3. Data Fusion Based on Tensor Computing
Tensor computing provides an efficient way of data fusion, which is based on the data structure of tensor as shown in (
1). The big data from the smart grid and the power communication network are both dealt with in the format of tensors. Due to practical reasons, the tensor big data is sometimes sparse or incomplete. The tensor completion scheme is used to complete sparse tensor big data. In order to generate the fused data
, the tensor decomposition scheme is used to analyze the target tensor big data from a specific dimension.
3.1. Preliminary of Tensor Computing
Here the tensor is defined as a multidimensional array. More precisely, an
Nth-order or
N-way tensor is an element of
N vector spaces defined by the tensor product, each of which has its own coordinate system. This notion of a tensor is not equal to tensors in physics and chemistry, such as stress, and is always termed as a tensor field in mathematics. The concept of tensors is a generalization of vectors or matrices. A first-order tensor is a vector, a second-order tensor is a matrix, and tensors of order three or more are called higher-order tensors. An
N-way tensor
is rank-one if and only if it can be written as the outer product of N vectors, i.e.,
, where
denotes a
i-length vector. Tensor matricization, expressed as unfolding, is the process of reordering the elements of a tensor into a matrix. The mode-n matricization of a tensor
is denoted by
and arranges the mode-n vectors to be the columns of the unfolding matrix. Tensors can be multiplied, and it is obvious that the product of tensors is much more complex than matrices. Here we just consider the tensor n-mode product rather than a full treatment of tensor multiplication. The n-mode (matrix) product of a tensor
with a matrix
is denoted by
and is of size
Elementswise, we have
where
is the element of
and
denotes the
-the element of
.
3.2. Tensor Decomposition
Tensor decomposition can be achieved by matrix singular value decomposition (SVD) and be utilized in the field of principal component analysis (PCA); that is, it can be considered as a higher-order generalization of matrix decomposition. Tensor decomposition can solve the dimensional disaster problem so as to fulfill dimensionality reduction processing, missing data filling, and implicit relationship mining. However, this method will make the structural information of the data lost, and the use of tensors to store the data can retain the structural information of the data. Two common decompositions in tensor decomposition are the Canonical Polyadic Decomposition (CPD) and the Tucker decomposition.
3.2.1. Cp Decomposition
The CPD is a form of decomposing arbitrary higher-order tensors into sums of multiple rank-one tensors. Take the third-order tensor
as an example; the CPD of the tensor can be written as
where
R is the size of tensor rank,
, the operation “∘” denotes the vector outer product. The decomposition expression is concise, but the solution for rank is an NP-hard problem. The matrix composed of vectors that make up rank-one tenors is called the factor matrix under CPD, such as
, the factor matrix
and
are defined the same. The CPD in matrix form can be written as
The CPD can usually be more simply written as follows
Taking the third-order tensor
as an example, the goal of the algorithm is to calculate a CPD containing R rank-one tensors, so that it is as close as possible to the actual tensor, i.e.,
3.2.2. Tucker Decomposition
Tucker decomposition was first proposed as a generalization of PCA in high dimensions. The model for the Tucker decomposition of the third-order tensor is
where
denotes the core tensor and
,
, and
are three matrices from three dimensions. The scalar form is expressed as
where
. When
and the kernel tensor is a supersymmetric tensor, the Tucker decomposition degenerates into the CPD. One of Tucker decomposition algorithms is indicated in Algorithm 1:
| Algorithm 1 Tucker decomposition algorithm |
- 1:
for n = 1, …, N do - 2:
= left singular vectors of - 3:
- 4:
return - 5:
end for
|
3.3. Tensor Completion
In reality, due to the limitation of data collection faults and other abnormal conditions, there are parts of missing data in the big data, which are called missing values. The repair of these missing values is called completion, and the estimation of missing values in the tensor domain is tensor completion. The core problem of missing data estimation is how to construct the relationship between missing values and observed values. Tensor completion is based on the impact of existing data on missing values and the low-rank assumption, which is mainly divided into two types of methods: one is based on the given rank and update factor in tensor completion; the other is to directly minimize the tensor rank and update the low-rank tensors. In the following, we take a third-order tensor completion problem as an example to introduce a special tensor completion algorithm named HaLRTC (high accuracy low rank tensor completion). Similar to matrix completion, given a sparse tensor
of size
, the index set corresponding to the observed elements is denoted as
. Let the tensor
of the same size be a binary tensor composed of elements 0 and 1, and satisfy
, otherwise
. The objective function of the tensor completion problem can be written in the following format
where
represents the estimation of the original tensor
, the magnitude of tensors
,
,
are
, the matrix
with the magnitude of
represents the mode-1 unfolding of tensor
under mode-1 unfolding and the matrix
represents the mode-2 unfolding of
, and the matrix
represents the mode-3 unfolding of
. In the objective function, the symbol
represents the trace norm. The parameters
,
,
need to satisfy
. There are two constraints of the optimization model. The first is to ensure that the elements of the estimated tensor
and the original tensor
on the set
are equal. The second is to set the intermediate variables
,
, and
equal to the estimated tensors. The constraints are given as follows
The HaLRTC algorithm is indicated in Algorithm 2:
| Algorithm 2 HaLRTC algorithm |
- 1:
Input , adaptively changing and maximum number of iterations K. - 2:
Initialize estimated tensor that , and attached zero tensor . - 3:
Let k = 1. - 4:
Update : , next; (). - 5:
Update : . - 6:
Update : . - 7:
If , return to step 4, else return estimated tensor . - 8:
End.
