
Improved Parallel Implementation of 1D Discrete Wavelet Transform Using CPU-GPU
 , , ,
, , ,
Abstract
:1. Introduction
2. 1D Discrete Wavelet Transform
3. Methodology
3.1. Sequential Multi-Core Strategy
3.2. Parallel Graphics Processing Unit Strategy
4. Experimental Setup and Results
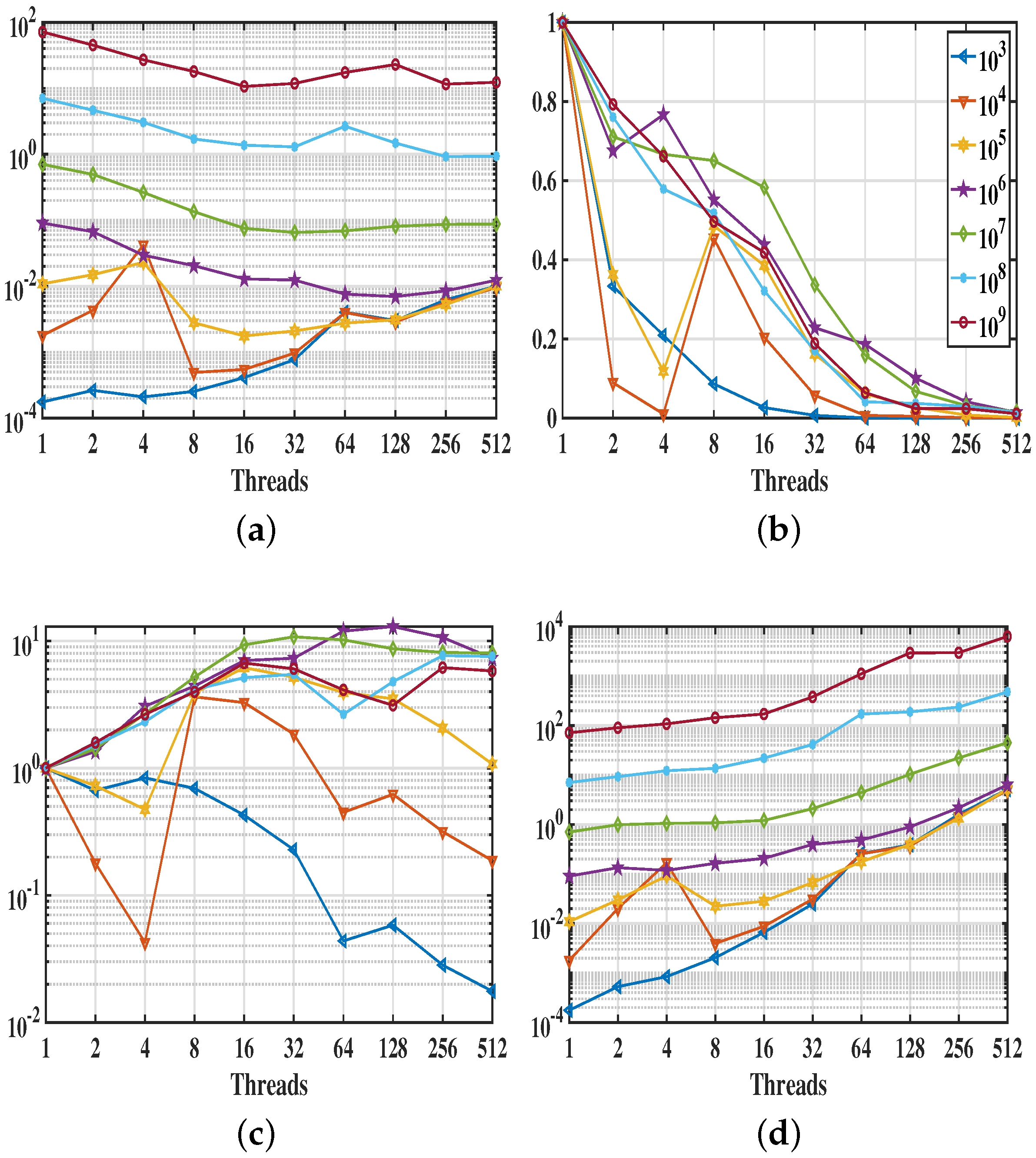
4.1. Parallel Convolution Performance and Scalability
4.1.1. Multi-Core Strategy
4.1.2. Graphics Processing Unit Strategy
4.2. Dwt Performance and Scalability
4.2.1. Multi-Core Strategy
4.2.2. Graphics Processing Unit Strategy
5. Comparison vs. Most Competitive Work
6. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, F.; Shi, F. A Comparative Survey of Big Data Computing and HPC: From a Parallel Programming Model to a Cluster Architecture. Int. J. Parallel Program. 2022, 50, 27–64. [Google Scholar]
- Di Rocco, L.; Ferraro Petrillo, U.; Palini, F. Using software visualization to support the teaching of distributed programming. J. Supercomput. 2023, 79, 3974–3998. [Google Scholar] [CrossRef]
- Umayanganie Munipala, W.; Moore, S.V. Position paper: An evaluation framework for scientific programming productivity. In Proceedings of the 2016 IEEE/ACM International Workshop on Software Engineering for Science (SE4Science), Austin, TX, USA, 16 May 2016; pp. 27–30. [Google Scholar]
- Barlas, G. Computer Architecture: A Quantitative Approach, 2nd ed.; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Gulcan, S.; Ozdal, M.M.; Aykanat, C. Load balanced locality-aware parallel SGD on multicore architectures for latent factor based collaborative filtering. Future Gener. Comput. Syst. 2023, 146, 207–221. [Google Scholar] [CrossRef]
- Ketchaya, S.; Rattanatranurak, A. Parallel Multi-Deque Partition Dual-Deque Merge sorting algorithm using OpenMP. Sci. Rep. 2023, 13, 6408. [Google Scholar] [CrossRef]
- Williams-Young, D.B.; Asadchev, A.; Popovici, D.T.; Clark, D.; Waldrop, J.; Windus, T.L.; Valeev, E.F.; De Jong, W.A. Distributed memory, GPU accelerated Fock construction for hybrid, Gaussian basis density functional theory. J. Chem. Phys. 2023, 158, 234104. [Google Scholar] [CrossRef]
- Peng, H.; Hu, B.; Shi, Q.; Ratcliffe, M.; Zhao, Q.; Qi, Y.; Gao, G. Removal of ocular artifacts in EEG—An improved approach combining DWT and ANC for ubiquitous applications. IEEE J. Biomed. Health Inform. 2013, 17, 600–607. [Google Scholar] [CrossRef]
