

X-ray Detection of Prohibited Item Method Based on Dual Attention Mechanism

Abstract
:1. Introduction
2. Related Work
3. Proposed Method
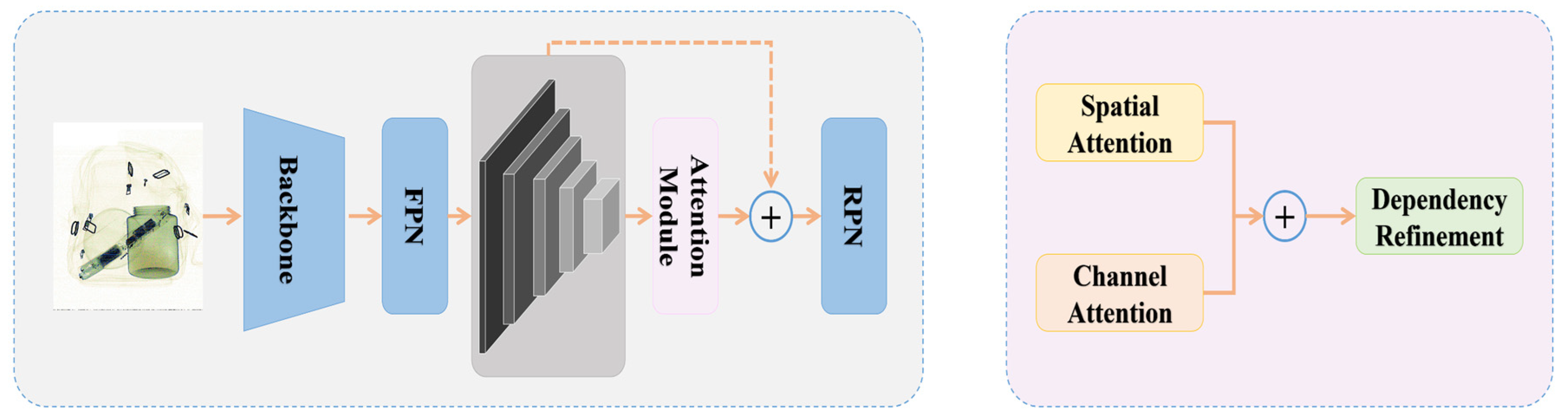
3.1. Network Architecture
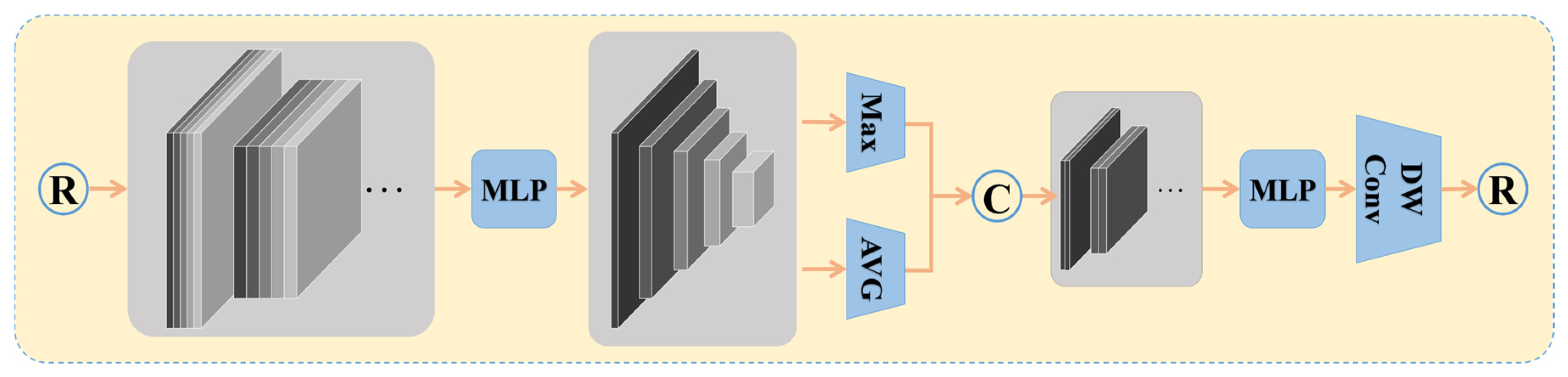
3.2. Spatial Attention Module
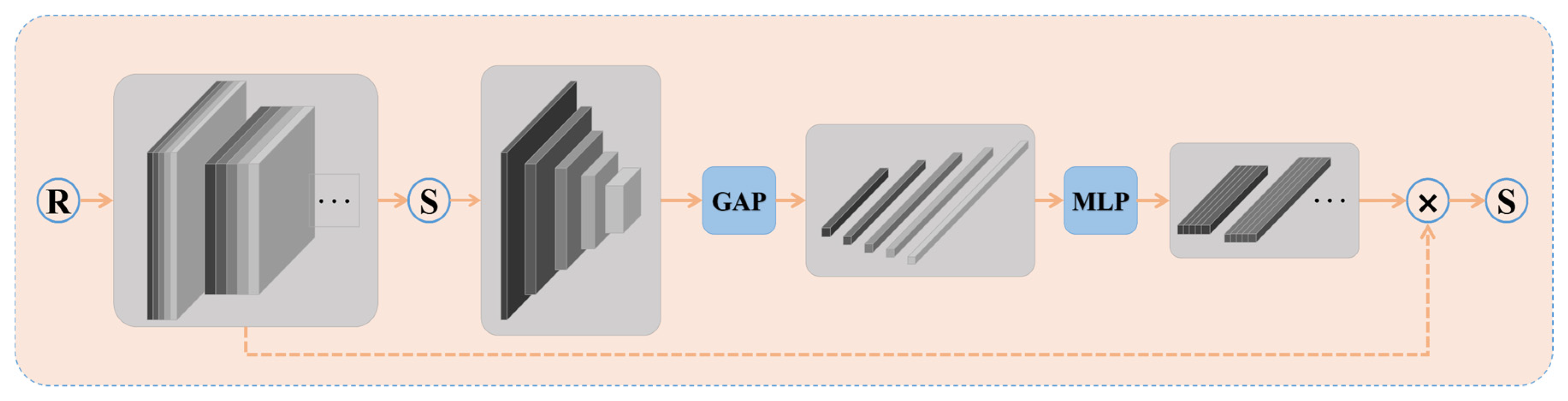
3.3. Channel Attention Module
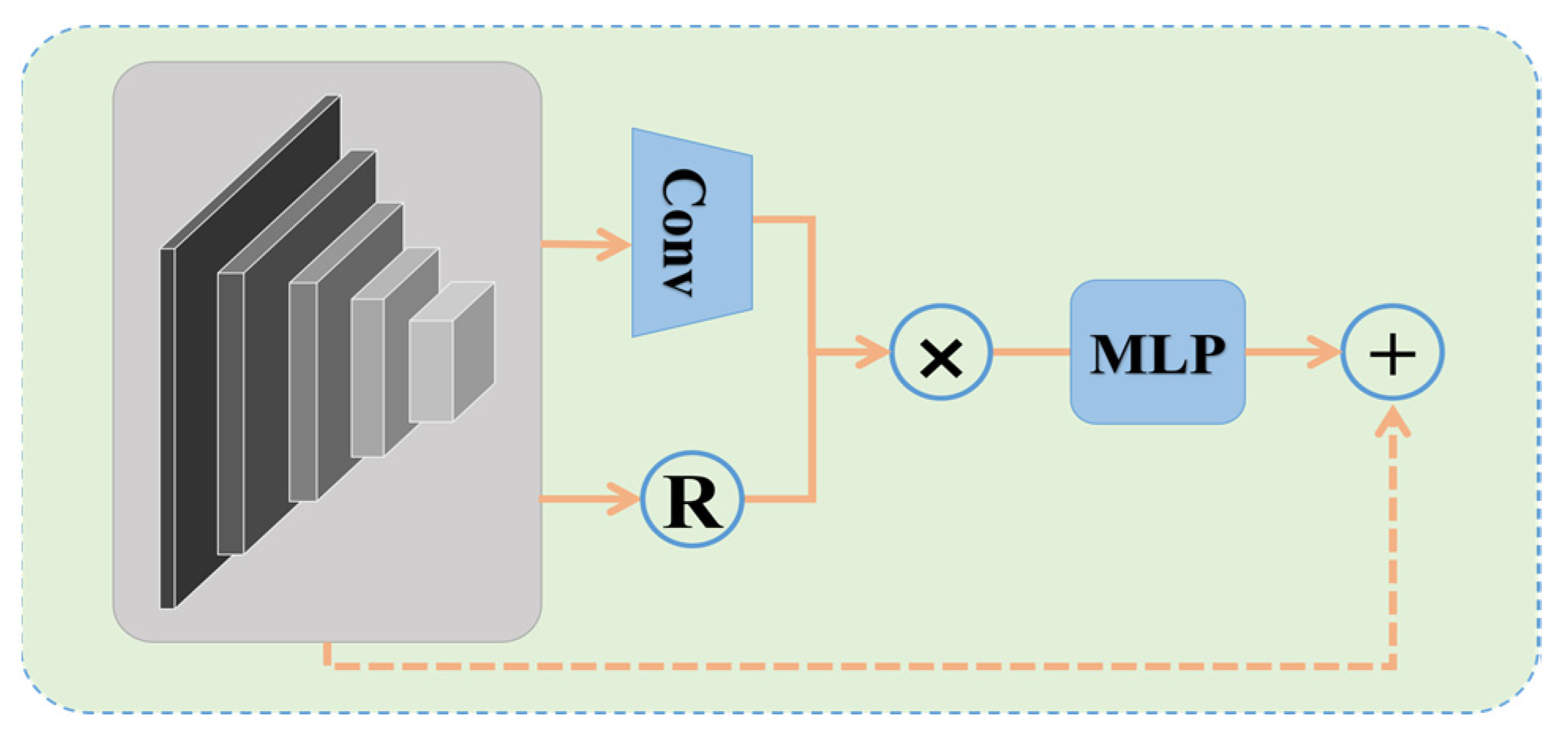
3.4. Dependency Refinement
4. Experiment and Performance Evaluation
4.1. Dataset
4.2. Experimental Parameter Settings
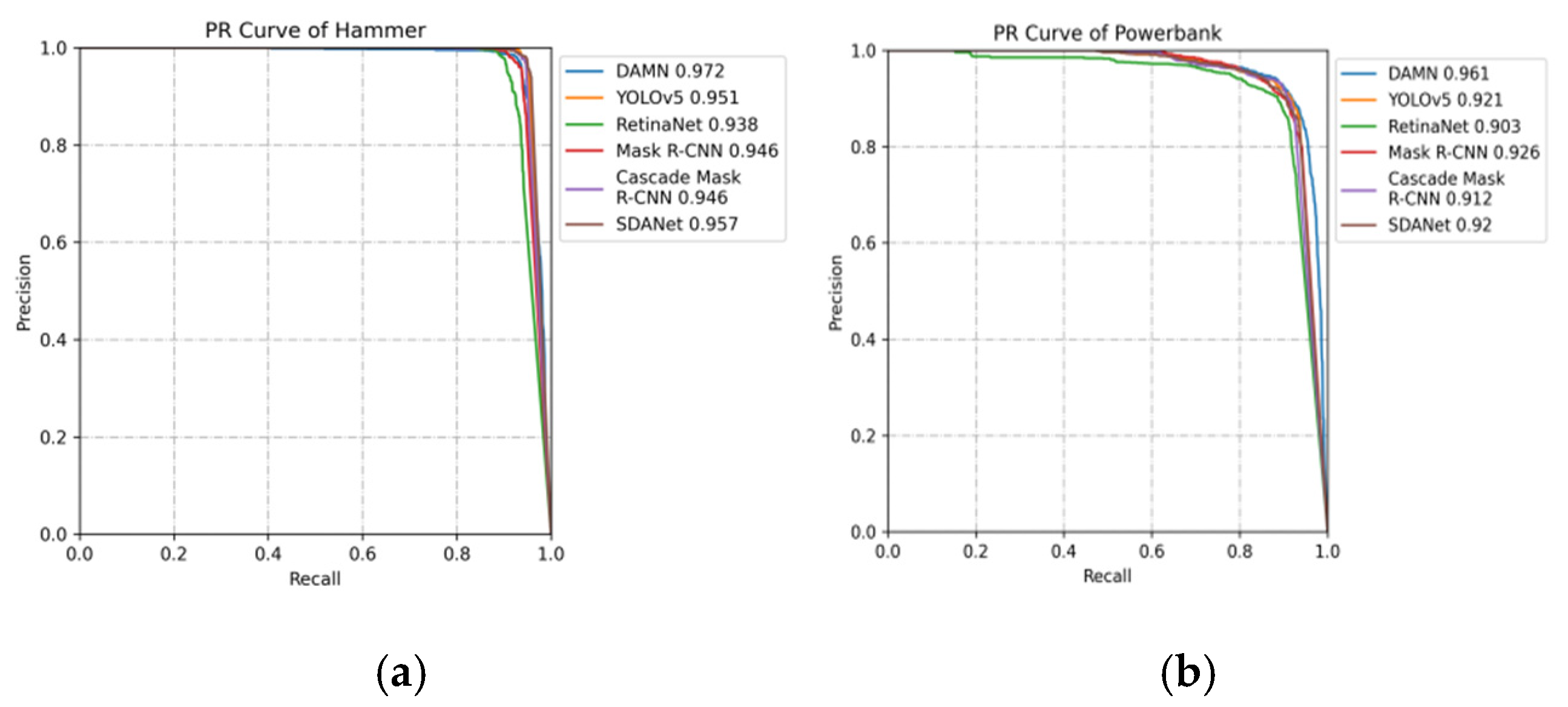
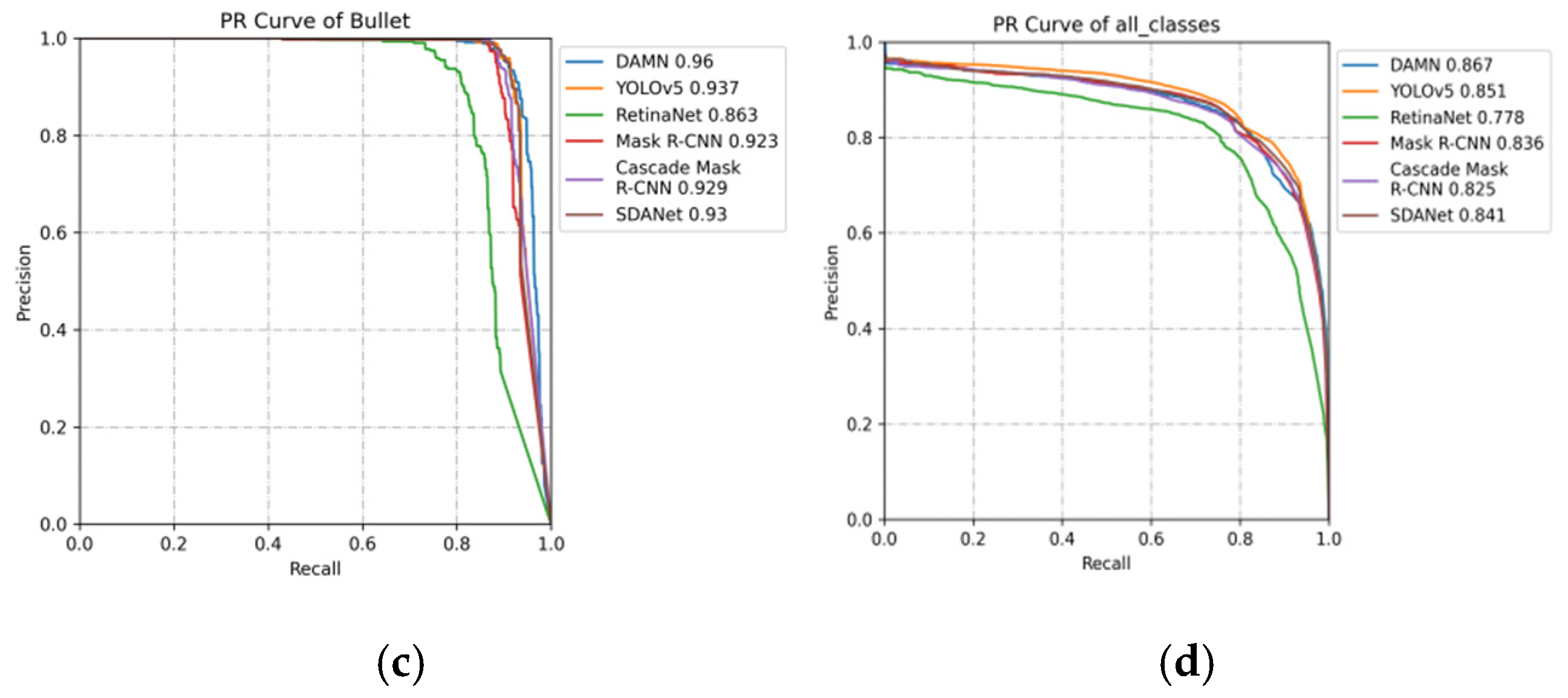
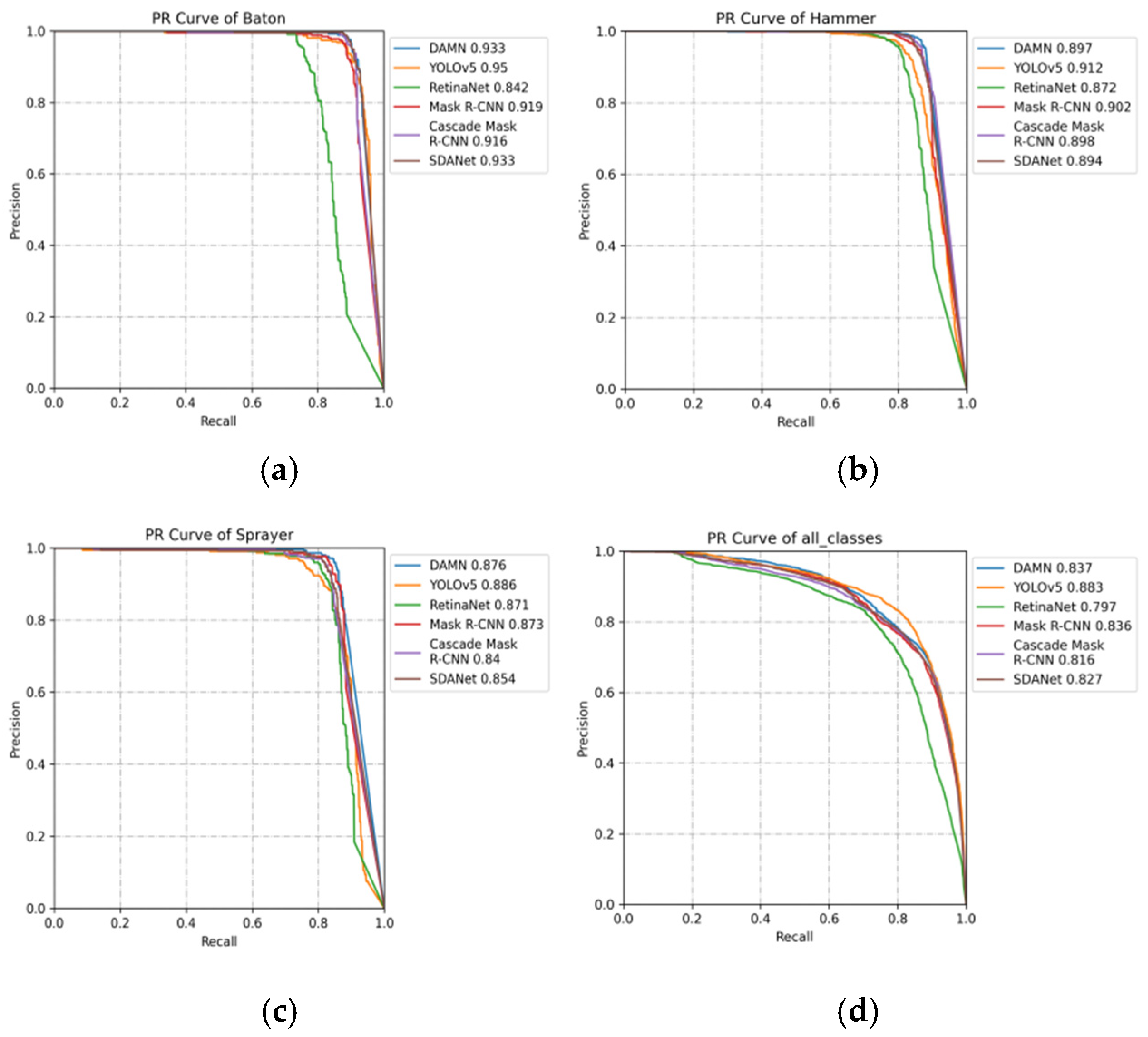
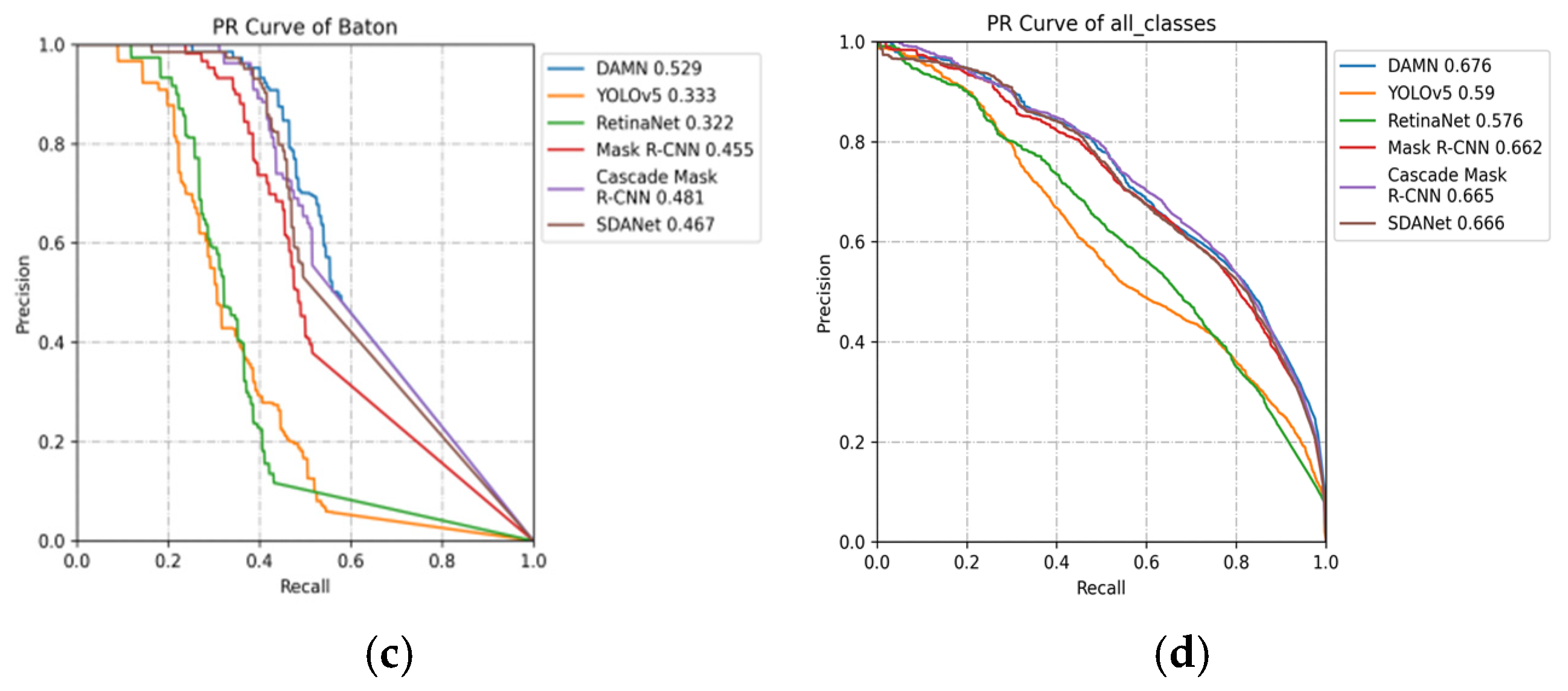
4.3. Experimental Results and Analysis
4.4. Special Case Analysis
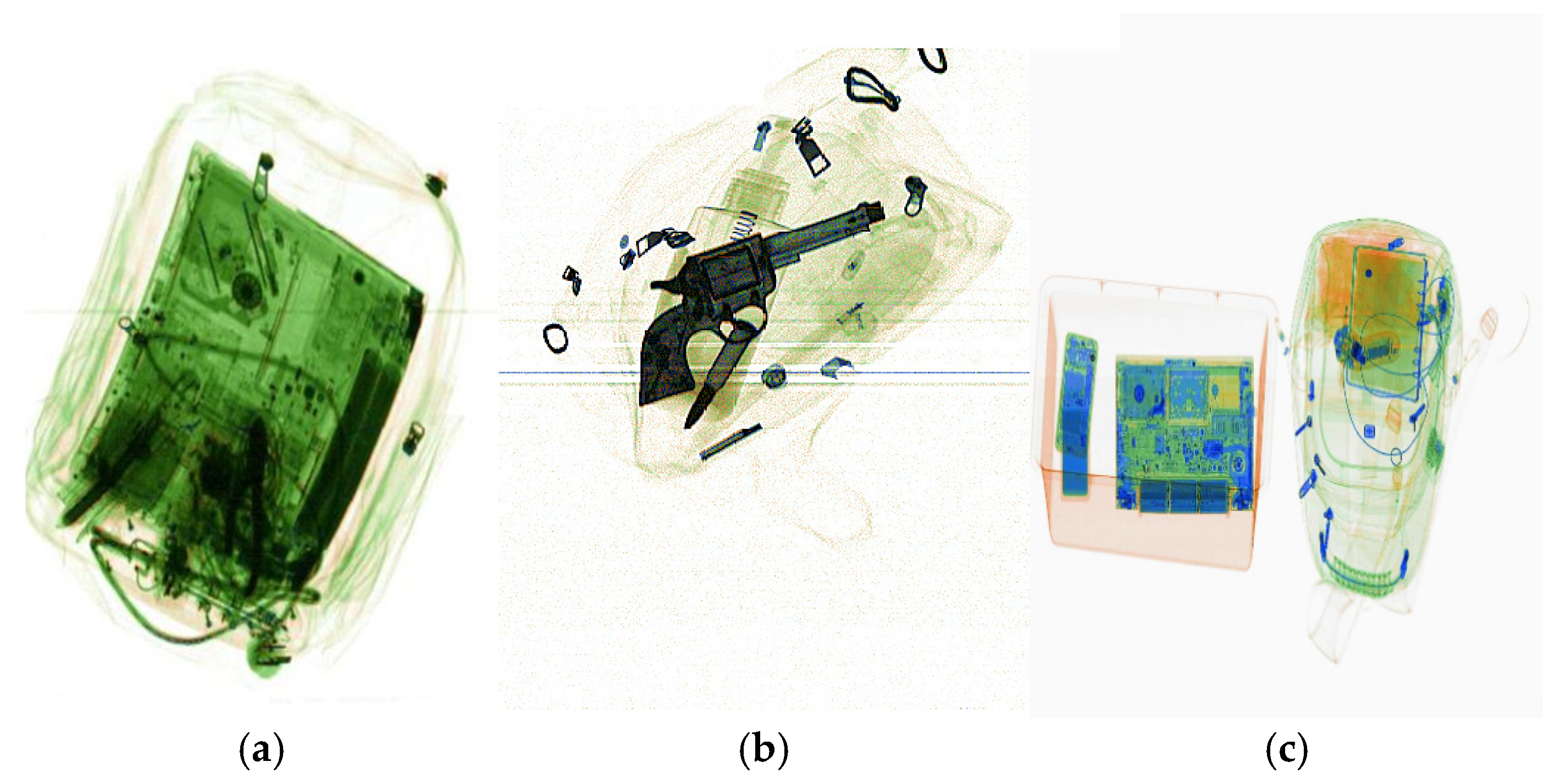
4.4.1. Detection of Small Prohibited Items
4.4.2. Detection of Prohibited Items with Easily Lost Details
4.4.3. Detection of Overlapping and Occluded Prohibited Items
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Michel, S.; Koller, S.M.; de Ruiter, J.C.; Moerland, R.; Hogervorst, M.; Schwaninger, A. Computer-based training increases efficiency in X-ray image interpretation by aviation security screeners. In Proceedings of the 2007 41st Annual IEEE International Carnahan Conference on Security Technology, Ottawa, ON, Canada, 8–11 October 2007; pp. 201–206. [Google Scholar]
