
Performance Analysis of Several Intelligent Algorithms for Class Integration Test Order Optimization

Abstract
:1. Introduction
2. Literature Review
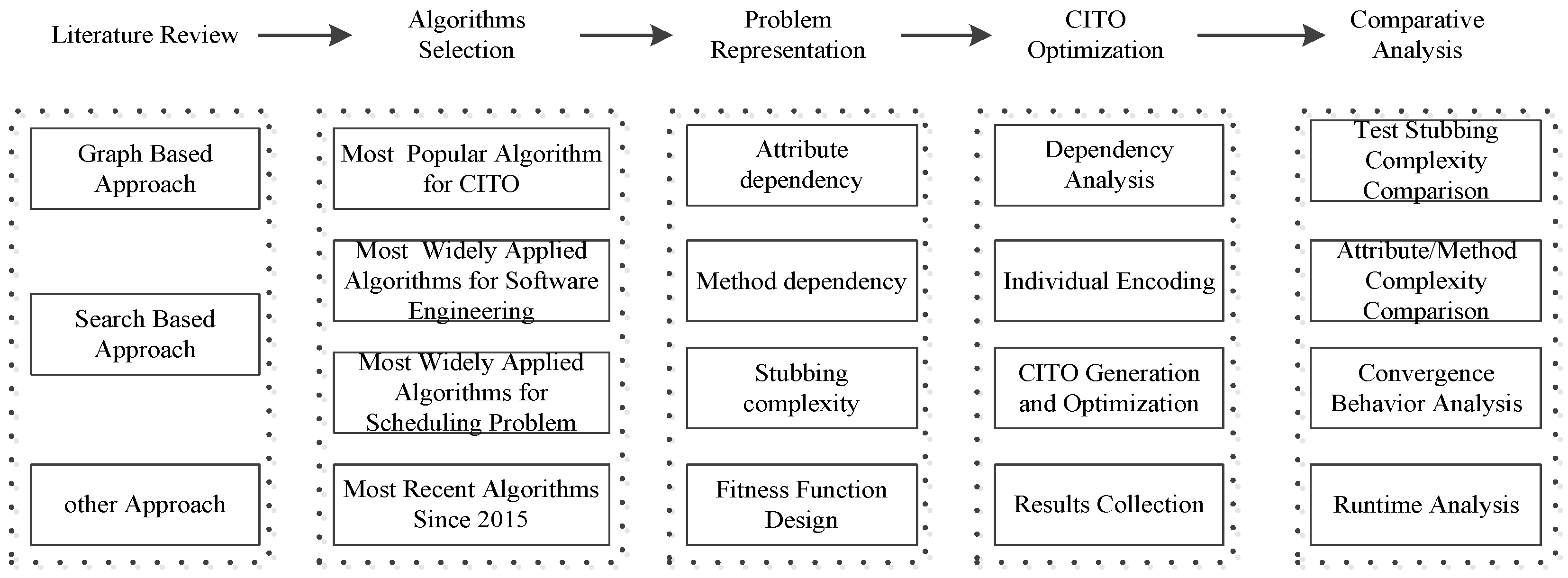
3. Research Methodology
3.1. Algorithms Selection
- (1)
- Genetic algorithm and particle swarm optimization algorithm are widely recognized and commonly employed for generating integration test orders.
- (2)
- (3)
- Grey wolf optimization algorithm, moth flame algorithm, sine cosine algorithm, salp swarm algorithm, and Harris hawk optimization algorithm have emerged as more efficient solutions since 2015. They have been successfully applied to scheduling or routing problems and various combinatorial optimization problems with a huge and noisy search space [7]. The relevance of these problems to the test order problem makes these algorithms suitable candidates in the CITO context.
3.2. Problem Representation
3.2.1. Stubbing Complexity
3.2.2. CITO Formulation
3.3. CITO Optimization
3.3.1. Mapping CITO to Individual Position
| Algorithm 1: Map a class integration test order to individual position |
| Input: class integration testing order o list of classes in descending order list number of classes n Output: position
|
3.3.2. Mapping Individual Position to CITO
| Algorithm 2: Map individual position to a class integration test order |
| Input: position list of classes in descending order list number of classes n Output: a class integration test order o
|
3.3.3. Constraints
3.4. Comparative Analysis
4. Experimentation
4.1. Experiment Subjects
4.2. Parameters Settings
4.3. Experiment Design
4.4. Effectiveness Analysis
4.4.1. Stubbing Complexity
- (1)
- Dependencies Distribution Factor Analysis
- ●
- Systems with few dependencies
- ●
- Systems with mid-sized dependencies
- ●
- Systems with large-sized dependencies
- (2)
- Coupling Distribution Factor Analysis
- (3)
- Wilcoxon Analysis
4.4.2. Attribute Complexity and Method Complexity
- (1)
- Attribute Coupling Factor Analysis
- (2)
- Method Coupling Factor Analysis
4.5. Efficiency Analysis
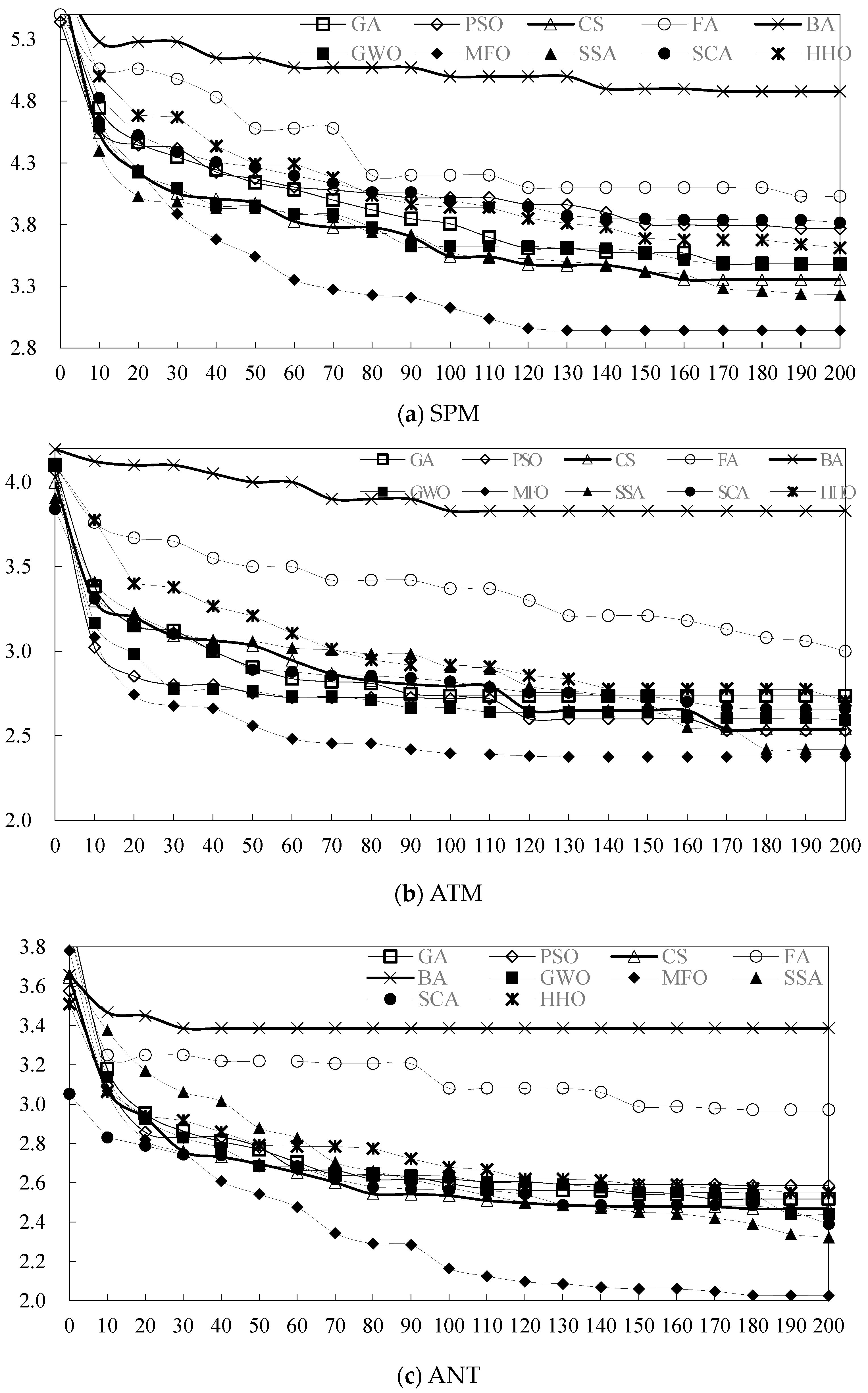
4.5.1. Convergence Behavior Analysis
4.5.2. Runtime Analysis
4.5.3. Memory Analysis
4.6. Answering the Research Questions
5. Threats to Validity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khari, M.; Sinha, A.; Verdu, E.; Crespo, R.G. Performance Analysis of Six Meta-heuristic Algorithms over Automated Test Suite Generation for Path Coverage based Optimization. Soft Comput. 2021, 24, 9143–9160. [Google Scholar] [CrossRef]
- Le Hanh, V.; Akif, K.; Le Traon, Y.; Jézéque, J.M. Selecting an Efficient OO Integration Testing Strategy: An Experimental comparison of Actual Strategies. In Proceedings of the 15th European Conference on Object-Oriented Programming, Budapest, Hungary, 18–22 June 2001; pp. 381–401. [Google Scholar]
- Jiang, S.J.; Zhang, M.; Zhang, Y.M.; Wang, R.; Yu, Q.; Keung, J.W. An Integration Test Order Strategy to Consider Control Coupling. IEEE Trans. Softw. Eng. 2021, 47, 1350–1367. [Google Scholar] [CrossRef]
- Kung, D.; Gao, J.; Hsia, P.; Toyoshima, Y.; Chen, C. A Test Strategy for Object Oriented Programs. In Proceedings of the 19th Annual International Computer Software and Applications Conference, Dallas, TX, USA, 9–11 August 1995; pp. 239–244. [Google Scholar]
