
Short Text Classification Based on Hierarchical Heterogeneous Graph and LDA Fusion


Abstract
:1. Introduction
- 1.
- The short text classification technology is used to analyze the data of industrial equipment, which can better understand the running state of equipment and diagnose the fault.
- 2.
- The short text classification technology is used to classify and cluster large-scale news reports and social media topics and analyze and predict the development and trend of events.
- 3.
- According to the historical behaviors and interests of users, the short text library is classified and matched to recommend personalized goods or services for users.
2. Related Work
2.1. Short Text Classification
2.2. SHINE Model
2.3. LDA Topic Model
- 1.
- For text , the topic distribution is generated by .
- 2.
- For the nth word of the text , topic of word is generated by the polynomial distribution .
- 3.
- Determining the distribution probability matrix of topics and words is a distribution of with parameter . At the same time, according to topic , determines a term distribution .
- 4.
- According to the distribution of words , generate the selected topic term .
- 5.
- Repeat Steps 1 to 4 to generate for all words in the text. Repeat Steps 1 to 5 above for all text in the text set to generate the entire text set D.
3. Proposed Method
3.1. Word-Level Graph [13]
3.1.1. Node Embedding
3.1.2. Graph Construction
- 1.
- How to define node N:This is defined according to the characteristics to be integrated. If it is merging POS information, N is the POS tag. If it is merging entity information, then N is the entity label.
- 2.
- How to build adjacency matrix:
- Pointwise mutual information (PMI) [24]:PMI is used to measure the correlation between the two variables. The calculation formula of PMI is as follows.where x and y are two variables. The larger the PMI, the higher the correlation between the two variables.
- Cosine similarity:The cosine similarity is the cosine value of the angle between two vectors in the vector space, which is used to measure the similarity between two vectors. The calculation formula of the cosine similarity is as follows.where and are two vectors. In the trigonometric function, the function value of the cosine function is . Therefore, the cosine similarity range between the two vectors is . When the angle between the two vectors is , the similarity is 1. When the angle is , the similarity is . The larger the cosine value, the more similar the two samples are.
- 1.
- Word graph:Build a word graph [13] , where represents a graph of type W, represents a set of nodes, and represents the adjacency matrix. Firstly, the short text is segmented into words using NLTK. Then, the word set is represented as N, and the PMI between any two words in the entire dataset is calculated to construct .where . Then, use Formula (2) to learn the node representation function (W is the type of graph) based on this graph. This calculates the representation of each node, which is the embedding of each word. The initial representation uses one-hot encoding.
- 2.
- POS tag graph:Build a POS tag graph [13] , where represents a graph of type P, represents a set of nodes, and represents the adjacency matrix. The construction and node representation of the graph are similar to the word graph. The only difference is that the words in the original dataset are replaced with POS tags, and the POS tag set provided by NLTK is used to obtain the POS tags for each word in the short text.
- 3.
- Entity graph:Build an entity graph [13] , where represents a graph of type e, represents a set of nodes, and represents the adjacency matrix. The node set from the entity type is defined in the NELL knowledge base [25]. The adjacency matrix is calculated as follows.is the embedding of the entity type. It is learned by the TransE [26] method, a classic knowledge graph embedding method. In general, the NELL knowledge base [25] is first used to identify the entities contained in each text. Then, use the TransE [26] method to learn the embedding of each entity. Finally, the cosine distance calculates the similarity between two entities to fill .