- Li, Y.; Sun, S.; Zhang, C.; Yang, G.; Ye, Q. One-stage disease detection method for maize leaf based on multi-scale feature fusion. Appl. Sci. 2022, 12, 7960. [Google Scholar] [CrossRef]
- Kundegorski, M.E.; Akcay, S.; Devereux, M.; Mouton, A.; Breckon, T.P. On using feature descriptors as visual words for object detection within X-ray baggage security screening. In Proceedings of the International Conference on Imaging for Crime Detection & Prevention, Madrid, Spain, 23–25 November 2016; pp. 1–6. [Google Scholar]
- Akcay, S.; Kundegorski, M.E.; Devereux, M.; Breckon, T.P. Transfer Learning Using Convolutional Neural Networks for Object Classification within X-ray Baggage Security Imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1057–1061. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Banerjee, S. Modern computer vision techniques for X-ray testing in baggage inspection. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 682–692. [Google Scholar] [CrossRef]
- Akcay, S.; Breckon, T.P. An evaluation of region based object detection strategies within X-ray baggage security imagery. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within X-ray baggage security imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef]
- Liu, J.; Leng, X.; Liu, Y. Deep convolutional neural network based object detector for X-ray baggage security imagery. In Proceedings of the IEEE International Conference on Tools with Artificial Intelligence, Portland, OR, USA, 4–6 November 2019. [Google Scholar]
- Bhowmik, N.; Wang, Q.; Gaus, Y.F.A.; Szarek, M.; Breckon, T.P. The good, the bad and the ugly: Evaluating convolutional neural networks for prohibited item detection using real and synthetically composited X-ray imagery. arXiv 2019, arXiv:1909.11508. [Google Scholar]
- Subramani, M.; Rajaduari, K.; Choudhury, S.D.; Topkar, A.; Ponnusamy, V. Evaluating one stage detector architecture of convolutional neural network for threat object detection using X-ray baggage security imaging. Rev. d'Intelligence Artif. 2020, 34, 495–500. [Google Scholar] [CrossRef]
- Su, Z.G.; Yao, S.Q. A multi-object prohibited items identification algorithm based on semantic segmentation. J. Signal Process. 2020, 36, 7. [Google Scholar]
- Gu, J. A Study on X-ray Safety Check Contraband Image Detection Based on Deep LEARNING. Master’s Thesis, Yunnan University, Kunming, China, 2021. [Google Scholar]
