

Enhancing QoS with LSTM-Based Prediction for Congestion-Aware Aggregation Scheduling in Edge Federated Learning

Abstract
:1. Introduction
1.1. Motivation and Problem Statement
1.2. Paper Contributions
- The system architecture is given to handle the virtualization approach for orchestrating resource pooling properties within the NFV infrastructure (NFVI). The framework divides the plane into participants, edge aggregators, and controllers, strengthened by a modified LSTM (MLSTM) algorithm for predicting congestion levels. The structural planes enhance interactivity and interface connections to facilitate scalability for the multi-service IIoT model aggregation.
- MLSTM-CEFL is introduced for collecting feature inputs, predicting congestion rates, determining high-impact latency-efficient conditions, and optimizing the final model learning objectives. The procedural flow of feature collection and EFL-based IIoT model communications are presented in this paper.
- The proposed reliable model aggregation policy is presented by considering the output of quality of service (QoS) guarantees and orchestration capabilities in configuring proactive congestion detection and prioritizing model flows. The simulation is implemented with DL policy modelling in a TensorFlow and Keras-based environment and network topology in Mininet and MiniNFV.
1.3. Paper Organization
2. Related Works
2.1. LSTM-Based Prediction for QoS Enhancements
2.2. Applicability of LSTM with (Edge) FL and IIoT Applications
3. Congestion-Aware EFL-Based Model Aggregation Policy in Edge Computing
3.1. System Architecture
- Participant tier refers to local devices with image datasets, computing models, and service type indicators.
- Edge tier involves a heterogeneity of multi-service image processing for industrial applications, model labels/features, and allocatable virtual capacities.
- Controller tier comprises three primary processing phases. First, the modified LSTM congestion prediction (MLSTM-CP) module assists in predicting congestion levels. Next, the offloading decision-maker module executes to facilitate the selection of the optimal edge aggregator for offloading. Lastly, the policy installation for model aggregation concludes the tier’s functionalities. Comprehensive descriptions of the primary notations are given in Table 1.
3.1.1. Participant Tier
- Adequate local resources: Participants need to ensure the connectivity, energy capacities, and model computing capabilities within both auxiliary and intrinsic memories.
- High-quality data input: The integrity and reliability of the data are required in contributing to the overall performance of our framework.
- Non-malicious intent: This requirement ensures the security and trustworthiness of the collaborative learning environment for all selected participants.
3.1.2. Edge Tier
3.1.3. Controller Tier
- During non-congestion states, the offloading decision-maker modules adhere to the current policy, retaining incoming local models.
- In cases of congestion, the scheduling and aggregation destinations for that specific time slot are altered by modifying forwarding rules within the primary controller.
- For heavy congestion, adjustments are made to the virtual resource placement properties within each functional instance’s descriptor. This adaptation is guided by the proposed policy and prioritized service types at that time slot.
3.2. Primary Objectives and Algorithm Designs
- Participant tier: The selection criteria are listed, including the non-malicious user status, sufficiency of resource capacities, and high-quality image sensing contributions. Real-time wireless data planes in SDN-enabled architectures involve various end-user equipment, including robotic image sensing nodes, manufacturing nodes, surveillance videos, and tracking/monitoring applications.
- Edge tier: Virtual resource edge aggregators adapt to the formulated industrial service type and class- prioritization orchestrated through the virtualization layer. This orchestration directly follows the controller tier. values are loaded into global loss minimization processes directed towards the edge-aggregated parameters .
- Controller tier: With multi-services in IIoT-EFL-based applications, the final averaged learning model for each application type is independently computed following the scheduling policies of the defined congestion states from MLSTM-CP output and controller-based orchestration in VIM.
- Distributing model structures and hyperparameters for each matching service type between distinct aggregators and local nodes .
- After obtaining the primary model, local computing optimizes model parameters using local data, followed by uploading the refined model parameters back to the corresponding edge aggregator.
- By collectively gathering multi-type local model parameters, the edge-aggregated models are executed and subsequently categorized based on their respective service types. This categorization sets the stage for the final averaging process during the last-index iteration.
- Each service class computes the final learning model by dynamically adopting the aggregation and scheduling policies outlined by the proposed controller.