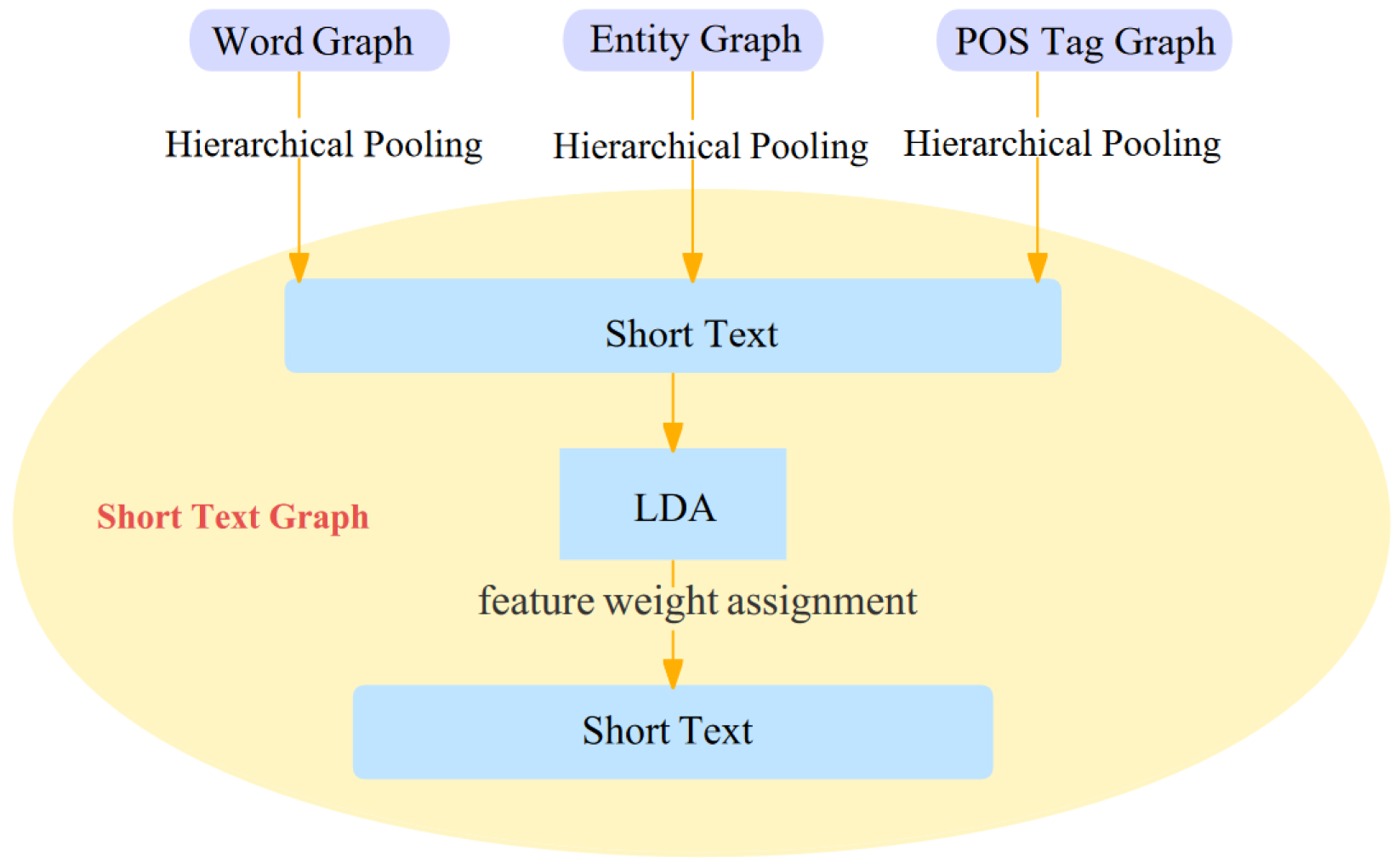
3.2. Short Text Graph
| Algorithm 1 Pseudocode for our algorithm. |
|
4. Experiments
4.1. Experimental Environment
4.2. Datasets
4.3. Hyperparameter Setting
4.4. Evaluation Metrics
- 1.
- Accuracy: Accuracy (ACC) refers to the number of samples in which the results are correctly predicted as a percentage of the total results [32].Among them, indicates that the prediction is a positive class and the actual number of texts in the positive class. indicates that the prediction is a positive class, which is the number of texts in the negative class. indicates that the prediction is negative, and it is the number of negative texts. means that the prediction is a negative class, which is the number of texts in the positive class.
- 2.
- F1 value: The F1 value is the harmonic average of the precision and recall rate. Because the precision and recall rate have difficulty in fully reflecting the classification results, the F1 value comprehensive evaluation index was introduced [33].where and .