- Zhang, M.; Keung, J.W.; Chen, T.Y.; Xiao, Y. Validating Class Integration Test Order Generation Systems with Metamorphic Testing. Inf. Softw. Technol. 2021, 132, 106507. [Google Scholar] [CrossRef]
- da Veiga Cabral, R.; Pozo, A.; Vergilio, S.R. A Pareto Ant Colony Algorithm Applied to the Class Integration and Test Order Problem. In Proceedings of the esting Software & Systems-ifip Wg 61 International Conference, Natal, Brazil, 8–10 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 16–29. [Google Scholar]
- Hussain, K.; Mohd, M.S.; Cheng, S.; Shi, Y. Metaheuristic Research: A Comprehensive Survey. Artifical Intell. Rev. 2019, 52, 2191–2233. [Google Scholar] [CrossRef]
- Tai, K.C.; Daniels, F.J. Interclass Test Order for Object-Oriented Software. In Proceedings of the 21st International Computer Software and Applications Conference, Washington, DC, USA, 11–15 August 1997; pp. 602–607. [Google Scholar]
- Traon, Y.L.; Jezequel, J.M. Efficient Object-Oriented Integration and Regression Test. IEEE Trans. Reliab. 2000, 49, 12–25. [Google Scholar] [CrossRef]
- Briand, L.C.; Labiche, Y.; Wang, Y. An Investigation of Graph-Based Class Integration Test Order Strategies. IEEE Trans. Softw. Eng. 2003, 29, 594–607. [Google Scholar] [CrossRef]
- Zhang, M.; Keung, J.; Xiao, Y.; Kabir, M.A.; Feng, S. A Heuristic Approach to Break Cycles for the Class Integration Test Order Generation. In Proceedings of the IEEE 43rd Annual Computer Software and Applications Conference, Milwaukee, WI, USA, 15–19 July 2019; pp. 47–52. [Google Scholar]
- Briand, L.; Feng, J.; Labiche, Y. Experiment with Genetic Algorithms and Coupling Measures to Devise Optimal Integration Test Orders; Technical report SCE-02-03; Carleton University: Ottawa, ON, Canada, 2002. [Google Scholar]
- Borner, L.; Paech, B. Integration Test Order Strategies to Consider Test Focus and Simulation Effort. In Proceedings of the International Conference on Advances in System Testing and Validation Lifecycle, Porto, Portugal, 20–25 September 2009; pp. 80–85. [Google Scholar]
- Vergilio, S.R.; Pozo, A.; Árias, J.C.G.; Cabral, R.d.V.; Nobre, T. Multi-objective Optimization Algorithms Applied to the Class Integration and Test Order Problem. Softw. Tools Technol. Transf. 2012, 14, 461–475. [Google Scholar] [CrossRef]
- Mariani, T.; Guizzo, G.; Vergilio, S.R.; Pozo, A.T. Grammatical Evolution for the Multi-Objective Integration and Test Order Problem. In Proceedings of the Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; pp. 1069–1076. [Google Scholar]
- Czibula, G.; Czibula, G.; Marian, Z. Identifying Class Integration Test Order Using an Improved Genetic Algorithm based Approach. In Proceedings of the International Conference on Software Technologies, Madrid, Spain, 24–26 July 2018; pp. 163–187. [Google Scholar]
- Zhang, Y.M.; Jiang, S.J.; Chen, R.Y.; Wang, X.Y.; Zhang, M. Class Integration Testing Order Determination Method based on Particle Swarm Optimization Algorithm. Chin. J. Comput. 2018, 41, 931–945. [Google Scholar]
- Zhang, Y.N.; Jiang, S.J.; Zhang, Y.M. Approach for Generating Class Integration Test Sequence based on Dream Particle Swarm Optimization Algorithm. Comput. Sci. 2019, 46, 159–165. [Google Scholar]
- Zhang, M.; Keung, J.W.; Xiao, Y.; Kabir, M.A. Evaluating the Effects of Similar Class Combination on Class Integration Test Order Generation. Inf. Softw. Technol. 2021, 129, 106438. [Google Scholar] [CrossRef]