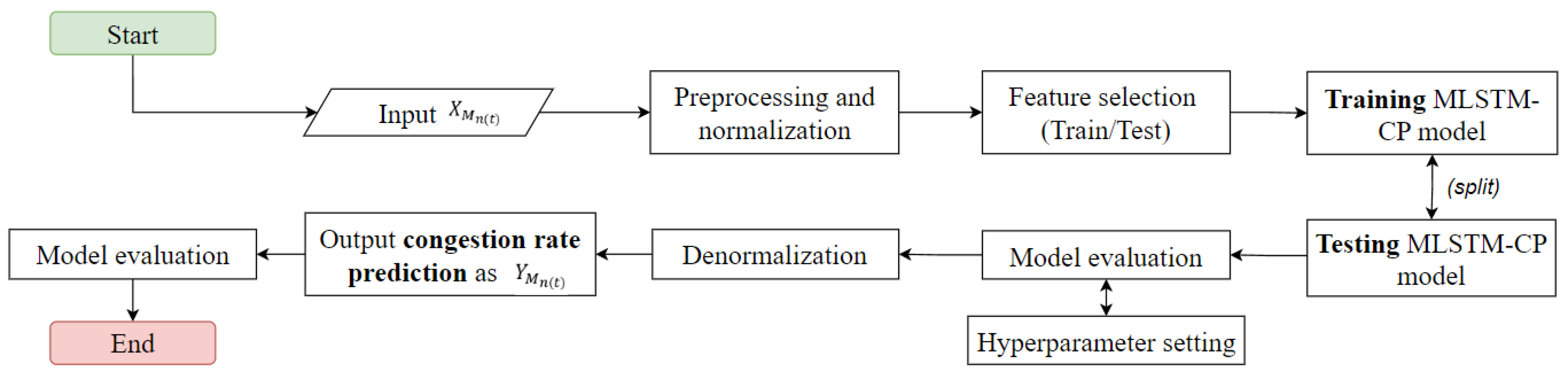
3.3. MLSTM-CP and Orchestration of EFL Model Aggregation
- Input data (): At each time step, the input data is fed into the MLSTM cell, and the gates and operations process this input to determine how much new information should be integrated, how much previous knowledge should be retained, and how the hidden state of the model should be updated based on the evolving conditions of the industrial process. The collected features are from various edge devices/servers deployed in the industrial setting (see (5)).
- Input gate () represents the decision-making process for how much new information from the current participants–edge data should be incorporated into the model update (see (6)). Different edge devices might have varying degrees of relevancy or noise in their data due to the conditions of the industrial processes that are being monitored.
- Forget gate () symbolizes the importance of retaining experienced information from previous participants–edge updates (see (7)). assists our system to determine how much to retain from past states in order to make better decisions;
- Output gate () acts as the filter that decides how much of the current hidden state should be exposed and utilized for influencing the global model. reflects how much the insights and knowledge gained from a particular participant–edge update experience should contribute to the comprehensive learning process (see (8)).
- Cell state () acts as the “memory” of the MLSTM, which captures the accumulation of insights and patterns from various participants–edge data and updating schedules. retains essential information about the evolving system dynamics. The updated cell state, denoted as , is the result of combining between (1) the previous cell state ( that was preserved based on the forget gate and (2) the new candidate cell state () that was incorporated based on the input gate (see (9) and (10)).
- Hidden state () represents the encoded information that the MLSTM uses to influence the model update process (see (11)). In other words, acts as the output of the MLSTM cell and encapsulates the input pattern understanding of how the various participants–edge updates contribute to the overall improvement of the model.
- Returned congestion rate (): and components assist the output features by encapsulating the distilled knowledge and encoded patterns learned from over multiple timesteps. controls how much of is exposed and utilized to contribute to the output features as congestion rates, which in turn influence the scheduling awareness of global model updates (see (12)).
