1. Introduction
With the rapid development of information technology, scientific computing has permeated almost all fields of science and engineering, finding extensive applications in energy surveys, game rendering, meteorology and oceanography, finance and insurance, and computer-aided design, among others. Scientific computing in these fields often involves a considerable number of floating-point transcendental function computations, such as trigonometric functions (sine and cosine), inverse tangent functions, exponential functions, etc. These functions cannot be directly represented and computed using a finite number of basic mathematical operations, such as addition, subtraction, multiplication, division, and square root. Instead, they require mathematical transformations or iterative approximation methods to obtain approximate results. Moreover, different domains have varying requirements for numerical precision during the computation process. In modern digital communication systems, common modulation techniques like orthogonal frequency-division multiplexing and quadrature amplitude modulation use signal phase as a modulation parameter, making phase extraction techniques increasingly important. Phase detection can be achieved using the arctangent function. Additionally, arctangent calculations are frequently encountered in applications such as digital frequency modulation and demodulation, navigation communication, motor control, and image processing. As their applications become more widespread, there is an increasing demand to efficiently and accurately implement floating-point arctangent functions in hardware. Previously, the main focus of optimizing floating-point arctangent was at the software level, aiming to enhance operational efficiency through code optimization. Over time, significant progress has been made in software optimization efforts, but it has now reached a point of diminishing returns, with limited room for further improvement. Conversely, hardware-level optimization offers more significant potential for improvement compared to software. Utilizing hardware for calculating transcendental functions like arctangent will consume a certain amount of chip area, but it significantly enhances computational efficiency. With the advancement of IC manufacturing processes, the benefits of hardware-level optimization undoubtedly outweigh the drawbacks.
Compared to the software level, the computation of the arctangent function is not easily implementable in hardware. There are no simple function modules that can be directly called; instead, hardware algorithms for the corresponding complex functions must be designed. In the early hardware algorithms, the main methods used for function computation were lookup tables [
1,
2] and polynomial approximation [
3,
4]. The principle of lookup tables is straightforward, where input values correspond one-to-one with the computed results of transcendental functions. The hardware structure can be simple and easily implemented within a small range of angle values [
5]. However, when computing large angle values, a substantial amount of storage units is required, leading to inefficient resource utilization. On the other hand, the principle of polynomial approximation involves expanding the target function into a Taylor series within its domain, transforming the transcendental function into a series of power exponents, and approximating the function values numerically. But the use of Taylor series expansions involves a significant amount of multiplication and division, resulting in a large consumption of hardware resources [
6]. Moreover, in order to accelerate computation speed, polynomial approximation often utilizes fourth or fifth-order Taylor series convergence, leading to insufficient precision due to the limitations of the order. Later, a combined approach that combines lookup tables with polynomial approximation was proposed [
7]. This method effectively improves the efficiency of transcendental function computation, resulting in shorter operational cycles for the entire system. However, it requires the design of dedicated multipliers and adders, leading to a substantial increase in hardware circuit complexity and a significant increase in chip area. In summary, the aforementioned methods have drawbacks such as low computational efficiency, complex hardware resource requirements, and low computational precision.
To address the aforementioned issues, the Coordinate Rotation Digital Computer (CORDIC) algorithm was proposed in Reference [
8]. This algorithm approximates the target angle by rotating a predetermined fixed angle repeatedly. Since the fixed rotation angle is only dependent on the base and the number of rotations, computations of complex functions can be decomposed into simple shift and addition operations [
9]. Furthermore, the output precision of CORDIC is directly related to the number of iterations, offering adjustable output precision and a simple hardware implementation. To extend the range of basic functions that can be resolved, the unified CORDIC algorithms were introduced in Reference [
10], unifying circular, hyperbolic, and linear rotations into the same CORDIC iteration equation. This laid a solid theoretical foundation for designing a versatile CORDIC processor. In recent years, numerous researchers have made significant efforts to improve CORDIC algorithms by enhancing computational accuracy, expanding angle coverage, reducing the number of iterations, and minimizing resource consumption. In Reference [
11], a new micro-rotation angle set was used to achieve faster convergence and reduce the number of adders. However, its hardware implementation was challenging and did not achieve the desired precision. In Reference [
12], the TCORDIC algorithm was proposed, combining low-latency CORDIC with Taylor algorithms, utilizing sign prediction, compressed iteration, and parallel iteration techniques to reduce latency and errors at the boundary. However, it increased power consumption and area usage. In Reference [
13], the addition and subtraction operations in the CORDIC algorithm were executed in parallel using dedicated adders and subtractors, reducing latency but increasing resource consumption. In Reference [
14], a hardware implementation method that divides resources between addition and subtraction operations was proposed, but it added hardware overhead and latency. Reference [
15] presented a radix-4 CORDIC algorithm using a pipelined architecture, effectively balancing latency and hardware complexity. In Reference [
16], the number of CORDIC iterations and bit-width were chosen based on the relationship derived from software-based simulation, reducing area and latency. However, its maximum operating frequency was limited, and precision was not improved. In Reference [
17], an efficient CORDIC architecture based on the Ladner Fischer adder was proposed, but it consumed a significant amount of resources and was challenging to implement. In Reference [
18], an approximation and lookup table strategy were utilized to increase data throughput but resulted in increased circuit area. In Reference [
19], a scheme with dual-iteration sign prediction and multiplexer compression was proposed to reduce latency and control area, but precision improvement was not achieved. In Reference [
20], a new hybrid algorithm for sine and cosine functions minimized the number of steps, reducing hardware volume and potential computation delay but significantly increasing the occupied ROM area. Reference [
21] proposed a two-step branch CORDIC algorithm, where two branches execute different operations at each step, reducing computation cycles compared to the traditional CORDIC algorithm. In Reference [
22], a CORDIC algorithm with rotation gain compensation was introduced, achieving a good trade-off between approximation error and resource consumption. However, its gain compensation had constant errors, limiting the precision of the algorithm. In Reference [
23], a prediction circuit was included to select the most suitable predefined angle for iteration, reducing the number of iterations, but it only focused on phase and did not consider amplitude, and the maximum displacement count remained unchanged. In Reference [
24], the Z-path was transformed into a lookup table to reduce circuit area consumption, but it did not improve calculation accuracy and speed. In Reference [
25], resource consumption was reduced using a rough approximation method based on the traditional CORDIC algorithm, but output precision was compromised. In Reference [
26], angle interval folding, optimal predefined angle selection, and omission of certain predefined angles were employed to narrow the iteration range and unify vector rotation direction. This achieved low resource consumption and short computational cycles but lacked sufficient precision improvement. Reference [
27] proposed a low-latency hybrid CORDIC algorithm, further optimizing the computation cycle, significantly reducing the number of iterations. The comparative outcomes of the aforementioned research findings are illustrated in
Table 1.
From the analysis of the above literature, it can be observed that the current research on floating-point arctangent functions still exhibits drawbacks such as low computational precision, a high number of iterations, and slow execution efficiency. Moreover, to the best of our knowledge, there is currently no existing 128-bit floating-point arctangent arithmetic unit in this field. Therefore, these issues are addressed in this paper by studying the computational strategy for high-precision floating-point arctangent functions, thus filling the research gap in this area. The main contributions of this paper are as follows:
An improved CORDIC algorithm is proposed, utilizing a four-step parallel branch iteration strategy to reduce the number of iterations in the arctangent algorithm and decrease the output latency;
The improved CORDIC algorithm is applied to the calculation of a 128-bit high-precision floating-point arctangent function, resulting in improved computational precision while reducing computational complexity;
The 128-bit high-precision floating-point arctangent algorithm is implemented in hardware, making it suitable for the design of dedicated chips for high-precision CORDIC algorithms.