- Dong, Y.S.; Li, Z.X.; Guo, J.Y.; Chen, T.Y.; Lu, S.H. Improved YOLOv5 model for X-ray prohibited item detection. Adv. Lasers Optoelectron. 2023, 60, 8. [Google Scholar]
- Li, S.; Ya, S.; Mu, S. Improved YOLOv7 X-ray image real-time detection of prohibited items. Comput. Eng. Appl. 2023, 59, 193–200. [Google Scholar]
- Han, N. A Deep Learning-Based Dangerous Goods Detection and Tracking Algorithm from X-ray Images; Lanzhou University: Lanzhou, China, 2018. [Google Scholar]
- Zhang, Y.K.; Su, Z.G.; Zhang, H.G.; Yang, J.F. Multi-scale prohibited item detection in X-ray security image. J. Signal Process. 2020, 36, 11. [Google Scholar]
- Zhang, Z.; Li, M.Z.; Li, H.F.; Ma, J.Q. Improved SSD algorithm and its application in subway security detection. Comput. Eng. 2021, 47, 7. [Google Scholar]
- Ren, J. X-ray Security Inspection Image Contraband Detection Based on YOLOv5; China University of Geosciences (Beijing): Beijing, China, 2021. [Google Scholar]
- Mu, S.Q.; Lin, J.J.; Wang, H.Q.; Wei, X.Z. An Algorithm for detection of prohibited items in X-ray images based on improved YOLOv4. Acta Armamentarii 2021, 42, 2675–2683. [Google Scholar]