- Zhang, B.Q.; Fei, Q.; Wang, Y.C.; Yang, Z. Study on Integration Test Order Generation Algorithm for SOA. Comput. Sci. 2022, 49, 24–29. [Google Scholar] [CrossRef]
- Zhang, W.N.; Zhou, Q.L.; Jiao, C.Y.; Xu, T. Hybrid Algorithm of Grey Wolf Optimizer and Arithmetic Optimization Algorithm for Class Integration Test Order Generation. Comput. Sci. 2023, 50, 72–81. [Google Scholar]
- Harman, M.; Mcminn, P. A Theoretical and Empirical Study of Search Based Testing: Local, Global and Hybrid Search. IEEE Trans. Softw. Eng. 2010, 36, 226–247. [Google Scholar] [CrossRef]
- Harman, M.; Yue, J.; Zhang, Y. Achievements, Open Problems and Challenges for Search Based Software Testing. In Proceedings of the 8th IEEE International Conference on Software Testing, Verification and Validation, Graz, Austria, 13–17 April 2015. [Google Scholar]
- Khari, M. An extensive evaluation of search-based software testing: A review. Soft Comput. 2019, 23, 1933–1940. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, S.; Zhang, M.; Ju, X. Survey of Class Test Order Generation Techniques for Integration Test. Chin. J. Comput. 2018, 41, 670–694. [Google Scholar]
- Zhang, M.; Jiang, S.J.; Zhang, Y.M. Research on Multi-objective optimization in Class Integration Test Order. J. Chines Comput. Syst. 2017, 38, 1772–1777. [Google Scholar]
- Khari, M.; Kumar, P.; Burgos, D.; Crespo, R.G. Optimized Test Suites for Automated Testing Using Different Optimization Techniques. Soft Comput. 2018, 22, 8341–8352. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Yang, X.S.; Deb, S. Cuckoo Search via Levy Flights. In Proceeding of the World Congress on Nature and Biologically Inspired Computing (NaBIC2009), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: London, UK, 2010; pp. 81–89. [Google Scholar]
- Yang, X.S. A New Metaheuristic Bat-inspired Algorithm. Comput. Knowl. Technol. 2010, 284, 65–74. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame Optimization Algorithm: A Novel Nature Inspired Heuristic Paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for Solving Optimization Problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A Bio-Inspired Optimizer for Engineering Design Problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Classes | Usages | Associations & Aggregations | Compositions | Inheritance | Dependencies | Cycles | #LOC |
|---|---|---|---|---|---|---|---|---|
| Elevator | 12 | 8 | 3 | 16 | 0 | 27 | N/A | 934 |
| SPM | 19 | 24 | 34 | 10 | 4 | 72 | 1178 | 1198 |
| ATM | 21 | 39 | 9 | 15 | 4 | 67 | 30 | 1390 |
| Daisy | 23 | 31 | 2 | 3 | 0 | 36 | N/A | 1148 |
| ANT | 25 | 54 | 16 | 2 | 11 | 83 | 654 | 4093 |
| DEOS | 25 | 52 | 15 | 6 | 5 | 78 | N/A | 2215 |
| 39 | 44 | 5 | 12 | 2 | 63 | N/A | 2276 | |
| BCEL | 45 | 18 | 226 | 4 | 46 | 294 | 416,091 | 3033 |
| DNS | 61 | 211 | 23 | 12 | 30 | 276 | 16 | 6710 |
| Notepad | 65 | 122 | 8 | 11 | 0 | 141 | N/A | 2419 |
| System | Attribute Coupling | Method Coupling | Total | ||||
|---|---|---|---|---|---|---|---|
| Max | Average | Sum | Max | Average | Sum | ||
| Elevator | 3 | 1.62 | 21 | 25 | 6.33 | 158 | 179 |
| SPM | 21 | 7.97 | 462 | 8 | 2.41 | 135 | 597 |
| ATM | 13 | 6.02 | 283 | 7 | 2.33 | 84 | 367 |
| Daisy | 11 | 3.78 | 34 | 16 | 4.22 | 135 | 169 |