|
3.4. Tensor Based Data Fusion
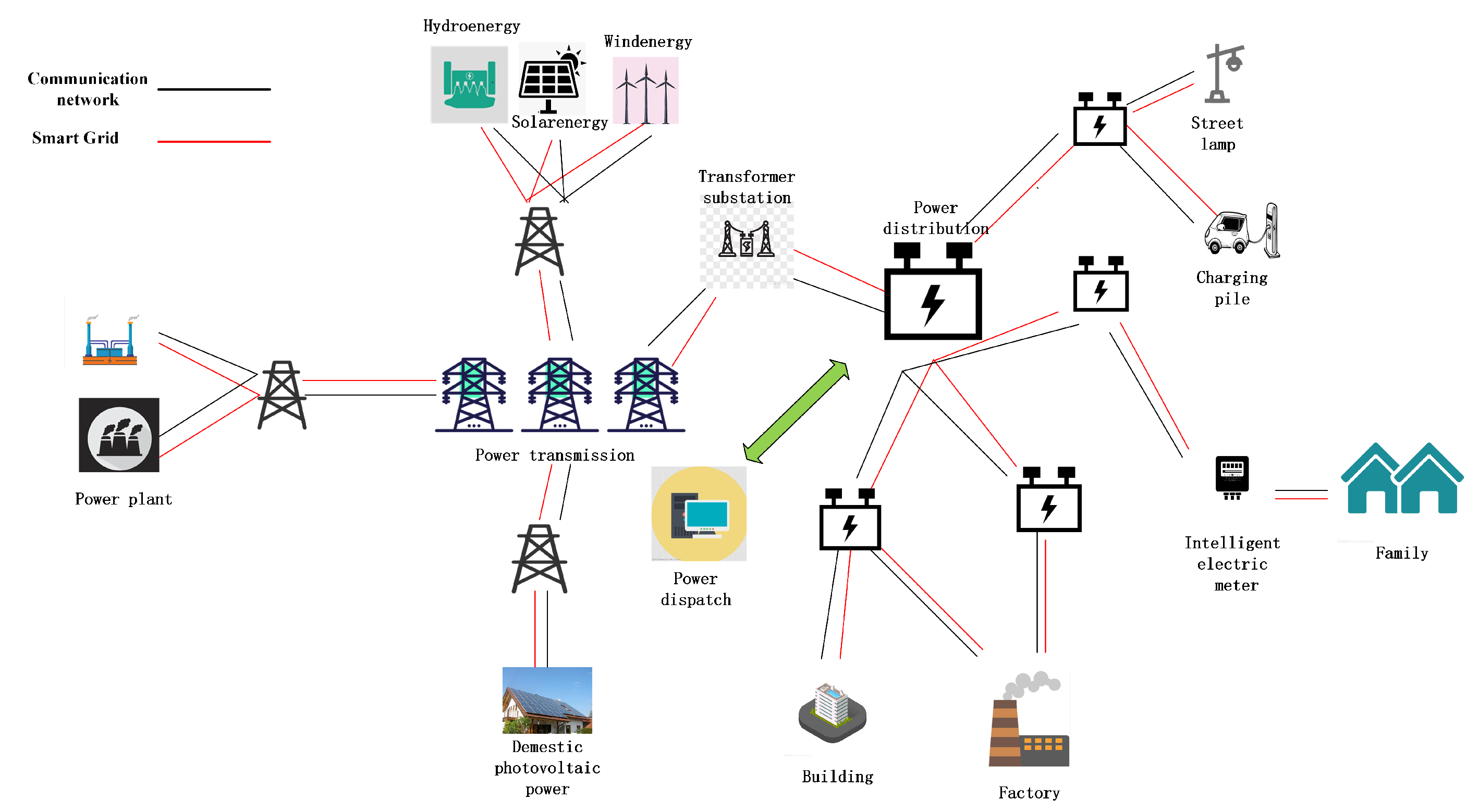
The big data from both the smart grid and the power communication network should be heterogeneous and multidimensional due to the different kinds of sensors. The big data should also be sparse, and some key elements are missing due to unideal operation scenarios.