4.5. Compared Methods
4.6. Model Sensitivity on Twitter
4.7. Application to Chinese
4.7.1. Jieba Segmentation
4.7.2. Experimental Result
5. Conclusions
- 1.
- Improved algorithm efficiency and accuracy:Future studies could continue to optimize the algorithm and improve its classification efficiency and accuracy.
- 2.
- Explore other text feature fusion methods:The algorithm fuses the hierarchical heterogeneous graph and LDA topic model to process text features, and future studies can explore the fusion methods of other text features.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LDA | Latent Dirichlet allocation |
| POS | Parts-of-speech |
| PMI | Pointwise mutual information |
| ACC | Accuracy |
References
- Maron, M.E. Automatic Indexing: An Experimental Inquiry. J. ACM 1961, 8, 404–417. [Google Scholar] [CrossRef]
- Vo, D.T.; Ock, C.Y. Learning to classify short text from scientific documents using topic models with various types of knowledge. Expert Syst. Appl. 2015, 42, 1684–1698. [Google Scholar] [CrossRef]
- Du, Y.; Yi, Y.; Li, X.; Chen, X.; Fan, Y.; Su, F. Extracting and tracking hot topics of micro-blogs based on improved Latent Dirichlet Allocation. Eng. Appl. Artif. Intell. 2020, 87, 103279. [Google Scholar] [CrossRef]
- Kilimci, Z.H.; Omurca, S.I. Extended Feature Spaces Based Classifier Ensembles for Sentiment Analysis of Short Texts. Inf. Technol. Control 2018, 47, 457–470. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Tian, N.; Li, W.; Yang, J. A Text Classification Algorithm for Power Equipment Defects Based on Random Forest. Int. J. Reliab. Qual. Saf. Eng. 2022, 29, 2240001. [Google Scholar] [CrossRef]
- Chen, H.Y. Personalized recommendation system of e-commerce based on big data analysis. J. Interdiscip. Math. 2018, 21, 1243–1247. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; He, Y.; Liu, Y.; Bao, M.; Wang, L.; Song, Y.; Yang, Q. Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018. [Google Scholar]
- Wang, J.; Wang, Z.; Zhang, D.; Yan, J. Combining Knowledge with Deep Convolutional Neural Networks for Short Text Classification. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Chen, J.; Hu, Y.; Liu, J.; Xiao, Y.; Jiang, H. Deep Short Text Classification with Knowledge Powered Attention. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’19/IAAI’19/EAAI’19), Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Hu, L.; Shi, C.; Ji, H.; Li, X.; Nie, L. HGAT: Heterogeneous Graph Attention Networks for Semi-Supervised Short Text Classification. ACM Trans. Inf. Syst. 2021, 39, 1–29. [Google Scholar] [CrossRef]
- Phan, X.H.; Nguyen, L.M.; Horiguchi, S. Learning to Classify Short and Sparse Text & Web with Hidden Topics from Large-Scale Data Collections. In Proceedings of the 17th International Conference on World Wide Web (WWW’08), Beijing, China, 21–25 April 2008; pp. 91–100. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; AAAI Press: Washington, DC, USA, 2016; pp. 2873–2879. [Google Scholar]
- Wang, Y.; Wang, S.; Yao, Q.; Dou, D. Hierarchical Heterogeneous Graph Representation Learning for Short Text Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 3091–3101. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Shallow to Deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Bicalho, P.V.; Pita, M.; Pedrosa, G.; Lacerda, A.M.; Pappa, G.L. A general framework to expand short text for topic modeling. Inf. Sci. 2017, 393, 66–81. [Google Scholar] [CrossRef]
- Tang, Q.; Li, J.; Chen, J.; Lu, H.; Du, Y.; Yang, K. Full Attention-Based Bi-GRU Neural Network for News Text Classification. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 1970–1974. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar] [CrossRef] [Green Version]