- Kang, J.N.; Zhang, L. Multi-scale X-ray security inspection image detection with multi-channel region proposal. Comput. Eng. Appl. 2022, 58, 8. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Wu, Z.; Gobichettipalayam, S.; Tamadazte, B.; Allibert, G.; Paudel, D.P.; Demonceaux, C. Robust rgb-d fusion for saliency detection. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czechia, 12–15 September 2022; pp. 403–413. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–4 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Qu, Y.; Shao, Z.; Qi, H. Non-Local Representation based Mutual Affine-Transfer Network for Photorealistic Stylization. arXiv 2019, arXiv:1907.10274. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Wen, L.; Liu, X.; Wu, Y. Towards real-world prohibited item detection: A large scale X-ray benchmark. arXiv 2021, arXiv:2108.07020. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Volume 13, pp. 740–755. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Network Framework | Method | Contribute | References | Year |
|---|---|---|---|---|---|
| Firearms (17,419) | AlexNet | CNN using transfer learning | Higher detection performance and robustness | Akcay, etc. [4] | 2016 |
| GDXray (1950) | AlexNet GoogleNet | Compared to traditional machine learning methods | Deep learning methods achieve higher detection accuracy | Mery, etc. [5] | 2016 |
| Baggage security (11,627) | SW-CNN R-CNN Faster-RCNN | CNN for transfer learning | Improve real-time applicability of detection | Akcay, etc. [6] | 2017 |
| Baggage security (3080) | SSD | Design SSD detectors and tracking managers | Improve the multiobject detection accuracy | Han [15] | 2018 |
| Baggage security (12,700) | SSD | New feature maps generated by MF are fed into ATM and DCM | Better detection accuracy for multiple obstructed prohibited items | Zhang, etc. [16] | 2020 |
| Baggage security (550) | SSD | Lightweight network integration into feature pyramid layer | Better small object detection accuracy | Zhang, etc. [17] | 2020 |
| Baggage security (2026) | YOLOv5 | CBAM Incorporating adaptive feature fusion (ASFF) and attention mechanism (CBAM) | Higher accuracy of small object detection | Ren [18] | 2021 |
| SIXray (8900) | YOLOv4 | Adding attention mechanism to hollow dense convolutional modules | Better detection accuracy for multiple obstructed prohibited items | Mu, etc. [19] | 2021 |
