
Efficient Intrusion Detection System in the Cloud Using Fusion Feature Selection Approaches and an Ensemble Classifier

 , , ,
, , ,
Abstract
:
1. Introduction
- An ensemble model is developed with the ML and DL models with SVM, LSTM, XGBoost, and FLN.
- A comprehensive feature set is generated with the help of a filter and automated feature selection.
- The weights of the selected ML and DL models are selected with the CSA.
- We overcome the issue of unbalanced datasets by utilizing the SMOTE algorithm (Synthetic Minority Oversampling Technique), with the purpose of enhancing the detection accuracy for minority-type attacks.
- The experiment is validated using old and modern benchmark datasets (NSL-KDD, Kyoto, and CSE-CIC-IDS-2018), that reflect a real-world environment involving the latest attacks. The outcomes are calculated in terms of accuracy, recall, false positive rate, false negative rate, precision, and F-measure.
2. Related Work
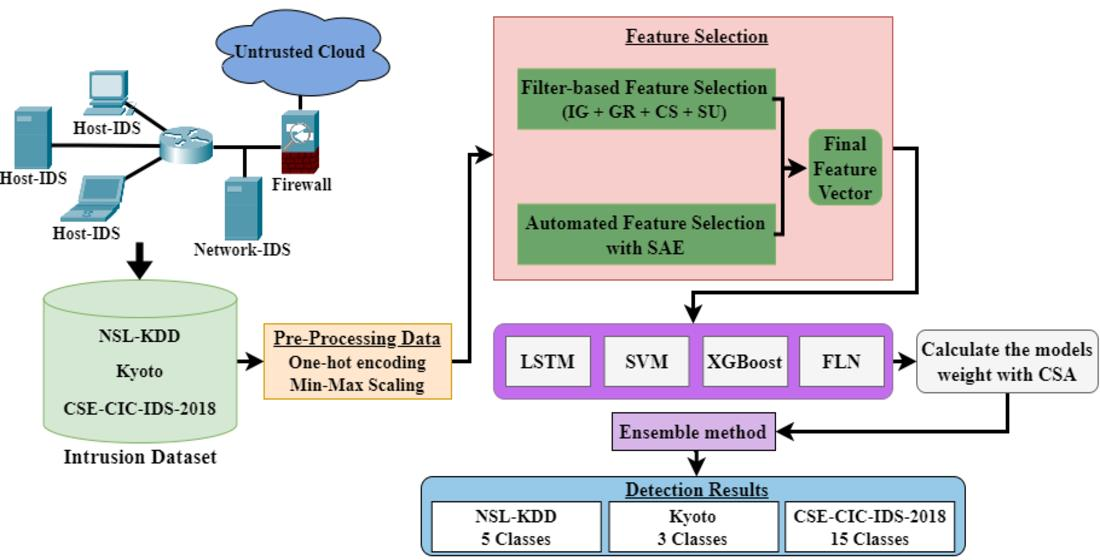
3. Methodology
3.1. Pre-Processing
- Removing the noisy, incomplete outliers and irrelevant, duplicate values and deleting features: In NSL-KDD we deleted features such as “difficulty_level”, and in the Kyoto dataset, we omitted features such as “Source IP Address”, “Destination IP Address”, etc. Furthermore, “Timestamp”, “Destination Address”, “Source Address”, “Source Port”, and other features were removed in CSE-CIC-IDS 2018 [33], that means we only retain one useful value.
- Feature encoding, also known as feature mapping, which means transforming categorical variables into numerical form. There are two methods used for this, one-hot encoding and ordinal encoding, in which one-hot encoding yields a higher classifier performance than ordinal coding [34]. As a result, one-hot encoding was adopted in this study. Protocol type, service, and flag are three symbolical characteristics in the NSL-KDD dataset. For example, the feature of protocol type has three category values (TCP, UDP, and ICMP). They form binary vectors (1, 0, 0), (0, 1, 0), and (0, 0, 1) after one-hot encoding [35], and we will perform the same operation on the Kyoto dataset. In the CSE-CIC-IDS 2018 dataset, we implement one-hot encoding on a protocol, that is a nominal feature that has three groups (protocol 0.0: hop-by-hop IPv6 “HOPOPT”, protocol 6.0: TCP, and protocol 17.0: UDP) [36].
- Feature scaling, also known as data normalization, which is a technique to convert the whole scope of values from a set of features into a predetermined range. Common methods of feature scaling are normalization and standardization. Standardization is called also Z-score normalization, where a single standard deviation and values centered around the mean indicate that the attribute’s mean tends to zero, and the resulting distribution has a standard deviation of one unit. Normalization or Min-Max scaling is the process of shifting and rescaling values so that they fall in the range [0,1], which offers satisfying outcomes in the AE procedure [36]. In our research, we used Min-Max scaling, shown in the following equation:where is the initial value, are the data after the process, is the impacting data sequence’s lowest value, and is said sequence’s highest value [37].
- Depending on the attack type, the label/class field must be gathered. The class column is split into two groups for detection: normal and abnormality. Regarding attack classification, the class column is separated into types as follows: 4 types (DOS, Probe, R2L, and U2R) in NSL-KDD [38], 2 types (known and unknown attacks) in the Kyoto dataset, and 14 types (DDOS attacks-LOIC-HTTP, DDOS attack-HOIC, DDOS attack-LOIC-UDP, FTP-Brute Force, SSH-Brute force, Brute Force-XSS, Brute Force-Web, DOS attacks-SlowHTTPTest, DOS attacks-Hulk, DOS attacks-GoldenEye, DOS attacks-Slowloris, Infilteration, Bot, and SQL Injection) in the CSE-CIC-IDS 2018 dataset.
- Feature correlation. This is a useful technique for feature engineering, and is a statistical method that defines the relevance between one or more variables in order to detect the related important features and only keep these features [39].