| ANT | 31 | 9.14 | 585 | 14 | 2.9 | 177 | 762 |
| DEOS | 4 | 2.04 | 26 | 15 | 3.28 | 223 | 249 |
| 22 | 3.13 | 72 | 40 | 4.18 | 222 | 204 | |
| BCEL | 8 | 2.52 | 454 | 4 | 1.55 | 369 | 823 |
| DNS | 10 | 4.35 | 766 | 8 | 1.92 | 328 | 1094 |
| Notepad | 8 | 1.88 | 102 | 37 | 1.74 | 181 | 283 |
| Algorithm | Parameters | Reference |
|---|---|---|
| GA | pm = 0.01, pc = 0.5 | Briand 2002 [12] |
| PSO | wmax = 0.9, wmin = 0.4, c1 = 2, c2 = 2 | Zhang 2018 [17] |
| CS | p = 0.02, α = 0.15, λ = 1.5 | Yang 2009 [29] |
| FA | α = 0.2, β0 = 1, γ = 1 | Yang 2010 [30] |
| BA | α = 0.9, γ = 0.7, fmin = 0, fmax = 2 | Yang 2010 [31] |
| GWO | αfirst = 2, αfinal = 0 | Mirjalili 2014 [32] |
| MFO | b = 1, θ ∈ [−1, 1] | Mirjalili 2015 [33] |
| SCA | α = 2, r2 ∈ [0, 2π], r3 ∈ [−2, 2], r4 ∈ [0, 1] | Mirjalili 2016 [34] |
| SSA | m = 2, c2, c3 ∈ [0, 1] | Mirjalili 2017 [35] |
| HHO | β = 1.5, E0 ∈ [−1, 1], J ∈ [0, 2] | Heidari 2019 [36] |
| System | Stats. | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elevator | best | 1.76 | 1.79 | 1.76 | 1.85 | 1.97 | 1.76 | 1.76 | 1.76 | 1.76 | 1.94 |
| worst | 1.85 | 1.95 | 1.89 | 2.27 | 2.37 | 1.91 | 1.82 | 1.88 | 1.93 | 3.91 | |
| mean | 1.81 | 1.86 | 1.84 | 2.03 | 2.20 | 1.84 | 1.79 | 1.79 | 1.85 | 3.52 | |
| Stdev | 0.02 | 0.05 | 0.04 | 0.09 | 0.13 | 0.04 | 0.02 | 0.03 | 0.04 | 0.54 | |
| rank | 3 | 7 | 4 | 8 | 9 | 5 | 1 | 2 | 6 | 10 | |
| SPM | best | 3.05 | 3.40 | 2.99 | 3.35 | 4.05 | 3.04 | 2.45 | 2.55 | 3.58 | 2.99 |
| worst | 3.96 | 4.16 | 3.80 | 4.99 | 6.37 | 3.80 | 3.54 | 3.77 | 4.19 | 4.08 | |
| mean | 3.51 | 3.75 | 3.37 | 4.03 | 4.88 | 3.45 | 2.97 | 3.19 | 3.82 | 3.61 | |
| Stdev | 0.28 | 0.22 | 0.27 | 0.46 | 0.62 | 0.21 | 0.23 | 0.32 | 0.19 | 0.30 | |
| rank | 5 | 7 | 3 | 9 | 10 | 4 | 1 | 2 | 8 | 6 | |
| ATM | best | 2.32 | 2.17 | 2.29 | 2.26 | 3.02 | 2.29 | 2.17 | 2.17 | 2.32 | 2.27 |
| worst | 3.18 | 2.82 | 2.74 | 3.52 | 4.90 | 2.77 | 2.55 | 2.94 | 2.94 | 2.98 | |
| mean | 2.74 | 2.53 | 2.54 | 3.00 | 3.83 | 2.50 | 2.37 | 2.42 | 2.65 | 2.69 | |
| Stdev | 0.25 | 0.16 | 0.12 | 0.17 | 0.44 | 0.12 | 0.09 | 0.16 | 0.18 | 0.21 | |
| rank | 8 | 4 | 5 | 9 | 10 | 3 | 1 | 2 | 6 | 7 | |
| Daisy | best | 0.32 | 0.32 | 0.35 | 0.43 | 0.55 | 0.22 | 0.19 | 0.48 | 0.26 | 0.39 |
| worst | 0.59 | 0.74 | 0.61 | 1.68 | 1.22 | 0.51 | 3.86 | 0.77 | 0.67 | 0.67 | |
| mean | 0.46 | 0.54 | 0.48 | 0.65 | 0.94 | 0.43 | 0.72 | 0.61 | 0.50 | 0.54 | |
| Stdev | 0.09 | 0.13 | 0.07 | 0.28 | 0.18 | 0.09 | 1.00 | 0.09 | 0.13 | 0.08 | |
| rank | 2 | 6 | 3 | 8 | 10 | 1 | 9 | 7 | 4 | 5 | |
| ANT | best | 2.12 | 2.16 | 2.14 | 2.13 | 2.69 | 1.86 | 1.75 | 1.93 | 2.17 | 2.31 |
| worst | 2.83 | 2.79 | 2.65 | 2.92 | 4.36 | 2.61 | 2.34 | 2.68 | 2.57 | 2.82 | |
| mean | 2.51 | 2.59 | 2.45 | 2.99 | 3.41 | 2.44 | 2.03 | 2.30 | 2.39 | 2.55 | |
| Stdev | 0.21 | 0.15 | 0.14 | 0.21 | 0.48 | 0.19 | 0.16 | 0.22 | 0.12 | 0.15 | |
| rank | 6 | 8 | 5 | 9 | 10 | 4 | 1 | 2 | 3 | 7 | |
| DEOS | best | 3.42 | 3.28 | 3.20 | 3.96 | 4.18 | 3.24 | 2.84 | 3.20 | 2.92 | 3.33 |
| worst | 4.06 | 4.18 | 4.02 | 4.84 | 5.39 | 3.85 | 3.73 | 3.68 | 4.05 | 4.46 | |
| mean | 3.74 | 3.81 | 3.63 | 4.32 | 4.94 | 3.57 | 3.18 | 3.47 | 3.71 | 3.86 | |
| Stdev | 0.17 | 0.28 | 0.24 | 0.62 | 0.36 | 0.20 | 0.29 | 0.15 | 0.33 | 0.28 | |
| rank | 6 | 7 | 4 | 9 | 10 | 3 | 1 | 2 | 5 | 8 | |
| best | 0.70 | 0.66 | 0.65 | 1.10 | 1.05 | 0.73 | 0.56 | 0.75 | 0.70 | 0.62 | |