The organization of this paper is as follows: In
Section 2, the fundamental CORDIC algorithm is introduced and improved. A four-step parallel branch iteration CORDIC algorithm is proposed and applied to the calculation of a quad-precision floating-point arctangent function. In
Section 3, the hardware circuit implementation and optimization of the quad-precision floating-point arctangent function are presented. In
Section 4, the circuit simulation results are compared and analyzed with the standard calculations from Python’s bigfloat package, and FPGA and ASIC implementations of the hardware circuit are performed. Finally, conclusions are presented in
Section 5.
2. CORDIC Algorithm and Improvement
2.1. IEEE 754 Floating-Point Standard
For floating-point computation, the Institute of Electrical and Electronics Engineers (IEEE) proposed the IEEE-754 floating-point standard in 1985, and the latest version was released in 2008 [
28]. The IEEE-754 standard defines floating-point numbers as composed of three parts: the sign bit, exponent part, and mantissa part, represented in scientific notation as shown in Equation (
1).
Here,
S represents the sign bit,
E represents the value of the exponent part, bias is a fixed offset value,
M represents the value of the mantissa part, and 1.
M is the actual value used for computation, composed of the mantissa part value
M and 1 hidden bit of precision. Floating-point numbers of different precisions have different bias values, as well as varying widths for the exponent and mantissa parts, resulting in different ranges for representing fixed-point numbers. The parameters of different precision floating-point numbers are shown in
Table 2.
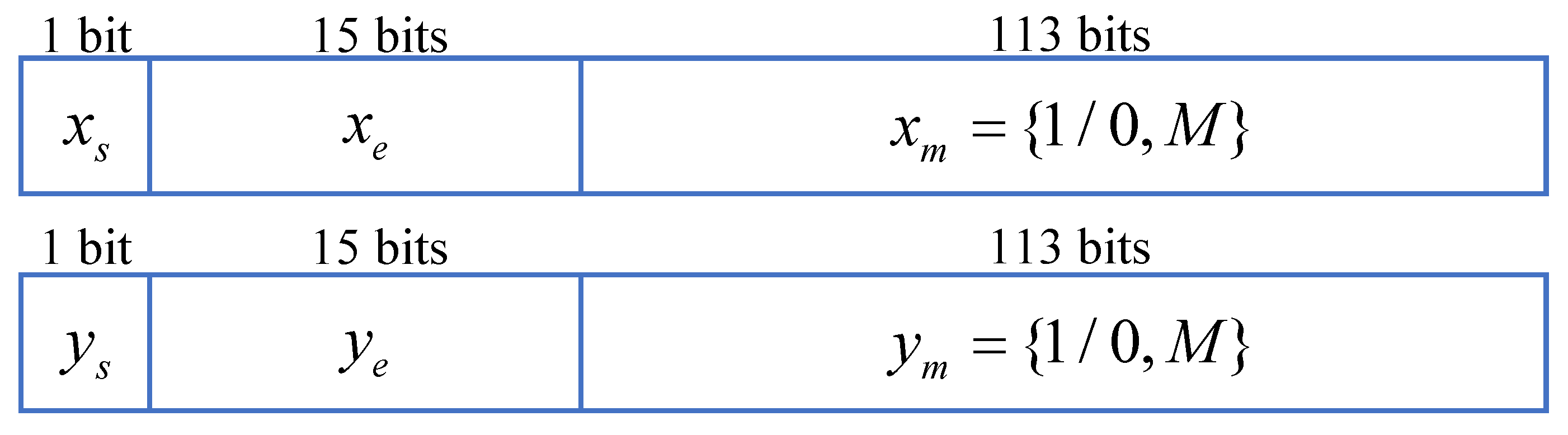
With the rapid development of integrated circuits, high-performance processors increasingly rely on high-speed and high-precision floating-point computations. Consequently, single-precision and double-precision floating-point calculations are no longer sufficient to meet the requirements. Therefore, this paper focuses on studying floating-point arctangent computation under quad-precision conditions. The format of normalized quad-precision floating-point numbers is illustrated in
Figure 1.
Furthermore, based on the different values of
E and
M, IEEE-754 classifies floating-point numbers into various types, as shown in
Table 3. In the subsequent arctangent computation, it is essential to perform the detection and handling of exceptions and special inputs according to the specified floating-point number types listed here.
2.2. Basic CORDIC Algorithm
In Reference [
8], the CORDIC algorithm was first proposed. Its principle involves rotating the initial vector in different directions by specific angle values within a given coordinate system to iteratively approach the target vector infinitely. In the polar coordinate system, the iterative formula of the CORDIC algorithm is given by Equation (
2), where (X,Y,Z) represents the intermediate iteration values of the three channels,
is the rotation factor and
, and it determines the rotation direction for each iteration. The value of
can be either 1 for counterclockwise rotation or −1 for clockwise rotation.
represents the rotation angle for each iteration, satisfying Equation (
3). During the hardware circuit implementation, each value of
is pre-stored in a lookup table with a specific precision.
In vector mode, the goal of iteration is
, which is to rotate the initial vector
to align with the
x axis. Upon completion of the iteration, the final iteration values for the three channels are given by Equation (
4). In this equation,
represents the correction term during the iteration process, which satisfies Equation (
5).
Therefore, by initializing with the appropriate values for the three channels, the final values of Z at the end of the iteration represent the result of the arctangent function .
Through analysis, it can be observed that, for quad-precision floating-point number computations, the traditional CORDIC algorithm faces a bottleneck. This is because each iteration’s rotation factor needs to wait for the result of the previous iteration for prediction, limiting the algorithm to a single-step iteration. In other words, only one iteration can be performed in each clock cycle, yielding 1-bit precision. Consequently, to achieve 113-bit precision, it would require 113 clock cycles, resulting in slow computation speed. Therefore, the following sections focus on addressing this issue and proposing improvements to the traditional CORDIC algorithm.
2.3. Four-Step Parallel Branching Iteration CORDIC Algorithm for Four-Precision Floating-Point Arctangent Function
In order to address the issue of slow computation speed in the traditional CORDIC algorithm, a four-step parallel branching iterative CORDIC algorithm suitable for arctangent functions is proposed in this paper. The algorithm is designed by taking into account both the complexity of circuit design and the efficiency of computation.
Unlike the method in Equation (
2) where each of the three channels
undergoes only one iteration based on the rotation factor, we adopt the concept of trading area for time and serial to parallel conversion. By performing four iterations in parallel within one clock cycle, the overall computation efficiency is improved fourfold. Below is the derivation of the four-step parallel branching iterative formula for the three channels
. For channel
X, after four iterations, we substitute the results into Equation (
2) successively, leading to Equation (
6):
Similarly, for both channel
Y and channel
Z, Equations (7) and (8) can be derived.
Thus, we obtain the of the three channels after each cycle iteration in the four-step parallel branch iteration algorithm. It can be observed that the key to successful iteration lies in accurately predicting the rotation factor simultaneously. According to formula (4), the CORDIC algorithm for arctangent aims to rotate vector to the x axis, and the prediction of the sign is determined by the sign bit from the previous iteration. In this algorithm, the value range of is determined as , where 0 indicates that after this iteration, the algorithm will cross the x axis without rotation, and −1 indicates that after this iteration, the algorithm will still not cross the x axis, requiring a clockwise rotation. Therefore, such value assignment ensures that remains in the first quadrant, avoiding crossing the x axis, and it causes some coefficients in the expression of to be 0, effectively reducing the algorithm’s complexity and saving hardware circuit area.
When the range of
is considered to be
, all its possible results fall within the range of
to
. As for the iterative expression of
, the potential outcomes of the 16 branches are shown in
Table 4. Completing these 16 branch computations requires a total of 32 additions and subtractions, 16 multiplications, and 21 shift operations.
The 16 potential branch results for the iterative expression of
are shown in
Table 5.
The 16 potential branch results for the iterative expression of
are shown in
Table 6.
In the prediction of the rotation factor, for each iteration, can be predicted. In the calculation of the arctangent function, the simplest method is to directly compare the 16 potential branch results of the Y channel and select the one with the absolute value closest to 0. However, if this method is used, a significant amount of area will be consumed, and considerable delay will be introduced in the subsequent hardware circuit design. Therefore, a faster and more area-efficient method is adopted in this paper.