3.2. Feature Selection
3.2.1. Filter Methods
Information Gain
Gain Ratio
Chi-Squared
Symmetric Uncertainty
3.2.2. Automated Feature Selection with Stacked Autoencoder
3.3. Classification Using the Ensemble Learning Approach
3.3.1. LSTM
3.3.2. SVM
3.3.3. XGBoost
3.3.4. FLN
3.4. Crow Search Algorithm (CSA) and Weighted Voting
4. Experimental Results
4.1. Dataset Description
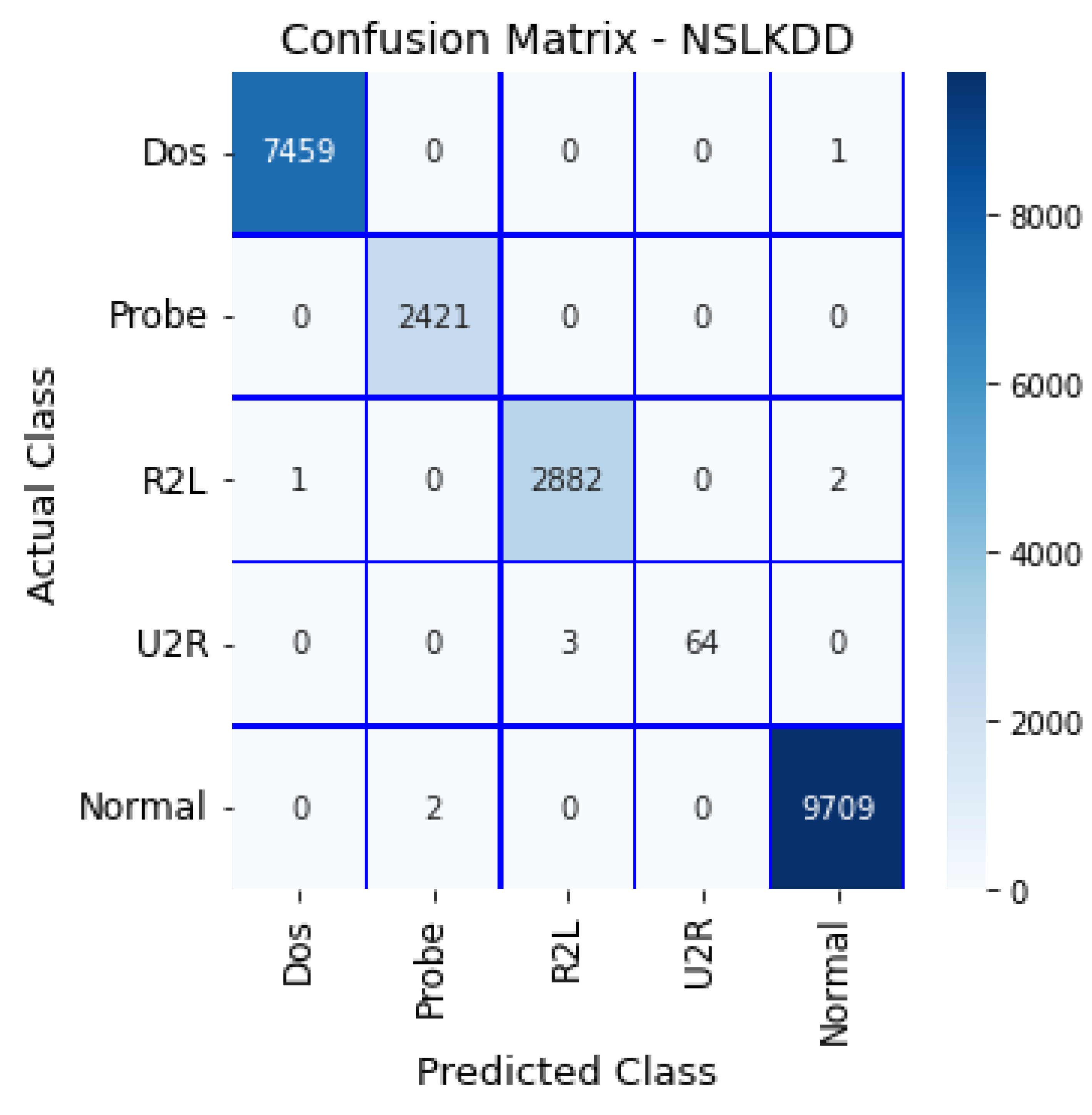
4.1.1. NSL-KDD
4.1.2. Kyoto
4.1.3. CSE-CIC-IDS-2018
4.2. Performance Metrics
- Accuracy (ACC): It is the proportion of instances that have been correctly detected to the overall number of instances. It is determined as follows:
- Recall (R): It is the proportion of successfully recognized normal instances to the total number. Furthermore, it is called the detection rate (DR), sensitivity (S), or true positive rate (TPR). It is calculated according to:
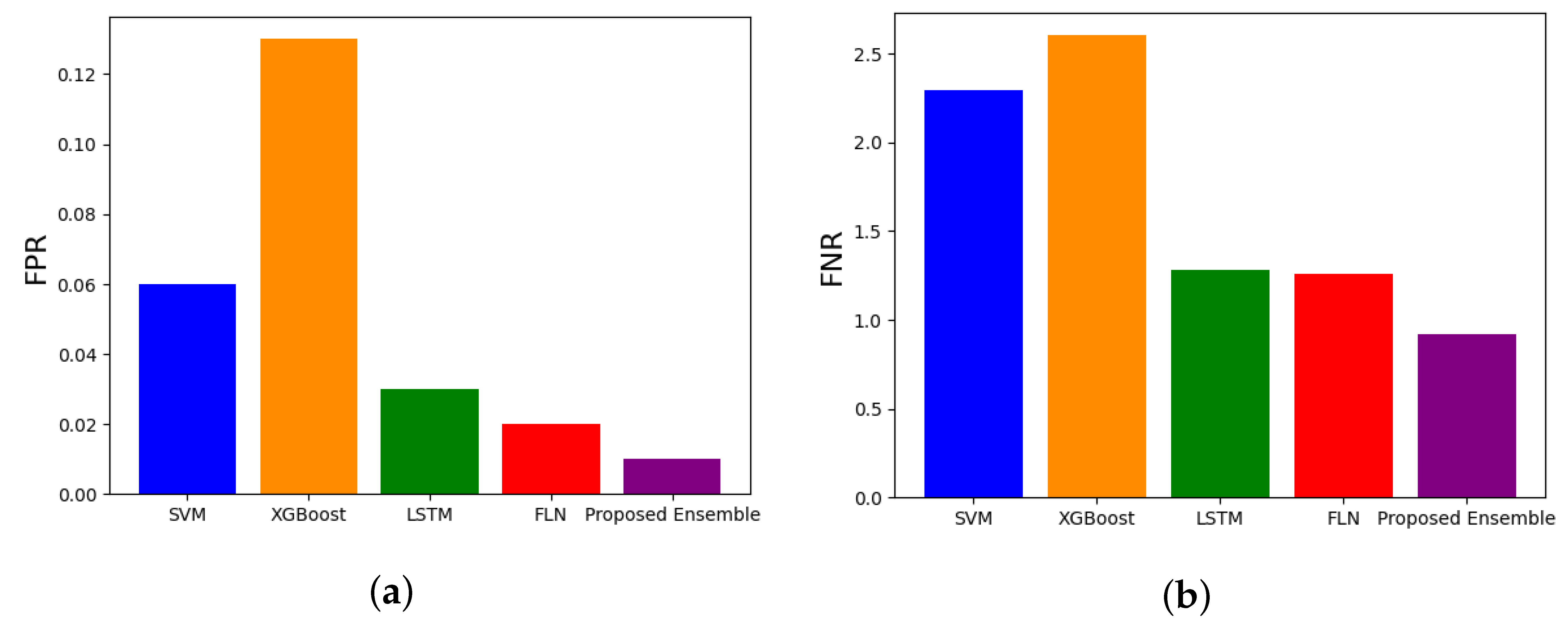
- False Alarm Rate (FAR): It calculates the ratio of records that are mistakenly detected as attacks to all records. Furthermore, it is names the false positive rate (FPR). It is estimated as follows:
- False Negative Rate (FNR): It is also known as the missed alarm rate (MAR), and is the proportion of instances that are wrongly detected as normal to all instances. It is given as follows:
- Precision (P): It is the ratio of accurately predicted attacks to all attack samples, which provides how accurate predicted positive values are. It is evaluated as follows:
- F-measure (F): It is utilized to assess the accuracy of a detection system taking into account precision and recall, also known as the F1 score. It is computed according to:
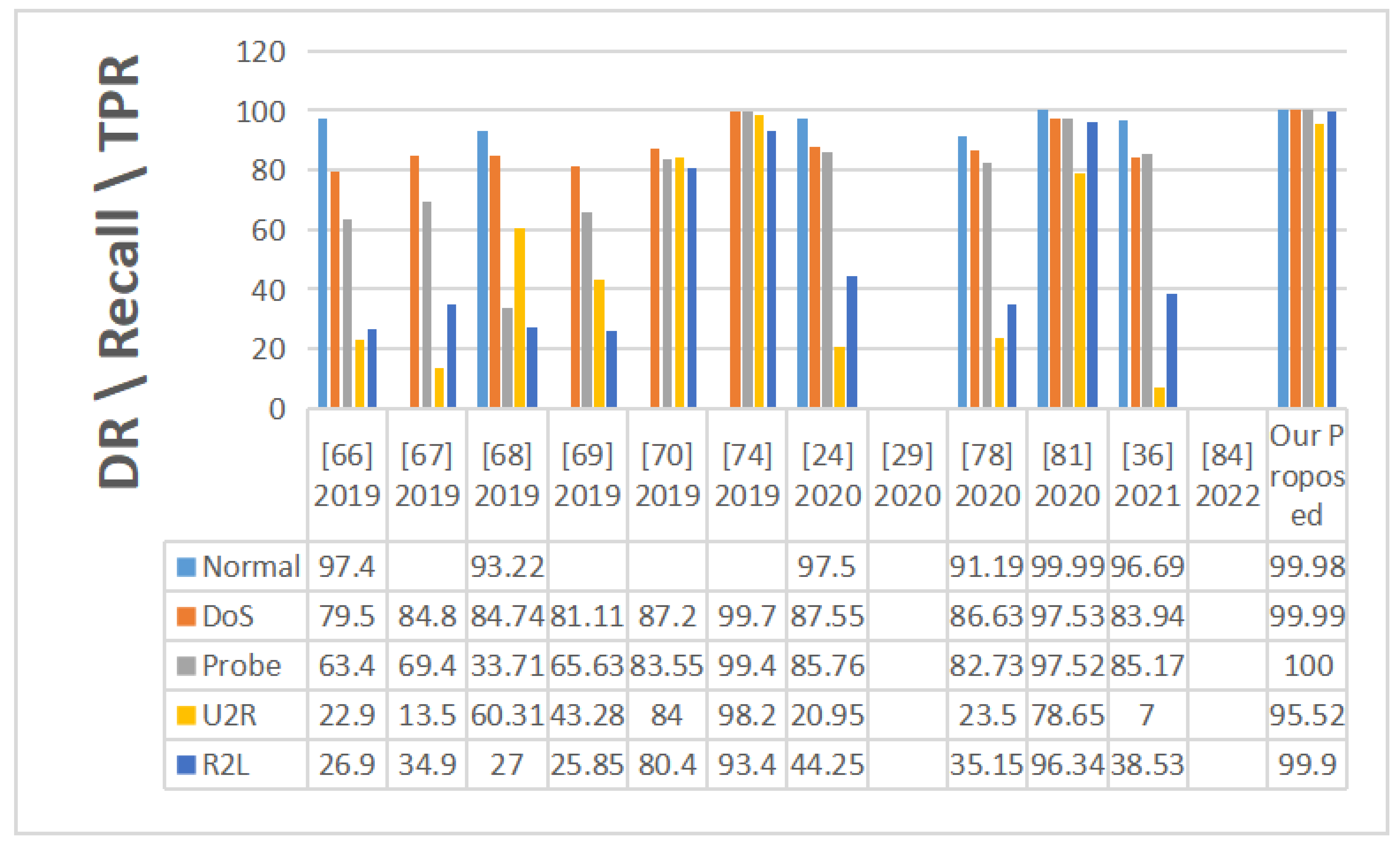
4.3. Results Discussion
- Feature selection or feature extraction methods in addition to one of the machine learning models for classification.
- Deep learning models to determine and classify features.
- A method to handle the problem of imbalanced datasets along with ML or DL models.
- Ensemble learning model based on majority voting.
