
Multi-Modality Tensor Fusion Based Human Fatigue Detection

Abstract
:1. Introduction
- Through experiments, we explore whether a given problem can be viewed and solved from a complex perspective by combining multiple effects from data on the single-modal side. In particular, quantitative analysis results were intended to confirm whether they are effective in achieving indicators on qualitative evaluation criteria, providing implications for AI research such as empirical and intellectual judgment using complex human senses as inputs.
- By comparing the effect of combining the results and analyzing each input data with a high-performance model to the effect of analyzing the representations of the raw input data, we propose an initial methodological study to discover new analysis orientations such as viewpoint and intention.
2. Related Works
2.1. Multimodal Learning
2.2. Measuring Fatigue and Fatigue Levels
2.3. Findings on Human Activities
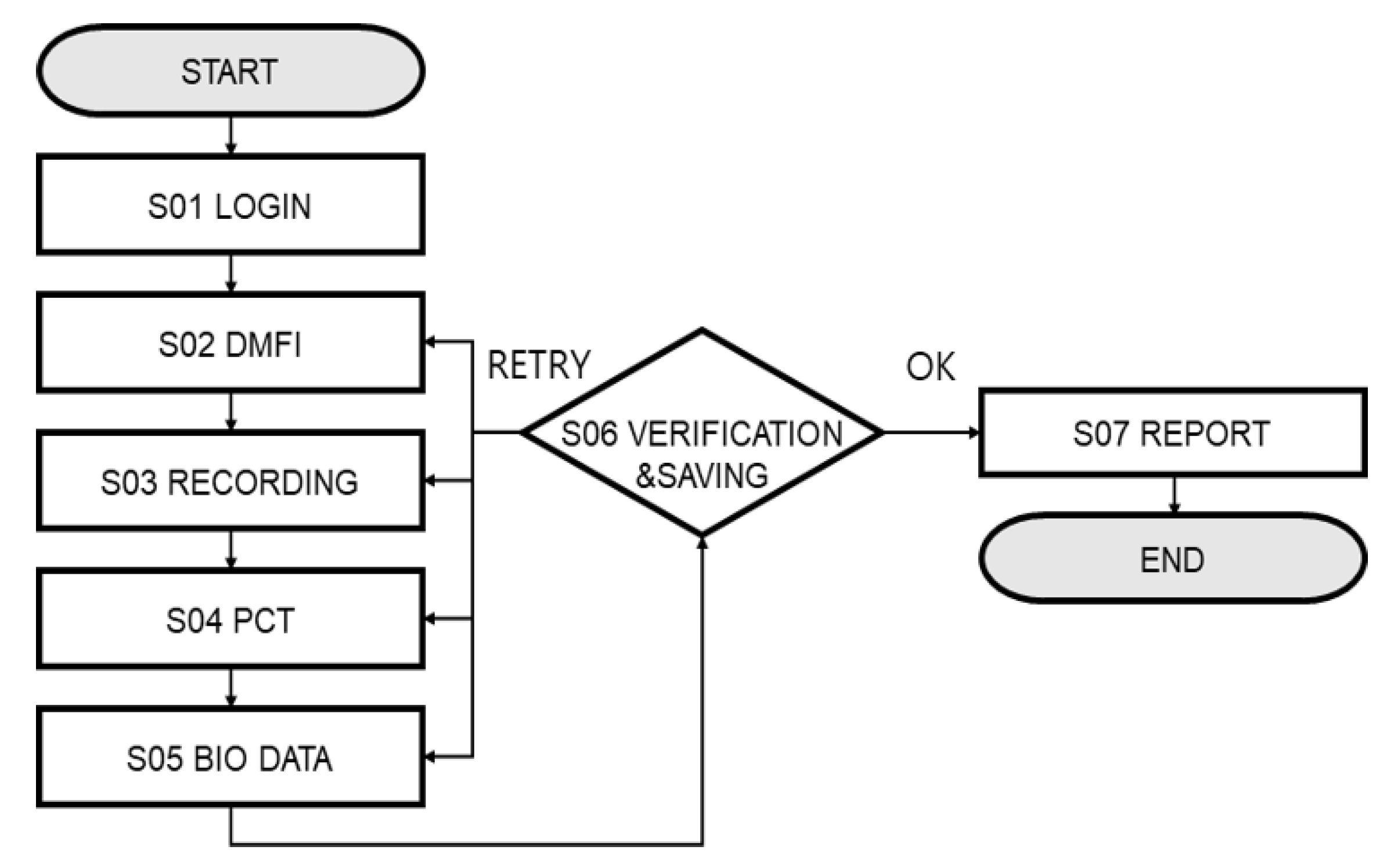
3. Detecting Fatigue Levels through Multimodal Tensor Fusion
3.1. F-TFN1: SubModels
3.2. F-TFN2: SubNets