It is known that the value of
determines whether
requires a clockwise rotation or no rotation to approach the
x axis, while
approaches 0. By examining the highest sign bit of
in each iteration, we can determine whether the
after rotation crosses the
x axis. As shown in
Figure 2, the
_
represents the highest sign bit of 16 branches of
, and from left to right is the
corresponding to
from
to
(for the convenience of drawing, −1 is replaced by 1 here). According to Equations (3) and (8) and
Table 6, the 16 branches of
are arranged in ascending order. Therefore, if the left prediction branch has
as a negative number (the rotation will cross the
x axis), then the right prediction branch will have
as a negative number. Thus, we can ascertain that the values in
_
will appear in consecutive 0s or consecutive 1s. Based on this principle, in order for
to approach 0 without crossing the
x axis, a successful prediction
must be located at the boundary between 0 and 1 in
_
, as indicated by the red mark in
Figure 2. Subsequently, we can use the predicted rotation factor
to select the corresponding
and
from
Table 5 and
Table 6. With this, one cycle of the four-step parallel branch iteration is completed.
3. Hardware Circuit Implementation of a Four-Precision Floating-Point Arctangent Function
3.1. Top-Level Module
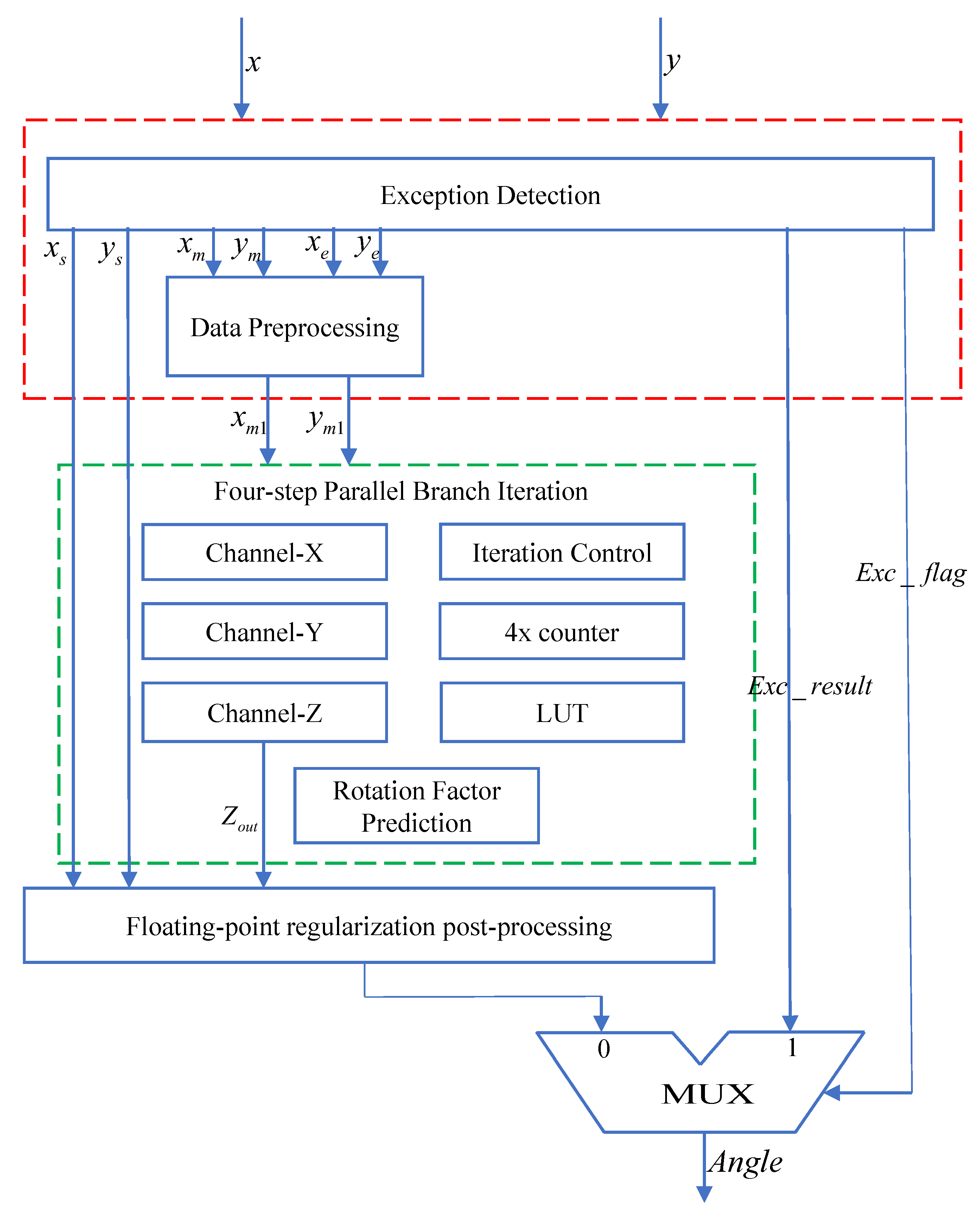
According to the proposed four-precision floating-point arctangent function’s four-step parallel branch iterative CORDIC algorithm, the entire hardware circuit structure mainly consists of three modules: the exception detection and pre-processing module, the four-step parallel branch iteration module, and the floating-point normalization module.
The exception detection and pre-processing module first splits the normalized 128-bit four-precision floating-point input values
x and
y. Then, based on
Table 3 and the arctangent function’s curve, it performs exception detection on the split data. If any exceptions are detected, it outputs the exception flag signal Exc_flag and the result of the exception handling Exc_result. Subsequently, the four-step parallel branch iteration module predicts the rotation factor
and iteratively calculates the three channels
. After completing the iterations, it processes the output results of the
Z channel, converting them from fixed-point to standard four-precision 128-bit floating-point output. Finally, based on the exception flag signal, the module selects the final arctangent result for output.
The hardware structure of the top-level module is illustrated in
Figure 3.