- One of the optimization algorithms in addition to ML or DL models.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Reference No. | Year Published | Methodology | ACC | R | P | F |
|---|---|---|---|---|---|---|---|
| 1 | [64] | 2019 | FFDNN | 86.62 | - | - | - |
| 2 | [65] | 2019 | ICVAE-DNN | 85.97 | 77.43 | 97.39 | 86.27 |
| 3 | [66] | 2019 | 5-layers DNN | 78.50 | 78.50 | 81.00 | 76.50 |
| 4 | [67] | 2019 | WGAN-GP | 80.80 | - | - | - |
| 5 | [68] | 2019 | AE-RL | 80.16 | 80.16 | 79.74 | 79.40 |
| 6 | [69] | 2019 | CNN-1D | 78.97 | - | - | - |
| 7 | [70] | 2019 | AFSA-GA-PSO-DBN | 82.36 | - | - | - |
| 8 | [71] | 2019 | FNN-LSO | 94.04 | 89.83 | 97.43 | 93.05 |
| 9 | [72] | 2019 | MDPCA-DBN | 82.08 | 70.51 | 97.27 | 81.75 |
| 10 | [73] | 2019 | RNN-ABC | 95.62 | 95.84 | - | - |
| 11 | [74] | 2019 | GA+DBN | - | 97.67 | 97.36 | - |
| 12 | [24] | 2020 | BAT-MC | 84.25 | - | - | - |
| 13 | [29] | 2020 | CFS-BA-Voting(C4.5,RF,ForestPA) | 99.81 | 99.80 | 99.8 | 99.8 |
| 14 | [33] | 2020 | DSSTE+AlexNet | 82.84 | 82.78 | 83.94 | 81.66 |
| 15 | [40] | 2020 | AESMOTE | 82.09 | 82.09 | 84.11 | 82.43 |
| 16 | [75] | 2020 | AE | 87.00 | 82.04 | 87.85 | 81.21 |
| 17 | [76] | 2020 | FCM-SMO | 86.00 | 88.40 | 84.70 | 86.50 |
| 18 | [77] | 2020 | C5+OC-SVM | 83.24 | - | - | - |
| 19 | [78] | 2020 | Multi-CNN fusion | 81.33 | - | - | - |
| 20 | [79] | 2020 | CNN-BiLSTM | 83.58 | 84.49 | 85.82 | 85.14 |
| 21 | [80] | 2020 | DRNN | 92.18 | 94.27 | 90.23 | 92.29 |
| 22 | [81] | 2020 | GA-KELM | - | 94.01 | - | - |
| 23 | [8] | 2021 | T2FNN | - | 97.30 | 98.50 | 96.00 |
| 24 | [16] | 2021 | UEFFS | 96.06 | 97.90 | - | - |
| 25 | [18] | 2021 | MFFSEM | 84.33 | 96.43 | 74.61 | 84.13 |
| 26 | [20] | 2021 | MapReduce+GA+Random Tree | 90.45 | - | - | - |
| 27 | [21] | 2021 | CAFE-CNN | 83.43 | - | - | - |
| 28 | [36] | 2021 | PTDAE+DNN | 83.33 | 83.33 | 86.02 | 82.04 |
| 29 | [82] | 2021 | OCNN-HMLSTM | 90.67 | 95.19 | 86.71 | 91.46 |
| 30 | [83] | 2021 | I-SiamIDS | 80.00 | - | - | - |
| 31 | [30] | 2022 | IG+GR+CS-SVM | 88.15 | 90.45 | 82.87 | 83.48 |
| 32 | [84] | 2022 | ABC-BWO-CONV-LSTM | 98.67 | 100 | 97.48 | 98.73 |
| 33 | [85] | 2022 | CP-GWO-O-LSTM | 96.38 | 98.63 | 97.59 | 98.11 |
| 34 | [31] | 2023 | EGA-PSO-IRF | 98.09 | 88.53 | 96.24 | 91.87 |
| Our Proposed Ensemble | 99.01 | 99.08 | 99.95 | 99.51 |
| No | Reference No | Year Published | Methodology | ACC | R | P | F |
|---|---|---|---|---|---|---|---|
| 1 | [86] | 2014 | CSV-ISVM | - | 90.14 | - | - |
| 2 | [87] | 2015 | OS-ELM | 96.37 | 97.95 | 95.80 | 96.86 |
| 3 | [88] | 2018 | VAE-Label | - | 75.30 | 97.50 | 85.00 |
| 4 | [89] | 2018 | BA-ELM | 97.96 | 98.75 | - | - |
| 5 | [66] | 2019 | 5-layers DNN | 88.50 | 96.40 | 91.30 | 93.80 |
| 6 | [90] | 2019 | HIDS (NBFS-OSVM-PKNN) | - | 94.75 | 56.89 | - |
| 7 | [31] | 2023 | IG+GR+CS-SVM | 96.42 | 96.23 | 90.53 | 92.96 |
| Our Proposed Ensemble | 98.99 | 98.93 | 98.16 | 98.53 |
| No | Reference No | Year Published | Methodology | ACC | R | P | F |
|---|---|---|---|---|---|---|---|
| 1 | [91] | 2019 | SMOTE-LSTM+AM | 96.20 | 96.00 | 96.00 | - |
| 2 | [92] | 2019 | CNN | 95.14 | - | - | - |
| 3 | [33] | 2020 | DSSTE+miniVGGNet | 96.99 | 96.97 | 97.46 | 97.04 |
| 4 | [58] | 2020 | RBM | 96.55 | 94.00 | - | - |
| 5 | [93] | 2020 | DNN+PSO | 95.00 | 98.20 | - | - |
| 6 | [94] | 2020 | DNN | 90.25 | 59.00 | 65.00 | - |
| 7 | [36] | 2021 | PTDAE+DNN | 95.79 | 95.79 | 95.38 | 95.11 |
| 8 | [95] | 2021 | HCRNN | 97.75 | 97.12 | 96.33 | 97.60 |
| 9 | [84] | 2022 | ABC-BWO-CONV-LSTM | 98.25 | 98.67 | 97.48 | 98.18 |
| 10 | [31] | 2023 | IG+GR+CS-SVM | 99.89 | 92.93 | 93.02 | 92.97 |
| Our Proposed Ensemble | 99.99 | 99.87 | 99.96 | 99.91 |
4.4. Limitations and Constraints of the Study
- Lack of a systematically collected dataset: Creating a dataset is an expensive procedure that requires a lot of money and high-level expertise. As a result, one of the key difficulties for IDS is the systematic creation of an up-to-date dataset with sufficient examples of practically all the intruder types. To aid the research community, the dataset should be regularly updated to incorporate the most recent attack records. In the current work, datasets with older (NSL-KDD and Kyoto) and newer (CSE-CIC-IDS-2018) attacks were used to test and validate the proposal. However, we emphasize the requirement for an up-to-date comprehensive dataset that represents new attacks on real environment networks that exist today. By including the definition of the largest number of intrusions in a dataset, the system will be able to discover additional patterns and offer a defense against the greatest number of zero-day attacks.
- An unbalanced dataset has an impact on performance: It is noted from the current study that we used the SMOTE technique to increase the number of minority attack instances to balance the dataset, which led to an increase in the data size and thus the computational resources needed. Therefore, we can use random undersampling to decrease the number of instances in the majority class, then use any existing technologies such as SMOTE to oversample the minority class to balance the class distribution. However, we may try alternative approaches, such as the Difficult Set Sampling Technique (DSSTE), Adaptive Synthetic Sampling (ADASYN), RandomOverSampler (ROS), etc, to decrease the dataset’s unbalance ratio for a better performance.
- Unknown efficiency in a real-world environment: The proposal was evaluated in a lab setting based on publicly available datasets. However, it was not put to the test in a real-world setting. Therefore, it is not yet clear how it will function in real situations. Thus, to ensure that the suggested strategy works effectively for contemporary networks, it should be tested in a real-time setting after being evaluated in a lab setting.