| worst | 0.86 | 0.89 | 0.81 | 1.85 | 1.43 | 0.91 | 0.80 | 1.10 | 0.91 | 0.92 | |
| mean | 0.78 | 0.81 | 0.73 | 1.33 | 1.20 | 0.82 | 0.69 | 0.90 | 0.78 | 0.81 | |
| Stdev | 0.05 | 0.06 | 0.05 | 0.20 | 0.11 | 0.06 | 0.07 | 0.10 | 0.06 | 0.07 | |
| rank | 3 | 5 | 2 | 10 | 9 | 7 | 1 | 8 | 4 | 6 | |
| BCEL | best | 10.19 | 10.90 | 10.45 | 11.00 | 11.98 | 10.35 | 11.98 | 10.00 | 10.71 | 10.33 |
| worst | 11.65 | 11.98 | 11.95 | 13.63 | 11.98 | 11.47 | 11.98 | 11.85 | 11.59 | 11.98 | |
| mean | 10.89 | 11.62 | 11.29 | 11.75 | 11.98 | 10.79 | 11.98 | 10.83 | 11.14 | 11.16 | |
| Stdev | 0.56 | 0.51 | 0.40 | 0.60 | 0.00 | 0.44 | 0.00 | 0.63 | 0.26 | 0.47 | |
| rank | 3 | 7 | 6 | 8 | 9 | 1 | 10 | 2 | 4 | 5 | |
| DNS | best | 6.31 | 7.34 | 7.20 | 6.53 | 8.63 | 6.97 | 6.30 | 6.68 | 7.34 | 6.95 |
| worst | 9.45 | 9.63 | 9.11 | 10.27 | 12.80 | 8.95 | 8.37 | 8.71 | 10.05 | 9.65 | |
| mean | 7.98 | 8.63 | 8.14 | 9.31 | 10.39 | 8.06 | 7.33 | 7.70 | 8.94 | 8.64 | |
| Stdev | 0.92 | 0.73 | 0.70 | 0.86 | 1.57 | 0.69 | 0.81 | 0.67 | 0.76 | 0.75 | |
| rank | 3 | 6 | 5 | 9 | 10 | 4 | 1 | 2 | 8 | 7 | |
| Notepad | best | 1.75 | 1.83 | 1.77 | 1.76 | 1.90 | 1.53 | 1.65 | 1.43 | 1.80 | 1.77 |
| worst | 1.93 | 2.17 | 1.96 | 2.41 | 3.09 | 1.97 | 1.85 | 2.21 | 1.94 | 2.17 | |
| mean | 1.84 | 1.98 | 1.85 | 2.07 | 2.50 | 1.77 | 1.73 | 1.92 | 1.85 | 1.90 | |
| Stdev | 0.05 | 0.10 | 0.07 | 0.24 | 0.30 | 0.13 | 0.06 | 0.20 | 0.04 | 0.15 | |
| rank | 3 | 8 | 4 | 9 | 10 | 2 | 1 | 7 | 5 | 6 |
| Algorithm | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO | Cases Where p-Value < 0.05 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GA | - | 0.053 | 0.722 | 0.001 | 0.001 | 0.958 | 0.920 | 0.947 | 0.239 | 0.042 | 3 |
| PSO | 0.958 | - | 0.999 | 0.001 | 0.001 | 0.999 | 0.976 | 0.993 | 0.813 | 0.528 | 2 |
| CS | 0.313 | 0.002 | - | 0.001 | 0.001 | 0.858 | 0.920 | 0.947 | 0.096 | 0.010 | 4 |
| FA | 1.000 | 1.000 | 1.000 | - | 0.002 | 1.000 | 0.997 | 1.000 | 1.000 | 0.968 | 1 |
| BA | 1.000 | 1.000 | 1.000 | 0.999 | - | 1.000 | 0.997 | 1.000 | 1.000 | 0.976 | 0 |
| GWO | 0.042 | 0.002 | 0.171 | 0.001 | 0.001 | - | 0.903 | 0.784 | 0.010 | 0.002 | 6 |
| MFO | 0.097 | 0.032 | 0.097 | 0.005 | 0.005 | 0.116 | - | 0.096 | 0.065 | 0.042 | 4 |
| SSA | 0.065 | 0.010 | 0.065 | 0.001 | 0.001 | 0.216 | 0.922 | - | 0.042 | 0.014 | 5 |
| SCA | 0.797 | 0.216 | 0.922 | 0.001 | 0.001 | 0.993 | 0.947 | 0.968 | - | 0.161 | 2 |
| HHO | 0.968 | 0.528 | 0.993 | 0.042 | 0.032 | 0.999 | 0.968 | 0.990 | 0.862 | - | 2 |
| System | Stats. | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elevator | min | 9 | 8 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| max | 9 | 9 | 9 | 10 | 11 | 9 | 9 | 9 | 10 | 19 | |
| mean | 9.00 | 8.90 | 9.00 | 9.30 | 10.40 | 9.00 | 9.00 | 9.00 | 9.40 | 15.70 | |
| Stdev | 0.00 | 0.30 | 0.00 | 0.57 | 0.66 | 0.00 | 0.00 | 0.00 | 0.40 | 3.03 | |
| rank | 2 | 1 | 2 | 3 | 5 | 2 | 2 | 2 | 4 | 6 | |
| SPM | min | 52 | 58 | 49 | 60 | 68 | 54 | 45 | 47 | 52 | 63 |
| max | 71 | 89 | 72 | 103 | 132 | 76 | 63 | 74 | 111 | 128 | |
| mean | 61.60 | 68.18 | 61.20 | 83.73 | 100.27 | 63.13 | 53.60 | 56.47 | 86.36 | 95.45 | |
| Stdev | 5.38 | 9.21 | 7.89 | 12.05 | 17.89 | 6.63 | 4.67 | 8.27 | 18.64 | 19.78 | |
| rank | 4 | 6 | 3 | 7 | 10 | 5 | 1 | 2 | 8 | 9 | |