- Sitaula, C.; Shahi, T.B. Multi-channel CNN to classify nepali covid-19 related tweets using hybrid features. arXiv 2022, arXiv:2203.10286. [Google Scholar]
- Sitaula, C.; Basnet, A.; Mainali, A.; Shahi, T.B. Deep Learning-Based Methods for Sentiment Analysis on Nepali COVID-19-Related Tweets. Comput. Intell. Neurosci. 2021, 2021, 2158184. [Google Scholar] [CrossRef] [PubMed]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Porteous, I.R.; Newman, D.; Ihler, A.T.; Asuncion, A.U.; Smyth, P.; Welling, M. Fast collapsed gibbs sampling for latent dirichlet allocation. In Proceedings of the KDD, Las Legas, NV, USA, 24–27 August 2008. [Google Scholar]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Church, K.W.; Hanks, P. Word Association Norms, Mutual Information, and Lexicography. In Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 26–29 June 1989; pp. 76–83. [Google Scholar] [CrossRef]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an Architecture for Never-Ending Language Learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI’10), Atlanta, Georgia, 11–15 July 2010; AAAI Press: Washington, DC, USA, 2010; pp. 1306–1313. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS’13), Red Hook, NY, USA, 5–10 December 2013; Volume 2, pp. 2787–2795. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Classification Algorithms. In Mining Text Data; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the ACL, Ann Arbor, MI, USA, 25–30 June 2005. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’19/IAAI’19/EAAI’19), Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4821–4830. [Google Scholar] [CrossRef] [Green Version]
- Ikonomakis, E.; Kotsiantis, S.; Tampakas, V. Text classification: A recent overview. In Proceedings of the 9th WSEAS International Conference on Data Networks, Communications, Computers (DNCOCO’10), Faro, Portugal, 3–5 November 2005; p. 125. [Google Scholar]
- Yang, Y.; Liu, X. A Re-Examination of Text Categorization Methods. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’99), Berkeley, CA, USA, 15–19 August 1999; pp. 42–49. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Quantity | Average Length in Words | Classes | Train (Ratio) |
|---|---|---|---|---|
| 10,000 | 3.5 | 2 | 40 (0.40%) | |
| Snippets | 12,340 | 14.5 | 8 | 160 (1.30%) |
| TagMyNews | 32,549 | 5.1 | 7 | 140 (0.43%) |
| MR | 10,662 | 7.6 | 2 | 40 (0.38%) |
| Headlines Today | 15,425 | 19.2 | 15 | 300 (1.94%) |
| Model | Snippets | TagMyNews | MR | |||||
|---|---|---|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| SHINE | 72.54% | 72.19% | 82.39% | 81.62% | 62.50% | 56.21% | 64.58% | 63.89% |
| HGAT | 63.21% | 62.48% | 82.36% | 74.44% | 61.72% | 53.81% | 62.75% | 62.36% |
| LDA + SVM | 54.34% | 53.97% | 62.54% | 56.40% | 40.40% | 30.40% | 54.40% | 48.39% |
| SHINE + LDA | 73.17% | 73.17% | 84.45% | 84.45% | 72.75% | 72.71% | 73.00% | 69.24% |
| Model | ACC | F1 |
|---|---|---|
| LDA + SVM | 61.2% | 59.4% |
| LDA + KNN | 60.1% | 57.7% |
| LDA + TF-IDF | 86.8% | 87.1% |
| SHINE + LDA | 84.2% | 83.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Li, B.; Shen, Y.; Luo, B.; Zhang, C.; Hao, F. Short Text Classification Based on Hierarchical Heterogeneous Graph and LDA Fusion. Electronics 2023, 12, 2560. https://doi.org/10.3390/electronics12122560
Xu X, Li B, Shen Y, Luo B, Zhang C, Hao F. Short Text Classification Based on Hierarchical Heterogeneous Graph and LDA Fusion. Electronics. 2023; 12(12):2560. https://doi.org/10.3390/electronics12122560
Chicago/Turabian StyleXu, Xinlan, Bo Li, Yuhao Shen, Bing Luo, Chao Zhang, and Fei Hao. 2023. "Short Text Classification Based on Hierarchical Heterogeneous Graph and LDA Fusion" Electronics 12, no. 12: 2560. https://doi.org/10.3390/electronics12122560