4. Experiment and Analysis
4.1. Simulation Environment
| Algorithm 1 Pseudocode of softwarized MLSTM-CP | ||||
| Requires: | ||||
| Ensure: Optimal schedule flow batches | ||||
| 1: | Initialize , , , | |||
| 2: | def modelBuilder(): | |||
| 3: | Embedding and SpatialDropout1D | |||
| 4: | ) | |||
| 5: | hiddenLayer = concatenate([GlobalMaxPooling1D, GlobalAveragaePooling1D]) | |||
| 6: | hiddenLayer | |||
| 7: | ouputLayer ) | |||
| 8: | finalModel = Model(inputs = X, outputs = ouputLayer) | |||
| 9: | finalModel.compile (loss, optimizer) | |||
| 10: | return finalModel | |||
| 11: | Split | |||
| 12: | Sampling weights: | |||
| 13: | for each model in range of do | |||
| 14: | finalModel = modelBuilder() | |||
| 15: | for global iteration in range of do | |||
| 16: | finalModel | |||
| 17: | Executing prediction and flatten output | |||
| 18: | Average based on | |||
| 19: | Obtain to EFL-controller and pre-calculate QoS | |||
| 20: | if do | |||
| 21: | Obtain optimal schedule flow batches to MLSTM-CEFL | |||
| 22: | else | |||
| 23: | Re-schedule model flow rules and resource descriptors (Mininet, MiniNFV) | |||
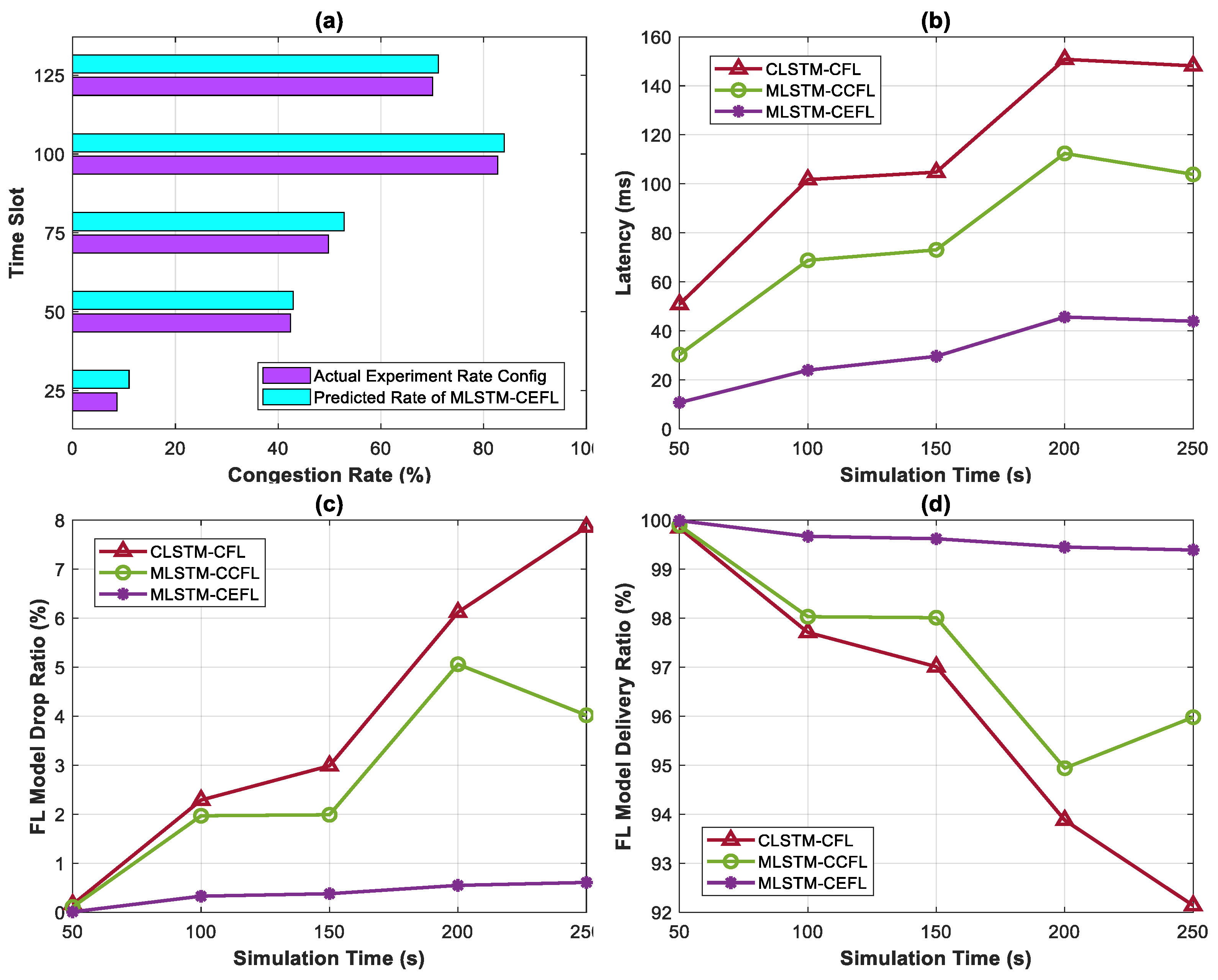
- MLSTM-CCFL employs the same MLSTM architecture to predict congestion rates within a centralized FL framework. This approach capitalizes on MLSTM’s proficiency in capturing temporal dependencies and adapting to dynamic input sequences. However, in this method, data from multiple participants and edge devices, along with their update statuses, are collected and transmitted to a central processing unit where the MLSTM model predicts congestion. The centralized feature of this approach introduces a trade-off between two factors: (1) the increased latency due to the need to transmit input features to a central server for processing and (2) the benefits of globalized and uniform decision making.