4. Results
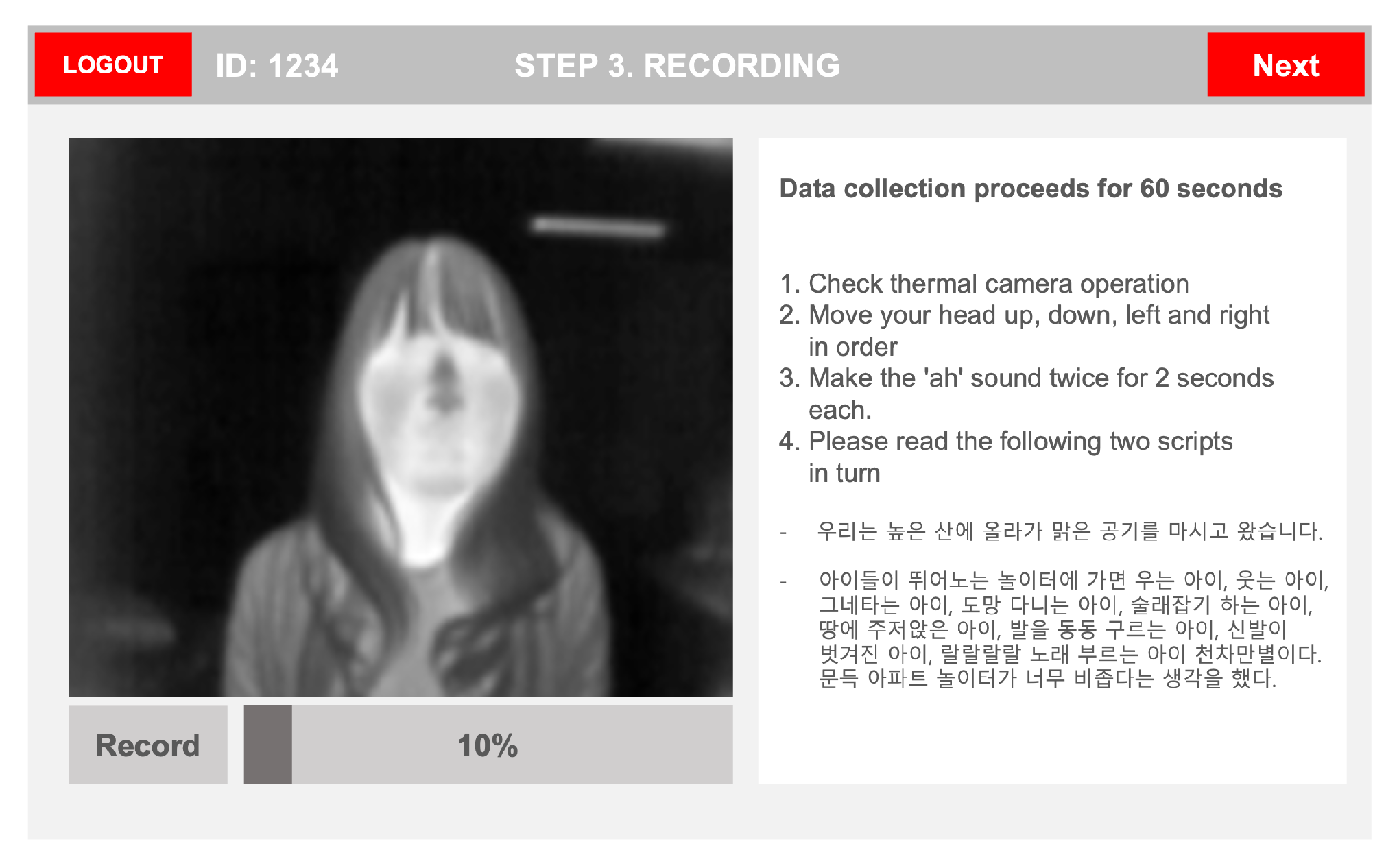
4.1. Fatigue Level Dataset
4.2. Model Tuning
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Seo, P.H.; Nagrani, A.; Arnab, A.; Schmid, C. End-to-end generative pretraining for multimodal video captioning. In Proceedings of the of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 17959–17968. [Google Scholar]
- Fu, J.; Rui, Y. Advances in deep learning approaches for image tagging. APSIPA Trans. Signal Inf. Process. 2017, 6, E11. [Google Scholar] [CrossRef] [Green Version]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Mathur, P.; Gill, A.; Yadav, A.; Mishra, A.; Bansode, N.K. Camera2Caption: A real-time image caption generator. In Proceedings of the International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 2–3 June 2017; pp. 1–6. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2020; pp. 1505–1514. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Wu, D.; Cao, L.; Zhou, P.; Li, N.; Li, Y.; Wang, D. Infrared small-target detection based on radiation characteristics with a multimodal feature fusion network. Remote Sens. 2022, 14, 3570. [Google Scholar] [CrossRef]