- Resource consumption: DL models utilize power to learn features deeply, which provides outstanding results in detecting attacks; however, it demands a lot of time, storage, and computational resources. Bio-inspired algorithms can be used in the future to improve the effectiveness and intelligence of feature selection, reduce computational resources, and achieve better results.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, R.R.; Tomar, A.; Shameem, M.; Alam, M.D. Optcloud: An optimal cloud service selection framework using QoS correlation lens. Comput. Intell. Neurosci. 2022, 2022, 2019485. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.R.; Shameem, M.; Khanam, R.; Kumar, C. A hybrid evaluation framework for QoS based service selection and ranking in cloud environment. In Proceedings of the 2018 15th IEEE India Council International Conference (INDICON), Coimbatore, India, 16–18 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Kumar, R.R.; Shameem, M.; Kumar, C. A computational framework for ranking prediction of cloud services under fuzzy environment. Enterp. Inf. Syst. 2022, 16, 167–187. [Google Scholar] [CrossRef]
- Akbar, M.A.; Shameem, M.; Mahmood, S.; Alsanad, A.; Gumaei, A. Prioritization based taxonomy of cloud-based outsource software development challenges: Fuzzy AHP analysis. Appl. Soft Comput. 2020, 95, 106557. [Google Scholar] [CrossRef]
- Bakro, M.; Bisoy, S.K.; Patel, A.K.; Naal, M.A. Performance Analysis of Cloud Computing Encryption Algorithms. In Advances in Intelligent Computing and Communication; Springer: Singapore, 2021; pp. 357–367. [Google Scholar] [CrossRef]
- Bhushan, K.; Gupta, B.B. Security challenges in cloud computing: State-of-art. Int. J. Big Data Intell. 2017, 4, 81–107. [Google Scholar] [CrossRef]
- Bakro, M.; Bisoy, S.K.; Patel, A.K.; Naal, M.A. Hybrid Blockchain-Enabled Security in Cloud Storage Infrastructure Using ECC and AES Algorithms. In Blockchain Based Internet of Things; Springer: Singapore, 2022; pp. 139–170. [Google Scholar] [CrossRef]
- Srilatha, D.; Shyam, G.K. Cloud-based intrusion detection using kernel fuzzy clustering and optimal type-2 fuzzy neural network. Clust. Comput. 2021, 24, 2657–2672. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An intrusion detection system using a deep neural network with gated recurrent units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Abbas, G.; Mehmood, A.; Carsten, M.; Epiphaniou, G.; Lloret, J. Safety, Security and Privacy in Machine Learning Based Internet of Things. J. Sens. Actuator Netw. 2022, 11, 38. [Google Scholar] [CrossRef]
- Mighan, S.N.; Kahani, M. A novel scalable intrusion detection system based on deep learning. Int. J. Inf. Secur. 2021, 20, 387–403. [Google Scholar] [CrossRef]
- Mayuranathan, M.; Murugan, M.; Dhanakoti, V. Best features based intrusion detection system by RBM model for detecting DDoS in cloud environment. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 3609–3619. [Google Scholar] [CrossRef]
- Arora, N.; Kaur, P.D. A Bolasso based consistent feature selection enabled random forest classification algorithm: An application to credit risk assessment. Appl. Soft Comput. 2020, 86, 105936. [Google Scholar] [CrossRef]
- Mirza, A.H. Computer network intrusion detection using various classifiers and ensemble learning. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Kushwah, G.S.; Ranga, V. Voting extreme learning machine based distributed denial of service attack detection in cloud computing. J. Inf. Secur. Appl. 2020, 53, 102532. [Google Scholar] [CrossRef]
- Krishnaveni, S.; Sivamohan, S.; Sridhar, S.; Prabakaran, S. Efficient feature selection and classification through ensemble method for network intrusion detection on cloud computing. Clust. Comput. 2021, 24, 1761–1779. [Google Scholar] [CrossRef]
- Thaseen, I.S.; Chitturi, A.K.; Al-Turjman, F.; Shankar, A.; Ghalib, M.R.; Abhishek, K. An intelligent ensemble of long-short-term memory with genetic algorithm for network anomaly identification. Trans. Emerg. Telecommun. Technol. 2020, 33, e4149. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.L.; Liu, X.M.; Dong, C. Multi-dimensional feature fusion and stacking ensemble mechanism for network intrusion detection. Future Gener. Comput. Syst. 2021, 122, 130–143. [Google Scholar] [CrossRef]
- Singh, P.; Ranga, V. Attack and intrusion detection in cloud computing using an ensemble learning approach. Int. J. Inf. Technol. 2021, 13, 565–571. [Google Scholar] [CrossRef]
- Mehanović, D.; Kečo, D.; Kevrić, J.; Jukić, S.; Miljković, A.; Mašetić, Z. Feature selection using cloud-based parallel genetic algorithm for intrusion detection data classification. Neural Comput. Appl. 2021, 33, 11861–11873. [Google Scholar] [CrossRef]
- Shams, E.A.; Rizaner, A.; Ulusoy, A.H. A novel context-aware feature extraction method for convolutional neural network-based intrusion detection systems. Neural Comput. Appl. 2021, 33, 13647–13665. [Google Scholar] [CrossRef]
- Tummalapalli, S.R.K.; Chakravarthy, A. Intrusion detection system for cloud forensics using bayesian fuzzy clustering and optimization based SVNN. Evol. Intell. 2021, 14, 699–709. [Google Scholar] [CrossRef]
- Punitha, A.; Indumathi, G. A novel centralized cloud information accountability integrity with ensemble neural network based attack detection approach for cloud data. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4889–4900. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Bhati, B.S.; Chugh, G.; Al-Turjman, F.; Bhati, N.S. An improved ensemble based intrusion detection technique using XGBoost. Trans. Emerg. Telecommun. Technol. 2021, 32, e4076. [Google Scholar] [CrossRef]
- Suman, C.; Tripathy, S.; Saha, S. Building an effective intrusion detection system using unsupervised feature selection in multi-objective optimization framework. arXiv 2019, arXiv:1905.06562. [Google Scholar] [CrossRef]
- Rajagopal, S.; Kundapur, P.P.; Hareesha, K.S. A stacking ensemble for network intrusion detection using heterogeneous datasets. Secur. Commun. Netw. 2020, 2020, 4586875. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Conditional variational autoencoder for prediction and feature recovery applied to intrusion detection in IoT. Sensors 2017, 17, 1967. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef]