- Hu, B.; Peng, H.; Zhao, Q.; Hu, B.; Majoe, D.; Zheng, F.; Moore, P. Signal quality assessment model for wearable EEG sensor on prediction of mental stress. IEEE Trans. Nanobioscience 2015, 14, 553–561. [Google Scholar]
- Guger, C.; Allison, B.Z.; Miller, K. (Eds.) Brain-Computer Interface Research: A State-of-the-Art Summary 8; SpringerBriefs in Electrical and Computer Engineering; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Peng, H.; Hu, B.; Zheng, F.; Fan, D.; Zhao, W.; Chen, X.; Yang, Y.; Cai, Q. A method of identifying chronic stress by EEG. Pers. Ubiquitous Comput. 2013, 17, 1341–1347. [Google Scholar] [CrossRef]
- Wagh, K.P.; Vasanth, K. Performance evaluation of multi-channel electroencephalogram signal (EEG) based time frequency analysis for human emotion recognition. Biomed. Signal Process. Control 2022, 78, 103966. [Google Scholar] [CrossRef]
- Sharmila, A.; Geethanjali, P. DWT based detection of epileptic seizure from EEG signals using naive bayes and k-nn classifiers. IEEE Access 2016, 4, 7716–7727. [Google Scholar] [CrossRef]
- Chamanzar, A.; Shabany, M.; Malekmohammadi, A.; Mahammadinejad, S. Efficient hardware implementation of real-time low-power movement intention detector system using FFT and adaptive Wavelet transform. IEEE Trans. Biomed. Circ. Syst. 2017, 11, 585–596. [Google Scholar] [CrossRef]
- Healey, J.A.; Picard, P.W. Detecting stress during real-world driving task using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef] [Green Version]
- Strickland, E. Mind games. IEEE Spectr. 2018, 55, 40–41. [Google Scholar] [CrossRef]
- Qiu, S.; Li, Z.; He, W.; Zhang, L.; Yang, C.; Su, C.Y. Brain-machine interface and visual compressive sensing-based teleoperation control of an exoskeleton robot. IEEE Trans. Fuzzy Syst. 2017, 26, 58–59. [Google Scholar] [CrossRef] [Green Version]
- Ali, A.H.; George, L.E. High synthetic audio compression model based on fractal audio coding and error-compensation. Ann. Emerg. Technol. Comput. 2022, 2, 1–12. [Google Scholar]
- Ding, E.; Ozdemir, N.; Ustundag, O.; Buker, E.; Tikan, G.; Hoang, V.D. Wavelet signal processing tools for quantifying and monitoring the in-vitro dissolution profiles of Tenofovir Disoproxil Fumarate and Emtricitabine in tablets. J. Mex. Chem. Soc. 2022, 66, 488–499. [Google Scholar]
- Mota-Carmona, J.R.; Pérez-Escamirosa, F.; Minor-Martínez, A.; Rodríguez-Reyna, R.M. Muscle fatigue detection in upper limbs during the use of the computer mouse using discrete wavelet transform: A pilot study. Biomed. Signal Process. Control 2022, 76, 103711. [Google Scholar]