- Rana, A.; Jha, S. Emotion based hate speech detection using multimodal learning. arXiv 2022, arXiv:2202.06218. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. Soundnet: Learning sound representations from unlabeled video. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Oh, T.H.; Dekel, T.; Kim, C.; Mosseri, I.; Freeman, W.T.; Rubinstein, M.; Matusik, W. Speech2face: Learning the face behind a voice. In Proceedings of the of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7539–7548. [Google Scholar]
- Morency, L.P.; Mihalcea, R.; Doshi, P. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the of the 13th international conference on multimodal interfaces, Alicante, Spain, 14–18 November 2011; pp. 169–176. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the of the conference on empirical methods in natural language processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar]
- Elliott, D.; Kiela, D.; Lazaridou, A. Multimodal learning and reasoning. In Proceedings of the of the 54th annual meeting of the association for computational linguistics: Tutorial abstracts, Berlin, Germany, 6–12 August 2016. [Google Scholar]
- Chen, C.; Han, D.; Wang, J. Multimodal encoder-decoder attention networks for visual question answering. IEEE Access 2020, 8, 35662–35671. [Google Scholar] [CrossRef]
- Verma, G.; Mujumdar, R.; Wang, Z.J.; De Choudhury, M.; Kumar, S. Overcoming Language Disparity in Online Content Classification with Multimodal Learning. arXiv 2022, arXiv:2205.09744. [Google Scholar] [CrossRef]
- Hou, J.C.; Wang, S.S.; Lai, Y.H.; Tsao, Y.; Chang, H.W.; Wang, H.M. Audio-visual speech enhancement using multimodal deep convolutional neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Rastgoo, M.N.; Nakisa, B.; Maire, F.; Rakotonirainy, A.; Chandran, V. Automatic driver stress level classification using multimodal deep learning. Expert Syst. Appl. 2019, 138, 112793. [Google Scholar] [CrossRef]
- Ma, Y.; Hao, Y.; Chen, M.; Chen, J.; Lu, P.; Košir, A. Audio-visual emotion fusion (AVEF): A deep efficient weighted approach. Inf. Fusion 2019, 46, 184–192. [Google Scholar] [CrossRef]