3.2. Exception Detection and Pre-Processing Module
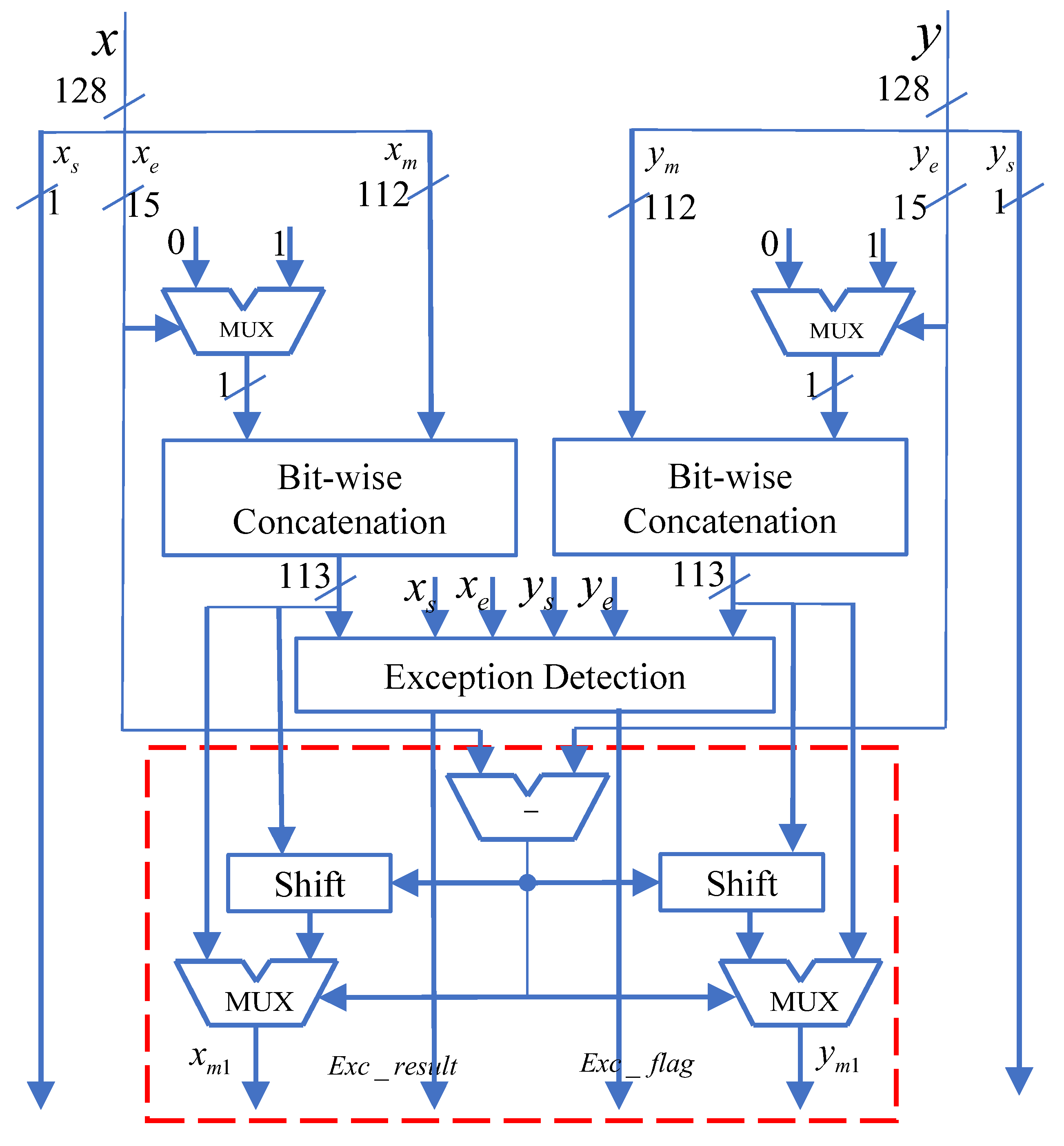
The exception detection and pre-processing module first detects and handles exceptional and special inputs. If the inputs are valid, the module proceeds to pre-process the two input values to ensure they fall within the calculable region of the CORDIC algorithm.
During the process of detecting exceptional and special inputs, the normalized 128-bit floating-point numbers,
and
, are first split into their respective components: the sign bit, the exponent part, and the fraction part with an added hidden precision bit, as shown in
Figure 4. The split data is then subject to exceptional input detection. When exceptional or special inputs are detected, the Exc_flag is set to 1. The possible types of exceptional and special inputs are outlined in
Table 7.
In the data pre-processing module, in order to enhance the computational precision, both and are extended by 15 bits. Simultaneously, for the computation of the arctangent function, in this design, all input vectors are transformed into the first quadrant, and and are used as quadrant identifiers. Additionally, based on the magnitude of and , the following processing is performed to convert the two floating-point numbers into fixed-point numbers without altering their proportional relationship, facilitating subsequent iterative calculations.
(1) When is true, is right-shifted by bits to obtain , and is assigned to .
(2) When is true, is right-shifted by bits to obtain , and is assigned to .
Here, if is true, then during the shift operation on , it will exceed 128 bits, resulting in becoming 0 after the shift. At this point, ’s value approximates , and based on the value of , Exc_result is set to or . Similarly, if is true, then during the shift operation on , it will exceed 128 bits, causing to become 0. As a result, the iterative process of this arithmetic component will not execute, and Exc_result is set to 0.
The circuit structure of the exception detection and pre-processing module is illustrated in
Figure 5.
3.3. Four-Step Parallel Branch Iteration Module
The four-step parallel branch iteration module is the core component of the floating-point arctangent function computation unit, which implements the aforementioned four-precision floating-point arctangent function using the four-step parallel branch iterative CORDIC algorithm. This algorithm prioritizes speed over area, employing a single-level loop structure. Its input signals originate from and of the exception detection and pre-processing unit. Through multiple iterations, the module performs parallel computations for the three channels and outputs the arctangent result. Finally, this result, combined with the sign bit preserved by the exception detection and pre-processing unit, is forwarded to the floating-point regularization post-processing module to obtain the final angle value.
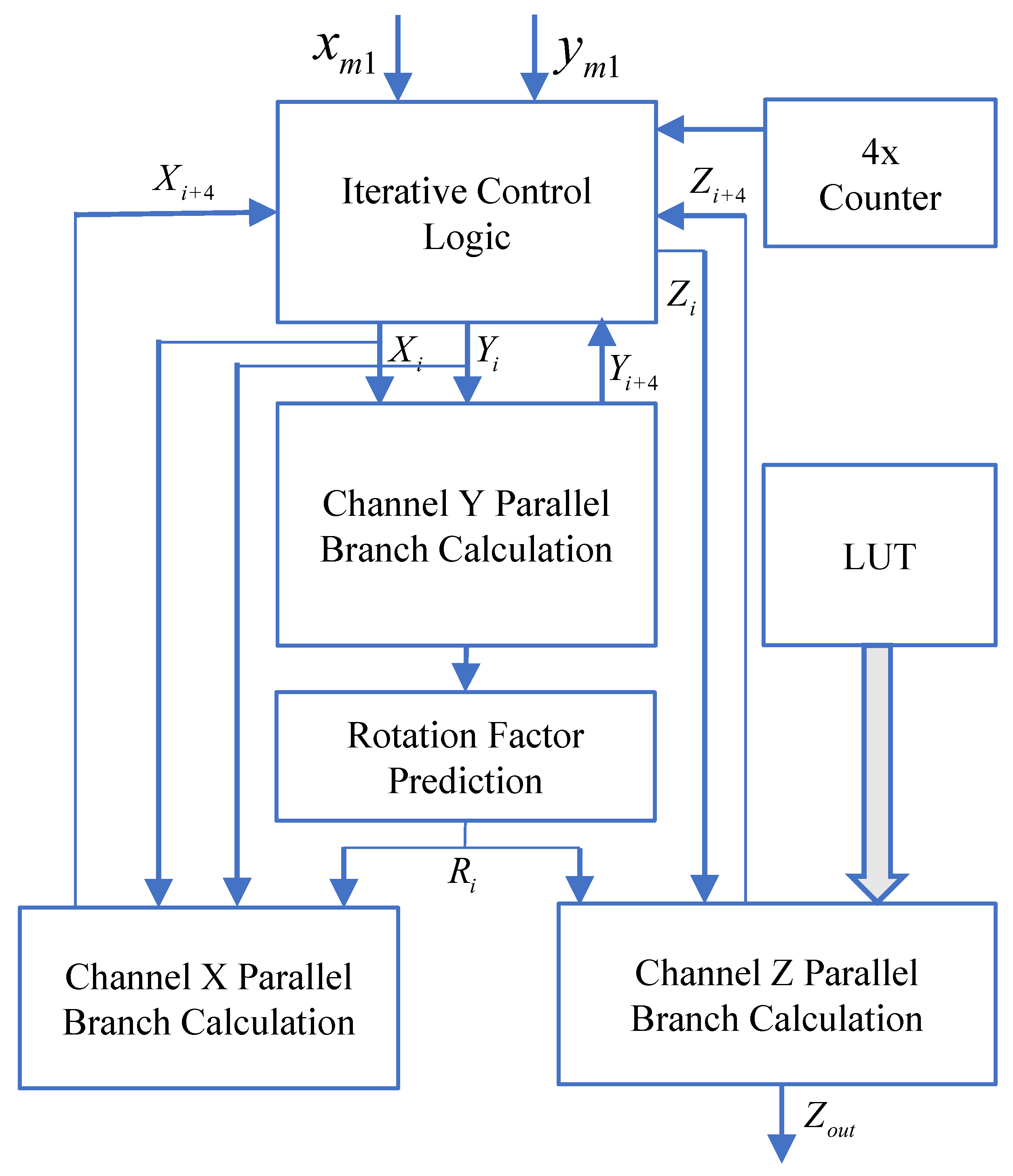
The hardware structure of the four-step parallel branch iteration module is illustrated in
Figure 6. It includes a counter, iteration control logic, Y-channel parallel branch computation module, X-channel parallel branch computation module, Z-channel parallel branch computation module, lookup table (LUT), and rotation factor prediction module. In each iteration, the Y-channel first performs parallel computations for 16 predicted branches. Then, the rotation factor prediction module selects the branch
in the Y-channel that is closest to zero and does not cross the x-axis, obtaining the corresponding value
=
. Based on
, the module selects the corresponding branch results
and
from the X-channel and Z-channel.