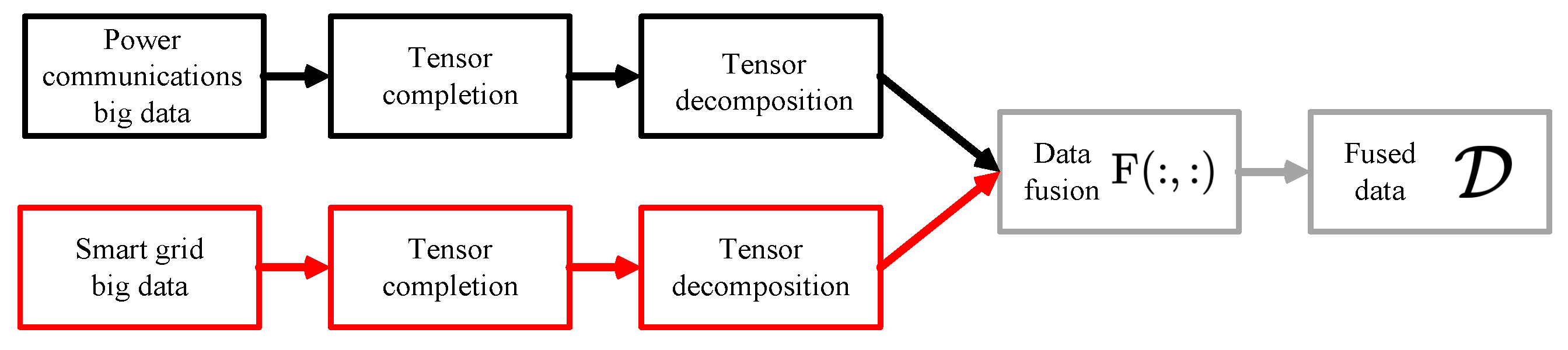
The DF scheme is shown in
Figure 2, where the big data generated from both networks are completed and decomposed with tensor completion and tensor decomposition.
The big data is first transformed into the tensor format, meaning that the sparse and heterogeneous data are compacted into a given tensor format, such as
and
. The tensor completion is used to complete the missing elements of
and
. The tensor decomposition is used to analyze the tensor big data from a specific dimension, such as time, frequency, or value. The tensor big data from both networks
and
are provided to the fusion function
as indicated in (
1) and the fused tensor data
is generated with the given format.
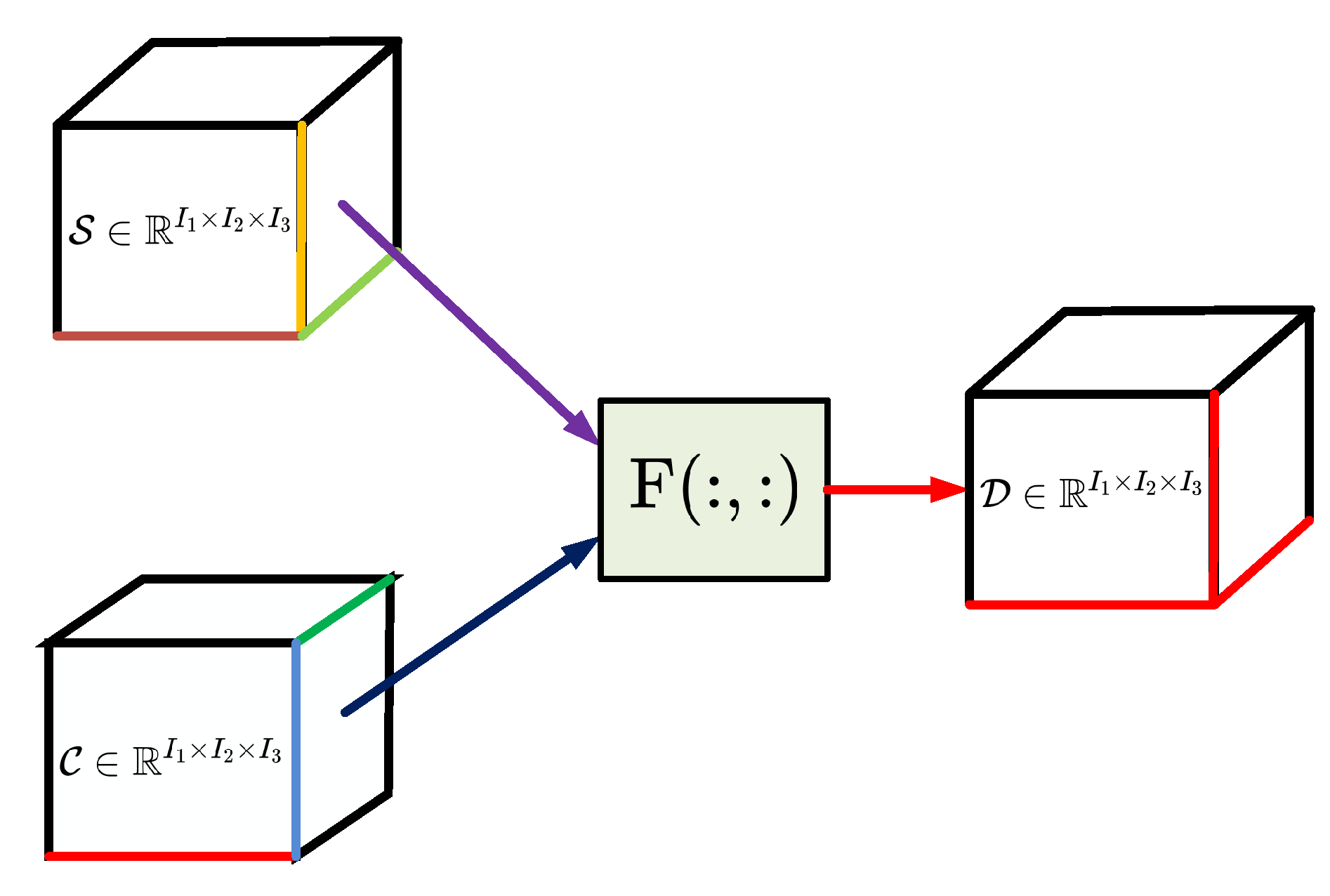
The data fusion scheme is shown in
Figure 3, where both the tensor data
of the smart grid and the tensor data
of the power communication network are assumed to be the third-order tensors, i.e.,
and
. Three dimensions
, and
can present different dimensions, such as the time
T, the frequency
F, and the value
V. The heterogeneous and multidimensional big data from both networks can be compacted and denoted by sparse tensors. With this expression method, the big data can be processed in an efficient and low-complexity way. The key function of DF is
, which generates a new tensor data
with the same tensor format
. The fused tensor data
is used to indicate the total states of two networks, and two networks can also be analyzed based on
. Based on the fused tensor data
, the situation of both networks can be sensed and evaluated.