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.H.; Chang, S.F.; Cui, Y.; Gong, B. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; Volume 34. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient low-rank multimodal fusion with modality-specific factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Dinges, D.F. An overview of sleepiness and accidents. J. Sleep Res. 1995, 4, 4–14. [Google Scholar] [CrossRef]
- Smets, E.; Garssen, B.; Bonke, B.d.; De Haes, J. The Multidimensional Fatigue Inventory (MFI) psychometric qualities of an instrument to assess fatigue. J. Psychosom. Res. 1995, 39, 315–325. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.; Shin, S.; Cho, T.; Yeom, H.; Kim, D. An Experimental study on Self-rated Fatigue Assessment Tool for the Fatigue Risk Groups. In Proceedings of the of 2021 KMIST Conference, Virtual Event, 11–15 January 2021; pp. 1755–1756. [Google Scholar]
- Choe, J.H.; Antoine, B.S.R.; Kim, J.H. Trend of Convergence Technology between Healthcare and the IoT. Inf. Commun. Mag. 2014, 31, 10–16. [Google Scholar]
- Kim, K.; Lim, C. Wearable health device technology in IoT era. Korean Inst. Electr. Eng. 2016, 65, 18–22. [Google Scholar]
- Kim, D. A Study on the Pilot Fatigue Measurement Methods for Fatigue Risk Management. Korean J. Aerosp. Environ. Med. 2020, 30, 54–60. [Google Scholar] [CrossRef]
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver drowsiness detection via a hierarchical temporal deep belief network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 117–133. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Yoo, S.; Kim, S.; Kim, D.; Lee, Y. Development of Acquisition System for Biological Signals using Raspberry Pi. J. Korea Inst. Inf. Commun. Eng. 2021, 25, 1935–1941. [Google Scholar]








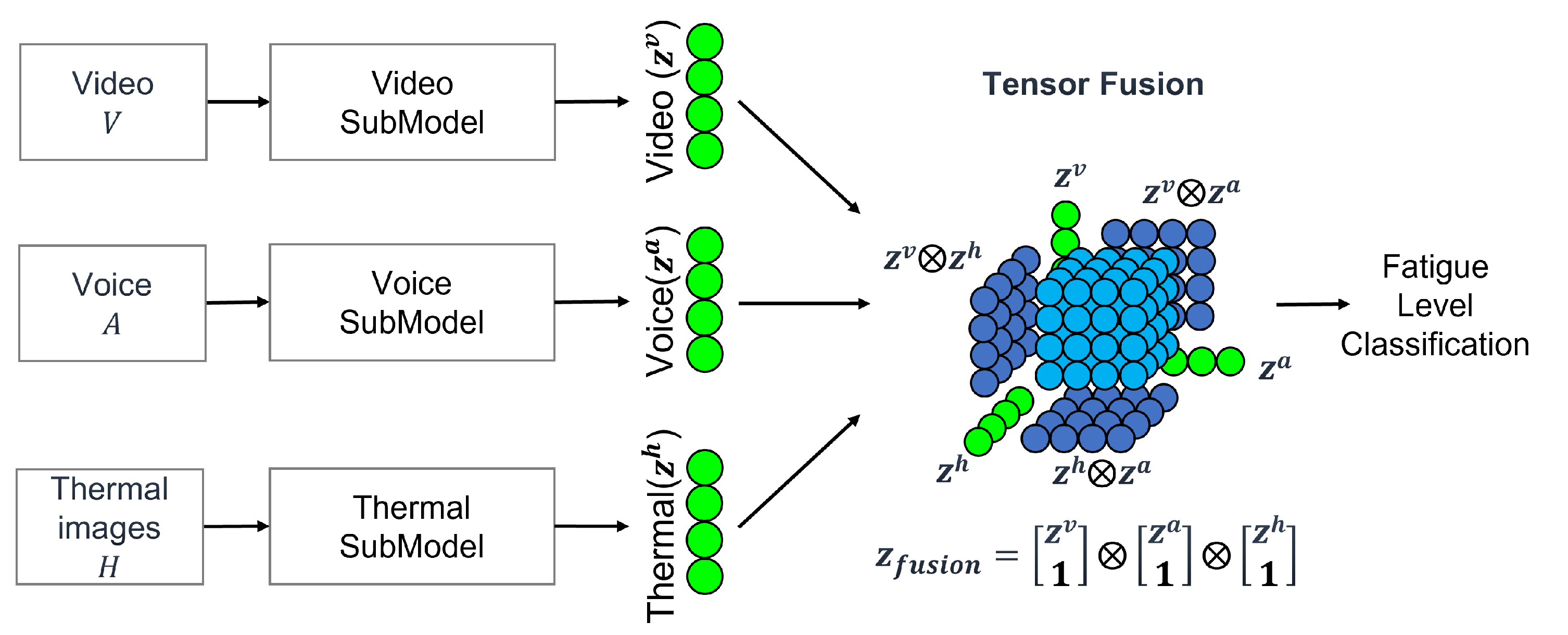{kind=link}
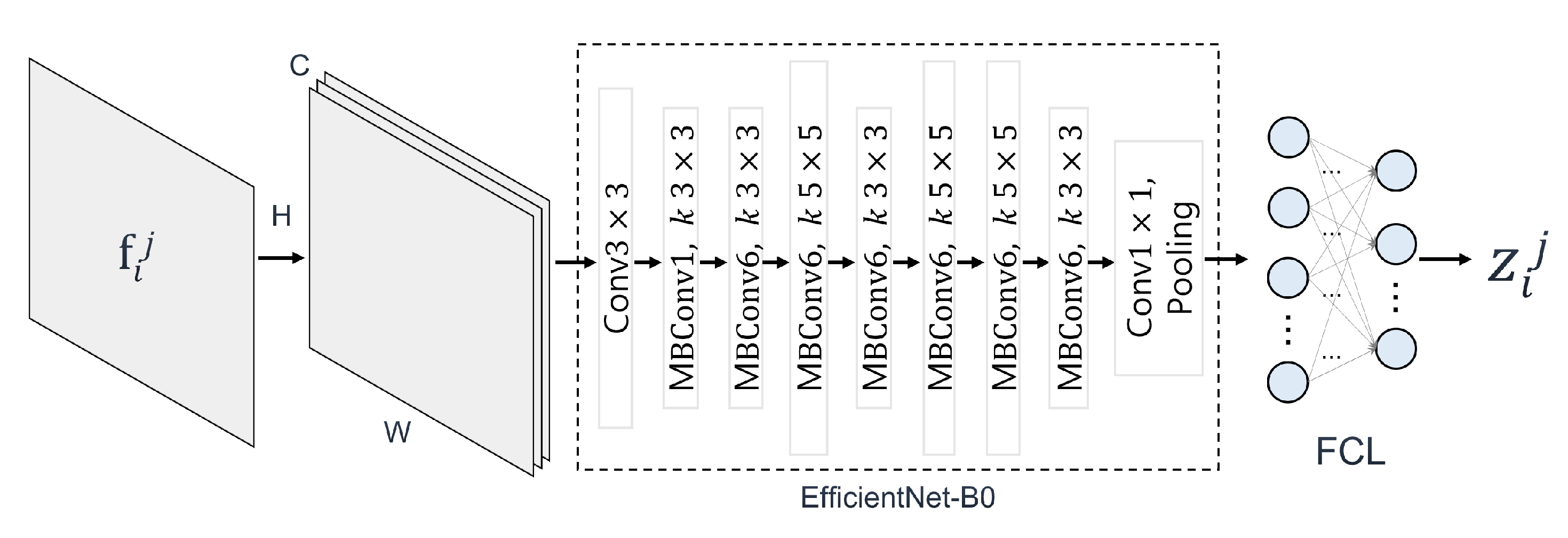{kind=link}
{kind=link}
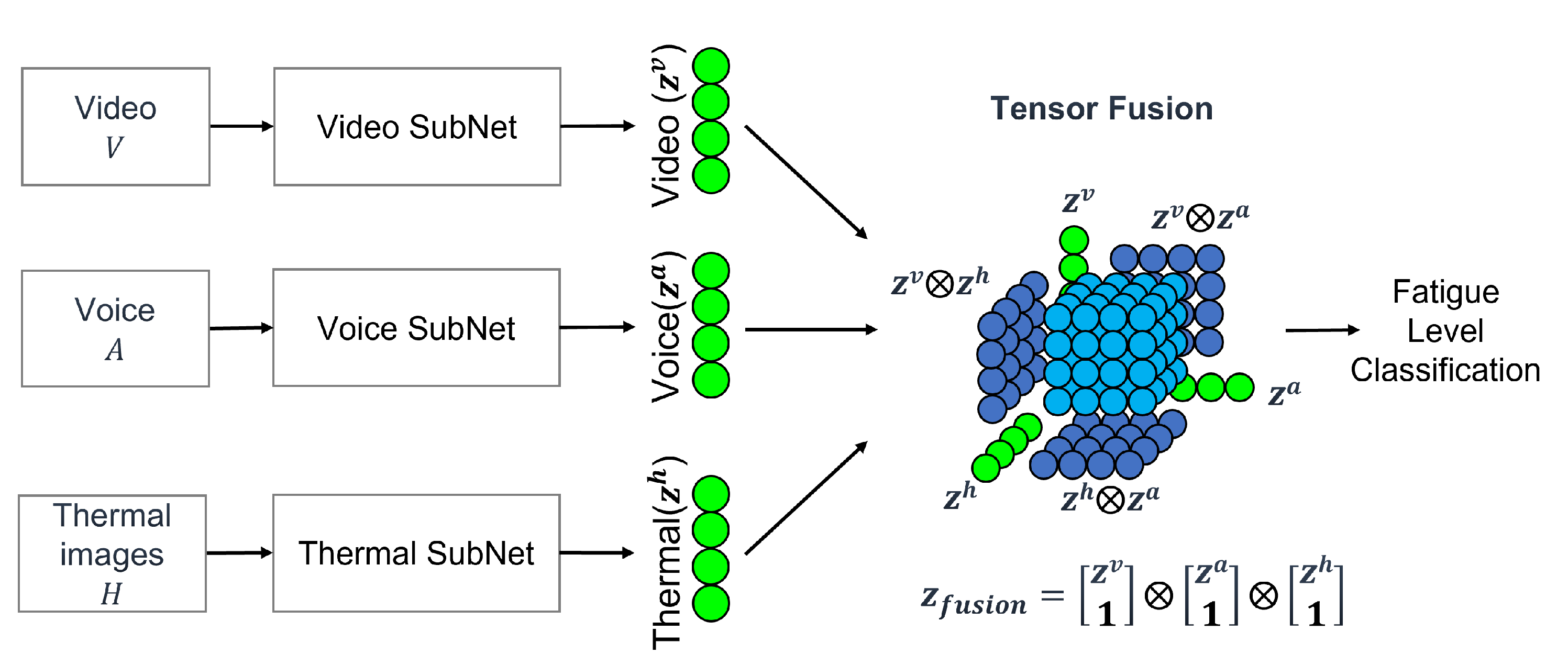{kind=link}
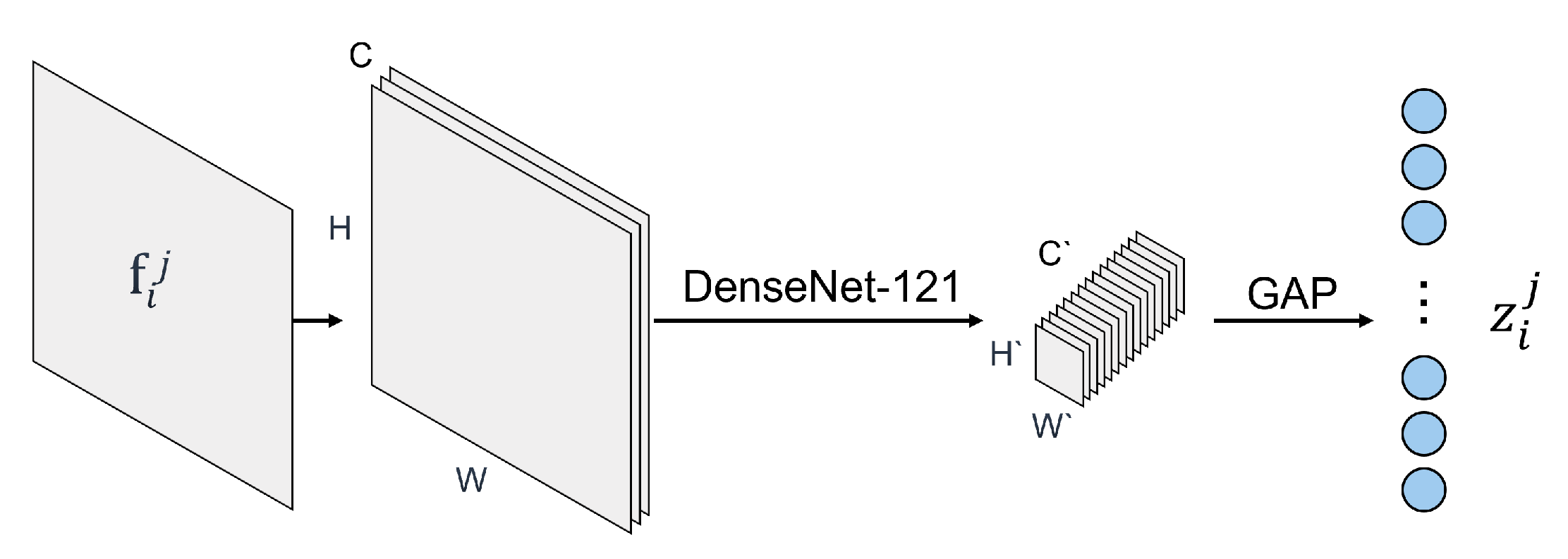{kind=link}
{kind=link}
{kind=link}
| Environment | Modalities | F-TFN 1 (SubModel) | F-TFN 2 (SubNet) | ||||
|---|---|---|---|---|---|---|---|
| Accuracy | Recall | Precision | Accuracy | Recall | Precision | ||