- CLSTM-CFL relies on the capacity of traditional LSTM to recognize temporal patterns and relationships in FL input data. CLSTM-CFL can be limited by its conventional LSTM architecture, which may hinder its ability to promptly respond to real-time variations and adapt effectively to evolving state dynamics, such as multi-round participant model updates and edge aggregation. Nevertheless, its advantage lies in resource consumption, as it operates with lightweight execution.
4.2. QoS Evaluation Metrics
4.3. Results and Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khalil, R.A.; Saeed, N.; Masood, M.; Fard, Y.M.; Alouini, M.-S.; Al-Naffouri, T.Y. Deep Learning in the Industrial Internet of Things: Potentials, Challenges, and Emerging Applications. IEEE Internet Things J. 2021, 8, 11016–11040. [Google Scholar] [CrossRef]
- Khan, A.I.; Al-Badi, A. Open Source Machine Learning Frameworks for Industrial Internet of Things. Procedia Comput. Sci. 2020, 170, 571–577. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.-P.; Al-Dhahir, N. Secrecy-Energy Efficient Hybrid Beamforming for Satellite-Terrestrial Integrated Networks. IEEE Trans. Commu. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
- Lin, Z.; An, K.; Niu, H.; Hu, Y.; Chatzinotas, S.; Zheng, G.; Wang, J. SLNR-Based Secure Energy Efficient Beamforming in Multibeam Satellite Systems. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 2085–2088. [Google Scholar] [CrossRef]
- Sun, Y.; An, K.; Zhu, Y.; Zheng, G.; Wong, K.-K.; Chatzinotas, S.; Ng, D.W.K.; Guan, D. Energy-Efficient Hybrid Beamforming for Multilayer RIS-Assisted Secure Integrated Terrestrial-Aerial Networks. IEEE Trans. Commun. 2022, 70, 4189–4210. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Kim, S. Efficient Resource Slicing Scheme for Optimizing Federated Learning Communications in Software-Defined IoT Networks. J. Internet Serv. Appl. 2021, 22, 27–33. [Google Scholar]
- European Telecommunications Standards Institute (ETSI). Deployment of Mobile Edge Computing in an NFV Environment. ETSI Group Rep. MEC 2018, 17, V1. [Google Scholar]
- Qu, K.; Zhuang, W.; Ye, Q.; Shen, X.; Li, X.; Rao, J. Dynamic Flow Migration for Embedded Services in SDN/NFV-Enabled 5G Core Networks. IEEE Trans. Commun. 2020, 68, 2394–2408. [Google Scholar] [CrossRef]
- Mahmood, A.; Beltramelli, L.; Fakhrul Abedin, S.; Zeb, S.; Mowla, N.; Hassan, S.A.; Sisinni, E.; Gidlund, M. Industrial IoT in 5G-And-beyond Networks: Vision, Architecture, and Design Trends. IEEE Trans. Ind. Inform. 2021, 18, 4122–4137. [Google Scholar] [CrossRef]
- Yang, H.; Alphones, A.; Zhong, W.-D.; Chen, C.; Xie, X. Learning-Based Energy-Efficient Resource Management by Heterogeneous RF/VLC for Ultra-Reliable Low-Latency Industrial IoT Networks. IEEE Trans. Ind. Inform. 2020, 16, 5565–5576. [Google Scholar] [CrossRef]
- Jin, H.; Jia, L.; Zhou, Z. Boosting Edge Intelligence with Collaborative Cross-Edge Analytics. IEEE Internet Things J. 2021, 8, 2444–2458. [Google Scholar] [CrossRef]
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing. IEEE Trans. Wirel. Commun. 2019, 19, 447–457. [Google Scholar] [CrossRef]
- Lin, Z.; Bi, S.; Zhang, Y.-J.A. Optimizing AI Service Placement and Resource Allocation in Mobile Edge Intelligence Systems. IEEE Trans. Wirel. Commun. 2021, 20, 7257–7271. [Google Scholar] [CrossRef]
- Brendan, M.H.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016. Available online: https://arXiv.org/abs/1602.05629 (accessed on 10 June 2023).