4. Situation Awareness Based on Deep Reinforcement Learning
DF scheme provides an efficient way to process and express the big data from both networks based on tensor computing. Tensor completion and decomposition schemes also provide solutions to deal with sparse tensor big data and analyze them from a specific dimension. The fused tensor big data can be used in SA. Some key information can be analyzed and generated from the fused tensor data .
4.1. Situation State and Observation State
The situation state can be modeled and compacted in tensor data , in which multidimensional elements are used to indicate the situations of two networks. For example, the key information of the smart grid can be presented with tensor data . The operation information, such as current, total consumption, and so on, can be compacted into the tensor data. Moreover, the key information of the power communication network, such as bandwidth, outage probability, data rate, spectrum efficiency, and so on, can be compacted into tensor data .
The situation state can be sensed by N agents from K channels, so the state information in the time slot t by the nth agent can be expressed as a K-length state vector , where denotes two working states: correct (1) or wrong (0). The state values 1 and 0 are used to indicate whether the situation state is correct, meaning that the current state is working well. With N agents, for a given time slot t, a situation state matrix can be generated. For a period time T, a state tensor can be formulated. Note that the state matrix can be calculated by the state tensor from a specific dimension. Therefore, based on tensor big data and , the situation states of both networks can be formulated in the format of tensors. Following the same way, the observation state of the nth agent in the time slot t can be expressed as a K-length observation vector , where . The observation tensor can be generated.
4.1.1. Agent Action
Total N agents are used to sense the situation states with K channels in total T time slots. The action of the agent is used to sense the current state and return sense results. The action of N agents can be defined as , where denotes a K-length action vector and the element means the n-th agent takes the action at the k-th channel at the t-th time slot. The action of 1 indicates that the result of action (sensing) is correct with the current real situation.
4.1.2. System Reward
When the
n-th agent senses the current situation state successfully, the system can receive reward feedback denoted by a given number. Define the
N-length agent reward vector as
and let
denote the reward for the
n-th agent at the
t-th time slot. When the agent can sense the situation state correctly, a positive reward
is returned to the system; otherwise, a negative reward
p as a penalty will be returned. The reward
of the
n-th agent at the
t-th time slot can be given as
where
and
are used to denote the positive and negative rewards, respectively.
For the proposed SA scheme, the final goal is to achieve an optimal sensing strategy
ß to train the whole system to obtain the maximum reward, in other words, all
N agents should work together to obtain situation states correctly. So we define a long-term accumulated reward
, which is based on the given policy
. The accumulated reward
based on the reward function can be expressed as
where
is the expectation function,
is denotes a loss factor and
is the time cumulative series.
4.2. Deep Reinforcement Learning Scheme
In order to achieve an optimal SA scheme, the DQN algorithm and the MAAC algorithm are discussed.
4.2.1. Deep Q-Network Algorithm
The DQN algorithm is currently one of the most popular reinforcement learning algorithms. It can be used in dynamic situation environment, and huge state spaces. Each agent has an independent DQN network, where the input is the observation state and the output is the corresponding Q value. Then the network is updated and iterated with the following formulation
where
is the output Q value of the target network,
is the learning rate. The action selection policy in DQN adopts the
-greedy policy to find the optimal policy
, which can be expressed as
where
denotes the optimal policy of the
n-th agent.
4.2.2. MAAC Algorithm
Each agent can perform a dynamic SA scheme based on the MAAC algorithm [
21]. There are total
N agents, which can simultaneously sense the situation and perform the corresponding actions to obtain system rewards. The system is distributed, and each agent should select actions independently using training networks. Additionally, each agent has an actor network to take action and a critic network to evaluate its actions. Using
N agents, the system can sense the situation and take the corresponding actions. In order to achieve the optimal policy for the system, all agents should learn the way to sense the situation, take action and obtain rewards. All agents receive their rewards and evaluate their actions by those rewards.