| Uni-modality | Videos | 0.359 | 0.185 | 0.332 | 0.401 | 0.167 | 0.498 |
| Voices | 0.311 | 0.334 | 0.327 | 0.345 | 0.463 | 0.324 | |
| Thermal images | 0.320 | 0.241 | 0.263 | 0.317 | 0.280 | 0.370 | |
| Bi-modality | Videos + Voices | 0.419 | 0.409 | 0.637 | 0.424 | 0.455 | 0.553 |
| Videos + Thermal images | 0.452 | 0.382 | 0.570 | 0.381 | 0.315 | 0.453 | |
| Voices + Thermal images | 0.403 | 0.431 | 0.425 | 0.457 | 0.553 | 0.497 | |
| Tensor Fusion | Videos + Voices + Thermal images | 0.598 | 0.703 | 0.651 | 0.646 | 0.742 | 0.717 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, J.; Ryu, J.; Ko, J. Multi-Modality Tensor Fusion Based Human Fatigue Detection. Electronics 2023, 12, 3344. https://doi.org/10.3390/electronics12153344
Ha J, Ryu J, Ko J. Multi-Modality Tensor Fusion Based Human Fatigue Detection. Electronics. 2023; 12(15):3344. https://doi.org/10.3390/electronics12153344
Chicago/Turabian StyleHa, Jongwoo, Joonhyuck Ryu, and Joonghoon Ko. 2023. "Multi-Modality Tensor Fusion Based Human Fatigue Detection" Electronics 12, no. 15: 3344. https://doi.org/10.3390/electronics12153344