- Balyan, A.K.; Ahuja, S.; Lilhore, U.K.; Sharma, S.K.; Manoharan, P.; Algarni, A.D.; Elmannai, H.; Raahemifar, K. A hybrid intrusion detection model using ega-pso and improved random forest method. Sensors 2022, 22, 5986. [Google Scholar] [CrossRef]
- Bakro, M.; Kumar, R.R.; Bisoy, S.K.; Addas, M.O.; Khamis, D. Developing a Cloud Intrusion Detection System with Filter-Based Features Selection Techniques and SVM Classifier. In Proceedings of the Computing, Communication and Learning: First International Conference (CoCoLe 2022), Warangal, India, 27–29 October 2022; Springer: Cham, Switzerland, 2023; pp. 15–26. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Z.; Bai, R.; Mao, Y. A hybrid system with filter approach and multiple population genetic algorithm for feature selection in credit scoring. J. Comput. Appl. Math. 2018, 329, 307–321. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Potdar, K.; Pardawala, T.S.; Pai, C.D. A comparative study of categorical variable encoding techniques for neural network classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Potluri, S.; Diedrich, C. Accelerated deep neural networks for enhanced intrusion detection system. In Proceedings of the 2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Suprapto, B.Y. Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. J. Inf. Secur. Appl. 2021, 58, 102804. [Google Scholar] [CrossRef]
- Ren, F.; Long, D. Carbon emission forecasting and scenario analysis in Guangdong Province based on optimized Fast Learning Network. J. Clean. Prod. 2021, 317, 128408. [Google Scholar] [CrossRef]
- Wang, Z. Deep learning-based intrusion detection with adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Xiao, P.; Qu, W.; Qi, H.; Li, Z. Detecting DDoS attacks against data center with correlation analysis. Computer Communications 2015, 67, 66–74. [Google Scholar] [CrossRef]
- Ma, X.; Shi, W. Aesmote: Adversarial reinforcement learning with smote for anomaly detection. IEEE Trans. Netw. Sci. Eng. 2020, 8, 943–956. [Google Scholar] [CrossRef]
- Sigirci, I.O.; Albayrak, A.; Bilgin, G. Detection of mitotic cells in breast cancer histopathological images using deep versus handcrafted features. Multimed. Tools Appl. 2021, 81, 13179–13202. [Google Scholar] [CrossRef]
- Wang, W.; Liu, J.; Pitsilis, G.; Zhang, X. Abstracting massive data for lightweight intrusion detection in computer networks. Inf. Sci. 2018, 433, 417–430. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Atashgahi, Z.; Sokar, G.; van der Lee, T.; Mocanu, E.; Mocanu, D.C.; Veldhuis, R.; Pechenizkiy, M. Quick and robust feature selection: The strength of energy-efficient sparse training for autoencoders. Mach. Learn. 2021, 111, 377–414. [Google Scholar] [CrossRef]
- Yu, M.; Quan, T.; Peng, Q.; Yu, X.; Liu, L. A model-based collaborate filtering algorithm based on stacked AutoEncoder. Neural Comput. Appl. 2022, 34, 2503–2511. [Google Scholar] [CrossRef]
- Sai, A.V.; Hitesh, M.S.V.; Jadala, V.C.; Pasupuleti, S.K.; Raju, S.H.; Shameem, M. Flower Identification and Classification applying CNN through Deep Learning Methodologies. In Proceedings of the 2022 International Mobile and Embedded Technology Conference (MECON), Noida, India, 10–11 March 2022; pp. 173–180. [Google Scholar] [CrossRef]
- Ma, Z.; Guo, S.; Xu, G.; Aziz, S. Meta learning-based hybrid ensemble approach for short-term wind speed forecasting. IEEE Access 2020, 8, 172859–172868. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Soumaya, Z.; Taoufiq, B.D.; Benayad, N.; Yunus, K.; Abdelkrim, A. The detection of Parkinson disease using the genetic algorithm and SVM classifier. Appl. Acoust. 2021, 171, 107528. [Google Scholar] [CrossRef]
- Deepak, S.; Ameer, P. Automated categorization of brain tumor from mri using cnn features and svm. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 8357–8369. [Google Scholar] [CrossRef]
- Nobre, J.; Neves, R.F. Combining principal component analysis, discrete wavelet transform and XGBoost to trade in the financial markets. Expert Syst. Appl. 2019, 125, 181–194. [Google Scholar] [CrossRef]
- Adamu, A.; Abdullahi, M.; Junaidu, S.B.; Hassan, I.H. An hybrid particle swarm optimization with crow search algorithm for feature selection. Mach. Learn. Appl. 2021, 6, 100108. [Google Scholar] [CrossRef]
- Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 2016, 169, 1–12. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- Canadian Institute for Cybersecurity, University of New Brunswick. NSL-KDD | Datasets | Research | Canadian Institute for Cybersecurity | UNB. 2009. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 3 March 2022).
- Dhanabal, L.; Shantharajah, S. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Kyoto University. Traffic Data from Kyoto University Honeypots. 2006. Available online: http://www.takakura.com/Kyoto_data/new_data201704/ (accessed on 3 March 2022).
- Canadian Institute for Cybersecurity. IDS 2018 Datasets Canadian Institute for Cybersecurity. 2018. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 3 March 2022).
- Kilincer, I.F.; Ertam, F.; Sengur, A. Machine learning methods for cyber security intrusion detection: Datasets and comparative study. Comput. Netw. 2021, 188, 107840. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. A deep learning method with filter based feature engineering for wireless intrusion detection system. IEEE Access 2019, 7, 38597–38607. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Yang, Y. Improving the classification effectiveness of intrusion detection by using improved conditional variational autoencoder and deep neural network. Sensors 2019, 19, 2528. [Google Scholar] [CrossRef] [PubMed]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Wang, J.T.; Wang, C.H. High performance WGAN-GP based multiple-category network anomaly classification system. In Proceedings of the 2019 International Conference on Cyber Security for Emerging Technologies (CSET), Doha, Qatar, 27–29 October 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Caminero, G.; Lopez-Martin, M.; Carro, B. Adversarial environment reinforcement learning algorithm for intrusion detection. Comput. Netw. 2019, 159, 96–109. [Google Scholar] [CrossRef]