The parameters of the actor network and the critic network are and , respectively. In the actor network, the observed state of the agents is the input, and the action is the output. The action selection function selects the action based on the policy and the process can be described as . In the critic network, the current action obtained from the actor network and the current observation state are input, the Q-value is output, which is used to evaluate the actions. For each agent, the actor network is used to sense the situation and take the corresponding actions, and the critic network is used to evaluate its action based on the given policy.
The
n-th agent senses the situation, obtains the rewards, and calculates the Q-value
with the critic and the target critic networks. In this case, the loss function can be defined to update the critic network. The loss function
of the
n-th agent for the parameter
can be formulated as
where
D is the replay buffer and the function
can be defined as
For the actor network and the critic network, the parameters are
and
, respectively. Two parameters of the target networks can be updated by
where the parameter
is a soft update factor. The proposed MAAC algorithm for SA is summarized in Algorithm 3.
| Algorithm 3 The MAAC Algorithm for SA |
Initialization: Randomly initialize network parameters . Initialize buffer O. Simultaneously obtain initial observation states S0 for all agents with sensing accuracy μ.
- 1:
for do - 2:
for do - 3:
Each agent sequentially and independently selects the action based on the policy . - 4:
end for - 5:
Simultaneously execute actions for all agents to obtain rewards . - 6:
Update environment to obtain new observation states . - 7:
Store replay units of all agents in O. - 8:
for do - 9:
Randomly sample a mini-batch of replay units from O. - 10:
Calculate Q-value by the critic network. - 11:
Calculate and by target actor network and target critic network, respectively. - 12:
Calculate regression loss function to update the critic network. - 13:
Calculate via the actor network and via the critic network. - 14:
Update the action network by computing the policy gradient . - 15:
Soft update parameters of target networks by ( 19). - 16:
end for - 17:
end for
|
5. Simulation Results
In this section, the proposed DF and SA are evaluated and analyzed by simulations. Two kinds of simulations are provided to evaluate the proposed tensor-based DF scheme and DRL-based SA scheme.
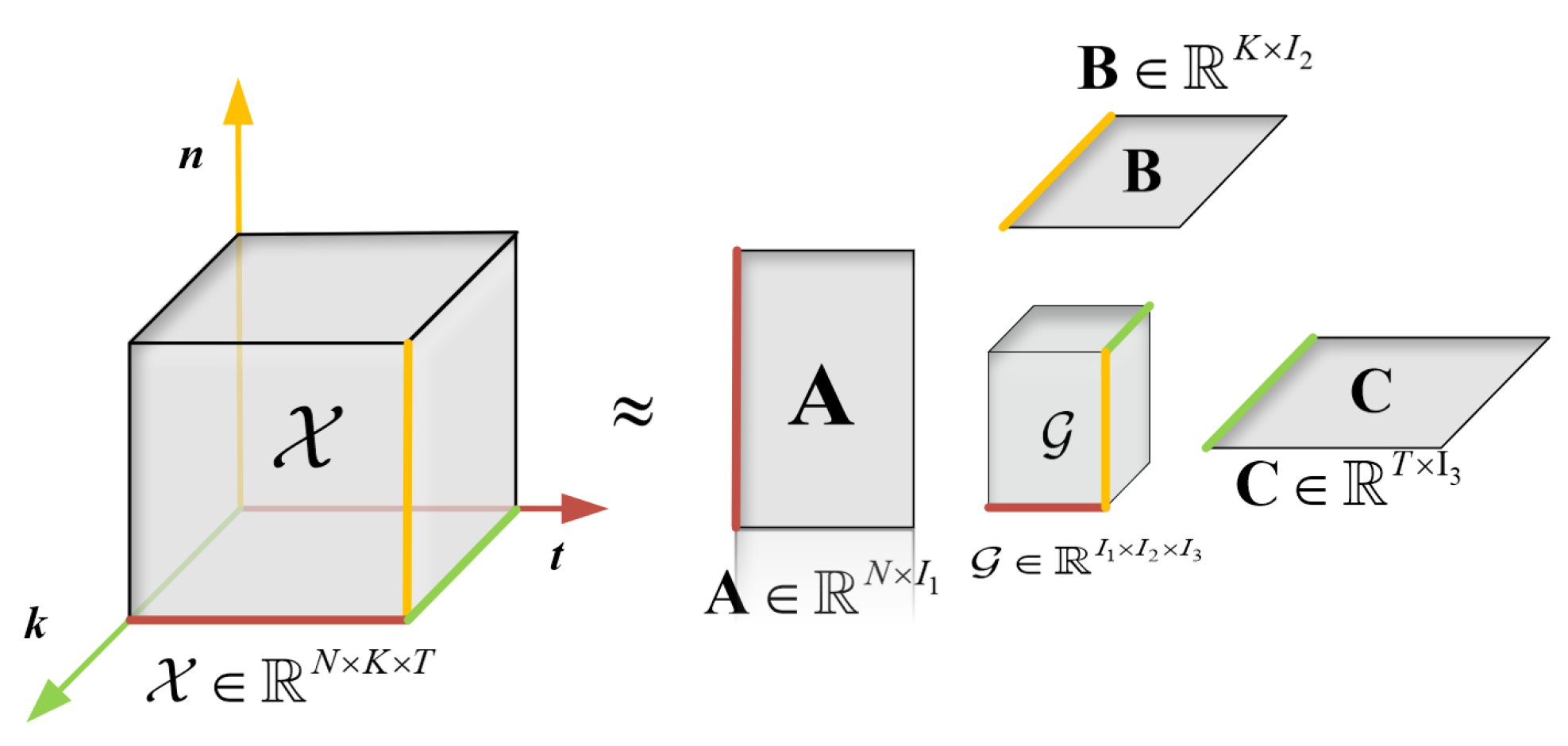
In
Figure 4, a third-order tensor
is used to illustrate the process of tensor decomposition. The tensor
is decomposed into one core tensor
and three matrices
,
, and
.