3.3.1. Calculation of 16 Branches for X and Y Channels
Through
Table 4 and
Table 5, it can be observed that among the 16 predicted branches in the Y-channel and X-channel, there are numerous multiplication terms involving the same constant coefficients. To address this issue of multiple-constant multiplication (MCM), a dedicated independent MCM module is designed in this paper. Taking the Y-channel as an example, the split results of the MCM required for its 16 predicted branches are presented in
Table 8. Initially, the input
y undergoes the first-level constant multiplication, where the constants are all powers of 2, readily obtainable through bit shifting. Furthermore, the second-level constants depend on the results from the first level, while the third-level constants necessitate the utilization of the split results from the previous two levels. Thus, by employing appropriate combinations of addition, subtraction, and bit shifting operations, all multiplication terms with their respective constant coefficients can be derived. This method fully utilizes the split results of earlier levels, reducing the number of computations compared to the use of multiple single-constant multipliers. As a result, it addresses the bottleneck issue caused by extensive multiplication calculations, accelerates computation speed, and minimizes area consumption.
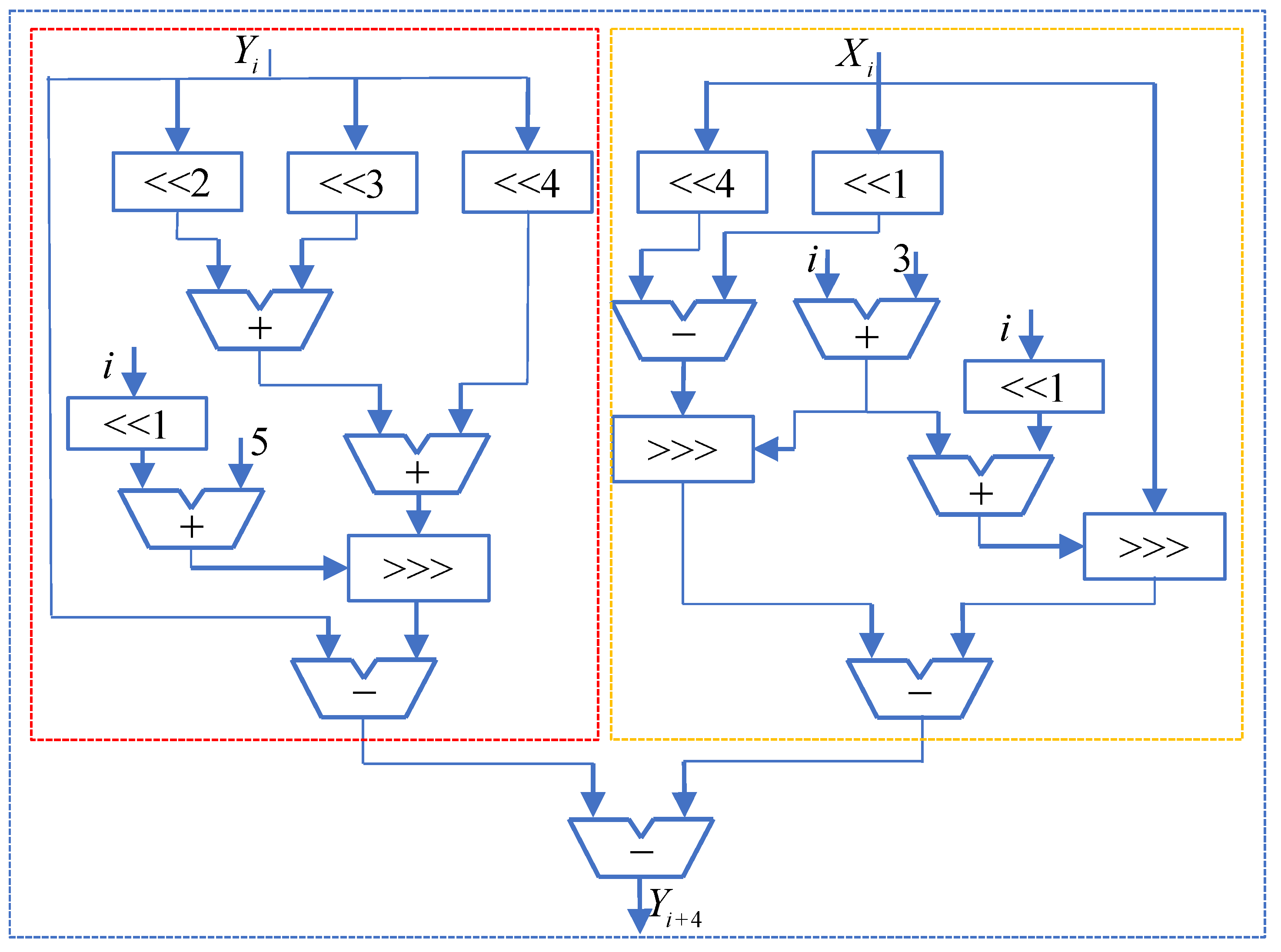
Taking the Y-channel as an example, the specific branch computation structure is provided based on the rules of multiple-constant splitting and the corresponding iterative expressions for
. In
Figure 7, the computation process for the 15th branch
is illustrated. Initially,
and
are fed into the Multiple-Constant Multiplier module. Then, based on the add-4 counter, a shift operation is performed, enabling
and
to undergo a left-shift operation before a subsequent right-shift operation. This approach reduces bit loss and effectively enhances precision. To minimize critical path delay, the first two and last two terms of this branch are computed in parallel, followed by a subtraction operation to obtain the final result. The computation principles for the other 15 branches are similar. Similarly, results can be obtained for the 16 branches in the X-channel.