| ATM | min | 31 | 30 | 31 | 35 | 44 | 31 | 30 | 30 | 40 | 31 |
| max | 51 | 38 | 39 | 52 | 74 | 38 | 34 | 35 | 138 | 149 | |
| mean | 36.30 | 33.40 | 33.45 | 43.70 | 55.00 | 33.10 | 31.15 | 31.35 | 81.91 | 70.27 | |
| Stdev | 5.52 | 2.33 | 2.33 | 4.26 | 7.48 | 1.80 | 1.18 | 1.27 | 37.03 | 43.29 | |
| rank | 6 | 4 | 5 | 7 | 8 | 3 | 1 | 2 | 10 | 9 | |
| Daisy | min | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| max | 3 | 1 | 1 | 21 | 4 | 2 | 1 | 2 | 23 | 28 | |
| mean | 0.36 | 0.75 | 0.50 | 9.91 | 1.27 | 0.40 | 0.18 | 0.91 | 8.45 | 8.82 | |
| Stdev | 0.92 | 0.46 | 0.53 | 5.68 | 1.27 | 0.70 | 0.41 | 0.70 | 7.59 | 10.33 | |
| rank | 2 | 5 | 4 | 10 | 7 | 3 | 1 | 6 | 8 | 9 | |
| ANT | min | 45 | 48 | 47 | 63 | 55 | 42 | 34 | 37 | 70 | 50 |
| max | 66 | 76 | 74 | 95 | 111 | 69 | 55 | 82 | 105 | 124 | |
| mean | 57.53 | 64.4 | 56.93 | 73.60 | 85.07 | 57.73 | 42.20 | 53.73 | 89.00 | 91.36 | |
| Stdev | 6.20 | 7.86 | 7.67 | 8.62 | 15.61 | 7.93 | 5.21 | 10.79 | 8.89 | 21.10 | |
| rank | 4 | 6 | 3 | 7 | 8 | 5 | 1 | 2 | 9 | 10 | |
| DEOS | min | 6 | 6 | 7 | 14 | 8 | 6 | 6 | 8 | 13 | 10 |
| max | 12 | 12 | 13 | 31 | 15 | 11 | 9 | 10 | 29 | 32 | |
| mean | 8.8 | 8.7 | 9.1 | 21.1 | 12.9 | 8.9 | 7.4 | 8.9 | 20.5 | 19.8 | |
| Stdev | 1.87 | 1.89 | 2.08 | 6.91 | 2.08 | 1.73 | 1.17 | 0.88 | 5.21 | 7.91 | |
| rank | 3 | 2 | 5 | 9 | 6 | 4 | 1 | 4 | 8 | 7 | |
| min | 5 | 7 | 6 | 8 | 7 | 9 | 7 | 5 | 11 | 11 | |
| max | 13 | 13 | 10 | 34 | 21 | 13 | 11 | 16 | 57 | 44 | |
| mean | 9.64 | 9.33 | 8.57 | 24.73 | 14.27 | 11 | 8.33 | 11 | 28.18 | 30.64 | |
| Stdev | 2.21 | 2 | 1.62 | 8.25 | 4.47 | 1.41 | 1.51 | 3.5 | 14.13 | 9.48 | |
| rank | 4 | 3 | 2 | 7 | 6 | 5 | 1 | 5 | 8 | 9 | |
| BCEL | min | 66 | 78 | 53 | 72 | 93 | 65 | 78 | 44 | 116 | 128 |
| max | 102 | 100 | 111 | 155 | 140 | 98 | 93 | 106 | 281 | 347 | |
| mean | 83.72 | 90.39 | 86.37 | 107.73 | 111.64 | 78.54 | 81.91 | 67 | 151.36 | 168.72 | |
| Stdev | 8.82 | 6.05 | 17.04 | 25.20 | 11.74 | 5.73 | 13.71 | 19 | 21.52 | 22.73 | |
| rank | 4 | 6 | 5 | 7 | 8 | 2 | 3 | 1 | 9 | 10 | |
| DNS | min | 69 | 68 | 73 | 113 | 122 | 76 | 70 | 69 | 121 | 154 |
| max | 107 | 116 | 112 | 154 | 170 | 100 | 99 | 99 | 502 | 318 | |
| mean | 89.13 | 92.5 | 93.2 | 131.63 | 140.75 | 88.88 | 83 | 81 | 218.36 | 203.27 | |
| Stdev | 11.67 | 15.37 | 14.62 | 13.11 | 17.88 | 10.25 | 12 | 7.3 | 31.71 | 49.58 | |
| rank | 4 | 5 | 6 | 7 | 8 | 3 | 2 | 1 | 10 | 9 | |
| Notepad | min | 5 | 6 | 5 | 14 | 9 | 5 | 5 | 6 | 10 | 13 |
| max | 9 | 12 | 7 | 66 | 20 | 11 | 6 | 13 | 26 | 64 | |
| mean | 5.91 | 8.2 | 6.2 | 35.64 | 12.73 | 7.9 | 5.36 | 9.4 | 17.8 | 31.71 | |
| Stdev | 1.14 | 2.35 | 0.84 | 22.45 | 3.52 | 2.51 | 0.51 | 2.5 | 5.18 | 22.30 | |
| rank | 2 | 5 | 3 | 10 | 7 | 4 | 1 | 6 | 8 | 9 |
| System | Stats. | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elevator | min | 17 | 18 | 17 | 20 | 25 | 17 | 17 | 17 | 17 | 27 |
| max | 23 | 33 | 25 | 30 | 34 | 24 | 22 | 22 | 32 | 125 | |
| mean | 20.30 | 22.30 | 21.50 | 27.34 | 28.70 | 21 | 18.90 | 18.60 | 24.70 | 76.70 | |
| Stdev | 1.87 | 4.01 | 2.81 | 3.75 | 3.28 | 2.20 | 2.12 | 2.06 | 4.82 | 26.8 | |
| rank | 3 | 6 | 5 | 8 | 9 | 4 | 2 | 1 | 7 | 10 | |
| SPM | min | 22 | 22 | 20 | 24 | 30 | 21 | 18 | 19 | 26 | 30 |
| max | 31 | 32 | 31 | 37 | 48 | 31 | 27 | 28 | 45 | 56 | |
| mean | 27.33 | 28.09 | 25.26 | 28.93 | 37.93 | 25.60 | 22.06 | 24.13 | 35.27 | 40.73 | |