| SIXray_OD (8718) | Faster-RCNN | Introducing dilation convolution to construct a multiscale detection network | Improving the detection accuracy of small object prohibited items | Kang, etc. [20] | 2022 |
| OPIXray (8885) HiXray (45,364), etc. | YOLOv5 | Add the CBAM attention mechanism | Improve detection capabilities for overlapping prohibited items | Dong, etc. [13] | 2022 |
| HiXary (9565) CLCXray (45,364) | YOLOv7 | Add Mobile NetViTv3 block | Reduce the missed detection rate of overlapping prohibited items | Li, etc. [14] | 2023 |
| Method | Backbone | Detection AP | Segmentation AP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Hard | Hidden | Overall | Easy | Hard | Hidden | Overall | ||
| Mask R-CNN | ResNet-101-FPN | 64.6 | 59.0 | 43.7 | 55.7 | 57.5 | 50.1 | 35.1 | 47.6 |
| Cascade Mask R-CNN | ResNet-101-FPN | 70.8 | 63.0 | 47.0 | 61.0 | 59.1 | 51.4 | 36.1 | 48.8 |
| SDANet | ResNet-101-FPN | 71.1 | 64.1 | 49.5 | 61.5 | 59.8 | 51.0 | 37.4 | 49.7 |
| YOLOv5 | CSP Darknet53 | 71.8 | 67.3 | 43.3 | 60.8 | - | - | - | - |
| RetinaNet | ResNet50 | 64.0 | 58.6 | 41.4 | 54.7 | - | - | - | - |
| DAMN | ResNet-101-FPN | 72.7 | 66.6 | 52.1 | 63.8 | 64.0 | 58.6 | 41.4 | 54.7 |
| Method | Channel Attention | Spatial Attention | Dependency Refinement | Detection AP |
|---|---|---|---|---|