- Park, J.; Samarakoon, S.; Elgabli, A.; Kim, J.; Bennis, M.; Kim, S.-L.; Debbah, M. Communication-Efficient and Distributed Learning over Wireless Networks: Principles and Applications. Proc. IEEE 2021, 109, 796–819. [Google Scholar] [CrossRef]
- Hu, C.-H.; Chen, Z.; Larsson, E.G. Device Scheduling and Update Aggregation Policies for Asynchronous Federated Learning. arXiv 2021. Available online: https://arXiv.org/abs/2107.11415 (accessed on 15 June 2023).
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges. arXiv 2021. [Google Scholar] [CrossRef]
- Raj, J.T. Building Decentralized Image Classifiers with Federated Learning. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 489–494. [Google Scholar]
- Ren, Y.; Guo, A.; Song, C. Multi-Slice Joint Task Offloading and Resource Allocation Scheme for Massive MIMO Enabled Network. KSII Trans. Internet Inf. Syst. 2023, 17, 794–815. [Google Scholar]
- Zhu, Y.; Liu, C.; Zhang, Y.; You, W. Research on 5G Core Network Trust Model Based on NF Interaction Behavior. KSII Trans. Internet Inf. Syst. 2022, 16, 3333–3354. [Google Scholar]
- Hu, Y.; Zhu, L.; Zhang, J.; Cai, Z.; Han, J. Migration and Energy Aware Network Traffic Prediction Method Based on LSTM in NFV Environment. KSII Trans. Internet Inf. Syst. 2023, 17, 896–915. [Google Scholar]
- Pei, J.; Hong, P.; Xue, K.; Li, D.; Wei, D.S.L.; Wu, F. Two-Phase Virtual Network Function Selection and Chaining Algorithm Based on Deep Learning in SDN/NFV-Enabled Networks. IEEE J. Sel. Areas Commun. 2020, 38, 1102–1117. [Google Scholar] [CrossRef]
- Xie, J.; Fang, J.; Liu, C.; Li, X. Deep Learning-Based Spectrum Sensing in Cognitive Radio: A CNN-LSTM Approach. IEEE Commun. Lett. 2020, 24, 2196–2200. [Google Scholar] [CrossRef]
- Tajiri, K.; Kawahara, R.; Matsuo, Y. Optimizing Edge-Cloud Cooperation for Machine Learning Accuracy Considering Transmission Latency and Bandwidth Congestion. In Proceedings of the NOMS 2022—IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–9. [Google Scholar]
- Zhang, F.; Li, X.; Fan, G. Optimized LSTM Network Based on Particle Swarm Algorithm for Power Time Series Data Prediction. In Proceedings of the 13th International Conference on Intelligent Computation Technology and Automation (ICICTA), Xi’an, China, 24–25 October 2020; pp. 394–398. [Google Scholar]
- Bi, J.; Zhang, X.; Yuan, H.; Zhang, J.; Zhou, M. A Hybrid Prediction Method for Realistic Network Traffic with Temporal Convolutional Network and LSTM. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1869–1879. [Google Scholar] [CrossRef]
- Wan, X.; Liu, H.; Xu, H.; Zhang, X. Network Traffic Prediction Based on LSTM and Transfer Learning. IEEE Access. 2022, 10, 86181–86190. [Google Scholar] [CrossRef]
- Na, H.; Shin, Y.; Lee, D.; Lee, J. LSTM-Based Throughput Prediction for LTE Networks. ICT Express 2021, 9, 247–252. [Google Scholar] [CrossRef]
- Nihale, S.; Sharma, S.; Parashar, L.; Singh, U. Network Traffic Prediction Using Long Short-Term Memory. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 338–343. [Google Scholar]
- Trinh, H.D.; Giupponi, L.; Dini, P. Mobile Traffic Prediction from Raw Data Using LSTM Networks. In Proceedings of the 2018 IEEE 29th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Bologna, Italy, 9–12 September 2018; pp. 1827–1832. [Google Scholar]
- Chen, L.; Zhang, X.; Sun, L. Network Flow Delay Prediction Model Based on LSTM. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–25 September 2021; pp. 395–399. [Google Scholar]
- Tam, P.; Math, S.; Lee, A.; Kim, S. Multi-Agent Deep Q-Networks for Efficient Edge Federated Learning Communications in Software-Defined IoT. Comput. Mater. Contin. 2022, 71, 3319–3335. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; Brendan, M.H.; et al. Towards Federated Learning at Scale: System Design. arXiv 2019. Available online: https://arXiv.org/abs/1902.01046 (accessed on 30 June 2023).