Therefore, the tensor decomposition scheme provides a way to analyze the tensor big data of smart grid and power communication networks, such as and . The core tensor can be used to keep the core information with the reduced dimensions and the three matrices , , and can be used to denote the information for the given dimension.
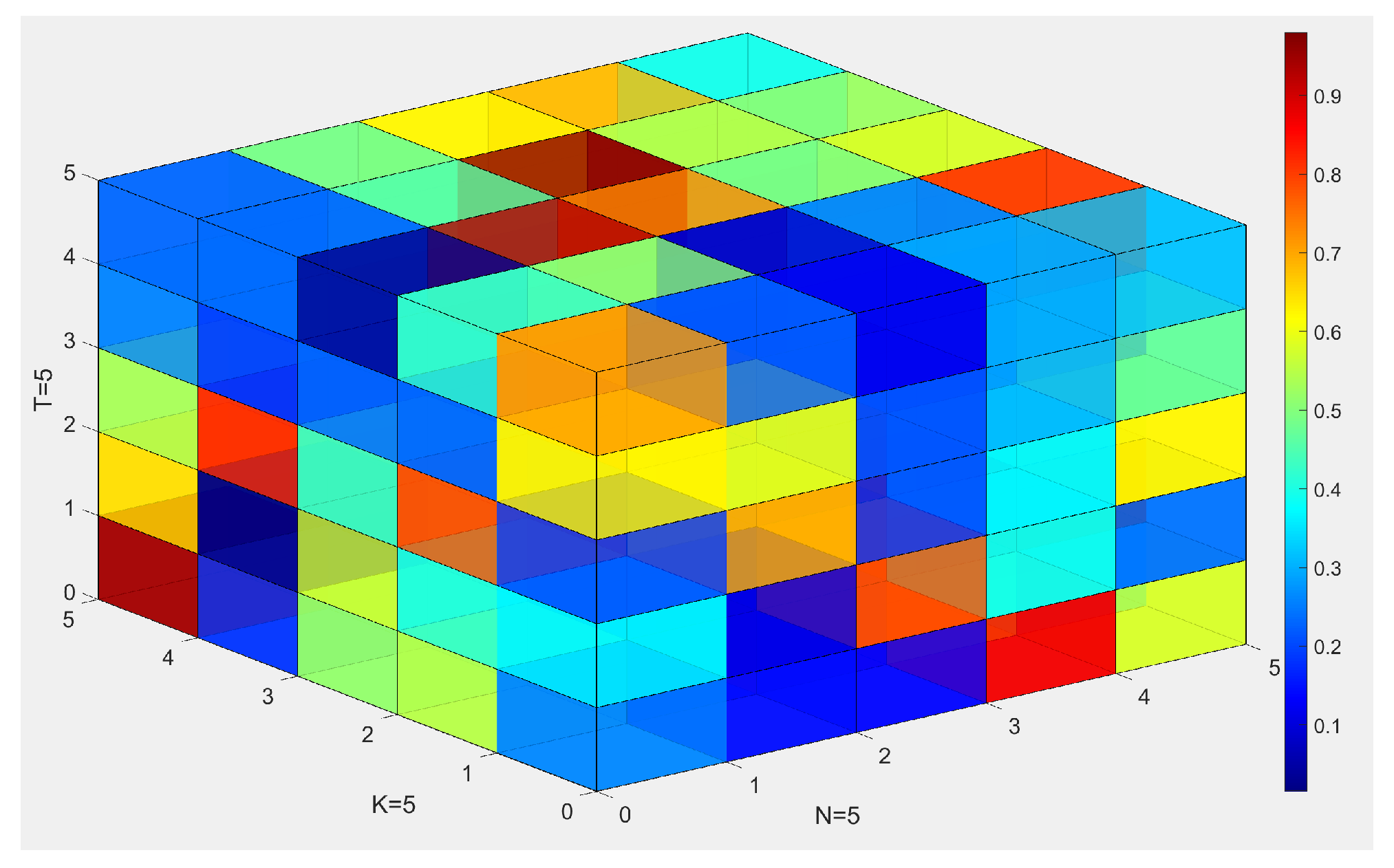
The fused tensor
is shown in
Figure 5, where there are total 125 elements
in the tensor big data. As indicated by the color bar, the value of the element is normalized by one unit. Different colors are used to indicate different element values. As indicated in this figure, the fused tensor
is generated from the tensor big data
and
as shown in
Figure 3. The fused tensor
can also be analyzed from three dimensions: five agents
, five channels
, and five time slots
. For a specific location, say
, the fused data can be evaluated by the value
.