- Dong, Y.; Zhou, H.; Fu, Y.; Li, X.; Geng, H. Wavelet periodic and compositional characteristics of atmospheric PM2.5 in a typical air pollution event at Jinzhong city, China. Atmos. Pollut. Res. 2021, 12, 245–254. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, G.; Li, S.; Li, Y.; He, L.; Liu, D. Arrhythmia classification algorithm based on multi-head self-attention mechanism. Biomed. Signal Process. Control 2023, 79, 104206. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, C.; Sun, J.; Cao, Y.; Fu, L. Classification of heavy metal Cd stress in lettuce leaves based on WPCA algorithm and fluorescence hyperspectral technology. Infrared Phys. Technol. 2021, 119, 103936. [Google Scholar] [CrossRef]
- La Cour-Harbo, A.; Jensen, A. Wavelets and the Lifting Scheme. In Encyclopedia of Complexity and Systems Science; Meyers, R.A., Ed.; Springer: New York, NY, USA, 2009; pp. 10007–10031. [Google Scholar]
- Relkar, R.E.; Rathkanthiwar, A.P. VLSI architecture design for DWT: Using polyphase and pipelining and their effective comparasion. In Proceedings of the 2015 International Conference on Information Processing (ICIP), Pune, India, 16–19 December 2015; pp. 828–832. [Google Scholar] [CrossRef]
- Zhi, L.; Liu, W.; Liu, Q. Matrix Operation of Discrete Wavelet Transform. In Proceedings of the 2012 International Conference on Industrial Control and Electronics Engineering, Hangzhou, China, 23–25 March 2012; pp. 1214–1216. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Z.; Wang, C.; Feng, L.; Zhang, Z. Implementation of discrete wavelet transform. In Proceedings of the 2014 12th IEEE International Conference on Solid-State and Integrated Circuit Technology (ICSICT), Guilin, China, 28–31 October 2014; pp. 1–3. [Google Scholar]
- Nicolier, F.; Laligant, O.; Truchetet, F. Discrete wavelet transform implementation in Fourier domain for multidimensional signal. J. Electron. Imaging 2002, 11, 338–346. [Google Scholar]
- Kamil, S.; Kamil, W.; Mykhaylo, Y. An efficient implementation of one-dimensional discrete wavelet transform algorithms for GPU architectures. J. Supercomput. 2022, 78, 11539–11563. [Google Scholar]
- Proakis, J.; Manolakis, D. Digital Signal Processing: Principles, Algorithms, and Applications; Pearson-Prentice Hall: Hoboken, NJ, USA, 2007. [Google Scholar]