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated Learning for Industrial Internet of Things in Future Industries. IEEE Wirel. Commun. 2021, 28, 192–199. [Google Scholar] [CrossRef]
- Qiu, W.; Ai, W.; Chen, H.; Feng, Q.; Tang, G. Decentralized Federated Learning for Industrial IoT with Deep Echo State Networks. IEEE Trans. Ind. Inform. 2023, 19, 5849–5857. [Google Scholar] [CrossRef]
- Hu, X.; Zhao, Y.; Huang, Y.; Zhu, C.; Yao, J.; Fang, N. Hierarchical Resource Management Framework and Multi-hop Task Scheduling Decision for Resource-Constrained VEC Networks. KSII Trans. Internet Inf. Syst. 2022, 16, 3638–3657. [Google Scholar]
- Guo, W.; Zhao, M.; Cui, Z.; Xie, L. A Bi-objective Game-based Task Scheduling Method in Cloud Computing Environment. KSII Trans. Internet Inf. Syst. 2022, 16, 3565–3583. [Google Scholar]
- Kong, Q.; Yin, F.; Lu, R.; Li, B.; Wang, X.; Cui, S.; Zhang, P. Privacy-Preserving Aggregation for Federated Learning-Based Navigation in Vehicular Fog. IEEE Trans. Ind. Inform. 2021, 17, 8453–8463. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep Reinforcement Learning Assisted Federated Learning Algorithm for Data Management of IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- He, Y.; Yang, M.; He, Z.; Guizani, M. Computation Offloading and Resource Allocation Based on DT-MEC-Assisted Federated Learning Framework. IEEE Trans. Cogn. Commun. Netw. 2023. [Google Scholar] [CrossRef]
- Chakraborty, A.; Misra, S. QoS-Aware Resource Bargaining for Federated Learning over Edge Networks in Industrial IoT. IEEE Trans. Netw. Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, Q.; Li, Q.; Yan, H.; Qi, Y. Long Short-Term Memory Neural Network for Network Traffic Prediction. In Proceedings of the 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Mogyorosi, F.; Pasic, A.; Cziva, R.; Revisnyei, P.; Kenesi, Z.; Tapolcai, J. Adaptive Protection of Scientific Backbone Networks Using Machine Learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1064–1076. [Google Scholar] [CrossRef]
- Zhuo, Y.; Li, B. Fedns: Improving Federated Learning for Collaborative Image Classification on Mobile Clients. In Proceeding of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Tam, P.; Math, S.; Nam, C.; Kim, S. Adaptive Resource Optimized Edge Federated Learning in Real-Time Image Sensing Classifications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10929–10940. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Kim, S. Optimized Multi-Service Tasks Offloading for Federated Learning in Edge Virtualization. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4363–4378. [Google Scholar] [CrossRef]
- National Communications Authority. Guidelines on Regulatory Aspects of QoS; ITU-T E.800-series; National Communications Authority: Accra, Ghana, 2021. [Google Scholar]
- Poryazov, S.A.; Saranova, E.T.; Andonov, V.S. Overall Model Normalization towards Adequate Prediction and Presentation of QoE in Overall Telecommunication Systems. In Proceeding of the 2019 14th International Conference on Advanced Technologies, Systems and Services in Telecommunications (TELSIKS), Nis, Serbia, 23–25 October 2019; pp. 360–363. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of local IIoT participants | |
| Set of edge aggregators with specified resource pooling properties | |
| Set of services for participant | |
| Set of local loss-minimized model parameters from participant at -index round communications | |
| Loss-minimized model parameters in edge aggregator at round | |
| Data distribution of participant at round | |
