 3 | 6 | 8 | 5.8 | 2.1 | 3 |
| Sym | 15% | 5.8 | 5.6 | 3.2 | 3.9 | 7.3 | 5.3 | 2.4 | 2.6 |
| 30% | 6 | 5.8 | 3.7 | 4 | 6.8 | 4.5 | 2.8 | 2.4 | |
| 45% | 7 | 5.2 | 4.1 | 3.5 | 6.3 | 4.1 | 3.5 | 2.3 | |
| 60% | 7.1 | 4.9 | 5.1 | 3.2 | 6.3 | 3 | 3.5 | 2.9 | |
| Asym | 10% | 5.2 | 4.9 | 2.6 | 4.8 | 7.4 | 5.2 | 2.9 | 3 |
| 20% | 5.9 | 5.4 | 3 | 4.6 | 7.1 | 4.3 | 3 | 2.7 | |
| 30% | 5.8 | 5.3 | 3.6 | 4.2 | 6.7 | 4.5 | 3.2 | 2.7 | |
| 40% | 6.5 | 5.6 | 2.8 | 4.1 | 6.2 | 4.4 | 3.8 | 2.6 | |
| IDN | 30% | 6.7 | 5.4 | 4 | 3.8 | 6.3 | 3.8 | 3.2 | 2.9 |
| 40% | 6.6 | 6.2 | 3.6 | 3.9 | 5.9 | 3.6 | 3.4 | 2.8 |
| Vanilla | SIGUA | Co-Teaching | BMM | Dividemix | Sel-CL | SREA | TF-NLC | ||
|---|---|---|---|---|---|---|---|---|---|
| Clean | 0 | 0.870 | 0.863 | 0.871 | 0.786 | 0.527 | 0.869 | 0.839 | 0.876 |
| Sym | 10% | 0.830 | 0.825 | 0.832 | 0.763 | 0.569 | 0.828 | 0.809 | 0.846 |
| 20% | 0.780 | 0.800 | 0.806 | 0.748 | 0.541 | 0.762 | 0.772 | 0.813 | |
| 30% | 0.744 | 0.721 | 0.734 | 0.682 | 0.600 | 0.720 | 0.718 | 0.756 | |
| 40% | 0.629 | 0.621 | 0.609 | 0.611 | 0.591 | 0.679 | 0.620 | 0.647 | |
| IDN | 30% | 0.726 | 0.734 | 0.727 | 0.718 | 0.586 | 0.719 | 0.701 | 0.759 |
| 40% | 0.653 | 0.595 | 0.621 | 0.661 | 0.498 | 0.707 | 0.632 | 0.662 |
| Vanilla | w/o Sel. | w/o | FF | TT | TF-NLC | |
|---|---|---|---|---|---|---|
| ArrowHead | 0.773 | 0.826 | 0.893 | 0.853 | 0.843 | 0.902 |
| CBF | 0.774 | 0.794 | 0.779 | 0.545 | 0.869 | 0.803 |
| FaceFour | 0.785 | 0.877 | 0.877 | 0.840 | 0.875 | 0.898 |
| MelbournePedestrian | 0.768 | 0.796 | 0.847 | 0.720 | 0.875 | 0.851 |
| OSULeaf | 0.670 | 0.754 | 0.773 | 0.652 | 0.806 | 0.807 |
| Plane | 0.771 | 0.829 | 0.947 | 0.958 | 0.944 | 0.956 |
| Symbols | 0.768 | 0.884 | 0.966 | 0.920 | 0.971 | 0.970 |
| Trace | 0.720 | 0.906 | 0.966 | 0.954 | 0.928 | 0.968 |
| Epilepsy | 0.760 | 0.904 | 0.895 | 0.837 | 0.838 | 0.902 |
| NATOPS | 0.672 | 0.731 | 0.737 | 0.640 | 0.713 | 0.767 |
| Average | 0.746 | 0.830 | 0.868 | 0.792 | 0.866 | 0.882 |
| Accuracy | Avw_F1 | |||
|---|---|---|---|---|
| Vanilla-FedAVG | TF-NLC-FedAVG | Vanilla-FedAVG | TF-NLC-FedAVG | |
| ArrowHead | 0.399 | 0.573 | 0.312 | 0.535 |
| CBF | 0.807 | 0.838 | 0.789 | 0.822 |
| FaceFour | 0.535 | 0.642 | 0.503 | 0.619 |
| MelbournePedestrian | 0.285 | 0.485 | 0.233 | 0.456 |
| OSULeaf | 0.285 | 0.468 | 0.202 | 0.426 |
| Plane | 0.791 | 0.891 | 0.784 | 0.863 |
| Symbols | 0.463 | 0.705 | 0.395 | 0.657 |
| Trace | 0.765 | 0.795 | 0.729 | 0.746 |
| Epilepsy | 0.749 | 0.782 | 0.748 | 0.774 |
| NATOPS | 0.739 | 0.764 | 0.735 | 0.752 |
| Average | 0.582 | 0.694 | 0.543 | 0.665 |
| Accuracy | Avw_F1 | |||
|---|---|---|---|---|
| Vanilla-FedAVG | TF-NLC-FedAVG | Vanilla-FedAVG | TF-NLC-FedAVG | |
| C1P1 | 0.633 | 0.685 | 0.606 | 0.652 |
| C1P2 | 0.630 | 0.715 | 0.607 | 0.676 |
| C1P3 | 0.684 | 0.749 | 0.685 | 0.747 |
| C2P1 | 0.832 | 0.906 | 0.830 | 0.900 |
| C2P2 | 0.763 | 0.814 | 0.758 | 0.812 |
| C3P1 | 0.757 | 0.803 | 0.769 | 0.801 |
| C3P2 | 0.861 | 0.950 | 0.834 | 0.950 |
| C3P3 | 0.850 | 0.855 | 0.845 | 0.849 |
| Average | 0.751 | 0.809 | 0.742 | 0.798 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhou, M.; Zhao, Y.; Zhang, F.; Wang, J.; Qian, B.; Liu, Z.; Ma, P.; Ma, Q. Electrical Power Edge-End Interaction Modeling with Time Series Label Noise Learning. Electronics 2023, 12, 3987. https://doi.org/10.3390/electronics12183987
Wang Z, Zhou M, Zhao Y, Zhang F, Wang J, Qian B, Liu Z, Ma P, Ma Q. Electrical Power Edge-End Interaction Modeling with Time Series Label Noise Learning. Electronics. 2023; 12(18):3987. https://doi.org/10.3390/electronics12183987
Chicago/Turabian StyleWang, Zhenshang, Mi Zhou, Yuming Zhao, Fan Zhang, Jing Wang, Bin Qian, Zhen Liu, Peitian Ma, and Qianli Ma. 2023. "Electrical Power Edge-End Interaction Modeling with Time Series Label Noise Learning" Electronics 12, no. 18: 3987. https://doi.org/10.3390/electronics12183987