| Stdev | 2.74 | 2.74 | 2.89 | 3.45 | 4.63 | 3.02 | 3.08 | 2.51 | 5.29 | 7.32 | |
| rank | 5 | 6 | 3 | 7 | 9 | 4 | 1 | 2 | 8 | 10 | |
| ATM | min | 11 | 11 | 11 | 13 | 13 | 12 | 11 | 11 | 14 | 13 |
| max | 20 | 19 | 15 | 23 | 27 | 15 | 14 | 17 | 45 | 36 | |
| Stdev | 14.05 | 13.75 | 13.50 | 17.65 | 19.4 | 13.20 | 12.70 | 13.25 | 24.82 | 20.09 | |
| mean | 2.09 | 1.89 | 1.15 | 2.66 | 3.93 | 1.01 | 0.75 | 1.33 | 9.26 | 8.85 | |
| rank | 6 | 5 | 4 | 7 | 8 | 2 | 1 | 3 | 10 | 9 | |
| Daisy | min | 10 | 10 | 9 | 13 | 17 | 7 | 6 | 13 | 48 | 24 |
| max | 18 | 21 | 19 | 81 | 34 | 16 | 17 | 22 | 83 | 78 | |
| mean | 13.82 | 15.5 | 14 | 54 | 27.09 | 12.9 | 12.20 | 17.46 | 61.36 | 47.55 | |
| Stdev | 2.48 | 4.00 | 2.75 | 18.12 | 5.48 | 3.14 | 3.28 | 2.66 | 13.03 | 16.40 | |
| rank | 3 | 5 | 4 | 9 | 7 | 2 | 1 | 6 | 10 | 8 | |
| ANT | min | 32 | 30 | 33 | 34 | 36 | 30 | 29 | 30 | 47 | 40 |
| max | 47 | 42 | 42 | 51 | 70 | 42 | 36 | 40 | 74 | 73 | |
| mean | 38.27 | 37.07 | 36.67 | 42.60 | 48.53 | 36.47 | 32.53 | 34.53 | 58.20 | 58.09 | |
| Stdev | 3.94 | 3.41 | 2.79 | 3.78 | 8.94 | 2.88 | 2.47 | 2.88 | 9.07 | 12.22 | |
| rank | 6 | 5 | 4 | 7 | 8 | 3 | 1 | 2 | 10 | 9 | |
| DEOS | min | 42 | 48 | 43 | 66 | 55 | 40 | 39 | 37 | 73 | 64 |
| max | 60 | 61 | 67 | 126 | 84 | 54 | 53 | 52 | 109 | 118 | |
| mean | 52.8 | 54 | 50.8 | 92.9 | 70.2 | 48.9 | 45.5 | 46.9 | 90.2 | 89.9 | |
| Stdev | 6.27 | 4.74 | 7.31 | 18.75 | 8.55 | 4.18 | 4.93 | 4.68 | 14.71 | 15.76 | |
| rank | 5 | 6 | 4 | 10 | 7 | 3 | 1 | 2 | 9 | 8 | |
| min | 22 | 24 | 22 | 38 | 34 | 26 | 20 | 22 | 71 | 62 | |
| max | 34 | 39 | 34 | 145 | 57 | 34 | 33 | 46 | 131 | 129 | |
| mean | 30 | 32.11 | 28.57 | 105.64 | 46.36 | 29.33 | 26.3 | 34 | 96.64 | 102.36 | |
| Stdev | 3.61 | 4.48 | 4.16 | 30.96 | 9.71 | 3.08 | 4.32 | 6.8 | 20.85 | 20.28 | |
| rank | 4 | 5 | 2 | 10 | 7 | 3 | 1 | 6 | 8 | 9 | |
| BCEL | min | 87 | 92 | 96 | 102 | 109 | 86 | 91 | 89 | 104 | 99 |
| max | 109 | 109 | 109 | 121 | 123 | 106 | 109 | 109 | 198 | 241 | |
| mean | 91.55 | 103.28 | 101.10 | 113.36 | 117.45 | 90.63 | 105.82 | 100.72 | 150.64 | 160.18 | |
| Stdev | 4.85 | 5.57 | 4.01 | 10.99 | 4.63 | 5.74 | 22.32 | 6.89 | 26.71 | 38.37 | |
| rank | 2 | 5 | 4 | 7 | 8 | 1 | 6 | 3 | 9 | 10 | |
| DNS | min | 50 | 59 | 53 | 80 | 75 | 52 | 47 | 54 | 92 | 88 |
| max | 77 | 84 | 74 | 100 | 114 | 85 | 67 | 79 | 163 | 152 | |
| mean | 64.25 | 68.38 | 61.6 | 87.75 | 95.13 | 62.6 | 59 | 66.5 | 116.64 | 127.91 | |
| Stdev | 8.92 | 7.39 | 7.70 | 6.48 | 13.82 | 10.7 | 7.54 | 9.4 | 20.90 | 21.10 | |
| rank | 4 | 6 | 2 | 7 | 8 | 3 | 1 | 5 | 9 | 10 | |
| Notepad | min | 69 | 60 | 73 | 67 | 61 | 53 | 56 | 56 | 80 | 63 |
| max | 80 | 82 | 78 | 119 | 94 | 73 | 77 | 80 | 100 | 100 | |
| mean | 76.10 | 74.3 | 76 | 92.73 | 82.27 | 64.1 | 70.3 | 66 | 89.2 | 90.14 | |
| Stdev | 3.59 | 8.08 | 1.87 | 17.24 | 10.68 | 7.42 | 7.48 | 9.4 | 7.55 | 13 | |
| rank | 6 | 4 | 5 | 10 | 7 | 1 | 3 | 2 | 8 | 9 |
| System | Classes | Dependencies | Cycles | Top 4 Fastest Algorithms with Excellent Optimization Results |
|---|---|---|---|---|
| SPM | 19 | 72 | 1178 | MFO (moth flame optimization algorithm) GWO (grey wolf algorithm) CS (cuckoo search algorithm) SSA (salp swarm algorithm) |