- Hennessy, J.; Patterson, D. Computer Architecture: A Quantitative Approach, 6th ed.; Morgan Kaufmann: Burlington, MA, USA, 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| j | 0 | 1 |
| −0.1115407434 | 0.4946238904 | |
| −0.0010773011 | 0.0047772575 | |
| j | 2 | 3 |
| −0.7511339080 | 0.3152503517 | |
| 0.0005538422 | −0.0315820393 | |
| j | 4 | 5 |
| 0.2262646940 | −0.1297668676 | |
| 0.0275228655 | 0.0975016056 | |
| j | 6 | 7 |
| −0.0975016056 | 0.0275228655 | |
| −0.1297668676 | −0.2262646940 | |
| j | 8 | 9 |
| 0.0315820393 | 0.0005538422 | |
| 0.3152503517 | 0.7511339080 | |
| j | 10 | 11 |
| −0.0047772575 | −0.0010773011 | |
| 0.4946238904 | 0.1115407434 |
| Attribute | Value |
|---|---|
| CUDA driver version/runtime version | 11.0/10.2 |
| CUDA capability | 6.1 |
| Total amount of global memory | 8 GB |
| (20) Multiprocessors, (128) CUDA cores/MP | 2560 CUDA cores |
| Maximum number of threads per multiprocessor | 2048 |
| Maximum number of threads per block | 1024 |
| Max dimension size of a thread block (x, y, z) | (1024, 1024, 64) |
| Max dimension size of a grid (x, y, z) | (2,147,483,647, 65,535, 65,535) |
| Data Size 1 | Data Size 2 | Data Size 3 | Data Size 4 | Data Size 5 | Data Size 6 | Data Size 7 | |
|---|---|---|---|---|---|---|---|
| Stokfiszewski [29] | – | – | |||||
| Proposal |
| Length/Time | |||||||
|---|---|---|---|---|---|---|---|
| Stokfiszewski [29] | – | – | |||||
| Proposal | |||||||
| Length/Time | ||||||
|---|---|---|---|---|---|---|
| Stokfiszewski [29] | – | |||||
| Proposal | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez-Martinez, E.; Benavides-Alvarez, C.; Aviles-Cruz, C.; Lopez-Saca, F.; Ferreyra-Ramirez, A. Improved Parallel Implementation of 1D Discrete Wavelet Transform Using CPU-GPU. Electronics 2023, 12, 3400. https://doi.org/10.3390/electronics12163400
Rodriguez-Martinez E, Benavides-Alvarez C, Aviles-Cruz C, Lopez-Saca F, Ferreyra-Ramirez A. Improved Parallel Implementation of 1D Discrete Wavelet Transform Using CPU-GPU. Electronics. 2023; 12(16):3400. https://doi.org/10.3390/electronics12163400
Chicago/Turabian StyleRodriguez-Martinez, Eduardo, Cesar Benavides-Alvarez, Carlos Aviles-Cruz, Fidel Lopez-Saca, and Andres Ferreyra-Ramirez. 2023. "Improved Parallel Implementation of 1D Discrete Wavelet Transform Using CPU-GPU" Electronics 12, no. 16: 3400. https://doi.org/10.3390/electronics12163400