3.3.2. Calculation of 16 Branches for Z-Channel
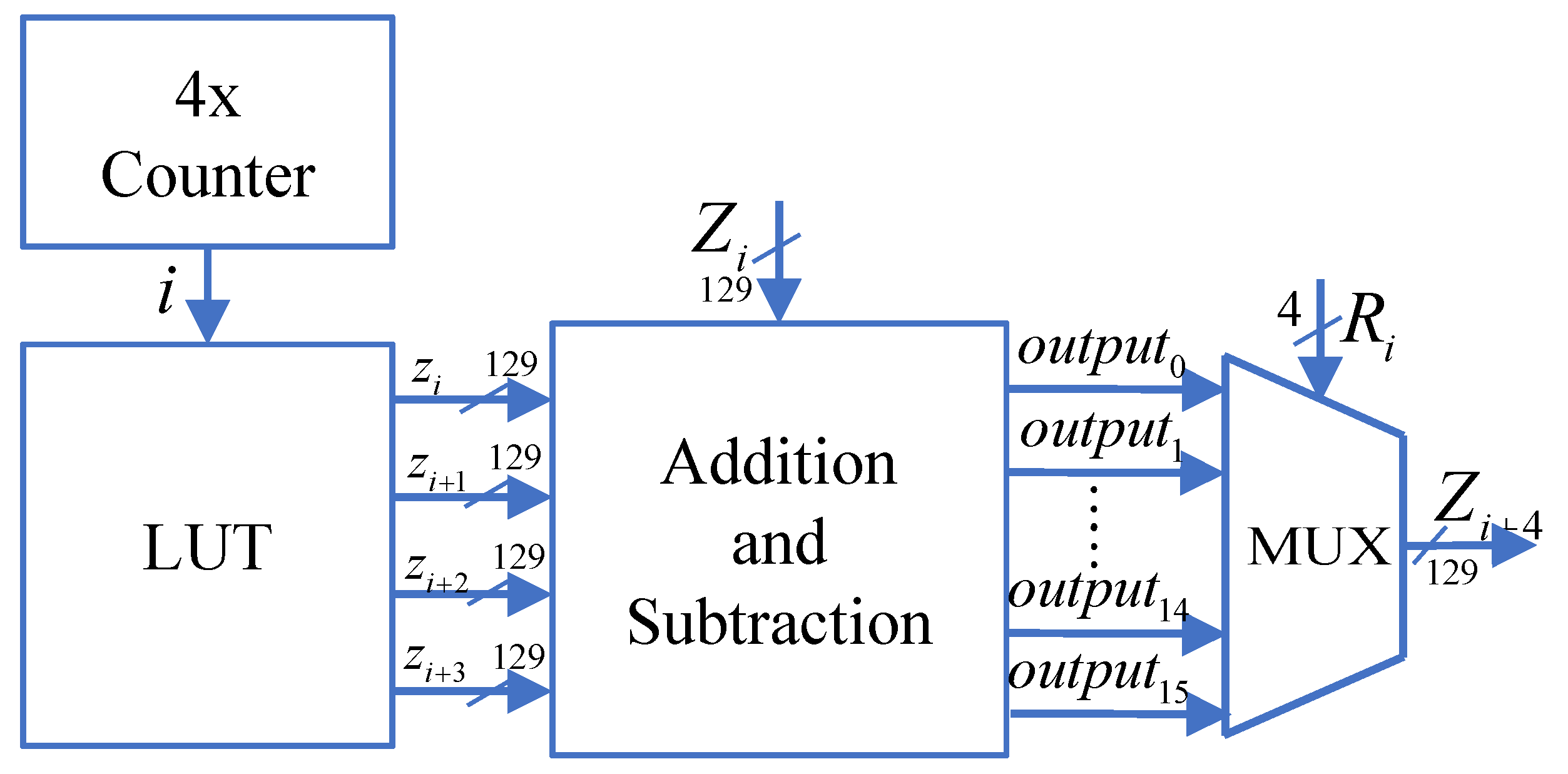
In
Table 6, the 16 predicted branches of the Z-channel are obtained through addition and subtraction operations based on precomputed four angles using rotation factors. These four angles are indexed using the output of the add-4 counter and obtained from the lookup table. The lookup table has a bit width of 129 bits, with the highest bit set to 0, preparing for signed addition and subtraction operations in the Z-channel. The precomputed values placed in the lookup table correspond to
,
,
and so on. Since all calculations are performed using fixed-point representation, each floating-point arctangent value needs to be converted into fixed-point format before being stored in the lookup table. For a decimal fraction less than 1, its corresponding binary floating-point representation, as shown in Equation (
8), can be truncated to the fractional part to obtain the corresponding fixed-point value. Then, by appending a leading 0 to the highest bit, a 129-bit fixed-point value for the lookup table is obtained, as illustrated in Equation (
9).
The computation block diagram for the Z-channel is illustrated in
Figure 8.
3.3.3. Twiddle Factor Prediction Module
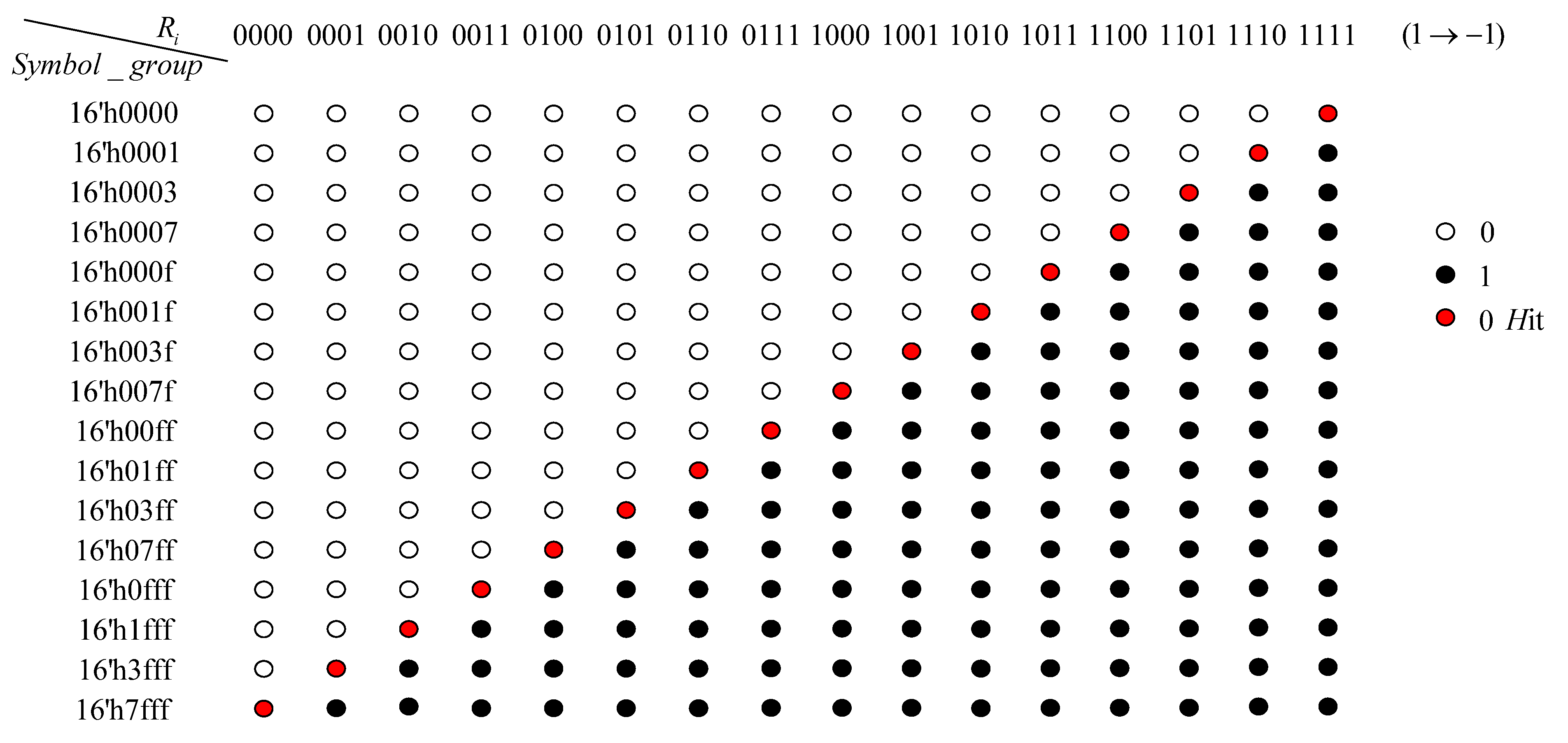
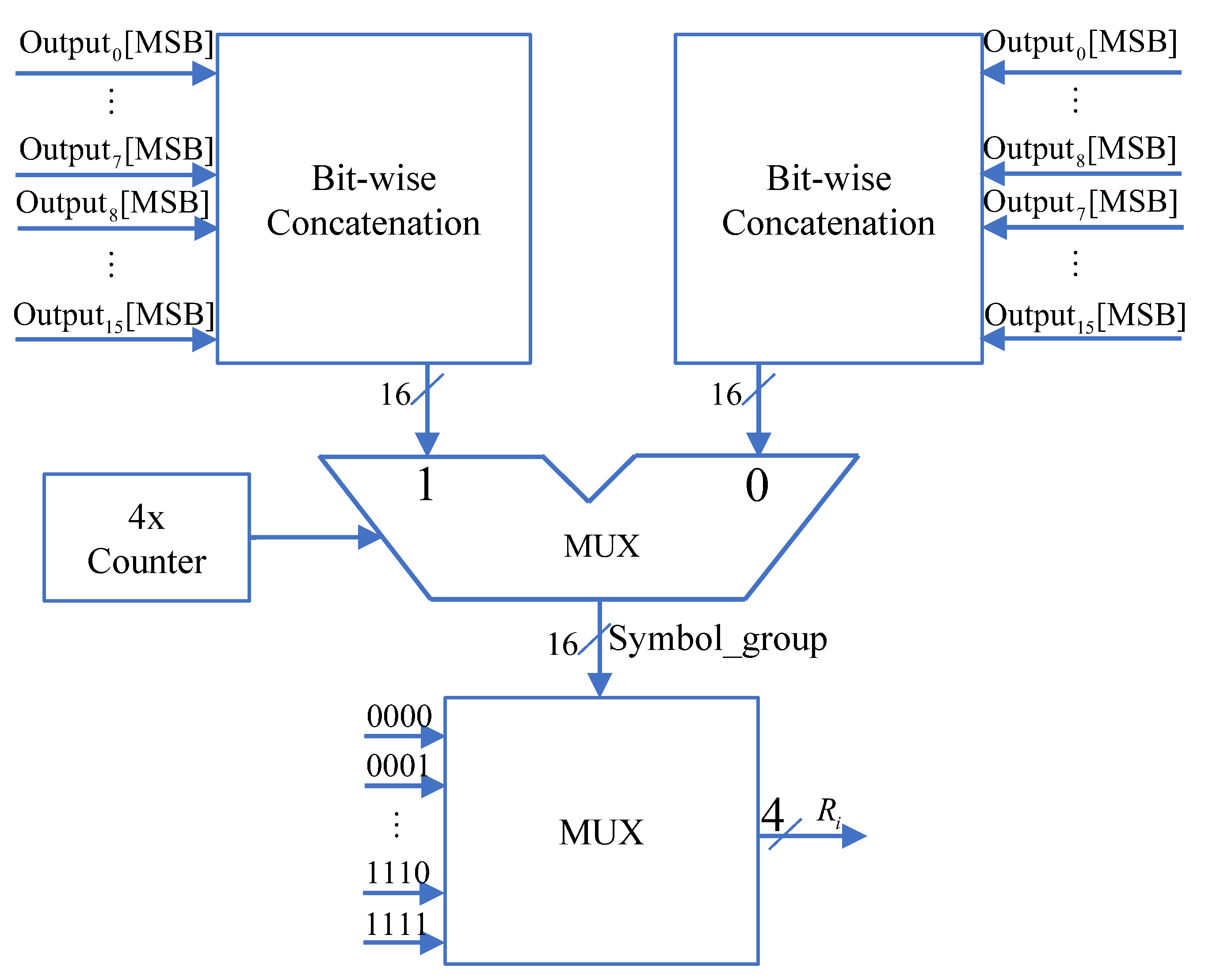
Based on the prediction strategy shown in
Figure 2, the highest sign bit of the 16 predicted branches of
, is combined to form a 16-bit Symbol_group selection signal. Subsequently, according to this selection signal, the corresponding rotation factor
=
is outputted. The relationship between Symbol_group and
is presented in
Table 9. Finally, based on the successfully predicted rotation factor, the corresponding
is selected as the output result for this iteration.
As
=
varies from (0, 0, 0, 0) to (−1, −1, −1, −1) incrementally, due to
, the values of
to
, combined with the results of the 16 predicted branches in
Table 6, are arranged in ascending order. However, there is a special case where
exists during the first iteration, causing
. As a result, in the first iteration, the highest sign bits of the two