| Cascade Mask R-CNN | 0.470 | |||
| A | √ | 0.492 | ||
| B | √ | 0.497 | ||
| C | √ | √ | 0.513 | |
| D | √ | √ | 0.502 | |
| E(DAMN) | √ | √ | √ | 0.521 |
| Method | Backbone | Detection mAP@0.5 | |||
|---|---|---|---|---|---|
| Easy | Hard | Hidden | Overall | ||
| Mask R-CNN | ResNet-101-FPN | 83.6 | 83.6 | 66.2 | 77.8 |
| Cascade Mask R-CNN | ResNet-101-FPN | 82.5 | 81.6 | 66.5 | 76.9 |
| SDANet | ResNet-101-FPN | 84.1 | 82.7 | 66.6 | 77.8 |
| YOLOv5 | CSP Darknet53 | 85.1 | 88.3 | 59.0 | 77.5 |
| RetinaNet | ResNet50 | 77.8 | 79.7 | 57.6 | 71.7 |
| DAMN | ResNet-101-FPN | 86.7 | 83.7 | 67.6 | 79.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, C.; Sun, S.; Yang, G. X-ray Detection of Prohibited Item Method Based on Dual Attention Mechanism. Electronics 2023, 12, 3934. https://doi.org/10.3390/electronics12183934
Li Y, Zhang C, Sun S, Yang G. X-ray Detection of Prohibited Item Method Based on Dual Attention Mechanism. Electronics. 2023; 12(18):3934. https://doi.org/10.3390/electronics12183934
Chicago/Turabian StyleLi, Ying, Changshe Zhang, Shiyu Sun, and Guangsong Yang. 2023. "X-ray Detection of Prohibited Item Method Based on Dual Attention Mechanism" Electronics 12, no. 18: 3934. https://doi.org/10.3390/electronics12183934