By comparing the simulation results of the MAAC algorithm and the DQN algorithm, we evaluate the performance of the MAAC algorithm. In our simulations, for both algorithms, we set the episodes as 120,000, the reward of successful allocation r as 10, the reward of no allocation negative f as −5, and the batch size as 128, which is the number of parameters transmitted to the program for training at a time. The discount factor of the MAAC algorithm is set as 0.9, the exploration rate of the DQN algorithm decreases from 0.9 to 0.
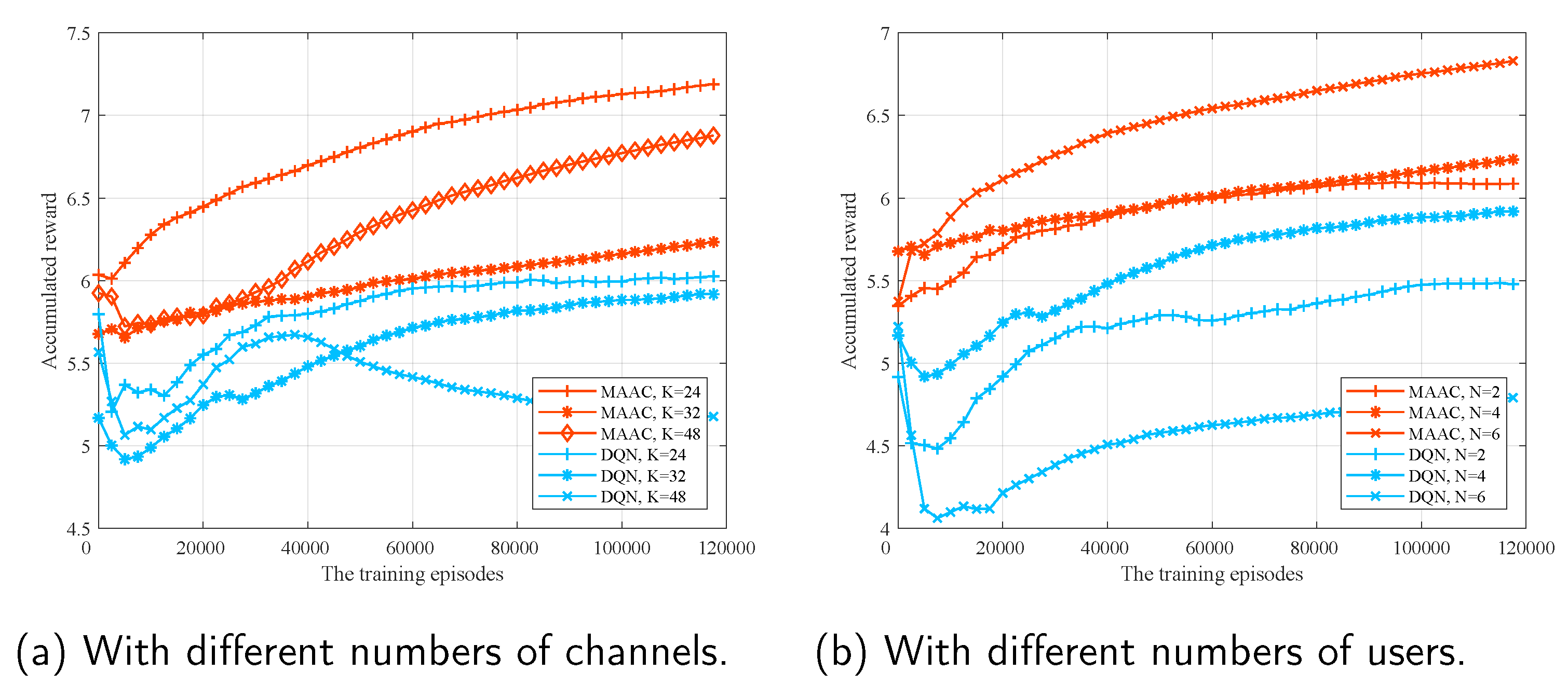
We compare the performances of the DQN algorithm and the MAAC algorithm when the number of channels is different; N = 4, and the sensing probability p = 0.9, the accumulated reward of the system is the average reward of all agents during previous episodes.