| ATM | 21 | 67 | 30 | MFO (moth flame optimization algorithm) GWO (grey wolf optimization algorithm) PSO (particle swarm optimization algorithm) SSA (salp swarm algorithm) with slow convergence speed at early stage and fast convergence speed at later stage |
| ANT | 25 | 83 | 654 | MFO (moth flame optimization algorithm) SCA (sine cosine algorithm) GWO (grey wolf optimization algorithm) SSA (salp swarm algorithm) with slow convergence speed at early stage and fast convergence speed at later stage. |
| BCEL | 45 | 294 | 416,091 | GWO (grey wolf optimization algorithm) GA (genetic algorithm) SSA (salp swarm algorithm) SCA (sine cosine algorithm) |
| DNS | 61 | 276 | 16 | MFO (moth flame optimization algorithm) GA (genetic algorithm) SSA (salp swarm algorithm) GWO (grey wolf algorithm) |
| System | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elevator | 2578 | 1004 | 2067 | 2652 | 2759 | 1003 | 1010 | 993 | 1085 | 779 | 1593 |
| SPM | 5919 | 2489 | 4816 | 6335 | 8159 | 2394 | 2432 | 2428 | 2668 | 1826 | 3947 |
| ATM | 10,503 | 2948 | 5723 | 7653 | 8199 | 2918 | 2905 | 3027 | 3225 | 2268 | 4937 |
| Daisy | 7540 | 3566 | 6962 | 8027 | 9320 | 3476 | 3514 | 3546 | 3877 | 2675 | 5250 |
| ANT | 8426 | 4189 | 8011 | 9422 | 11,874 | 4069 | 4151 | 4157 | 4560 | 3149 | 6201 |
| DEOS | 8323 | 4225 | 8037 | 9678 | 11,720 | 4054 | 4156 | 4158 | 4602 | 3108 | 6206 |
| 20,216 | 9975 | 19,495 | 22,876 | 28,365 | 9704 | 10,061 | 9985 | 10,958 | 7608 | 14,924 | |
| BCEL | 26,855 | 13,232 | 25,821 | 29,350 | 36,527 | 13,157 | 13,140 | 13,181 | 14,150 | 10,358 | 19,577 |
| DNS | 81,973 | 24,306 | 47,800 | 60,892 | 72,791 | 23,698 | 24,191 | 24,964 | 26,141 | 17,212 | 40,397 |
| Notepad | 74,445 | 27,413 | 52,760 | 61,349 | 78,079 | 26,831 | 27,334 | 28,084 | 29,509 | 24,475 | 43,028 |
| System | GA | PSO | CS | FA | BA | GWO | MFO | SSA | SCA | HHO | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elevator | 216 | 256 | 236 | 332 | 208 | 264 | 336 | 320 | 332 | 248 | 275 |
| SPM | 252 | 312 | 160 | 416 | 244 | 166 | 332 | 360 | 380 | 368 | 299 |
| ATM | 148 | 132 | 200 | 364 | 160 | 184 | 348 | 332 | 264 | 388 | 252 |
| Daisy | 196 | 208 | 184 | 360 | 192 | 302 | 328 | 332 | 320 | 456 | 288 |
| ANT | 208 | 160 | 580 | 592 | 209 | 268 | 328 | 332 | 328 | 496 | 350 |
| DEOS | 288 | 140 | 220 | 488 | 384 | 360 | 324 | 520 | 320 | 360 | 340 |
| 176 | 248 | 532 | 640 | 236 | 392 | 332 | 692 | 368 | 436 | 405 | |
| BCEL | 612 | 616 | 656 | 604 | 644 | 556 | 544 | 572 | 768 | 476 | 605 |
| DNS | 968 | 876 | 956 | 1084 | 1324 | 1152 | 1088 | 1392 | 1296 | 1248 | 1138 |
| Notepad | 844 | 524 | 844 | 628 | 372 | 832 | 688 | 856 | 840 | 840 | 727 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Zhou, Q.; Guo, L.; Zhao, D.; Gou, X. Performance Analysis of Several Intelligent Algorithms for Class Integration Test Order Optimization. Electronics 2023, 12, 3733. https://doi.org/10.3390/electronics12173733
Zhang W, Zhou Q, Guo L, Zhao D, Gou X. Performance Analysis of Several Intelligent Algorithms for Class Integration Test Order Optimization. Electronics. 2023; 12(17):3733. https://doi.org/10.3390/electronics12173733
Chicago/Turabian StyleZhang, Wenning, Qinglei Zhou, Li Guo, Dong Zhao, and Ximei Gou. 2023. "Performance Analysis of Several Intelligent Algorithms for Class Integration Test Order Optimization" Electronics 12, no. 17: 3733. https://doi.org/10.3390/electronics12173733