First, this section briefly explains the most relevant works to our study. After that, it describes the various types of KNN algorithms in the literature.
2.1. A Review of Related Literature
K-nearest neighbors (KNN) is a supervised machine learning method that can be utilized for both classification and regression tasks. KNN considers the similarity factor between new and available data to classify an object into predefined categories. KNN has been widely used in many fields such as industry [
7,
8,
9], machine engineering [
10], health [
11,
12,
13], marketing [
14], electrical engineering [
15], security [
16,
17,
18], manufacturing [
19], energy [
20,
21,
22], aerial [
23], environment [
24], geology [
25,
26], maritime [
27,
28], geographical information systems (GIS) [
29], and transportation [
30].
In the field of industry, the authors introduced a hybrid bag of features (HBoF) in [
7] to classify the multiclass health conditions of spherical tanks. In their HBoF-based approach, they extracted vital features using the Boruta algorithm. These features were then fed into the multiclass KNN to distinguish normal and faulty conditions. This KNN-based method yielded high accuracy, surpassing other advanced techniques. In [
8], the authors have reported that the KNN algorithm attained a great performance according to different evaluation metrics for predicting the compressive strength of concrete. Their model was highly recommended in the construction industry owing to the fact that it required fewer computational resources to be implemented. In another work [
9], a KNN-based method was developed to efficiently detect faults by considering outliers on the basis of the elbow rule for industrial processes. Similarly, in machine engineering, the authors presented a KNN-based fault diagnosis approach for rotating machinery, which was validated through testing on the bearing datasets [
10].
In the field of health, Salem et al. [
11] investigated a KNN-based method for diabetes classification and prediction that can contribute to the early treatment of diabetes as one of the main chronic diseases. The outperformance of their method was evaluated in terms of various metrics and approved its applicability in the healthcare system for diabetes compared to other techniques. In another work [
12], the researchers focused on an approach to early detect placental microcalcification by the KNN algorithm, which could lead to the improvement of maternal and fetal health monitoring during pregnancy. The results gained from real clinical datasets revealed the efficiency of the proposed model for pregnant women. In [
13], a wearable device was introduced on the basis of embedded insole sensors and the KNN machine learning model for gait analysis from the perspective of controlling prostheses. The results of applying the KNN algorithm showed the success of the device in predicting various gait phases with high accuracy.
In marketing, Nguyen et al. [
14] represented a beneficial recommendation system via KNN-based collaborative filtering, in which similar users according to their cognition parameters were effectively grouped to obtain more relevant recommendations in different e-commerce activities. In the field of electrical engineering, Corso et al. [
15] developed a classification approach for the insulator contamination levels by the KNN algorithm with high accuracy to predict insulating features as predictive maintenance of power distribution networks. In the field of security, a KNN-based technique was proposed in [
16] to classify botnet attacks in an IoT network. In addition, the forward feature selection was utilized in their technique to obtain improved accuracy and execution time in comparison to other benchmark methods. In [
17], a novel security architecture was provided to effectively deal with forged and misrouted commands in an industrial IoT considering different technologies, namely, KNN, random substance learning (RSL), software-defined network (SDN), and a blockchain-based integrity checking system (BICS). In another work [
18], an intrusion detection system (IDS) was implemented for wireless sensor networks by employing KNN and arithmetic optimization algorithms in that an edge intelligence framework was utilized for denial-of-service attacks in WSNs.
In the field of manufacturing [
19], Zheng et al. introduced a consensus model on the basis of KNN to classify cloud transactions regarding their priorities. In their model, different parameters, e.g., service level agreements (SLA), cloud service providers (CSP), cloud service consumers (CSC), and smart contract (SC) types, were utilized for distance calculation in the KNN algorithm. In the field of electrical energy [
20], a short-term load forecasting technique was proposed by the weighted KNN algorithm to achieve high accuracy for fitting the model. Similarly, in another work [
21], the authors focused on an effective KNN-based model for the failure diagnosis of wind power systems regarding particle swarm optimization. In [
22], the researchers investigated seismic energy dissipation for rocking foundations in the seismic loading process by means of different supervised machine learning algorithms, including KNN, support vector regression (SVR), and decision tree regression (DTR). The k-fold cross-validation was applied to the mentioned algorithms and, according to the results, KNN and SVR outperformed DTR in terms of accuracy.