- Verma, A.K.; Kaushik, P.; Shrivastava, G. A network intrusion detection approach using variant of convolution neural network. In Proceedings of the 2019 International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 17–19 July 2019; pp. 409–416. [Google Scholar] [CrossRef]
- Wei, P.; Li, Y.; Zhang, Z.; Hu, T.; Li, Z.; Liu, D. An optimization method for intrusion detection classification model based on deep belief network. IEEE Access 2019, 7, 87593–87605. [Google Scholar] [CrossRef]
- Benmessahel, I.; Xie, K.; Chellal, M.; Semong, T. A new evolutionary neural networks based on intrusion detection systems using locust swarm optimization. Evol. Intell. 2019, 12, 131–146. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an effective intrusion detection system using the modified density peak clustering algorithm and deep belief networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Qureshi, A.U.; Larijani, H.; Mtetwa, N.; Javed, A.; Ahmad, J. RNN-ABC: A new swarm optimization based technique for anomaly detection. Computers 2019, 8, 59. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, P.; Wang, X. Intrusion detection for IoT based on improved genetic algorithm and deep belief network. IEEE Access 2019, 7, 31711–31722. [Google Scholar] [CrossRef]
- Ieracitano, C.; Adeel, A.; Morabito, F.C.; Hussain, A. A novel statistical analysis and autoencoder driven intelligent intrusion detection approach. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Samriya, J.K.; Kumar, N. A novel intrusion detection system using hybrid clustering-optimization approach in cloud computing. Mater. Today Proc. 2020. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J.; Alazab, A. Hybrid intrusion detection system based on the stacking ensemble of c5 decision tree classifier and one class support vector machine. Electronics 2020, 9, 173. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Liu, Z.; Hou, H.; Zheng, Y.; Xin, Y.; Zhao, Y.; Cui, L. Robust detection for network intrusion of industrial IoT based on multi-CNN fusion. Measurement 2020, 154, 107450. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, W.; Wang, A.; Wu, H. Network intrusion detection combined hybrid sampling with deep hierarchical network. IEEE Access 2020, 8, 32464–32476. [Google Scholar] [CrossRef]
- Almiani, M.; AbuGhazleh, A.; Al-Rahayfeh, A.; Atiewi, S.; Razaque, A. Deep recurrent neural network for IoT intrusion detection system. Simul. Model. Pract. Theory 2020, 101, 102031. [Google Scholar] [CrossRef]
- Ghasemi, J.; Esmaily, J.; Moradinezhad, R. Intrusion detection system using an optimized kernel extreme learning machine and efficient features. Sādhanā 2020, 45, 1–9. [Google Scholar] [CrossRef]
- Kanna, P.R.; Santhi, P. Unified deep learning approach for efficient intrusion detection system using integrated spatial–temporal features. Knowl.-Based Syst. 2021, 226, 107132. [Google Scholar] [CrossRef]
- Bedi, P.; Gupta, N.; Jindal, V. I-SiamIDS: An improved Siam-IDS for handling class imbalance in network-based intrusion detection systems. Applied Intelligence 2021, 51, 1133–1151. [Google Scholar] [CrossRef]
- Kanna, P.R.; Santhi, P. Hybrid intrusion detection using mapreduce based black widow optimized convolutional long short-term memory neural networks. Expert Syst. Appl. 2022, 194, 116545. [Google Scholar] [CrossRef]
- Dora, V.; Lakshmi, V.N. Optimal feature selection with CNN-feature learning for DDoS attack detection using meta-heuristic-based LSTM. Int. J. Intell. Robot. Appl. 2022, 6, 323–349. [Google Scholar] [CrossRef]
- Chitrakar, R.; Huang, C. Selection of candidate support vectors in incremental SVM for network intrusion detection. Comput. Secur. 2014, 45, 231–241. [Google Scholar] [CrossRef]
- Singh, R.; Kumar, H.; Singla, R. An intrusion detection system using network traffic profiling and online sequential extreme learning machine. Expert Syst. Appl. 2015, 42, 8609–8624. [Google Scholar] [CrossRef]
- Malaiya, R.K.; Kwon, D.; Kim, J.; Suh, S.C.; Kim, H.; Kim, I. An empirical evaluation of deep learning for network anomaly detection. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 893–898. [Google Scholar] [CrossRef]
- Shen, Y.; Zheng, K.; Wu, C.; Zhang, M.; Niu, X.; Yang, Y. An ensemble method based on selection using bat algorithm for intrusion detection. Comput. J. 2018, 61, 526–538. [Google Scholar] [CrossRef]
- Saleh, A.I.; Talaat, F.M.; Labib, L.M. A hybrid intrusion detection system (HIDS) based on prioritized k-nearest neighbors and optimized SVM classifiers. Artif. Intell. Rev. 2019, 51, 403–443. [Google Scholar] [CrossRef]
- Lin, P.; Ye, K.; Xu, C.Z. Dynamic network anomaly detection system by using deep learning techniques. In Proceedings of the International Conference on Cloud Computing; Springer: Cham, Switzerland, 2019; pp. 161–176. [Google Scholar] [CrossRef]
- Kim, J.; Shin, Y.; Choi, E. An intrusion detection model based on a convolutional neural network. J. Multimed. Inf. Syst. 2019, 6, 165–172. [Google Scholar] [CrossRef]
- Farhan, R.I.; Maolood, A.T.; Hassan, N.F. Optimized Deep Learning with Binary PSO for Intrusion Detection on CSE-CIC-IDS2018 Dataset. J. Al-Qadisiyah Comput. Sci. Math. 2020, 12, 16–27. [Google Scholar]
- Farhan, R.I.; Maolood, A.T.; Hassan, N. Performance analysis of flow-based attacks detection on CSE-CIC-IDS2018 dataset using deep learning. Indones. J. Electr. Eng. Comput. Sci. 2020, 20, 1413–1418. [Google Scholar] [CrossRef]
- Khan, M.A. HCRNNIDS: Hybrid convolutional recurrent neural network-based network intrusion detection system. Processes 2021, 9, 834. [Google Scholar] [CrossRef]










| KDDTrain+ | KDDTest+ | |
|---|---|---|
| Normal | 67,343 | 9711 |
| DOS | 45,927 | 7460 |
| Probe | 11,656 | 2421 |
| R2L | 995 | 2885 |
| U2R | 52 | 67 |