corresponding to these
should be swapped to ensure that the value of Symbol_group consists of consecutive 0s and consecutive 1s. The hardware structure of the rotation factor prediction module is illustrated in
Figure 9.
From
Table 8, it can be observed that the maximum constant coefficient in the multiplier is 35. To ensure that the computation process does not result in overflow errors, 6 additional bits should be reserved in
and
. Moreover, since the current design employs signed arithmetic for addition and subtraction, consideration should be given to a sign bit and an additional carry bit. Thus, before entering the four-step parallel branch iteration module,
and
should be padded with 8 bits at the high end to prevent overflow. As the precision of the CORDIC algorithm improves with increasing iteration count, the selection of an appropriate bit width is essential to enhance the precision of the computational results while considering area consumption. Through debugging, this design includes a compensatory bit width of 15 bits appended to the tails of
and
, resulting in their final bit width being set to 136 bits. Since
involves only addition operations, the lookup table can be set to 128 bits, and adding a carry bit leads to
being set to 129 bits. Thus, each computation requires (113 + 15)/4 = 32 iterations, where 113 represents the fraction bit width and 15 is the compensatory precision. After the completion of 32 iterations, the iterative process concludes, and the output value of Z-channel represents the result of the fixed-point arctangent angle.
3.4. Floating-Point Regularization Post-Processing Module
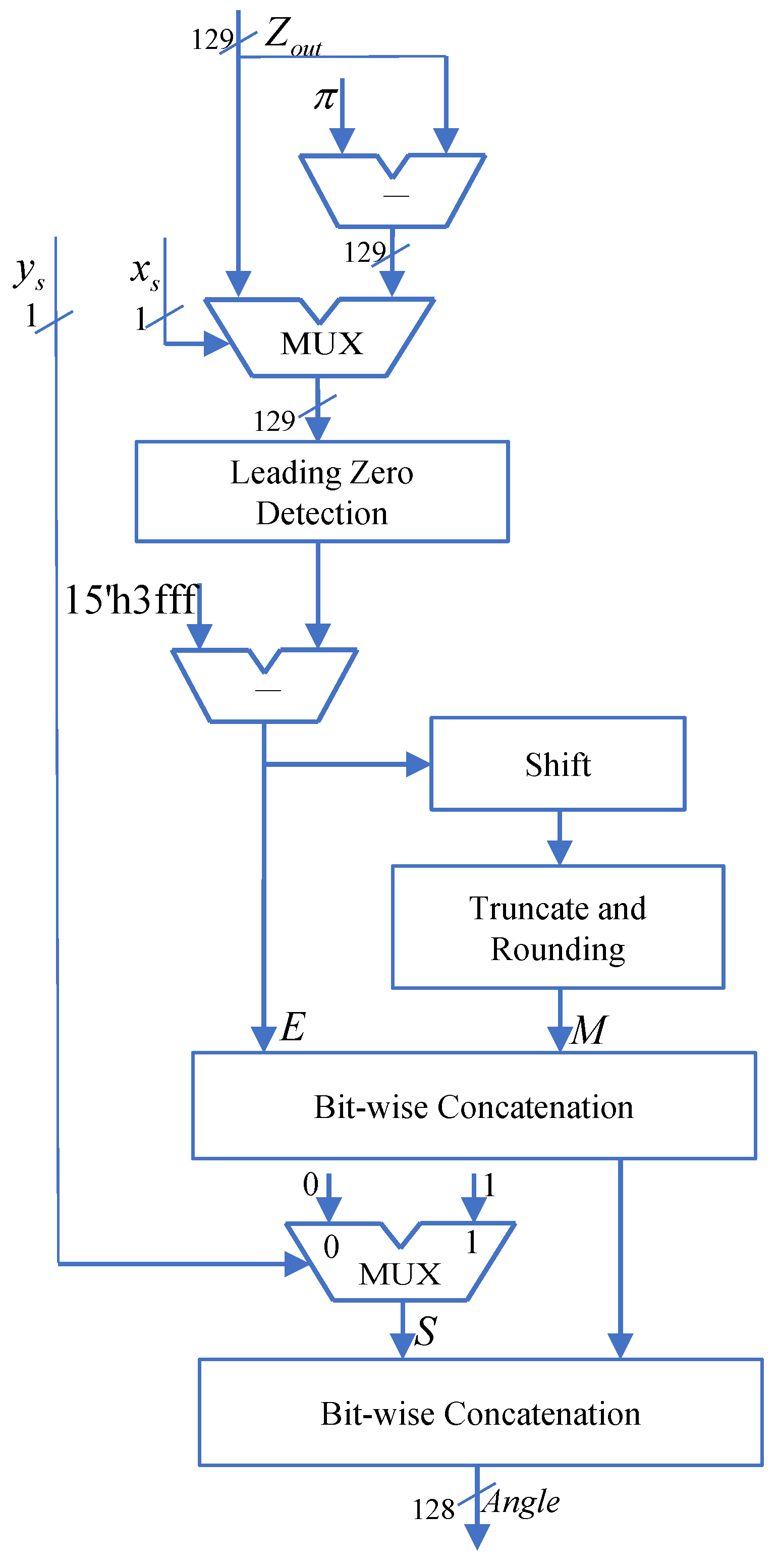
The floating-point normalization module aims to convert the computed results into floating-point numbers that comply with the IEEE-754 standard. It receives the sign bit from the exception detection and pre-processing module and the 129-bit fixed-point arctangent result from Z-channel after iteration. Through floating-point normalization processing, it eventually outputs a 128-bit floating-point number.