In the aerial field, Martínez-Clark et al. [
23] represented a KNN-based method as a flock inspiration from nature for a group of unmanned aerial vehicles (UAVs). In their method, an optimal number of UAVs was obtained with regard to heading synchronization in drone implementation. In the environment field, a predictive model was developed in [
24] for the construction and demolition waste rate forecast by means of KNN and principal component analysis (PCA). In the field of geology, the authors [
25] reported that the KNN algorithm was utilized for a three-dimensional envision of the stratigraphic structure of porous media related to sedimentary formations. In a similar work in geology, Bullejos et al. [
26] implemented a technique for the evaluation of KNN prediction confidence in that the three-dimensional model for the stratigraphic structure of porous media is approved. The results of their KNN-based method contributed to improving the predictability of groundwater investigations.
In the maritime field, the authors [
27] introduced a novel trajectory model for offshore waters with the means of KNN and long short-term memory (LSTM) techniques for high-density and low-density trajectories, respectively. Their experimental results revealed that the mean square error is significantly decreased in comparison with the previous artificial-neural-network-based models. Another research [
28] in this area employed a KNN-based approach. The authors utilized the PCA method for predictive ship maintenance, with a specific emphasis on propulsion engines. In the field of GIS, the authors [
29] presented a predictive model with an ensemble KNN for typhoon tracks, which included supervised classification and regression applied on various samples of typhoons gaining experimental results with high accuracies and low running times. In the field of transportation [
30], the effect of missed data was detected through the KNN classifier for the prediction of traffic flow on public roads. Their results show that the presented method was efficiently applicable for smart transportation in urban traffic control.
2.2. A Review of KNN Variants
In the literature, researchers have provided various types of KNN algorithms considering their importance among other machine-learning-based models. Thanks to the advantages of KNN, it is considered as one of the highly recommended benchmark algorithms in machine learning for different applications, as discussed in the previous section. One of the KNN variants is uniform kNN [
31], in which a weighting scheme is considered based on the
k value. It means that the distances between a data point and its
k-nearest corresponding neighbors have the same impression on the prediction process. Another form of KNN is weighted kNN [
31], in that the generated weights through a weighting function are assigned to the
k-nearest neighbors of a data point. The idea behind this type of KNN is to provide greater weights for near data points and smaller weights for far data points, e.g., through a reverse function of the distance between points. Another algorithm, entitled the kNN learning method based on a graph neural network (kNNGNN) [
31], involves a weighting function in the KNN graph neural network for a specified data point to predict its class label.
Another type of KNN was introduced as k-min–max sum (k-MMS) [
32] regarding the remoteness of every
k neighbor from the previously chosen neighbors and the approachability of these
k neighbors to the sample, simultaneously. The k-Min Ranking Sum (k-MRS) [
32] is the other type of KNN algorithm, in that the neighbors are considered for a sample that is less than
k-nearest points to that sample. The other KNN variant is the k-nearest centroid neighborhood (k-NCN) [
33], in that the
k-nearest centroid neighbors of a sample are found, and the majority of obtained votes are assigned to the class of that sample with the aim of solving their ties in a random manner. Similarly, the nearest neighbor rule (NN) [
34] is another variant of KNN. In this classification method, the closest neighbors are allocated to a sample, and then the most probable class is determined via voting technique. Besides, various schemes are proposed for NN to improve its performance, e.g., sample weighting, geometric neighboring, and metric learning.