It can be seen in
Figure 6a, when K = 24, K = 32, and K = 48, the accumulated reward of the DQN algorithm increases when the training episodes = 120,000, while the accumulated reward of the MAAC algorithm is significantly higher than the reward of the DQN algorithm, the accumulated reward of the MAAC algorithm is higher than that of the DQN algorithm, and the training process of the MAAC algorithm is more stable than that of the DQN algorithm.
Then we compare the performance of the DQN algorithm and the MAAC algorithm with the different number of agents when the sensing probability p = 0.8 and the number of channels K = 32.
As shown in
Figure 6b, the MAAC algorithm not only accumulated a higher reward than the DQN algorithm but also the convergence speed is faster than the DQN algorithm; when N = 2, N = 4, and N = 6, the convergence of the MAAC algorithm is earlier than that of the DQN algorithm.
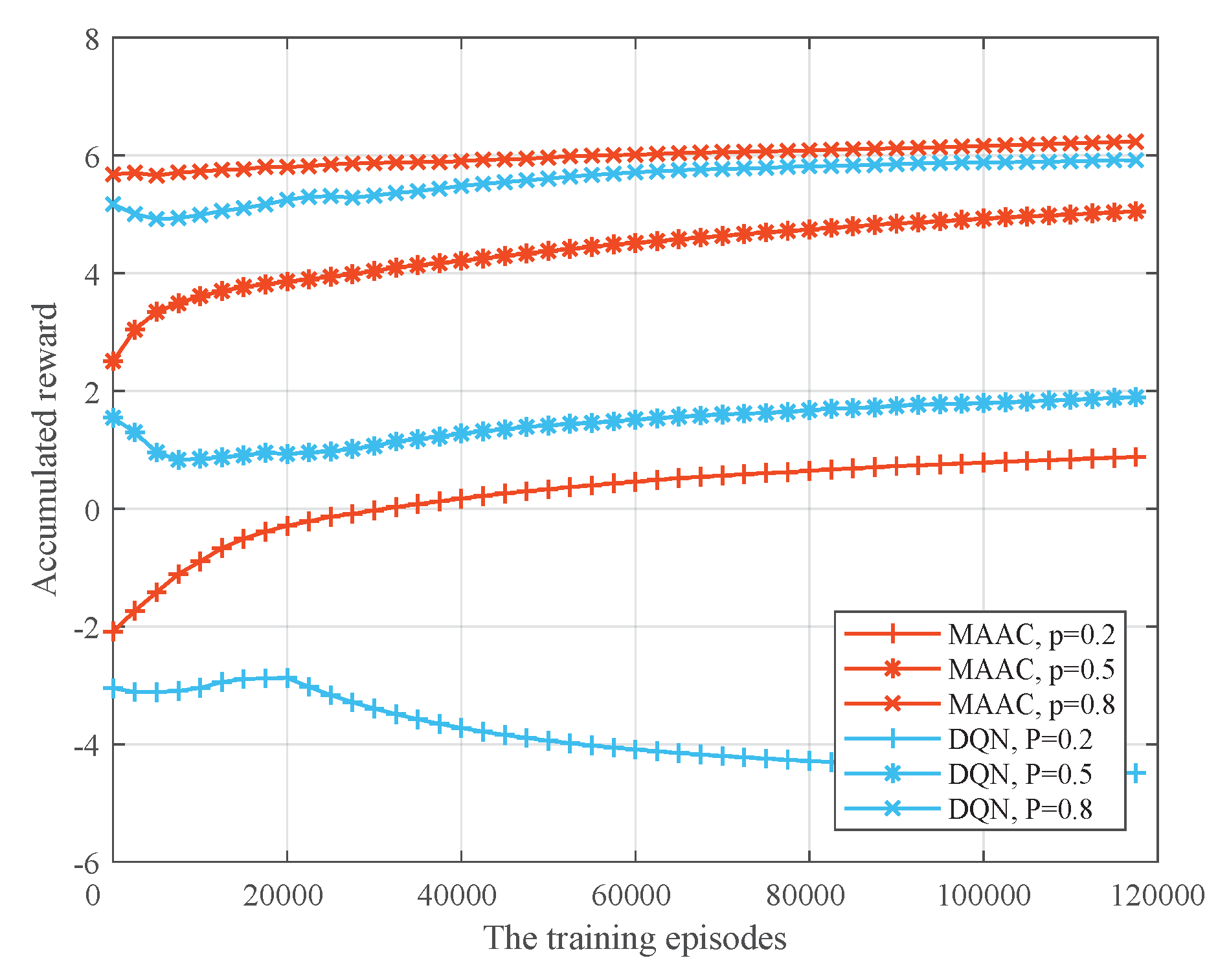
In
Figure 7, we compare the performances of the DQN algorithm and MAAC algorithm under different sensing probabilities. With the same parameters, the accumulated reward of the MAAC algorithm is always higher than the DQN algorithm. For the two algorithms, the higher the sensing probability, the higher the accumulated reward; when the sensing probability is very high such as
p = 0.8, the rewards of the two algorithms tend to be approximate.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