Before performing floating-point normalization, it is necessary to detect leading zeros in the fixed-point arctangent angle value. The conventional approach for leading zero detection involves sequential logic, counting from the highest bit until the first non-zero position is found. However, implementing this structure generally results in significant area and power consumption and is not suitable for this application, especially when there are a large number of leading zeros, requiring multiple detections and significantly slowing down the computation speed. Reference [
29] proposes a leading zero detection algorithm based on tree coding, which is efficient for smaller bit widths with fewer encoding and merging operations. However, in this design, the operand is 129 bits long, and applying the tree coding method for leading zero detection would inevitably lead to a long detection chain and considerable gate-level delay.
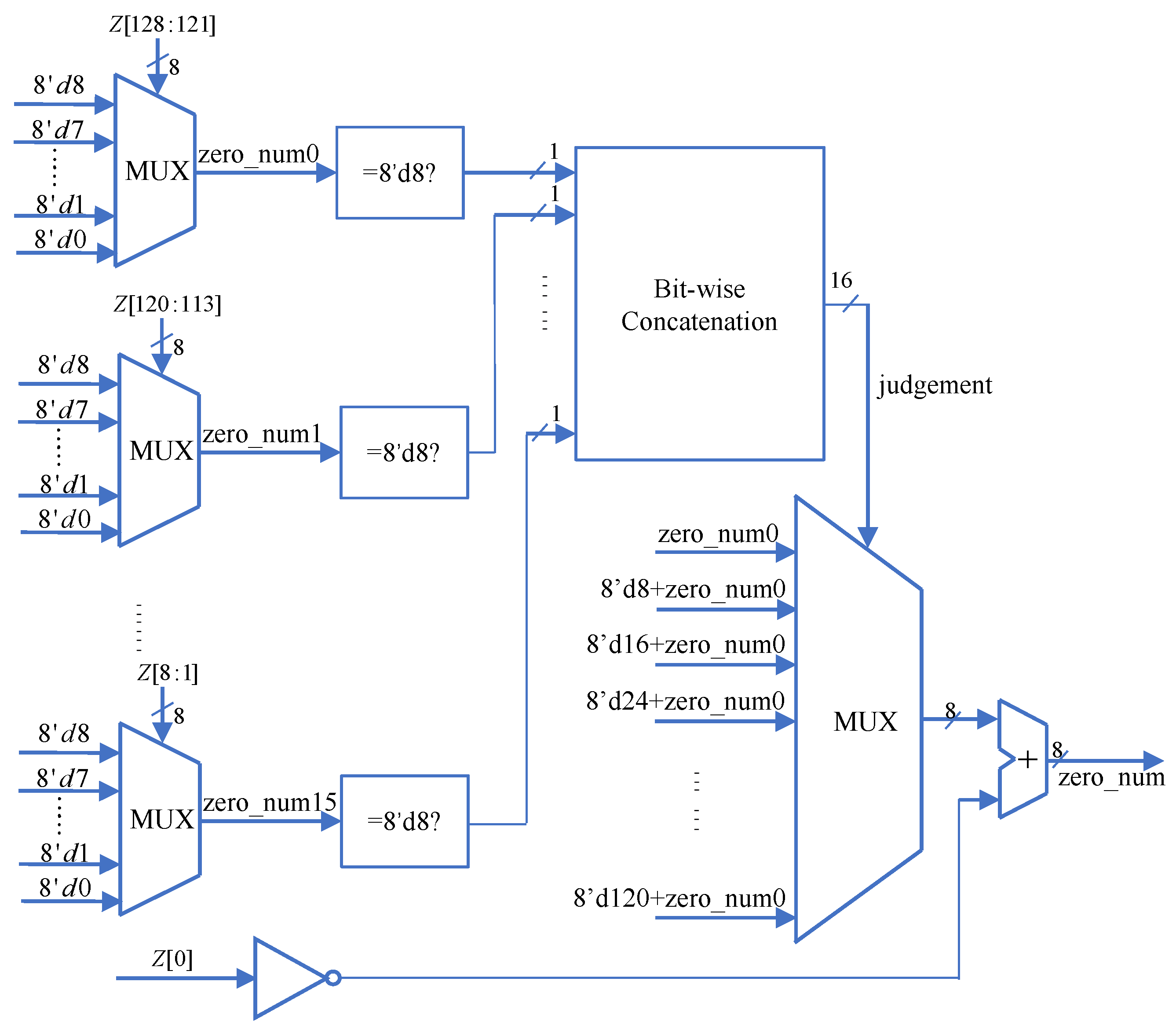
Therefore, in this design, the tree coding method was not chosen, and instead, a multi-way selector was employed to implement the leading zero detection circuit. The multi-way selector is already optimized and readily available in the technology library, offering a smaller delay compared to the tree coding method and a simpler implementation. The 129-bit leading zero detection module in this design consists of two layers of multi-way selectors, and its hardware structure is shown in
Figure 10.
First, the 129-bit data to be detected is divided into groups of 8 bits each, forming leading zero detection subunits called lzd_unit. Each subunit takes 8 bits of the data as the selection signal and outputs the number of leading zeros, zero_num, for those 8 bits. Due to the presence of special positions for leading zeros, many terms in the multi-way selector can be combined, significantly reducing the delay. The 129-bit data is divided into 16 groups of 8-bit arrays, with the lowest bit as a separate unit, forming 16 lzd_units and obtaining 16 sets of leading zero counts. Each of these 16 zero_num values is then compared to 8’d8 to check for equality, and the comparison results are concatenated to form a 16-bit determination signal which is called judgment. Finally, judgment is used as the control signal for the multi-way selector to make a selection from the 16 results, ultimately outputting the number of leading zeros for the high 128 bits of the input data. The lowest bit data is combined with the output to obtain the number of leading zeros for the entire 129-bit input data. Since judgment consists of multiple leading ones and the remaining data, it is equivalent to performing leading one detection using the multi-way selector, allowing for further term merging in the selector. The hierarchical connection of the two-layer multi-way selector enables the leading zero detection function to be achieved with minimal delay cost.
The format of the fixed-point arctangent values is shown in
Figure 11, and their corresponding real rad range is between 0 and 2. To convert them into IEEE-754 standard floating-point numbers, the exponent part is determined as (16,383-zero_num) based on the number of leading zeros. Simultaneously, the data is left-shifted by zero_num bits, and the 112 bits following the hidden precision bit 1 are extracted as the mantissa. Finally, combined with the sign bit output from the exception detection and pre-processing module, they form a 128-bit standard floating-point value, resulting in the arctangent angle range of
. The hardware structure of the floating-point regularization post-processing module is illustrated in
Figure 12.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}