The other variant of KNN is the k-nearest feature line (k-NFL) [
35], which supposes that there are linearly self-reliant points to assign for each class in a minimum manner. Then, the feature points of that class are inferred via a predefined feature plane to calculate the final class points concerning distance calculation. Furthermore, the k-nearest neighbor line (k-NNL) [
36] was introduced based on the locally nearest neighborhood rule. In this algorithm, alleviation of the computational cost is considered in comparison with k-NFL because of computing just one feature line for every class. Other types of KNN were discussed in [
37], namely, k-center nearest neighbor (k-CNN) and k-tunable nearest neighbor (k-TNN). In the k-CNN model, the remoteness of a data point sample for all feature lines is calculated. After, the voting technique is utilized to select the most probable class among the k-closest feature line class labels. In this model, the leave-one-out error estimator is used for the computation of the most efficient values for
k. In the k-TNN model, sample data point distance from all feature lines is calculated through the TNN approach. Then, the
k-closest feature lines are identified, and the voting method is applied to them to specify the most probable classes. Similarly, the leave-one-out error estimator is applicable in the k-TNN model to determine the best
k values.
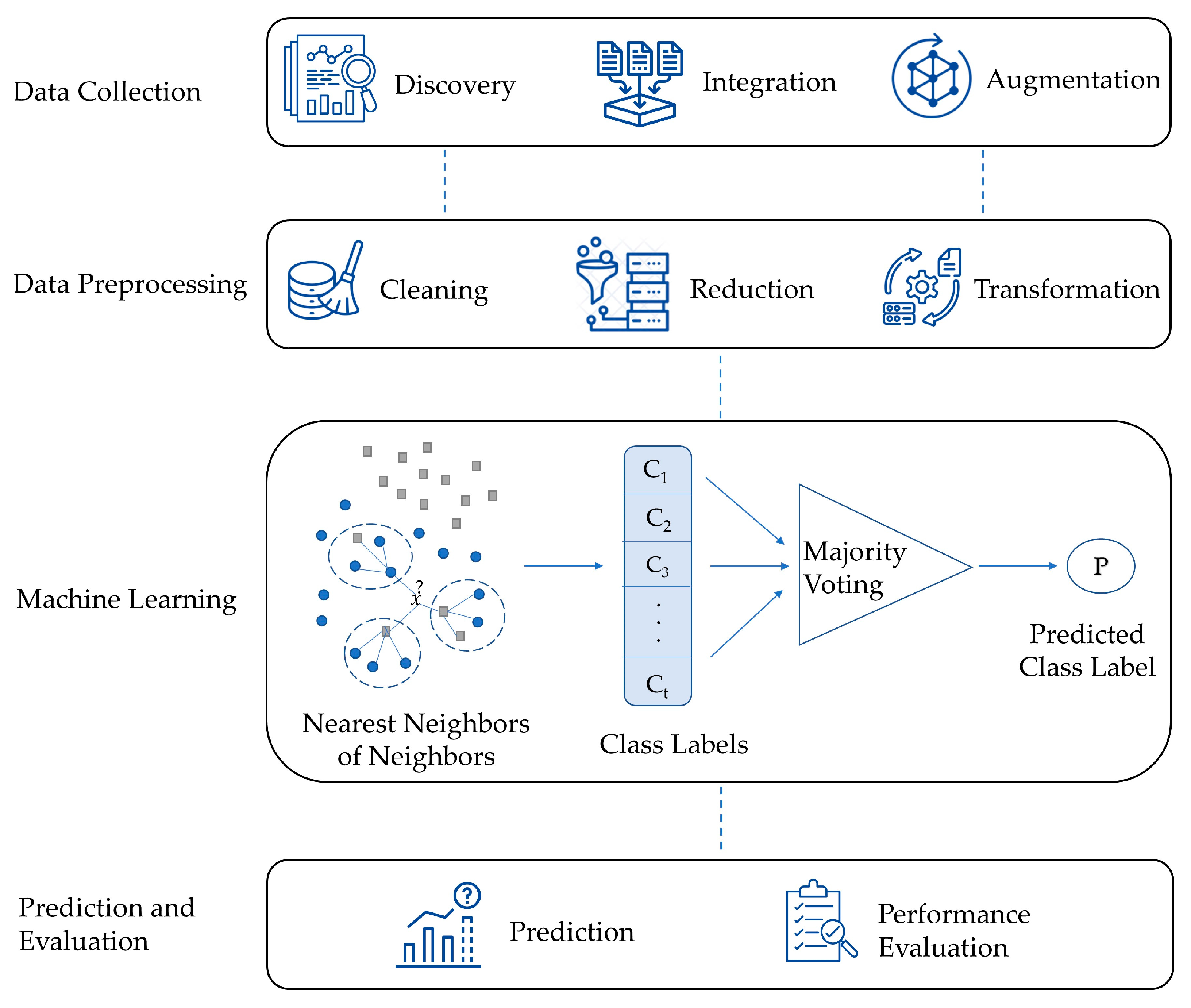
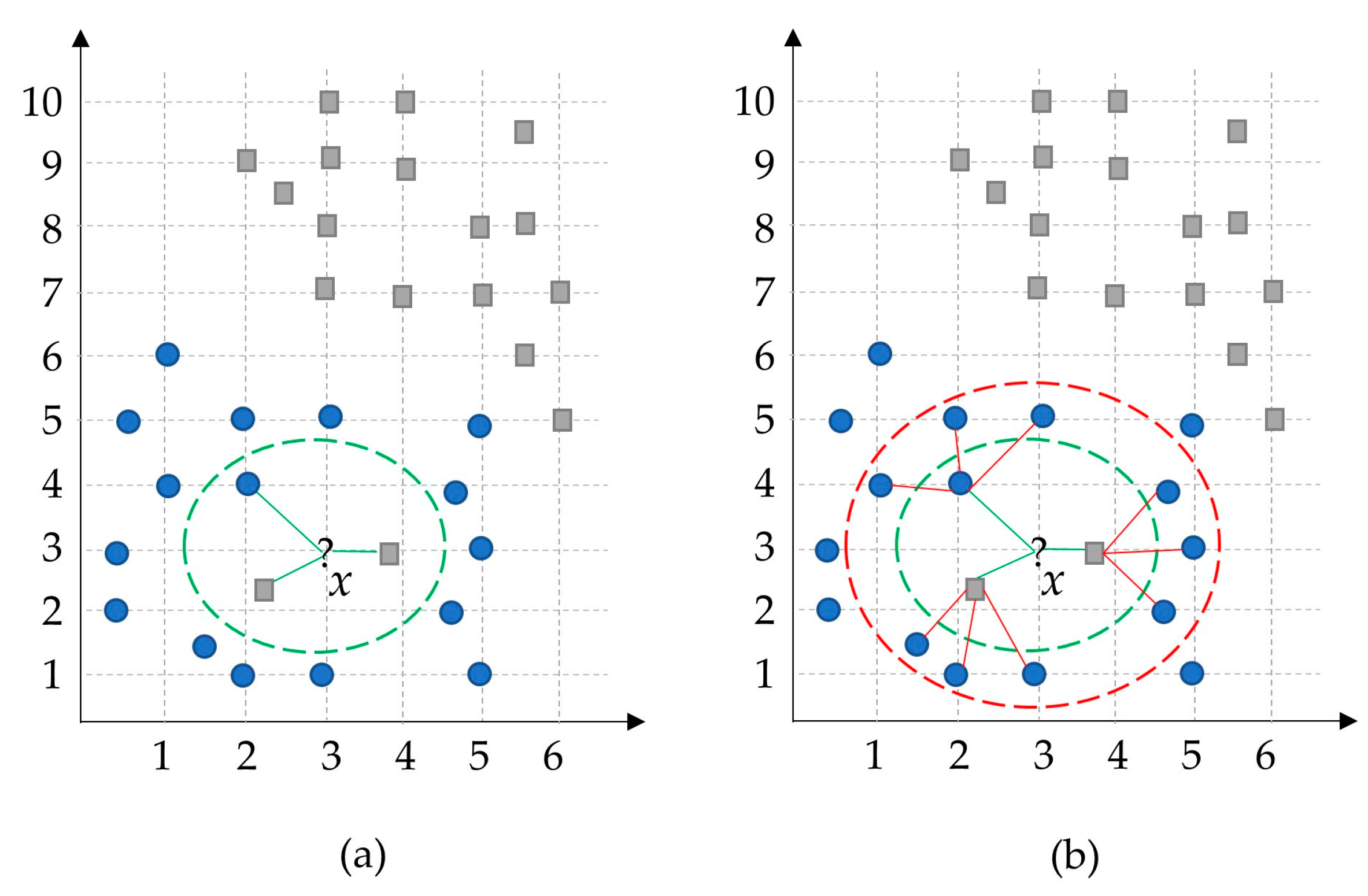
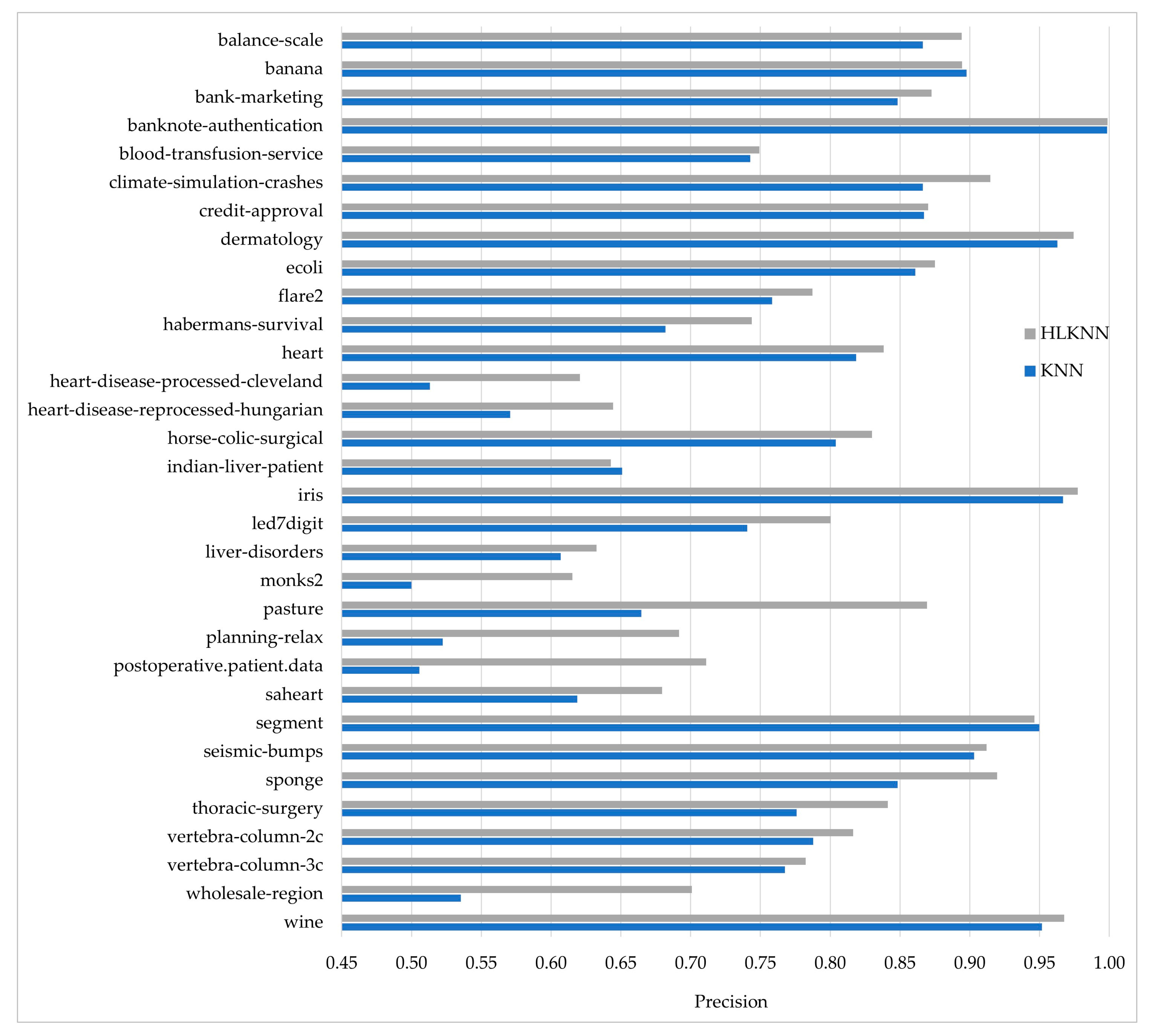
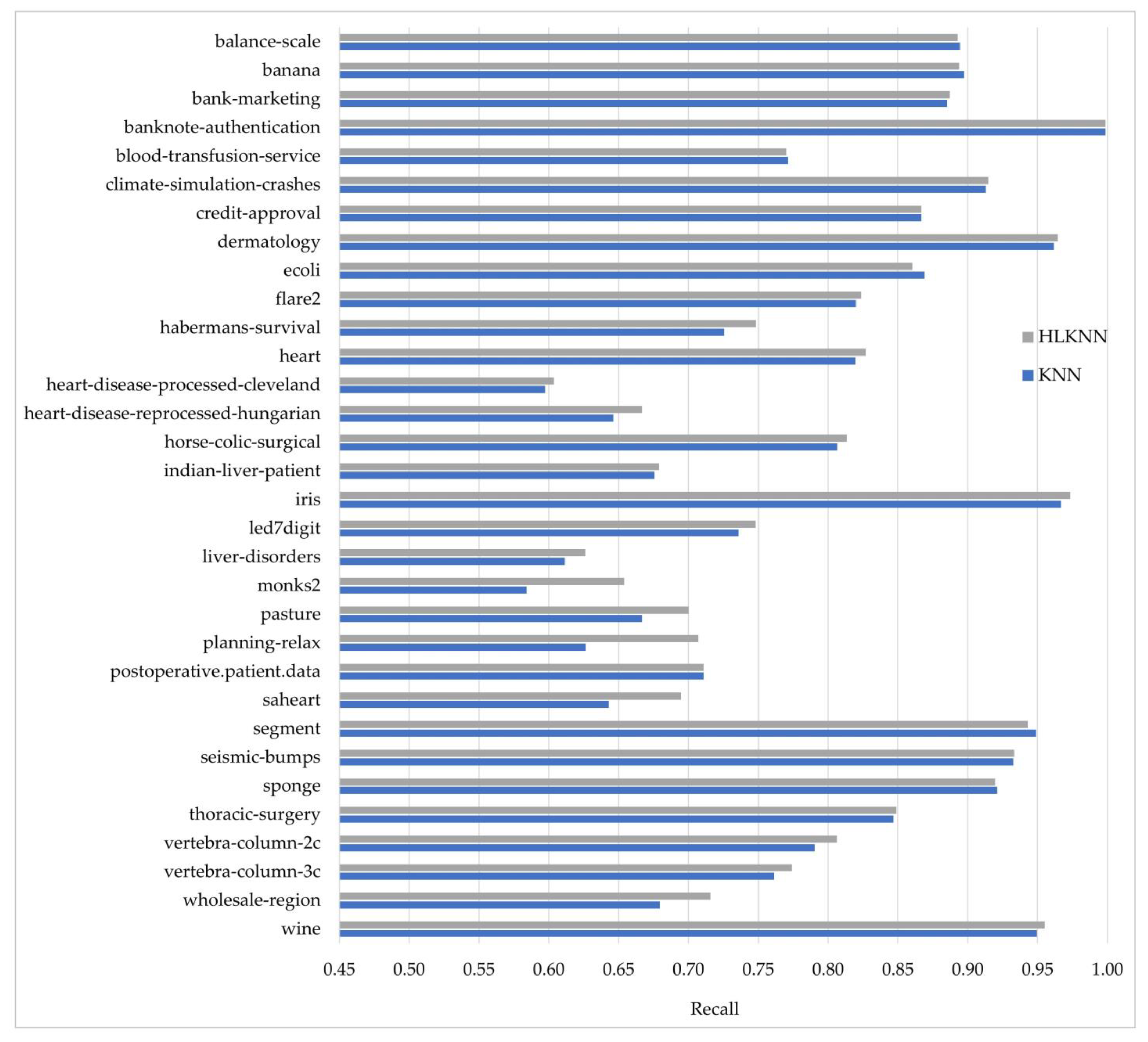
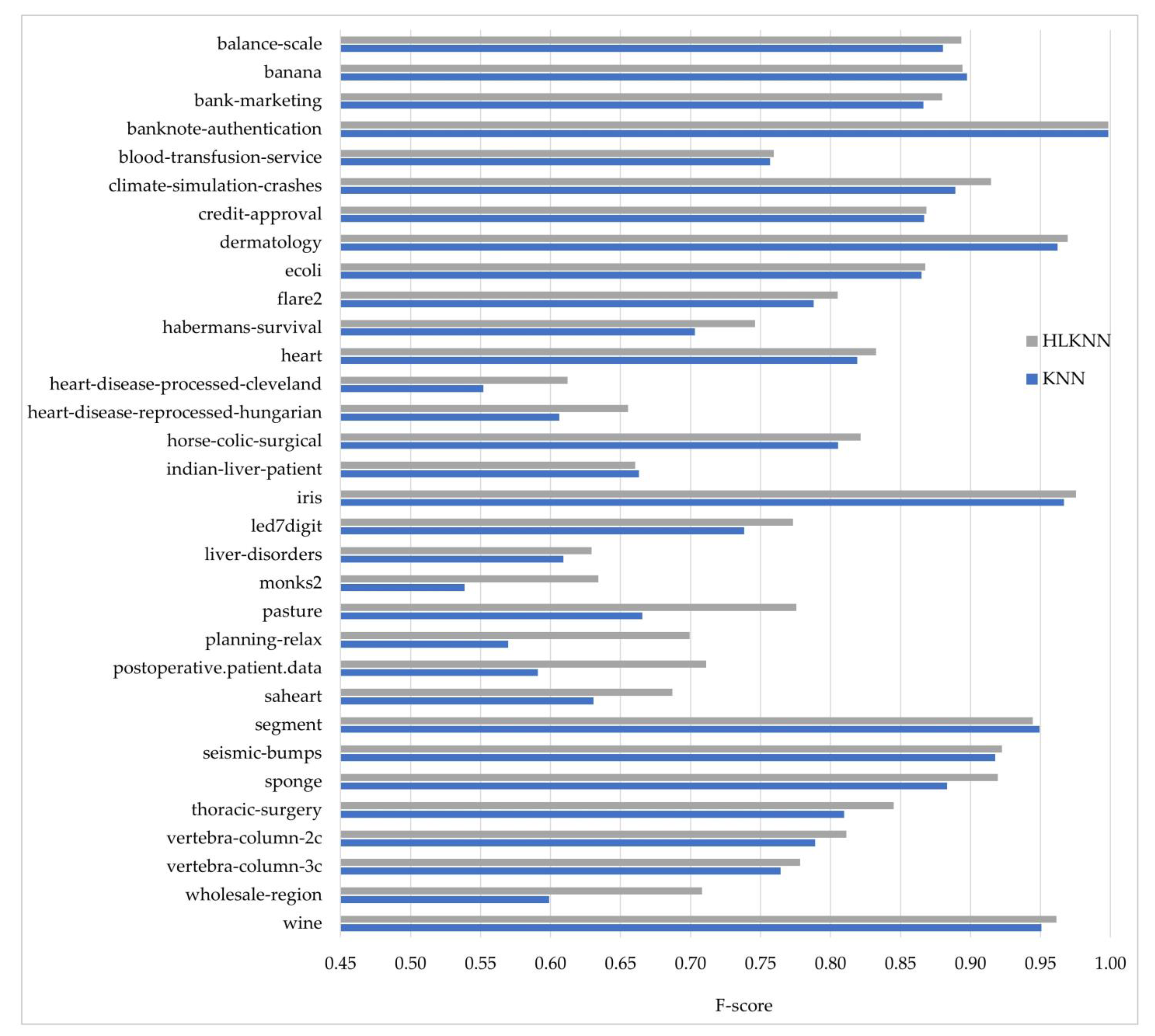
Our work is different from the previous studies in many respects. It presents a novel machine learning method, abbreviated as HLKNN. It proposes a different neighborhood searching mechanism. Instead of only considering k neighbors of a given query instance, it also takes into account the neighbors of these neighbors. It contributes to improving the accuracy of KNN and also other variants of the KNN algorithm in the literature.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}