| Size-based processing time of local model | |
| Tolerable latency of local model | |
| Service criticality of local model | |
| Time slot of local model at edge aggregator | |
| Buffer size of adjusted edge aggregator that loaded | |
| Queueing index of at current time slot at | |
| Upper-bound QoS (e.g., delay) for service | |
| Latency of averaging service toward final model in | |
| Computation latency at participant | |
| Communication latency between participants to edge aggregator | |
| Computation latency in edge aggregator at round | |
| Uplink data rate for updating the local model | |
| Input data and target features | |
| Training input data and target features | |
| Testing input data and target features | |
| Number of models | |
| Batch sizes | |
| Dense units | |
| MLSTM units | |
| Number of epochs | |
| Sampling weights (e.g., weight matrices that determine how the input data contribute to the computation of input gate ) | |
| Bias (e.g., bias terms associated with the input gate ) | |
| Sigmoid and tanh activation functions | |
| , and | LSTM components: input gate, forget gate, output gate, cell state, new cell state, and hidden state |
| ⊙ | Element-wise multiplication |
| Conditions | Upper-Bound Delays | Criticalities | FL-Based Scenarios |
|---|---|---|---|
| Class-1 | 50 ms | High mission-critical | Visual-assisted robot, low-latency manufacturing control |
| Class-2 | 150 ms | Mission-critical | Industrial visual/surveillance systems |
| Class-3 | 300 ms | Low mission-critical | Imaging compression for storage and retrieval |
| Purpose/Platform | Specification |
|---|---|
| Hosting infrastructure | Intel(R) Xeon(R) Silver 4280 CPU @ 2.10 GHz, 128 GB, NVIDIA Quadro RTX 4000 GPU |
| DL platform | Python (TensorFlow and Keras) |
| FL platform | TensorFlow Federated (MNIST dataset) |
| Number of models | 3 (CLSTM-CFL, MLSTM-CCFL, and MLSTM-CEFL) |
| Input shape | (Number of time steps, number of features) |
| Dropout rate | 0.2 |
| Recurrent dropout rate | 0.1 |
| Batch sizes | 512 |
| Dense units | 4 times of MLSTM units |
| MLSTM units | 128 |
| Number of epochs (training, testing) | (1000, 125) |
| Optimizer | Adam |
| Loss | Mean Squared Error |
| Activation function | Sigmoid and Tanh |
| Learning rate | 0.001 |
| Validation split | 0.2 |
| Simulation times for capturing QoS | 250 s (Fair-queueing-based pacing) |
| SDN/NFV-UE, control, and interfaces | Mininet+MiniNFV, RESTful API |
| Number of participants, edge aggregator, and server | (500, 5, 1) |
| CLSTM-CFL | MLSTM-CCFL | MLSTM-CEFL | |
|---|---|---|---|
| Training accuracy | 88.8403% | 95.3122% | 99.5101% |
| Training loss | 0.5991 | 0.2892 | 0.0225 |
| Testing accuracy | 85.1598% | 91.8991% | 99.1356% |
| Testing loss | 0.7812 | 0.4515 | 0.0399 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tam, P.; Kang, S.; Ros, S.; Kim, S. Enhancing QoS with LSTM-Based Prediction for Congestion-Aware Aggregation Scheduling in Edge Federated Learning. Electronics 2023, 12, 3615. https://doi.org/10.3390/electronics12173615
Tam P, Kang S, Ros S, Kim S. Enhancing QoS with LSTM-Based Prediction for Congestion-Aware Aggregation Scheduling in Edge Federated Learning. Electronics. 2023; 12(17):3615. https://doi.org/10.3390/electronics12173615
Chicago/Turabian StyleTam, Prohim, Seungwoo Kang, Seyha Ros, and Seokhoon Kim. 2023. "Enhancing QoS with LSTM-Based Prediction for Congestion-Aware Aggregation Scheduling in Edge Federated Learning" Electronics 12, no. 17: 3615. https://doi.org/10.3390/electronics12173615