| Total | 125,973 | 22,544 |
| Train | Test | |
|---|---|---|
| Normal | 45,260 | 11,250 |
| Known attack | 303,412 | 75,945 |
| Unknown attack | 11,095 | 2747 |
| Total | 359,767 | 89,942 |
| Category | Attack Type | Training | Test |
|---|---|---|---|
| Benign | - | 144,198 | 36,003 |
| Botnet | Bot | 14,602 | 3759 |
| Brute Force-Web | 611 | 160 | |
| Web Attack | Brute Force-XSS | 230 | 51 |
| SQL Injection | 87 | 24 | |
| DDOS attack-HOIC | 34,376 | 8536 | |
| DDOS Attack | DDOS attack-LOIC-UDP | 1730 | 450 |
| DDOS attacks-LOIC-HTTP | 28,906 | 7215 | |
| DOS Attack | DoS attacks-GoldenEye | 8185 | 2059 |
| DOS attacks-Hulk | 23,113 | 5796 | |
| DOS attacks-SlowHTTPTest | 7068 | 1753 | |
| DOS attacks-Slowloris | 4003 | 992 | |
| Brute force | FTP-BruteForce | 9998 | 2494 |
| SSH-Bruteforce | 9973 | 2439 | |
| Infilteration | Infilteration | 8107 | 2066 |
| Total | - | 295,187 | 73,797 |
| Predicted (Attack) | Predicted (Normal) | |
|---|---|---|
| Actual (Attack) | True Positive (TP) | False Negative (FN) |
| Actual (Normal) | False Positive (FP) | True Negative (TN) |
| Method | Dataset | No. of Features | ACC | R | P | F |
|---|---|---|---|---|---|---|
| Filter methods | NSL-KDD | 50 | 97.99 | 90.42 | 96.44 | 93.13 |
| Kyoto | 10 | 96.52 | 95.81 | 94.42 | 94.88 | |
| CSE-CIC-IDS-2018 | 6 | 98.90 | 92.75 | 99.50 | 95.17 | |
| Automated with SAE methods | NSL-KDD | 93 | 98.41 | 94.33 | 98.33 | 96.17 |
| Kyoto | 33 | 97.67 | 96.96 | 96.14 | 96.43 | |
| CSE-CIC-IDS-2018 | 6 | 99.02 | 97.86 | 99.91 | 98.79 | |
| Fused features | NSL-KDD | 45 | 99.01 | 99.08 | 99.95 | 99.51 |
| Kyoto | 15 | 98.99 | 98.93 | 98.16 | 98.53 | |
| CSE-CIC-IDS-2018 | 6 | 99.99 | 99.87 | 99.96 | 99.91 |
| Method | Dataset | ACC | R | P | F |
|---|---|---|---|---|---|
| NSL-KDD | 97.01 | 90.31 | 95.45 | 92.61 | |
| Without CSA | Kyoto | 96.19 | 95.52 | 91.92 | 93.25 |
| CSE-CIC-IDS-2018 | 98.18 | 96.11 | 93.21 | 92.69 | |
| NSL-KDD | 99.01 | 99.08 | 99.95 | 99.51 | |
| With CSA | Kyoto | 98.99 | 98.93 | 98.16 | 98.53 |
| CSE-CIC-IDS-2018 | 99.99 | 99.87 | 99.96 | 99.91 |
| Attack Type | ACC | R | FAR | FNR | P | F |
|---|---|---|---|---|---|---|
| Normal | 99.98 | 99.98 | 0.02 | 0.02 | 99.97 | 99.97 |
| DOS | 99.99 | 99.99 | 0.01 | 0.01 | 99.99 | 99.99 |
| Probe | 99.99 | 100.00 | 0.01 | 0.00 | 99.92 | 99.96 |
| R2L | 99.97 | 99.90 | 0.02 | 0.10 | 99.90 | 99.90 |
| U2R | 99.99 | 95.52 | 0.00 | 4.48 | 100.00 | 97.71 |
| Attack Type | ACC | R | FAR | FNR | P | F |
|---|---|---|---|---|---|---|
| Normal | 99.65 | 97.66 | 0.07 | 2.34 | 99.53 | 98.59 |
| Known Attack | 99.48 | 99.76 | 2.00 | 0.24 | 99.63 | 99.69 |
| Unknown Attack | 99.83 | 99.38 | 0.15 | 0.62 | 95.32 | 97.31 |
| Attack Type | ACC | R | FAR | FNR | P | F |
|---|---|---|---|---|---|---|
| Benign | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| Bot | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| Brute Force-Web | 100.00 | 100.00 | 0.00 | 0.00 | 99.38 | 99.69 |
| Brute Force-XSS | 100.00 | 98.04 | 0.00 | 1.96 | 100.00 | 99.01 |
| SQL Injection | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DDOS attack-HOIC | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DDOS attack-LOIC-UDP | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DDoS attacks-LOIC-HTTP | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DoS attacks-GoldenEye | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DoS attacks-Hulk | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DoS attacks-SlowHTTPTest | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| DoS attacks-Slowloris | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| FTP-BruteForce | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| SSH-Bruteforce | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| Infilteration | 100.00 | 100.00 | 0.00 | 0.00 | 100.00 | 100.00 |
| Attack Type | Our Proposed | [36] 2021 | [58] 2020 | ||||
|---|---|---|---|---|---|---|---|
| ACC | R | FAR | ACC | R | FAR | R | |
| Benign | 100.00 | 100.00 | 0.00 | 97.48 | 99.46 | 4.48 | - |
| Bot | 100.00 | 100.00 | 0.00 | 100.00 | 99.97 | 0.00 | 96.19 |
| Brute Force-Web | 100.00 | 100.00 | 0.00 | 99.98 | 60.00 | 0.00 | 82.22 |
| Brute Force-XSS | 100.00 | 98.04 | 0.00 | 99.99 | 74.42 | 0.00 | 83.16 |
| SQL Injection | 100.00 | 100.00 | 0.00 | 100.00 | 43.75 | 0.00 | 100.00 |
| DDOS attack-HOIC | 100.00 | 100.00 | 0.00 | 100.00 | 100.00 | 0.00 | 97.54 |
| DDOS attack-LOIC-UDP | 100.00 | 100.00 | 0.00 | 99.99 | 100.00 | 0.01 | 96.15 |
| DDoS attacks-LOIC-HTTP | 100.00 | 100.00 | 0.00 | 99.98 | 99.82 | 0.00 | 96.18 |
| DoS attacks-GoldenEye | 100.00 | 100.00 | 0.00 | 100.00 | 99.93 | 0.00 | 92.01 |
| DoS attacks-Hulk | 100.00 | 100.00 | 0.00 | 100.00 | 99.99 | 0.00 | 91.32 |
| DoS attacks-SlowHTTPTest | 100.00 | 100.00 | 0.00 | 98.33 | 51.99 | 0.43 | 93.31 |
| DoS attacks-Slowloris | 100.00 | 100.00 | 0.00 | 100.00 | 100.00 | 0.00 | 97.04 |
| FTP-BruteForce | 100.00 | 100.00 | 0.00 | 98.33 | 88.16 | 1.29 | 100.00 |
| SSH-Bruteforce | 100.00 | 100.00 | 0.00 | 100.00 | 99.97 | 0.00 | 100.00 |
| Infilteration | 100.00 | 100.00 | 0.00 | 97.50 | 23.84 | 0.27 | 96.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakro, M.; Kumar, R.R.; Alabrah, A.A.; Ashraf, Z.; Bisoy, S.K.; Parveen, N.; Khawatmi, S.; Abdelsalam, A. Efficient Intrusion Detection System in the Cloud Using Fusion Feature Selection Approaches and an Ensemble Classifier. Electronics 2023, 12, 2427. https://doi.org/10.3390/electronics12112427
Bakro M, Kumar RR, Alabrah AA, Ashraf Z, Bisoy SK, Parveen N, Khawatmi S, Abdelsalam A. Efficient Intrusion Detection System in the Cloud Using Fusion Feature Selection Approaches and an Ensemble Classifier. Electronics. 2023; 12(11):2427. https://doi.org/10.3390/electronics12112427
Chicago/Turabian StyleBakro, Mhamad, Rakesh Ranjan Kumar, Amerah A. Alabrah, Zubair Ashraf, Sukant K. Bisoy, Nikhat Parveen, Souheil Khawatmi, and Ahmed Abdelsalam. 2023. "Efficient Intrusion Detection System in the Cloud Using Fusion Feature Selection Approaches and an Ensemble Classifier" Electronics 12, no. 11: 2427. https://doi.org/10.3390/electronics12112427